
高维多目标头脑风暴优化算法
2020-03-27 11:22吴亚丽付玉龙李国婷张亚崇
控制理论与应用 2020年1期
吴亚丽 付玉龙李国婷张亚崇
(1.西安理工大学自动化与信息工程学院,陕西西安 710048;2.陕西省复杂系统控制与智能信息处理重点实验室,陕西西安 710048;3.西安飞行自动控制研究所,陕西西安 710065)
1 引言
作为一种典型的复杂优化问题,多目标优化问题(multi-objective optimization problem,MOP)已广泛应用于工程领域以及现实生活中,如地下水监测问题[1]、PID控制器设计问题[2]、网络社会物理系统[3]等领域.近几年,随着时代的发展,现实所面临的问题越来越复杂,并且呈现出动态、多约束、大规模、目标个数增加等特性.通常,称目标个数多于3个的MOP为高维多目标优化问题(many-objective optimization problem,MaOP).
与单目标优化问题(single-objective optimization problem,SOP)相比,MOP需要得到一组解来逼近问题真实的前沿,这组解在决策空间中被称为Pareto最优解集(pareto set,PS),在目标空间中被称为Pareto最优前沿(pareto front,PF).当问题的目标个数增加时,用来解决多目标问题的经典算法表现出了较大的局限性,主要表现在收敛能力和多样性保持能力两个方面.
由于目标数目的增加,种群中的非支配解所占比重随着目标个数急剧增加[4],选择压力减小,支配关系难以适用,导致算法的进化速度降低.基于此问题,主要研究分为以下两点:①开发或改进支配方式,增加选择压力,如ϵ--支配[5]、L--最优[6]、模糊支配[7]、网格支配[8]、θ--支配[9]、增强支配(strengthened dominance relation,SDR)等[10],其主要通过更加松弛的支配关系来对原本互不支配的个体进行区分,以更加合理地进行适应度选择和环境选择;②Pareto支配与其他选择指标相结合,如基于分解的多目标进化算法[11-13]、基于指标的多目标进化算法[14-15]等,主要通过权重向量对个体进行衡量或根据个体对整体指标的贡献来对个体进行适应度值分配.
在多样性的保持能力方面,由于目标函数的增加使得候选解稀疏地分布在高维空间里,导致了传统多样性维持策略的低效性.尽管拥挤距离的策略已较为成熟且表现出良好的性能[16],但在MaOP方面仍然表现出较低的效率.为此,文献[17]提出角度惩罚距离的概念,并证明了基于角度的度量不仅具有可扩展性,而且性能优于基于欧氏距离的方式.基于参考点的选取也是当前流行的一种Pareto解集的维持策略,已被应用于很多比较流行的算法中[12,17-18].
由上述分析可以看出,MaOP问题的研究难点是收敛性和多样性之间的权衡.大多数算法将其归结于根据目标值进行适应度值分配以及选择问题,并从各方面提出了分配以及选择策略.文献[13]和文献[19]从问题角度出发,围绕各决策变量对目标的影响将其分为收敛性相关变量和多样性相关变量,然后分别对其进行优化,增强优化结构;此外,采用分而治之的思想对无关收敛性相关变量分别进行优化,提高优化效率,取得了非常好的效果.
在众多的智能优化算法中,史玉回教授2011年提出的头脑风暴优化算法(brain storm optimization,BSO)以聚类中心为导向,并以概率朝着其他个体进行学习,能够较好地兼顾收敛性和多样性[20].在经典算法的基础上,不同研究者围绕其聚类、变异、以及更新归档集的方式衍生出了多种多目标头脑风暴优化算法(multi-objective brain storm optimization,MOBSO),均取得了较好的结果[21-23].文献[21]将聚类应用于目标空间,并采用精英类策略,加快MOBSO的收敛速度.文献[22]采用DBSCAN聚类代替经典BSO中的k--means聚类,用差分变异代替高斯变异,提出了改进的多目标头脑风暴优化算法(modified multi-objective brain storm optimization,MMBSO),效果大幅提高.文献[23]采用了MBSO中的简单聚类,并在差分变异的基础上引入了开放性概率,有效避免陷入局部最优(self-adaptive multi-objective brain storm optimization,SMOBSO),吴亚丽等人[24]将其用于解决热电联供环境经济调度(environment economic dispatch,EED)问题,结果优于效果较好的准对抗教学优化算法(quasioppositional teaching learning based optimization,QOTLBO).
基于上述的研究基础,本文综合BSO算法的进化优势与聚类思想的选择策略,提出一种有效的高维多目标头脑风暴优化算法.算法对MaOP问题的决策变量特性进行进一步特征提取,并基于不同的特征设计不同的进化策略.主要步骤为:首先,根据决策变量的特征将其分为收敛性相关变量和多样性相关变量,并采取不同的优化策略.对于收敛性相关变量,对收敛性相关变量进行独立性分析,对于相互独立的变量“分而治之”,提高算法优化效率;并采用分解的策略将多个目标转换为一个目标,增加选择压力,提高收敛速度;对于多样性相关变量,提出了一种新的以角点为聚类中心的自适应聚类方式,以一定的概率基于类中心产生新个体提高算法的扩展性:采用参考点策略更新种群,提高算法的均匀性.此外,为了增强算法的导向性,个体对应的权重向量和参考点均采用标准边界交叉方法(normal-boundary intersection,NBI)方式生成且相对应,且每次迭代中进行动态分配.在以权重向量进行目标转换和以参考点进行更新时,个体以参考点为导向.文中给出大量的仿真算例来验证算法的有效性.
2 头脑风暴优化算法的基本原理
2.1 头脑风暴优化算法
头脑风暴优化算法(BSO)是受人类头脑风暴会议所启发,将产生的每一个想法看做是一个潜在的可行解,产生想法的过程遵循“庭外判决”、“各抒己见”、“取长补短”、“追求数量”的原则,即产生尽可能多的解,量变产生质变.与人类头脑风暴会议过程类似,头脑风暴优化算法以聚类中心为导向产生新个体对应于以一个较好的想法为参考生成新的想法.在得到导向之后,新个体通过在其基础上进行变异来产生,每一次迭代完后进行比较,保留较好的个体进入下一次迭代.头脑风暴优化算法过程如下所示[20]:
Step 1种群初始化;
Step 2评价个体,聚类;
Step 3产生新个体;
Step 4更新种群和聚类中心;
Step 5若达到最大迭代次数则输出最优个体,否则转Step 2.
传统的BSO采用k--means进行聚类,并将每个类中最优的个体作为聚类中心.在产生新个体时,选择个体以一定的概率分别为一个聚类中心、一个类中个体、两个聚类中心或者类中个体的加权和.在此基础上,通过加变异实现对当前解的探索过程,常用的高斯变异定义如下:
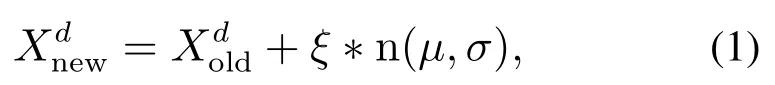

