
基于层次结构感知的细粒度实体分类方法
2022-11-08 12:42谢斌红李书宁张英俊
计算机应用 2022年10期
谢斌红,李书宁,张英俊
(太原科技大学 计算机科学与技术学院,太原 030024)
0 引言
命名实体识别(Named Entity Recognition,NER)是一种规范的信息抽取任务,旨在从给定的文本中识别出所包含的命名实体并给其分配预定义的语义标签(如person、location和organization 等),在关系抽取[1]、实体链接[2]、问答系统[3]和知识库构建[4]等多种自然语言处理任务中发挥着重要的作用。
随着深度学习的兴起,各种深度学习模型和预训练语言模型被应用到NER 系统,并分别从输入的分布式表示、上下文编码和标签解码三方面提升系统性能。输入的分布式表示主要经历了三个阶段的发展:1)单词级的词向量表示,如Word2vec、GloVe(Global Vectors for word representation)[5]和FastText[6]等;2)字符级的词向量表示,如Peters等[7]提出的字符级语言模型ELMo(Embeddings from Language Models),它能够随着上下文动态生成不同的词嵌入向量;3)单词级和字符级的混合表示,如Devlin等[8]基于混合表示提出了一种语言表示模型BERT(Bidirectional Encoder Representations from Transformers)。上下文编码主要使用卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)和长短期记忆(Long Short-Term Memory,LSTM)网络[9]等作为输入文本的特征提取网络。而标签解码以编码器对文本进行上下文编码后的语义信息为输入,生成与输入序列对应的标记序列,常见的标签解码器有条件随机场(Conditional Random Field,CRF)、多层感知机(Multi-Layer Perceptron,MLP)和Softmax 函数。
NER 任务在理论研究和实验效果上已经较为成熟,但是在实际场景中却凸显出一系列问题,如传统的NER 任务仅能识别粗粒度(如人名、地名、组织机构名等)标签类别,而无法满足更精细类别标签分类的要求,这就需要通过对现有的实体类型体系进行扩充,将命名实体分配到更细粒度标签类别中。细粒度的实体标签将提供更加丰富的语义信息,为关系抽取等下游任务提供帮助,因此,更多的学者将研究方向转向细粒度实体分类。
细粒度实体分类(Fine-Grained Entity Typing,FGET)是在一段已知实体的文本中,结合上下文语境给实体指定一个或多个具有层级结构的实体类型。如在“Yao Ming is an excellent basketball player,playing for the Houston Rockets.”这个句子中“Yao Ming”为实体,根据其所在的上下文为其分配的实体类型为“/person/athlete/basketballer”,然而在传统的命名实体识别任务中,只能将其分类为“/person”类型。在近年来的细粒度实体分类研究中,许多研究人员将研究重点聚焦于更好提取实体和上下文的特征,并在分类时简单将其建模为多标签分类问题,平等对待所有实体类型,而忽略了实体类型所具有的层次结构信息,这样很容易产生模型输出违反标签层级结构的问题。因此,如何在FGET 任务中利用实体类型标签之间的层次结构信息成为了提升模型性能的突破点,也成为了该任务研究的热点。
