
面向工业生产的中文Text-to-SQL模型
2022-11-08 12:42吕剑清王先兵陈刚张华王明刚
计算机应用 2022年10期
吕剑清,王先兵*,陈刚,张华,王明刚
(1.空天信息安全与可信计算教育部重点实验室(武汉大学),武汉 430072;2.武汉大学 计算机学院,武汉 430072;3.遵义铝业股份有限公司,贵州 遵义 563100)
0 引言
自然语言查询转SQL(Structured Query Language)语句(Text-to-SQL)任务就是将自然语言描述转化成对应的SQL查询语句。随着工业自动化水平和信息化水平不断发展,工业生产领域早已积累了大量的生产数据。但工业领域与传统商业领域不同,工业领域产生的数据可解释性差且比较分散,这就使得目前工业生产领域所产生的大部分数据还停留在数据仓库层面,仅仅只是将历史数据保存起来,并没有有效发挥这些数据的价值。利用Text-to-SQL 模型,工厂管理人员不再需要去了解具体数据库配置信息和数据表信息等底层存储细节,仅仅需要通过自然语言的交互方式便可获取想要的数据。
Text-to-SQL 任务的历史悠久,自20 世纪70 年代以来,自然语言数据库接口任务就开始受到人们关注[1-5],受限于当时的技术发展,这些方法无法适用于复杂多变的自然语言查询场景,只能应用在简单的单表查询任务中。直到近几年,随着语义分析高级神经方法的发展以及大规模、跨领域的Text-to-SQL 数据集WikiSQL[6]和Spider[7]的发布,它才渐渐回归人们的视线。
目前Text-to-SQL 任务主要分为单表查询和多表查询两种场景。单表查询由于其事先明确了SQL 查询所对应的表格以及自然语言查询问句对应的SQL 语句结构,早在2019年英文单表查询数据集WikiSQL 和中文单表查询数据集TableQA 上最优模型[8-9]的准确率就已经达到了普通人类水平,因此当前研究人员的目标在于多表查询的Text-to-SQL 任务。在真实的查询场景中,用户查询的数据往往包含了数据库中的多个表,SQL 语句的复杂程度也大大提升,因此Yu等[7]发布了大规模、跨领域的英文多表查询数据集Spider,研究人员提出了很多新颖的处理策略和模型使得Spider 数据集任务的准确率得到了显著提升[10-15]。相较之下中文多表Text-to-SQL 任务的研究相对较少,虽然目前已经发布了中文多表查询数据集Cspider[16]和DuSQL[17],但当前Text-to-SQL任务相关的研究都聚焦于英文数据集,中文多表查询任务在推出数据集后仍有待研究。本文借鉴英文的模型和处理方法并结合实际查询需求对模型进行微调后,构建了新的模型用于处理中文工业数据集查询任务。
本文使用基于铝冶炼行业的工业生产数据集,在对英文模型进行迁移的过程中,主要存在以下几点问题:
1)自然语言查询的描述与数据库中表名和列名等数据库对象信息的描述不一致,即数据库中表名和列名一般为缩略语等简略化表达形式,例如自然语言问句中的“出铝量”,在数据库中的对应列名描述为“AlCnt”。
2)SQL 语句的列名未明显出现在问句中,而是包含在该列所存储的数据中,很常见的一类就是记录时间信息的列。
3)目前英文模型在识别自然语言问句的where 子句中列名对应的value 值时使用的方法难以应用于大型的工业数据表。文献[18]通过基于变换器的双向编码器表示技术(Bidirectional Encoder Representation from Transformers,
BERT)计算出自然语言问句与数据库表中该列存储的所有数据的注意力分数,这种方法适用于Spider 这种单表数据量小的数据集,但实际工业数据集中大部分数据表都存储上万条数据,所以实际工业数据集的value 识别需要寻求其他解决方法。
