
基于Transformer的DGA域名检测方法*
2020-03-26 10:56房一泉
计算机工程与科学 2020年3期
张 鑫,程 华,房一泉
(华东理工大学信息科学与工程学院,上海 200237)
1 引言
近年来WannaCry等恶意软件爆发,对政府、能源、制造业等关键基础设施造成重大损失[1]。恶意软件使用随机生成的DGA(Domain Generation Algorithm)域名,与C&C(Command and Control)服务器建立通信连接,躲避安全软件检测。文献[2]系统地分析了43个恶意软件,超过半数的恶意软件采用DGA作为唯一的通信方式,因此准确有效地检测DGA域名对于恶意软件的发现具有重要意义。
基于机器学习的DGA域名检测方法通过提取域名的统计信息[3]和流量特征[4]对DGA域名进行检测,存在误报率较高、精确率低等问题。引入深度学习等方法后,DGA域名检测精确率获得了较大的提高;文献[5]用长短期记忆网络LSTM(Long Short-Term Memory)检测DGA域名,对随机性高、长度较长的DGA域名检测获得了高精确率;文献[6]用LSTM与域名注册信息结合的方式,有效地区分类似英语单词的DGA域名,如suppobox、matsnu种类;文献[7]用门控循环单元结合注意力机制,关注域名序列中随机性高的字符组合,提高了对低随机 DGA 域名的识别率。
基于循环神经网络的DGA检测方法对正常的缩略域名有较高的误报率,如将“jd.com”识别为DGA域名。使用文献[7]的方法对本文域名数据集进行检测,误报为DGA的域名中缩略域名占64.5%。从单字符的角度分析,缩略域名具有较高的随机性,其通常来自于单词缩写,因此事实上字符间存在长程依赖性;而基于循环神经网络的检测方法只对相邻字符计算,从而间接获取长程依赖性,不能有效地辨别缩略域名。
文本翻译任务中的Transformer[8]模型能提取句子中单词间的指代关系等,通过自注意力获得单词间的依赖性,可以提取域名中单个字符和所有字符间依赖性;其可以通过多头映射将域名线性映射到不同子空间内,计算多个子空间内域名字符的依赖性,提取字符间的更多层信息。本文在Transformer模型的编码过程中,提出用LSTM对域名编码进行改进,以更好地捕获字符位置信息。由此构建基于Transformer的DGA域名检测方法MHA(Multi-Head Attention based DGA detection method)。对比实验表明,该方法在获得更高精确率的情况下,可以有效降低缩略域名的误报率。
2 域名字符依赖性分析
2.1 缩略域名
缩略域名的字符是单词或拼音的缩写,保留其中最具代表性的字符,期望与单词或拼音表达相同的语义信息,因此保留字符构成了缩略域名的主体结构。
