
基于优化的灰狼算法的大规模Web服务组合
2022-11-08 12:43徐雪敏张秀国肖媛元曹志英
计算机应用 2022年10期
徐雪敏,张秀国,肖媛元,曹志英
(大连海事大学 信息科学技术学院,辽宁 大连 116026)
0 引言
随着Web 2.0、云计算、大数据、移动互联网和物联网等技术的迅猛发展,越来越多的企业以开放Web 服务的形式在不同的云计算平台上发布自己的服务,这使得互联网上不同领域的开放Web 服务资源数量呈爆炸式增长[1]。与此同时,用户的需求也朝着个性化、复杂化的趋势发展。当用户的复杂需求无法采用单一服务满足时,就需要整合和协调来自不同领域的不同服务,将多个功能各异的Web 服务按照服务组合方案进行组合,形成大粒度的服务提供给用户[2]。服务数量的迅速增加和服务的多样性使得服务环境具有大规模的特点,如何在大规模服务环境中组合出满足用户需求的组合服务成为服务计算的研究热点。
目前,研究者已经从不同角度对大规模Web 服务组合进行了研究,主要有以下三种方法:
1)服务组合空间缩减。通过对服务组合空间的缩减可以有效地去除冗余服务,提高服务组合的效率。Wang等[3]将Skyline 计算与Q-learning 结合用于服务组合,利用Skyline计算,选取服务质量(Quality of Service,QoS)不被支配的服务减少候选服务数量,提高组合的效率,并结合能反映用户偏好的强化学习方法来解决动态环境下的服务组合问题;但这种筛选方法会随着QoS 的增多而遇到维度灾难的问题。Fan等[4]将大规模Web 服务组合问题转化为从服务依赖图提取最优组合,通过全局和局部的剪枝策略,去除冗余服务和无用的搜索空间,提出了一种链式动态规划算法(Chained Dynamic Programming algorithm,Chain-DP);但这种算法在构建服务之间的拓扑关系时需要消耗大量的时间,并且动态规划的运行时间仍然是伪多项式的。
2)基于服务质量感知的大规模Web 服务组合优化。张苑蕾等[5]提出一种融合遗传聚类的可靠Web 服务组合优化模型,利用置信度表对服务进行筛选,使用聚类和遗传算法对组合服务集合进行多次划分,不但提高了组合可靠性,而且模型最终收敛于全局最优解。Zhang等[6]在果蝇优化算法的基础上引入动态步长、信息共享和精英策略,提高了算法的全局搜索能力和搜索效率,增加了算法在解决服务组合问题上的稳定性。然而这些优化算法在实际应用时也存在着明显的不足,例如烟花算法实现复杂、收敛速度缓慢而且稳定性较差;果蝇优化算法依赖参数的设定,容易陷入局部最优。
3)采用MapReduce 并行编程模型提高大规模Web 服务组合的计算效率。Jatoth等[7]提出了一种基于MapReduce 的并行引导变异的遗传算法(Evolutionary Algorithm with Guided mutation,EA/G)来求解大服务组合问题,该算法引入Skyline 算子从QoS 层面筛选候选服务,利用分布估计算法(Estimation of Distribution Algorithm,EDA)改进遗传算法,通过仿真实验在大服务环境下证明了该算法的可行性和优异性。Zhang等[8]利用改进的离散粒子群算法和MapReduce 来解决大规模动态服务组合问题,引入Skyline 算子剔除冗余的Web 服务,采用混沌序列初始化粒子群,用Chaos-Process扰动机制处理粒子的早熟收敛状态。并行算法在解决服务组合问题上体现了比串行算法更好的性能,但在面对海量的服务时仍具有较大的搜索空间。以上的算法都是仿真实验,没有给出具体的需求描述和真实世界的Web 服务。