英文模型识别自然语言问句关键信息时所用的是指针网络(pointer network)[19],pointer network 最后的输出结果会指向输入序列,即输出只能从输入序列中选择,导致最终英文模型迁移后会产生前两类问题。根据文献[15],Spider 任务中50%的错误都是由这两类问题导致。针对这两个问题,本文模型选择在数据库模式标记的过程中添加元数据。第一类问题本文选择将工厂元数据信息添加到具体的数据使用中,通过元数据对自然语言中的描述进行规范化。第二类问题主要分为两种情况:1)时间短语的识别,90%以上的工业报表都包含存储时间信息的列,同时由于时间短语的表达形式多种多样,本文使用BERT+双向长短期记忆(Bidirectional Long Short-Term Memory,BiLSTM)+条件随机场(Condition Random Field,CRF)模型提取自然语言问句中的时间实体。2)时间短语以外的情况,本文将自然语言中能暗含对应列名的序列称为标签项。例如“武汉”这个标签项暗含了它对应的列名“city”,即生成的SQL 语句中会存在“city=‘武汉’”。这种情况在工业查询中也经常存在,例如氧化铝生产中“锅炉煤耗”这个标签项暗含了对应的列名“tagname”。但是不同于时间短语,这种标签项的数量是有限的,数据仓库设计等工业元数据中会记录表格中的标签项信息,本文通过N元语言(N-Gram)模型即可标记出自然语言中的标签项和对应的列实体。
针对value 问题,本文发现中文自然语言查询中value 经常出现在对应column 相近的位置,根据这一特性本文使用基于相对位置的注意力机制来识别问句中的value。针对实际工业数据集中SQL 语句的结构问题,本文从SQLNet[20]所用到的sketch 中得到灵感,同时不同于SQLNet 仅仅只有一种标准形式,在详细分析工业自然语言问句的特征后将问句进行分类,每种类别设置不同的标准形式,这几个类别足以涵括绝大部分查询场景。
本文主要研究中文Text-to-SQL 的工业应用,直接将英文的主流模型迁移到中文工业Text-to-SQL 任务后得到的SQL语句精确匹配率都不高。本文在分析错误原因后发现当前主流模型难以处理列名描述不一致和列名未明显出现在问句中等问题,然后针对这些问题构建了新的模型。本文模型在关键信息标记过程中添加元数据信息解决以上两个问题,然后结合中文问句中value 值的特性,改用相对位置的注意力机制识别where 子句的value值,最后在处理SQL 语句结构时结合了工业自然语言问句自身的特点,对问句进行分类后通过槽填充的方式提高SQL 语句结构预测的准确率。
1 数据集
由于缺乏工业领域的标准数据集,本文根据工厂业务人员的实际需求通过人工扩充的方式获取用于训练和测试的Text-to-SQL 数据集,这些问句囊括绝大部分的查询场景。本次实验的自然语言问句共2 836条,测试集问句350 条。为了验证最终的精确匹配率,本文为测试集中的350 条问句设计了准确的SQL 语句,即Gold SQL。数据库方面使用部分氧化铝和电解铝的数据表,共包含数据表格27 个。
本文总结了工业数据集和其他Text-to-SQL 数据集的统计数据,结果如表1所示。其 中:ATIS[21]、GeoQuery[22]和Spider 均为英文数据集;Cspider 和DuSQL 均为中文数据集且Cspider 是对Spider 进行中文翻译后得到的。表1中,Q 表示自然语言查询的数量,DB 表示该数据集中包含的数据库数量,Domain 代表数据集涉及的领域数量,Table/DB 表示平均每个数据库中数据表的数量。
