
信息技术辅助下医疗对话口译中的注视分析
2021-11-10 07:08张继飞袁小陆
西安邮电大学学报 2021年4期
张继飞,袁小陆
(西安邮电大学 人文与外国语学院,陕西 西安 710121)
医疗口译作为社区口译的分支,通常是在对话的交际过程中发生,亦即译员需要在异语双方面对面的互动交际中双向传译对方的对话[1]。最早出现于20世纪八九十年代西方的公共服务社区[2],此后逐渐得到国外组织机构和学术界的关注。对会话研究[3]和译员身份[4]的已有研究推动着医疗口译的社会性探索,言语和非言语信息正是社会人际交互过程中的重要信息,而医疗口译员准确传递这些信息可以保证医患之间的有效沟通。
国外很早便开始关注医患之间的非言语信息交流,研究主要讨论的是无译员协助下医患交流中一些肢体动作的指代含义[5-7],较少关注注视在交际过程中发挥的作用。注视作为社交互动的组成部分,是一项很重要的非言语提示,人类可以从注视中推断出他人的意图[8]。在国内,因受限于医疗口译市场和语料的收集和研究进度远落后于国外[9],已有的研究主要是对口译成果的分析,包括身份探讨、策略应用等[10-12],对过程研究较少,鲜有注视在医疗对话口译中的研究。
信息技术的发展使得口译过程研究成为可能。针对上述不足,为了更好地促进医患之间的交流,拟利用多模态分析软件ELAN,全面展示如何借助软件分析医疗对话口译过程中的言语和以注视为主的非言语信息,拓展未来值得继续研究的方向。
1 基本问题描述
1.1 技术辅助下的口译研究
数字化技术的革新打破了纯言语单模态研究的束缚,多模态分析软件ELAN近年备受广大研究者青睐。口译方面,我国仍处于起步阶段,相关研究甚少,刘剑和胡开宝讨论了如何用多模态分析软件ELAN建口译语料库[13],杨柳燕尝试将该软件应用在口译笔记研究中[14],刘剑和陈水平借助ELAN研究了同传中语音拖长现象[15],但是至今还没有应用到对话口译。
1.2 口译中的注视
多模态口译涉及多方面的信息,注视便是其中之一。如前所述,注视在口译中的变化是认知变化的表现。认知负荷一旦发生改变,译员就会表现出眼神移动和动作转变等[16]。关于对话口译中的注视研究,Mason认为注视可以表示跟踪话轮、表示理解或不解[17],Vranjes等借用眼动追踪仪研究了校园咨询情景下注视对回应的影响[18],但是仍缺少医疗对话口译情景下的注视研究。
1.3 技术辅助下的医疗对话口译研究
通过传统观察法,Health和Rowbotham等已经说明了各类肢体动作等非言语信息在医患交际中的重要性[5-7]。在现代技术辅助下,Gerwing和Li用ELAN软件进一步探究了肢体动作在医疗对话口译过程中发挥的作用,经分析发现,肢体动作确实可以被视作理解译员译文的窗口[19]。遗憾的是,两位学者也没有借助软件进一步开展注视研究。
综上所述,借助多模态分析软件ELAN开展口译过程研究,以一次基于译员辅助的医疗会诊录像为例,展示在医疗口译过程中,如何利用软件研究非言语信息——注视在医疗口译中的作用。选取的探索问题包括译员加医患三方在沟通过程中呈现的注视转移模式以及三方表现的注视特征。
2 数据处理与方法
2.1 数据来源
研究材料节选自2017年译员为语言不通的外方医生和本地患者提供口译服务的一段视频录像。视频中的参与者包括一位经过医学口笔译专业训练的译员,一位来自德国的获博士学位的外科专家,资深医师,还有一位中国本土患者,完全不懂英文,讲的是方言,因此,其旁边还有一位本地负责他病情的主治医师。考虑录像制约,此医生作为实验条件出现,而非实验对象。医患双方沟通的内容主要是简单的病情咨询和初步诊断,总时长258 s。
2.2 研究方法
2.2.1 研究工具
