
考试评价在教学诊断中的应用探索
2024-01-04 07:56丁秀涛
考试研究 2023年5期
丁秀涛
[摘要]“加强考试评价研究,挖掘考试数据中蕴藏的教育教学信息”是实现高考引导基础教育教学的一个重要途径。实践中,模型简单、浅显易懂的经典测量理论在群体教学诊断方面具有明显优势。基于常模对高考各学科试卷进行知识、能力、素养等多维度的结构分析,通过分层分类分析法对考试数据进行深入挖掘,用考试数据进行区域教学诊断,能够发现不同区域、不同考生群体的学科优势与不足,引导教师更加关注学生的学科知识掌握情况、能力发展情况、素养形成情况,有利于破除唯分数、唯升学的弊端。未来需要进一步加强对考试数据挖掘分析方法的研究;进行“无锚”等值技术和方法的研究;将结果性考试数据与学校过程性考试数据相结合,进行教学综合诊断。
[关键词]高考;考试数据分析;考试评价;教学诊断
[中图分类号]G424.74[文献标识码]A
[文章编号]1673—1654(2023)05—041—009
基金项目北京市教育科学“十三五”规划2019年度优先关注课题“高考综合改革背景下的考试评价研究与实践”(CDEA19057)。
有什么样的评价指挥棒,就有什么样的办学导向。为深入贯彻落实习近平总书记关于教育的重要论述和全国教育大会精神,2020年10月,中共中央、国务院印发《深化新时代教育评价改革总体方案》,提出“坚持科学有效,改进结果评价,强化过程评价,探索增值评价,健全综合评价”。旨在破除“唯分数、唯升学、唯文凭、唯论文、唯帽子”的痼疾,扭转不科学的教育评价导向[1]。
高考是连接基础教育和高等教育的重要枢纽,对基础教育发挥着“指挥棒”作用。《中国高考评价体系》将高考的核心功能确定为“立德树人、服务选才、引导教学”[2]。可见,正在推进实施的新一轮高考改革特别注重高考对基础教育教学的引导。如何让考试正确引导教育教学?一个重要途径就是加强考试评价研究,通过分析考试数据,挖掘考试数据中蕴藏的教育教学信息,反馈指导教育教学,充分发挥考试数据在教学评价与诊断中的作用。
有研究者基于中国知网2010-2019年的文献,对近10年来普通高考考试数据的研究现状进行了计量分析,发现:高考数据在使用量方面极其有限,基于高考考试数据研究的期刊论文数量偏少,只占高考研究文献的1%;而且研究中所挖掘的数据量有限,很多文献仅是基于当年某个学校或某个地区的数据进行挖掘,数据样本很小,基于全国、全省级行政区的高考数据分析十分有限[3]。
作为大规模教育考试,高考不仅能够完成公平评价、选拔新生的任务,而且其考试数据中蕴藏着丰富的教育教学信息,如果只将高考作为高校录取的工具,是一种巨大的资源浪费。应当以问题为导向,以改进教学为目的,充分挖掘、分析考试数据,发挥考试数据诊断、引导教学的功能。
本着在我国现阶段可操作、可推广的原则,本文提出一些能够运用于反馈、诊断实际教学的考试数据分析方法,以期为挖掘、利用考试数据,促进教、学、考、招协同共进提供借鉴与参考。
一、研究方法
(一)测量理论的选择
