
CINO 双通道结合多头注意力机制藏文情感分类方法
2024-02-27 12:16白玛洛赛群诺尼玛扎西
电子设计工程 2024年3期
白玛洛赛,群诺,3,尼玛扎西,3
(1.西藏大学信息科学技术学院,西藏拉萨 850000;2.西藏大学西藏信息化省部共建协同创新中心,西藏拉萨 850000;3.西藏大学藏文信息技术教育部工程研究中心,西藏拉萨 850000)
情感分类是自然语言处理领域中热点之一,关于中英文的情感分类研究已相对成熟,而在藏文方面仍需深入探讨和研究。
而随着时代的发展,社交媒体上越来越多的以藏文为代表的小语种使用者也在社交平台表达自己的看法、观点。通过收集分析这类大多带有鲜明的情感色彩的信息不仅有利于解决目前藏文的情感数据缺失的问题,而且对于舆情监控、市场营销等方面有着重要意义[1]。
常用的情感分类方法主要包括传统情感词典构建、机器学习、深度学习等三种[2]。该文初步对藏文文本信息进行了粗粒度情感分类问题的研究,构建了包含积极、消极、中性三种维度的数据集,旨在为藏文情感分类问题提供参考。
1 相关研究
1.1 中文情感分类
在中文情感分类方面,Zhan 等人[3]通过词性和位置信息来建立情感词典取得了不错的效果。但上述方法太依赖情感词典的质量,难以保证情感分类的质量。随着机器学习的兴起,胡梦雅等人[4]使用朴素贝叶斯算法用作分类器对微博评论进行情感分类。
当前,随着深度学习方法在图像处理上的使用逐渐广泛,并取得了较好成果。深度学习模型因其具有学习能力和泛化能力强的特点,能更好地提取文本特征,研究者们开始将深度学习的方法逐步运用到自然语言处理当中。彭祝亮等人[5]针对句子情感极性分类效果差的问题,提出一种结合双向长短记忆网络和方面注意力模块的情感分类方法,与常用情感分类基线模型进行对比发现,该方法可有效提升情感分类效果。Jelodar H 等人[6]提出LSTM 新冠病毒在线讨论情感分类模型,与传统的机器学习模型相比,该文章提出的模型准确率高于机器学习模型,可有效解决RNN 梯度消失和梯度爆炸问题。Xie J等人[7]在BiLSTM 上融入注 意力机制Attention 对情感分类问题进行研究,发现加入注意力机制可以使模型提取更重要的文本信息,过滤掉无用的信息。ZhangY 等人[8]提出CCLA 模型以有效获取局部和远距离句子特征,但该模型是在传统词向量上进行的,存在不能很好地学到上下文信息的问题。李明超等人[9]提出使用Bert 预训练模型来得到包含上下文语义信息的动态词向量,构建BiGRU 结合注意力机制模型来获取全局信息,研究发现使用Bert词向量比传统的词向量效果得到了明显的提升。Cui Y 等人[10]基于Bert 模型生成词向量,结合卷积神经网络融合提取的文本特征,提高了中文文本分类的准确性。与近年来的文本分类模型相比,Bert+CNN模型提高了中文文本分类的准确性,并有效防止过拟合,且具有良好的泛化性。尧欢欢等人[11]使用ERNIE 双通道情感分类,通过将单通道和双通道以及传统的词向量和ERNIE 模型进行对比实验,发现ERNIE 模型的效果优于传统词向量,双通道模型效果优于单通道模型。
1.2 藏文情感分类
