
基于BERT和联合学习的裁判文书命名实体识别
2022-11-08 12:42曾兰兰王以松陈攀峰
计算机应用 2022年10期
曾兰兰,王以松,陈攀峰
(贵州大学 计算机科学与技术学院,贵阳 550025)
0 引言
近年来,大数据和人工智能技术的快速发展使得法院信息化建设的进程不断加快,多种自然语言处理技术被应用到了法律领域中[1]。命名实体识别(Named Entity Recognition,NER)是构建法律知识图谱的一项关键技术[2],而目前针对裁判文书的命名实体识别的研究尚且处于起步阶段,相关工作并不多。裁判文书具有一定的格式规范,对于一些格式规范、表达方式单一的实体可以直接利用规则进行抽取,如佘贵清等[3]利用正则表达式构建规则模板来对刑事判决书中的被告人信息、辩护人信息和量刑情节等进行抽取;宋传宝[4]通过编写基于规则的实体识别引擎(Java Annotation Patterns Engine,JAPE)规则实现了对案号、案件类型和审判时间等实体的抽取。但如受害人、作案工具和案发起因之类实体的表达方式复杂多样,并不能通过直接通过规则进行抽取。目前针对这类复杂的实体可使用神经网络模型进行识别,但需解决以下两个方面的问题:
1)多义词表示问题。裁判文书中存在大量的多义词,例如“他一下把刀夺了过来”和“他推了董某一下”中“一下”这个词的上下文语境理应是不一样,如果使用Word2vec[5]等静态词向量作为模型输入将无法对这些多义词进行表示。
2)实体边界识别错误问题。虽然使用词向量作为模型的输入能给模型提供一些实体的边界信息,但词向量的构建首先需要对文本进行分词,由于裁判文书中专业术语较多,单独利用分词工具进行分词则会带来分词错误,如分词工具会将“不锈钢碗”这个实体分成“不/锈/钢碗”,这可能会导致模型将该实体识别成“钢碗”。
针对上述问题,在BiLSTM-CRF(Bidirectional Long Short-Term Memory with a sequential Conditional Random Field)模型[6]的基础上,本文提出了一种基于联合学习和BERT(Bidirectional Encoder Representation from Transformers)[7]的BiLSTM-CRF模型,即JLB-BiLSTM-CRF(BiLSTM-CRF based on Joint Learning and BERT)模型。与仅使用双向长短期记忆(BiLSTM)网络来提取文本特征的BiLSTM-CRF 模型不同,除使用BiLSTM 网络建模长文本信息外,JLB-BiLSTM-CRF 模型还使用BERT 对输入的字符序列进行编码,在避免分词错误的同时通过对BERT 进行微调可以提升词向量的表征能力,从而解决一词多义问题;此外,该模型将命名实体识别任务与分词任务进行联合学习,通过让它们共享相同的BERT嵌入层,以此来提升实体的边界识别率。由于尚未有公开的裁判文书数据集可供使用,本文针对2 700 篇刑事裁判文书进行了标注。在该数据集上的实验结果表明,本文模型能有效提升多类实体的识别效果。
1 相关工作
