
基于改进PSO-SVM 的智能化医疗数据处理技术研究
2024-02-27 12:16黄祎王金珠孙梦琪包蕾
电子设计工程 2024年3期
黄祎,王金珠,孙梦琪,包蕾
(河北北方学院附属第一医院,河北张家口 075000)
采用原始统计或报表的方式对财务数据进行分析,既费时又费力。现有的一些智能算法如BP、传统SVM 等,虽然能够满足一些小数据、轻量化的需求,但在处理海量数据时效率低下、准确率不足,难以获得数据深层的潜在信息,造成资源的浪费[1-3]。
为此,文中在粒子群算法(PSO)、支持向量机算法(SVM)以及模拟退火算法(SA)的基础上提出了一种基于改进PSO-SVM 的智能医疗数据处理算法。通过SA-PSO 获取SVM 模型训练所需的惩罚系数与高斯核系数的最优值,并利用训练好的SVM 模型得到最终的数据处理结果。通过算法对比实验证明了所提算法的可行性以及相较于其他同类算法的优势,而性能实验则体现了算法的可靠性。该算法为后续进一步进行智能化财务数据处理提供了重要基础。
1 理论分析
1.1 PSO算法
该文所采用的粒子群算法(Particle Swarm Optimization,PSO)是通过研究生物群体捕食行为特征,而提出的一种数学计算理论[4-5]。粒子是PSO 算法中的重要概念,具体是指所研究问题中存在的潜在优化解,可以将其抽象成待解多维空间中具有自身位置、移动速度以及移动经验(适应度)的对象点。每个对象点均有自身的初始位置,在多维空间中以可变的速度移动时,会根据其他对象点的实时位置及获得的移动经验不断进行调整,同时在移动过程中记录其所经过的最优位置。通过上述描述可知,PSO 各粒子均包含位置、速度以及适应度三个特征。其中适应度值在某种意义上决定了PSO 算法的优劣,该数值通常由相应函数计算所得。在对实际问题的处理中,通过这些粒子的不断进化与迭代来实现最终结果的获取。PSO 算法流程,如图1 所示。
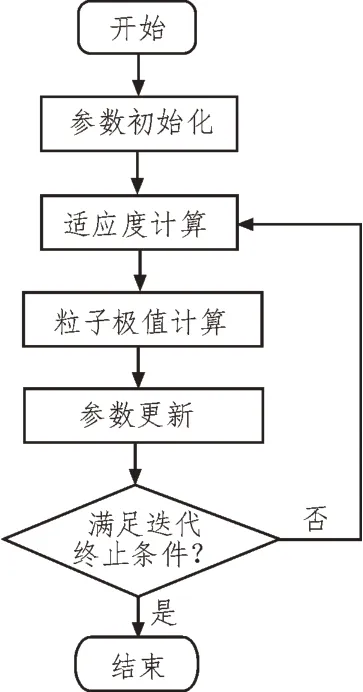
图1 PSO算法流程
PSO 算法流程可以分为以下五步:
1)参数初始化:该过程主要设定算法中粒子群的数量以及各粒子的初始位置和初始速度。
2)适应度计算:该过程主要是根据实际问题确定相应的适应度计算函数,并利用该函数计算粒子当前位置所对应的适应度。
3)粒子极值计算:该步骤所实现的功能为通过前一步得到的适应度对粒子群的个体极值和群体极值进行计算。