从利用考试数据反馈、诊断、指导教育教学的角度而言,考试评价研究的客体是教育教学情况,媒介是各学科试卷(测试工具)与考试数据,考试评价研究的最终目的是改进教育教学。2019年6月,国务院办公厅印发《关于新时代推进普通高中育人方式改革的指导意见》(以下简称《意见》),提出:减少高中统考统测和日常考试,加强考试数据分析,认真做好反馈,引导改进教学[4]。文件明确了对于考试及考试数据分析利用的要求。减少考试与统测次数,就需要更加充分地分析利用考试数据,更加充分地发挥每一次考试的功能,利用考试数据诊断教学效果,利用考试数据反馈、改进教学。
在教育考试评价领域里,经典测量理论(Classical Testing Theory,CTT)与项目反应理论(Item Response Theory,IRT)是目前被广泛使用的两种测验理论,二者各有优势[5]。近年来,项目反应理论得到业内的广泛重视,这对考试评价领域来说是一大进步。项目反应理论在测验等值、题库建设、量表开发等方面明显优于经典测量理论,但项目反应理论却不能替代经典测量理论,尤其在我国现阶段,对于广大一线教育工作者来说,项目反应理论专业性较强,需要一定的专业背景方能理解与使用,在短时间内很难大范围运用于分析、诊断教学。
从广泛理解与接受度来说,模型简单、浅显易懂的经典测量理论具有明显优势。因此,选用更容易被普遍理解和接受的经典测量理论与方法展开相关研究。
(二)研究假设
基于考试数据进行教学诊断的前提是各学科试题能够考查出考生的真实水平,达到应有的信度、效度、区分度等测量学指标。为验证这一点,北京市每年在高考各学科考后都会第一时间召开各区教研员、教师代表参加的考后座谈会;进行试卷质量的无记名问卷调查;出成绩后进行相应测量学指标的检验。多年来,无论是定性调研还是定量检验,都证明北京市各学科高考试题达到了包括信度、效度、区分度等在内的相关测量学要求。
因此,提出以下三点假设作为研究的前提:(1)考生的各学科考试成绩能够反映考生各学科知识、能力的水平;(2)考生群体的各学科成绩能够反映相应考生群体的学科知识、能力的水平;(3)不同考生群体的学科知识、能力水平可以反映一个区域的教育教学情况。
(三)评价依据
一直以来,《普通高中课程标准》和《高考考试大纲》是课程教学和高考命题的依据,也是考试评价的依据。2018年1月,教育部发布《普通高中课程方案和课程标准(2017年版)》,首次基于学科本质凝练了各学科的核心素养,研制了各学科的学业质量标准,明确了学生完成各学科学习任务后,学科核心素养应达到的水平,应达成的正确价值观念、必备品格和关键能力、关键表现。明确要求“校内评价或考试、学业水平考试、普通高等学校招生全国统一考试均应以本课程方案、课程标准和国家相关教学文件为依据”[6]。同时,国务院办公厅在《意见》中也明确提出:学业水平选择性考试与高等学校招生全国统一考试命题要以普通高中课程标准和高校人才选拔要求为依据,实施普通高中新课程的省份不再制定考试大纲[4]。因此,在高考综合改革背景下,《普通高中课程方案和课程标准》既是课程教学的依据,也是考试命题的依据,更是考试评价的标准与尺度。在考试评价研究中,遵循《普通高中课程方案和課程标准》,是保证评价结果科学性的前提与基础。
(四)在定量分析的基础上进行质性研究