ELAN是一款多由荷兰Max-Planck开发的多模态建库工具,其可以用来分层标注、转写、切割视频或音频文件里的内容。ELAN在操作上十分便捷,相比其他软件具备以下几个显著的优势:时间刻度精准到了毫秒,提升了时间指标的精确度;层与层之间可以是相互独立、并列和嵌入的关系;具有强大的检索功能,也就是说研究人员可以快速地查找或替换之前标注的内容。此外,ELAN作为一款多模态语料库分析软件,可以被用来标注多维度信息,包括言语文本信息、非言语信息如注视和肢体动作及音频信息如音高等。考虑医疗对话口译中既有言语信息,又有非言语信息的传递,这一优势可以发挥在医疗对话口译的研究当中,借助ELAN这一信息技术,医疗对话口译可以从不同的视角研究。
2.2.2 数据导入
首先,将存储视频另存为.mov格式,借助其他软件将视频另存为.wav格式的音频。其次,将另存的视频与音频一起导入ELAN软件,如图1所示。

图1 标注界面展示
2.2.3 数据处理
视频的标注与分层,关于用ELAN做视频标注,有学者提出用于对话口译分析的多模态资源应该包括文字文本信息、语音特点信息、视觉符号如注视和动作等及语境信息如特定文化等[20]。该研究内容主要在于言语文本与注视分析之间的内在联系,针对研究内容进行了5层标记,分别命名为源语(Source Language,SL),目的语(Target Language,TL),译员注视(Interpreter’s Gaze),外方医生注视(Foreign Doctor’s Gaze),患者注视(Patient’s Gaze)。值得说明的是,考虑真实场景因素,此次医疗对话口译中还有一位中方医生参与,因此,注视标注与分析中也将中方医生纳入了分析。为了方便标注,缩略词“INT”表示译员,“FD”表示外方医生,“PT”表示患者,“DD”表示国内医生。在源语和目的语层,按照实际内容标注,凡是发言人或译员产出的都会被记录,以音频轨道中有连续发音轨迹的内容为一个单位,发言中间出现停顿未发言,则不标记,如外方医生说“Is there something if he...”,接着停顿了几秒,继续说后续内容,这种情况前后内容不能被标注到一起,需留出空白。在参与者的注视层,按照实际眼神交流情况标注,眼神转移一次为一个单位,标注命名则借鉴前人做法[19],包含3层信息:一是注视序列号;二是注视发起者与指向对象;三是听谁或向谁说时发起的注视,对于沟通过程中存在的特殊注视点则会单独备注,如标注信息“Gaze6:INT-PT[Speaking to PT]”指的是第6次注视转移、译员在看患者、译员正在对着患者讲话。
2.2.4 数据导出与筛选
标注完毕后,再检查一遍,确保信息没有标注错误,利用ELAN自带的统计功能,将标好的数据按照分层类别输出另存为.csv格式,借助Excel整理统计。
为进一步研究三方交流过程中特殊注视点所发生的情景,借助Matlab进行了非言语信息与言语信息的关联检查筛选,程序分为以下6个步骤,如图2(a)所示。
步骤1读取通过ELAN所获取的“注释.xlsx”文件中的所有数据,并将其中的数据保存为数字矩阵,文本保存为cell矩阵。
步骤2对获取的数据进行筛选,剔除数据矩阵中的非数字部分,删除cell矩阵中的无关信息。
步骤3根据“注释.xlsx”文件中所标注的特殊注视点,筛选出特殊注视所在的时段,生成医患与译员三方特殊注视时间矩阵。
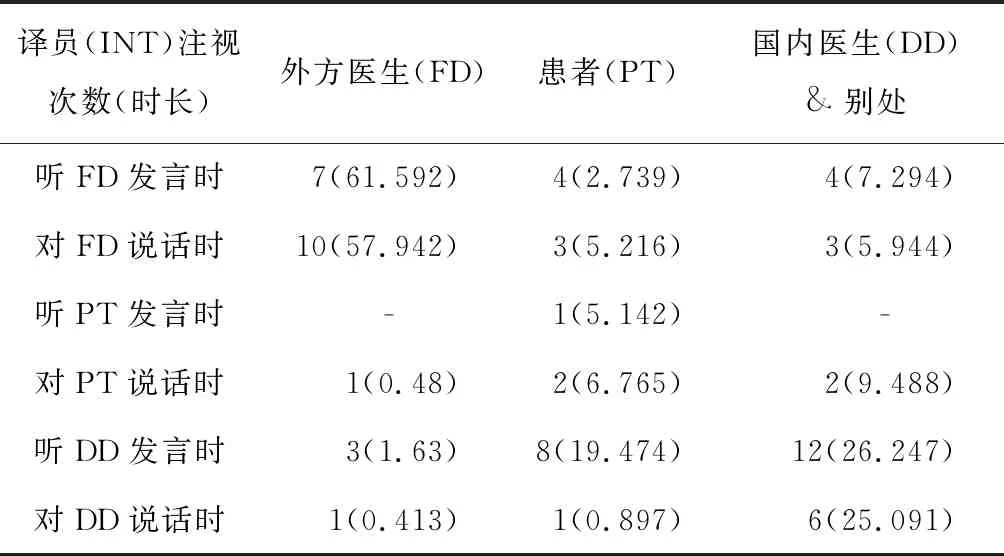
步骤4令文本时间为t,特殊注释时间为t′,设置选择参数a,通过a对特殊注释与文本进行匹配,具体匹配机制为|t-t′| 步骤5通过历遍步骤4中所生成的数字矩阵生成一个仅包含“0”与“1”的cell矩阵,并在历遍完成后与步骤1中所获取的文本cell矩阵合并。 步骤6将所获得的cell矩阵按照“外方医生/译员/患者特殊注视-源语/目的语”分别保存在“结果.xlsx”文件中。 图2 操作流程示意图 需要特殊说明的是,选择参数a对于特殊注视点与文本的匹配至关重要。选取过小的a会导致部分时延较长的特殊注视点没有文本与之匹配,过大的a则会导致出现文本数量多于特殊注视点数量。