为了解决上述问题,一些学者开始探索如何将实体类型标签所具有的层次结构信息融合到FGET 任务中,进一步提升模型的分类性能。Ren等[4]认为语义信息更接近的类型往往更相关,为此提出了自适应边界排序损失,让语义相似的实体类型之间有更短的路径,但这种方法只能将语义信息相似的标签进行聚类,而未能充分融合标签的层级信息。Xu等[10]提出了层次损失归一化函数,该函数惩罚了违反实体类型层级的输出,可以使模型在一定程度上融入预定义的实体类型层次结构信息。Lin等[11]为了捕获标签类型之间的相互依赖关系,提出了一个包含类型潜在表示的混合模型,该模型学习预测了一个通过标签空间转换获得的潜在类型特征的低维向量,并从这种潜在表示中重构稀疏和高维类型向量,但该方法没能充分捕获实体类型的语义信息导致不能得到更好的实体特征表示。Chen等[12]提出了利用标签类型层次结构信息的多层级排序学习方法,在给定实体的条件下对候选实体类型进行排序,因为对于类型层次树的每个层级分类难易程度不同,细粒度的实体类型相较于粗粒度的实体类型更难分类,所以该方法提出了一个由粗粒度标签到细粒度标签的解码器,通过对每个层级设置不同的边距参数来适应不同层级的分类,保证模型的输出不违反标签之间的层级关系,从而得到更准确的标签输出。
综上所述,目前的研究工作通过相同语义的标签进行聚类,标签空间转换得到潜在类型特征的低维向量,设置不同层级的分类器等方法来感知标签之间的层级关系,取得了可观的性能表现,但仍没能真正将类型层次信息融合到模型分类学习和推理过程中。为此,本文提出一种基于层次结构感知的细粒度实体分类(Hierarchy-Aware Fine-Grained Entity Typing,HAFGET)方法,该方法首先使用图卷积网络(Graph Convolutional Network,GCN)对实体类型层次结构构建层次结构感知模型,然后分别用实体标签信息和实体信息作为层次结构感知模型的输入,使最终的实体表示具有层次结构信息,为最终的分类提供更好的表示。本文在三个公共数据集验证了所提的层次结构感知细粒度实体分类方法的有效性。
1 HAFGET方法框架
HAFGET 方法的整体框架如图1 所示。HAFGET 方法的整体框架包括三部分:输入层、实体信息编码层和层次结构感知信息融合层。在层次结构感知信息融合层中提出了基于层次结构感知的细粒度实体分类多标签注意力(Hierarchy-Aware Fine-Grained Entity Typing Multi-Label Attention,HAFGET-MLA)模型和基于层次结构感知的细粒度实体分类实体特征传播(Hierarchy-Aware Fine-Grained Entity Typing Mention Feature Propagation,HAFGET-MFP)模型,两种层次结构感知模型以不同的方式对实体和实体上下文特征进行层次结构感知和分类,二者区别在于前者可以融合实体类型特征的信息。
