
基于语义关系图的跨模态张量融合网络的图像文本检索
2022-11-08 12:42刘长红曾胜张斌陈勇
计算机应用 2022年10期
刘长红,曾胜,张斌,陈勇
(1.江西师范大学 计算机信息工程学院,南昌 330022;2.南昌工程学院 工商管理学院,南昌 330029)
0 引言
随着人们日常生活中多媒体数据(如文本、图像、语音等)的爆炸性增长,跨模态图像文本检索已成为视觉和语言领域的基本任务之一。它是以一种模态数据作为查询检索另一种模态的相关数据,如给定一条文本检索相关的图像。由于涉及两种不同模态的数据(图像和文本),因此跨模态图像文本检索不仅要解决不同模态数据之间的异构性,还要考虑它们之间的跨模态语义相关性。近年来,虽然该任务已取得了重大进展并且被广泛应用[1],但仍然是一个非常具有挑战性的研究问题。
目前,跨模态图像文本检索方法大致可以分为两类:粗粒度匹配方法[2-11]和细粒度匹配方法[12-16]。粗粒度匹配方法将图像和文本信息直接映射到一个公共的潜在语义空间,然后在公共的潜在语义空间中计算图像和文本的相似度。然而,粗粒度匹配方法仅粗略地捕获了不同模态数据之间的全局语义相关性,无法描述图像区域和文本单词之间的细粒度(局部)语义相关性。为了更好地学习这种图像区域与文本单词对象之间的语义相关性,细粒度匹配方法建模了图像中的图像区域和文本中的单词之间局部相似性度量,并进一步融合得到全局相似性度量。Karpathy等[12]分别提取图像和文本的片段特征(图像区域和文本中的单词),然后将二者的片段特征进行密集匹配。由于图像和文本都是由小的图像区域或单词所组成(通常图像区域对应于某个词对象),因此细粒度匹配方法一定程度上提高了图像和文本匹配的准确度。然而目前大多数细粒度匹配方法仅考虑到图像区域和文本单词对象之间语义相关性,忽略了图像区域间的关系以及文本单词间的关系。
如图1(a)所示,图像数据中“女孩”区域对应单词“girl”,“球”区域对应单词“ball”,但“throw”等表示动作或者对象关系的单词无法匹配到对应的图像区域,而图像和文本的语义相关性往往体现在模态内对象之间的关系和模态间的关联。如图1(b)所示,图像中的“手臂”区域和“球”区域的关系对应文本中表示对象之间的关系动词“throw”“衣物”区域和“女孩”区域之间的关系对应文本中的关系词“in”。为了挖掘图像区域之间的关系,Li等[16]提出了一种视觉语义推理网络(Visual Semantic Reasoning Network,VSRN),采用图卷积网络(Graph Convolutional Network,GCN)[17]推理图像区域间的关系,然后生成各模态全局语义表示进行全局语义推理,该方法没有显式地对模态间的对象关系的关联进行建模。Wei等[18]提出了一种基于交叉注意力机制的图文匹配网络,将模态内和模态间的关联关系进行统一建模。
为了捕获模态内的对象关系和模态间的语义相关性,本文提出了一种基于语义关系图的跨模态张量融合网络(Cross-Modal Tensor Fusion Network based on Semantic Relation Graph,CMTFN-SRG)的图像文本检索方法。采用GCN 建模图像区域间的关系和门控循环单元(Gated Recurrent Unit,GRU)[19]学习文本单词级别的特征以及单词之间的作用关系(模态内对象之间的关系);另外,为了挖掘模态间的语义相关性,本文采用张量融合的方式学习模态间(图像区域、图像区域的关系和文本单词之间)的细粒度关联关系,并将图像和文本的全局特征进行匹配以获得模态间的全局语义相关性,通过联合优化细粒度和全局语义相关性以获取图像和文本的最佳匹配。
