
融合多维注意力机制与动态尺度的数据校核算法
2024-02-27 12:16张小凡李涛
电子设计工程 2024年3期
张小凡,李涛
(河北北方学院附属第一医院,河北张家口 075000)
随着我国医疗卫生信息化的快速发展,大数据、人工智能等新兴技术被广泛应用于医疗领域,这使得对相关活动中设备、药品、耗材等物资以及人员的消耗进行实时监管成为可能。然而从海量医疗数据中挖掘出异常信息并进行校核的工作,在现阶段仍具有较大的挑战性[1-4]。
目前,国内外学者对医疗数据的挖掘也进行了诸多研究。文献[5]为了能够解决传统单病种医疗费用分析方法处理数据时效率偏低的问题,使用模糊聚类(Fuzzy Clustering,FC)和BP 神经网络对医疗费用数据进行统计分析,并获得了较高的准确度。文献[6]为了对医疗质量进行管控,建立了基于Hadoop的医疗数据监控系统。文献[7]详细介绍了基于物联网的医疗数据挖掘模型,并对传统算法加以改进。而文献[8]则使用命名实体识别模型来对医疗大数据进行症状名识别以及严重程度的估计。为了能够更有针对性且准确地对医疗设备、耗材及药品的采购进行监控与数据核对,文中提出了基于多维注意力机制(Multi-dimensional Attention)的动态尺度数据校验算法模型,从而帮助医疗机构和主管部门进行决策分析。
1 技术原理分析
传统机器学习(Machine Learning,ML)在对海量数据进行处理时,通常使用支持向量机(Support Vector Machine,SVM)、逻辑回归(Logistic Regression,LR)、决策树(Decision Tree,DT)等模型[9-11]。这些模型对于医疗活动所产生的数据已经具备了一定的分析校核能力,但准确度偏低且仍有大量异常数据被遗漏。2017 年谷歌团队提出了基于自注意力机制(Self-Attention)的模型Transformer[12],并受到了广泛的关注和认可。其在自然语言的处理上显示出了强大的表征与信息融合的能力,因此该文以该模型作为算法的主要架构。
Transformer 模型[13-14]通常由编码器和解码器两部分组成,前者负责对输入数据执行编码转换,后者则将内部表示进行重新转换并输出数据。编码器与解码器的总体结构基本相似,主要由位置编码、多头注意力机制、归一化、残差连接(Skip-Connect)及前馈神经网络(Feedforward Neural Network,FNN)组成,区别仅在于是否带掩膜。值得注意的是,在Transformer 中也采用了类似残差神经网络ResNet 的残差块结构。通过向网络添加一个直接连接通道,并保留前一个网络层的输出百分比,从而解决了传统卷积网络(Convolutional Neural Networks,CNN)或全连接网络(Fully Connected Netural Network,FCN)在传输时因梯度消失或爆炸而造成深度较深的网络无法训练的问题。同时,还在解码部分之后加入了线性映射和Softmax 函数实现对异常数据的发现。Transformer 的模型架构,如图1 所示。