本文聚焦大规模Web 服务组合问题,以面向用户需求的服务功能选择为基础,结合群体智能算法,提出一种基于服务主题模型和灰狼算法(Grey Wolf Optimizer,GWO)的Web服务组合方法。
1 大规模Web服务组合问题定义
1.1 相关定义
定义1Web 服务组合
本文用一个三元组CWC=(T,CTRs,W)表示一个具体的Web 服务组合,其中,T={t1,t2,…,tN}表示抽象Web 服务,N表示抽象Web 服务的个数;CTRs是一系列控制结构,包括顺序、并行、选择和循环四种控制结构;W=(w1,w2,…,wk)表示不同QoS 对应的权值(所有权值之和为1),k表示QoS 属性的个数。
定义2候选服务集
候选服务集是一组功能上等价但QoS 属性值不同的具体Web 服务的集合,表示为WSs=其中,是第i个抽象Web 服务的第j个具体Web 服务,i∈{1,2,…,N}表示一个组合服务由N个抽象Web 服务组成,j∈{1,2,…,k}表示一个抽象Web 服务的候选服务集中有k个具体Web 服务是服务的QoS 属性值。
定义3服务质量
Web 服务质量是指Web 服务的非功能属性,本文用一个五元组QoS=(C,R,A,RT,TP)来表示,其中C表示价格,R表示可靠性,A表示可用性,RT表示响应时间,TP表示吞吐量。
由于一个Web 服务具有多个QoS 属性,通常根据其对服务选择的影响效果划分为积极属性和消极属性两类。为了消除不同量纲的影响,需要对QoS 进行归一化处理。对于积极属性如可用性、可靠性等,它们的值越高对服务效能越有益;对于消极属性如时间、费用等,它们的值越低对服务效能越有益。积极属性和消极属性分别按照式(1)~(2)进行归一化计算:
1.2 组合服务的QoS计算
在实际应用中,不同控制结构下的组合服务的QoS 有不同的计算方法,本文将组合服务各个QoS 属性用集合CWQ表示,具体形式如下:
其中,CWqC、CWqR、CWqA、CWqRT、CWqTP分别表示组合服务的价格、可靠性、可用性、响应时间和吞吐量,根据组成组合服务的各个Web 服务的QoS 属性值和服务组合的控制结构计算组合服务的QoS。
本文以响应时间和吞吐量为例说明在四种控制结构下QoS 的计算方法,如表1 所示。其中:RTi、Ti、分别为第i个服务的响应时间和吞吐量,m表示抽象服务组合中包含的抽象服务的数量,pi为选择某分支的概率,c为循环次数。
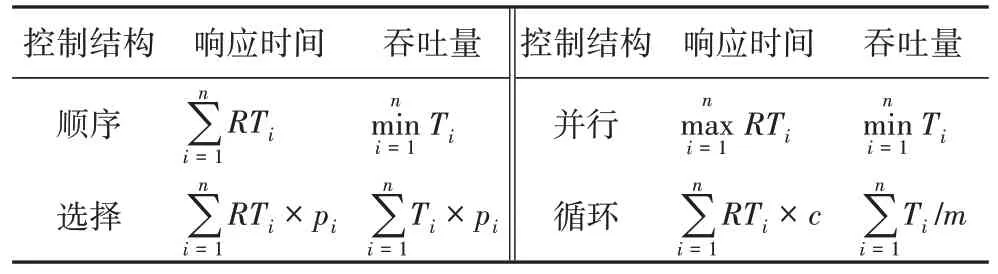
表1 组合服务QoS计算方法Tab.1 QoS calculation methods of composite service
本文将大规模Web 服务组合问题归纳为一个多目标优化问题,使用线性加权的方式将其转为单目标优化问题,通过计算组合服务的服务质量表征组合服务的优劣,服务质量越大,组合服务越佳。大规模服务组合的目标函数如式(3)所示:
其中:fit()表示组合服务的服务质量;maxfit()表示组合服务服务质量的最大值;CWqi表示组合服务第i个QoS 属性值;wi表示第i个QoS 属性所占权重且=1,Q表示QoS 属性的个数。
2 基于优化的灰狼算法的服务组合方法
为了解决大规模Web 服务组合问题,文本提出一种基于优化的灰狼算法和MapReduce 框架的大规模Web 服务组合方法。本文方法的框架如图1 所示。
如图1 所示,该方法首先采用文档对象模型(Document Object Model,DOM)对XML 描述的用户需求文档进行解析;然后基于服务主题模型进行服务筛选,即通过度量用户功能需求描述和服务描述文档的概率主题相似度筛选出各抽象Web 服务的候选服务集;最后利用MapReduce 框架并行实现优化的灰狼算法以选出最佳服务组合方案。
