
藏文图像文本识别在安卓系统中的应用
——基于混合注意力机制神经网络模型
2021-03-17 03:33王悦凝华却才让才让当知环科尤
青海师范大学学报(自然科学版) 2021年4期
王悦凝,华却才让,2*,才让当知,环科尤
(1.青海师范大学 计算机学院,青海 西宁 810008;2.青海师范大学 藏文信息处理教育部重点实验室,青海 西宁 810008)
1 引言
文本识别是人工智能领域一个重要的分支,是模式识别应用中最重要的技术,在光学字符文字识别中,最古老、最复杂的技术之一是识别印刷体文本,Youngmin Baek[1]等人通过注意力机制精准定位文本,并完成端到端的字符识别.藏文图像文本识别是藏文智能信息处理研究领域重点研究的课题之一,相比较于中英文的文本识别,藏文文本识别的起步略晚,由此,许多研究者开始对藏文的文字进行研究以解决藏文的文字识别问题.如今藏文文本识别技术也逐渐成熟,卷积神经网络成为研究藏文文本识别的典型技术之一,当前流行的卷积神经网络模型有LeNet[2-3]、AlexNet、Res Net、VGG[4]等模型,为了提高模型精准度引入注意力机制的概念,可以将其融入到网络中的任一位置,该思想已经在针对藏文图像分类、印刷体藏文文本识别、语音识别、机器翻译等研究领域都有广泛的实际应用 .
藏文的字形结构多变,字体工整优美,字体以基字为核心,其余字母围绕基字上下左右叠加字母,最后组成完整的字体,由于字体结构较为复杂,字体的粘连性通过分割方可识别.目前Android市场中含有藏文的文本图像识别系统只有十款左右[5],较突出的软件如:汉王OCR文字识别软件,该识别软件支持识别多种字体,识别率达到85%,亟需丰富安卓市场资源并提高识别率.虽然Android已经成为目前的主流操作系统,但含有藏文文本识别功能的工具较少,所以选用Android作为开发平台[6],鉴于此,本文提出了基于CBAM-LeNet-5模型的Android藏文图像文本识别系统.
2 预处理技术
二值化处理后的文本图像会呈现清晰的轮廓,其思想是将图像设置一个阈值,如果该图像中的像素点大于所设定的阈值则为255,相反小于设定阈值则为0,公式为:
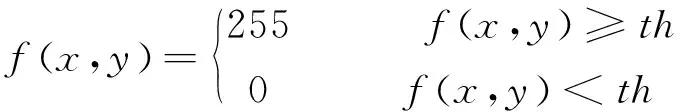
(1)
实现二值化的方法有全局阈值分割、OSTU阈值二值化[7]、迭代等方法.本文采用OSTU二值化方法,其主要思想是按照特征设置一个初始阈值,根据阈值将其分为前景与背景.通过电子设备拍摄一张藏文文本图像如图1所示.首先,假定一个灰度值将图像分成大于阈值和小于阈值的两个部分,即前景与背景两个部分,其次利用求出的前景、背景的两个占比再求出对应的平均值,通过阈值的循环轮值最后计算出两部分之间的类间方差,找到类间方差最大的值,则为理想阈值,如图1所示.

(a)文本图像原图 (b)二值化后文本图像结果图1 藏文文本图像二值化效果对比
获取文档的时候会因人为因素导致文档图像的倾斜,导致字符出现不同角度的旋转或位置的偏移,图像发生位置变化严重时会影响文本切分,特别是在识别过程中影响对藏文字符基线特征的定位,常见的图像矫正方法有霍夫变换矫正算法、透视变换和旋转矫正等.
霍夫变换主要是通过寻找最大的参数叠点对应的角度进行图像变换的位置矫正,找到可能存在的直线,该算法主要思想利用y=kx+b方程的参数空间和变量空间的对应关系,其中k、x分别代表斜率和截距,(k,x)为变量空间中的已知量,(k,b)在参数空间中作为变量坐标.直线y=k1x+b1在参数空间映射的点为(k1,b1),参数空间直线y=k1x+b1在变量空间映射的点为(x1,y1),过变量(x,y)有无数直线与参数空间点对应.
