
基于数据增强和弱监督对抗训练的中文事件检测
2022-11-08 12:42罗萍丁玲杨雪向阳
计算机应用 2022年10期
罗萍,丁玲,杨雪,向阳*
(1.同济大学 电子与信息工程学院,上海 201804;2.软通动力信息技术(集团)有限公司,河北 廊坊 065000)
0 引言
事件检测任务的目标是将文本中提及的事件触发词抽取出来并将其分类到预先定义的事件类型[1]。具体而言,触发词通常指代能激发某一事件的词或者短语。例如,“普京15 号在文莱斯里巴加湾会见美国总统克林顿”这句话中,触发词“会见”触发了“Contact-Meet”这一事件。作为事件抽取的一个重要子任务,事件检测为智能问答[2]、信息检索[3]、阅读理解[4]等其他下游自然语言处理(Natural Language Processing,NLP)应用奠定了坚实的基础。鉴于其重要性,许多学者都致力于为这项极具挑战性的任务作出贡献。
事件检测任务的研究方法大致包括基于特征工程的方法和基于神经网络的方法。早在深度学习时代,学者们就尝试使用token 级特征[5-6]和结构化特征[7-8]来解决事件检测任务。近年来,随着神经网络在其他研究领域的快速发展,将上下文语义信息嵌入低维空间并将事件检测视为逐词分类任务的神经网络方法取得了重大进展[9-10]。尤其是随着预训练语言模型的发展,BERT(Bidirectional Encoder Representation from Transformers)已被广泛用于事件抽取任务[11-12]。
尽管上述完全监督的事件检测方法取得了很大的进步,但有限的数据规模仍然阻碍它们实现更高的性能[13]。此外,完全监督的深度学习模型通常深受过拟合问题[14]的困扰,因此无法将它们应用于新的任务场景或现实世界情况。为了克服这些缺陷,本文提出了一种新的基于数据增强的弱监督对抗训练方法,即基于BERT 的混合文本对抗训练(BERT based Mix-text ADversarial training,BMAD)方法。首先,采用回译[15]的传统数据增强方法从原始数据构建真实无标注数据,并在半监督场景下训练事件检测模型。接下来,聚焦于新型数据增强方式Mix-Text 来创建虚拟训练数据和标签,旨在通过训练这些生成的不准确数据和带噪学习来提高模型的泛化能力并尽量避免过拟合。最后,设计了一种基于Mix-Text 的对抗训练策略来增强模型的鲁棒性。简而言之:一方面训练生成器,使其更好地生成假样本来欺骗判别器;另一方面,训练判别器以更好地判别给定实例是否是虚假样例。
本文的主要工作如下:
1)提出了一种名为BMAD 的事件检测方法,它可以创建弱监督学习场景以解决数据稀缺的问题;
2)设计了一种基于Mix-Text 的对抗训练策略,旨在抵抗噪声以增强模型的鲁棒性并提高事件检测任务模型的性能。
1 相关工作
1.1 事件检测
事件检测作为一项具有挑战性的任务一直受到学者们的广泛关注。该任务的传统方法[16-21]严重依赖于人工设计的特征,可以在特定领域实现高性能,但在迁移到不同语言或标注标准发生改变时则表现不佳。
近年来,能够自动提取高层特征的深度学习方法取得了重大进展。Chen等[22]首次提出了一种基于动态多池卷积神经网络的事件检测方法来建模触发词和论元角色之间的依赖关系。Nguyen等[23]提出了一种基于循环神经网络的联合事件提取方法。Liu等[24]提出通过有监督注意机制在事件检测中编码论元信息的方法。Liu等[25]提出了触发词检测动态记忆网络来使用上下文信息以解决事件检测问题。Yan等[26]使用了基于依赖树的聚合注意力图卷积网络模型对事件检测任务进行建模。Wang等[27]提出了一种新颖的多层残差和基于门控的卷积神经网络框架,通过扩展感受野以获得多尺度上下文信息。
1.2 弱监督学习