HAFGET 方法的学习过程分为三个步骤:
步骤1 通过预训练语言模型ELMo 获得输入文本对应的词向量。
步骤2 使用不同的方法对生成的文本词向量按实体和实体上、下文三部分分别进行特征提取和融合,获得最终的实体特征表示。
步骤3 使用层次结构感知信息融合层对最终的实体特征进行处理,使其特征融合实体类型及其层次结构信息,该部分分为两种方法:1)将实体表示和通过层次结构编码器编码的标签类型表示运用注意力机制进行特征融合,最后通过标签解码层获取其对应的实体类型;2)将实体的最终实体特征表示输入到层次结构编码器使其最终表示融合实体类型层次结构信息,最后通过标签解码层获取其对应的实体类型。
1.1 输入层
本文使用Peters等[7]提出的动态预训练词向量ELMo 来捕获实体和上下文语义信息并生成词的嵌入向量,由于ELMo 是字符级信息嵌入表示,所以能更好地表示实体和实体的上下文特征。在文本信息编码层中,把句子分成实体和实体上、下文三部分进行编码,其中实体嵌入表示m=(w1,w2,…,wM),实体左边文本嵌入表示cl=(w1,w2,…,wL)和实体右边文本嵌入表示cr=(w1,w2,…,wR),其中wi∈Rdw,M表示实体的长度,L和R分别表示实体左右文本的长度,句子的长度表示为dS=M+L+R。
1.2 实体信息编码层
实体信息编码层包括实体和实体上下文信息的编码,将其对应的特征向量输入到实体信息编码层可得到最终的实体特征表示。
1.2.1 实体表示
由于实体中的每个单词对实体分类结果作用不同,受Lin等[11]的启发,在实体表示上使用注意力机制学习不同单词的重要程度。具体实体嵌入表示m的计算如式(1)所示:
其中:ai是实体中第i个字符对实体表示的注意力权重系数;We∈和va∈Rda是可训练参数,这样相对简单的实体表示可以防止模型过拟合。
1.2.2 实体上下文表示
在实体的上下文表示中,引入了Zhang等[13]提出的实体上下文注意力,将实体向量m作为查询向量,采用Luong等[14]提出的乘法注意力得到实体上下文特征向量c,因为实体左、右上下文的注意力系数计算方式类似,所以只给出了左边上下文注意力系数,具体计算如式(3)~(5)所示:
1.3 层次结构感知信息融合层
实体类型层次结构表征了实体类型之间的依赖关系及整体层次结构,其中实体类型依赖关系用实体类型之间的先验概率表示,层次结构基于语料库预定义。
1.3.1 构建实体类型层次结构
其中:P(va∩vb)是指{va,vb}同时发生的概率;Na、Nb为标签在数据集中出现的次数,并且对于节点va的所有子标签的条件概率之和为1。
图2 是OntoNotes 数据集中部分标签的有向无环图结构,其中从“ROOT”节点到“organization”“location”“person”“other”四个子节点的先验概率和为1,由于上述四个节点的子节点众多,所以第三层仅显示了部分标签。
1.3.2 层次结构信息编码器
图卷积网络(GCN)被广泛用于编码聚合层次结构分类中的节点信息[15],为了充分利用实体类型的层次结构信息,本文使用GCN 作为结构编码器,提出了基于细粒度层次结构的图卷积网络模型,对实体类型标签间的层次关系进行建模。