基于词典和规则的命名实体识别方法需要人工去制定规则或词典,可移植性差,代价高。随着语料集的丰富,一些统计学习方法如隐马尔可夫模型(Hidden Markov Model,HMM)[8]、条件随机场(Conditional Random Field,CRF)[9]、支持向量机(Support Vector Machine,SVM)[10]也被应用于命名实体识别中,但特征的提取依赖于人工,泛化能力不强。神经网络模型能自动进行特征的提取,不依赖于繁琐的特征工程,所以近年来神经网络模型被广泛应用于命名实体识别任务中,如Hammerton[11]首次将长短期记忆(Long Short-Term Memory,LSTM)网络应用于命名实体识别任务中;相较于LSTM 的单向编码,Lample等[6]提出的BiLSTM-CRF 模型则使用BiLSTM 捕获句子的双向语义,并通过CRF 层预测出每个词的标签;Zhang等[12]利用外部词典将词向量信息融入到了字向量中,有效避免了分词错误问题;Dong等[13]提出的Radical-BiLSTM-CRF 模型能学习到中文字符级别及其部首级别的表示,在无需精心设计特征的情况下能获得更好的性能。除了利用BiLSTM 网络提取特征之外,也有一些工作将卷积神经网络(Convolutional Neural Network,CNN)应用到了命名实体识别领域中,如Strubell等[14]使用迭代膨胀卷积神经网络(Iterated Dilated CNN,IDCNN)替代BiLSTM,与CRF层结合组成IDCNN-CRF 模型,在捕获到更大范围的序列信息的同时还能加快模型的训练速度;而Ma等[15]提出的BiLSTM-CNNs-CRF 模型能够自动学习到词级别和字符级别的表示。由于Word2vec 之类的静态语言模型无法对多义词进行表示,而BERT[7]模型具有表征一词多义的能力,在多个领域的命名实体识别任务上都取得了很好的效果,如Liu等[16]利用BERT-BiLSTM-CRF 从非结构化的历史文本数据中提取实体信息,在历史文化领域的命名实体识别任务中取得了良好的效果;针对中文电子病历命名实体识别任务,Li等[17]为了利用到未标记的特定领域知识,使用未标记的中文电子病历对BERT 模型进行了预训练,并加入了字典特征和部首特征以提升模型性能;使用相关任务联合训练命名实体识别模型能有效提升实体的识别效果,如Wang等[18]通过让在不同数据集上训练的生物医学命名实体识别模型共享参数以学习到更通用的词向量表示;Tong等[19]将实体的分类任务作为辅助任务联合训练命名实体识别模型,能在低资源场景下取得更好性能。
在司法领域也有一些关于命名实体识别的研究,如Huang等[20]使用了句向量 的分布记忆模 型(Distributed Memory model of Paragraph Vector,PV-DM)来学习更鲁棒的句子向量表示并改进了Viterbi 算法来提升模型的效率;Wang等[21]提出的Attention-BiLSTM-CRF 模型除使用BiLSTM进行序列建模外还利用了注意力机制提取句子内部的局部特征;王得贤等[22]提出的融合字、词和自注意力的双重LSTM(Join Character Word and Attenion-Dual Long Short-Term Memory,JCWA-DLSTM)模型分别使用了字符模型和自注意力机制获取词语的表示和句子的内部表示,将这两种语义表示进行拼接融合后的句子语义表示能有效提升法律实体的边界识别率。