1 相关工作
本文主要研究跨模态图像文本检索,致力于探索视觉和语言的潜在对应关系。目前跨模态图像文本检索的方法大致可分为两类[20]:1)粗粒度匹配方法,将整个图像和文本映射到一个共同的嵌入空间学习模态间的全局语义相关性;2)细粒度匹配方法,注重于学习图像和文本对象间的局部语义相关性。
1.1 粗粒度匹配方法
Wang等[21]通过线性投影的方式最大化不同模态数据的相关性,该方法直接将两个模态的数据投影到一个共同的潜在语义空间以获取不同模态数据的潜在语义特征。Kiros等[2]采用卷积神经网络(Convolutional Neural Network,CNN)提取图像特征和长短期记忆(Long Short-Term Memory,LSTM)网络提取文本特征,然后通过成对排序损失(Pairwise Ranking Loss)将图像和文本嵌入到共同语义空间。Liu等[22]采用循环残差融合网络学习多语义的特征表示。Faghri等[4]在三元损失函数的基础上提出了难例挖掘(Hard Negative Mining)方法进一步提高了检索精度。
上述方法虽然在跨模态图像文本检索任务上取得了不错的效果,但是忽略了图像和文本数据在细粒度层面上的语义关联。
1.2 细粒度匹配方法
近些年来在跨模态图像文本检索任务上,越来越多的研究倾向于探索跨模态图像文本的细粒度视觉语言对应关系。Karpathy等[12]分别对图像和文本提取图像区域和单词特征,然后在嵌入空间中将提取好的两种模态数据特征进行对齐。Niu等[13]将文本构造成一棵语义树,其中每一个节点代表一个短语,然后采用分层LSTM 提取短语层次的特征。Nam等[14]提出了一种双重注意力机制网络,该网络包含两个分支,分别用于获取图片和文本的局部关键语义特征,然后通过融合这些局部关键语义特征计算图像和文本的全局相似度。Lee等[15]通过堆叠交叉注意(Stacked Cross-attention)加强不同模态数据的对齐。Li等[16]采用GCN 学习图像区域的关系(局部特征),然后使用GRU 将这些局部特征进一步融合得到图像的全局特征。虽然上述方法一定程度上解决了粗粒度匹配方法中的问题,但是这些方法均未考虑图像区域间的关系与文本单词之间的语义关联。Wei等[18]基于交叉注意力机制建模了模态内和模态间的关联关系,而本文通过全局语义推理网络和张量融合网络学习模态内对象之间和模态间的语义相关性。而本文将通过全局语义推理网络和张量融合网络学习模态内对象之间和模态间的语义相关性。
2 CMTFN-SRG模型
本文所提出的基于语义关系图的跨模态张量融合网络模型主要由三个部分组成:图像模态内关联关系及全局语义学习模块、文本单词级别的特征及全局语义学习模块和跨模态张量融合模块,如图2 所示。首先,对于图像区域特征,采用基于Faster-RCNN(Faster Region-based Convolutional Neural Network)[23]的自下而上注意力模型(Bottom-Up Attention Model)[24]提取,对图像区域采用图卷积网络构建图像区域之间的语义关系图,学习图像区域之间的关系;对于文本特征,采用双向门控循环单元(Bidirectional GRU,Bi-GRU)学习文本单词对象特征以及对象之间的关系;然后,将所学习到的图像和文本的语义关系以及对象特征通过张量融合网络进行匹配以学习图像和文本在细粒度层面上模态间的语义相关性;最后,用图像特征生成文本并计算图像和文本之间的全局语义相关性。