细粒度层次结构的图卷积网络对上文构建的实体类型层次结构有向图进行编码,得到了编码后细粒度层次结构信息,具体来说,实体类型va的特征是基于相邻节点的特征来编码的,假设节点va相邻节点表示为N(va)={va,child(va),parent(va)},则其特征表示hva计算如式(7)~(9)所示:
1.3.3 实体类型层次结构感知器
在构建好层次结构编码器的基础上,本文采用HAFGET-MLA 模型和HAFGET-MFP 模型来感知实体类型层次结构信息。前者将实体类型的特征向量作为输入,通过层次结构编码器后获得具有实体类型层次结构信息的实体类型特征;后者则是将实体特征作为输入后得到具有实体类型层次结构信息的实体特征。
HAFGET-MLA 模型是在You等[16]的多标签注意力机制基础上提出的,具体是将实体特征与经过层次结构编码器编码的实体类型特征进行融合,融合后的特征Z计算如下:
其中:实体特征S是通过两层前馈网络映射到类型空间S∈RD×dim,使用层次结构编码器的隐藏状态向量作为标签表示。将最终的实体特征Z映射到低维向量后输入到分类器中预测。
HAFGET-MFP 模型受Duvenaud等[17]启发,该模型利用图神经网络获得局部节点的相关性和整体图结构,并在整个层次结构中传播实体特征,使其实体的表示融合实体类型层次结构信息。将实体特征S作为编码器的输入,并通过具有层次结构感知的结构编码器更新实体特征,计算公式如下:
其中:M∈是可训练的权重矩阵;S∈是实体特征的表示;Z∈RN×dim是层次结构编码器的输入。实体经过层次结构编码器编码后得到具有实体类型层级结构特征表示,将编码器的隐藏状态输出h作为分类器的输入,最终得到实体的分类结果。
由于HAFGET-MFP 模型在文本信息上进行了转化,不需要标签嵌入向量的融合,结构编码器在训练和验证过程中更新参数,用于传递跨层次结构文本信息,收敛速度更快,但是相较于HAFGET-MLA 模型有较高的计算复杂度。
1.4 标签分类和损失函数
经过编码得到最终的层次结构感知特征之后,输入到一个全连接层进行实体类型标签预测,模型的损失函数是递归正则损失函数和二元交叉熵损失函数的组合,损失函数计算如式(12)~(14)所示:
其中:Lr是递归正则损失函数;Lq是用于多标签分类的二元交叉熵损失函数;λ是训练过程中可学习的参数;Ti是对应该实体的正确标签是模型输出的标签。在测试阶段,将≥0.5 类型输出,如果预测的所有概率<0.5,则将其中概率最大的标签类型输出。
2 实验与结果分析
2.1 数据集
为了验证模型的有效性和泛化能力,本文遵循Xin等[18]使用以下三个公开数据集对HAFGET 的性能进行评估。数据集中训练集、验证集和测试集的样本分配情况,以及标签数量、标签层数和每一层的标签数如表1 所示。其中L1、L2、L3 分别对应标签第1、2、3 层级的标签数。

表1 数据集统计信息Tab.1 Dataset statistics
1)FIGER 数据集[19]。该数据集于2012 年发布,从Wikipedia 的文章中抽取得到训练数据和验证数据,通过把Wikipedia 的标识符映射到Freebase 中自动生成。FIGER 数据集是一个两层的分类体系,使用113 个类型标注了实体。包含来自维基百科的270 万个自动标注的训练实例和来自新闻报道的434 个人工标注的句子。