其中:logsig是一个S型对数传递函数;T 为最大迭代次数;t为当前迭代次数;K用来改变logsig的斜率,可调节算法由全局搜索到局部搜索的速度;rand产生(0,1)之间的随机值.
张军等人[25]提出以差分变异代替高斯变异,并取得了更好的效果且已经成功用于多种版本的BSO中[23-24,26].差分变异如式(3)所示:

其中:Ld,Hd为第d维的上下界,为在当代全局中选择的两个不同的个体的第d 维.为了保持种群的多样性,防止陷入局部最优,设置开放性概率Pr.
从式(3)可以看出,与高斯变异相比,差分变异运算量减小,运行速度提高.而且变异量的产生是基于当代种群内其他个体而来,可根据种群内个体的离散程度来自适应调节,能够更好地与种群内其他个体共享信息,其搜索效率显著提高.因此,差分变异能够在搜索过程中更好地平衡局部搜索和全局搜索,有效地提高算法性能.
2.2 多目标头脑风暴优化算法
与BSO相比,MOBSO引入了归档集的策略,用来保存Pareto最优解.在每次迭代中对种群进行非支配排序,取非支配解计入归档集,然后进行更新,最终得到一组足够靠近最优前沿且均匀的解.MOBSO采用循环拥挤距离策略更新归档集.首先令两个端点的拥挤距离为无穷大,然后分别计算所有个体相邻点在目标空间的曼哈顿距离,逐次删除拥挤距离最小的个体,以保持归档集内的个体具有均匀性.MOBSO能够很好地解决两个目标的优化问题并应用于实际,由于其对新个体的选择机制使得难以用于解决MaOP,且原始的基于Pareto支配策略导致使得算法收敛速度过慢.基于此,本文将归档集的更新策略和多样性选择机制进行重新设计,提出了一种求解高维多目标优化问题的头脑风暴优化算法.
3 高维多目标头脑风暴优化算法
3.1 主要框架
多目标优化算法的目的在于得到一组优秀且均匀的Pareto最优解,由于不同特性的决策变量对优化结果有着不同的影响[19],因此在每一次迭代中先后进行收敛性优化和多样性优化,即先使得个体向好的方向移动,然后保持种群的多样性.在进行优化之前,首先需产生参考点以及对决策变量进行聚类.算法的主要框架见算法1.
算法1MaOBSO.
输入:M(目标个数),Emax(最大评价次数),Po(选择一个个体产生新个体的概率),Pc(选择聚类中心产生新个体的概率);
输出:P(最终种群);

