
基于NBSR模型的入侵检测技术*
2020-03-26 11:07朱世松巴梦龙申自浩
计算机工程与科学 2020年3期
朱世松,巴梦龙,王 辉,申自浩
(河南理工大学计算机科学与技术学院,河南 焦作 454000)
1 引言
当前,网络安全威胁日益突出,网络安全风险不断向政治、经济、文化、社会、生态、国防等领域渗透,国家互联网应急中心CNCERT(National Internet Emergency Center)于2018年发布的互联网网络安全态势综述中显示[1,2],2018年全年CNCERT共协调处置网络安全事件约10.6万起,云平台成为发生网络攻击的重灾区,给网民人身安全、财产安全带来了安全隐患。如何更有效地检测入侵者攻击行为,保护数据的安全越来越受到重视。
入侵检测系统IDS(Intrusion Detection System)能够及时发现入侵行为,通过采集并分析计算机网络关键节点的活动信息,即可判断网络或系统是否遭到入侵[3]。按入侵检测技术基础可分为异常检测和误用检测,即正常特征白名单技术与入侵特征黑名单技术,异常检测通常需要建立庞大的正常特征库,容易造成较高误警率。误用检测针对已知的入侵行为建立模型,易实现,误报率低、检测快,但无法检测未知的入侵行为,因此过旧的检测模型会使得误检率上升从而造成重大损失。如何提升模型分类精度,降低模型误检率,已成为研究的热点。
2 相关研究
研究人员将机器学习技术融入IDS,训练机器学习检测模型应对复杂的网络环境。常用的经典分类算法有支持向量机SVM(Support Vector Machine)、随机森林、逻辑回归LR(Logistics Regression)、决策树DT(Decision Tree)和朴素贝叶斯NB(Naive Bayes)等,国内外学者针对入侵检测不断改进算法模型。
王春东等[4]提出基于特征相似度的贝叶斯网络入侵检测方法。利用相似度对网络连接数据的属性特征进行选择,抽取其关键特征,并降低属性的冗余度,以优化朴素贝叶斯的分类性能。但是,其数据集中缺少新的网络流量和低占用率攻击,已经不适合作为现代入侵检测特征数据集。
Bivens等[5]使用DARPA(Defense Advanced Research Projects Agency)1999数据集构建了基于多层感知神经网络的入侵检测系统。该系统使用时间滑动窗口对多个数据包进行检测,能够检测持续时间较长的攻击类型。实验结果表明,该系统对正常行为识别率达100%,但对未知攻击行为的检测效果不佳,误检率高达76%。
王琳琳等[6]基于算法级联的思想,提出了一种结合极限学习机和改进的K-means算法的混合式入侵检测方法。在NSL-KDD(Data Mining and Knowledge Discovery)数据集上的仿真实验结果表明,所提出的入侵检测方法可以提高对入侵攻击的检测效率。但是,由于NSL-KDD数据集缺少基于入侵检测网络的公共数据集,所以NSL-KDD数据集并不能贴近现有真实网络。