图像校正后通过藏文图像文本分割得到字丁.首先使用水平投影法确定文本行位置,其主要思想是在图像中的多行文本中,沿着纵轴方向取直线,统计穿过该直线的文字像素累加后的数值,通过二值化后的图像背景区域为黑色,含有文字区域像素值为1,空白区域为0,扫描并统计每行带有黑色像素值.对于多行文本,见图2(a),再利用投影法对其进行文本行切分,基于投影法的水平投影的轮廓可视化,如图2(b)所示.

(a)原图

(b)水平投影图2 行分割效果
藏文字丁的结构包括:元音、上加字、基字、下加字,藏文字符的书写规则是保证基字必须存在,其余结构可与基字自由组合.藏文字丁在分割时有一些难点:①上加字和基字两个字符或者元音与上加字两个字符会产生粘连性.②藏文音节字符整体过大影响字丁分割.通常采用投影法进行分割,通过垂直投影法[8]计算文本图像中单个字符宽度值,解决切分字符问题,其基本思想为在图像中的每一行文本横轴取直线.本文针对藏文字丁字符研究,找准藏文字丁基线,以藏文字丁为切分单位,基于垂直投影进行列分割从而计算出每个字符的宽度,统计垂直于该直线的图像上文字像素累加和数值.
图3是以字丁为分割单位的投影分割效果图,首先对藏文文本进行行分割,再进行字丁按列分割,由图3可见,分割错误的类型主要有三种;①有元音的字丁.例如:、、以及等.②有下加字的字丁,例如:、和. ③元音和下加字同时存在,例如:、和.这三种分割错误的主要原因是元音和下加字的笔画宽度大于基字,部分笔画延伸到了前后字符区域.投影分割法按列遍历像素起始位置时,元音像素区域和前后的文字像素区域有相交,被误判为一个字符区域,因此分割错误.

图3 投影法分割效果
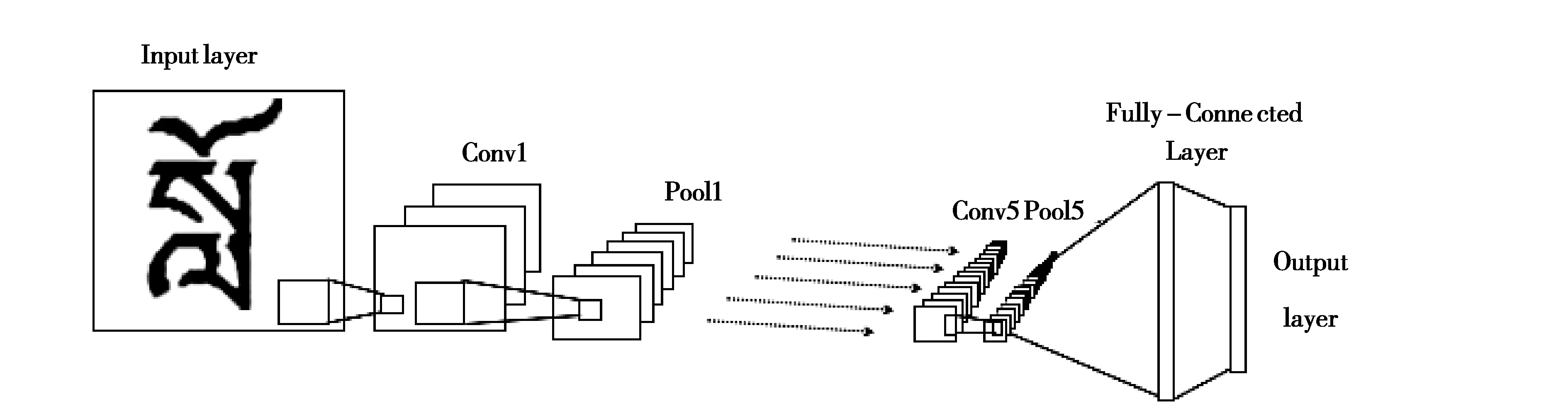
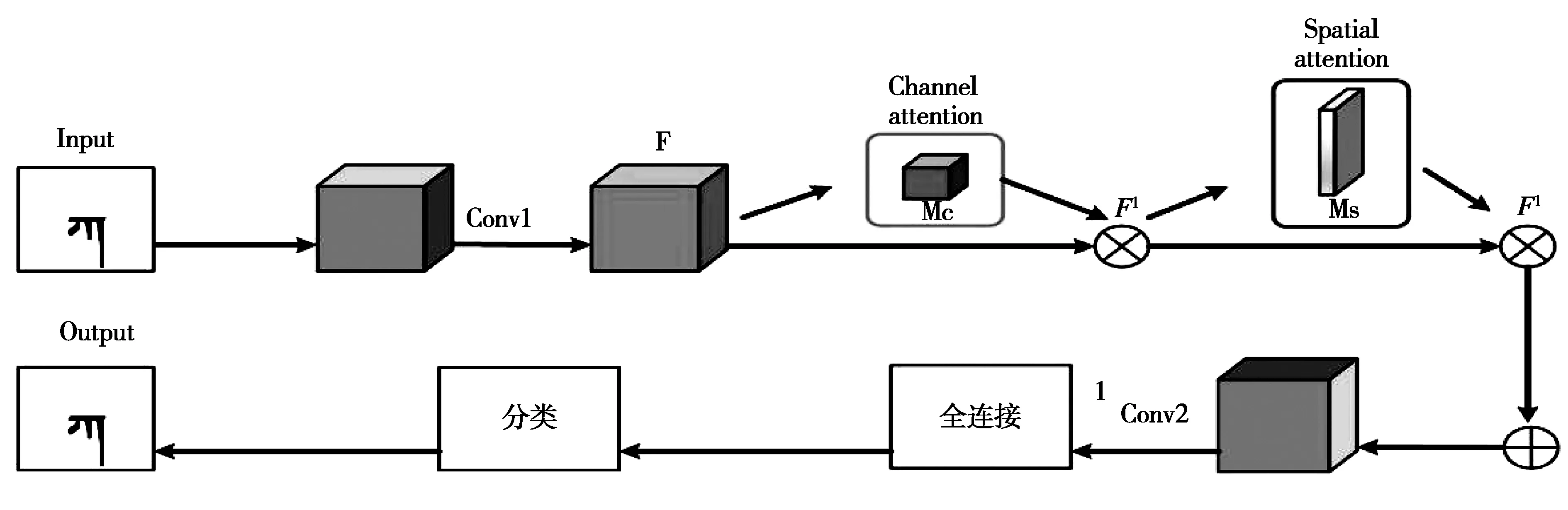