MaOBSO采用NBI[18]的方式生成权重向量,因此直接将种群视为归档集.在算法1中,首先进行初始化,包括生成新的种群以和参考点,并以角点为聚类中心对参考点进行聚类.然后将个体与参考点进行匹配,并将参考点的聚类结果对应到种群中.接着将决策变量分为收敛性相关变量和多样相关变量,并对收敛性相关变量进行独立性分析.最后进行变量优化.
算法2VectorAllocation(P,w,M).
输入:P(种群),w(参考向量),M(目标个数);
输出:w(分配后的向量),cluster(聚类结果);


算法2为将参考点和个体相对应以及聚类的过程.本文采用参考向量的策略,首先对参考向量根据以其角点(极端点)为中心进行聚类,确定每个向量所属类别.然后计算每个向量与个体在目标空间的夹角,根据角度进行分配,并以分配关系将参考点的角力聚类结果对应到种群.以3目标DTLZ1为例,在进化途中种群在目标空间中的聚类结果如图1所示.

图1 3目标DTLZ1进化中聚类结果Fig.1 The cluster result of DTLZ1 of 3 objectives while evolutionary
3.2 决策变量聚类
现实中的问题是多种多样的.对于有的问题来说,其对维度变化非常敏感,当某些维度有较小偏离时,其适应度值便极度远离真实的Pareto前沿,或者对整体均匀性造成很大的影响.以以下多目标问题为例:

分别对式(4)中x1和x2保持不变,让另一个变量在定义域内均匀变化,观察其在目标空间中的变化,如图2所示.
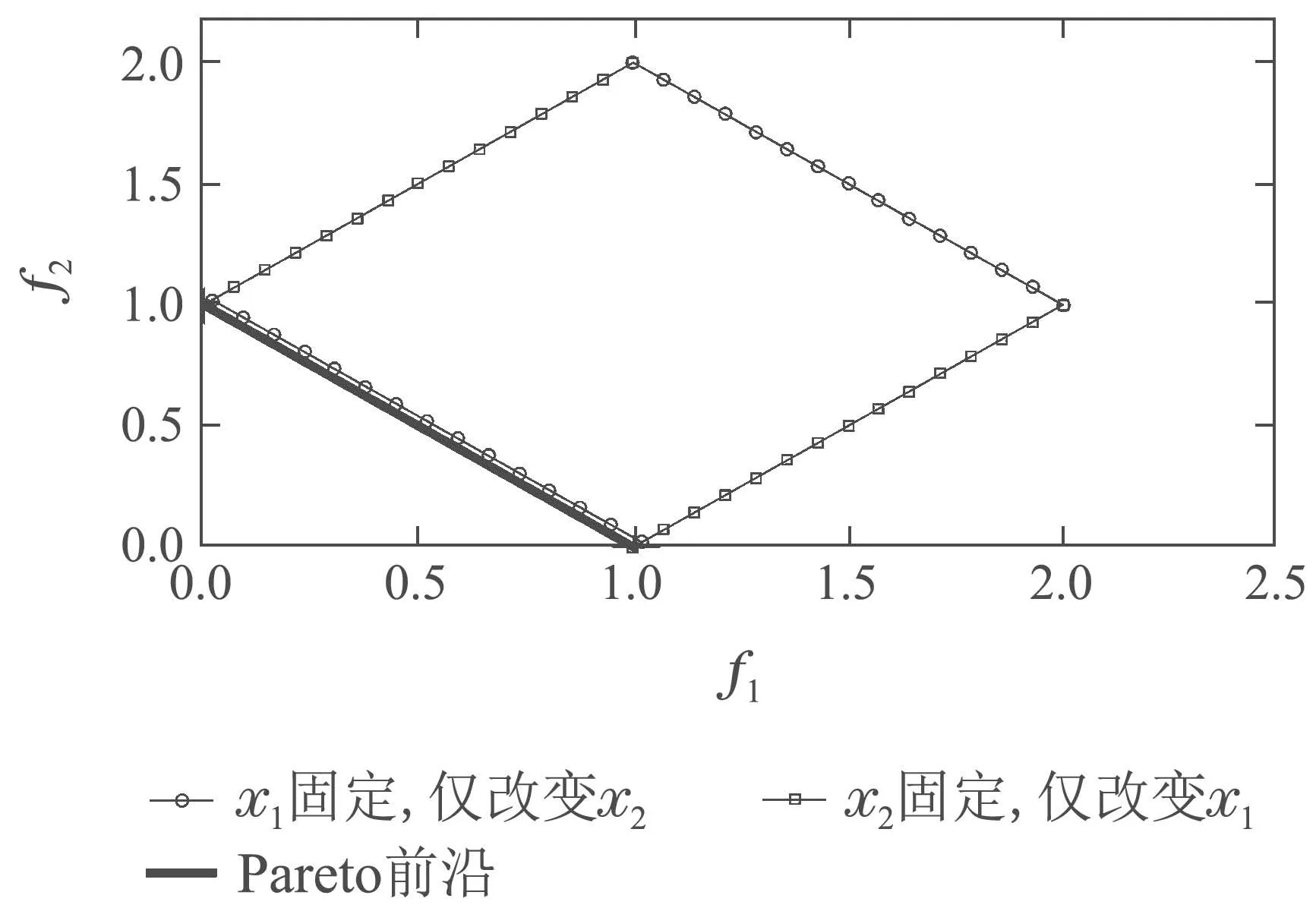
图2 分别改变x1和x2得到的适应度值分布Fig.2 The fitness distribution obtained by perturbing x1and x2respectively
由图2可见,当分别改变x1和x2而固定其他维度时在目标空间中有着不同的影响,显然,x1影响MOP的收敛性,而x2影响多样性,分别称为收敛性相关变量(convergence variables,CV)和多样性相关变量(diversity variables,DV).对于CV,需要找到一个最优值,来支配其他所有值下对应的解;而对于DV,需要使其合理分布,促使对应的解在目标空间中均匀分布[13,18].
算法3VariableCluster(P).
输入:P(种群);
输出:DV(多样性相关变量);CV(收敛性相关变量);