2.1 图像模态内关联关系及全局语义学习
给定一张图像I,使用基于Faster-RCNN 的自下而上注意力模型[25]提取图像区域特征,图像区域特征的集合O表示为:
其中:oi表示O中的一个图像区域特征;n表示I中检测到的图像区域总数;d表示单个图像区域的特征维度。
为了学习图像区域之间的关系,本文根据所获取的图像区域特征构建全连接图G=(O,R),其中R表示图像区域之间的关系矩阵,表示为:
其中:μ(·)和ν(·)是通过反向传播学习的两个全连接层。
然后将所构建的全连接图输入到带有残差连接的GCN中学习图像区域之间的关系,如图3 所示。其中,经过第l层GCN 所学习到的具有模态内对象关系信息的图像区域特征表示为:
其中:Rl∈Rn×n,Ol-1∈Rn×d∈Rd×d和∈Rn×n分别为GCN 和残差连接的权重矩阵,本文设置d为2 048,n为36。为了充分学习图像区域之间的关系,本文使用了l层GCN。
最后将GCN 的输出结果输入到GRU 中得到图像的全局特征,表示为:
2.2 文本单词级别的特征及全局语义学习
为了实现图像和文本的细粒度关联,本文采用Bi-GRU作为编码器提取文本单词级别的特征以及单词之间的关系,如图4 所示。
对于一个包含m个单词的文本C,每个单词wj均采用连续的嵌入向量ej=Wewj,∀j∈[1,m]表示,其中We是需要学习的嵌入矩阵。为了利用上下文信息增强单词级别的特征表示,本文使用Bi-GRU 获取文本C中向前和向后两个方向的信息:
最后,文本C的特征可以表示为:
2.3 基于张量融合网络的跨模态匹配
为了学习模态间的关系,本文采用张量融合网络以学习模态间(图像区域、图像区域的关系和文本单词之间的关系)的细粒度语义相关性。
然后通过两个全连接层Wm和WT得到图像和文本模态间的局部细粒度相似性度量:
考虑到图像和文本的全局语义对齐,本文采用内积的方式对图像和文本的全局特征进行相似度计算,表示为:
其中:ϕ(·)表示相似度计算函数;Vg和Tg分别表示图像和文本的全局特征。
2.4 联合损失函数
对于匹配部分,本文借鉴了文献[4]中的方法,在训练过程中重点关注一个batch 中错误匹配中得分最高的图像-文本对(hardest negative pairs),则局部语义损失函数定义为:
另外,本文将学习到的图像特征进一步生成文本以提高所学习的全局图像语义特征与文本之间的相关性。采用Seq2seq(Sequence to sequence)模型[26]将2.1 节中所学习到的图像特征生成对应的文本T。如果图片特征学习的越好,则生成的文本越接近真实的文本,因此将文本生成的损失函数定义为:
其中:={ti|i=1,2,…,N}表示生成的文本,N是生成文本的长度;φ是Seq2seq 模型通过反向传播所学习的参数。
最后通过联合式(12)~(14)得到最终的损失函数:
3 实验与结果分析