2.1 基于DOM的用户需求文档解析
对用户需求文档解析可以得到抽象服务组合序列和每个抽象Web 服务的功能需求,抽象服务组合序列包含了服务之间的组合结构信息。本文采用DOM 对XML 格式的用户需求文档进行解析,获得抽象服务组合序列和各个抽象Web 服务的功能需求。
以一个简单的旅游需求为例,用户需求描述文档中主要包含以下功能:位置查询(t1)、酒店预定(t2)、餐厅预定(t3)、在线支付(t4)、旅游计划(t5)、照片上传(t6)。首先用户查询自己所在的位置,根据自己的位置预定周围的酒店,同时查找和预定附近的餐厅,用在线支付功能对酒店和餐厅的订单进行支付,然后通过旅游计划服务进行旅游计划的制定,最后将在旅游过程中拍摄的照片上传到社交平台上进行分享。XML 格式的用户需求文档格式如下:
用户需求文档经过解析后得到的抽象服务组合序列如图2 所示。其中,ts表示开始,tf表示结束,t2和t3是并行结构,其他服务是顺序结构。
2.2 基于服务主题模型的服务筛选
为了缩小候选服务规模,在获取到抽象服务组合序列后,根据得到的各个抽象Web 服务的功能描述,对服务候选集进行基于服务主题模型的服务筛选。
2.2.1 服务主题模型建立
概率主题模型是一种可以挖掘大规模文档集合潜在主题的文本信息特征抽取技术,已被广泛开发和用于主题提取和文档建模[9]。针对服务描述文档,使用潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)主题建模技术获取服务描述文档的隐含主题,能够更加准确地度量Web 服务描述文档的语义相似度。
本文首先将Web 服务描述文档进行预处理,经过文本令牌化、小写转换、去除停用词、词形还原和抽取名词动词之后,最终得到的服务描述文档可抽象表达为dtext={w1,w2,…,wn},其中n表示服务描述文档中词的个数,然后采用Bigrams 模型对服务功能描述进行词向量建模,将得到的词向量输入到LDA 主题模型中进行服务主题模型的训练。针对服务描述文档的LDA 主题建模过程如图3 所示,相关符号及含义如表2 所示。

表2 LDA主题模型符号Tab.2 Symbols of LDA topic model
针对服务描述文档的LDA 主题建模过程如下:
1)对每个主题k∈{1,2,…,K}采样生成主题k的词分布:φk~{Dirichlet(β)}。
2)对每篇Web 服务描述文档m∈{1,2,…,M}采样生成文档m的主题分布:θm~{Dirichlet(α)}。
3)对文档m中每个词n∈{1,2,…,Nm},其生成过程为:①选择主题,从θm中抽样生成文档m的第n个词的主题Zm,n~Multinomial(θm);②生成一个词,从所选主题中抽样生成词wm,n~Multinomial()。
表3 为LDA 主题模型生成的服务文档-主题矩阵,其中:di表示服务文档集的第i个文档;Ti表示服务文档集共享的第i个主题。
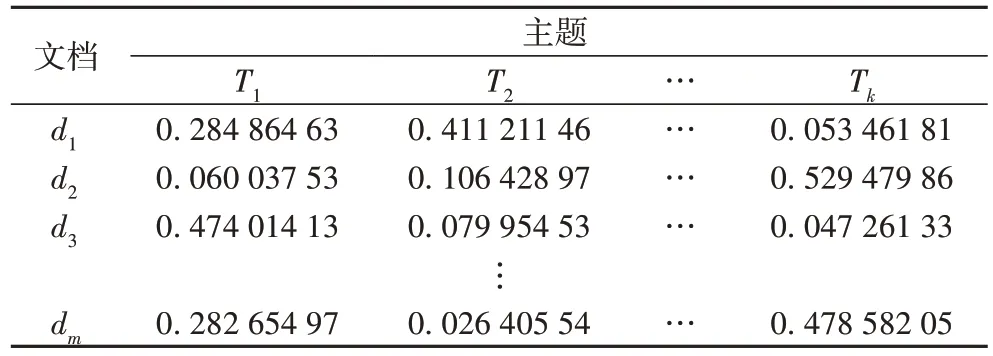
表3 服务文档-主题矩阵Tab.3 Service document-topic matrix
2.2.2 服务筛选
表4 为在线支付功能需求与部分服务描述文档的JS 散度,其中di表示服务文档集的第i个文档。
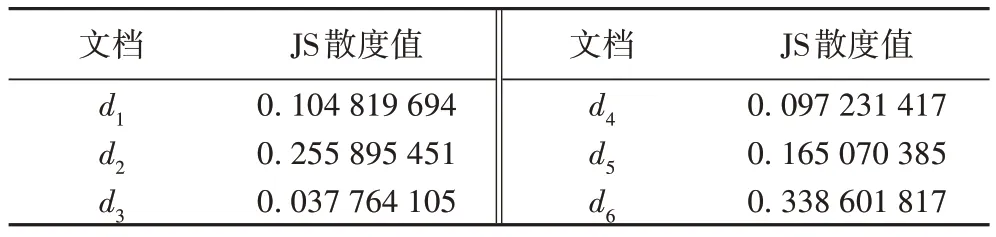