20世纪80年代,以库巴(Egong Guba)和林肯(Y. S.Lincoln)等为代表创立了“第四代教育评价理论”。第四代评价理论在实证的基础上,引进了质性研究方法,注意了评价过程中评价双方的互动作用及动态分析。他们提倡在评价中充分听取不同方面的意见,并把评价看作是一个由评价者不断协调各种价值标准间的分歧、缩短不同意见间的距离、最后形成公认的一致看法的过程。这是在将基于考试数据的考试评价应用于诊断、指导教育教学中可以借鉴的。
为此,北京高考考试评价将定量分析与质性研究相结合,在对考试数据量化研究的基础上进一步采用质性评价方法。量化评价使用测量手段,用统计分析方法和数学量来评价教育现象;质性评价通过观察和实践,用定性的分析辩证地认识教育现象。质性评价既是量化评价的基础,也使量化数据分析得以深入,对问题间的交互影响和因果关系的分析具有独到的优势。把统计数据和评价者的经验、对教学现状的把握结合在一起,在评价中与中学教师互动,就是力求将学生的学习过程和教学过程体现在评价中。
二、基于诊断教学的考试数据分析方法
(一)分层分类分析法
我国幅员辽阔,各省市基础教育发展存在较大差异,而对于一个省市来说,不同地区基础教育发展也不均衡。这种差异、不均衡与当地的经济发展、生源、师资、学校软硬件、学生家庭背景等条件密切相关。如果忽视这些不同条件,只用一个标准来衡量不同区域、不同学校学生的学业水平是不科学的。因此,在利用考试数据分析、诊断教育教学时,有必要对各地区、各学校进行分层和分类,不同区域、不同类别学校用更适合各自的尺度来衡量,这样才能够准确诊断不同区域、不同学校的教育教学情况。
与全国多数省市相比,北京市总体基础教育规模较小且相对均衡,即便如此,就北京市基础教育内部来说,仍然存在发展不均衡问题。例如,城区与郊区基础教育之间存在较大差异,加上初中升高中,使郊区优质生源向城区的流动、优秀教师从郊区向城区的流动,进一步加大了城郊之間高中教育的差距。同样,在一个区的不同学校之间,也存在相似情况。因此,必须进行分层分类分析。同时,为了避免片面的唯高考成绩论英雄评价各个学校,与各区约定:不进行单个学校考试数据分析,请各区根据本区教育教学实际情况将高中学校分为三至四类(同一类别学校的基本情况大致相同或相近)。根据各区划分的学校类别,对各区高考数据进行多层次分析,形成各区的高考数据分析报告。各区的数据报告包括北京市整体、城区、郊区、本区整体、本区各类别学校5个层次。
(二)常模参照、相对比较法
高考的高利害性使得基于锚人、锚题等测验等值的测量技术难以实现。这就使得直接利用高考数据进行教学诊断分析带有局限性。为此,提出常模参照、相对比较法。
常模是一种供比较的标准量数,由标准化样本测试结果计算而来,即某一标准化样本的平均数和标准差,它是用于比较和解释测验结果时的参照分数标准。可细分为组间常模、组内常模。
北京采取的是全样本分析,首先将市整体、城区、郊区的全样本作为三个组间常模群体。为了便于各区优势类别学校找到合适的参照目标,另从原来的市级示范校与区级示范校中分别抽取10所学校,形成示范校一、示范校二作为示范校抽样的组间常模。
为了更精准地分析一个群体内不同层次考生的特点及其相应的教育教学情况,进一步按照各考生群体的学科总分从低到高平均分成10个学科能力水平组,形成该考生群体的10个组内常模群体G1—G10。