2)KNET(dataset)数据集[18]。该数据集是在FIGER 数据集的基础上从Wikipedia 派生的数据集。它由一个运用远程监督自动标注(WIKI-AUTO)的子集和一个人工注释(WIKIMAN)的测试集组成。数据集包含74 种细粒度实体类型,实体类型层级为2 层。
3)OntoNotes 数据集。该细粒度的实体类型数据集来自OntoNotes 语料库,并由Gllick等[20]选择了其中新闻语料作为远程监督细粒度实体分类的数据集,文档共13 109篇,其中77 篇作为测试集由人工标注。数据集包含87 种细粒度实体类型,实体类型层级为3 层。
2.2 评价指标
本文采用了与Lin等[11]相同的评价标准,即通过准确率(Acc)、宏平均F1 值(F1Macro)和微平均F1 值(F1Micro)来评价HAFGET 的性能。对于第i个句子中的实体,模型预测的标签结果为,该实体的真实标签类型为Ti。
准确率(Acc)的计算如式(15)所示:
宏平均F1 值是由宏平均准确率和宏平均召回率计算得到,具体计算分别如式(16)~(18)所示:
微平均F1 值是由微平均准确率和微平均召回率计算得到,具体计算分别如下所示:
2.3 参数设置
本实验中使用的相关参数设置主要根据经验设定,具体的实验参数设置如表2 所示。
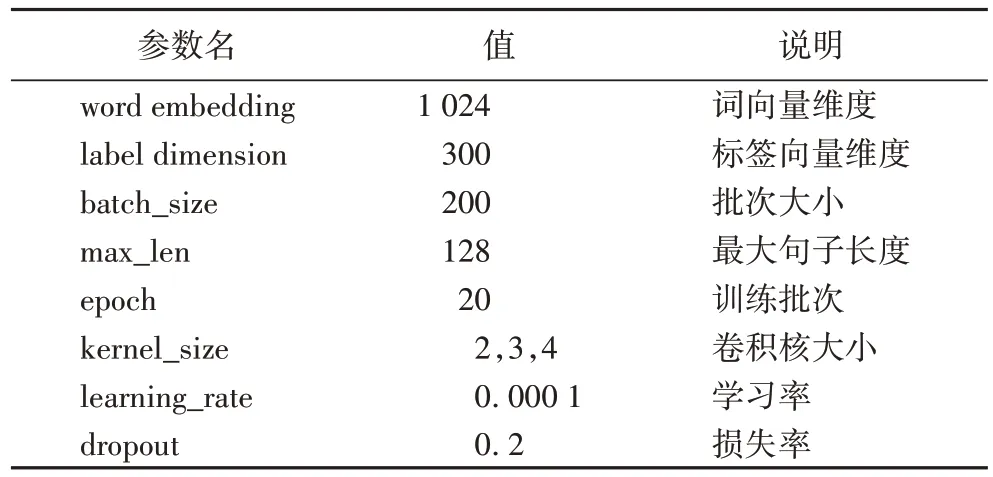
表2 参数设置Tab.2 Parameters setting
2.4 实验结果分析
为了验证HAFGET 在细粒度实体分类任务中的有效性,本文在2.1 节的三个公开数据集上对HAFGET 的性能进行了评估,并与以下几种主流模型进行对比:
1)基于知识注意力机制的神经细粒度实体分类(Knowledge-attention Neural fine-grained Entity Typing,KNET)模型[18]。KNET 模型是将知识库的信息引入特征向量,同时利用了实体注意力(Mention Attention,MA)机制、知识注意力(Knowledge Attention,KA)机制和消除歧义的知识注意力(Knowledge Attention with Disambiguation,KAD)机制来提取实体特征。
2)使用潜在类型表示的细粒度实体分类模型[11]。该模型首先预测一个低维向量,并通过潜在标签空间对其转换获得潜在类型特征,然后利用从该特征表示中重构的稀疏高维类型向量对实体类型进行预测。
3)基于多级学习排序的层次实体分类模型[12]。该模型多级标签排序学习给定了实体的候选实体类型,并且保证预测不违反层次结构属性。还提出了exclusive 和undefined 两种实体类型标注方法:exclusive 表示数据集预定义的层次结构中不包含其实体类型(修改数据集的标签,每个根节点下后添加一个“/other”节点表示不属于其类型);undefined 表示不修改数据集的预定义层次结构。