在藏文情感分类方面,张瑞等人[12]通过构建藏文情感词典的方法解决藏文情感分类问题。闫晓东等人[13]使用极性词典的方式进行了实验,由于创建情感词典的方法太过依赖情感词典的质量,对文本特征提取不充分,导致情感分类存在准确率过低等问题。随着深度学习在藏语自然语言处理中的运用。却措卓玛等人[14]提出了word2vec 结合双向长短期记忆神经网络藏文情感分类方法,该方法有效解决了长文本句子信息提取不足问题,与机器学习模型相比,其准确率得到提升。曲塔吉等人[15]利用LSTM神经网络对藏文语言中的情绪进行了识别,并取得了较好的识别效果。
但是上述藏文情感分类方法都是基于传统词向量进行实验,仍然存在对上下文词之间语义信息理解能力不足的问题。
2 方法
2.1 CINO双通道结合多头注意力机制情感分类模型
该文提出一种基于CINO 双通道结合注意力机制的模型,首先,通过使用CINO 预训练词向量,CINO 预训练语言模型借鉴了BERT 模型的优势,基本模块使用transformer 模型、MLM 方法,不仅更准确地学习到词语的信息,更能学习到词语的位置信息等。其次,将词向量放入下游任务进行fine-tune,其中下游任务采用双通道,通道一使用TextCNN 模型来获取文本句子局部特征。通道二使用BiGRU模型对长序列句子全局特征进行提取。然后,将双通道结果进行融合,使用多头注意力机制使模型学习到更重要的信息,以提升情感分类准确性,最后,利用该模型进行藏语文本的情感分类。基于CINO双通道结合注意力机制的模型结构图模型如图1所示。
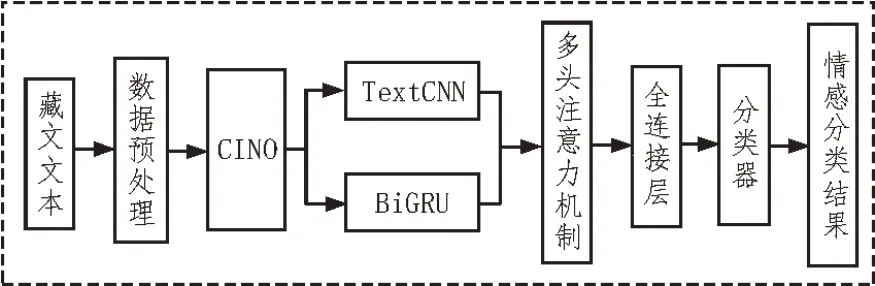
图1 CINO双通道结合多头注意力机制模型结构图
2.2 CINO预训练模型
CINO 预训练模型[16]是基于多语言的XLM-R(XLM-RoBERTa)预训练模型所构建,在国内的多种少数民族低资源语言语料上进行了二次预训练,该模型不仅具备XLM-R 中对100 多种语言的特征提取能力,也提供了蒙语、藏语、维吾尔语、哈萨克语、朝鲜语、壮语等少数民族低资源语言的语言理解能力。多个研究发现,其在多个少数民族语言数据集上均取得了较好的效果,为相关NLP 研究人员提供了重要的应用价值。
CINO 模型为了适应少数民族语言,还进行了词汇拓展和词汇修剪以减小模型误差。近期还推出了base 版本和Large 版本,相比较于XLM-R,CINO 更适用于算力不足的情况,且对少数民族语言的预训练效果优于XLM-R。因此该文使用基于CINO-base来进行词向量的预训练。
2.3 TextCNN模型
卷积神经网络最早用于图像处理方面,之后逐渐被研究者们运用到自然语言处理研究中,TextCNN网络于2013 年被Kim 等人提出。TextCNN 是CNN 的一个变体,TextCNN 网络主要用于文本分类,在短文本提取局部特征方面具有较好的效果。TextCNN 模型通过利用不同的卷积核对输入文本进行特征学习,以此充分学习整个句子的特征,完成分类。
TextCNN 模型主要由卷积层、池化层、全连接层组成,模型结构如图2 所示。

图2 TextCNN模型结构图