这样,提供给各区用于诊断教学的高考数据,除了该区考试数据,还有北京市整体、城区、郊区、示范校一、示范校二5个组间常模数据,各区数据与各组间常模数据又都包括10个组内常模数据,供各区对区整体以及各类学校、各能力水平组学生进行学习情况的对比研究和分析。
三、多维度挖掘,让考试数据发挥独有价值
考试数据中蕴藏着丰富的教育教学信息,只有结合学科特点,依据学科课程标准,进行多维度深入分析,才能发现考试数据独有的价值。
(一)维度划分
北京在高考评价中,对每一类别的考生群体数据进行了分学科、多维度的挖掘分析。以某年度高考语文学科为例,分析维度包括:总分分析、题型分析、各内容组块分析、各能力组块分析、各专题分析以及各大题、各小题、各选项分析,等等。其中内容组块包括:多文本阅读、文言文阅读、古代诗歌阅读、文学作品阅读、微写作与大作文;能力组块包括:识记、理解、运用、分析综合、鉴赏评价与综合表达;专题分析包括:文言文文本内容的理解、文言文文本内容的归纳概括、古典诗歌内容的理解和作者情感的体察、古诗文名句名篇的识记理解和运用、现代文中信息的筛选整合、现代文作者思想感情观点态度的理解分析等。
(二)客观、科学解读,赋予考试数据实践价值
经过对各学科的每一个能够对教学诊断作为证据的维度进行统计分析,完成各学科的考试数据分析报告,只是完成了对各学科考试数据的定量研究,更加重要的是对这些数据报告进行客观、科学的解读,对考试数据进行质性分析,赋予考试数据实践价值。这时,需要各学科的评价专家在听取各区教师、教研员对各学科试卷的意见以及一线教师与考生反馈的基础上,对照《普通高中课程方案和课程标准》,运用自己的教学经验和对教学现状的客观把握,分析数据统计结果、考生的学科知识掌握情况、学科能力发展水平以及学科素养形成情况,研究所映射出的学科教育教学情况,探究影响教学的各种因素,进行归因分析,提出教学改进建议。
(三)案例分析
从《某年度北京市高考语文学科考生水平评价及教学建议》中选取一个案例,介绍高考评价在教学诊断中的具体应用方法。
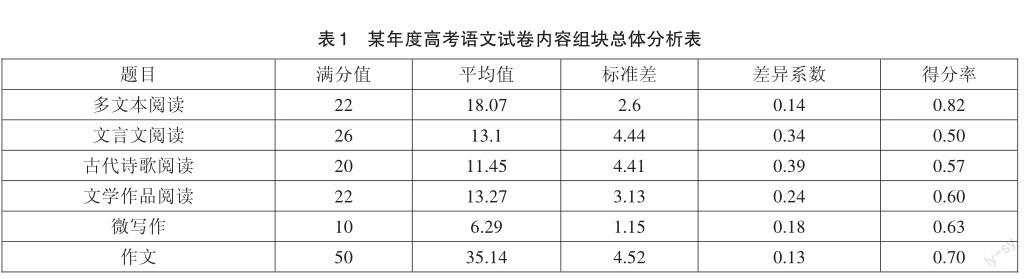
评价研究组将当年语文学科试卷按照考查内容分为多文本阅读、文言文阅读、古代诗歌阅读、文学作品阅读、微写作、大作文6个组块。全市考生在各组块的整体表现如表1所示:
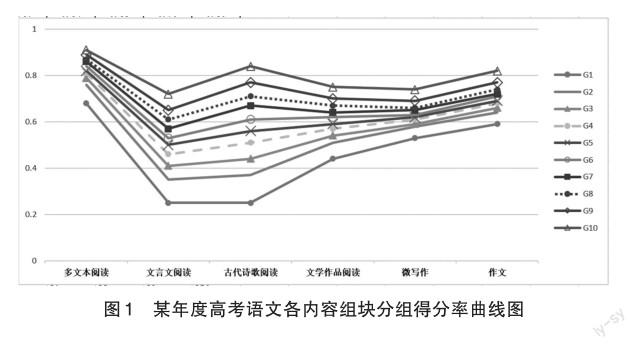
从表1可以看出,各内容组块考生得分率由高到低依次为多文本阅读、作文、微写作、文学作品阅读、古代诗歌阅读、文言文阅读,考生得分率最低的是古诗文阅读。结合标准差和差异系数看,考生成绩在古代诗歌阅读和文言文阅读两个组块离散程度最大。为了解不同能力水平学生的特点,将考生按照语文学科总分从低到高平均分为10组(G1-G10),根据各组考生在各知识组块的得分率做出该年度高考语文各内容组块分组得分率曲线图。
从图1可以明显看出,各内容组块高分组与低分组水平差距由大到小依次为古代诗歌阅读、文言文阅读、文学作品阅读、多文本阅读、作文、微写作。可以说,古诗文阅读是拉开考生差距的关键组块。对于古代诗歌阅读,全市前20%的优秀学生得分率能够达到0.7以上,而后20%的学生得分率低于0.4。對于文言文阅读,无论哪个层次的考生,表现都不令人满意,全市前10%的优秀学生得分率也未能达到0.8,全市中等生(G3-G7)得分率在0.5左右,而后20%的学生得分率仅在0.3左右。这固然有命题难度的原因,但也暴露出学生在古诗文阅读方面的薄弱之处[7]。
