
基于门控循环单元网络的钻井井漏智能监测方法
2024-02-27 12:16李辉刘凯李威桦孙伟峰戴永寿
电子设计工程 2024年3期
李辉,刘凯,李威桦,孙伟峰,戴永寿
(1.中海油田服务股份有限公司油田技术研究院,河北廊坊 065201;2.中国石油大学(华东)控制科学与工程学院,山东青岛 266580;3.中国石油大学(华东)海洋与空间信息学院,山东青岛 266580)
井漏是钻井过程中常见的风险,其发生会增加非生产时间,降低钻井效率。若井漏得不到及时控制,可能会造成井喷等严重事故,威胁现场人员的生命安全[1-2]。因此,准确监测井漏风险是实现安全钻井的重要保障。
目前,钻井现场的井漏监测以基于综合录井技术的监测方法[3]为主,现场人员通过分析泥浆池体积[4]、出口流量[5]等参数的变化特征[6-7]识别井漏。然而该方法存在特征提取不准确、井漏监测准确率低等问题。李雪松[8]、涂思羽[9]等人开展了基于深度学习的井漏智能监测方法研究,提高了风险识别的准确性。其中,长短期记忆网络[10(]Long Short-Term Memory,LSTM)具有提取时序特征的优点,实现了钻井风险的准确监测[11-14]。但LSTM 网络需要较多训练参数,且模型收敛速度较慢。
为此,提出了一种基于门控循环单元(GRU)网络的井漏监测方法。GRU 网络具有长期记忆功能,有助于提高井漏风险识别的准确率。利用LSTM 与GRU 网络进行了井漏监测实验,结果表明,基于GRU 网络的井漏监测模型具有更优的识别性能。
1 常用的井漏识别网络简介
目前,用于井漏监测的神经网络类型主要包括传统的人工神经网络(Artificial Neural Network,ANN)、循环神经网络(Recurrent Neural Network,RNN)和长短期记忆网络。
1.1 人工神经网络
人工神经网络是一种可广泛并行互联的网络,由自适应性的简单单元构成,能够模拟生物神经系统对外部世界的感知[15]。人工神经网络结构如图1所示。

图1 人工神经网络结构图
人工神经网络一般由输入层、隐藏层和输出层组成。输入层的作用是接收数据,输入层与输出层之间的隐藏层的作用是处理数据,输出层则作为网络的输出。
人工神经网络具有很强的学习能力,能够通过网络的内部结构提取蕴含在数据集中的抽象特征,然后在特征之间用不同的网络节点连接,通过训练得到连接网络的权重。
1.2 循环神经网络
在普通的人工神经网络中,信息是单向传递的,很难处理时序数据。在处理时序数据时,网络的输出不应只考虑与当前时刻输入的关系,也应当考虑与过去一段时间内的输入之间的关联。时序数据的长度一般是不固定的,而普通人工神经网络的输入与输出的维数是固定的。因此,为了解决时序任务,需要利用一种更复杂的循环神经网络。
循环神经网络是一种具有短期记忆功能的神经网络,它在人工神经网络的基础上增加了循环结构,将隐藏层的节点状态传递给下一时刻。在该网络中,神经元不仅可以处理其他神经元的信息,还可以处理自身的信息,形成循环的神经网络结构[14],如图2 所示。