表3~4 是在KNET(dataset)数据集的不同测试集上的实验对比结果,WIKI-MAN 是人工标注的测试集,与WIKIAUTO 自动标注的测试集相比,其实体标签的标注粒度更细,模型预测难度更大。从实验结果可以看到,本文提出的MLA 模型和MFP 模型在F1Macro和F1Micro上均高于对比模型,特别地,在WIKI-AUTO 数据集上与文献[11]模型相比,MLA、MFP 模型的准确率分别提高了2.9、2.4 个百分点。此外,在WIKI-AUTO 数据集上,MLA 模型比MFP 模型在准确率指标上提升了0.5 个百分点。由此可知,实体类型标签信息的融合丰富了模型的分布式表示,通过图卷积网络对实体类型的层级关系进行建模,充分利用实体类型之间的相互依赖,可以帮助模型更好地对实体进行细粒度标签的分类。
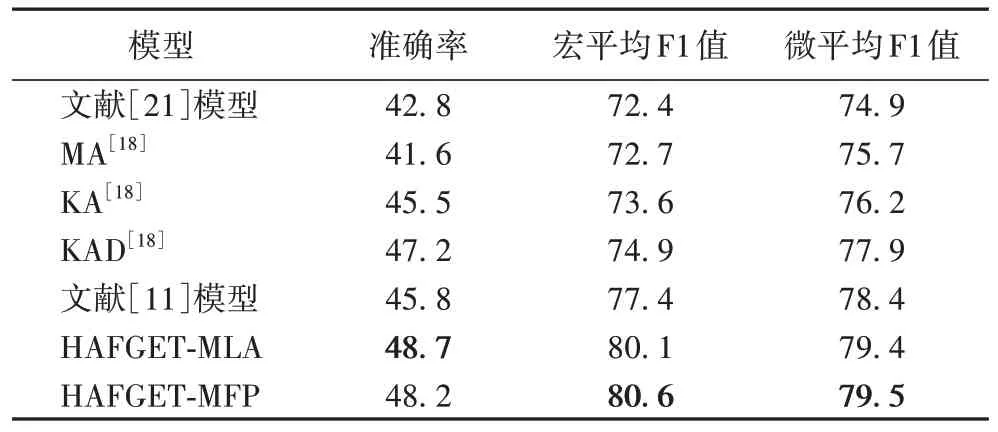
表3 WIKI-AUTO数据集上的实验结果 单位:%Tab.3 Experimental results on WIKI-AUTO dataset unit:%
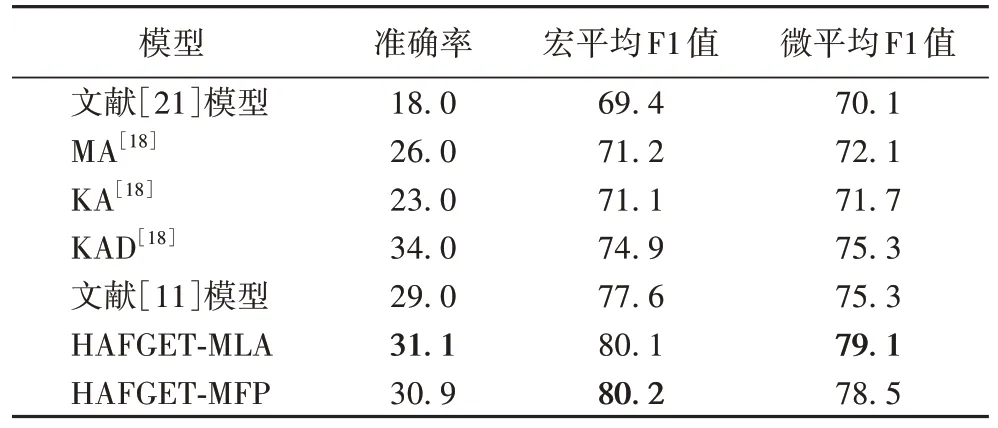
表4 WIKI-MAN数据集上的实验结果 单位:%Tab.4 Experimental results on WIKI-MAN dataset unit:%
表5 是在OntoNotes 数据集上的实验结果,其中,文献[11]模型的实验结果明显高于本文模型,这是因为文献[11]中所使用的训练集数量是本文所用训练集的10倍,随着训练数据量越大,模型性能通常也会越好。由于文献[11]未公开处理数据集,所以本文的测试结果不能与其进行公平对比。除文献[11]模型之外,本文模型在3 个评价指标上均达到了最优性能,与基于多级学习排序的层次实体分类模型[12]相比,MLA 模型的F1Macro最少提升了8.3 个百分点。OntoNotes 数据集相较于KNET(dataset)数据集,其实体类型和层次结构更多,在这种复杂场景下,本文模型仍能对实体准确分类,展现出较好的性能。
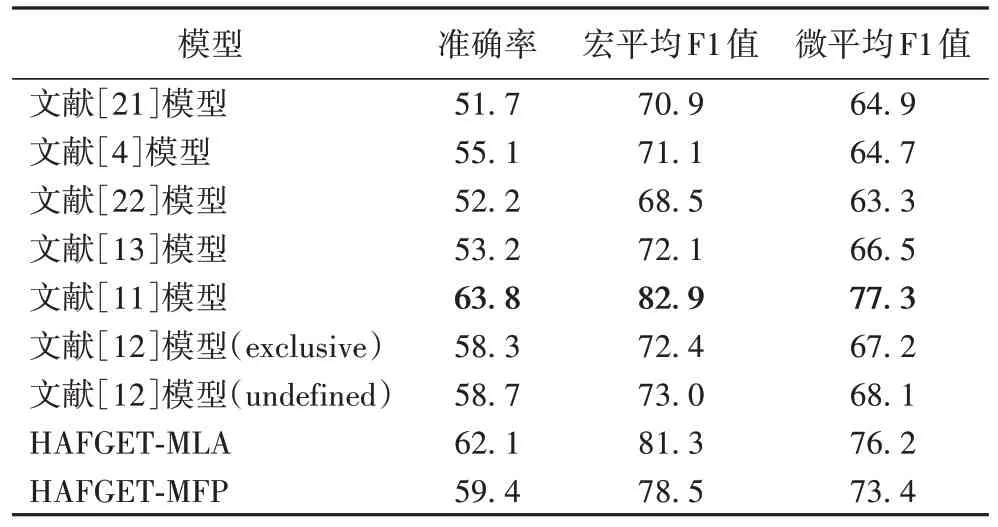
表5 OntoNotes数据集上的实验结果 单位:%Tab.5 Experimental results on OntoNotes dataset unit:%
在FIGER 数据集的测试结果如表6 所示,MLA 模型在3个指标上均优于文献[11]模型;与文献[12]模型(exclusive)、文献[12]模型(undefined)相比,MLA 模型的F1Macro值提升了至少3.6 个百分点;但是文献[12]模型(exclusive)的准确率最高,这是因为该模型改变了数据集标签层次结构,在每一个子树上都添加了“/Other”节点,每个未分类的实体都会给定一个“/Other”节点,因而其准确率最高。相较于KNET(dataset)数据集和OntoNotes 数据集,本文模型在FIGER 数据集上实现了最好的性能表现,Acc、F1Macro和F1Micro最高分别达到了66.9%、86.2%和82.2%。FIGER 数据集训练数据量较大,实体类型多达113种,这说明随着训练数据量的增加,本文模型有潜力准确分类出更多更细粒度的实体类型。
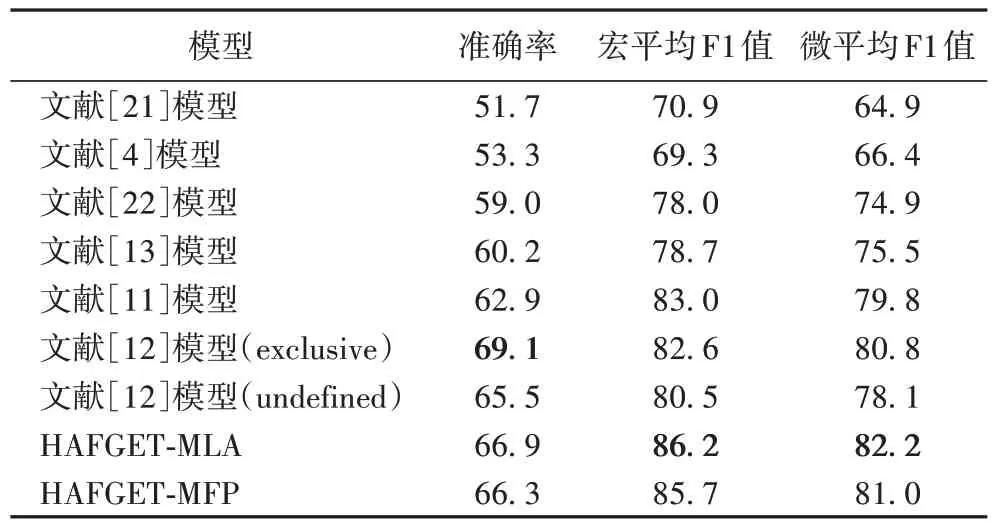