上述法律命名实体识别模型大多利用静态的词向量作为模型的输入,但静态的词向量表示并不能区分词语在不同上下语境中的含义,故本文在BiLSTM-CRF 模型的基础上利用BERT 来动态生成含有丰富上下文信息的词向量。此外,受多任务学习的启发,本文将分词任务作为辅助任务,通过让分词任务和命名实体识别任务进行联合学习以提升实体的边界识别率。
2 本文模型
本章将详细介绍JLB-BiLSTM-CRF 模型的组成部分和中文分词(Chinese Word Segmentation,CWS)任务作为辅助任务联合训练命名实体识别模型的实现过程。
2.1 JLB-BiLSTM-CRF模型结构
JLB-BiLSTM-CRF 模型的整体结构如图1 所示,模型主要由三层构成:第一层是嵌入层,该层利用BERT 对输入的字符序列进行编码,生成字符的语义向量表示;第二层是BiLSTM层,BiLSTM 对输入的字符向量进行双向编码,捕获字符序列的长距离依赖关系;第三层是CRF层,CRF 用来对上层的输出进行解码,它通过学习标签之间的约束关系可得到最优的标注序列。
2.1.1 BERT预训练模型
静态语言模型如N-Gram、Word2vec 等无法对多义词进行表示,而BERT 可以动态生成含有上下文信息的词向量。如图2 所示,BERT 的输入是由词的嵌入信息(Token Embedding)、句子中词的位置信息(Position Embedding)以及用于区分不同句子的向量表示(Segment Embedding)叠加而成。每个序列的第一个token 是[CLS],在分类问题中可当作序列的表示,而[SEP]则用来分隔两个句子。
BERT-base-Chinese 是使用中文维基百科相关语料预训练的中文BERT 模型,本文将在模型训练过程中使用本文的数据集对它进行微调。如图3 所示,BERT 利用Transformer[23]进行特征的提取,给定一个句子输入{w1,w2,…,wn},将它输入到BERT 模型中可得到输出向量{x1,x2,…,xn}。
2.1.2 BiLSTM层
与循环神经网络(Recurrent Neural Network,RNN)相比,LSTM 能捕获到更长距离的依赖关系。在LSTM 的单元结构中,t时刻LSTM 的输入分别是t -1 时刻的隐藏层向量ht-1和t时刻的特征向量xt,输出是ht,同时ht又是下一个LSTM 单元的输入;而ct-1和ct属于记忆单元,ct-1会在遗忘门作用下选择性地遗忘部分历史信息,然后在输入门作用下加入部分当前的输入信息生成ct,最后在输出门控制下生成新的输出ht。整个LSTM 的更新过程如下所示:
其中:σ表示Sigmoid 函数;W、U表示权重矩阵;b表示偏置向量;it、ft、ot分别表示输入门、遗忘门、输出门的输出向量。
因为LSTM 在对句子进行建模时,无法编码从后到前的信息,而通过将当前时刻LSTM 层的前向和后向输出进行级联可以捕捉到双向的语义信息,所以t时刻BiLSTM 的输出ht可表示为:
2.1.3 CRF层
CRF 能学习到标签之间约束关系,降低输出的错误率。假设BiLSTM 的输出矩阵为P,其中Pi,j代表第i个词对应的标签是j的得分,而A表示CRF 学习到的转移矩阵,Ai,j表示标签i的下一个标签是j的得分。