为了确保程序的准确性,通过编写Matlab程序对a的大小进行选择,具体步骤如图2(b)所示。 步骤1从选择程序中获取生成患者特殊注视时间矩阵与译员特殊注视时间矩阵。 步骤2设置循环体,a的大小为0.1~3,步长为0.01。在循环体内对特殊注视时间与文本进行匹配,具体匹配机制为|t-t′| 步骤3对匹配结果进行分析,选取出特殊注视点没有遗漏,且文本数量最接近特殊注视点时的a。 根据标注的注视信息,统计得出译员加医患三方沟通过程中表现的注视转移情况,具体数据如表1所示。 表1 注视转移次数与时长统计 由表1可以看出,在这次有译员协助的医患沟通中,译员、外方医生和患者三方之间表现的注视转移即眼神交流促成了三方的交流,不过译员转移次数(64)明显多于医生(38)和患者(22)。此外,标注还发现,三方均有沟通时将注意力转移到其他方向的情况,特别是外方医生与译员。 通过进一步分析发现,三方追视国内医生是因为交流过程中,国内医生偶尔参与了对话,而译员和外方医生将视线转移到别处,观察发现,是他们在作为指定听者或发言者[21]时大脑处理信息的一种表现。从数据看,译员将注意力转移到别处的次数和时间分别为16次和39.849 s,明显多于医患双方的次数和时间,这点或许说明了译员在工作时付出了更多的认知负荷。 从注视时长维度看,译员与外方医生的交流时间最久,译员在外方医生身上注视的时间为122.056 s,要远大于其他人员。ELAN转写统计得译员输出共273个词。其中,对外方译员说的有120个词,约占44%;外方医生注视译员最久,其次注视点在中方医生身上,注视发生是在中方医生解释病情的时候,尽管中外方医生语言不通,但适当的肢体动作有助于外方医生理解,因此,外方医生会看中方医生。考虑患者和译员都是同一母语,患者则将更多的注视放在了译员身上,更容易建立关系,使其融入医患对话中,有助于传递信息。 除了正常交流过程中交流双方的眼神交流,还存在其他形式的特殊注视形式。借助ELAN标注软件和Matlab获得并筛选信息,具体分析结果如下。 3.2.1 译员特殊注视点 Elan软件标记后,译员在不同对象身上的注视次数与时长统计如表2所示。 表2 译员在不同对象身上的注视次数与时长统计 由表2可以看出,较为显著的数据是译员在与外方医生或中方医生交互时,无论是作为指定听者还是发言者,他的注视点除了停留在了医生身上之外,还有数次是在患者身上。其中,与外方医生沟通时,向患者累计注视7次;与中方医生沟通时,向患者注视累计9次。这也成了译员视角下的代表性注视特征,通过Matlab对这些特殊注视点信息与对应的言语筛选后,得出译员视角下具有代表性的注视转移变化,如图3所示。 图3 译员视角下的注视转移变化 图3中译员在与外方医生沟通时(注视17),时不时关注患者(注视18),然后又将视线转向医生(注视19)。研究发现,译员无论是作为指定听者或发言者,注视转移到患者身上都是在医生提及到患者的时候发生,译员这种注视行为实际上是在将患者纳入沟通框架中,实现了以患者为中心[22]的目标。译员注视转移到别处,据译员回溯,是大脑在加工听到的信息和解读记下的内容时的一种表现。这类注视累计17次,平均每次注视时长不超过2.3 s,这个数据能否证明译员多任务处理能力仍有待进一步验证。 3.2.2 外方医生特殊注视点 Elan软件标记后,外方医生注视次数与时长统计如表3所示。 表3 外方医生注视次数与时长统计 从表3可以看出,外方医生向译员(15次,139 s)、中方医生和别处(16次,92.777 s)注视转移的次数和时长明显要高于向患者注视(10次,18.377 s)。患者在这次交流中发言的次数非常少,发言字数总计为22字,不包含两次模糊不清的表达,因此,导致外方医生缺少对患者的关注。不过,外方医生在解释患者病情时,其注视表现出了不一样的特征,通过Matlab对这些特殊注视点信息与对应的言语筛选后,得出外方医生视角下具有代表性的注视转移变化如图4所示。 