图2 循环神经网络结构
1.3 长短期记忆网络
为了解决传统循环神经网络处理时序数据时存在的长期依赖、梯度消失和梯度爆炸问题,研究人员提出了LSTM 网络。LSTM 独有的“门”结构能够对历史数据进行选择性的存储或者遗忘,从而实现信息的长期记忆[16]。图3 所示为LSTM 网络结构图。
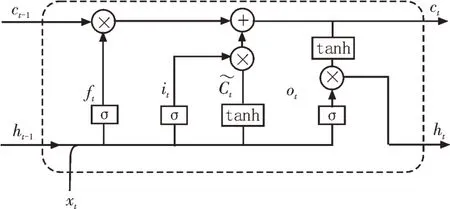
图3 LSTM网络结构图
LSTM 网络通过遗忘门、输入门和输出门来控制细胞状态,实现信息的添加或删除。遗忘门fi主要对上一个节点输入的信息进行选择性遗忘,决定了从细胞状态中遗忘的信息。输入门it决定了当前时刻输入的内容,计算信息候选单元状态͂ 并更新细胞状态Ct,最终由输出门ot根据细胞状态Ct对信息进行选择性输出。
式中,ft为遗忘门的输出,σ为Sigmoid 函数,xt为当前时刻的输入,ht-1为上一时刻隐藏层的输出,Wf和bf分别代表遗忘门的权重矩阵和偏置矩阵。Wi和bi分别代表输入门的权重矩阵和偏置矩阵。ot和ht分别代表输出门的输出和当前时刻的隐藏层输出。
2 基于GRU网络的井漏风险监测方法
基于GRU 网络的井漏风险监测方法主要包括数据预处理和井漏智能监测两部分。首先对综合录井数据进行归一化处理并剔除数据中的异常值,之后以泥浆池体积、出口流量和立管压力为输入构建了GRU 网络,综合三个参数的变化趋势实现对井漏的智能监测。
2.1 数据预处理
2.1.1 归一化处理
由于出口流量、池体积和立管压力的量纲及取值范围不同,为提高模型的收敛速度,提高识别准确率,在模型训练前需要对输入参数进行归一化处理。采用min-max 方法将出口流量、池体积和立管压力数据映射到[0,1]之间,如式(7)所示:
式中,xmax和xmin分别代表一组数据中的最大值和最小值;x表示原始数据;xnorm表示归一化处理后的数据。
2.1.2 异常值剔除
异常值是指在综合录井数据中存在的偏离参数正常取值范围的数据值。常用的异常值剔除方法包括3σ准则、箱形图等。考虑到算法的计算效率,采用3σ准则进行异常值剔除。
3σ准则又称莱特准则,利用其进行异常值剔除的基本思想:假设数据中的随机误差服从正态分布,则误差的绝对值主要集中在其均值附近。
对于服从正态分布的数据,首先计算该组数据的均值μ和标准差σ;然后计算每个测量值的误差d,将误差绝对值大于3σ的测量值替换为该组数据的平均值,从而达到去除异常值的目的。
2.2 GRU模型的工作原理
与LSTM 网络相比,GRU 网络将遗忘门和输入门合并为更新门,同时混合了神经元状态和隐藏状态,使得网络的结构更加简单,训练效率更高。图4所示为GRU 网络结构图。

图4 GRU网络结构图