4)参数更新:通过对比各粒子适应度与所记录最优位置的适应度,对粒子位置和速度进行更新。
5)迭代寻优:判断所得结果是否满足精度或迭代次数是否达到最大值,若满足迭代结束得到最优解;反之则返回步骤2)。
1.2 SVM算法
支持向量机(Support Vector Machine,SVM)是基于统计学理论提出的一种人工智能机器学习算法[6-9]。SVM 算法建立在VC 维理论及结构风险最小化原则的基础之上,目的在于解决传统BP 等神经网络的问题,更好地将神经网络应用于样本空间的非线性分类及回归处理中。
SVM 算法的设计原理:将实际问题通过设定的核函数映射到待求解的高维特征空间,通过求解空间特征向量的权重系数,获取空间样本数据存在的最大化间隔,同时利用该最大化间隔实现样本分类。SVM 从根本上分析可以看作是对凸二次规划问题求解的数学模型,这也保证了SVM 所获得的解为全局最优解,防止结果为局部最小值的错解。SVM的经典算法模型如图2 所示,一般由输入层、支持向量层以及输出层三部分组成,图中的圆形和方形框分别表示组成对应层次的各个单元。其中,输入层负责接收样本数据,支持向量层是模型核心层,负责进行样本数据处理,该层中包含了由多个支持向量所组成的中心节点,而输出层则为SVM 模型处理的表示,是支持向量层各中心节点的线性组合。
SVM 模型可以分为线性可分SVM 与非线性SVM 两类[10-11]。其中,在线性可分SVM 中最大间隔所涉及的超平面具有唯一性,能够准确地将样本划分为两类。而在非线性SVM 中,需要引入松弛变量,接受部分样本分类所存在的误差,实现结构风险模型与性能之间的均衡。
在SVM 算法中,核函数的选择至关重要,其能够将非线性问题转换为线性问题进行处理。在实际需求中,通常需要根据具体情况选择最优的核函数进行处理。常见的核函数包括:线性核函数(LKF)、多项式核函数(PKF)、高斯径向基核函数(RBF)以及多层感知机核函数(MPF)等。文中通过对比分析,选用其中适用性更强、性能更优的高斯径向基核函数进行后续处理。
2 数据处理
文中旨在提出一种财务数据的分析与处理算法,能够服务于医疗机构的财务系统,为管理人员的分析与决策提供参考,因此提出了基于改进PSOSVM 的智能化医疗数据处理方法。下文将从算法架构设计入手,详细介绍与分析了该算法的设计思路及处理流程。
2.1 技术架构