表4 在线支付功能需求与部分服务文档的JS散度Tab.4 JS divergence of online payment function requirement and part of service documents
本文根据抽象Web 服务的功能需求和服务描述文档的JS 散度和经验或者实际情况选定阈值th,为每个抽象Web 服务选出Top-k个服务构成服务组合的候选服务集合。
综上,基于服务主题模型的服务筛选算法见算法1。
算法1 基于服务主题模型的服务筛选算法。
2.3 基于OGWO/LN的大规模Web服务组合求解
由于大规模Web 服务组合面对的候选服务数量巨大且对时间性能要求较高,为了保证服务系统能在合理的时间里组成组合服务返回给用户,本文利用MapReduce 框架将优化的灰狼算法并行化,提高算法在解决大规模服务组合问题时的效率。
2.3.1 对灰狼算法的优化
灰狼算法(GWO)是由Mirjalili等[10]于2014 年提出的一种新型群体智能优化算法,源于对自然界中灰狼种群等级机制和捕猎行为的模拟。GWO 具有参数设置少、原理简单等优点,在参数调整、经济调度、成本预估等问题中已经得到广泛的应用[11]。GWO 将灰狼按照其社会地位从高到低划分为α狼、β狼、δ狼、ω狼四种类型来模拟自然界灰狼的领导层级,同时定义了三种灰狼的狩猎行为:包围猎物、追捕猎物和攻击猎物。
GWO 具有全局搜索能力强、参数设置少、收敛速度快等特点,但也存在着易陷入局部最优的问题。为了使GWO 能更好地应用到服务组合问题中,本文对GWO 进行优化。由于服务组合本质上是一个搜索问题,需要尽可能地进行全局搜索,为此,本文提出一种基于Logistic 混沌映射和非线性收敛因子的优化的灰狼算法(Optimized Grey Wolf Optimizer based on Logistic chaotic map and Nonlinear convergence factor,OGWO/LN),该算法采用谈发明等[12]对灰狼算法初始种群的优化策略,用Logistic 混沌映射生成初始种群,使灰狼种群尽可能地在搜索空间中均匀分布;同时,为了提高GWO的寻优性能,提出一种非线性收敛因子来平衡算法的开发能力和探索能力。
1)混沌生成初始种群。
GWO 以初始种群为基础,通过领导层的灰狼位置和适应度函数进行迭代运算生成新的狼群,因此初始种群的好坏会影响算法的收敛速度和生成结果的优劣[13]。GWO 是通过随机生成的方式完成种群的初始化,这种方式生成的初始种群无法保证灰狼个体在搜索空间的均匀分布[14],使得初始种群缺乏多样性,算法容易陷入局部最优。
为了避免随机生成初始种群产生的问题,本文采用Logistic 混沌映射生成初始种群,这样可以在初始化种群阶段让个体尽可能地均匀分布在搜索空间里,提高算法的搜索效率。
Logistic 混沌映射被用于生成混沌序列,是一种由简单的确定性系统产生的随机性序列,映射方程如式(6)所示:
其中:∈[0,1]为在i维上的混沌变量,i=1,2,…,n表示混沌变量的序号,n表示搜索空间的维数;j=1,2,…,M表示种群序号,M表示种群规模;μ为控制变量,当μ=4时,进入完全混沌状态。
其中:ui是第j只灰狼位置第i维的解空间大小,在服务组合问题中表示第i个服务类的候选服务规模。
2)非线性收敛因子。
群体智能算法的性能优劣体现在两方面:一方面是探索能力即全局搜索能力;另一方面是开发能力即局部搜索能力。探索能力能够尽可能地发现全局最优解,而开发能力能提高算法的求解精度和收敛速度[15]。如何在两种能力之间达到平衡是群体智能算法获得较高寻优性能的关键。