对于输入序列X={x1,x2,…,xn} 对应的预测序列是Y={y1,y2,…,yn}的得分可表示为:
利用Softmax 函数指数归一化思想,可以得到预测序列Y概率值为:
其中:YX表示X对应的所有可能的预测标注序列。
为了方便计算,利用了对数似然,则NER 的损失函数可定义为:
其中:S表示训练数据中所有句子的集合;表示句子s对应的输入序列;表示句子s对应的预测序列。
2.2 利用分词任务进行联合学习
NER 的识别过程包括两个部分:一是正确识别出实体边界;二是确定实体类型。由于中文文本不像英文文本那样具有明确的分隔符,所以对于某些中文实体而言,很难正确识别对实体的边界位置。而在自然语言处理领域,中文分词(CWS)是对文本中的词语进行划分,即确定词的边界位置。由此可见CWS 和中文命名实体识别(Chinese Named Entity Recognition,CNER)具有高度的相关性。
多任务学习通过共享某些层可以让模型从相关任务中获取到有用的信息,因为模型需要同时兼顾多个任务,所以多任务学习还能够减少模型的过拟合以及提高模型的鲁棒性[24]。受多任务学习思想的启发,如图1 所示,本文将CWS和CNER 进行联合学习,使其共享相同的BERT 嵌入层,使用不同的CRF 解码层进行输出。通过这种方式,模型可以对CWS 中有用的信息进行编码,以学习到含有词边界信息的上下文字符向量表示,这有助于模型提升实体的边界识别率。
分词任务也属于序列标注任务,其损失函数可表示为:
其中:S表示训练数据中所有句子的集合;表示句子s对应的输入序列;表示句子s对应的预测序列。
为了使命名实体识别任务能得到充分训练,本文将命名实体识别任务损失的权重置为1,然后通过λ来调节分词任务损失所占的权重,其中λ∈[0,1],两个任务的联合损失L可表示为:
JLB-BiLSTM-CRF 模型的训练过程如算法1 所示,对于每个epoch,模型在获取到训练数据Dt后分别进行命名实体识别任务和分词任务的训练,然后根据这两个任务的损失来计算联合损失函数,最后进行梯度的更新。
算法1 训练JLB-BiLSTM-CRF 模型。
3 实验与结果分析
由于法律领域没有直接可供使用的命名实体识别数据集和分词数据集。本文先构建两个数据集,然后设置了多组对比实验来验证本文模型的有效性。
3.1 数据集和实验参数配置
3.1.1 数据集
本文所使用的命名实体识别数据集是自主构建的,所用的语料来自于上海市高级人民法院公开的裁判文书(http://www.hshfy.cn),共收集了2 万篇一审刑事判决书,通过统计分析,选取了其中犯罪率较高且实体类别具有一定相似性的3 种案由(寻衅滋事罪、故意伤害罪和盗窃罪)进行标注。由于刑事裁判文书中案情描述复杂,实体类别丰富,为了减少其他无关信息的影响,本文先利用规则将这3 种案由里面的案情提取出来,然后选取了案情描述部分提取完整的2 700条数据进行人工标注,共标注了9 类实体,各类实体数目如表1 所示。
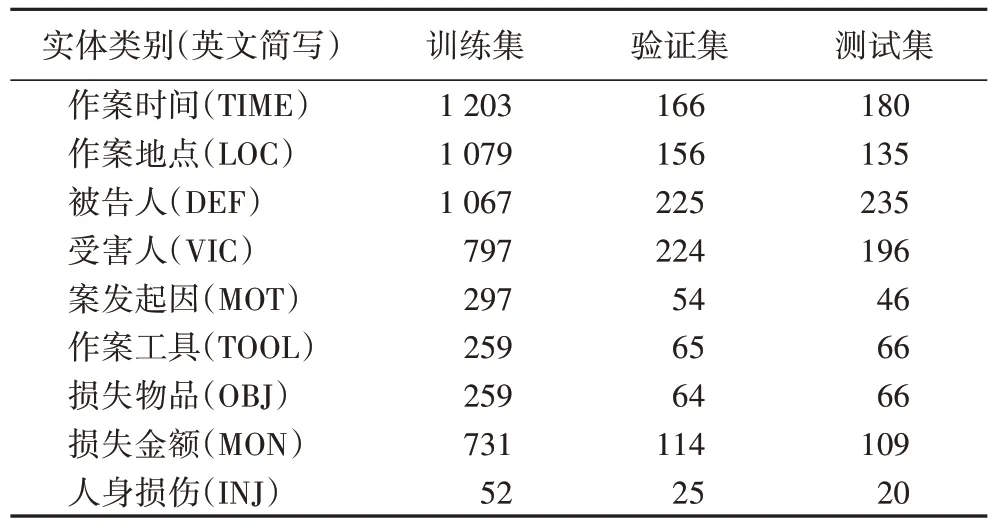
表1 各类实体数目Tab.1 Number of entities in each category