算法3为决策变量聚类的过程.本文从定义出发,对于每一个决策变量,分别在其他决策变量不变的情况下对其进行扰动,即由一个个体得到种群,然后对种群进行非支配排序,则非支配序列便可反映决策变量的特征.
所有决策变量得到的非支配序列构成的矩阵反映了所有的特征.严格来说,收敛性相关变量得到种群的非支配序列个数为1,而多样性相关变量的序列个数等于对应个体数.因此,本文采用k--means聚类将序列得到的矩阵分为两类,较小的类别为收敛性相关变量.较大的则为多样性相关变量.
3.3 变量独立性分析
决策变量规模增加时优化难度也随之增加,但现实中往往需要解决较大规模的问题.一直以来,学者们致力于找到一种更好的方法来找到全局最优解,另一种策略便是对问题进行简化,将一个大规模优化问题分解为多个简单的小规模优化问题.对于一个SOP,称满足
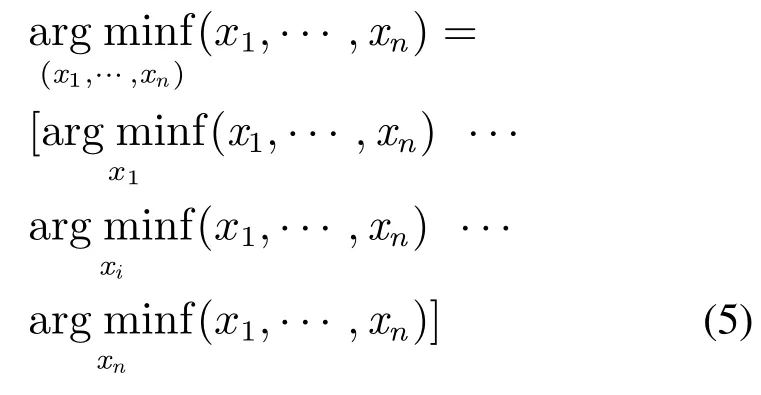
的函数为可分离函数,否则称为不可分离函数.
对优化问题“分而治之”能够很大程度上提高优化效率,其表示变量之间互不影响,因此能够逐个对变量进行优化.但问题的变量之间是否具有依赖性难以提前所知,判断的方式为:对于两个决策变量xi和xj,若存在a1,a2,b1,b2满足

则称xi和xj为互不独立变量.对于收敛性相关变量独立性分析算法见算法4.
算法4InteractionAnalysis(P,CV).
输入:P(种群);CV(收敛性相关变量);
输出:sub CVs(非独立的收敛性相关变量集合);
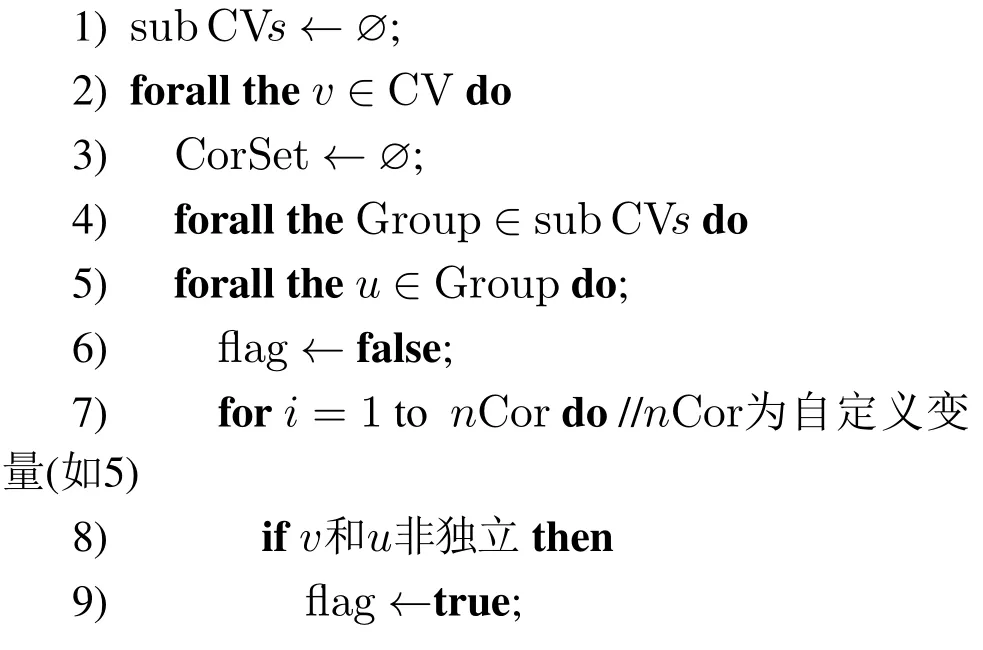

