
基于密集分割网络的车道线检测方法*
2020-03-26 10:56丁海涛程旭升
计算机工程与科学 2020年3期
丁海涛,孙 锐,程旭升,高 隽
(合肥工业大学计算机与信息学院,安徽 合肥 230601)

Figure 1 Diagram of the lane line detection method图1 车道线检测方法框图
1 引言
现代智能汽车都配置了车道偏离警告系统LDWS(Lane Departure Warning System)和车道保持辅助系统LKAS(Lane Keeping Assist System)。其中,车道线检测是车道偏离警告系统LDWS和车道保持辅助系统LKAS中的关键技术。目前,车道线检测方法大体分为基于特征、基于模型和基于深度学习的检测方法。基于特征的方法通常利用车道线的颜色特征[1,2]、纹理特征[3]和几何特征[4,5]等,再与霍夫变换[6 - 9]或卡尔曼滤波器[9 - 12]相结合检测车道线,识别车道线后,利用后处理滤除误检得到最终的车道线。基于模型[13 - 17]的检测方法首先要估计道路的数学模型,利用图像信息确定道路数学模型的参数。通常,这些基于特征和基于模型的检测方法容易受到车辆遮挡和地面污损等不良天气道路场景的影响。随着深度学习在计算机视觉领域的成功运用,国内外学者提出了一些基于深度学习的车道线检测方法。例如,Li等人[18]使用卷积神经网络CNN(Convolutional Neural Network)和循环神经网络RNN(Recurrent Neural Networks)进行车道线检测。作者在CNN提取道路特征信息的基础上,结合RNN进行车道线检测。Lee等人[19]提出一种多任务卷积神经网络的车道线检测算法。作者采集了多种环境下的车道线和道路标志,利用特殊的grid标注方法标注消失点,再利用灭点引导网络VPGNet(Vanishing Point Guided Network)进行车道线检测。文献[20]提出了一种新的卷积神经网络用于车道线检测,这种卷积神经网络通过切片到切片之间的卷积提取特征信息,适合学习连续的、长的形状结构。这些基于深度学习的车道线检测方法虽然有着较好的性能,但是还不能很好地解决车辆遮挡和地面污损问题。
针对车辆遮挡和地面污损问题,本文将车道线检测视为连续细长区域实例分割问题,提出了一种基于密集分割网络DSNet(Dense Segmentation Network)的车道线检测方法。首先,在SegNet网络模型[21]的基础上,使用稠密块[22]构建了1个密集分割网络,该网络由1个提取实例特征的下采样路径和1个恢复输入图像分辨率大小的上采样路径组成。所构建的深度分割网络在不同层之间建立了连接关系,使得该网络具有重复使用特征的特性,减少了网络的加深导致细长区域实例特征信息的损失,提高了图像分割的准确性。其次,为了使得车道线边界更为准确,该方法引入了邻近AND运算和Meanshift聚类算法,对密集分割网络的输出进行处理,以减小非车道线像素的干扰。最后,为了能够对车道线进行实例分割,本文制作了一个与图森训练集对应的车道线实例分割数据集,结合图森训练集一起对该网络进行端到端的训练。实验表明,本文提出的方法能很好地解决车辆遮挡和地面污损的问题,具有较好的鲁棒性和实时性,同时还能确定检测的车道线的数量。
2 车道线检测方法
本文提出的车道线检测方法逻辑框图如图1所示,该方法可以通过端到端的训练密集分割网络学习到道路场景中车道线的实例特征,对因车辆遮挡和地面污损导致的车道线不连续的区段进行预测,输出每个车道线和背景像素集合的RGB图像IS;再通过邻近AND运算设定合适的阈值过滤掉图像IS中的非车道像素得到车道线二值分割图IB,获取图像IB中像素值为“1”的位置,从图像IS中标记相同位置的像素点,使用Meanshift聚类算法对标记的像素点进行聚类,得到以不同颜色区分不同车道线实例的车道线实例分割图。
2.1 密集深度分割网络
SegNet由1个下采样网络、1个上采样网络和1个像素分类层(Softmax)组成。下采样路径采用13层的视几何组网络VGG(Visual Geometry Group Network)网络作为语义特征的提取器,将提取到的特征通过与下采样路径具有相同层数的上采样路径恢复至输入图像分辨率大小,实现端到端的输出。
SegNet网络中的层与层之间是顺序连接的,随着网络的加深,该网络能较好地学习到相对大点的区块的实例特征,但是细长区域的实例特征信息会有较大的损失。为了提高SegNet网络模型对细长区域分割的性能,使其适用于车道线检测,本文在该网络模型的基础上,用稠密块构建密集分割网络,结构如图2所示,该网络也是由1个下采样路径和1个上采样路径组成。稠密块结构如图3所示,该结构为了改善不同层之间信息的流动,采用了一种将任何一层与后面所有层建立密集的连接的方式,使得特征和梯度能够更加有效地传递。因此,第l层会接受前面所有层的特征图x0,x1,…,xl-1作为输入:
xl=Hl([x0,x1,…,xl-1])
(1)
其中,x0,x1,…,xl-1为0,1,…,l-1层的特征图,Hl(x)为第l层的非线性函数。本文的密集分割网络采用具有在不同层间建立连接方式的稠密块重新构建了SegNet的下采样路径和上采样路径,使得网络能够充分利用特征,以相对较少的参数提高提取车道线实例特征和恢复特征图分辨率的性能,同时还能使得梯度的传递更加有效,让网络在无需使用预训练参数的情况下变得更加容易训练。