本文中的命名实体识别数据集采用的是“BIO”标注法,对于每个实体,将第一个字标记为“B-实体名称”,其余部分标记为“I-实体名称”。对于非实体,一律标记为O。如“王某某”这个受害人实体每个字对应的标签分别是“B-VIC”“IVIC”“I-VIC”。
在法律领域也尚无公开的分词数据集可供使用,如果利用人工去标注分词数据会耗费大量的人力,但若是直接利用分词工具进行分词又会带来分词错误。通过观察语料集发现除了标注的实体词之外,剩下的大部分属于日常用词。为了减少分词错误,本文在jieba 分词工具中加入了搜狗中文词 典(https//github.com/liujunxin/CWS_with_Dictionary/blob/master/data/cidian.txt),然后利用jieba 分词工具来对除实体词以外的部分进行分词,而对于已经标注的实体则单独划分成一个词。由于只在模型训练过程中使用到分词信息,所以只需对2 160 条训练数据进行分词即可。
对于分词数据集采用的是“BMES”标注法,即将一个词语开头标记为B,词语结尾标记为E,中间部分全部标记成M,而S 用来标记单个字的词。例如“李某因情感纠纷”的分词标签为“BESBMME”。
3.1.2 实验参数配置和评价指标
本实验使用PyTorch 1.7.0 进行模型结构搭建,在显存容量为24 GB 的NVIDA TITAN RTX 上进行模型的训练;实验采用Adam 优化器,学习率为8E-5,衰减系数为1E-5;批处理大小为64;BERT 预训练词向量维度为768,多头注意力个数为12,由于训练文本的长度普遍在150 与300 之间,故选取最大长度为256,如果文本长度超过256 部分则直接进行截断;LSTM 的隐藏层维度设为128,丢弃率为0.5;联合损失函数中的超参数λ为0.3;训练集、验证集、测试集的比例为8∶1∶1。
实验的评估指标采用的是精确率、召回率和F1值,计算方式如下:
3.2 实验结果与分析
3.2.1 不同模型的性能
为了验证模型的有效性,本文与以下对比模型进行了对比实验:
1)BiLSTM-CRF[6]:BiLSTM-CRF 是命名实体识别领域的常用模型,与LSTM-CRF[11]相比,它能捕捉到双向的语义依赖关系。
2)BiLSTM-CRF(Word2vec):使用2018 年法研杯语料集预训练100 维Word2vec 词向量,将其作为BiLSTM-CRF[6]的输入来探究预训练的静态词向量对模型识别效果的影响。
3)ID-CNN-CRF[14]:该模型利用空洞卷积来学习全局特征,能在不引入过多超参数的同时捕获到更长的上下文序列信息。
4)Lattice-LSTM[12]:该模型在字向量中融入了外部词典中的词向量信息,能在避免分词错误的同时引入词级别的信息。
5)BERT-CRF[25]:BERT 具有强大的特征提取能力,能根据上下文语境预测出每个字符对应的标签类型。
6)BERT-BiLSTM-CRF[16]:虽然BERT 模型在训练时加入了位置信息,但随着层数的加深,这些信息会减弱,而通过加入BiLSTM 层能更好地捕捉到长距离依赖关系。
实验结果的对比如表2 所示。为了验证联合学习的效果,本文还对比了3 种不同模型在示例上的表现,不同类型的实体使用不同的下划线来进行标记,标记结果如表3 所示。由表2~3 可得出以下结论:
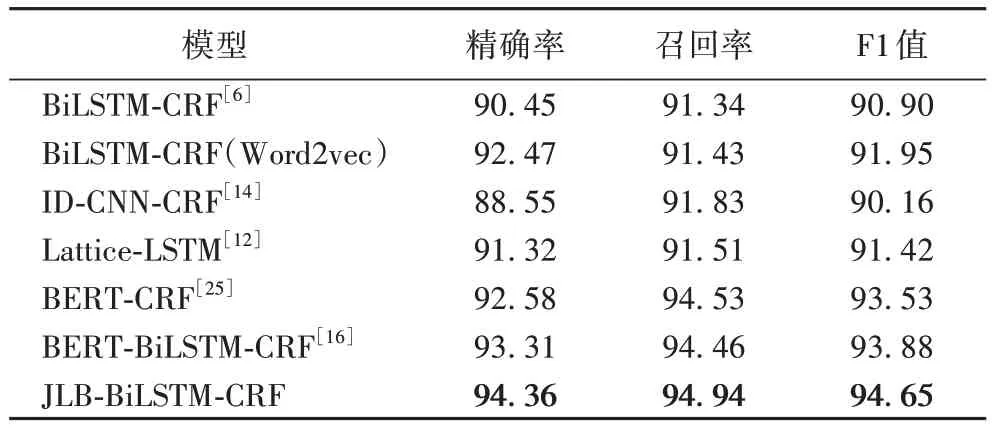