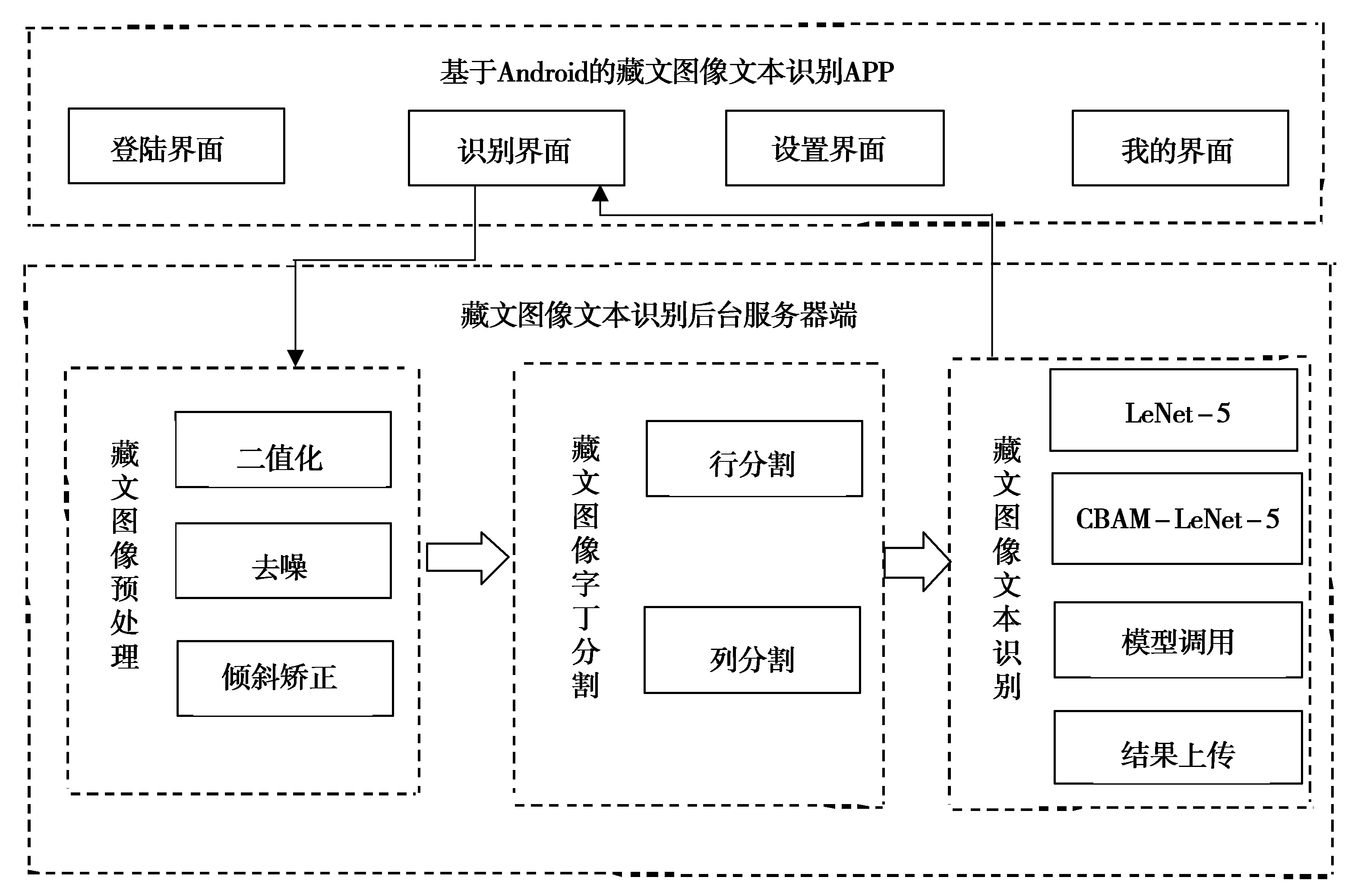
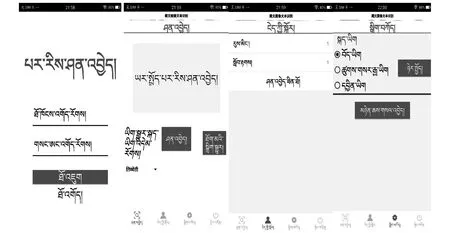
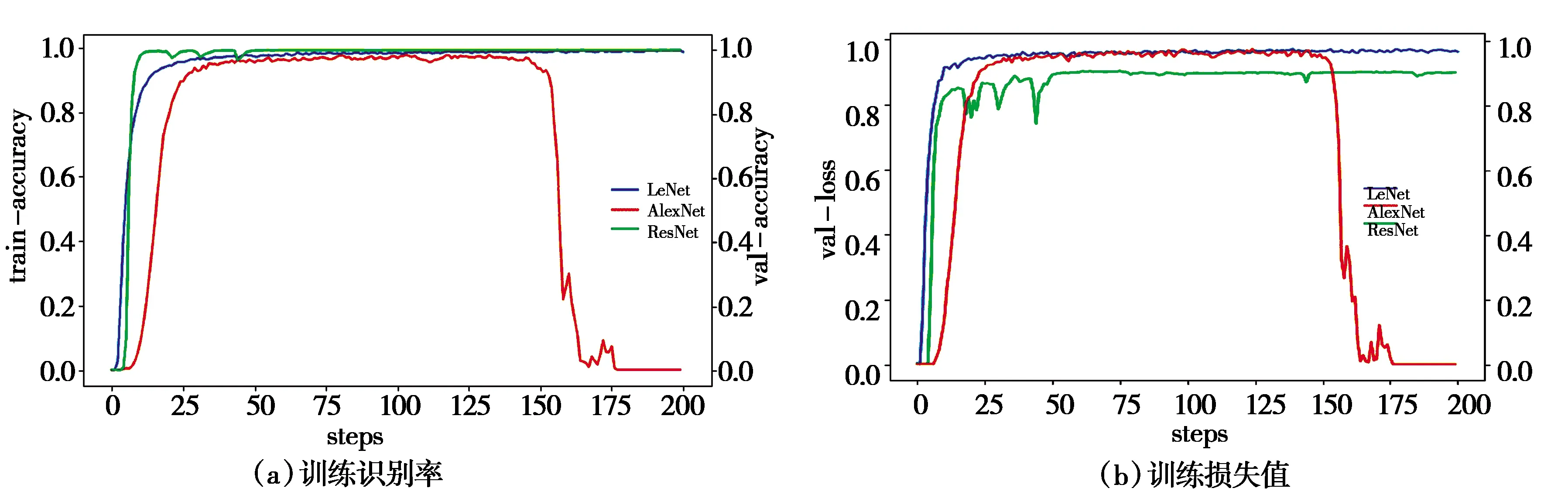
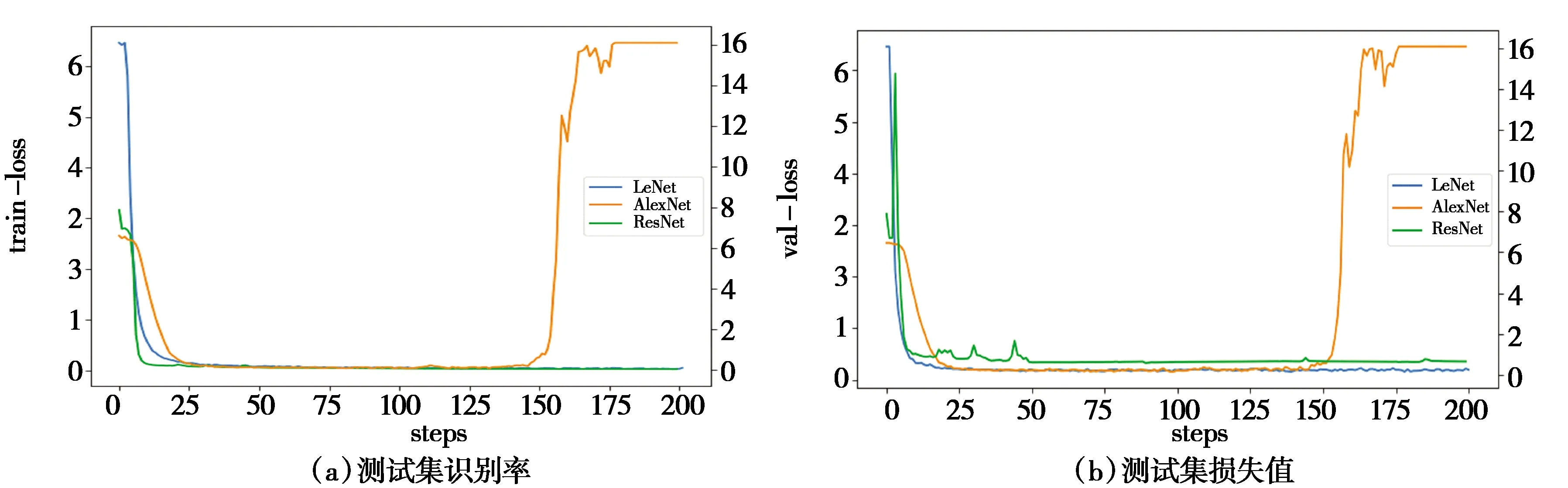
其次,计算字丁宽度T.当字丁带有元音时,整个字丁的宽度是音节分割符的6倍,否则是音节分割符的5倍.因此,设置检测字丁宽度阈值t为5×Min(w) 最后,异常文字按比例分割.遍历每个L当中的文字,若当前文字宽度w小于等于Min(w)或在阈值t区间时,不进行切分.否则当作异常宽度文字,按比例等切.例如图3第1行的“”,它的宽度分别是“”和“”的2倍,因此可以从“”中间位置切分得到“”和“”,切分效果如图4.图4中有232个字丁,其中10个字丁没有正确分割,按等切算法分割,其分割正确率达95.69%. 图4 等切分割法效果 近年来,卷积神经网络有很多成熟的网络模型[9],本文为了减小模型体量,选择单独使用模型,通过三种网络模型之间的实验,选出准确率最高的LeNet-5模型.图像首先经过预处理后进行字符分割与图像归一化,为了加快识别速率,识别时通过图像投影抽取藏文文本图像的像素点,由此获得字符的特征向量. LeNet网络模型是经典的卷积神经网络模型,由Yann LeCun[10]等人研究手写识别数字时提出,直到现在仍然受用,该模型由卷积层、池化层、全连接层组成,为了防止过拟合,在最后加入Dropout层.卷积神经网络是提取特征图像的过程,由此为了提高图像重点区域部分,引入注意力机制思想,将赋予藏文文本图像对应权重完成特征提取.本文识别藏文图像文本基线采用LeNet-5网络模型,引入注意力思想从中提取重点区域的特征.LeNet-5网络模型具体结构如图5所示. 