
基于WordSmith4.0语料库的英文词汇结构信息抽取方法
2022-06-09 05:45呼媛玲
自动化技术与应用 2022年5期
呼媛玲
(西安职业技术学院,陕西 西安 710017)
1 引言
计算机与互联网飞速发展,各类信息形式呈指数级增长,但庞大的信息数据淹没了真正所需的信息,准确、及时地提取、整理众多无序信息是时代发展的必然趋势,信息抽取(Information Extraction,IE)技术应运而生,该项技术的发展与研究方向因MUC(Message Understanding Conference,消息理解会议)的确立而受到一定程度的推动,其主要是从自然语言文本中获取事实信息,用结构化形式表达信息,为用户提供更好的信息获取工具,便于后续的信息查询、文本深层挖掘操作等[1]。网络信息载体以文本形式为主,信息抽取技术的主要目的是提升互联网知识使用者的体验感。作为自然语言处理中发展较快的研究领域,该项技术融合了语料资源、自然语言处理与语义技术,发展形势逐渐成熟。
在国外,关于信息抽取的研究始于20世纪60年代,仅是从文本中抽取出一些结构化的信息,后来逐渐发展为信息抽取系统,该系统主要是针对故事内容来进行,有学者发展至20 世纪80年代末,信息抽取已成为自然语言处理领域的独立分支。随着信息技术的不断发展,有学者基于知识图谱进行信息抽取,但只能局限于知识图谱范围内的问题,此外,罗明等人[2]为解决因自然语言歧义性、多样性以及结构性等属性造成的信息抽取复杂问题,构建一种金融事件下信息抽取的层次化词汇-语义模式方法,基于界定的某个金融事件表示模型,利用深度学习词向量策略,完成同义概念词典的自动生成,通过有限状态机驱动层次化词汇-语义规则模式,自动抽取各种金融事件信息。杨兵等人[3]针对医学领域的文本数据,构建一种结构化信息抽取方法,根据聚类的文本与提取的关键词,获得常用术语特征,基于术语库辅助完成分词处理,依据词间的语义依存关系,架构依存句法树,实现文本信息所描述关键指标与指标值的识别与抽取。
随着信息抽取技术的不断发展,信息抽取的范围逐渐从封闭的语料库转变为开放的语料库,故本文以Word-Smith4.0 语料库的英文词汇为研究目标,设计一种新的结构信息抽取方法,以提高英文词汇结构的信息抽取适用性。在已有信息抽取方法的基础上,通过标注词性,来提升词性标记准则的统一性;根据解得的词汇结构相似度,来提升信息分类准确度;利用各模式簇,奠定泛化操作基础;设计基于逆向最短编辑距离的泛化流程,加快簇收敛速率,以提升簇内模式的覆盖性能;采用各映射模式阶段,判定信息匹配是否成功。
2 WordSmith4.0 语料库下英文词汇结构信息抽取方法
2.1 英文词汇结构分析