3.4 变量优化
本文将决策变量分为收敛性相关变量和多样性相关变量,对其进行不同的优化策略对算法的进化结构有着显著的提升.算法5为收敛性优化过程,为了增加选择压力,使种群更快地趋近于Pareto前沿,本文采用加权边界相交(penalty-based boundary intersection,PBI)的策略来评价一个解的优劣[12].PBI策略能将个体的多个目标值转换为一个目标值,其计算公式为

其中:θ为自定义的惩罚参数,可用来权衡解收敛性与多样性.可见,d1为所有目标构成的点f距离所有目标最小值构成的点的距离,能够衡量x的收敛程度,d2表示点f 与权重w的间距,能够衡量x的分布特性,因此PBI能够更加全面地用一个值来衡量一个解的优劣程度.
算法5ConverOptimi(P,sub CVs,Zmin).
输入:P(种群),sub CVs(非独立的收敛性相关变量集合),Zmin(当前种群中每个目标的最小值);
输出:P(新种群);


算法5以个体的PBI值为标准以轮盘赌的方式选择父代,通过模拟二进制交叉(simulated binary crossover,SBX)来产生新个体,在种群更新方面,通过比较父代与新个体的PBI值保留较好的进入新的种群.
算法6为多样性优化的过程.与原始BSO的机制类似,算法以聚类中心为导向,并以概率选择其他个体作为当前个体,通过变异实现对个体周围的搜索.在得到新的种群后,将原种群与新种群进行合并,通过计算与参考点的夹角来对种群进行更新.
此外,为了避免不必要的搜索,本文设置了收敛优化指标.当种群的收敛性相关变量的方差的平均值小于某一阈值时停止收敛性优化.值得注意的是,在收敛性优化和多样性优化时,分别只改变收敛性相关变量和多样性相关变量.
算法6DiverOptimi(P,Po,Pc,DV,w,cluster,Zmin,Znad).
输入:P(当前种群),Po(用一个个体产生新个体的概率),Pc(用聚类中心产生新个体的概率),DV(多样性相关变量),w(参考点),cluster(聚类结果),Zmin(当前种群中每个目标上的最小值),Znad(Pareto前沿在每个目标上的截距);
输出:P(新种群);


4 仿真结果与分析
为了测试本文算法的性能,本文分别选择ZDT和DTLZ测试函数集来评价算法解决MOP和MaOP的性能,以反演世代距离(inverted generational distance,IGD)[27]为指标来综合比较本文算法与几种经典算法的性能.
4.1 多目标优化问题的性能
本文采用ZDT测试函数集来评价算法解决MOP的性能,并与算法MOBSO,MMBSO,SMOBSO以及经典算法NSGA--II进行综合比较.其中,选用30维的ZDT1-ZDT4和ZDT6;归档集大小和总评价次数统一 为51 和20000;细节方面,MOBSO,MMBSO 和SMOBSO分别设p1,p2,p3,p4为0.8,0.8,0.2,0.2,聚类个数为4,NSGA--II采用模拟二进制交叉和多项式变异,MaOBSO分别设Po和Pc为0.8,0.3.拥挤距离策略在处理双目标优化问题时非常高效且操作简单,因此在测试算法解决MOP能力时,采用拥挤距离策略来进行环境选择.算法运行30次,记录平均值以及标准如表1所示,其中,加粗以及加黑的结果表示最优的性能.