Al-Yaseen 等[7]提出了基于SVM分类器与极限学习机结合的多级入侵检测模型。该模型使用KDD 1999数据集,将改进后的K-means用于减少训练数据集中的特征数量,对经过转换和标准化的训练和测试数据集进行预处理,以使其适合于SVM分类器与极限学习机。该模型与基于相同数据集的其他方法相比,具有较高的攻击检测效率。但是,由于用于训练的数据集中缺失未知攻击样本,从而导致误检率较高。
Khor等[8]提出了基于贝叶斯网络与决策树C4.5分类器结合的多级入侵检测模型。该模型着力解决数据集中攻击类别分布不均匀的状况,并提出了一种二分法。该模型先将稀有类别从训练数据集中分离出来,减小主要攻击类别对分类器的影响,然后训练级联分类器以处理稀有类别和其他类别,从而提高了稀有攻击类别的检测率。但是,由于实验数据集中未知攻击类别的收录并不完全,仍存在较高的误检率。
入侵检测系统已成为检测网络域中各种恶意活动的重要机制。基于前面的研究,本文提出了一种基于NBSR(Naive Bayes and Softmax Regression)模型的入侵检测技术。首先针对ReliefF特征选择算法存在的缺点,引入Pearson相关系数计算特征之间的相关性,提出Relieff-P算法;其次利用Relieff-P算法对UNSW-NB15数据集进行处理,去除无关特征,得到新的特征子集,用于训练模型;然后将朴素贝叶斯分类器和Softmax回归分类器级联构成NBSR分类器。最后,结合仿真实验测试,实验数据结果显示,本文方法在入侵检测中对入侵事件分类的精度和误检率方面都具有较强的优势,尤其是与其他入侵检测技术进行比较发现,本文方法在准确率方面有较为明显的提升。
3 基于NBSR模型的入侵检测
3.1 相关系数改进的Relieff-P特征选择算法
数据处理对机器学习的训练和研究具有重要的意义。未经处理的数据存在噪声,各特征间的关联性不大,且冗余数据的存在会使算法开销增大甚至结果产生偏差。
ReliefF特征选择算法通过计算相同类别与不相同类别的相邻样本评估样本的相关性和冗余度[9],在处理目标属性为连续值的回归问题时,先从原始数据集中随机选出样本子集;再从样本子集的同类样本集中找出n个近邻样本;最后从与样本子集类别不同的样本集中找出n个近邻样本,分别计算特征权重值然后更新。迭代此过程,直到计算出每个样本的类别与特征的相关度。然后,依据特征权重的值对特征降序排列,筛选出特征权值小于给定阈值的特征,选择大于给定阈值的部分特征用于构成新的特征子集。
ReliefF仅考虑了特征与类别之间的相关性程度,没有考虑特征之间的相关性,本文提出一种相关系数定义的Relieff-P算法。引入Pearson相关系数来度量特征之间的相关性程度,其计算步骤如下:
从原始数据集中随机选择1个样本子集Si;从Si的同类样本集找到n个最近邻Hj(j=1,2,…,n)。计算样本子集Si和Hj在特征L上的差:
(1)
从Si不同类样本集中,找到n个最近邻Mj(C),计算样本子集Si和Mj(C)在特征L上的差:
(2)
式(1)与式(2)中diff(L,S1,S2)表示样本子集S1和样本子集S2在特征L上的差,其计算公式如下所示:
diff(L,S1,S2)=