自由词根与粘着词根共同构成词根[4],前者具有独立使用性,后者则要结合其他词素组成词汇。例如粘着词根port的含义是“搬运、带”,fect/fact的含义是“做”,表1中所示的是两粘着词根与其他词素组成的部分词汇。
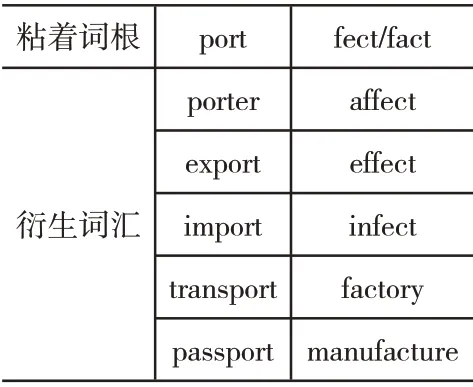
表1 粘着词根构成词汇表
根据表格中的构成词汇可以看出,由port 与fect/fact组成的各个词汇中,“搬运、带”与“做”的意义仍然突出。英文词汇结构的认知参照点即为此中心意义的词根,词汇之间存在的关联性即为相似度。
依据功能将词缀[5]分成派生词缀与曲折词缀,若按照词汇结构位置,词缀又分为前缀与后缀。例如be-为behead前缀,-ish为boyish后缀。表2所示为语义“和……一起、共同”的前缀与“……的人”的后缀。
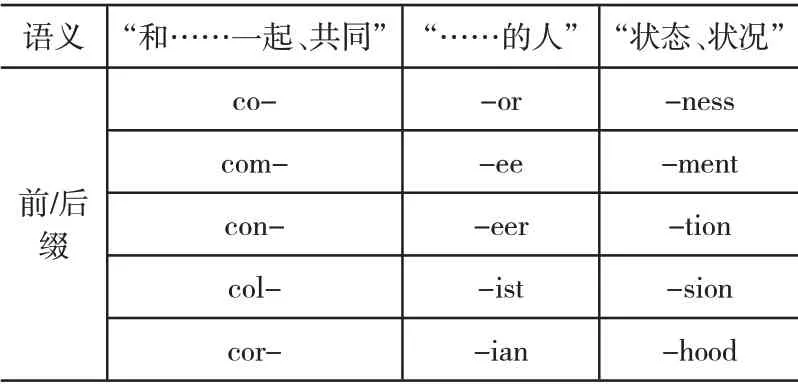
表2 各语义的前缀与后缀表
此类词汇结构形成的原因是,中心成分规约化的变化形式以及以中心成分为基点向外扩散而构成的扩展结构。图1所示即为语义“和……一起、共同”的扩展结构示意图。
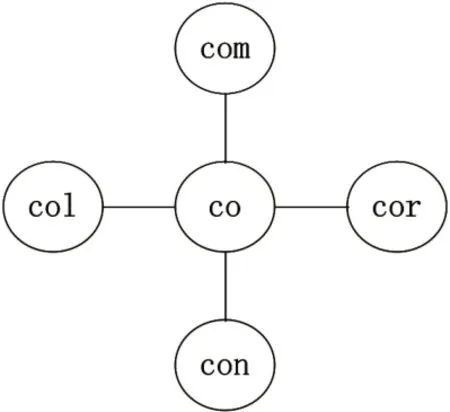
图1 语义“和……一起、共同”扩展结构示意图
另外一些不是词根也不是词缀的字母组合通常也存在一定的含义,比如由st-与fl-构成的单词多数含有“静止”与“动态”的语义,其组成的单词如表3所示。
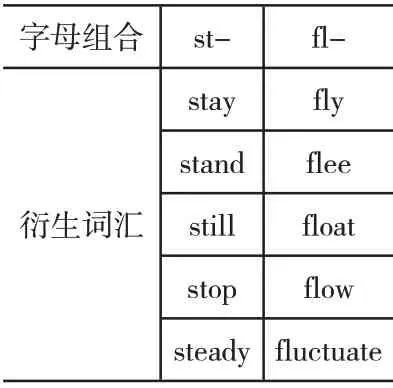
表3 字母组合st-与fl-单词构成统计表
综上所述,多数英文词汇的结构组成部分为词根与词缀。以“引导”的-duct为例,若在该词根上附加前缀、后缀,则可得到下列派生词[6]:
(1)con+duct+ive=conductive(导电的)
(2)con+duct+ible=conductible(可导电的)
(3)con+duct+ion=conduction(导电)
(4)semi+con+duct+or=semiconductor(半导体)
例如“建造”-struct可延伸出下列派生词:
(1)con+struct=construct(构筑、建筑)
(2)de+struct=destruct(破坏)
(3)re+con+struct+ion=reconstruction(重建)
(4)mis+con+struct+ion=misconstruction(曲解、误解)
因此,词汇的结构与含义具有显著的理据性,各词素含义相加后即为整个词汇的意义,可用下列表达式简单描述:

上式中,词汇为W,词素为M,一个含有三个词素的词汇结构中通常是前缀M1、词根M2以及后缀M3。