Figure 2 Structure of dense segmentation network 图2 密集分割网络结构

Figure 3 Dense block structure 图3 稠密块结构
在下采样网络中,如图4a和图4b所示,稠密块中的层由批量正则化(Batch Normalization)、ReLU激活函数、卷积和Dropout组成,过渡层由批量正则化、ReLU、卷积、Dropout和大小为2×2的非重叠滤波窗口执行最大池化(Max Pooling)操作组成。由于最大池化操作会降低特征图的分辨率,造成边界信息损失,因此在最大池化操作之前,需要存储特征图中的边界信息。为了更加有效地保留特征图中的边界信息,只需要存储最大池化索引,即滤波窗口中最大特征值的位置。虽然这种内存存储方式会导致精确度有轻微损失,但是可以提高内存利用率,缩短运行时间。
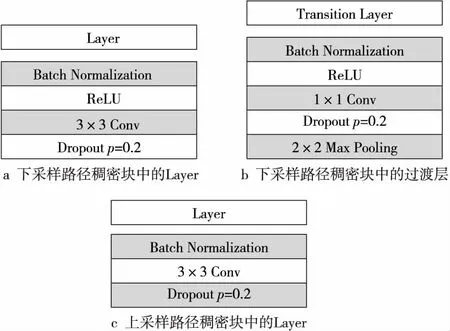
Figure 4 Structure of layer in upsampling and downsampling path图4 上、下采样中层的结构图
在上采样网络中,如图4c所示,稠密块中的层由批量正则化(Batch Normalization)、卷积和Dropout组成。上采样过程如图5所示,图中a~d为对应像素的像素值,该过程用原先存储的对应的最大池化索引对输入的特征图进行上采样,将道路场景中的车道线分割出来。
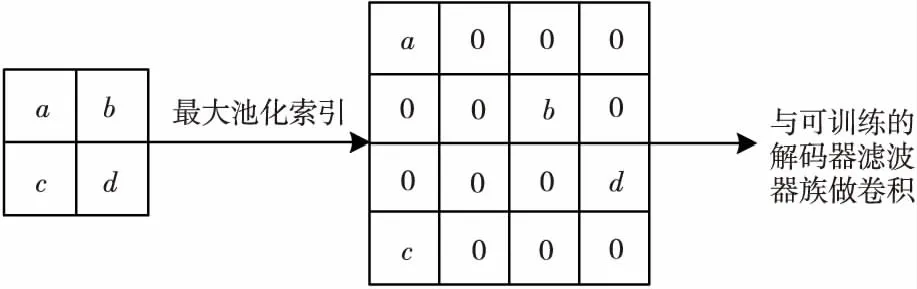
Figure 5 Upsampling图5 上采样
2.2 邻近AND运算
密集分割网络预测的车道线边界有模糊的现象,因此本文增加了邻近AND运算。该运算先将图像IS灰度化,使用查找垂直和水平线的Sobel算子对灰度图像执行梯度测量查找边缘信息。再设定一个合适的阈值th,根据式(2)将灰度图像IG1和IG2进行二值化得到IB1和IB2:
(2)
邻近AND运算的数学表达式如式(3)所示,它能使二值图像IB1和IB2中车道线邻近的共同特征更为清晰,并过滤掉非共同部分的特征,得到像素值为1和0的二值图,其中像素值为1表示车道线,像素值为0表示背景。
(3)
其中,k为邻近参数。