表1 MaOBSO与经典算法解决MOP时IGD比较Table 1 The comparison of IGD between MaOBSO and classic algorithms while solving MOP
由表1 可见,与其他算法相比,MaOBSO 表现出非常优异的性能.对于较为常规的ZDT1 和ZDT2,MaOBSO较大幅度领先于经典版本的多目标BSO,与经典算法NSGA--II相比也有所领先;对于有着不连续前沿的ZDT3,算法在收敛性能和多样性能优化方面均难度较大,MaOBSO性能提升更加明显;对于具有大量局部极值点的ZDT4和非均匀函数ZDT6,其他算法综合性能变差,而MaOBSO仍能够保持非常优异的性能.为了更加直接地观察算法得到的Pareto最优解,以ZDT1,ZDT3,ZDT4为例,取30 次中最接近IGD 平均值的一次结果如图3所示.

图3 MaOBSO与经典算法解决MOP时的Pareto最优解集Fig.3 The Pareto set of MaOBSO and classic algorithms while solving MOP
由图3可见,对于几个测试函数而言,MaOBSO从综合性能上有着最优异的表现.从收敛性角度看,MaOBSO在ZDT1,ZDT3上略微领先于其他算法,在ZDT1 以及SMOBSO 处理ZDT3 时更加明显.对于ZDT4,MaOBSO与相比其他算法有着较为明显的提升,对比几种版本的头脑风暴优化算法可见,MMBSO中差分变异相比MOBSO的高斯变异能够更加积极地促进算法的收敛性,而SMOBSO引入的开放性概率对于算法收敛起到了进一步的促进作用.从多样性角度来看,MaOBSO在ZDT1上略微领先于其他算法,对于ZDT3而言,MMBSO,SMOBSO和MaOBSO性能优于MOBSO和NSGA--II,表明了循环拥挤距离在维持多样性方面领先于拥挤距离.而对于ZDT4 而言,即使MMBSO和SMOBSO采用了循环拥挤距离,但依然有着较差的多样性能,可见算法的收敛性能较差时对多样性能有着一定程度的影响.
综上分析,MaOBSO在处理MOP时从收敛性能和多样性能方面均有较大幅度的提升,当优化难度增加时更为明显,表明了采用决策变量聚类策略在改进算法进化结构方面的合理性与高效性,且具有更大的潜力.此外,从稳定性角度来说,MaOBSO处理MOP时IGD指标标准差较小,表明了算法具有较好的稳定性.
4.2 高维多目标优化问题的性能
本文采用经典的DTLZ测试函数集来评价算法解决MaOP 的性能,并与当前较为流行的算法MOEA/DD,NSGA--III,LMEA,MOEA/DVA以及RVEA进行综合比较.对于DTLZ测试函数集而言,决策维度D=K+M−1,其中:M为目标个数,K为难度因子.本文对于DTLZ1设K=5,DTLZ2-DTLZ6设K=10,DTLZ7设K=20;分别测试M=3,5,8,10下的性能,归档集大小分别设置为105,126,72,65,最大迭代次数统一设为 100000;细节方面,MOEA/DD中设δ=0.9,RVEA中设α=2,fr=0.1;算法运行30次,记录平均值以及标准差如表2所示,其中,加粗以及加黑的结果表示最优的性能.除了本文算法外,其他算法在高维多目标优化算法platEMO[28]上运行.
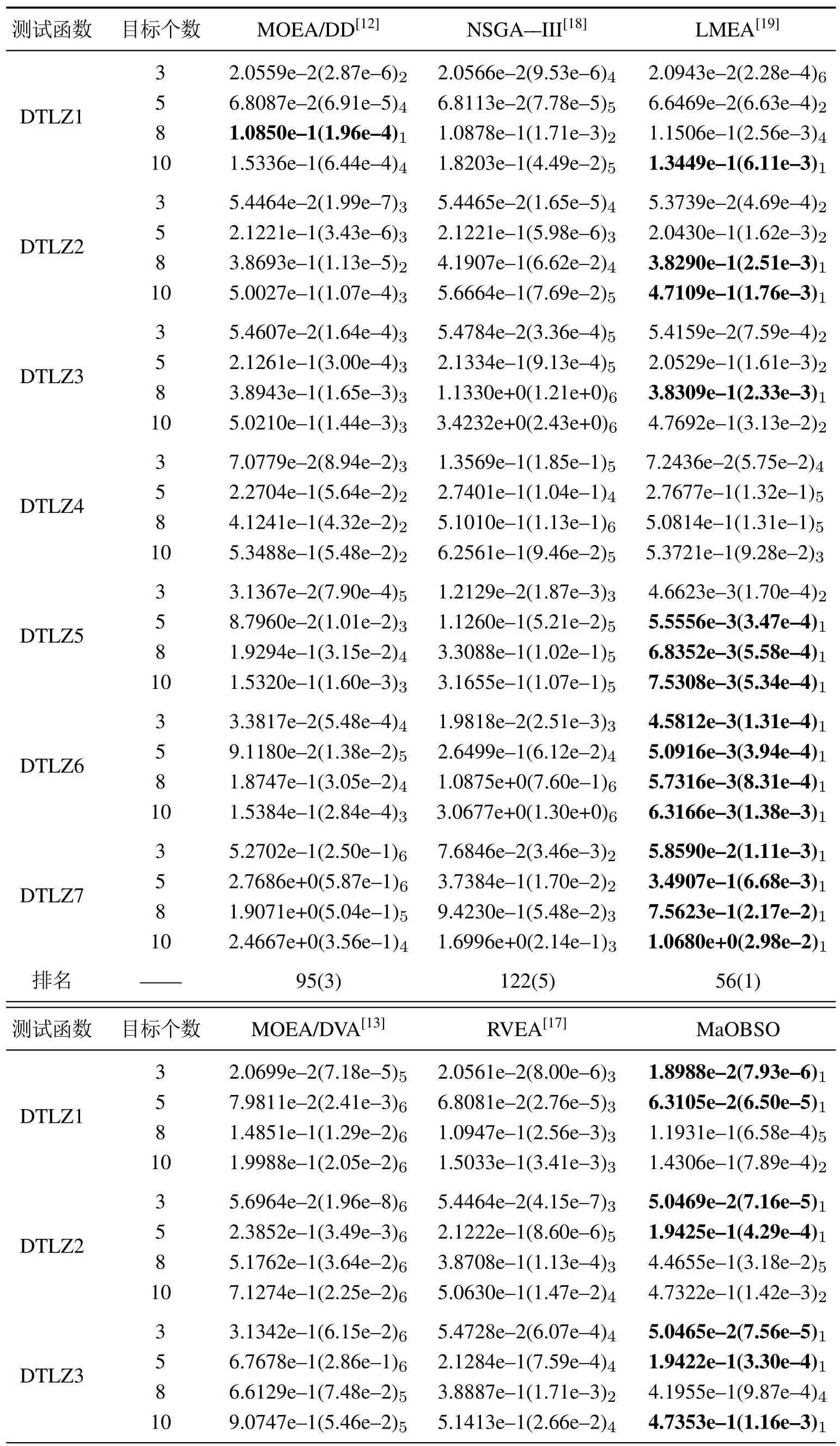
表2 MaOBSO与几种算法IGD的比较Table 2 The comparison of IGD between MaOBSO and several algorithms