2.2 WordSmith4.0语料库下英文词汇结构特征获取
抽取英文词汇结构信息之前,应先获取WordSmith4.0语料库中的英文词汇集合,划分词汇结构与标注词汇属性,通过计算词汇结构的相似度,完成阈值设定,根据词汇的语义距离[7],判定相似度,计算公式如下所示:
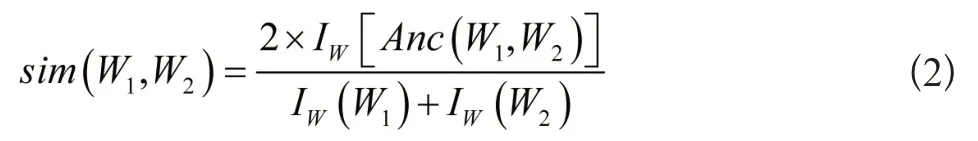
上式中,单词W1与W2的共同祖先节点为sim(W1,W2),单词具有的信息量用IW(W)表示。词汇之间的语义相似度随着两者共同祖先信息的增多而变大,两指标呈正相关关系。
假设用Unigram 表示词汇的一元特征,用CWS+表示一元字符特征与词汇特征,那么将一元特征Unigram 或者字符特征CWS+与词性特征相结合,用POS+表示,将词汇特征与字符特征POS+与词典特征相结合,用Dictionary+表示,综上,用Unigram、POS+、Dictionary+等词汇特征与CWS+、POS+、Dictionary+等字特征完成对等特征的界定。将信息提取的过程简化为如下内容:
(1)一元字符特征:设定组成词汇的字符集合为D={d1,d2,…,dn},其中,字符用di(i=1,2,…,n)表示,假设VUnigram(E)={vu1,vu2,…,vun}指代各字符E的一元特征矢量,字符集合与该特征矢量的维数一致,且vui(i=1,2,…,n)取值使下列条件式成立:

(2)词汇特征:提取的一元特征已经展示出词汇特征,词汇特征主要是对结构信息做整体描述。假设任意四维向量为VCWS(E)={vc1,vc2,vc3,vc4},且该四维向量取值令下列条件式成立:

(3)词性特征:通过标注各词汇词性,以统一词性的标记准则。假设标记词性后的词汇集合为,p表示字符E的词性,Vpos(E)=(vp1,vp2,…,vpm)表示特征向量,则vpi取值使下列条件式成立:

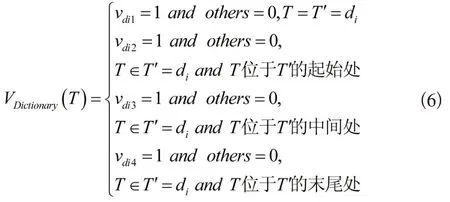
2.3 英文词汇结构信息分类
经过上述操作后,按照词性、结构聚类各集合中的词汇,获取簇内高相似度、类间低相似度的各模式簇,具体流程描述如下:
(1)根据得到的词汇标注集合,构建关键字符的特征集合P=(P1,P2,…,Pn)与聚类阈值Cp,且将Cp设置为0.31-0.81之间;
(2)对关键字符簇集合Clusterkeyword={cluster1,cluster2,clustern}进行初始化,令clusteri={Pi},其中,1≤i≤n;
(3)如果簇clusteri与clusterj的特征集合Pl与Pk满足下列不等式,则将两簇合并:

采用下列计算公式求取簇相似度:
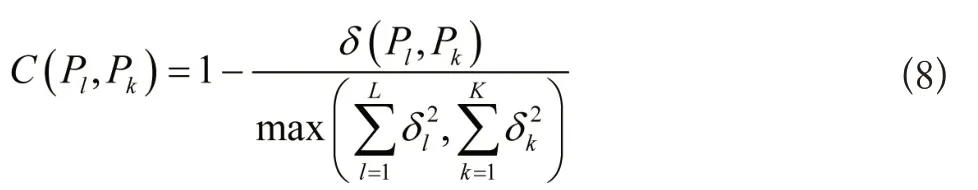