文中所设计的基于改进PSO-SVM 的智能化医疗数据处理算法架构,如图3 所示。
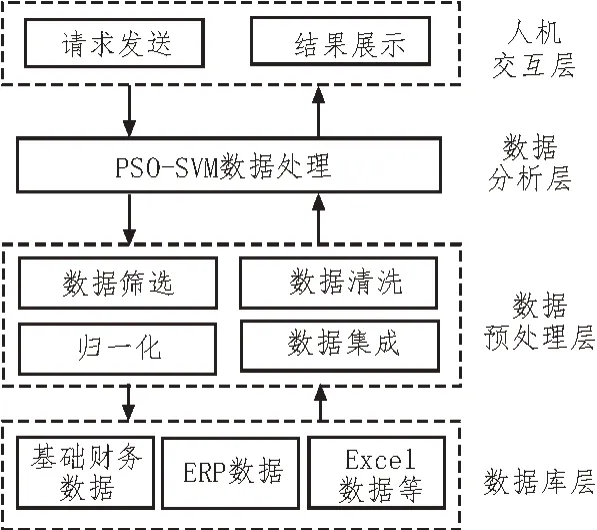
图3 医疗数据处理算法架构
该架构主要由数据库层、数据预处理层、数据分析层以及人机交互层所组成。其中,数据库层负责永久化存储医疗机构产生的各类财务数据,包括基础财务数据、ERP 数据以及人力资源系统Excel 所记录的相关数据等。经大量收集到机构所产生的财务数据后,才能够利用该算法对这些数据进行准确地分析,进而为后续的决策提供更有力的支持。数据预处理层负责对数据库的数据进行筛选、清洗、归一化等操作。其中,数据筛选主要是挑选原始财务数据感兴趣的样本以及剔除相关性强的数据指标;数据清洗则是去除原始数据中的噪声、异常记录以及冗余数据,加强数据的完整性;数据归一化则是消除同类数据不同记录方式之间所存在的差异。而数据分析层则是利用提出的PSO-SVM 算法对预处理后的数据进行进一步处理,得到蕴含在样本中的深层次信息。人机交互层也可称为展示层,主要功能分为两部分,一是为用户提供操作界面,用户可通过该页面进行数据库查询以及数据分析等操作;二是进行请求结果的展示,将用户所需内容以可视化方式进行呈现。下面将对其中的关键算法PSO-SVM 算法进行讨论。
2.2 PSO-SVM算法
支持向量机SVM 算法的优势在于理论基础完善、所需样本数量少、可解决高维问题,但也不能忽略其不足之处,主要体现在训练参数选择困难、拟合精度难以保证等。SVM 算法中惩罚系数与高斯核函数是对算法性能影响较大的两个参数。通常,惩罚系数是模型分类精度与平滑性的权衡,提高惩罚系数能够相应提升模型的最终精度,但泛化效果会随之降低,反之降低惩罚系数泛化效果则会相应提高。高斯核函数则会对模型中的支持向量产生较大影响,高斯核函数越大,支持向量之间的相关程度就越高,模型训练效果就越差。基于此,要合理设置SVM 的这两个参数。
PSO 算法经过多年的发展与完善,已经在参数优化领域取得了良好的实践效果。为此文中提出采用粒子群PSO 算法对SVM 参数进行优化的PSOSVM 方法,来最大化提高SVM 算法模型的性能。所提出的利用PSO 进行SVM 算法优化的架构,如图4所示。
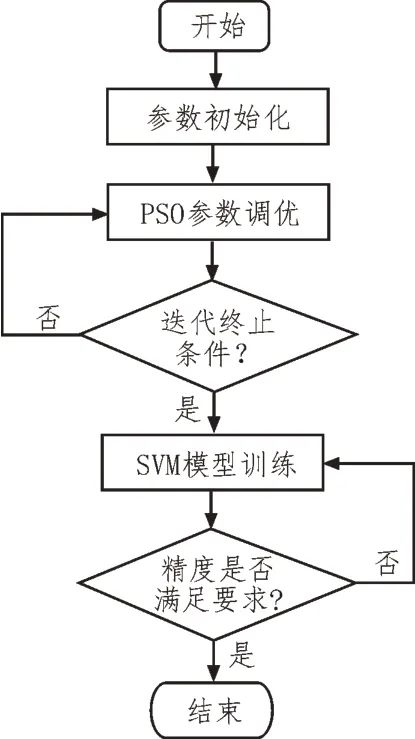
图4 PSO-SVM算法架构
所设计PSO-SVM 算法涉及的主要步骤包括:
1)参数初始化:将SVM 算法涉及到的惩罚系数、高斯核函数作为PSO 中的粒子,对粒子群规模、各粒子的初始位置和初始速度进行设定。
2)PSO 参数调优:通过PSO 过程中所记录最优位置的适应度,对粒子位置和速度进行持续更新。
3)迭代条件判断:判断是否达到所设定的终止条件,若达到则停止PSO 参数优化,进行SVM 模型训练;否则,继续进行PSO 的参数寻优。
4)SVM 模型训练:利用PSO 算法得到的优化参数对SVM 模型进行训练,能够在保证模型训练效率的同时,尽可能地避免人为因素的影响,提高最终模型的准确率及泛化效果。
2.3 改进PSO-SVM算法
上文提出的PSO-SVM 算法已经能在较大程度上提高数据处理结果的准确性,但仍有改进的空间。改进点在于PSO 算法容易产生过早收敛,使得参数陷入局部最优的问题,为此文中又在上述PSO-SVM 算法的基础上引入模拟退火(Simulated Annealing,SA)算法,来对其中的PSO 算法进行优化。
SA 算法的优势在于将概率的思想应用于最优解的获取,不依赖涉及参数的初始值,且全局搜索效率高[12-19]。这些特点使得在与PSO 算法结合的过程中提高PSO 的灵活性、粒子的多样性以及最优参数的搜索范围,进而有效减低传统PSO 算法不足所带来的影响。SA 算法对PSO 优化的具体流程,如图5所示。
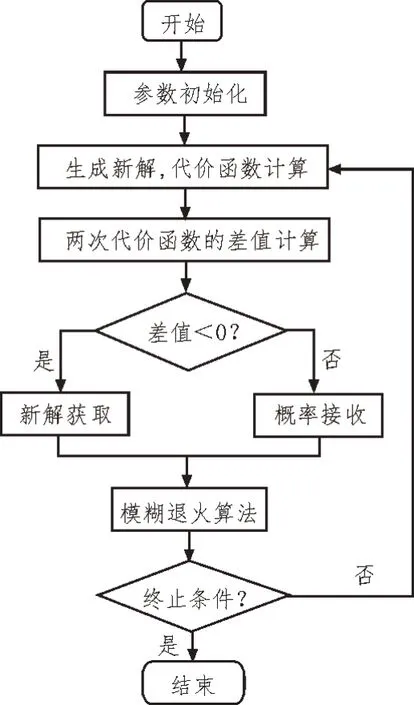
图5 SA优化PSO流程
SA 算法对PSO 的优化使得粒子在过早收敛时,能够及时摆脱局部最优的影响。SA 在获取解的同时,除了得到符合设定条件的解之外,也会概率性得到不完全符合设定条件的解。
3 实验与分析
为了验证文中所提算法的可行性与可靠性,体现相较于其他同类算法的优势,设置了相关实验,并对实验结果进行分析与探讨。
3.1 实验准备
该部分主要对算法中涉及到的一些参数进行设置,具体如表1 所示。

表1 算法参数设置
3.2 算法对比实验
该实验主要测试该算法在实际进行医疗财务数据处理中的表现以及相较于其他同类别算法的优势。为此特别设置了BP 神经网络算法、传统SVM 算法、PSO-SVM 算法作为对照组,测试指标包括数据处理的准确率(ACC)、错误处理次数(EHT)以及消耗时间(TIME)。在其他实验环境参数一致的条件下,各算法进行医疗财务数据处理的结果,如表2 所示。