通过CINO 预训练得到输出序列[S1,S2,S3,…,Sn],并输入至卷积运算层中。卷积层使用滑动窗口进行卷积运算产生新的特征,提取数据的局部特征,保证词的完整性,不会丢失了单个词的信息。针对文本数据,二维文本矩阵的水平方向长度表示单个字向量的长度,垂直方向是文本序列的长度,其中卷积核的宽度与单个词预训练向量的维度数相同。具体公式如下:
其中,W∈Rhd表示卷积核,h为输入高度(h<n,n为文本长度),d为输入宽度,b∈R为偏置项,σ为激活函数。
经过卷积运算层的计算,得到隐藏特征图c=[c1,c2,…,cn-h+1] 之后,采用最大池化法对提取的最大特征值进行降维,具体公式如下:
2.4 BiGRU模型
起初解决序列问题一般使用循环神经网络RNN,但是由于RNN 在长序列的情况下存在信息丢失,在反向传播的过程中存在梯度消失和爆炸问题,便出现了RNN 的变体长短时记忆神经网路LSTM 模型。LSTM 能够通过三个门控机制保留长距离有效信息,有效提取长文本序列语义特征,解决了RNN存在的梯度消失和爆炸问题,但其只能保留单向的信息。
GRU 模型也叫门控循环单元,跟LSTM 模型相比,它将输入门和遗忘门合成为更新门,因此GRU模型只有重置门和更新门。与LSTM 模型相比,其计算代价以及参数均更少,在模型训练速度方面更优。GRU 的优点是简化了LSTM 的门,GRU 采用单向获取信息,而未考虑后向的下文信息使得获取信息不全面,这使得GRU 在实际应用效果未能如意。而BiGRU 采用正反两个GRU 网络单元,利用双向GRU 获取前后的信息,保留双向的历史有效信息,以此获取全面的文本信息,大幅度提高了模型准确率。由此提出双向门控循环单元BiGRU 模型,其优点是采用正反两个GRU 网络单元,BiGRU 模型结构如图3 所示。GRU 公式如下所示:
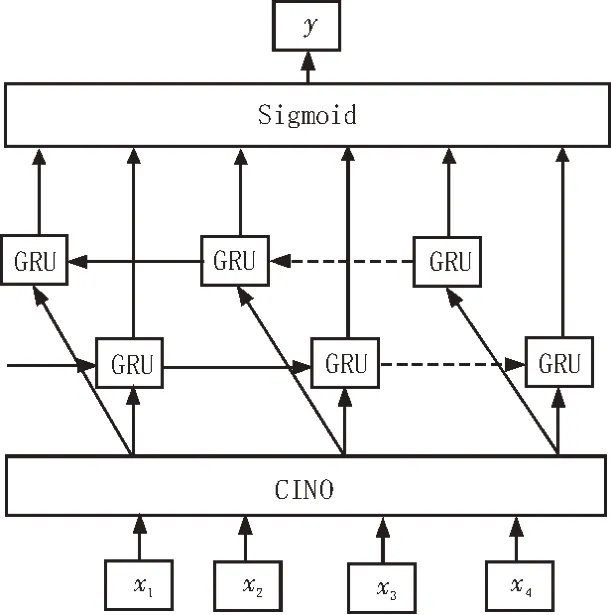
图3 BiGRU模型结构图
其中,rt为重置门,zt为更新门,σ是Sigmoid 函数,ht-1是t-1 时刻隐藏层状态信息;Wr、Wz、Wh͂为权重矩阵;*为点积运算。
BiGRU 的输入为[S1,S2,S3,…,Sn],经过BiGRU,得到隐藏表达序列[h1,h2,h3,…,hn]。经过前向和后向的拼接,每个时刻的隐藏状态表达为
2.5 Multi-Attention模型
Attention 机制就是从人脑的注意力机制演化来的,其核心内容就是期望从众多信息中获取对当前任务目标最关键的信息。通过引入Multi-Attention模型对双通道输出相关性进行重要程度计算,越影响结果的向量分配越大的权重。
将TextCNN 输出的隐藏特征进行摊平操作后,得到:=flatten(cmax),其中cmax是TextCNN模型的输出,两个模块拼接后,得到新的隐藏特征Z=[,h]。Z为载入多头注意力模块的输入,对于某一个时刻,使用注意力层中三个不同的权重向量Wq、Wk、Wv计算得出向量qt、kt、vt:
首先计算每个输入特征计算得分:score=kt·qt。再对每个得分进行归一化计算,除以权重矩阵的维度,然后进行softmax 计算,再乘以价值V,公式如下:
该文采用多头注意力机制,与注意力机制Attention相比,多头注意力机制在其基础上采取重复多次对查询矩阵(Q)、键矩阵(K)、值矩阵(V)进行不同的线性映射,并计算出i个注意头的隐层编码向量,可以比单头注意力机制获取更多的特征信息。每一组注意力将映射到不同空间,设注意力头数为m,对于某一时刻,则计算公式如下:
对所有编码向量进行加权求和,得到一个综合隐藏表达e:
其中,Wo为权重向量,通过学习可得到。
多头注意力机制模型结构如图4 所示。
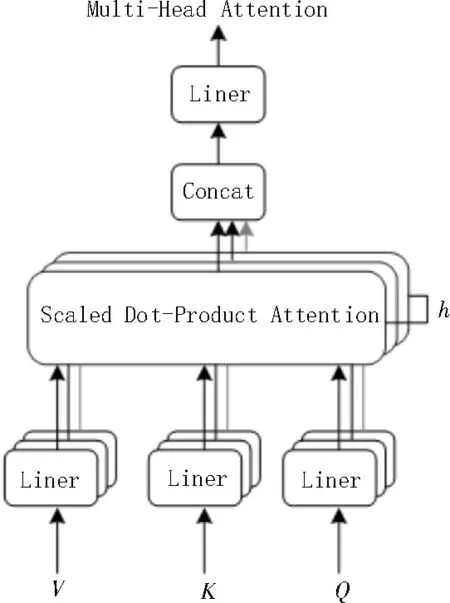
图4 多头注意力机制模型结构图
2.6 全连接层
将多头注意力模块输出的综合隐藏表达e,输入到全连接层进行分类。该过程表达式如式(15)所示:
3 实验
3.1 实验数据集
该文从大众点评官方网站爬取美食、影片、酒店等评论数据。将点评在4 到5 之间的归为积极数据,其标注为1;将点评在3 到3.5 归为中性数据,其标注为2;点评低于3 以下的归为消极数据,其标注为0。共爬取22 000 条数据,去除重复数据后共保留19 000 条数据。实验数据按8∶1∶1 划分为训练集、验证集、测试集。划分结果如表1 所示。
3.2 实验配置参数
该文实验在pytorch1.9.0 框架下完成的。GPU 显存使用24 GB RTX 3090 显卡。
3.3 模型参数
模型参数的选择会直接影响实验结果。该文采用预训练词向量CINO-base 为少数民族预训练模型。其中最大句子长度参数设置为32,学习率为5×10-3,正则化为0.5;卷积神经网络中卷积层的卷积核有三种不同尺寸,卷积核的宽度与输入文本矩阵的宽度一样都是768,高度分别是2、3、4;使用注意力的头数为8;激活函数采用ReLU 函数。
3.4 评估指标
该文采用准确率(Accuracy)、精准率(Precision)、召回率(Recall)和F1 值四个评价指标模型的效果,其公式分别为:

其中,TP 表示在正类情感样本里预测也为正类的样本数量,FP 表示在负类情感样本里预测为正类的样本数量,FN 表示在正类情感样本里预测为负类的样本数量,TN 表示在负类情感样本里预测也为负类的样本数量。
3.5 实验分析与结果
为了能够验证该文所提出的模型在情感分类上的效果,进行了如下实验:1)采用情感分类上常用的基线模型与该文所提出的模型进行对比实验;2)单通道模型与多通道模型对比实验;3)注意力机制与多头注意力机制对比实验。
对比实验所使用的模型如下:
1)TextCNN 模型:使用传统的词向量生成方式,结合卷积神经网络,采用了2、3、4 三种不同大小卷积核来获取文本不同的局部特征信息。
2)BiGRU 模型:使用传统的词向量生成方式,结合双向门控循环单元,记忆前后长序列句子,获取全局特征。
3)DPCNN 模型:使用传统的词向量生成方式,结合深度卷积神经网路,可以获取长序列文本信息,对长文本效果较好。
4)CINO+TextCNN 模型:使用CINO 预训练模型,结合卷积神经网路来进一步获取局部文本特征。
5)CINO+BiGRU 模型:使用CINO 预训练模型,结合双向门控单元进一步获取长序列文本信息全局特征。