为了验证本文所提方法的有效性,本文在两个公开的数据集MS-COCO 和Flickr30K 上进行了文本检索(给定图片检索文本)和图像检索(给定文本检索图像)实验,并与最近相关算法进行了对比分析。对比算法包括:1)递归残差融合(Recurrent Residual Fusion,RRF)方法[22],基于递归残差融合模块构建图像和文本的共同嵌入子空间学习具有判别力的表 示;2)视觉语义嵌入(Visual-Semantic Embeddings,VSE++)[4],使用难分样本学习视觉语义嵌入的方法;3)双分支卷积(Dual-Path Convolutional,DPC)[27],是一种通过双分支CNN 网络提取图像文本嵌入特征表示的方法;4)SCO(Semantic Concepts and Order)[28],通过学习语义概念和顺序增强图像的表示;5)堆叠交叉注意网络(Stacked Cross Attention Network,SCAN)[15],通过注意力机制捕获视觉和语言之间的细粒度关系、加强不同模态数据的对齐;6)多模态张量融合网络(Multi-modal Tensor Fusion Network,MTFN)[29],是一种基于多模态张量融合和重排序的图像文本检索方法;7)视觉语义推理网络(Visual Semantic Reasoning Network,VSRN)[16],是一种采用图卷积网络推理图像区域间关系的视觉语义学习方法;8)多模态交叉注意力(Multi-Modality Cross Attention,MMCA)[18],是一种基于自注意力和交叉注意力机制的图文匹配网络。
本文采用R@K作为评估指标,R@K表示检索结果取前K个实例时所获得的召回率(Recall),其值越高表示模型性能越好,通常K={1,5,10}。另外为了评估模型的整体表现,本文将R@K的均值(mean Recall,mR)作为评价指标,其值越大,则模型的整体表现越好,计算公式为:
其中:N为实例个数;RLK=0 表示第K个返回结果与查询实例无关,RLK=1 表示第K个返回结果与查询实例相关。
3.1 数据集
MS-COCO 数据集中每张图像有5 个文本注释,将其按照文献[4]中的划分方法进行划分。Flickr30K 数据集中每张图像包含5 个文本描述,将其按照文献[12]中的划分方法进行划分,两个数据集的划分结果如表1 所示。
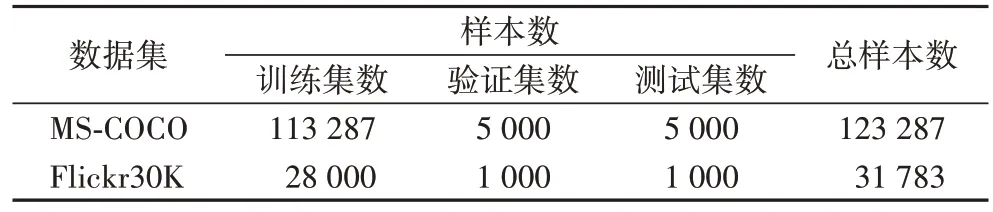
表1 两个常用的基准数据集Tab.1 Two commonly used benchmark datasets
在最后的测试阶段,为了验证模型的稳定性和鲁棒性,本文采用两种测试方法验证实验结果:第一种方法(MS-COCO5K)直接将5 000 张测试图像作为测试集进行测试;第二种方法(MS-COCO1K)则是采用5 折验证的方式进行测试,每次测试1 000 张图像,然后将5 次测试结果的平均值作为最终的测试结果。
3.2 实验细节
在实验中,本文采用基于Faster-RCNN 的自下而上注意力模型提取置信度得分排名前36 的图像区域,在2.1 节中GCN 个数设置为4。在模型训练期间采用Adam[30]作为优化器,迭代次数(epoch)设为40。对于Flickr30K 数据集,初始学习率设置为0.000 4,每5 次迭代进行一次学习率衰减,衰减因子为0.1,在2.3 节张量融合网络中K设置为20。在MSCOCO 数据集上训练时,学习率设置为0.000 2,每15 次迭代进行一次学习率衰减,衰减因子为0.1,在张量融合网络中K设置为15。在联合损失函数中,损失函数LF和LG中的边际参数α和β均设置为0.2。本文所有的实验都是使用RTX2080TI GPU 和PyTorch 0.4.1 深度学习框架实现。