Figure 6 Images and their corresponding lane line segmentation instances in the tuSimple training set图6 图森训练集中图像和与之对应的车道线实例分割图像示例
2.3 Meanshift聚类算法
为了减小图像IS中非车道线像素的干扰,得到边界线清晰的RGB车道线实例分割图,本文采用Meanshift聚类算法对图像IS中像素值被标记为1的像素进行聚类。Meanshift聚类算法是一种无参数概率密度估计算法,它不需要预先知道聚类的类别数,同时对聚类的形状也没有限制。假设在一个d维空间Rd中给定n个数据xi,i=1,2,…,n,多元核估计密度函数的数学表达式如式(4)所示:
(4)
其中,K(x)为核函数,K(x)=ck,dk(‖x‖2),这里ck,d是一个归一化常数,h为窗口的宽度。该算法是根据偏移向量调整下次计算的位置,而不是逐个像素计算,这就会减少冗余计算,加快收敛速度。由于Meanshift算法还可以使用核函数,使得计算区域中各像素对应的权值不同,离中心越远权值越小,对结果的影响也就越小,在一定程度上可以避免车道线周围噪声的干扰,提高了抗干扰能力,确定检测的车道线数量。
3 实验与分析
3.1 图森数据集
图森数据集由7 000个一秒钟视频剪辑组成。其中,训练集有3 626个视频剪辑,每个视频剪辑中有20帧,最后一帧图像的标签信息无序地存储在json文件中。测试集由2 782个视频集组成,每个视频剪辑中有20帧。这些视频剪辑包括不同的天气环境和交通环境场景。本文将车道线检测视为车道线实例分割问题。在训练模型的时候,不仅用到带标记的图像,还需要与标签对应的车道线实例分割数据集。本文的实验用Python语言并且借助第三方库OpenCV依次读取每幅图像中的每条车道线标签信息,制作每条车道线的灰度值从220依次递减50的灰度图像,构建与之对应的车道线实例分割数据集,示例如图6所示。
3.2 实验结果与分析
本文实验采用的网络结构如图7所示,用图森数据集和对应的车道线实例分割数据集训练该网络。实验所使用的硬件平台为内存:16 GB,处理器:Intel(R)Core(TM)i7-6700K CPU@3.60 GHz x8,显卡:GeForce GTX 1070Ti/PCIe/SSE2。实验参数设置:训练次数为50 000,批量大小为8,初始化学习率为0.000 1,并且每5 000次训练减少0.96。
本文采用的评价标准有2个:准确率(Acc)和误检率(FN)。准确率计算按每幅图像的平均正确点数计算,计算方法如式(5)所示:
(5)

Figure 7 DSNet network structure in the experiment图7 实验中的DSNet网络结构
其中,Cim表示预测正确点数目,Sim表示地面实况正确点数目。当地面实况和预测点之间的差异小于特定的阈值时,判定这个点是正确的。误检率的计算方法如式(6)所示:
(6)
其中,Mpred表示误判为车道线的数量,Ngt表示所有真实路况的车道线数量。
为了验证本文提出的方法能解决车辆遮挡和地面污损问题,从图森测试集中选取了车辆遮挡和地面污损的道路场景图像,检测结果如图8所示。从检测结果来看,本文方法能够对因车辆遮挡和地面污损导致车道线不连续的区段进行预测,并且检测结果的车道线边界线更为清晰。同时,从图8可以看出,在相同的道路场景下,基于密集分割网络的车道线检测效果明显优于基于SegNet网络的检测效果。