由表2可见,MaOBSO与其他算法相比整体表现出较为理想的性能.与现有的几种算法相比,其处于同等数量级且表现略微优异.具体分析如下:
对于同一测试函数而言,算法的IGD指标随着目标个数增加而增加,验证了目标个数的增加对优化带来的挑战性.可见当目标个数的增加导致种群更加离散地分布在在高维目标空间中,导致了种群的多样性维护难度增加.
对于不同测试函数而言,大多数算法在处理DTLZ1-DTLZ4有着更优秀的性能,因为他们有着更加规范的Pareto 前沿,算法进化过程中更容易得到Pareto最优解,且种群的多样性维护更为容易.而对于DTLZ5-DTLZ7,算法整体性能较差,且受目标个数的影响更大.
对于不同算法而言,在处理具有较为规范的Pareto前沿的DTLZ1-DTLZ4时,MaOBSO与几种经典算法性能处于同一数量级,但由于本文算法在处理均匀性优化时有着更高的效率,最终性能更加优秀.特别是对于DTLZ4,MaOBSO性能提升更为明显.而在处理DTLZ5-DTLZ7方面,LMEA与其他算法以及本文算法有着不同的保留机制,具有更强的适应性,最终得到更加均匀的前沿,算法性能最好且更加稳定.但相比于其他算法,MaOBSO性能更优.
从算法稳定性来讲,MaOBSO整体标准差较小,表明算法有着较好的稳定性.为了更加直接地观察算法得 到 的Pareto 最 优 解,以10 目 标DTLZ1,DTLZ4,DTLZ5及DTLZ7为例,取30次中最接近IGD平均值的结果对应的Pareto前沿的平行坐标如图4所示.
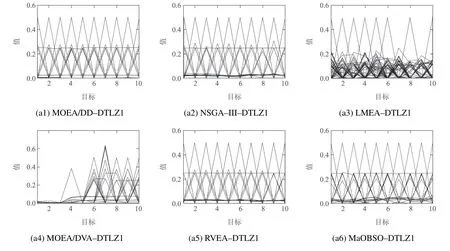