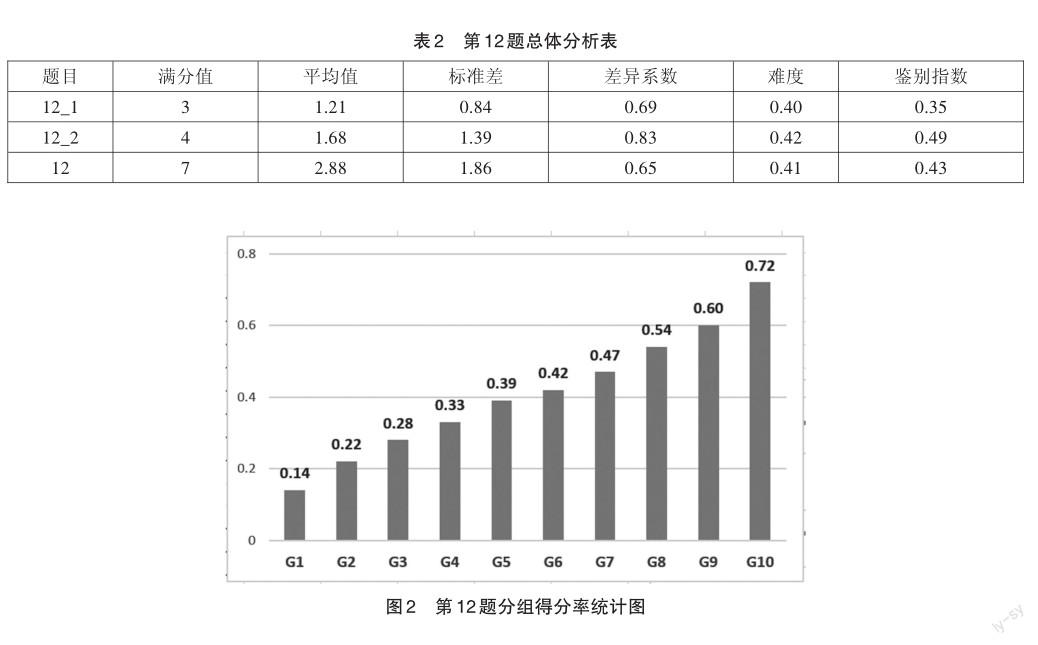
进一步从当年古诗文阅读组块中选取第12题进行分析。
第12题考查了传统文化经典《论语》的阅读。其中,第12_1题需要考生在理解文意的基础上把握孔子的思想,第12_2题则要求考生能够准确解说不同学者对同一句子的解读,既考查独立阅读文言文的能力,又考查对孔子思想的把握。
结合表2相关数据及图2可知,第12题得分率为0.41,考生整体表现不理想。G10组考生优势较明显,平均得分率为0.72,G1-G3组得分率均在0.30之下,其中G1组得分率只有0.14。
评价专家认为,客观地说,在本届学生的教学过程中,广大一线教师对《论语》的阅读非常重视,在内容整合、专题教学、策略优化等方面付出了许多努力,但从第12题考生的表现看,成效还有待提升。文化经典论著教学面临着诸多挑战:阅读时有较大的文字障碍,基础薄弱的学生读懂尤其困难;内涵丰厚,博大精深,对学生的认识水平、思维能力要求较高。但是,无论是弘扬中华民族优秀的传统文化,还是为各学科阅读古代文献提供助力,都需要切实提高学生的古文阅读能力。因此,建议教学中进一步加大古文阅读量的积累,且注重“面”(不同文体)的拓展,在此基础之上,将古文当作现代文来教,培养阅读理解能力,尤其是读懂文意的能力[7]。
四、基于考试数据进行区域教学诊断
(一)参照常模群体的选择确定
测验分数必须与某种标准比较,才能显示出它所代表的意义。选择参照常模群体就是为所研究的考生群体寻找一个参照标准。如果参照标准过高,将会直接影响研究对象改进的积极性与自信心,认为自己无论怎样努力也赶不上目标;而参照标准过低又会使研究对象认为自己已经达标而缺少继续改进的动力。因此,选择参照常模群体的原则是“跳一跳,够得着”,选择略高于研究对象水平的常模群体作为参照标准。
当利用高考考试数据进行某研究区域各学科教学情况分析时,可以通过对各群体总分的分析,找到略高于该区域总分得分率、分数分布相近的组内常模群体作为参照常模群体。为便于进行连续追踪研究,参照常模群体选定后应稳定一个时期。进入新一轮高考综合改革后,高中学业水平选择性考试(即等级考)等级转换分的加入使得高考总分的教学诊断意义降低。但是,由于各组间常模群体的整体水平是相对稳定的,故仍可使用改革前的高考总分来确定参照常模群体,这样,也有利于进行改革前后的对比研究。
因高考数据的敏感性,不便选用近两年的数据。因此,下面以改革前某区某年理科数据为例,演示如何选择确定参照常模群体。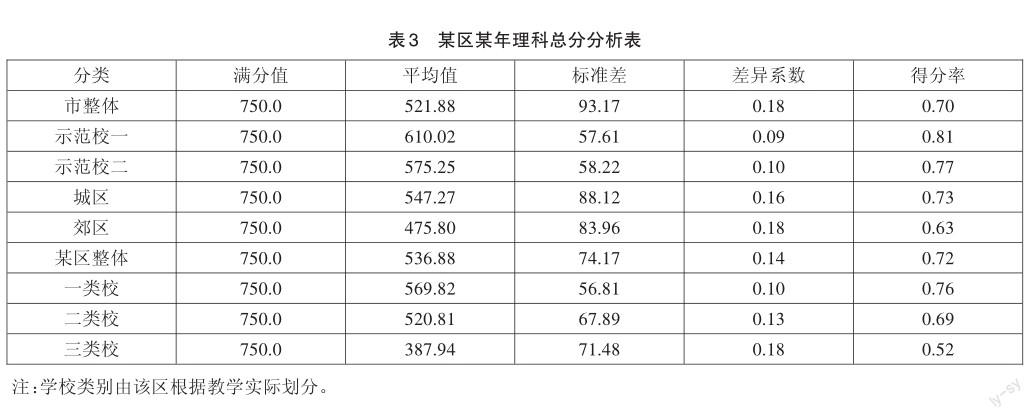
从表3可以看出:该区理科考生整体水平介于城区与全市平均水平之间,其中,一类校学生最为均衡,水平略低于示范校二,离散程度接近;二类校水平与北京市整体接近,但学生差异明显小于全市整体;三类校是该区教学的薄弱点,考生间差异最大,不仅与一、二类校有较大差距,而且水平远低于郊区平均水平。因此,选定城区作为该区整体的参照常模群体,选择示范校二作为该区一类校的参照常模群体,选择市整体作为该区二类校的参照常模群体,选择郊区作为该区三类校的参照常模群体,进行各学科横向与纵向的对比分析,以找到各类学校教育教学中的优势与不足。