3.3 实验结果及分析
3.3.1 在Flickr30k数据集上的结果
表2 给出了本文所提出的CMTFN-SRG 方法与对比方法在Flickr30K 测试集上的召回率对比结果。从表2 可以看出,本文所提出的CMTFN-SRG 方法与对比方法相比,在文本检索图像任务上R@1、R@5、R@10 指标均有明显的提高;在图像检索文本任务上仅次于MMCA 方法。与MMCA 方法相比,CMTFN-SRG 方法在文本检索图像的任务上R@1、R@5、R@10 分别提高了2.6%、1.4%、1.8%。MMCA 方法采用自注意力机制学习图像区域间的关系,然后通过交叉注意力机制对模态内和模态间的关联关系进行统一建模,将学习到的图像图全局语义特征与文本全局语义特征进行相似性匹配;而CMTFN-SRG 方法则采用张量融合网络对GCN 建模的图像区域间的关系以及图像区域特征和文本单词级别的特征进行语义相关性学习以捕获两种不同模态间的细粒度关联关系(模态间的对象以及对象关系的关联),因而取得了更好的结果。该实验结果也表明了本文采用张量融合网络能够有效学习模态间对象关系的语义相关性。
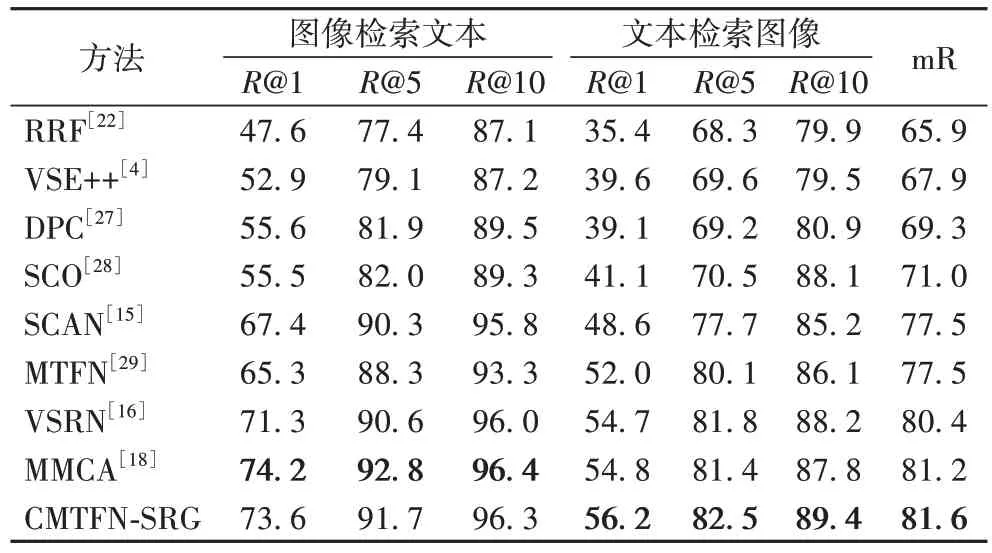
表2 Flickr30K测试集上的召回率对比结果 单位:%Tab.2 Recall comparison results on Flickr30K test set unit:%
3.3.2 在MS-COCO数据集上的实验结果
本文进一步对所提出的CMTFN-SRG 方法与对比方法分别在MS-COCO5K 测试集和MS-COCO1K 测试集上进行了文本检索图像和图像检索文本两个任务中的R@1、R@5、R@10召回率对比分析,对比结果分别见表3~4。实验结果表明本文所提方法优于大多数对比方法。在MS-COCO5K 测试集上,CMTFN-SRG 方法在文本检索图像的任务上R@5、R@10最优,其中文本检索图像的R@1 比MMCA 方法提升了4.1%;在MS-COCO1K 测试集上CMTFN-SRG 在文本检索图像任务中R@1、R@5、R@10 均高于MMCA 方法,其中文本检索图像的R@1 提升了9.0%。同时,相较于MMCA 方法,CMTFN-SRG 方法在Flickr30K 测试集、MS-COCO1K 测试集和MS-COCO5K 测试集上mR 分别提升了0.4、1.3 和0.1 个百分点。
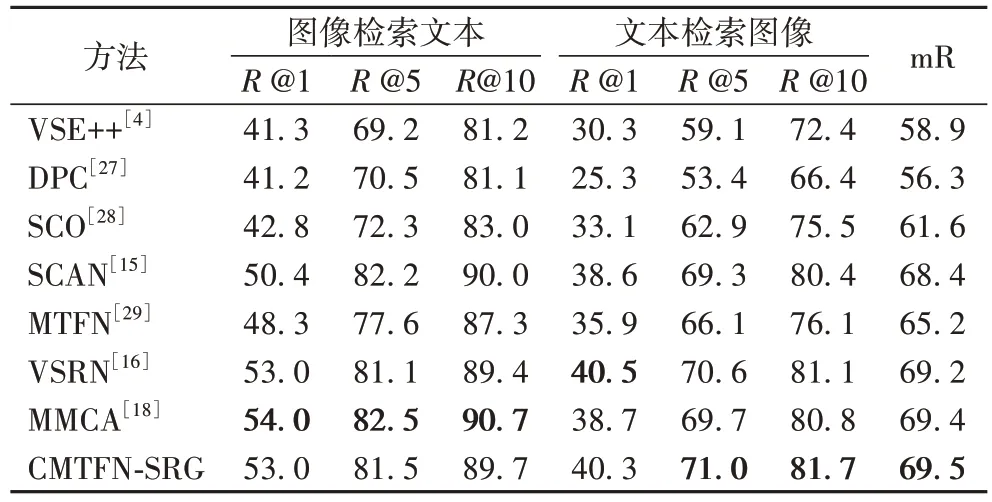
表3 在MS-COCO5K 测试集上的召回率对比结果 单位:%Tab.3 Recall comparison results on MS-COCO5K test set unit:%
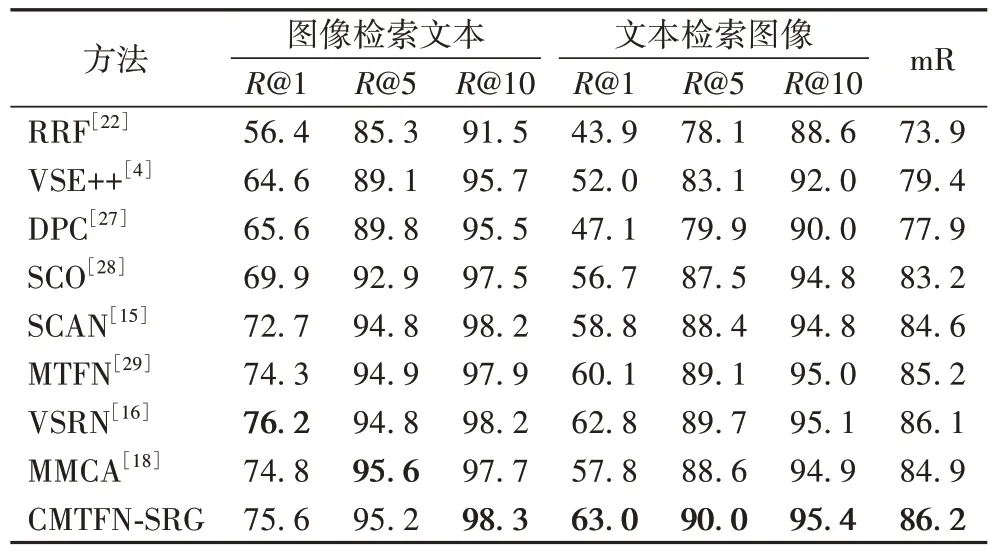
表4 MS-COCO1K测试集上的召回率对比结果 单位:%Tab.4 Recall comparison results on MS-COCO1K test set unit:%