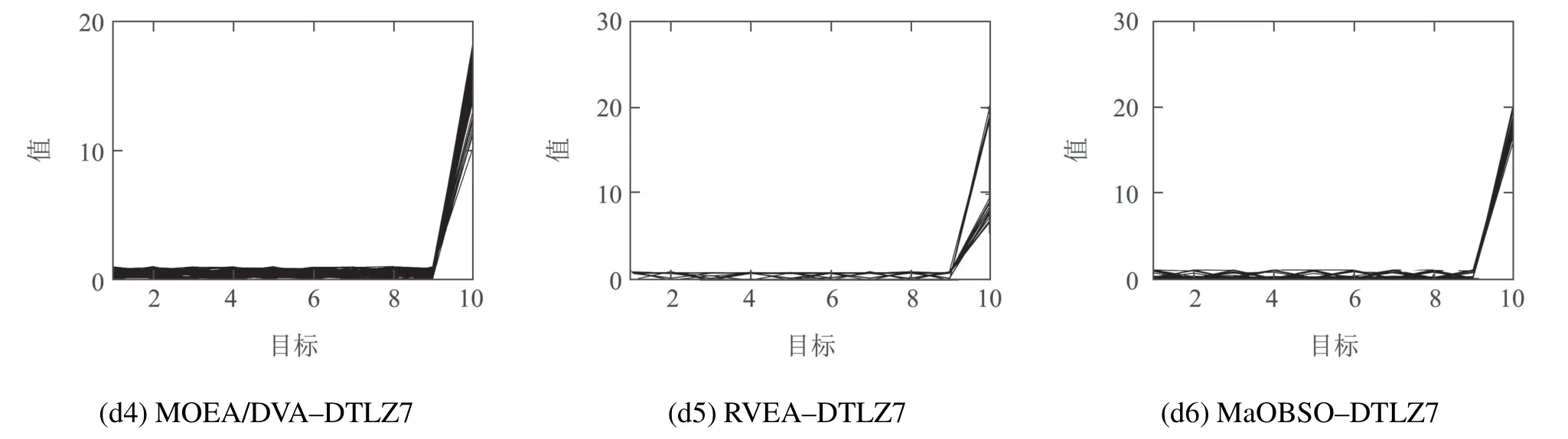
图4 MaOBSO与经典算法解决MaOP时的Pareto最优解集Fig.4 The Pareto set of MaOBSO and classic algorithms while solving MaOP
由图4可以看出,MaOBSO在4种测试函数上与其他几种算法性能各有胜负.对于DTLZ1,所有算法都表现出良好的性能,尽管几种算法的IGD指标较为接近,但从图4(a1)-(a6)可明显看到,LMEA均匀性稍差,MOEA/DVA收敛性稍差,多样性较差;对于均匀性优化难度较大的DTLZ4,从收敛性角度看,几种算法均有着良好的收敛性能,NSGA--III稍差;从多样性角度来看,NSGA--III,LMEA和MOEA/DVA性能较差,最优解集在目标空间中分布的广度以及均匀程度均不理想,算法得到的Pareto最优解大多数分布于边界上,且在某些目标上存在“缺失”现象,难以使得最优解集广泛地分布于整个非支配前沿上.而MaOBSO由于能够不受约束地产生新个体则表现出最优的性能,与其相比,而MOEA/DD和RVEA性能稍差;对于具有退化前沿的DTLZ5和不连续前沿的DTLZ7,LMEA表现出最优的性能,尽管MaOBSO难以达到理想的水平,但与其他算法相比仍表现出良好的竞争力,其中对于DTLZ5在收敛性能和多样性能方面均较大程度领先于其他算法,而在DTLZ7上与其他算法相仿.
综上所述,MaOBSO能够较好地处理各种MaOP,与当前流行的几种算法相比表现出良好的竞争力.对具有规则前沿的(高维)多目标优化问题,MaOBSO与其他算法同样表现出良好的性能且更加优异,而对于具有不规则前沿的问题,算法在多样性方面稍逊于LMEA算法,但整体性能略微领先于其他算法.
5 总结与展望
本文针对高维多目标优化算法的收敛性和多样性问题,结合头脑风暴优化算法的的思想,提出了一种高维多目标头脑风暴优化算法.算法采用决策变量聚类策略,对收敛性相关变量和多样性相关变量分别做出优化,并根据变量特征采用不同的个体产生策略和更新策略,融入了头脑风暴优化算法产生新个体的机制,仿真结果表明了算法具有良好的性能.此外,本文根据角点的特性采用了基于角点聚类的思想,对于多目标头脑风暴优化算法提出了一种新的自适应聚类策略,为之后的研究拓宽了方向.
在算法仿真研究时,作者发现本文基于参考点更新的方式对不规则Pareto前沿问题的性能还有待进一步的提升.因此,如何设计不规则前沿的多样性和收敛性更新策略,提高算法的普适性,并将其应用于实际的高维多目标优化问题将是作者今后进一步研究的方向.
猜你喜欢
数学物理学报(2022年5期)2022-10-09
数学物理学报(2022年5期)2022-10-09
今日农业(2022年15期)2022-09-20
好日子(下旬)(2020年6期)2020-08-04
消费导刊(2019年3期)2019-01-28
生物学教学(2018年3期)2018-08-08
计算机与数字工程(2018年4期)2018-04-26
中学生物学(2018年8期)2018-03-01