由于GWO 的搜索能力主要取决于A和C两个随机参数进行调节,而A的取值决定于收敛因子a,a在[0,2]里随迭代次数线性递减,这种线性递减与算法实际收敛过程不相符[16],所以,本文提出一种非线性收敛因子更新方式,如式(8)所示:
其中:a表示收敛因子;t表示当前迭代次数;tmax表示最大迭代次数。
收敛因子随迭代次数的变化如图4 所示。从图4 中可以看出,本文提出的非线性收敛因子前期收敛速度较慢,在迭代前期可以扩大搜索范围,易于全局搜索;后期收敛速度快,在迭代后期可以提高算法的求解效率,能够有效地平衡全局搜索和局部搜索能力。
3)狩猎行为。
当灰狼判断出猎物所在位置时,由灰狼α引导,灰狼β和灰狼δ作出配合进行追捕行为,其他灰狼个体ω根据灰狼α、灰狼β和灰狼δ的位置来更新自己的位置。其数学描述如式(9)~(13)所示:
其中:t表示当前的迭代次数;D表示灰狼与猎物之间的距离;A和C是系数向量;Xp(t)表示猎物的位置;X(t)表示灰狼的位置;r1和r2的模取区间[0,1]的随机数;a为收敛因子;X1、X2、X3分别表示灰狼α、β、δ追捕猎物后的更新位置;X(t+1)表示灰狼个体ω更新后的位置。
2.3.2 MapReduce框架下基于OGWO/LN的服务组合求解
1)编码方式。本文采用整数编码方式表示离散的服务,每个Web 服务组合方案相当于一只灰狼,则灰狼i在空间中的位置可以定义为Xi=(xi1,xi2,…,xin),将寻找最优组合服务问题转化为Xi寻求最优解问题。其中,n=(1,2,…,N),每只灰狼的位置有N维,分别对应服务组合路径中的N个抽象Web 服务,xij表示灰狼i在第j维的位置,在服务组合过程中对应一个抽象Web 服务从候选服务集中选择的服务编号。计算每个灰狼个体的适应度值,对该灰狼对应的服务组合方案进行评估,判断组合服务的优劣。具体编码模式如图5所示。
灰狼迭代寻优过程中,其位置常有越出边界的现象,为此本文按式(14)对超出搜索范围的灰狼个体进行越界处理。
2)基于MapReduce 框架的大规模Web 服务组合算法求解。MapReduce 是由Lämmel[17]提出的用于处理海量数据的并行编程模型,它主要有两个核心函数:Map 函数和Reduce函数。本文用MapReduce 模型将OGWO/LN 并行化以解决大规模服务组合问题。
在种群初始化阶段,用Logistic 混沌映射生成N只灰狼的初始种群并计算出每只灰狼的适应度值,找出适应度排名前三的三只灰狼,将初始狼群以文件的形式存储在分布式文件系统HDFS中,作为第一个MapReduce Job 的输入。文件中的灰狼信息以键值对的形式存放,每只灰狼占一行,Key 是灰狼的编号,Value 是灰狼的相关信息,灰狼的结构如表5 所示。

表5 键值对结构Tab.5 Structure of key-value pair
其中,灰狼的位置Xi=(xi1,xi2,…,xin),n表示抽象Web服务的个数,排名前三的灰狼及其适应度值分别为lbestagent,fitness(lbestagent),lsecondagent,fitness(lsecondagent),lthirdagent,fitness(lthirdagent)。
在MapReduce 阶段,每个Job 代表OGWO/LN 的一次迭代过程,一次Job 的输出结果为更新位置后的新狼群,该狼群作为下次迭代的输入。
在Map 阶段,每个Map 任务完成每一代狼群的位置更新操作,并更新每个子群的适应度前三的灰狼信息。Map 函数如算法2 所示。
算法2 Map Procedure。
在Reduce 阶段,Reduce 任务从各个Map 阶段得到的局部前三只灰狼中找出当前种群的全局前三,然后更新种群中所有灰狼的信息,输出完整更新后的种群,新种群代替旧种群作为下一次迭代的输入。Reduce 函数如算法3 所示。