鉴于完全监督方法受人工标注数据限制的缺陷,各种弱监督方法应运而生。Chen等[28]使用为每个事件类型检测关键论元角色和触发词的远程监督方法自动标记文本中的事件。Araki等[29]提出了一种远程监督方法,该方法能够不受任何特定数据集的限制生成高质量的训练数据。Zeng等[30]使用现有的结构化知识库或表格从无标注的文本中自动创建事件注释来扩充事件抽取训练实例,最终实现了远程监督学习。Huang等[31]设计了一个半监督向量量化变分自动编码器框架,以自动学习每个可见和不可见类型的离散潜在类型表示,并且使用可见类型事件注释对其进行优化。Shao等[32]通过最大化问答对和预测解决方案之间的互信息来明确利用问题与其解决方案之间的语义相关性,从而避免弱监督问答的伪解问题。
1.3 对抗训练
对抗学习[33]率先在计算机视觉领域取得了巨大的成功。最近,许多工作都尝试将对抗性学习应用于事件检测任务。Hong等[34]提出了一种使用生成对抗网络生成虚假特征的自调节学习方法。Wang等[35]构建了一个具有良好覆盖率的大型事件相关候选集,然后应用对抗性训练机制从候选集中不断迭代以识别那些富含信息的实例并且过滤掉那些含噪实例。Ma等[36]使用对抗训练进行无数据蒸馏,并最终将蒸馏模型应用于文本分类任务。
2 模型方法
本文提出的BMAD 的整体框架如图1 所示。它由四个模块组成,包括实例编码器模块、半监督模块、混合文本模块和对抗训练模块。首先,对于每个实例,编码器将每个目标token 编码为上下文相关的词嵌入。然后,使用半监督方法来训练有标注和无标注的数据。之后,应用基于BERT 的Mix-Text 方法进一步增强数据,以提高模型的泛化性能。最后,使用对抗训练策略,在指导生成器生成与真实样例相似的实例的同时促使鉴别器学会区分真假实例。
2.1 实例编码器模块
预训练语言模型已经被广泛证明能够为下游模型提供有用的特征。在本文中,使用基于Transformer 的BERT 模型[37]以获取词嵌入作为网络的输入特征,该模型在各种NLP任务中均取得了最先进的性能。
给定包含N个token 的句子(t1,t2,…,tN),BERT 采用多层双向Transformer 编码器,通过输入词、段和位置嵌入来获得隐藏层嵌入表示。其过程如下,
紧接着隐藏层词嵌入将会被输入到Transformer 模块中以获得最终的词表示X=[x1,x2,…,xN]。
2.2 半监督模块
本文中事件检测问题被视为一个跨度提取任务,即给定一段文本,将每一个触发词视为一个片段从该文本中提取出来。受Yu等[38]的启发,针对每一个事件类型,采用两个独立的前馈神经网络(FeedForward Neural Network,FFNN)作为分类器来分别预测一个候选触发词的开始token 和结束token。对应于每个token 和每个事件类型,通过式(2)~(3)计算它是一个触发器词的开始和结束的概率:
其中:FFNN 表示前馈神经网络。针对特定事件类型,p为所有token 提供成为开始token 或者结束token 的分数,是一个l×2 大小的张量。其中l是句子的长度,最后一个维度指示该token 是否是一个候选触发词的开始/结束。具体来说,ps提供每个token 的开始分数,pe提供结束分数。基于此,为每个事件类别的每个token 分配一个真或假类别y':
对于有标注数据,y表示一个token 的真实标签,p表示它是一个特定类别候选触发词的开始或结束的概率。使用焦点损失函数来改善类不平衡问题并计算监督损失如下:
对于无标注数据,在训练之前,首先固定模型参数并使用当前模型为它们的token 预测每一类别的起始概率,得到的分布q视为标签。然后在训练期间,使用相同的步骤得到另一个预测分布r。最后,将计算这两个分布之间的相对熵KLD(Kullback-Leibler Divergence)作为无监督损失,其计算公式如下:
2.3 混合文本模块