缩略后域名的随机性增加,如武汉大学域名:whu.edu.cn,将“wuhanuniversity”缩略为“whu”。“wuhanuniversity”的相对熵为0.86,而“whu”的相对熵为1,接近DGA的平均熵0.98[7]。缩略域名具有较高的随机性,增加了DGA域名检测难度。
单个字符并不能表达出具体语义,多个字符组合才体现出语义信息,如域名“hljswt”中“hlj”3个字符表示”HeiLongJiang”。字符“h”“l”和“j”,分别来自于“hei”“long”和“jiang”的第1个字符,缩略前字符间不是直接相邻的,其依赖性需要从全称域名或缩略域名中学习。例如,可以从“heilongjiangfupin”或“hljgvc”中学习到字符“h”“l”和“j”间的依赖性。因此,可以从全称域名中学习不相邻字符的依赖性,用于缩略域名的检测。
2.2 域名字符间依赖性分析
采用点互信息PMI(Pointwise Mutual Information)[9]计算域名中字符的依赖性[10]:
其中,p(x,y)为字符x和y同时出现的频率;p(x)为字符x出现的频率;p(y)为字符y出现的频率。图1为DGA域名、缩略域名、全称域名字符间点互信息。
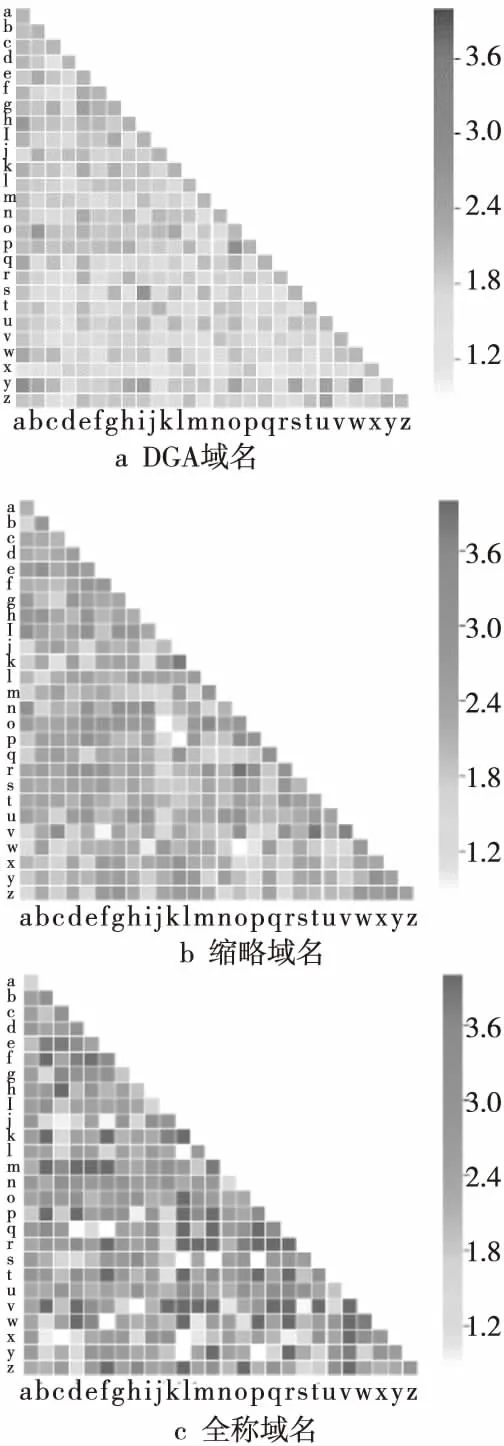
Figure 1 Pointwise mutual information of domain name characters图1 域名字符间点互信息
图1表明DGA域名字符间PMI差别很小,缩略域名的PMI位于DGA域名和全称域名之间,相对DGA有明显差异,说明缩略域名具有较强的依赖性。
表1中,全称域名是单词组合,其中固定组合的字符同时出现的频率高,字符依赖性大;非固定组合中字符同时出现的频率低,字符依赖性弱;导致全称域名依赖性方差大。而缩略域名用到的字符组合保持了频率高、依赖性强的特点,而被缩略的字符频率低、依赖性弱,导致方差远大于DGA域名的方差,均值接近于DGA域名的均值。
DGA域名字符间依赖性差别很小,真实域名中字符依赖性差别较大,因此本文提出提取域名字符间的依赖性,突出依赖性强的字符,从而在识别过程中降低误报率。
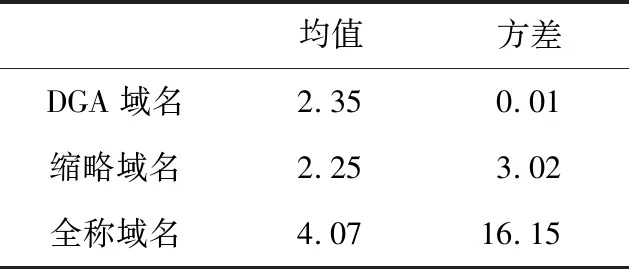
Table 1 Statistical characteristics of PMI between domain name characters表1 域名字符间点互信息的统计特征
以“heilongjiang”为例,计算合法域名中含“h”“l”“j”3个字符的域名的PMI,如表2所示,“hl”“lj”“hj”的PMI值远高于其他字符组合的PMI值,依赖性明显强于其他字符。这说明在真实域名中存在一定固定结构的字符对,若在检测域名时,突出固定字符对的依赖性,可提高检测效果。