从以上实验结果可以看出,CMTFN-SRG 不仅在小数据集Flickr30K 上性能良好,在大数据集MS-COCO 上也优于大多数相关算法,充分说明了本文所提方法的优越性和可扩展性。
3.4 消融实验
为了验证模态内关系的作用以及张量融合方法的有效性,本文通过一个基线模型逐步验证CMTFN-SRG 中的模态内关系学习模块和张量融合模块的作用。该基线模型不进行张量融合操作并将2.1 节中获取的图像区域特征O={oi|i=1,2,…,n,oi∈Rd}通过平均池化得到图像的最终特征表示,其他设置与CMTFN-SRG 保持一致。实验结果如表5 所示,其中:IR 表示加上了图像模态内关系学习模块;TF表示加上了张量融合模块,TF 前面的数字表示张量融合的数目。基线模型在文本检索任务上的R@1、R@10 分别为64.3%、90.5%,在图像检索任务上的R@1、R@10 分别为49.2%、83.4%。
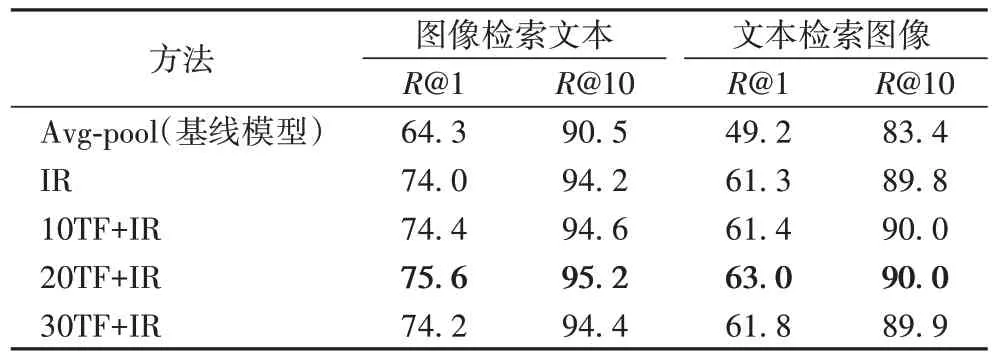
表5 在MS-COCO1K测试集上进行消融实验的结果 单位:%Tab.5 Ablation experimental results on MS-COCO1K test set unit:%
首先在平均池化操作之前加上模态内关系(IR)学习模块(见2.1 节)。从实验结果可以得出模态内关系学习模块能够有效地学习到图像区域之间的关系(模态内对象的关系),从而取得更好的检索结果。然后在模态内关系学习模块的基础上加上张量融合(TF)模块(见2.3 节)并且逐渐增加张量融合的次数。从实验结果中可以发现,张量融合模块能够有效地促进图像数据模态内关联关系以及图像区域特征和文本特征的匹配,进而提高检索精度。
3.5 可视化分析
图5~6 分别显示了图像检索文本和文本检索图像的相似度得分排名前五的可视化结果,其中加框的表示正确的结果。从图5~6 中可以看出,本文所提方法不仅能够有效地学习图像区域间的关系(模态内对象之间的关系),并且能准确地将图像和文本进行匹配(模态间的关系)。
4 结语
本文提出了一种基于语义关系图的跨模态张量融合网络的图像文本检索方法,该方法统一模态内对象之间的关系和模态间的对象关系的关联,结合张量融合网络和全局语义匹配网络,能有效地学习到模态间对象关系的局部语义相关性和全局语义相关性。在两大公开数据集上进行了实验对比分析,实验结果验证了本文所提出方法的有效性。下一步工作将考虑把图像和文本分别在全局语义层、对象关系层以及对象层进行匹配,进而实现更加精细和准确的匹配。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
昆明医科大学学报(2022年3期)2022-04-19
科技信息·学术版(2022年8期)2022-02-25
井冈山大学学报(自然科学版)(2021年4期)2021-10-13
华南师范大学学报(自然科学版)(2021年3期)2021-07-03
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
北华大学学报(自然科学版)(2020年6期)2021-01-05
软件导刊(2018年2期)2018-03-10
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