算法3 Reduce Procedure。
3 实验与结果分析
3.1 数据集与实验设置
3.1.1 数据集
本文采用WSDream[18]和API_PGW 的混合数据集。WSDream 数据集记录了142 个用户每15 min调用4 500 个Web 服务的真实响应时间和吞吐量两个属性值。API_PGW数据集是由石敏等[19]2016 年从ProgrammableWeb 网站爬取的12 920 个服务和本文从ProgrammableWeb 网站爬取的5 345 个服务组成,共18 265 个服务,每个服务都有服务名称、服务描述和所属类别。
本文按照以下规则将QoS 数据填充到API_PGW 数据集中。QoS 数据来自WSDream 数据集,并且经过了归一化以减少波动性,服务描述来自API_PGW 数据集。
1)对于API_PGW 中同一类的服务,本文从WSDream 数据集中获取一个用户调用不同服务的QoS 数据。
2)不同类别的服务获取不同用户调用的QoS 数据。
根据上述数据混合规则,得到了一个新的混合数据集,同时包含QoS 数据和服务描述。
3.1.2 实验环境
操作系统为Windows10 64位,Intel Core i5-8265U GPU@1.60 GHz,RAM 16.0 GB,PyCharm 2019,Python 3.6.1。Hadoop 平台是由3 台虚拟机搭建的小型集群,其中一台作为Master 节点,其他两台为Slaver 节点,虚拟机的配置为CentOS7,RAM 2 GB,Intel Core i5-8265U GPU@ 1.60 GHz,Hadoop 2.9.2,Java 运行环境是JDK1.8。
3.1.3 参数设置
1)主题数目K的确定。
本文使用Stevens等[20]的方法通过主题一致性来确定主题K的个数。图6 为不同主题数的主题一致性值,选取曲线趋于平稳前的最大值作为K值,故选取K为60 对服务主题模型进行训练。
2)JS 散度阈值th的确定。
本文根据图2 的抽象服务组合序列进行实验,序列中含有6 个抽象Web 服务。根据本文基于服务主题模型的服务筛选方法,需要确定JS 散度的阈值th。
精确率(Precision)是服务发现中最常用的度量指标,所以本文通过比较不同JS 散度阈值th下的查找服务的准确率情况来确定阈值。Precision@n表示检索返回的文档集中与查询语句相关的文档所占比例,如式(15)所示:
其中:L表示查询到的正确的服务条数;n表示查询到的服务条数。
不同JS 散度阈值对服务发现精确率的影响如图7 所示。当JS 散度阈值在0.04 到0.08 之间时精确率呈上升趋势,当JS 散度阈值在0.08 到0.10 之间时,精确率呈下降趋势。综合考虑不同JS 散度阈值对精确率的影响,本文实验将JS 散度阈值th设置为0.08,从而根据主题相似度确定6 个抽象Web 服务的候选服务数量分别为285、146、163、374、46、147。可组合的服务组合方案超过1011种,可以称得上是大规模Web 服务组合。
3)对比算法参数设置。