(二)各学科考试数据的具体分析方法
1.确定差异基准
基准是在测量工作中用作起始尺度的标准。差异基准是指研究对象与参照常模群体高考成绩的整体差异,用R表示。
如上所述,在进行某区域学科分析之前,首先要确定该区域各群体的组间参照常模群体。确定组间参照常模之后,计算研究对象的总分得分率与参照常模的差异,该差异即可作为研究对象与参照目标的差异基准R。
2.学科教学分析:计算学科差异,诊断优势与不足
有了差异基准R,再逐一计算该区域各学科的得分率与参照常模群体得分率的学科差异D;用学科差异D减去差异基准R,即可得到学科水平L;当L大于0时,说明相对参照常模,该学科为优势学科,当L小于0时,说明相对参照常模,该学科为劣势学科。
为避免一次考试的局限性,无论是在寻找参照常模群体时,还是在分析优势、劣势学科时,应采用同样的方法对比连续1-3年的历史数据。
下面仍以改革前的一组数据为例说明具体分析方法。假设某区某年理科考生各学科得分率如表4所示:
从表4可知,在各学科中,得分率最高的是数学(理)0.74,得分率最低的是语文0.67,如果按照以往不考虑各学科试题难度、直接用各学科平均成绩来衡量各学科的教学情况,无疑是数学成绩最好,语文成绩最低。
事实果然如此吗?假设通过总分分析,已经确定城区作为该区的参照常模群体。利用前面介绍的计算方法得出差异基准R,以及各学科的学科差异D和学科水平L,汇总形成表5: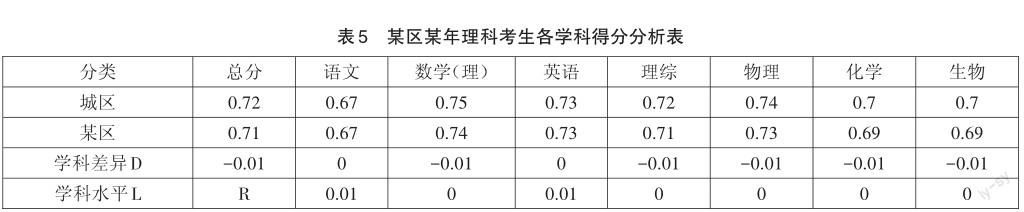
由表5可知,对比该区与参照常模群体城区,他们之间的差异基准R=-0.01。该区理科考生的语文、英语两科得分率与城区持平,其他学科都比城区平均水平低0.01。用学科差异D减去差异基准R,得到各学科水平L,語文、英语学科的学科水平L为0.01,其他学科为0,说明该区语文、英语为优势学科。用同样的方法追溯往年数据,发现该区理科学生的语文、英语的学科水平L一直大于0,两科成绩与参照常模城区的差距一直小于理综、数学与城区的差距。因此判断,该区理科的优势学科是语文与英语,弱势学科是理综与数学。如果想改进提升教学,达到城区平均水平,应在数学与理综各科上多下功夫。
3.学科内部知识、能力、素养教学分析:确定学科差异基准r,计算组块差异d,诊断教学不足
要诊断、改进教学,只分析到学科层面是不够的,还需要深入到学科内部进行考生学科知识掌握情况、学科能力发展情况以及学科素养形成情况的分析。前面的分析方法同样可以适用到学科内部的各组块、各个题目。
当进行学科内部知识、能力、素养分析时,将某区域某学科得分率与参照常模得分率的学科差异D作为学科差异基准r,然后计算该学科各知识、能力、素养组块的得分率与参照常模相应组块得分率的差异d;用学科组块差异d减去学科差异基准r,得到学科各知识(能力、素养)水平l;当l大于0时,说明在该学科中,本区域考生的某知识掌握情况(或能力发展水平、素养形成情况)较好;当l小于0时,说明在该学科中,本区域考生的某知识掌握情况(或能力发展水平、素养形成情况)较弱。