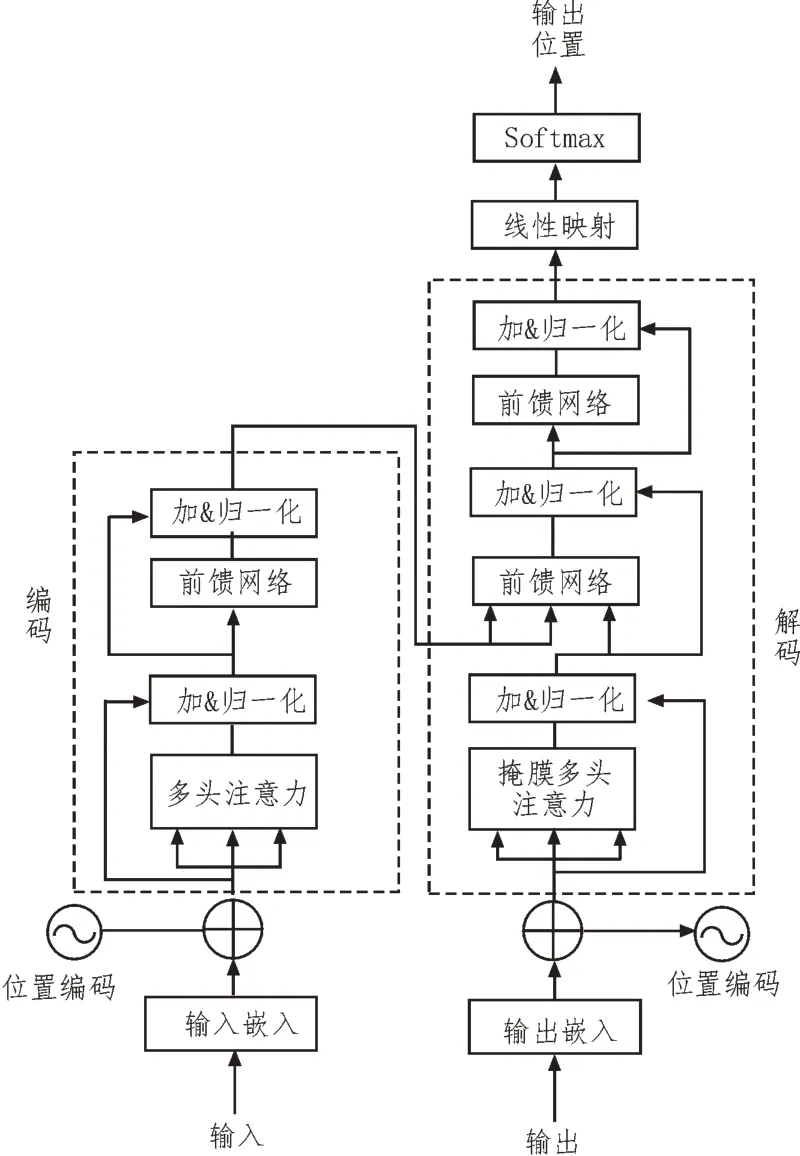
图1 Transformer模型架构
2 动态尺度数据校验
2.1 总体框架设计
该文所设计算法模型以Transformer 为主干网络,提出了基于多维注意力机制的动态尺度数据校核算法。利用该机制可以有针对性地对医疗设备、药品与耗材的各类相关信息进行特征提取,从而完成数据校核。算法的总体模型架构如图2 所示。
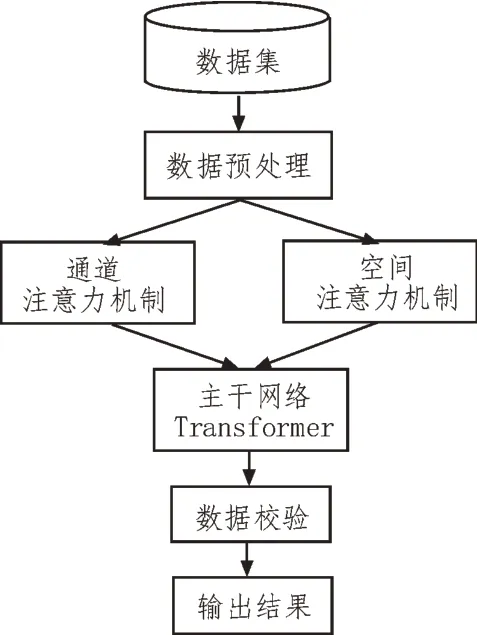
图2 算法模型总体架构
首先,对获得的数据进行预处理;然后,采用通道和空间注意力机制对数据的时空信息进行加权融合,并将融合后的信息输入至主干网络Transformer模型中加以训练,最终将完成训练后的信息输入到线性变换层及Softmax 层内,以实现数据的校核。该文所提算法模型的创新点为:1)将通道与空间注意力机制相融合,利用多维注意力机制对数据特征进行准确提取,同时还考虑了数据随时间变化的因素;2)将Transformer 网络应用于数据校验模型中,提高了校验的准确率;3)采用动态尺度,可以实现对全局特征的动态考虑,且进一步提升算法准确度。
2.2 Transformer主干网络
在Transformer 网络中,最关键的部分就是自注意力机制。对于输入的任意数据向量xi(i=1,2,…,n),将其编码嵌入映射至中间向量ai(i=1,2,…,n)上,并乘以一组矩阵Wq、Wk、Wv,得到向量qi、ki、vi,再对其进行点积,则有:
在实际数据处理过程中为了防止点积的结果过大,通常还需进行压缩,即:
然而仅利用这一组矩阵得到的注意力相对较为单一,无法满足对复杂医疗数据核对的要求。所以,文中设置了多组矩阵来实现对不同数据向量间关联性的表达。此时,多头注意力机制(Multi-Head Attention)就发挥了较大作用。该机制在参数总量保持不变的情况下,将Q,K,V映射至高维空间的不同子空间中进行计算,最后再将获得的信息进行合并,由此既可以防止过拟合,也能将不同数据序列间的关系进行综合。其计算方式如下:
式中,Z为多头注意力的输出矩阵,该矩阵包含了所有医疗数据向量相互之间的关联信息,便于之后流程的使用。同时,为了能够保持与输入矩阵相同的维度,还需要乘以矩阵Wz。
此外,为了预防梯度消失的问题,在每个Transformer 网络的基本模块中均加入了残差连接。目的是增加更多的网络层数,进而获得更深层次的特征信息。
2.3 多维注意力机制