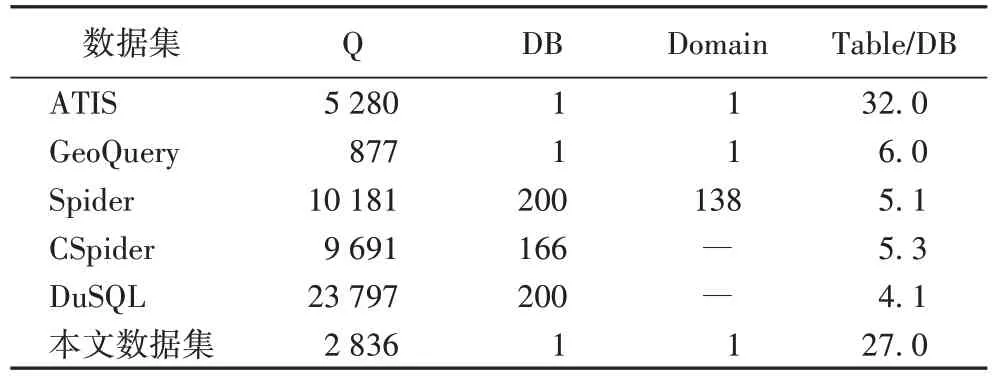
表1 Text-to-SQL数据集的比较Tab.1 Comparison of Text-to-SQL datasets
图1 为Spider 数据集和本文数据集中数据库表格的样例,其中数据表mill 来源于Spider 数据集,数据表fact_pot_dailymeasure 来源于本文构建的铝冶炼数据集。可以看出工业数据集中列名和表名的描述都不会与自然语言描述一致,例如“PotNo”表示电解槽槽号。对比两张数据表可以看出Spider、CSpider 和DuSQL 三个数据集中存储的数据都属于主数据,在企业中是用来定义业务对象的、具有持续性和稳定性的数据,而工业生产中常用的是会随着时间迁移数据量越来越多的业务数据。
图2 中给出了一些铝冶炼自然语言查询的示例,可以看出工业需求的自然语言查询更加注重业务数据而不是实体之间的关系。业务数据具有鲜明的动态时空特性,使得90%以上的工业自然语言查询问句中都包含时间实体,因此模型迁移过程中必须要对时间实体进行准确识别。相较于数据含义简单明了的Spider 数据集,本文的铝冶炼数据集是面向行业的数据集,符合实际工业应用中SQL 查询的分布。
2 本文模型
2.1 时间实体识别
本文模型使用命名实体识别(Named Entity Recognition,NER)来提取自然语言问句中的时间表达式,NER 旨在定位文本中的命名实体并分类为预先定义的类别,例如文献[23]中用来识别医学时间短语。时间实体识别板块如图3 所示,识别文本中的时间实体采用BERT+BiLSTM+CRF 模型。首先,使用Google BERT 的Chinese_L-12_H-768_A-12 模型作为特征表示层,相对于只输出静态词向量的Word2vec,BERT采用先进的Transformer 模型,使得每个词都可以捕获到文本双向关系;然后,将特征表示层的输出加入BiLSTM 中学习单词的上下文语义表示;最后经过CRF 对BiLSTM 层的输出进行优化,充分考虑序列前后的标签信息以获取全局最优的标签输出。
2.2 表名列名识别
Schema Link[11]的目标就是实现问句中表述的内容与数据库的表名和列名等数据库模式信息的映射,然后将得到的列名和表名的标记信息同自然语言问句和数据表结构信息一同作为神经网络的输入,以提高模型的准确率。
首先针对自然语言问句于数据表的表名和列名描述不一致的问题,通过在Schema Link 的过程中引入包含技术元数据的数据字典实现列名的映射,之后根据标记的列名来标记问句中涉及的表名。对于column 未明确出现在问句中的问题,这类问题出现的原因在于某些标签项能隐性说明它所对应的column,除了2.1 节提到的时间序列因其本身表述方式多种多样的特点需要单独处理外,其他情况可以根据数据字典、数据仓库设计等元数据完成映射。图4 是铝冶炼数据集的一个例子,自然语言问句为“氧化铝厂2020 年9 月3 号叶滤精液中苛性化氧化铝的化验量?”,其中“叶滤精液”是列名为tagname 的标签项。在没有其他外部信息输入的情况下当前主流模型难以直接通过“叶滤精液”这个标签项找到对应的column,但工厂元数据中会存储这些有限的标签项信息,因此“叶滤精液”这类标签项可以通过技术元数据的数据仓库设计构建标签项与其对应列名之间的映射关系来找到对应的列名。