通过对学科内部知识、能力、素养的分析,就可以更加精准地找到学科教学中存在的问题与不足,再结合区域、学校的教育教学实际,进行具体的归因分析,就可以对症下药,找到解决问题、弥补不足的方法,从而提升学科教学水平。
这种选择确定参照常模群体进行相对比较的解读考试数据方法,在一定程度上弥补了因缺少测验等值给考试数据分析带来的局限与误差。
五、适应综合改革需要,强化考试评价研究
随着高考综合改革逐步向纵深推进,教、考、招构成严谨的强耦合系统,任何一个环节的改革都必须放在这个全链条中进行考虑,以增强改革推进的系统性[8]。其中,高考内容改革是各项改革的一个重要枢纽。由于高考的高利害性和保密性,能得到并使用高考原始数据的研究人员极其有限。因此,专业化教育考试机构不仅需要研究构建引导学生德智体美劳全面发展的考试内容体系,而且需要加强考试数据的分析,以服务教学为目的,强化考试评价研究。
基于高考数据进行教学诊断的考试评价研究,会不会更加强化高考分数的作用,强化唯分数、唯升学?笔者认为恰恰相反。原因有三:
(一)考试评价研究有利于克服唯总分、唯升学的简单排队
破除唯分数、唯升学,并非不要分数、不要升学,而是要改变只重视高考总分、只看高考录取率的痼疾。基于高考数据进行学科教学诊断,能够引导学校、教师更加关注教学过程,在一定程度上淡化高考总分、学科总分、录取率的影响,克服唯总分、唯升学的简单排队,减轻唯分数、唯升学对教师的压力。
(二)考试评价研究有利于引导“从育分走向育人”
基于高考数据,通过分层分类、常模参照、相对比较法进行教学诊断,能够让高考数据发挥独有的价值,发现不同区域、不同考生群体的学科优势与不足,引导区县、学校更加重视对学科教学效果的分析,引导教师更加关注学生的学科知识掌握情况、能力发展情况、素养形成情况,引导基础教育“从育分走向育人”。
(三)考试评价研究可以为教育督导、教育管理以及教育教学决策提供科学依据
作为国家教育考试,高考、学业水平考试具有很高的权威性、科学性,各学科考生水平评价及教学质量分析报告的反馈,让教育督导部门、管理部门、教研部门能够及时了解学生学科知识掌握、学科能力发展、学科素养形成情况,为教育督导、教育管理和教学决策提供科学依据。
大规模教育考试形成、积累了海量的考试数据,其中蕴藏着许多非常珍贵的教育教学信息。为了适应改革需要,更好地挖掘利用考试数据反馈、诊断、指导教育教学,建议专家、学者加强以下方面研究:一是运用项目反应理论、认知诊断理论等进一步加强对考试数据挖掘、分析方法的研究,开展对考生个体的评价;二是进行基于无锚题、无锚人条件下的“无锚”等值技术、方法的研究,以实现对考试数据的纵向对比分析;三是将高考、学业水平考试等结果性考试数据与学校过程性考试数据相结合,进行教学的综合分析诊断。
考试评价研究的目的是改进,发现每个区域、每个群体、每个考生的优势与不足,让每个区域、每个群体、每个考生都能取得进步。只有这样,考试才能与教学形成良性互动,助力素质教育发展,助力学生全面而有个性的成长。
参考文献:
[1]中共中央国务院.深化新时代教育评价改革总体方案[EB/ OL].(2020-10-13)[2021-02-10].http://www.moe.gov.cn/jyb_xxgk/moe_ 1777/moe_1778/202010/t20201013_494381.html.