(4)迭代操作上述步骤,待全部簇不再收敛时结束;
(5)迭代操作以上步骤,待全部关键字符聚类完成时终止。
Pl与Pk中的字符个数为L和K,关键字符间的距离为δ,Pl与Pk的最短编辑距离[8]为δ(Pl,Pk)=H(i,j),计算公式如下所示:
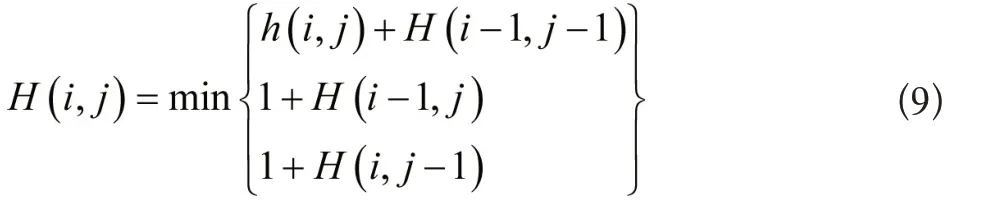
上式中,h(i,j)的取值条件公式如下所示:
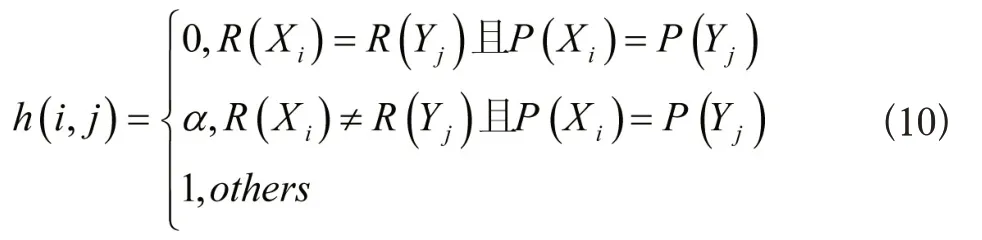
上式中,簇X与Y的中第i个与第j个保留字符分别是Xi与Yj,通配符Xi在簇X里的角色为R(Xi),通配符Xi的词性为P(Xi),子串X1…Xi与Y1…Yi的编辑距离为H(i,j),Xi与Yj的编辑距离为h(i,j),若Xi与Yj存在不同角色、相同词性,其编辑距离为α(0<α<1)。
2.4 泛化处理
为加快簇收敛速率,提升簇内模式的覆盖性能,利用编辑距离矩阵的逆向最短编辑距离,设计如下泛化流程:
(1)令i=m,j=n;
(2)当i=1,j=1时,返回XY;相反,则进入下一步;
(3)假 设i'与j'是min{H(i-1,j-1),H(i-1,j),H(i,j-1)}下标,△Hij=H(i,j)-H(i',j'),进入下一步;
(4)当i'=i-1,j'=j-1 时,进行第七步操作;反之,则进入下一步;
(5)当下标满足i'=i-1、j'=j时,实施第八步操作;反之,则进入下一步;
(6)当下标满足i'=i、j'=j-1时,执行最后一步操作;
(7)当H(i,j)-H(i',j')=0 时,在XY中引入Xi;当H(i,j)-H(i',j')=α时,引入;当H(i,j)-H(i',j')=1 时,引入(Xi|Yj);返回第二步;
(8)当△Hij=0 时,引入Xi;当△Hij=α 时,引入[Xi]*;当△Hij=1时,引入(Xi);返回第二步;
(9)当△Hij=0 时,引入Yj;当△Hij=α 时,引入[Yj]*;当△Hij=1时,引入(Yj)完成泛化处理。
2.5 结构信息抽取
将当前信息项中的词汇WS结构序列用下列表达式描述:
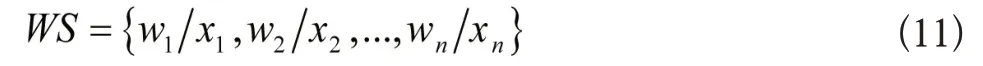
上式中,词汇结构序列的第i个字符为wi,各字符对应属性为xi。
若任意模式Pl的关键字符词性是x,则结构序列WS内与关键字符词性一致的集合表达式如下所示:
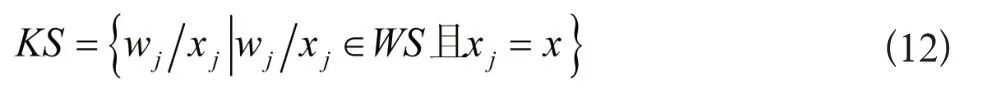
针对集合KS的wj/xj,将其中的序号设定为k,采用下列公式计算词汇WS与模式Pl的相似度cj(WS,Pl):
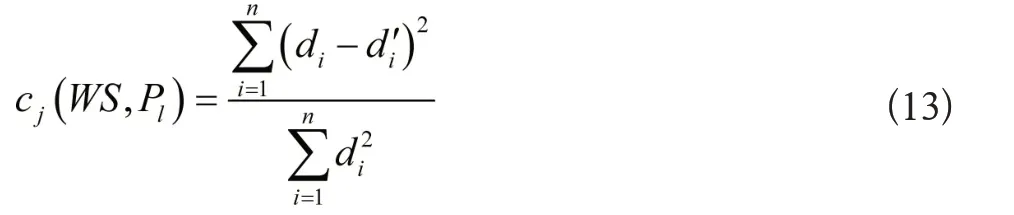