图4 中,ht-1为t-1时刻的输出;zt为更新门,rt为重置门;为t时刻隐藏层的激活状态;ht为t时刻的输出。信息在GRU 中前向传播分为两个阶段:
1)重置阶段。为了挖掘数据在短期内的时间依赖关系,根据上一时刻的隐藏层状态与当前时刻输入之间的相关性,计算重置门的门控信号:
式中,rt为重置门的输出,σ为Sigmoid 函数,xt为当前时刻的输入,ht-1为上一时刻隐含层的输出,Ur、Vr和br分别代表重置门的输入权重矩阵、隐藏层节点的权重矩阵以及偏置矩阵。
重置门的门控信号决定了上一时刻隐藏层节点状态能够保留下来的信息,然后与当前的输入相结合,并通过tanh 激活函数转变为新的隐藏层节点状态(取值范围为-1~1)。
式中,为当前时刻输入的隐藏层节点状态,tanh 为双曲正切函数,Uc为当前时刻的输入权重,Vc为上一时刻隐含层节点权重,bh代表重置门的偏置矩阵。
2)更新阶段。该阶段进行信息的筛选与传递,解决RNN 的长期记忆问题。根据上一时刻的隐藏层状态及当前时刻输入之间的相关性,计算更新门的门控信号,其表达式为:
更新门zt主要对上一个节点输出的信息进行选择性遗忘,决定了从上一时刻隐藏层状态中遗忘的信息和需要更新的信息。最终,将该时刻有用的信息传递到输出层或传递到下一时刻。
2.3 基于GRU网络的井漏风险监测模型构建
基于GRU 的井漏监测模型包括输入层、GRU层、Softmax 层、与输出层,模型结构如图5 所示。

图5 基于GRU的井漏监测模型结构
1)输入层:将池体积、出口流量和立管压力三个数据序列进行预处理后,作为模型的输入。
2)GRU 层:由两层GRU 结构组成,能够充分地学习时间序列的长期依赖关系,并从数据中自动获取全面、准确的特征。
3)Softmax 层:Softmax 是一种激活函数,可将一个数值向量归一化为一个概率分布向量,且各个概率之和为1。
4)输出层:以GRU 层的输出作为输入,采用Softmax 函数作为全连接层的激活函数,利用全连接层对提取的特征进行分类,得到识别结果。
3 井漏风险识别实验
3.1 数据集
利用从东部某探区收集的10 口井的录井数据构建了井漏风险数据集,数据集中包括立管压力、出口流量和池体积三个参数。数据集中包含800 组正常样本和800 组风险样本,每一组样本都是长度为20 的时间序列。对数据集按照7:3 进行划分,得到训练集和验证集。
网络在训练过程中需要给每一个样本添加标签,根据风险监测对网络的输出需求,输出结果采用独热编码方式进行标注。独热编码是人工智能分类模型训练过程中常用的打标签方式,n位的独热编码可以标注n个状态,而且每个状态相互独立,每次只输出一个状态。井漏智能识别模型只有两个输出:井漏和无井漏,因此采用两位独热编码器,如表1 所示。
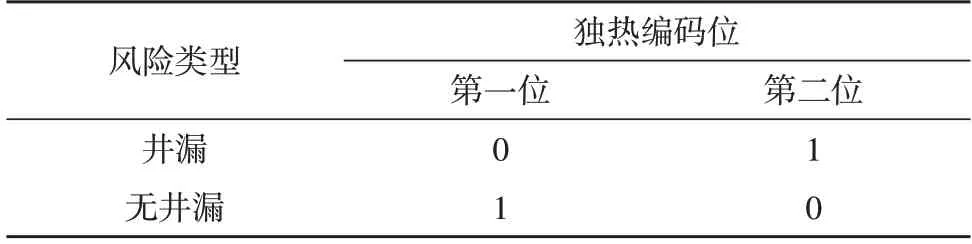
表1 独热编码形式的样本标签
为了将两个类型的输出转换为0-1 的概率形式,在输出层中加入Softmax 函数,让两种输出类型的概率总和为1。