Figure 8 Detection results under the scenes occluded by vehicles and groud fouling图8 地面污损和车辆遮挡场景下的检测效果图
表1给出了本文方法与几种典型方法在图森测试集上的性能比较。如表1所示,本文方法的准确率Acc和误检率FN比TF Placeholder方法分别提高了0.1%和0.003 6%。与文献[20]方法相比,该文献中的方法设计了一种特殊层的网络结构,训练时需要使用固定顺序的车道线标签数据集;而本文方法可以使用无序标签的车道线训练集,简化了构建训练集标志的工作,并且在处理速度方面提升至29 fps。与文献[23]方法相比,虽然该方法要优于本文方法,但是文献[23]方法的学习目标是学习嵌入像素特征向量,需要后处理来聚类像素发现车道线,很难确定车道线的数量;而本文方法可以很容易地确定所检测的车道线数量,为智能驾驶提供有关车道线数量的信息。
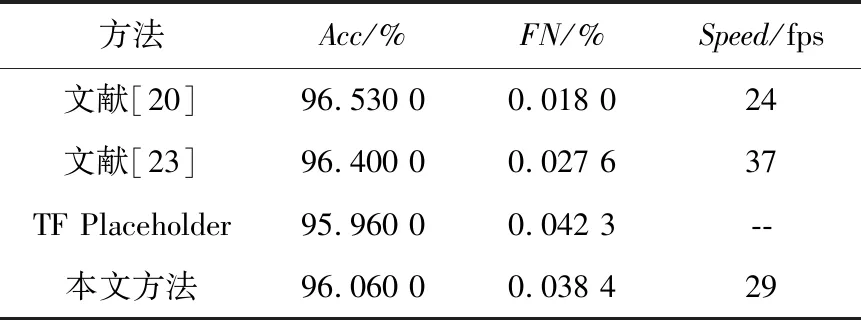
Table 1 Comparison of the method in this paper and typical methods 表1 本文方法与典型方法的对比
为了进一步验证本文方法的性能,使用包含多种道路场景的数据进行测试,结果如表2所示。从表2中可以看出,本文方法的平均准确率高达98.10%,其中在高速公路场景下的准确率高达100%,这是因为高速公路属于标准的结构化道路,并且影响因素也很少。夜晚场景下的准确率低,只有95.07%,这主要是由于光线不足导致的。另外,影响车道线检测的因素有很多,图9给出了几种典型干扰下的车道线检测结果,从中可以看出,本文方法能很好地适应光照剧变、非结构化区段和弯道等道路场景。
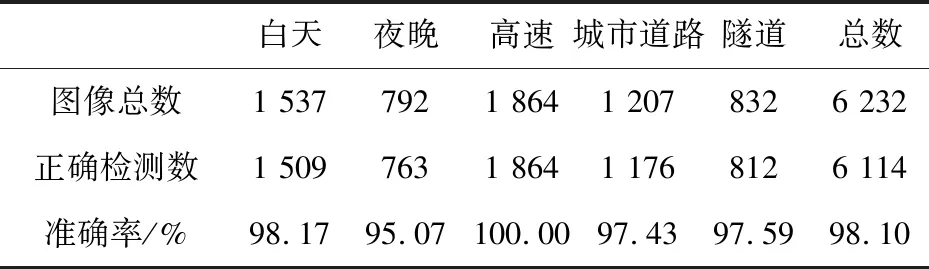
Table 2 Accuracy in different road scenarios表2 不同道路场景下的准确率

Figure 9 Detection results in some typical complex scenarios图9 一些典型复杂场景下的检测效果图
4 结束语
本文提出了一种基于密集分割网络的车道线检测方法,该方法先构建了一个密集分割网络,将车道线检测视为连续细长区域进行实例分割,再使用邻近AND运算和Meanshift聚类算法对密集分割网络的输出进行处理,减少非车道线像素的干扰,使得车道线的边界更连续、更准确。实验表明,本文方法能解决车辆遮挡和地面污损问题,确定检测的车道线数量,并且还能很好地适应综合性的复杂道路场景,具有较好的鲁棒性和实时性。
猜你喜欢
计算机仿真(2022年9期)2022-10-25
卫星应用(2021年11期)2022-01-19
科学大众(2021年9期)2021-07-16
数学小灵通·3-4年级(2021年6期)2021-07-16
中国交通信息化(2020年11期)2021-01-14
资源节约与环保(2019年11期)2019-01-21
中国舰船研究(2016年3期)2016-09-02
中国交通信息化(2015年10期)2015-06-06
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