注意力机制(Attention Mechanism)源于对人脑视觉的研究,人们在处理信息时会选择性地关注部分内容而忽略若干次要信息[15-16]。其核心思想是将注意力集中在重要的信息上,从而提高处理信息的灵敏度和准确度。为了能够更好地识别并校验不同类型的数据,该次引入了通道及空间注意力机制,利用多维注意力机制来实现对数据的准确识别。
通道注意力机制主要由压缩和激励两部分组成,在学习各个通道的信息时,需要先压缩特征图空间,然后在通道维度中进行学习,具体结构如图3所示。

图3 通道注意力机制的结构
在压缩部分对输入的特征F进行平均池化与最大池化,得到两个具有不同空间的描述符和,进而实现数据空间特征信息的聚合;之后将这些信息传递给由多层感知器MLP 组成的共享网络,以获得通道注意力Mc=ℝC×1×1。该文设置的隐藏激活空间的大小为ℝC/r×1×1,其可减少网络参数的开销,r表示缩减率。激励部分会对各通道分配不同的权重,并进行加权求和,最终融入全连接层。计算通道注意力的公式为:
式中,W0∈ℝC/r×C,W1∈ℝC×C/r,而MLP 的权重和则是对两个输入共享的。
与通道注意力机制不同,空间注意力机制注重数据的位置信息,并与前者相互补充,其结构如图4所示。首先该机制在通道方向上开展平均池化和最大池化,且将得到的结果相连接从而形成一个高效的特征描述符;然后通过卷积层生成空间注意力图Ms(F)∈ℝH×W;之后利用两个池化操作聚合特征图的通道信息,进而形成两个图:和,每个图均表示了跨通道的平均及最大池化特征;最后将这些特征全部连接,并利用卷积层生成空间注意力图。空间注意力图的计算方法为:

图4 空间注意力机制的结构
2.4 动态尺度
在对数据的每次训练迭代中,文中将获取异常数据所造成的损失比例作为反馈,并在模型训练期间的每次前向传播后进行计算。若在当前迭代t次时统计的损失比例低于某个阈值,则可认为此时能够通过潜补偿来缓解网络的不平衡,进而在t+1 次迭代中,使用下一个时间段的数据作为输入;若统计量高于阈值,则以当前时间段的数据作为下一次迭代的输入。上述二元确定性范式可以总结为:
式中,It+1表示在迭代t+1 次时输入网络的小批量数据;Ic和I表示在未来迭代中当前时间段和下一个时间段的数据;为迭代t次时占小尺度对象的损失比例;τ为控制数据准备的决策阈值。通过上述过程,便实现了数据的动态尺度调整。
3 数值实验与分析
3.1 数据集的建立
该文使用的数据集来源于某省的医疗数据总库信息,这些数据包含了医疗设备的价格、型号和参数,药品招采的信息,器材损耗使用的信息以及部分电子病历的疾病、诊断与用药信息。数据类型则包括结构化数据、非结构化数据及图片数据。考虑到疫情影响,数据选取的时间段为2018 年1 月1 日-2020 年12 月30 日,在每月的数据中随机选取80%的数据集作为训练数据,剩余20%则为测试数据。
3.2 实验环境