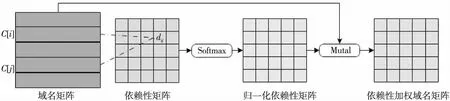
Figure 2 Character dependence computation by self-attention图2 自注意力计算字符依赖性
Table 2PMIof legitimate domain name
表2 合法域名PMI

hjjlhlcjhtjtlthglf35.2431.2430.257.256.506.506.505.525.50
3 基于Transformer的DGA检测模型
Transformer模型可以计算句子中单词间的依赖关系,被广泛应用在自然语言处理中。可基于Transformer在域名检测中提取字符间依赖性,获得域名内部的字符组合结构,解决缩略域名误报率高的问题。
3.1 Transformer模型
Transformer模型由多个相同的层组成,每个层包含1个多头自注意力机制和前馈网络。模型仅通过自注意力机制计算输入x=(x1,x2,…,xm)和输出y=(y1,y2,…,ym),将句子中的每个词和该句子中的所有词进行注意力计算,目的是学习句子内部的依赖关系,捕获句子的内部结构。
注意力机制用于提高局部关注,可描述为将查询(query)和1组键(key)值(value)对映射到输出,表示为:
Attention(Q,K,V)=softmax(QKT)V
其中,Q,K,V均为输入矩阵,分别代表查询、键和值。在key-value键值对与查询语句query的注意力计算中,key-value为源语句,query为目标语句,即计算目标语句与源语句之间的关系。当源语句与目标语句相同时,计算的便是语句自身的内部关系。
为使模型能够充分提取内部关系,研究人员引入了多头注意力,多头注意力允许模型在不同的位置共同关注来自不同表示子空间的信息[8]。多头注意力对输入的query、key和value进行多次线性映射,再对线性映射后的值进行注意力计算,得到多个注意力结果连接,再次进行线性映射,得到多头注意力输出,表示为:
MultiHead(Q,K,V)=
Concat(head1,…,headh)Wo
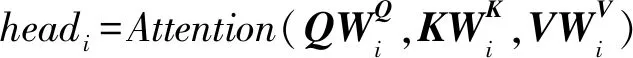
3.2 基于自注意力的字符依赖性计算
PMI计算字符间的依赖性只能根据整体域名样本的统计特征,不具有学习能力。Transformer模型使用自注意力计算字符间的依赖性,可通过模型训练学习到域名字符间依赖性,如图2所示。
将域名中每个字符与该域名中所有字符进行依赖性计算:
dij=C[i]×C[j]
其中,C[i],C[j]分别是第i个字符和第j个字符在域名矩阵中的表示。dij为第i个字符和第j个字符间的依赖性,实现了忽略字符间隔的依赖性计算。