(3)
更新特征L的权重值,公式如下所示:
(4)
其中,P(C)为该类别的比例,class(Si)为样本子集Si的类别,P(class(Si))为随机选取样本子集Si类别的比例,Mj(C)表示类C∉class(Si)中第j个最近邻样本。经过归一化处理后,每个特征的取值都转换到[0,1]。
2个属性特征之间的相关性系数的计算如式(5)所示:
(5)

算法1Relieff-P算法
Input:入侵检测训练样本集U。
Output:新的特征集Fu。
φ=0;
for eachiinm;
U→Si;//随机选取样本子集Si。
U→nearSi→C∈class(Si);
for eachC∈class(Si);
计算A(L);
end;
U→nearSi→C∉class(Si);
for eachC∉class(Si);
计算B(L);
end;
计算φ[L];
end;
for eachiinL;
Fu=max{ρLi,Lj};
outputFu
3.2 NBSR入侵检测模型
训练集中各个类别的样本分布不均匀时,分类器容易倾向于大类别而忽略小类别[10,11]。本文将此特性应用于NBSR模型中,利用第1阶段朴素贝叶斯分类器将小样本过滤至第2阶段Softmax回归分类器。Softmax回归算法是1种用于解决多分类问题的机器学习算法,具有模型简单、可泛化、解释性强等特点,用于估计某种事物的可能性[12]。若处理多分类问题则需要计算每个样本归属于每个类别的概率。把输入映射为0~1的实数,并且归一化保证和为1,因此多分类的概率之和也刚好为1。
通过对网络入侵数据集及上述分类器特性的分析,本文将改进后的Relieff-P算法应用于数据处理当中,将朴素贝叶斯分类器和逻辑回归分类器组合成级联分类器。基于NBSR模型的入侵检测流程如下所示:
(1)网络入侵数据集预处理。
预处理主要是对原始数据集进行预处理,主要包括数据变换和数据标准化,从而达到适用于机器学习的目的。首先将原始数据集中的非数值型数据进行转换;然后对所有的数值型数据进行标准化、归一化处理。因数据集中异常数据对Pearson相关系数方法有影响,因此使用箱线图剔除离群数据。
(2)最优特征子集。
Relieff-P特征选择算法为数据集中每个样本种类选择最优特征子集,最优子集为各子集的并集。在计算特征间的相关性时,重复的数据项只选其一参与Pearson相关性计算,又因朴素贝叶斯方法通过先验概率决策,故待相关性计算结束时,重复的数据项仍用来训练模型。将最优子集分别送入级联的分类器训练。特征选择过程无需在应用阶段运行,分类器只需使用其在训练阶段得到的最优特征子集即可。
(3)第1阶段朴素贝叶斯分类模型。
NB分类器训练主要是使用NB算法对包含Fuzzers、DoS、Exploits、Generic、Reconnaissance和Normal 6类数据的训练集进行训练,得到分类模型。
第1阶段分类模型的算法步骤如下所示:
Step1将样本X={A1,A2,…,An}表示为n维特征向量。
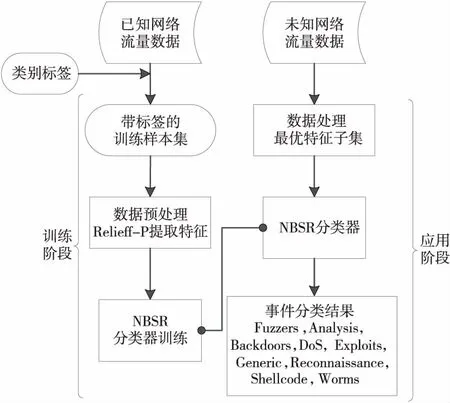