TMix 是Chen等[39]提出的一种新型文本分类半监督学习方法。它接收两个真实的文本样本作为输入,并在BERT 模型的隐藏层中混合它们,然后继续前向传递以预测混合样本的混合标签。
众所周知,事件检测任务比文本分类任务复杂得多,因为它在单一句子中存在多个相互关联的标签。直接使用TMix 可能会给模型注入过多的噪声,阻碍模型收敛。考虑到这一点,使用了Chen等[40]提出的另一种针对序列标注任务的改进方法Mix-Text 来缓解噪声问题。
本文使用的文本混合策略可分为两种情形,样本内混合及样本间混合。对于样本内混合情况,从单一样本重构xintra。具体来说,使用来自同一语句的相同token,但更改其顺序并通过以下方式在它们之间执行插值:
其中:l是服从Beta 分布的参数,用于对每个批次的数据进行插值;xi和xj是来自同一个句子的不同token。
对于样本间混合情况,使用两个不同的句子来构造。首先,随机采样一个句子x,然后从被采样句子的K最近邻(KNearest Neighbor,KNN)句子集中选取另一个句子x'。xinter由以下方式构造:
最终使用当前模型为无标注的重构语句预测它们的概率分布p并分别计算上述两种情形的损失:
其中:M是构造混合文本的空间分布;x为使用式(7)、(9)构造的混合文本实例;yx为其对应的构造标签;px为2.2 节中使用FFNN 计算得到的概率。
2.4 对抗训练模块
在对抗训练模块中,基于上述Mix-Text 方法设计了对抗策略。对抗训练模块由一个判别器和一个生成器组成,生成器用来产生尽可能真实的假实例,与此同时判别器用于区分真假实例,而训练过程则是一个二者之间的对抗性最小-最大博弈游戏。
生成器基于真实实例使用混合文本方法创建样本内混合实例和样本间混合实例,并假设其均为真实实例。为了帮助生成器更好地愚弄判别器,还使用了一个选择器为来自FFNNs(FFNN start)/FFNNe(FFNN end)的每个开始/结束概率计算置信度分数,之后置信度分数将被用于筛选生成实例,以此提高对抗训练的稳定性。在生成器训练期间,生成器将根据不可靠实例的置信度分数最小化损失,这意味着置信度分数较高的实例在计算损失时会被赋予较大的权重。为了达成该目标,构造了如下损失函数以优化生成器:
其中:U是经过BERT 隐藏层混合后的不可靠采样实例的数据分布;c表示选择器计算的置信度分数;p表示FFNN 计算的概率。
反之对于生成器创建的实例,判别器则会假设它们为假实例,并尝试最大化所选不可靠实例的损失,为优化判别器构造的损失函数如下所示:
经过充分的训练,生成器和判别器最终将达到平衡。生成器倾向于创建类似于真实样例的实例,同时判别器则可以更好地区分真假实例。
最终,BMAD 方法的损失函数定义如下:
其中:λ是一个超参数,权重随着训练进行不断增大。而Lossadv则根据训练阶段变化,在生成器优化阶段为Lossadv-g,在判别器优化阶段为Lossadv-d。
3 实验与结果分析
3.1 数据集和评估指标
在本文中,在自动文档抽取(Automatic Context Extraction,ACE)数据集ACE2005 上进行了一系列实验,其中共包含633 篇中文文档。参照之前相关工作的数据划分,分别使用569/64 个文档作为训练/测试集。在此基础之上,对于训练数据集,还使用了5 折交叉验证来减小方差并提高模型的泛化能力。
针对一个选定的触发词,当且仅当其事件子类型和偏移量与目标触发词的事件子类型和偏移量均匹配时才是正确的。最终,使用精确率(Precision,P)、召回率(Recall,R)和F1 分数作为评价指标。
3.2 基线模型
本文与以下先进模型进行了比较:
1)HNN(Hybrid Neural Network)模型[41]。该模型结合了双向LSTM(Long Short-Term Memory)和卷积神经网络来学习句子中每个token 的连续表示,并使用拼接后的特征来识别触发候选词并将每个触发候选词分类为特定的事件类型。