字符间的依赖性用Softmax归一化,得到归一化(权重)依赖性矩阵D:
D=Softmax(C·CT)
其中,D是权重,与域名矩阵C相乘得到依赖性加权的域名矩阵A∈Rl×l(l为域名长度):
A=D·C
图3为域名“bjut”和域名“beijing”的字符依赖性矩阵,颜色越深表明依赖性越强。2个域名都包含关键字符“b”和“j”,语义都为北京,2个字符在域名中的间距不同,模型将2个域名中字符“b”和“j”的强依赖性都检测出来了,这表明模型能够计算字符间长距离依赖。
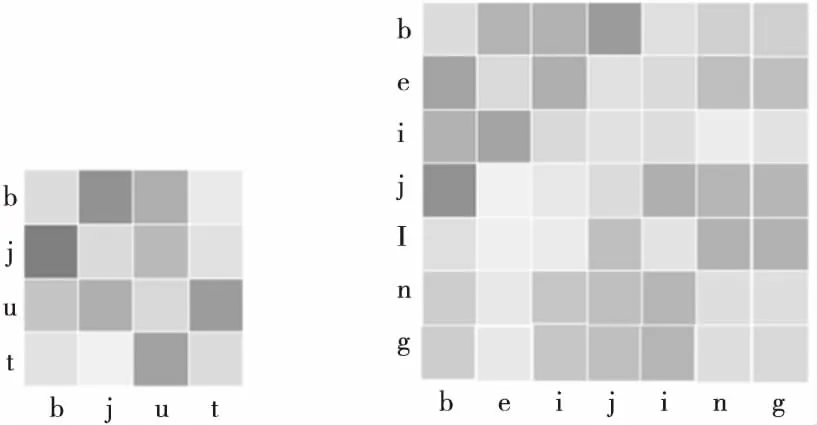
Figure 3 Domain name character dependence图3 域名字符依赖性
3.3 LSTM编码
Transformer模型中的位置编码基于自定义的三角函数实现,表示为:
PE(pos,2i)=sin(pos/100002i/d)
PE(pos,2i+1)=cos(pos/100002i/d)
其中,pos为字符在域名中的位置序号,i∈(0,d)为维度,d为字符嵌入维度。
该位置编码不具有学习能力,仅提供模糊的相对位置信息[11],对域名字符进行位置编码时,位置编码信息和字符无关,只和字符出现的位置有关,使得编码向量不能有效地结合字符的上下文信息和位置信息。为此,本文引入LSTM对域名进行编码,以代替位置编码。
LSTM输入门将向量化后的字符有选择地输入到神经元中,遗忘门控制对上1时刻学习到的字符信息的遗忘程度,在t时刻存储器内存储该时刻前学习到的字符向量St-1。遗忘门的输入为向量Gt,Gt由当前时刻输入的节点向量xt,与上1时刻输出向量ht-1拼接而成,输出门得到当前字符编码,包含了该时刻前学习到的字符向量St-1和当前字符向量xt。
LSTM字符编码包含了字符级的上下文信息和位置信息,从而将字符信息和字符位置信息结合起来。
3.4 DGA域名检测方法MHA
本文提出基于Transformer模型的DGA域名检测方法MHA,如图4所示,由LSTM编码、多头自注意力机制、Software组成,分类器输出结果。
Transformer模型中编码器由6个相同的层组成,每层都包含1次多头自注意力计算。在自然语言处理中,单词量很大,因此需要多次运算获得单词间的依赖信息;鉴于域名中字符种类较少,本文只使用单层的多头自注意力机制来捕获字符间的依赖性。

Figure 4 Diagram of DGA domain name detection method (MHA)图4 DGA域名检测方法MHA框图
(1)编码。
通过嵌入层训练,得到域名字符向量化表示:
C={C1,C2,C3,…,Cl}
其中,C为域名矩阵,Ci为单个字符的向量化表示,l为域名长度。并用LSTM层对字符向量编码,得到域名编码。