如图3 所示,本文使用N-Gram 模型实现Schema Link。N-Gram 模型主要用于评估一个句子是否合理和评估两个字符串之间的差异,后者可以用于进行模式匹配(又称字符串查找)。首先枚举出问句中1 到6 所有的字符串组合(gram),然后按照长度降序的方式与元数据中的数据字典进行匹配,如果一个gram 被认定为列名,则移除与之重叠的全部gram。通过以上方法识别问句中所有的列名实体,然后通过列名可以确认对应的表名。特别地,氧化铝的化验表中存在不同表中有相同的列项的情况,由于不同的表存储的是不同标签项上的化验信息,因此通过元数据和识别出来的标签项确定对应的表名。
2.3 value值识别
针对where 子句中value 的识别,目前的方法大多基于数据库内容(database content)[18],这种方法在Spider 这类每个数据表内容不够多的数据集上有良好的效果,但是实际工业应用中每张数据表的数据量远比Spider 上多,所以在实际应用中需要考虑新的处理方法。本研究着眼于实际的工业查询任务,使用了一种基于相对位置的注意力[24]模型来实现value 值的识别。
自注意力(self-attention)[25]模型的结构如图5 所示。对于self-attention,Q(Query)、K(Key)、V(value)3 个矩阵均来自同一输入。首先计算Q与K之间的点乘;然后为了防止其结果过大,除以一个尺度标度再通过Softmax 函数将其结果归一化为一个概率分布;最后再乘以矩阵V就得到权重求和向量,这个向量可以很好地考虑问句的上下文信息。
相对位置的模型在self-attention 的基础上,引入了两个与相对位置相关的向量,两个向量采用da维向量的表示形式。具体公式如下:
其中权重系数aij通过Softmax 计算得到:
兼容函数eij计算方法使用Scaled dot product:
zi是每个输入序列xi通过加权求和得到的输出元素,也就是说,如果xi是attention 的目标词,那么在计算xj对xi的注意力特征时,需要额外考虑xj对xi的两个与位置相关的向量。
本文将最大相对位置裁剪为最大绝对值k,即假设序列中两个元素的距离超过预先设定的k,则判定两元素之间的位置信息就没有意义,裁剪最大距离还能使得模型可以推广到训练期间没见到过的序列长度。本文设置k=4,并且最终只需关注与column 最相关的即为对应的value。
2.4 自然语言问句分类
在对铝生产行业进行实际考察后,总结了实际工业需求的自然语言输入问题的四个特点:
1)查询的目标更多注重于业务数据而不是实体之间的关系或知识,即物品的产量、材料的消耗、机器的运行状态以及产品的质量检测结果等。
2)查询的数据经常包含聚合操作,例如最值问题和平均值问题。
3)查询问句中的实体描述一般都较为规范,即所查询的属性一定是数据库中原本就有的属性。
4)工业应用中查询的数据很大部分属于生产业务数据,所以问句中一般都会包含有时间信息,如“昨天”“2021 年1月1 日”。由于时间信息的表达方式多种多样,但是在数据库中时间字段的存储格式均是统一的,因此需要将问句中的时间段和时间点都进行规范化。
根据以上特点将自然语言问句分为以下几个类别:
1)一般查询类问题。
该类问题主要是查询某个时间或时间段的一个或多个属性值。例如“2021 年3 月20 日槽号为2 835 的电解槽的出铝量,铝水平?”。可以看到这类问题的查询可以分为槽号、出铝量、铝水平三个关键主体,其中有确定value 值的2 835判定为查询条件,问句中找不到对应value 的判定为查询目标,所以查询的主体表就应该是包含有电解槽每日出铝信息的数据表。
2)最值问题。
该类问题主要是以最值为查询条件得到一个或多个查询目标。例如“2020 年9 月23 号出铝量最大的电解槽槽号?”。
3)时间段最值问题。
该类问题主要是查询目标在一段时间内的最值。例如“氧化铝厂2021 年1 月1 号到1 月30 号最大实产氧化铝量?”。