图5 基于藏文图像的LeNet-5网络模型 输入一张32×32的图像,C1卷积层有6个卷积核,卷积核的大小设置为5×5,偏置项为1最后得到一个28×28的特征图图像,卷积层公式见(2),公式中l为卷积层数,Mj为第j个特征图.S2池化层采用2×2,特征图为14×14.C3卷积层通过S2的特征计算得到C3层的卷积核数量为16,特征图的大小为10×10,S4池化层与S2层相同,C5卷积层,把每一张特征图与池化层全连接,F6全连接层,输出层采用softmax函数,概率范围为0~1. (2) MC(F)=σ(MLP(AvgPool(F)+MLP(MaxPool(F))) (3) 空间注意力模块与通道不同的是表达了特征信息在哪里的问题,使用了两个相似的输出接受通道轴的聚集,是平均池化与最大池化结合后的特征信息,沿着通道模块找到最优的特征信息位置,最终将信息转发到卷积层生成空间注意力模块,记为Ms(F)∈RH×W,并连接在网络结构中进行卷积提取特征.本文网络架构选择LeNet-5(实验分析中将展示最佳网络模型结果),通过注意力机制的思想决定强调文本图像的重点特征或抑制文本,空间注意力模块的过程见公式(4),公式中σ为Sigmoid,f5×5为卷积核的大小. Ms(F)=σ(f5×5([AvgPool(F);MaxPool(F)])) (4) 本文引入的卷积层注意力模块为混合注意力(CBAM),给定一张特征图F∈RC×H×W作为输入图像,集成了通道注意力机制与空间注意力机制,顺序为先通道注意力机制实现了通道层面的注意力后在空间注意力机制实现空间层的注意力,通过两种注意力,综合了通道和空间的因素组成最有效的网络模型.CBAM可以与卷积神经网络模型[12]任意结合,首先利用通道维度对特征图使用的最大池化和平均池化,将以上两个池化后的结果输入到卷积层中,产生空间注意力自动掩码,CBAM通过特征图的空间关系映射到空间注意力自动验码,选择最有力的卷积特征,过滤信息的冗余,CBAM-LeNet-5的结构如图6所示. 