(2)多头自注意力。
多头自注意力计算中,每1头即为1次线性映射。对域名编码E进行多次线性映射,得到不同子空间内域名表示Ei。在每个子空间内对Ei进行自注意力计算,其依赖性权重加权后域名表示为Ai。对提取的Ai进行连接,线性变换后得到矩阵α:
α=concat(A1,A2,A3,…,Ah)W
其中,W∈Rhd×1为参数矩阵,Ai为不同头计算的依赖性加权矩阵,α∈Rl×l为多头自注意力计算后域名的矩阵表示,concat为连接函数。
(3)全连接与Softmax。
将α输入全连接层降维后,再输入Softmax层进行分类检测,域名分类得到域名预测标签(DGA或正常域名):
∂=Softmax(Dense(α))
定义训练损失函数loss为真实标签的负对数似然率:
loss=-∑logP∂,I
其中,I是域名真实标签,P∂,I为∂被模型分类为I的概率。
4 实验
4.1 数据集
实验数据为2级域名,其中真实域名来自网络,主要为各地方政府机关、学校等包含地域信息的域名;DGA域名来自网络安全公司系统中无法检测的DGA域名。表3包括域名数据集的域名种类、数据集大小、最大最小长度等信息,数据集的80%数据用于训练模型,10%用于模型训练时验证,10%用于最终测试。训练轮数最大为30,验证集上若连续2轮准确率没有提升则结束模型训练。
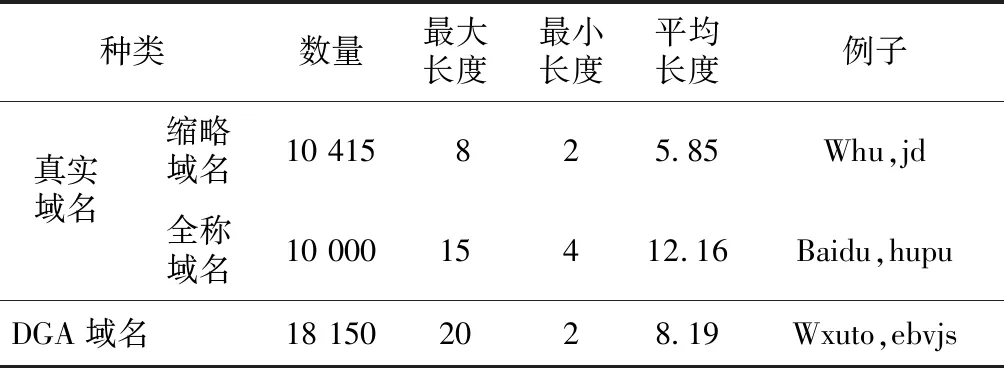
Table 3 Domain datasets表3 域名数据集
4.2 实验结果与分析
4.2.1 与传统方法比较
将本文MHA方法与Transformer方法、ATT-GRU方法[7]、逻辑回归(LR)方法、支持向量机(SVM)方法进行对比,其中Transformer模型使用模型自带的位置编码,其他结构和MHA完全相同。本文方法和Transformer、ATT-GRU方法的参数选择相同,包括嵌入层维度128维,LSTM选取128个单元,Dropout率均为0.5。
对模型评价采用精确率Precision和召回率Recall以及F1值。精确率反映模型对DGA域名的查准率,召回率反映模型对DGA域名的查全率,F1值综合考虑模型的有效性。
实验结果如表4所示,MHA方法的F1值为0.970 2,是所有方法中最好的,表明MHA模型的整体表现最好。传统应用统计特征的LR方法和SVM方法各项指标最差,说明基于统计方法不能有效区分DGA和缩略域名。
ATT-GRU的精确率和召回率均低于基于Transformer的2种方法,说明缩略域名相邻字符间的关联性弱,基于循环神经网络的方法不适合检测缩略域名。另外,MHA的召回率和精确率比Transformer分别提高了1.67%和1.05%,表明MHA可学习的位置编码能够有效地表示域名字符的上下文信息,提升了分类效果。