4)均值问题。
该类问题主要是查询某个时间或时间段的属性均值。例如“今天电解一区电解槽的平均工作电压?”“氧化铝厂1月15 号到2 月15 号平均每天的锅炉煤耗?”。
分类方法使用BERT 中文预训练模型,对BERT 的最后一层进行微调后即可用于本文的分类任务中。重载其中的DataProcessor 类并在主函数中添加该类,对输入数据进行预处理后即可用于训练和测试,BERT 的标志位CLS 接Softmax用于输出分类结果。
3 实验与结果分析
3.1 评价标准
按照文献[7]的标准,实验通过精确匹配率对模型进行评估,即自然语言问句生成的SQL 语句与事先准备的Gold SQL 完全一致的百分比,其中各子句中列名出现的顺序不影响准确率的计算。除了测试模型在工业数据集上的表现外,本研究还评估当前主流模型在不添加元数据信息的情形下在工业数据集上的表现。由于英文模型不涉及value 的识别,所以评判标准是不考虑where 子句中value 值的SQL 语句精确匹配率。
精确匹配率的计算公式如下:
其中:N表示自然语言问句的数量;PSQL、GSQL分别代表预测的SQL 语句、标准的SQL 语句;Accqm代表查询匹配的准确率。
3.2 对比实验
本文把测试集的350 条问句进行人工英文翻译后,再将列名进行人工泛化,使得问句中的列与数据库中的表示一致,最后在英文工业测试集上使用目前Spider 数据集各阶段的主流模型进行对比实验。由于Spider 的实验结果不考虑value,因此对比实验也不考虑value,时间实体也可以不进行处理。实验结果如表2 所示。
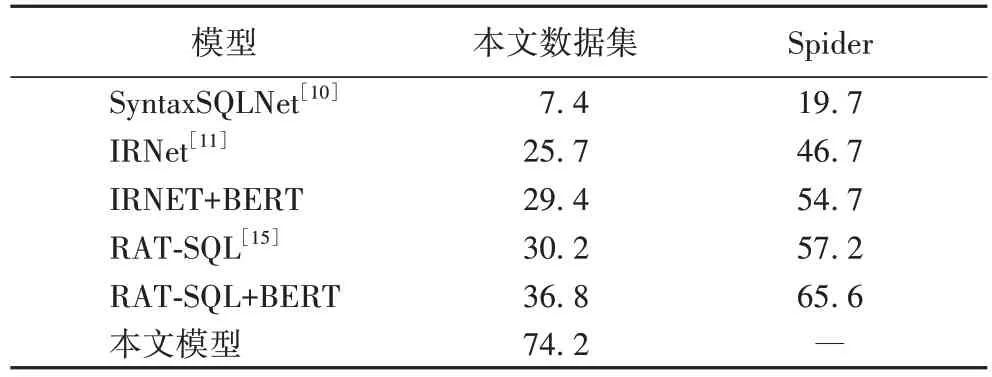
表2 不同模型的精确匹配率 单位:%Tab.2 Exact match accuracies of different models unit:%
其中SyntaxSQLNet[10]、IRNet[11]和RAT-SQL[15]为Spider数据集任务各阶段表现最好的基础模型。从表2 中可以看出,Spider 数据集任务的主流模型在迁移到实际的工业数据集时准确率都偏低。根据文献[7]中所述,Spider 是面向多领域的大规模数据集,并且为了提高模型的泛用性,测试集中30%的问句是训练集中从未见过的;但是从实验结果可以看出这些模型直接用到实际的工业问句中效果并不好,主要原因在于工业数据库的表结构信息远比Spider 数据集复杂,同时工业数据库中存储的数据可解释性差,在没有元数据的情况下机器难以理解自然语言查询问句的语义。另外由于表结构的差异,测试集中大量问句的列名没有明显出现在问句中,经统计本文构建的测试集中这类问句有126条,占全部测试集的40%,导致Spider 任务的模型找不到正确的列名或者根本没有识别出标签项处存在列名。对比本文模型的结果可以看出修改后的模型在处理工业自然语言查询问题时的有效性,同时也说明本文在迁移过程中提出的修改方法和处理策略具有一定理论意义和研究价值。
3.3 消融实验
对模型进行消融实验查看各个模块在模型中起到的作用。首先如果不使用元数据且不对原问句进行人工同义化处理,依靠现在模型的方法根本不能识别问句中任意一个列实体;然后评估添加部分元数据消除表述不一致的问题后模型的准确率;最后添加完整的元数据信息对比显示元数据在处理列名不会明显出现在问句中的效果。消融实验在本文构建的测试集上进行且会考虑value。表3 显示了消融实验的结果。

表3 消融实验的结果 单位:%Tab.3 Results of ablation experiment unit:%