2)NPN(Nugget Proposal Network)模型[42]。该模型首先使用token 级神经网络从字符级和单词级表示中学习混合表示,然后使用事件类型分类器来分配事件子类型。
3)TLNN(Trigger-aware Lattice Neural Network)模型[43]。该模型动态地结合了单词和字符信息,并使用外部知识库HowNet 来提高其性能。
4)HCBNN(Hybrid-Character-Based Neural Network)模型[44]。该模型提出通过将单词信息和语言模型表示结合到汉字表示中来改进逐字模型。
3.3 整体结果
本文方法的整体结果如表1 所示。从表1 中可以看到,BMAD 的F1 分数最高,其表现明显优于其他对比基线模型。与其他模型相比,BMAD 在ACE2005 数据集的触发词分类任务上F1 分数提升了至少0.84 个百分点。这表明所提方法可以提高模型的泛化能力,并在一定程度上缓解过拟合问题。
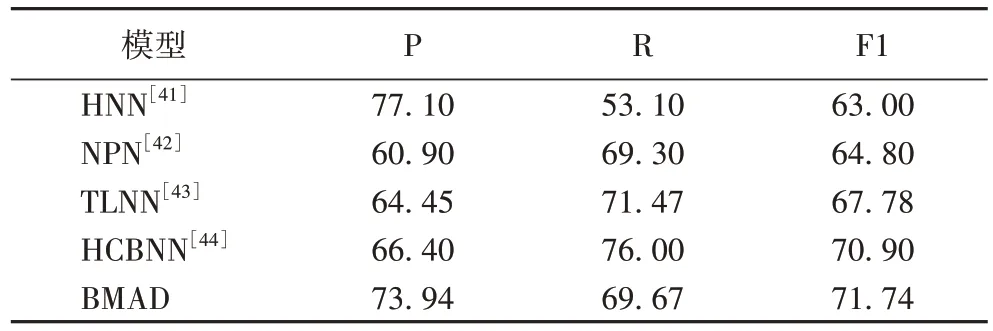
表1 ACE2005上触发词分类任务上的实验结果 单位:%Tab.1 Experimental results on trigger classification task on ACE2005 unit:%
除此之外,更加值得注意的是,虽然HNN 的精确率最高,但其召回率却最低,而BMAD 模型在较少牺牲召回率的情况下使精确率有了很大的提升,这意味着该模型在区分负样本时表现良好。也就是说,模型在作出新的预测时预测正确的概率更高。
3.4 消融实验
为了更好地反映模型中每个模块的贡献,进行了消融实验(见表2)。在实验中使用的基线模型Baseline 是BERT+FFNN+Focal-loss。
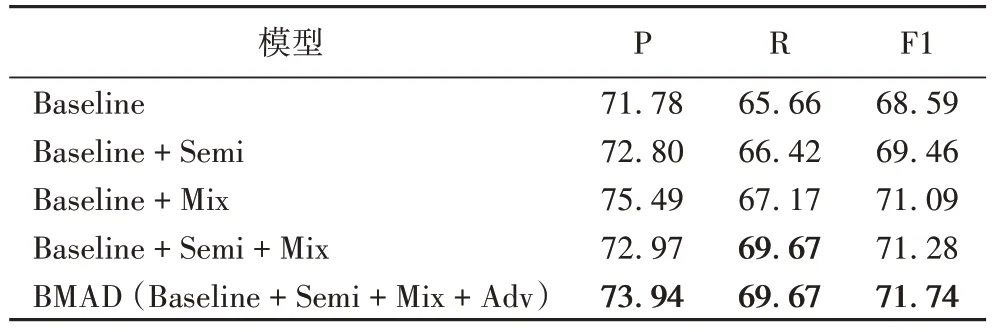
表2 消融实验结果 单位:%Tab.2 Ablation experimental results unit:%
对于半监督模块(Semi),针对回译方法,爬取谷歌翻译网页到本地并使用在线翻译器将中文语料库逐条翻译成英文语料,然后将它们翻译回来以形成无标注数据。为半监督损失设置的权重是0.01。值得注意的是,模型在训练初期的预测性能很差,过早使用半监督损失反而会增加噪声。为了避免这个问题,在F1 分数达到0.6 后再使用半监督损失来进行反向传播和优化,因为此时模型已经基本具备了预测能力。
对于混合文本模块(Mix),使用KNN 为一个特定实例生成一系列最相似的实例。BERT 的混合层参数和K的大小分别设置为8 和20。
从实验结果中,可以观察到模型可以从无标注的数据和不准确的数据中学习,并且与此同时,对抗训练的方法还可以缓解弱监督场景下的噪声问题。
4 结语
本文将事件检测任务重构成一个跨度提取任务,并采取了一种先进新颖的方法处理弱监督场景下的事件检测任务。首先,使用回译和Mix-Text 的方法进行了数据增强,旨在为弱监督学习场景构造数据;接着,为了训练模型,进一步使用了半监督学习与对抗训练策略相结合的弱监督方法进行训练。在广泛使用的ACE2005 数据集上评估了所提方法,结果表明所提方法达到了当前最优性能。未来计划将所提方法扩展到论元角色抽取(事件提取的第二阶段)以及联合事件抽取任务。
猜你喜欢
云南教育·小学教师(2022年4期)2022-05-17
人大建设(2020年4期)2020-09-21
甘肃教育(2020年8期)2020-06-11
艺术评论(2020年3期)2020-02-06
人大建设(2017年2期)2017-07-21
人大建设(2017年9期)2017-02-03
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
浙江人大(2014年4期)2014-03-20
克拉玛依学刊(2013年5期)2013-03-11