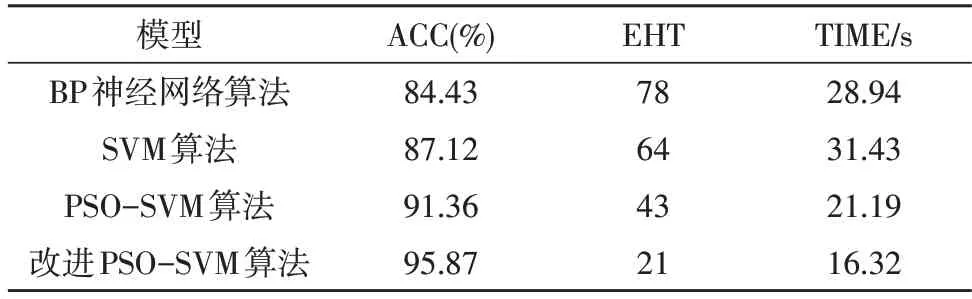
表2 各算法实验对比结果
为了更直观表现实验结果,绘制了图6 所示的各算法模型的ACC 和EHT 两个指标对比图。
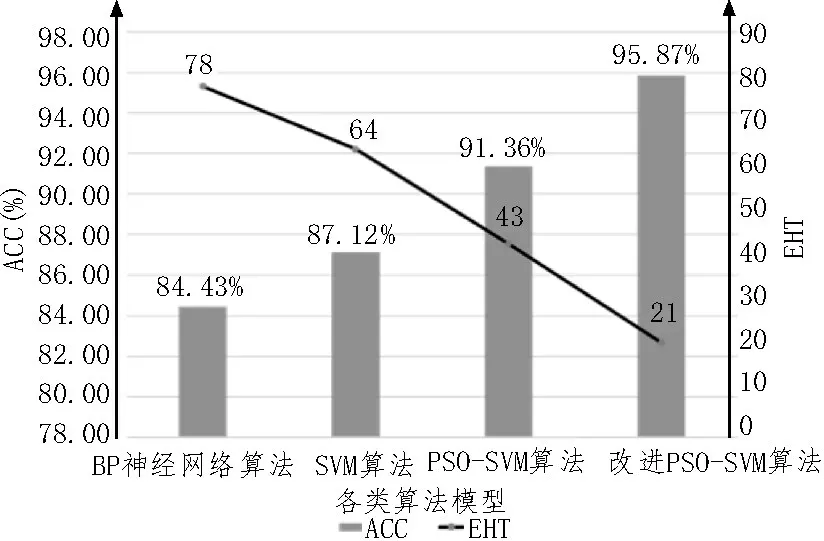
图6 各算法ACC和EHT指标对比图
由上述各模型实验对比结果可以看出,四种数据处理模型无论是准确率还是消耗时间,所提出的PSO-SVM 模型以及其对应的改进PSO-SVM 算法均优于其他两种算法。尤其是改进的PSO-SVM 算法,其准确率能够达到95.87%。该项实验充分验证了该算法的可行性,体现了文中算法相较其他同类算法的优势。
3.3 算法性能实验
该项实验主要对算法的性能进行测试,主要测试该算法在大样本数据量下是否能够保持优秀的性能,进一步验证算法的可靠性。为此设置了几种样本数不同的实验,实验结果如表3 所示。
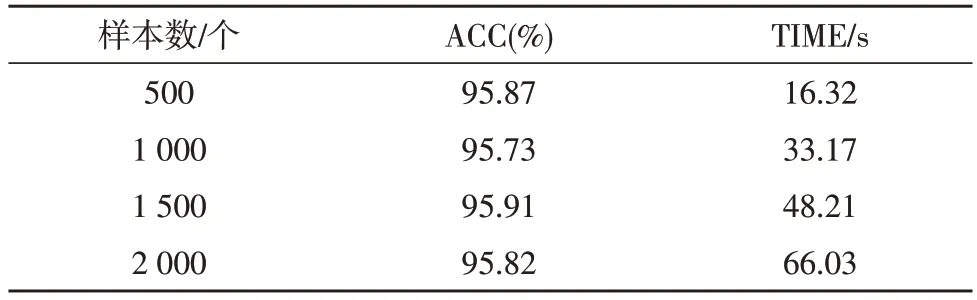
表3 算法性能实验结果
由上述性能实验结果可以看出,该算法在高数据量的条件下也能够在保证效率的同时对数据进行有效处理,体现了算法的可靠性。
4 结束语
文中在介绍与分析粒子群PSO 算法和支持向量机SVM 算法的基础上,基于改进PSO-SVM 技术提出了智能化医疗数据处理算法。该算法由数据库层、数据预处理层、数据分析层以及人机交互层四大模块所组成,能够充分发挥PSO 参数调优以及SVM 数据处理的优势。实验结果证明了所提算法的可行性与可靠性,同时也体现了该算法相较于其他同类算法的优势,表明其具有良好的实际应用价值。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
新高考·高一数学(2022年3期)2022-04-28
心理学报(2022年4期)2022-04-12
水泵技术(2021年3期)2021-08-14
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
高中生学习·高三版(2016年9期)2016-05-14
中国塑料(2016年11期)2016-04-16
新高考·高二数学(2015年11期)2015-12-23
中国惯性技术学报(2015年1期)2015-12-19
教育与职业(2014年16期)2014-01-19