图6 CBAM-LeNet-5结构图 本文实现的基于Android的藏文图像文本识别系统,由前端开发和后端识别两部分共同组成,前端开发Android采用三层框架模式,系统总体架构图如图7所示.前台与后台识别联通的方式是通过构造HTTP技术完成数据通信,本文使用Get和Post方法,Android开发中在URL_UPLOAD中可查看Get参数,在后台设置指定Starget_path用于接受文件目录,在Android端请求后台地址和绑定的端口号,在后台收到图像的请求识别后,解析数据后得到文本内容,解析的结果通过对应的参数条件将数据封装成JSON格式,最终请求获取数据返回内容,完成前台与后台的数据交互,由此完成藏文文本识别结果的上传. 图7 基于Android的藏文图像文本识别系统总体框架 系统包括四个功能模块:用户注册登录界面、识别界面、我的界面、退出系统界面,其中识别模块中包含图像采集处理、预处理功能、藏文文本识别完成识别功能,对于最终获取到返回的识别结果,可以对其进行复制与编辑,将其文本正确保存,可以在下一次登录时查找历史记录,本文在开发系统时在界面的设计上考虑到不同民族用户的习惯和需求从而设计了藏文语言的界面,功能界面展示图如图8所示(本文展示藏文界面). (a)用户登录界面 (b)识别界面 (c)我的界面 (d)设置界面图8 基于Android的藏文图像文本识别 实验中选择三种各有优势的网络模型(LeNet-5、AlexNet、ResNet)分别对藏文印刷体的图像进行模型训练.