Table 4 Precision,Recall and F1 score of different methods表4 不同方法的精确率、召回率和F1值
4.2.2 误报率分析
在保证精确率的前提下,误报率是安全系统考虑的重点。误报的发生会造成大量系统资源的误消耗,长期的高误报会降低安全检测的可靠性。
本文分别对缩略域名、中文全拼域名和DGA域名进行检测。评价标准为误报率,计算方式为:
本文将DGA域名标记为正样本,真实域名标记为负样本。TN表示被模型分类正确的负样本,FP表示被模型分类错误的正样本,i表示为缩略域名或全称域名。
由表5可知,缩略域名的误报率均高于全称域名的,表明缩略域名较全称域名更难检测。从方法分析,基于深度学习的方法在2类域名上的表现均好于传统机器学习的方法,深度学习方法具有更好的学习能力。MHA方法在5种方法中表现最好,说明注意力机制解决了缩略域名和DGA域名难以区分的问题,从而降低了模型的误报率,提升了模型的可靠性。
MHA方法在缩略域名误报率上比ATT-GRU降低了2.98%,说明基于依赖性检测DGA域名的方法解决了基于随机性方法对高随机缩略域名误报率高的问题。
对比Transformer,MHA方法在2类域名误报率上分别降低了1.19%和0.56%,说明基于LSTM的编码方式能够有效地获取字符位置信息,对于缩略域名误报率的降低幅度更大。
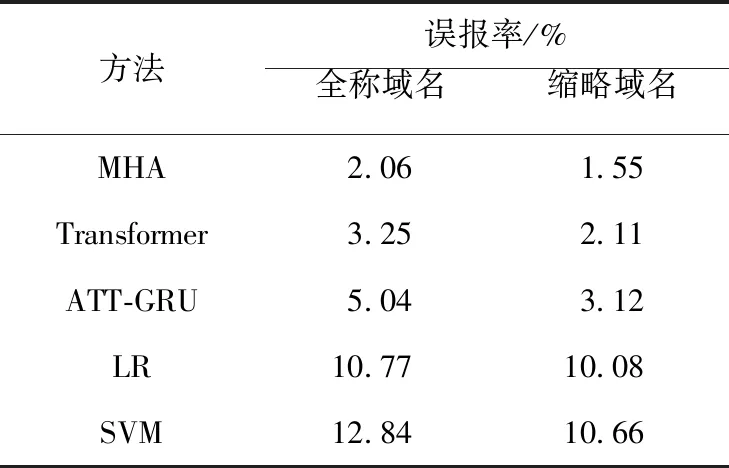
Table 5 Detecting results comparison of different domains name detection methods表5 不同种类域名检测结果比较
4.2.3 多头注意力分析
不同头(Head)数量在测试集上的准确率和损失值的变化如图5所示。
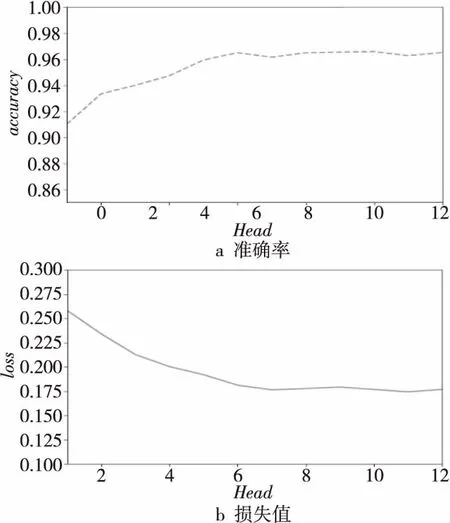
Figure 5 Trends of accuracy and loss value图5 准确率与损失值变化趋势
随着头数量的增加,准确率随之上升,损失值随之下降。当头数量达到6时,准确率和损失值趋于平稳,此时增加头的数量无法提升模型的准确率,即增加对域名矩阵进行线性映射的次数,无法在增加的线性空间内提取出有效的字符依赖性。因此,本文中选取头数量为6。
在不同头(Head)对应的子空间内,对域名进行自注意力运算得到字符间依赖性权值,如图6所示是本文方法对黑龙江科技厅域名“hljkjt”的检测结果。
图6a是头为2时计算的域名字符依赖性,图6b是头为5时计算的域名字符依赖性。前者检测出字符“h”“l”和“j”间的依赖性较强,后者检测出“k”“j”和“t”间的依赖性较强,2个头分别检测出代表黑龙江的字符“hlj”和代表科技厅的字符“kjt”。不同的头可检测域名内不同字符依赖性,多头可从更大的线性空间内检测字符依赖性,可以充分提取域名内字符依赖性。