[2]教育部考试中心.中国高考评价体系[M].北京:人民教育出版社,2019:12.
[3]朱文琪.近十年来普通高考考试数据研究的现状与思考——基于中国知网2010-2019年的文献计量分析[J].教育理论与实践,2021,41(7):17-24.
[4]国务院办公厅.关于新时代推进普通高中育人方式改革的指导意见[EB/OL].(2019-06-19)[2021-2-10].http://www.gov.cn/zhengce/ content/2019-06/19/content_5401568.htm.
[5]张敏强,梁正妍.新高考改革背景下的教育考试数据评价[J].中国考试,2020,(1):22-25.
[6]教育部.普通高中课程方案(2017年版)[M].北京:人民教育出版社,2018:3.
[7]北京教育考试院.北京市高考考生水平评价报告[M].北京:开明出版社,2019:12.
[8]孙海波.把握新时代改革方法论,以系统观念全面协调推进高考改革[J].中国考试,2021,(7):1-6.
Research on the Application of Examination Evaluation in Teaching Diagnosis
Ding Xiutao
Beijing Education Examinations Authority,Beijing,100083
Abstract:The new round of college entrance examination reform pays special attention to the guidance of elementary education and teaching.The important way to realize it is to strengthen the research of examination evaluation through the analysis of examination data,excavating the education and teaching information contained in the data,and guiding education and teaching. In practice,the classical measurement theory has obvious advantages in group teaching diagnosis.Based on the norm,this paper analyzes the knowledge,ability,literacy and other multi-dimensional structure of the college entrance examination data.Through the hierarchical classification analysis method,this paper deeply excavates the test data,and uses the test data for regional teaching diagnosis,which can find the subject advantages of different regions and different candidate groups.It can guide teachers to pay more attention to studentsmastery of subject knowledge,ability development and quality formation.This evaluation help to breaking the disadvantages of score only and entering a higher school only,and promoting the formation of benign interaction between examination and teaching.In the future,the research can be strengthened in three aspects. Firstly,the research could further strengthen the research on the test data mining analysis methods and carry out the evaluation of individuals. Secondly,the research could study the technology and method of“anchor-free”equivalence,so as to realize the vertical comparative analysis of test data.Thirdly,the research could combine the result test data of collage entrance examination and academic level test with the school process test data to carry out comprehensive analysis and diagnosis of teaching.
Key words:College Entrance Examination,Examination Data Analysis,Examination Evaluation,Teaching Diagnosis
(責任编辑:吴茳)
猜你喜欢
小学生作文辅导(2017年2期)2017-05-24
职业技术教育(2016年26期)2017-03-14
考试周刊(2016年99期)2016-12-26
湖北工业职业技术学院学报(2016年5期)2016-12-12
中学课程辅导·教师教育(中)(2016年9期)2016-10-20
考试周刊(2016年76期)2016-10-09
历史教学·中学版(2015年5期)2015-06-05
环球时报(2014-10-20)2014-10-20