实验选择了Windows 10 操作系统,该系统配备i7-7700k 处理器、64 GB 内存和GTX2080Ti 显卡;编程语言为Python3.7;整个实验基于Anaconda3 中的开源深度学习框架PyTorch 1.0。
该预测模型的相关参数设置如下:批量大小为32,采用AdamW 作为优化器,并使用余弦学习率衰减。通过对模型进行了100 次和5 次的训练-测试交叉实验来评估算法的分类性能。
3.3 结果与分析
数据校核是对海量数据进行检查,发现存在的错误数据,从而实现对相关行为与运转的监管。实验选用了精确率(Precision)、召回率(Recall)和F-分数(F-score)作为评价指标。
其中,精确率表示判断正确的正例数据占判断为正例数据的比例;召回率表示判断正确的正例数据占实际为正例数据的比例;F-分数为调和平均数。
图5 显示了训练和测试的精确率与迭代次数的关系,图6 则为训练及测试中损失函数的损失值与迭代次数之间的关系。

图5 精确率与迭代次数的关系

图6 损失与迭代次数的关系
从图5 和图6 中可以看出,模型在迭代至80次后趋于收敛,测试及训练结果逐渐稳定,即获得了最佳的预测效果。此时模型的精确率达到了96%,损耗也为最小。
为进一步验证所提模型的性能,实验时将数据集应用于常见的主流模型中,并对比了预测结果的指标,具体如表1 所示。

表1 不同模型评价指标
由表1 可知,所提模型的精确率分别比卷积神经网络(CNN)和Transformer 模型高21%与6%。同时召回率及F-分数也均优于其他模型,由此表明该模型对医疗数据的校核是有效的。
4 结束语
文中提出了基于多维注意力机制的动态尺度数据校核算法,该算法引入了通道注意力机制和空间注意力机制来更好地获取数据的特征信息,使用前者能够得到多维的特征向量,利用后者则可准确定位数据。同时还采用Transformer 模型完成对数据的校验,而动态尺度可以通过潜补偿来缓解不平衡网络,从而实现对数据的精准判断。将该算法应用于医疗大数据领域,实现了对临床设备、药品、耗材及病案等医疗数据的校核,并为相关机构的监管工作提供了一定的辅助手段。但该模型也存在一定的缺陷,其对于不同类型的数据并未进行严格区分,导致数据校核时仍有一定偏差。因此,下一步可以通过数据预处理技术实现对数据的分流建模,以获得更为理想的校核效果。
猜你喜欢
大电机技术(2022年5期)2022-11-17
小雪花·成长指南(2022年1期)2022-04-09
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
中国交通信息化(2020年12期)2020-02-06
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
水电站机电技术(2014年4期)2014-10-13
时代英语·高三(2014年5期)2014-08-26
河南科技(2014年22期)2014-02-27