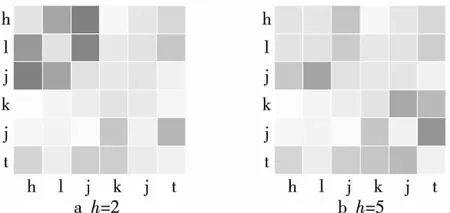
Figure 6 Character dependence in different subspaces图6 不同子空间内字符依赖性
4.2.4 训练中准确率与损失函数值分析
图7中,MHA在第24轮训练收敛,比Transformer收敛所需的轮次多。因为MHA使用LSTM计算字符编码,而Transformer使用函数计算位置编码,无需学习字符位置信息,MHA方法降低了时间效率。
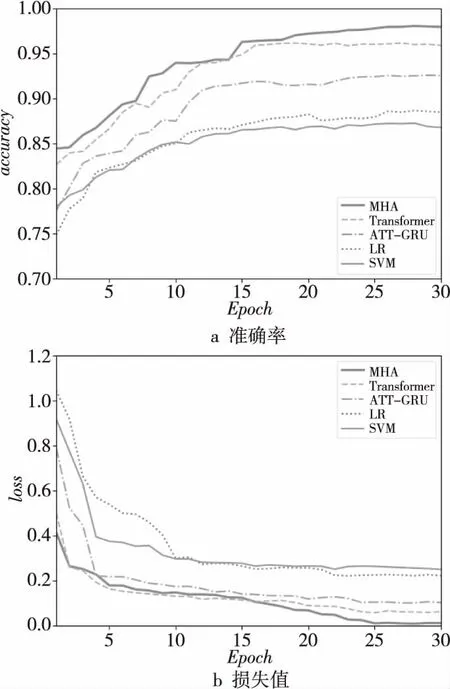
Figure 7 Training accuracy and loss value trends图7 训练准确率与损失值变化趋势
由图7a可知,MHA方法的准确率从第15轮就提高到95%,之后又缓慢提高到98.54%;Transformer在第15轮收敛,其准确率达到96.98%;ATT-GRU经过25轮后其准确率提高到93.7%,MHA的准确率最高。图7b中,MHA和Transformer在初始阶段损失值明显低于ATT-GRU的,多头注意力机制更适合处理域名分类任务。在15轮后,Transformer的损失值趋于稳定,MHA则有明显降低,此时LSTM编码优于Transformer的位置编码。
综合准确率和损失函数,MHA中使用LSTM对域名编码,结合Transformer中的多头注意力机制能更好地分辨缩略域名和DGA,有助于其更好地收敛。
5 结束语
本文分析了合法域名和DGA域名中字符间依赖关系的不同,得到了缩略域名字符间长程依赖性的计算方法,基于此,提出了基于Transformer模型的DGA检测方法(MHA方法)。通过LSTM提取字符信息改进和替代Transformer中的位置编码。实验表明,MHA方法考虑和学习到了字符间的依赖性,相比现有方法,较好地提高了DGA域名识别率,降低了对缩略域名的误报率,整体模型的评价优于现有方法。
猜你喜欢
湖南文理学院学报(自然科学版)(2022年2期)2022-05-06
煤气与热力(2021年6期)2021-07-28
延河·绿色文学(2020年6期)2020-09-10
设备管理与维修(2020年14期)2020-08-12
长江丛刊(2018年23期)2018-11-14
商情(2017年38期)2017-11-28
中国洗涤用品工业(2017年2期)2017-04-16
现代电子技术(2015年21期)2015-11-09
中国医疗美容(2015年1期)2015-07-12
中国医疗美容(2015年1期)2015-07-12