根据信息抽取策略依据,架构信息抽取流程,描述如下:
(1)映射模式边界到词汇结构序列边界,明确模式匹配的有限范围;
(2)映射模式所含关键字符到词汇结构序列里;
(3)映射模式内定长模块至词汇结构序列;
(4)映射模式内变长模块至词汇结构序列;
(5)完成映射说明匹配成功,进入下一步;如果未完成任意步骤映射,或因映射操作导致模块相对顺序发生变化,则说明匹配不成功;
(6)抽取词汇结构序列的关键字符、词缀、词根以及带有含义的字母组合。
3 信息抽取模拟实验
3.1 实验环境与评估指标
表4所示为实验开发环境。
表4 实验开发环境
以WordSmith4.0作为英文语料库,采用准确率、召回率以及F1作为评价指标,来评估抽取方法的效果,三种指标计算公式分别如下所示:

3.2 信息抽取效果对比分析
为验证方法的有效性与可行性,分别采用基于词汇-语义模式的抽取方法、采用结构化信息的抽取方法以及本文方法,展开信息抽取仿真实验,经整理各项实验指标结果,如表5-表7所示。
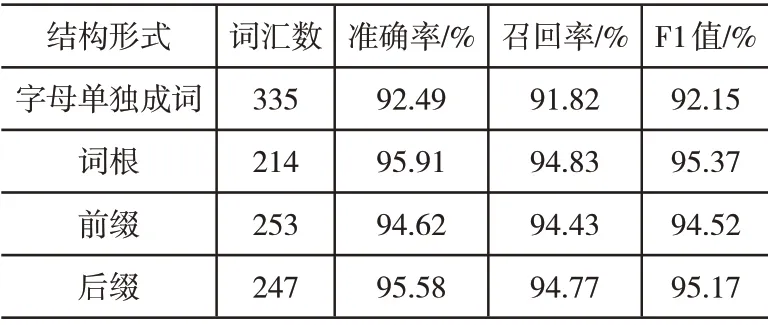
表5 本文方法的实验结果
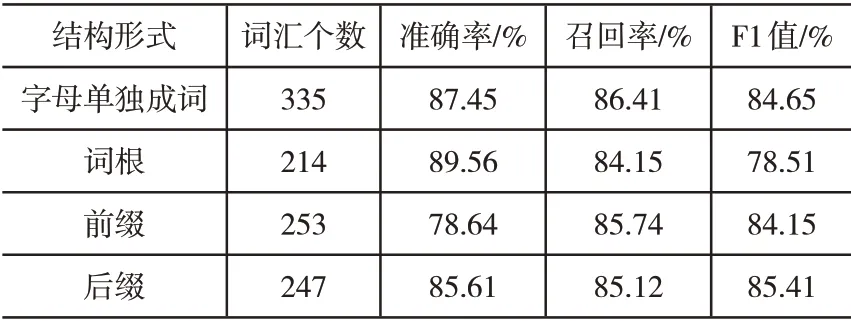
表6 基于词汇-语义模式的抽取方法实验结果
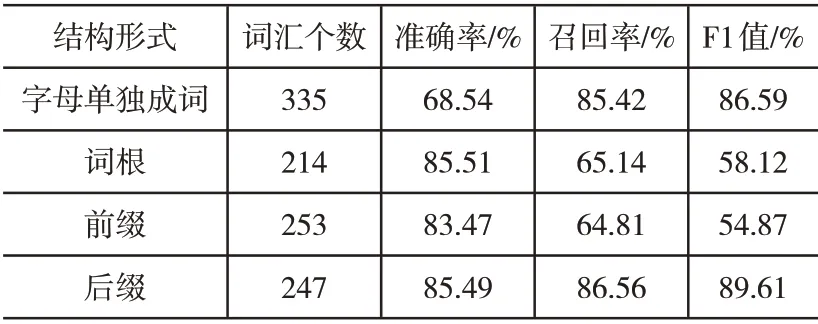
表7 采用结构化信息的抽取方法实验结果
通过上列表格可以看出,相比较基于词汇-语义模式的抽取方法以及采用结构化信息的抽取方法,本文方法的信息抽取效果最优,这是由于本文方法在获取词汇结构集合后,划分了词汇结构与标注词汇属性,计算了词汇结构的相似度,并逐步采取了分类、泛化等策略,因此,具有较高的抽取准确率、召回率以及F1值。
4 结束语
由于信息抽取技术受到一些因素的制约与限制,因此,本文以英文词汇结构为研究对象,提出一种WordSmith4.0语料库下信息抽取方法。因词汇样本容量存在局限性,应继续探索更理想的分类与抽取方法,提升结果准确度;深入研究抽取模式的关键字符分类,实现抽取模式与模式簇收敛。在今后的工作中需进一步分析方法的时间性能,加快抽取速率。
猜你喜欢
现代英语(2022年16期)2022-11-20
英语世界(2022年9期)2022-10-18
文化创新比较研究(2020年13期)2021-01-14
科教导刊·电子版(2021年36期)2021-01-02
汉字汉语研究(2020年2期)2020-08-13
天津外国语大学学报(2020年1期)2020-03-25
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
科技视界(2015年24期)2015-08-15