Step2假设有m个类别C1,C2,…,Cm。将X作为未知入侵行为样本,即没有类别标签。朴素贝叶斯分类将未知网络行为分配给Ci类别,并且只有在P(Ci|X)>P(Cj|X)的条件下才属于最大可能类别,此处1 (6) 由于P(X)和C的取值无关,因此只需要根据训练集数据来估计所有的P(X|Ci)P(Ci)即可。 Step3若数据集具有多个属性,P(X|Ci)的计算开销将会巨大。为了减少计算开销,进行条件独立性假设(Conditional Independence)。假设已经给出了样本类别标签,不同维度特征的取值之间是相互独立的,这意味着任何2个属性之间没有依赖关系: (7) Step4通过训练样本来估计概率P(X|C1),P(X|C2),…,P(X|Cm)。由式(7)可知,如果存在P(Ck|X)=max{P(C1|X),P(C2|X),…,P(Cm|X)},则X∈Ck。 Step5由上述结果得到NBSR第1阶段的分类器: (8) (4)第2阶段Softmax回归分类模型。 Softmax回归分类器训练主要是使用Softmax回归对包含Normal、Backdoors、Analysis、Shellcode和Worms 5类数据的训练集进行训练,得到分类模型。 第2阶段模型的算法步骤如下所示: Step1现有样本Ai∈{A1,A2,…,An},以及训练样本集的类别标签y。 Step2假设标签y总共有K个类别,对于给定的测试样本Ai,需要使用1个假设函数估计样本Ai属于j类别的概率,概率最大的类别就是该样本的类别。对应的Softmax 函数形式如下所示: (9) Step3对应的似然函数L(θ)表示为: (10) 其中,1(y=j)是一个指示性函数,1{true}=1,1{false}=0。 Step4对似然函数L(θ)取对数,可以得到所谓的对数似然函数l(θ): (11) Step5损失函数为: (12) Step6由上述结果得到NBSR第2阶段的分类器: (13) (5)NBSR分类器结构。 NBSR分类器通过级联2个不同的分类算法进行分类,每个分类器用于分类的类别不同,级联2个分类器的结构如图1所示。 Figure 1 NBSR classifier structure图1 NBSR分类器结构 这里NB分类器将数据分为6类,被分为Normal的数据进入Softmax回归分类器,Softmax回归分类器再进行后续分类。由于Backdoors、Analysis、Shellcode、Worms这4类样本数无论在训练集还是测试集中所占比例都较小,且朴素贝叶斯对不平衡数据的处理效果欠佳,正是由此将错分的类别送入下1级分类器,故将NB分类器当做第1分类器,Softmax回归分类器为第2分类器,最终得到9个入侵攻击大类的分类结果。 整个NBSR模型共分为训练和应用2个阶段。在训练阶段,通过Relieff-P对带标签的训练样本集提取特征,得到新的特征子集用于训练NBSR分类器;在应用阶段,将数据处理后送入训练好的NBSR分类器进行分类。通过一系列入侵检测流程的处理,最终得出合理的网络事件归类集合。该模型的入侵检测流程如图2所示。 