表2 不同模型的实验结果对比 单位:%Tab.2 Comparison of experimental results of different models unit:%
1)BiLSTM-CRF(Word2vec)模型的F1 值比随机初始化输入向量的BiLSTM-CRF 模型高1.05 个百分点,表明预训练Word2vec 词向量里面包含了更多有助于模型进行实体识别的信息。
2)ID-CNN-CRF 模型的F1值比BiLSTM-CRF 低0.74 个百分点,表明虽然该模型使用了空洞卷积进行长序列特征的提取,但对于长文本而言,它的识别效果并没有优于BiLSTM-CRF。
3)Lattice-LSTM 模型在测试集上的F1 值比BiLSTM-CRF(Word2vec)低0.53 个百分点,原因是虽然Lattice-LSTM 能引入词级别信息,但若是文本中词的匹配数过多,不仅会减慢模型的训练速度,还会引入过多的噪声影响模型的性能。
4)BERT-CRF 模型的F1 值比BiLSTM-CRF(Word2vec)高1.58 个百分点,表明与Word2vec 这类静态语言模型相比,BERT 的字符表征能力更强。而BERT-BiLSTM-CRF 模型的F1 值则比BERT-CRF 模型高0.35 个百分点,原因是在BERT之后加入BiLSTM 能让模型捕捉到句子的序列信息。
5)JLB-BiLSTM-CRF 模型的性能均优于其他对比模型,一方面是因为BERT 增强了字符的表征能力;另外一方面是因为联合学习框架能有效利用CNER 和CWS 的相关性,从而让模型学习到了有用分词信息。
6)由表3 可知,BiLSTM-CRF 和BERT-BiLSTM-CRF 均未识别出“方管托盘”这个实体,而JLB-BiLSTM-CRF 模型不仅能将其识别出来,并且相较于BERT-BiLSTM-CRF 还能正确识别出“救护车”“严1”和“严2”的实体边界,表明利用分词任务进行联合学习的确能够提升实体的边界识别率。

表3 三个模型对示例的标记结果Tab.3 Marking results of three models on examples
3.2.2 超参数λ对实体识别效果的影响
JLB-BiLSTM-CRF 模型在训练过程中需要调节联合损失函数中超参数的值,不同的λ值对实体识别效果的影响如图4 所示。当λ取值在0.1 到0.3 之间时,JLB-BiLSTM-CRF模型的精确率和召回率较为接近;大于0.3时,明显存在高召回率低精确率的现象,这主要是因为分词任务只关注边界信息,不关注词的类型,当分词任务占比增大时会使得识别出的实体数远大于识别正确的实数,从而导致精确率降低,因此对于本文的模型而言选择一个合适的λ值是很重要的。通过观察图4 中F1 值可以发现,不同λ对应的F1 值都比BERT-BiLSTM-CRF 模型的93.88%高出0.25 个百分点以上,这是因为在保证命名实体识别任务得到充分训练的情况下,引入分词任务能够让模型学习到额外的信息,该结果也说明了本文的模型具有一定鲁棒性。
3.2.3 BERT和联合学习对实体识别效果的影响