图4 外方医生视角下的注视转移变化 由图4可知,外方医生在经过简单问诊后,向译员解释患者可能存在的病灶(注视34),解释过程中还伴有一些肢体动作,外方医生在这时将注视同时转移到了中方医生,期待对方明白(注视35),解释结束后译员开始翻译,外方医生先看了译员,之后又看向中方医生(注视38),尝试通过观察对方反应确认是否明白。外方医生的这种注视特征实际上属于言语和视觉信息的分离确认[23]。 3.2.3 患者特殊注视点 Elan软件标记后,患者注视次数与时长统计如表4所示。 表4直观地展示了患者的注视情况,患者在译员和医生甚至其他地方的注视分布存在显著差异。患者在译员身上停留的次数远超于其他人,总共25次注视转移,仅占在译员身上的注视次数的56%。根据观察,可能是患者在沟通中处于劣势地位,无法与外方医生沟通,因此,更加依赖和其是同一母语的译员。通过Matlab对这些特殊注视点信息与对应的言语筛选后,可看出患者对译员的依赖性,代表性案例如图5所示。 表4 患者注视次数与时长统计 图5 患者视角下的注视转移变化 图5显示的是患者的第5次注视,一直停在译员身上,刚开始是中方医生代替其主诉,陈述时患者看着译员寻找补充机会,期间译员在记录信息,并给予了患者注视反馈(注视5)。于是,患者进行了病情补充(注视6),随后译员开始向外方医生翻译,此时患者的注视仍在译员方向(注视7)。这个案例充分地证明了当患者处于沟通不利的地位时,更加倾向将注视点停在同一母语者身上,期待被关注给予表达机会,因此,医疗口译中对译员、对患者的关注都是十分重要的。 医疗对话口译是一项集医患会话和交替传译于一体的跨学科研究课题。在信息技术的辅助下,利用多模态分析软件ELAN获得数据,然后通过Matlab筛选所需数据,全面展示了如何开展医疗口译过程中的注视研究,多项数据均显示有不同的发现。整体而言,个案注视分析验证了Brne和Oben在Eye-trackinginInteraction一书中所说的,注视在面对面交流中发挥着重要的作用[24]。具体而言,案例中三方的注视变化特征带来的启示包括以下几个方面:第一,译员视角下注视患者和其他地方的特征表明以患者为中心的理念在医患交际中是必不可少的,同时译员在注视方面表现的认知特征值得关注;第二,医生视角下形成的相互确认和分离确认等特征表明非言语信息在人际交互过程中的重要性;第三,患者视角下对同一母语者的依赖性、等待被加入交流框架的特征表明给予患者表达机会在医疗口译交际中非常关键。 当然不可否认的是,此个案研究存在样本量少,口译场景中干扰因素多等不足,希望借助信息技术对医疗对话口译中的注视模式与特征进行分析,进而引起学界对医疗口译中非言语信息的关注和研究。伴随着信息技术的广泛应用,对话口译过程研究的方向包括以下几个方面:首先,大量医疗对话口译语料库在各种编程软件辅助下,其言语与非言语信息之间的关联度特征会被深度挖掘;其次,注视研究只提供了表象数据,前沿技术应用眼动结合脑成像等方法或能揭秘更多医疗对话多方大脑内部的秘密;再次,虚拟仿真人际交互设计[25]与非言语信息理论研究相结合将实现信息传递效度的最大提升;最后,交互注视与视觉场景模型[26]的交叉研究或将推动视觉辅助下的人工智能翻译机器人的研发。
3 应用结果与分析
3.1 注视转移分析

3.2 特殊注视点分析





4 讨论与结语
猜你喜欢
小学教学研究·教研版(2022年3期)2022-04-08外语学刊(2021年3期)2021-11-30大众文艺(2020年5期)2021-01-28英语学习(2018年10期)2018-10-25卷宗(2017年26期)2017-10-17作文世界(小学版)(2017年5期)2017-06-08英语学习(2017年3期)2017-04-10英语学习(2016年12期)2017-02-28英语学习(2016年2期)2016-09-10中国诗歌(2013年3期)2013-08-15