Figure 2 Improved intrusion detection process图2 改进的入侵检测流程 本文选用UNSW-NB15数据集训练入侵检测模型。KDD CUP 1999 Data是1999年举行KDD竞赛时采用的数据集,距今有20年历史,网络攻击样本中缺少已知的入侵行为,且未知的入侵行为会使误用检测模型提高误检率。而UNSW-NB15数据集的原始网络数据包是由澳大利亚网络安全中心(Australian Centre for Cyber Security)网络范围实验室于2015年创建的,利用Tcpump工具捕获100 GB的原始流量[13,14],最大的特点就是包含了当代隐蔽攻击方式,能够比较完全地反映当代网络流量的真实状况。表1是2种数据集的对比。 Table 1 KDD CUP 1999 Date vs.UNSW-NB15表1 KDD CUP 1999 Date与UNSW-NB15对比 UNSW-NB15数据集有9个系列的攻击:Backdoorsh、Exploits、Shellcode、Fuzzers、DoS、Generic、Analysis、Worms 和Reconnaissance。表2所示为UNSW-NB15数据集中的攻击种类分布。 由表1数据可知,UNSW-NB15数据集的攻击环境更具有真实性。表2所示为UNSW-NB15数据集网络事件中9种类型的记录数目以及分别在UNSW-NB15入侵检测数据集的Training-set和Testing-set中的分布情况。 针对本次实验搭建的环境平台所使用的操作系统为64位Windows 7 旗舰版sp1,CPU频率为2.4 GHz,内存为4 GB,300 GB硬盘存储,编程工具为Python 3.6,入侵检测数据集则使用上述的UNSW-15数据集,实验结果如表3所示。 Table 2 Distribution of attack types in Training-set and Testing-set datasets表2 Training-set和Testing-set数据集中攻击种类分布 Table 3 Processed feature subsets表3 处理后的特征子集 表3所示为处理后的特征子集,实验结果表明Relieff-P算法能有效地对数据进行降维。 基于NBSR模型的入侵检测技术的检测效率分析以及改进前后算法的准确率TP(True Positive Rate)比较结果如图3和图4所示。 由图3和图4可看出,本文方法在Analysis、Backdoors、Worms、Shellcode、Exploits和Reconnaissance等类别中,准确率有明显的提升。 将本文提出的入侵检测技术与基于其他分类模型的入侵检测技术做了系统比较,从表4的实验数据中可以看出,NBSR模型与其他入侵模型相比,在精度(Precision)、F1值和误检率FPR(False Positive Rate)方面,都表现出了更好的效果。 