首先比对基线模型的训练识别率,最终ResNet网络模型样本上的识别率达到96.57%,训练集识别率和损失值如图9所示,但测试集中发现LeNet-5网络模型识别率更好,测试集变化趋势如图10所示,虽然LeNet网络与ResNet网络几乎在同一时刻收敛,但LeNet网络模型更加趋于平稳,即使在训练集中ResNet网络的识别率比LeNet-5网络高,但由于ResNet网络层很深,比较适合数据集庞大的训练. 图9 三种基线网络模型训练集识别率与损失值变化趋势 本文通过各个关于藏文的网站爬取到藏文字符,由此构建的数据集有9570张,其中字丁类别达到638个,相比于其他藏文字丁数据集中的字丁类别,本文的字丁类别较多,为此本文的数据集选用LeNet-5网络更合适,通过适当调整和优化LeNet-5网络,有利于基于字丁的藏文图像提高识别率. 图10 三种基线网络模型测试集识别率与损失值 针对传统的LeNet-5与引入注意力机制模块的CBAM-LeNet-5进行比对,最终本文所使用的网络模型比传统模型提高2.36%,实验结果见下表1.最后通过不同的参数进行实验,对初始化参数进行微调参数优化模型,训练出一款适合藏文图像文本的网络模型, 表1 基于藏文的两种网络模型识别率 通过上表实验结果可见,本文最终优化的网络模型CBAM-LeNet-5识别率更高,更加适用于藏文文本图像的识别,分别对训练参数进行实验,具体参数配置见下表2. 表2 基于CBAM-LeNet-5模型的最优化参数 系统的测试环境:Android7.1.1和Android10.0,Nexus S API:25和API:29,内存:4G,CPU主频:1.6GHz,CPU:i5-10th GEN.真机测试环境1:Meitu M6,Android 7.0,CPU主频:2.0GHz,CPU:Helio P10,内存:3GB.真机测试环境2:HONOR X10,Android 10.0,CPU:Kirin 820,内存:8GB. 