表6 FIGER数据集上的实验结果 单位:%Tab.6 Experimental results on FIGER dataset unit:%
此外,本文将文献[11]模型作为基线模型(baseline),在WIKI-AUTO 数据集上对本文提出的基于层次结构感知的多标签注意力模型(HAFGET-MLA)进行了消融实验,以详细考察HAFGET-MLA 中各个模块组件对整体性能的贡献,实验结果如表7 所示。通过分析可以得出结论,添加到模型中的每个关键组件都对模型性能的提高做出了积极贡献。其中,添加层次结构感知的注意力模块使准确率提升了2.9 个百分点,对模型性能影响最大,说明附加类型标签之间的层级结构信息作为先验知识,对分类标签起到一定的约束作用;同时通过注意力机制将其与实体特征融合,进一步丰富了实体表示,因而提高了性能;同样地,使用GCN 编码学习标签之间的层级关系并增加先验概率都对模型起到了积极作用。
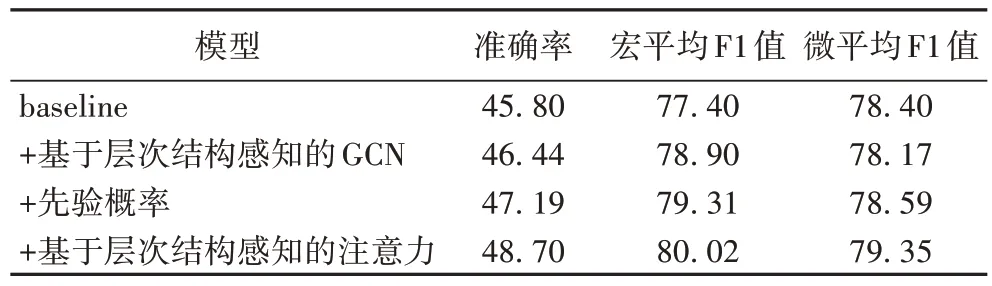
表7 在WIKI-AUTO数据集上的消融实验结果 单位:%Tab.7 Ablation experimental results on WIKI-AUTO dataset unit:%
最后,为了更直观地证明添加注意力模块的有效性,对添加注意力后的实体(表8)特征做了可视化表示,实体特征和实体类型特征融合后的注意力权重热力图如图3 所示。图3 中的左纵轴S1~S6 表示6 条输入句子中的实体,对应句子中的实体(表8 中加粗标识)和标签,右纵轴表示句子中的实体与每个标签的语义相似度,颜色越深表示与该标签的相似度越大。从图3 中可以看到,在融合实体类型层级结构后能加强实体正确标签的表示,为其分配更高的权重并成功预测出了句子中实体的正确类型。

表8 句子及所对应的标签Tab.8 Sentences and corresponding labels
3 结语
本文提出了一种基于层次结构感知的细粒度实体分类模型HAFGET,将预定义实体类型层次结构和先验概率先验层知识作为图卷积网络层次结构编码器的输入,通过感知层次信息与实体特征的融合提升了实体分类性能,并在多个数据集上对模型的性能进行了评估。实验结果验证了该模型在细粒度实体分类任务中的有效性,表明了充分利用标签本身所具有的层级结构信息对细粒度实体分类的性能提升有很大帮助,但是对于标签层次不明确的数据集上性能提升比较小,说明标签层次划分的好坏对实验结果有较大影响。接下来的研究工作期望基于数据集的降噪和标签层次结构的分类,更好地提升细粒度实体分类模型的性能。
猜你喜欢
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
软件导刊(2018年2期)2018-03-10
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
科技资讯(2017年7期)2017-05-06
科技创新与应用(2017年3期)2017-02-18
电脑知识与技术(2016年25期)2016-11-16
无线互联科技(2015年11期)2016-03-04
Coco薇(2015年11期)2015-11-09