Figure 3 Comparison of true positive rate (TP) before and after the first stage of the improved algorithm 图3 第1阶段改进前后算法的准确率(TP)比较 Figure 4 Comparison of true positive rate (TP) before and after the second stage of the improved algorithm 图4 第2阶段改进前后算法的准确率(TP)比较 Table 4 Efficiency comparison intrusion detectionbetween this method and other methods MethodsPrecisionRecallF1 ScoreFPRLR82.2795.3789.3422.65NB72.7991.2080.7838.62DT81.2296.3489.1124.36SVM73.5095.1883.8941.54本文方法87.3993.6891.6215.62 Relieff-P特征选择算法将特征之间的相关性加入到特征的评价中,当迭代次数或最近邻样本数发生改变时,不相关特征的权重始终保持不变。Relieff-P特征选择算法能较好地去除无关特征,具有稳定、易扩展、有效性强、运行效率高的特点。 针对互联网中海量而复杂的网络攻击事件,入侵检测行为其实是一系列不确定性行为过程的1个组合,鉴于朴素贝叶斯定理最适合解决概率性事件,将朴素贝叶斯决策理论分类器运用到入侵检测技术当中是完全可行的。本文将Softmax回归分类器与朴素贝叶斯分类器级联,提出了基于NBSR模型的入侵检测技术,通过实验测试表明其可以取得较好的分类效果,与其它分类方法的分类效果进行比较时,也表现出了较好的优势。但是,本文方法各方面的性能仍然有很大的提升空间,如何能够更准确地识别未知攻击类型需要进一步研究。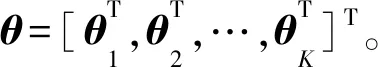

4 仿真实验与分析
4.1 UNSW-NB15数据集

4.2 实验结果与分析
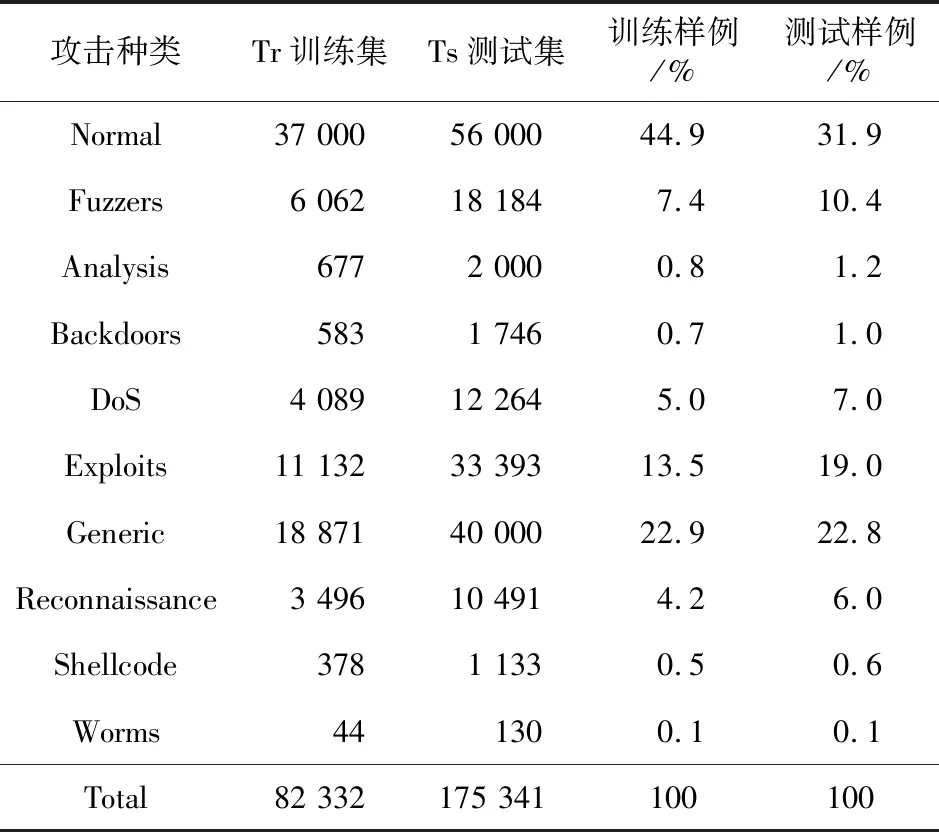
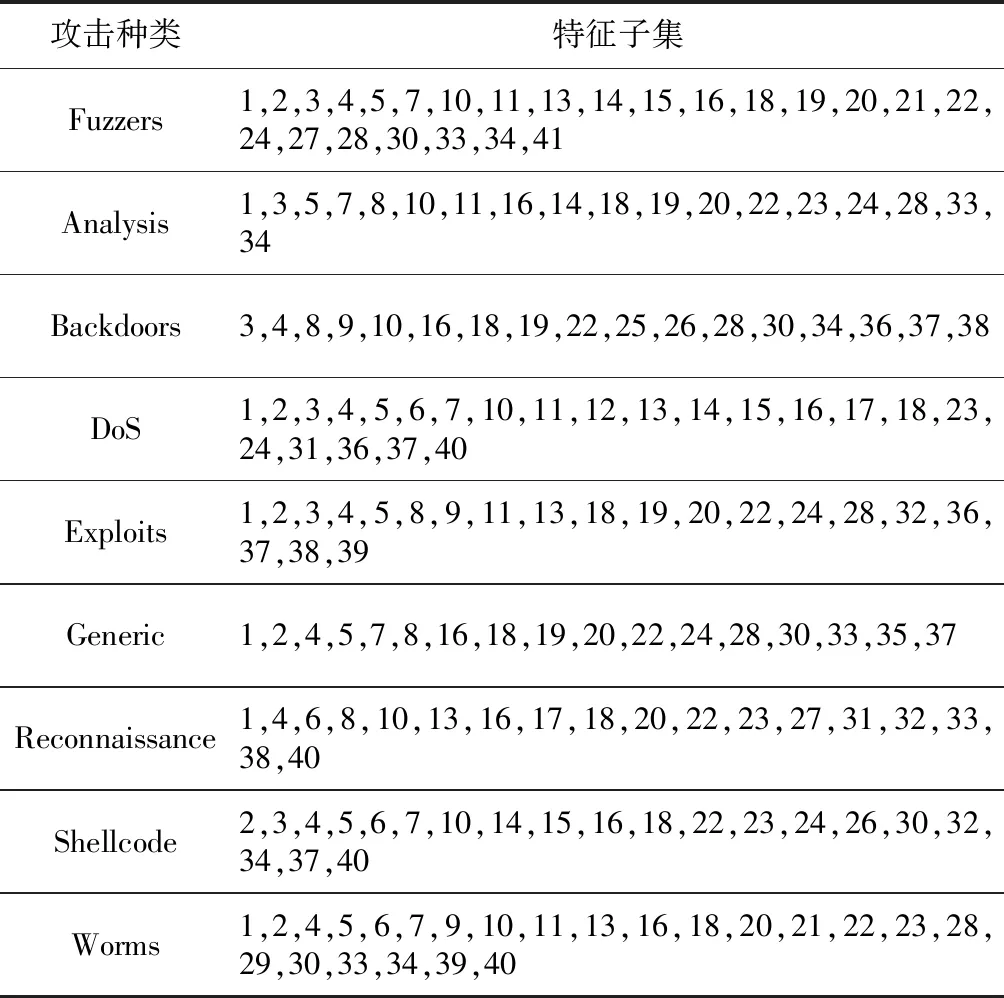
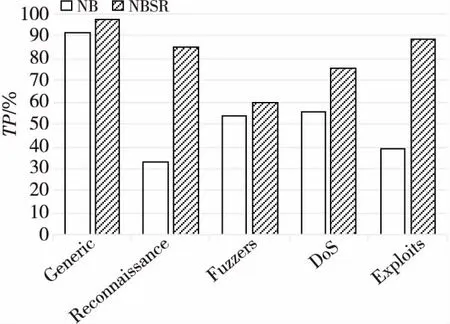
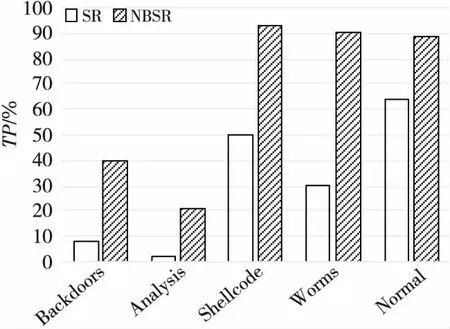
表4 本文方法与其他几种方法的入侵检测效率比较%
5 结束语
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
法律方法(2021年4期)2021-03-16
南京大学学报(数学半年刊)(2020年1期)2020-03-19
吉林大学学报(理学版)(2018年4期)2018-07-19
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
都市丽人(2015年4期)2015-03-20
航天返回与遥感(2014年5期)2014-07-31