系统在开发完成后要对每个功能进行测试以完善系统.启动APP之后,通过用户注册或直接登录系统,如图8(a)所示,用户名超过8个字符或输入其他符号则注册失败.在图8(b)中,识别界面为主要识别文本功能,识别前可对图像进行预处理,显示识别结果后对文字进行修改并保存结果,在我的界面中的识别记录中可查看保存结果如图8(c).如图8(d)设置的界面,可以分别选择三种界面,藏文、中文、英文,按钮可随意切换. 考虑到目前市场中出现多种安卓版本的手机设备,测试版本兼容性,经过以上测试,系统可以在模拟器和真机上正常运行. 本文首先对藏文图像进行预处理技术,通过改进的等切分割法分割字丁,将传统的LeNet-5的网络模型与CBAM注意力机制相结合,提取藏文文本图像的特征信息,最终通过微调模型参数,平均识别率达到96.03%.再通过Android开发平台开发手机APP,采用HTTP技术实现数据传输,实现基于Android的藏文图像文本识别的系统.由于目前构建的藏文字丁数据集只有9570,后续通过扩充数据集继续实验,模型也需要进一步改进.
3 基于CBAM-LeNet-5模型的藏文文本识别
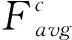
4 系统实现
5 实验分析及系统测试


6 总结
猜你喜欢
建材发展导向(2021年19期)2021-12-06
西藏研究(2021年1期)2021-06-09
临床骨科杂志(2020年1期)2020-12-12
颂雅风·艺术月刊(2020年4期)2020-12-07
布达拉(2020年3期)2020-04-13
学校教育研究(2020年3期)2020-02-18
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