3.2 模型训练
利用3.1 中的数据集对GRU 网络进行训练。该网络的隐含层由两层GRU 层构成,为防止训练过程中出现过拟合,在每层GRU 后加入0.15Dropout,防止出现过拟合。训练过程中,时间步长为20,批尺寸为32,迭代次数为100 次。
由于井漏智能监测属于二分类问题,因此选择分类交叉熵binary cross entropy 作为损失函数,其计算公式如下:
式中,FLoss表示损失值,N表示样本数量,yi表示第i个类别对应的真实标签,ŷi表示对应的模型输出值。
3.3 实验结果与分析
为了验证GRU 模型的井漏识别性能,分别采用GRU 模型与LSTM 模型进行井漏识别,并对识别结果进行了对比分析。两种模型使用相同的训练集和验证集,模型构建时采用相同的参数设置,保证模型构建过程中仅网络类别不同,以两种模型对井漏风险的识别准确率为评价准则。
图6所示为LSTM 模型在训练集和验证集上的识别性能。可见,LSTM模型在验证集上的识别准确率为95.82%。LSTM 能够对历史信息进行学习,在学习远距离信息时表现更好,因此具有较高的识别准确率。
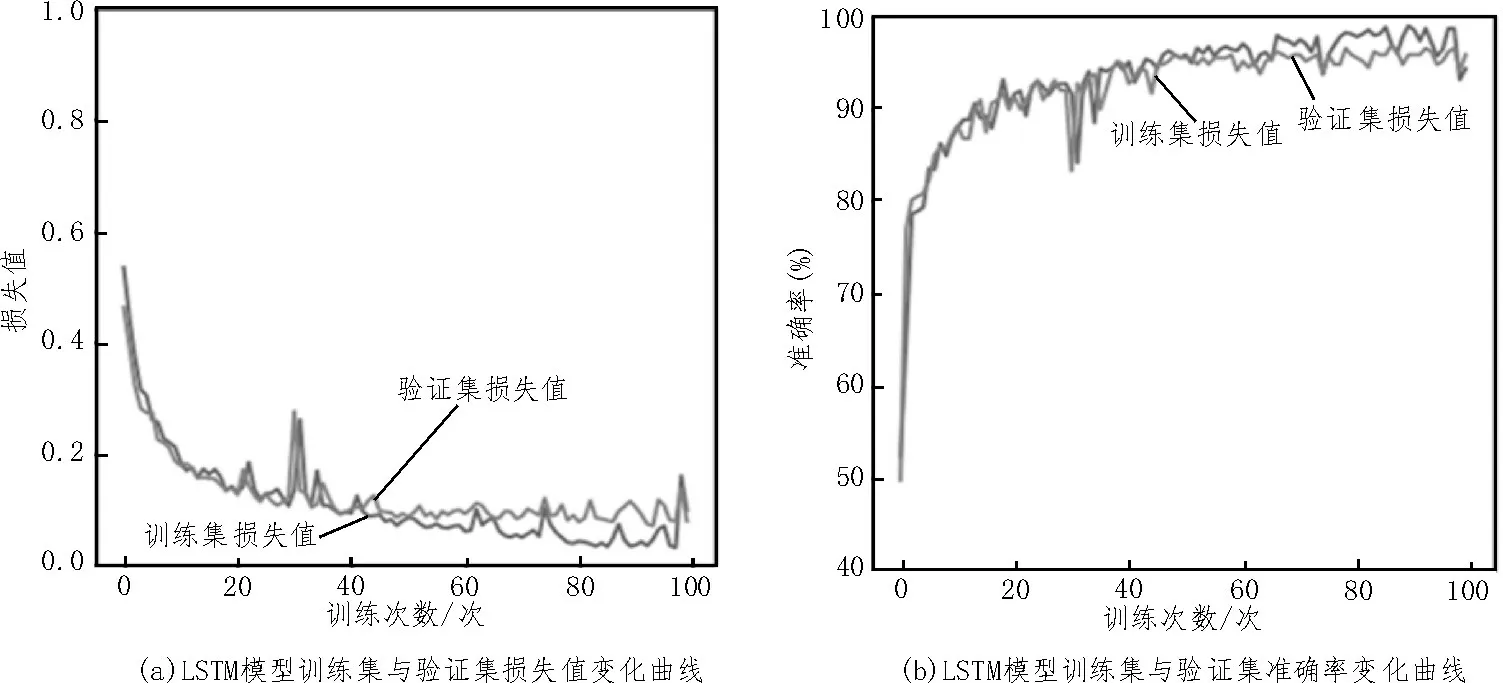
图6 LSTM模型在训练集和验证集上的性能对比
图7 给出了GRU 模型在训练集和验证集上的识别结果。该模型在验证集上的识别准确率达到了96.17%。与LSTM模型相比,GRU模型在验证集上的识别准确率高于LSTM 模型,且GRU 模型在迭代20 次左右时损失值达到了0.1,而LSTM 需要迭代至40 次左右。由此证明,GRU 模型在训练时的收敛速度更快。

图7 GRU模型在训练集和验证集的性能对比
利用测试集对模型进行测试,测试结果如表2所示。

表2 测试集上的模型性能对比
基于上述实验可知,GRU 模型在测试集上取得了良好的识别性能,比LSTM 模型具有更强的泛化能力和识别精度。
4 结论
文中建立了基于GRU 网络的井漏识别模型,利用GRU 网络的时间特征提取能力和对信息的长期记忆能力,准确监测到池体积、出口流量和立管压力的异常变化趋势,实现了对井漏的及时、准确识别,解决了传统井漏识别方法存在的时间特征提取困难、识别准确率低的问题,具有良好的现场应用前景。
猜你喜欢
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
数学年刊A辑(中文版)(2020年2期)2020-07-25
空间科学学报(2020年4期)2020-04-22
数学物理学报(2019年6期)2020-01-13
电子制作(2019年10期)2019-06-17
数学物理学报(2017年5期)2017-11-23
爆笑show(2015年4期)2015-06-24
小学阅读指南·高年级版(2014年2期)2014-05-27
建筑材料学报(2014年4期)2014-03-11