从表3 可以看出,添加部分元数据后虽然可以映射到大部分的列名,但对于问句中仅存在标签项的情况,列实体没有被识别出来,准确率只有39.4%,对比英文模型准确率提高了3%,说明单一领域的Text-to-SQL 问题针对查询问句的特征设计分类模型效果更好。在添加用于映射标签项的元数据之后本文模型的准确率提高了20%以上,说明引入元数据可以有效地处理列名未出现在问句中的问题。对比表2中本文模型的准确率可以看出本文模型在考虑where 子句value 时精确匹配率降低了8%,原因在于value 标记错误和匹配错误。消融结果表明针对数据解释性差且分散的工业数据集任务,利用存储着数据库配置信息和数据表信息的元数据能让工业Text-to-SQL 任务的准确率得到显著的提升。
3.4 错误分析
在对比分析了测试集预测的SQL 语句和用于参照的Gold SQL后,主要发现以下3 类错误:
1)value 匹配错误。主要原因在于工业自然语言问句中where 子句涉及的列实体较多且这些列实体所存储的数据类型相似,难以找到合适的特征区分这些value 导致列实体的匹配出现错误。
2)from 子句的表名匹配错误。主要原因在于工业数据库中不同表中经常含有相同的字段名,导致在联合查询中会出现表名识别错误的情况。未来的工作中将尝试使用全局信息重排序的方法来解决这类问题。
3)SQL 语句的结构错误。主要有两方面:一方面问句分类产生错误;另一方面在于本文的模型难以处理嵌套查询这类SQL 语句结构非常复杂的自然语言查询问题,这也是当前国内外Text-to-SQL 任务面临的最大挑战,将在未来的工作中尝试解决这类问题。
4 结语
本文主要研究中文Text-to-SQL 的工业应用,针对英文模型迁移到中文工业Text-to-SQL 任务过程中遇到的问题提出了一套完整的解决方案。首先针对自然语言查询的描述与数据库中表名和列名等数据库对象信息的描述不一致的问题,将工厂元数据信息融入到具体的数据使用中,通过元数据对自然语言中的描述进行规范化。其次针对列名未明显出现在文句中的问题:一方面通过BERT+BiLSTM+CRF 命名实体识别模型完成时间实体的识别;另一方面通过元数据中的数据仓库设计完成时间实体以外的标签项的映射,从而得出对应列名的标记。再次针对工业数据表中数据存储量过大难以直接套用英文模型的问题,利用中文问句中value 和column 位置特性选择使用相对位置的注意力模型,这样仅需问句和数据库模式信息即可完成value 的识别。最后对自然语言问句的查询特征进行归纳后使用添加问句分类模板槽填充的方式进一步提高SQL 语句结构预测的准确率。
本文根据实际需求构建了一个中文的工业Text-to-SQL数据集,并在该数据集上评估了目前Spider 任务的主流模型以及本文改进后的模型的效果。实验结果表明修改后的模型能有效处理工业自然语言查询问题,同时也表明本文在迁移过程中提出的修改方法和处理策略具有一定的理论意义和研究价值。对于嵌套查询这种非常复杂的SQL 语句,Spider 任务上的模型和本文的模型都没能得到很好的结果。在未来的工作中,将考虑构建严格的语法结构并通过递归的方式来处理嵌套查询这类复杂SQL 语句的查询问题,从而进一步提高中文工业Text-to-SQL 任务的准确率。
猜你喜欢
芜湖职业技术学院学报(2022年2期)2022-11-24
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
党员生活·下(2020年3期)2020-04-20
党员生活·下(2020年2期)2020-04-20
党员生活(2020年2期)2020-04-17
小学生·多元智能大王(2014年6期)2014-07-09
外语教学理论与实践(2014年1期)2014-06-15