为了验证OGWO/LN 在服务组合优化中的性能,将本文与算法IFOA4WSC(Improved Fruit Fly Optimization Algorithm for Web Service Composition,IFOA4WSC)[6]、MR-IDPSO(MapReduce based on Improved Discrete Particle Swarm Optimization,MR-IDPSO)[8]、MR-GA(MapReduce based on Genetic Algorithm,MR-GA)[21]进行比较。在所有的实验中,种群的数量都固定为100。在IFOA4WSC中,学习因子c1和c2的取值范围均为[0.5,2],惯性权重取值范围为[0.1,0.3],δ、η在[0,1]上随机选取。在MR-GA中,参数设置采用随机选择方法,交叉和变异的概率分别设为0.8 和0.1。在MR-IDPSO中,惯性权重从0.9 到0.7 线性变化,学习因子c1和c2取2。由于智能算法的随机性,每次实验运行20 次并取平均值,最大迭代次数为100,两种非功能属性(响应时间、吞吐量)对应的权值分别设置为0.6、0.4。
3.2 实验结果分析
为了验证不同算法在解决大规模服务组合问题时的寻优性能表现,比较4 种算法在不同迭代次数下的组合服务质量。通过计算服务组合的适应度值来对比分析4 种算法的寻优性能,根据本文实验定义的适应度值表示组合服务的服务质量,适应度值越大时表示组合服务的质量越好。实验结果如图8 和表6 所示。
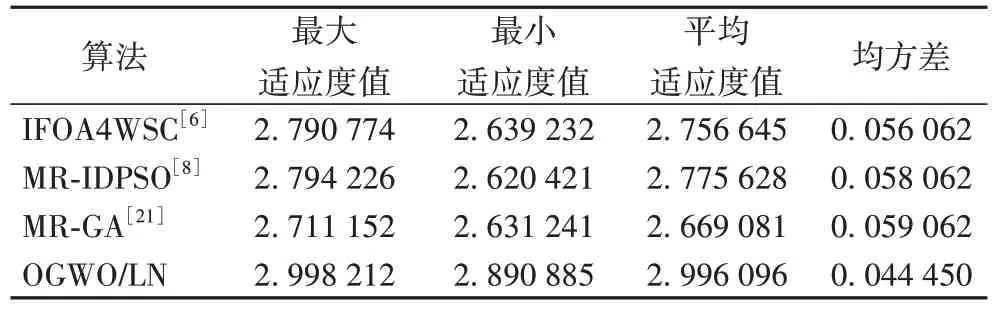
表6 四种算法的性能比较Tab.6 Performance comparison of four algorithms
图8 中纵坐标表示运行20 次的平均适应度值。从图8中可以看出,随着迭代次数的增加,服务组合的平均适应度值逐渐提高,并且OGWO/LN 的平均适应度值在不同迭代次数下都明显高于其他3 种算法。
表6 表示不同算法在迭代100 次、运行20 次时的最大、最小、平均适应度值和均方差。平均适应度值越高,表示算法的寻优性能越高,均方差越低,表示算法的稳定性越好。从 表6 中可以看出,相较于IFOA4WSC[6]、MR-IDPSO[8]和MR-GA[21],本文算法的平均适应度值分别提高了8.69%、7.94%和12.25%。因此,本文算法在相同服务类个数、服务组合规模下,OGWO/LN 在解决大规模服务组合问题上的整体性能优势明显,平均适应度值最佳且稳定性最好。
以上的实验结果验证了本文提出的大规模Web 服务组合方法可以有效地选出QoS 适应度值最优的组合,有效地解决大规模服务组合问题。
4 结语
本文分析了大规模Web 服务组合的特点和组合过程中面临的海量规模、跨界环境等挑战。为了应对以上挑战,提出了一种在复杂环境下的大规模Web 服务组合方法,可以有效地应对服务的海量规模,同时实现组合服务的质量最优。该方法首先采用LDA 主题模型建立服务主题模型对服务进行筛选,以缩减服务组合的搜索空间;其次,采用MapReduce框架并行实现OGWO/LN,为每个抽象Web 服务选出合适的服务提高服务组合的整体质量。最后通过一系列对比实验结果表明,OGWO/LN 相较于其他算法,在解决大规模场景中的Web 组合问题时,在质量上有着更优的效果,并且有着更强的稳定性。未来将进一步研究如何提高服务筛选的精度和复杂服务生态系统中服务质量的影响因素,从而更好地衡量服务质量,选出适合当今服务环境的组合服务。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
小学阅读指南·低年级版(2021年3期)2021-03-19
小太阳画报(2019年1期)2019-06-11
数学大王·低年级(2018年5期)2018-11-01
电脑爱好者(2017年7期)2017-05-06
当代旅游(2016年10期)2017-04-17
快乐作文·低年级(2017年3期)2017-03-25