通过分析 BiLSTM-CRF、BERT-BiLSTM-CRF、JLBBiLSTM-CRF 对9 类实体的识别结果可以得出BERT 和联合学习对实体识别效果的影响程度。在图5中,BERT、NER+CWS、BERT+NER+CWS 分别表示BERT-BiLSTM-CRF 相较于BiLSTM-CRF,JLB-BiLSTM-CRF 相较于BERT-BiLSTM-CFR,JLB-BiLSTM-CRF 相较于BiLSTM-CRF 在各实体上的F1 值提升率。通过分析图5 中的BERT 可知,BERT-BiLSTM-CRF 相较于BiLSTM-CRF 在被告人、受害人、损失物品和作案工具这四类实体上的F1 值提升率均超过5.00 个百分点,这表明BERT 依靠强大特征提取能力能学习到丰富的语义特征,使得多类实体的识别效果得到了大幅度提升。由图5 中的NER+CWS可知,JLB-BiLSTM-CRF 相较于BERT-BiLSTMCRF 在案发起因、损失物品和作案工具这三类实体上的F1值提升率均超过了1.00 个百分点,这表明对于一些较难识别的实体而言利用分词任务进行联合学习可以进一步提升它的识别效果。
3.2.4 JLB-BiLSTM-CRF模型的性能
由图5 中的BERT+NER+CWS 可知,JLB-BiLSTM-CRF 相较于BiLSTM-CRF 在作案时间、作案地点、人身损伤和损失金额这四类实体上的F1 值提升率仅在1.00 个百分点左右,主要是因为这四类实体易于识别,基准模型(BiLSTM-CRF)的识别率很高,所以本文模型对它们影响程度较小。此外,由表4 可知,作案工具和损失物品的F1 值分别为86.99%和85.92%,显著低于其他几类实体,这主要是由于作案工具和损失物品的表达方式复杂多样且标注量少,从而导致了它们的识别效果低于其他几类实体。但从图5 中的BERT+NER+CWS 可知,JLB-BiLSTM-CRF 相较于BiLSTM-CRF 在作案工具和损失物品的F1 值提升率均超过了7.00 个百分点,在被告人、受害人和案发起因这三类实体上的F1 值提升率也都超过了4.00 个百分点,表明JLB-BiLSTM-CRF 可以显著提升多类实体的识别效果。
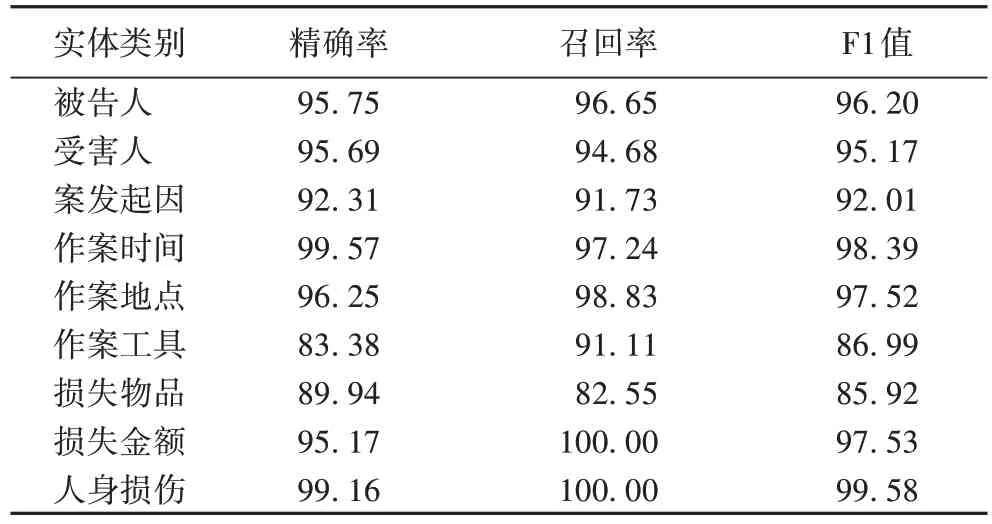
表4 JLB-BiLSTM-CRF模型对各类实体的识别效果 单位:%Tab.4 Recognition effect of JLB-BiLSTM-CRF model to each category of entities unit:%
4 结语
针对法律裁判文书的命名实体识别任务,本文提出了JLB-BiLSTM-CRF 模型。该模型不仅利用BERT 动态生成含有丰富上下文语境信息的词向量,还通过联合学习框架利用到了两个任务之间的相关性,让模型能够学习到有用的分词信息。实验结果表明,该模型能够有效提升实体的边界识别率,对多类实体的识别效果显著优于BiLSTM-CRF 模型。
为了避免繁琐手工调参,下一步将会考虑如何在模型训练过程中自动化调整联合损失函数中分词任务的权重。此外,针对本文中存在部分实体标注数量少、识别效果不佳的问题,未来的研究也会考虑使用数据增强或是迁移学习的方式来进一步提升标注量少的实体的识别效果。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
中国诗歌(2017年12期)2017-11-15
高中生学习·高三版(2016年9期)2016-05-14