6)CTBRU 模型:结合CINO+TextCNN 和CINO+BiGRU 组成的双通道情感分类模型。
7)CTBRA 模型:结合CINO+TextCNN 和CINO+BiGRU 双通道融合后加入注意力机制来进行情感分类。
8)CTBRM 模型:该文模型使用CINO+TextCNN和CINO+BiGRU 双通道,结合多头注意力机制进行情感分类。
3.5.1 不同预训练模型下的对比实验
将该文所提出的方法与TextCNN、BiGRU、DPCNN 进行了对比实验,其结果如表2 所示。
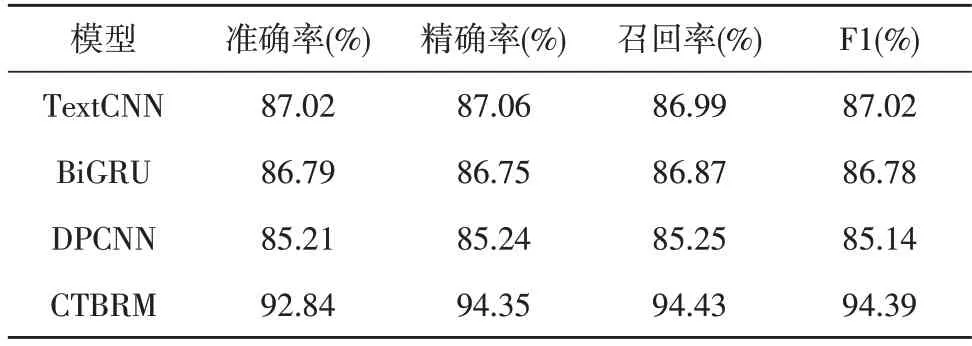
表2 单一结构模型进行对比实验
根据表2 可知该文提出的CTBRM 模型与使用传统的词向量生成方式结合单一模型相比,在藏文情感分类准确率上提升较大,能够在藏文情感分类上取得不错的效果。
3.5.2 不同通道下进行对比实验
该文研究了单通道和双通道情感分类模型。对CINO+TextCNN、CINO+BiGRU、CINO 单通道型与双通道模型进行对比实验,如表3 所示。

表3 单通道和多通道对比实验
从表3 可以看出,双通道CTBRM 模型在四个评价指标上比CINO+TextCNN 单通道模型和CINO+BiGRU 单通道模型效果更优。
3.5.3 注意力机制和多头注意力机制对比实验
将双通道CTBRU 模型上引入注意力机制和多头注意力机制进行对比,如表4 所示。

表4 单多头注意力机制对比实验
通过对比实验可知,多头注意力机制与单头注意力机制相比,在四个评测指标上均有所提升,因此多头注意力机制能够获取更多的特征信息,提高了对藏文情感分类的准确性。
通过上述实验结果表明,使用CINO 预训练模型得到动态词向量后,采用TextCNN 模型获取文本局部特征和BiGRU 模型获取长序列文本全局特征后,再加入多头注意力机制进行情感分类,可以实现藏文情感分类效果的提升。
4 结束语
该文通过将所提出的融入多头注意力机制的双通道藏文情感分类CTBRM 与传统的TextCNN、BiGRU、DPCNN 等模型进行对比实验,CTBRM 模型显著提升了藏文情感分类的准确性和有效性,其情感分类效果更具优越性。未来可以通过融合其他特征,以改进和优化双通道模型,进行实验以提高模型性能将成为研究的重点。而研究细粒度情感分类机制,收集藏文细粒度情感分类数据集,验证模型的鲁棒性也将成为研究的热点之一。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
昆明医科大学学报(2021年4期)2021-07-23
布达拉(2020年3期)2020-04-13
西夏学(2019年1期)2019-02-10
传媒评论(2017年3期)2017-06-13
西藏大学学报(自然科学版)(2016年1期)2016-11-15
第二课堂(课外活动版)(2016年2期)2016-10-21
新闻传播(2016年17期)2016-07-19
电子设计工程(2015年16期)2015-02-27
教育与职业(2014年31期)2014-01-19
