
基于脉冲神经网络与移动GPU计算的图像分类算法研究与实现*
2020-03-26 10:56徐频捷王诲喆
计算机工程与科学 2020年3期
徐频捷,王诲喆,李 策,唐 丹,赵 地
(1.中国科学院计算技术研究所,北京 100190;2.中国科学院大学,北京 100049; 3.中国矿业大学(北京) 机电与信息工程学院,北京 100083)
1 引言
神经科学希望能从生理学角度解释生物的神智活动,但是神经系统的生理学机制过于复杂,仅人脑就有超过一千亿的神经元,每个神经元又和上万个神经元构建联系,哪怕科技发展到今天该领域也没有取得突破性的进展。随着计算机科学的发展,人类所掌控的算力越来越强,在摩尔定律的加持下,利用计算机模拟人脑成为了可能,类脑计算应运而生。而以图像分类为代表的机器视觉作为类脑计算的重要任务之一,逐渐引起计算机科学家的重视。
Maass博士[1]称脉冲神经网络为第3代神经网络,与传统的人工神经网络不同,脉冲神经网络由精确的脉冲点火序列驱动,使用更具有生物可解释性的神经元模型和突触可塑性算法。漏极点火模型LIF(Leaky Integrate and Fire model)是由Lapicque[2]提出的,这种神经元模型最简单,但不够精确。随着生物学的发展,Hodgkin等[3]提出了霍奇金赫胥黎HH(Hodgkin Huxley)模型,HH模型高度仿生,精确地仿真了人脑神经元活动时的理化特性,但在模型仿真时需要求解大量的微分方程,需要付出较大的计算代价。为了找到一种既有更高的生物可解释性,又只需要较低算力代价的模型,Izhikevich[4]提出了Izhikevich模型,该模型介于LIF模型和HH模型之间,在算力代价大大降低的前提下,保证了较高的生物可信度。
脉冲神经网络的学习方法分为基于梯度下降、基于Widrow-Hoff规则、基于感知机规则3大类。其中基于梯度下降的方法以Bohte等[5]的基于梯度下降的脉冲反向传播SpikeProp(Spike Back Propagation)算法为代表;Mckennoch等[6]提出了带动量的反向传播算法作为改进;为了加快训练速度,Silva等[7]提出了快速梯度下降算法。在基于Widrow-Hoff规则的学习方法中,脉冲时序依赖可塑性STDP(Spike Timing Dependent-Plasticity)[8]算法最为常用;Ponulak等[9]的远程监督学习ReSuMe(Remote Supervised Method)方法通过计算期望输出和实际输出的差值体现神经元的突触可塑性;Chronotron[10]中的I-learning机制,通过神经元之间的带权值电流调整突触权值。而基于感知机规则的学习方法较为少见,以Xu等[11]提出的基于感知机规则的脉冲序列学习方法PBSNLR(Perceptron Based Spiking Neuron Learning Rule)为主。
虽然在传统人工神经网络上有关于低功耗算法的尝试[12],但是过拟合、缺少生物可解释性等问题仍然存在。为了克服人工神经网络的缺点,大量基于脉冲神经的视觉模拟算法被提出。Beyeler等[13]通过脉冲神经网络实现了生物视网膜的视觉选择机制,并实现了视频数据的特征提取;潘婷[14]提出了单层脉冲神经网络图像分类算法,并提出了一种改进的突触时序依赖可塑性算法;Diehl等[15]提出了一种基于液态机的图像分类算法,该算法模拟了人脑视觉神经元的连接方式,并通过自适应的脉冲点火阈值方法提高网络性能。
2 脉冲卷积神经网络
2.1 脉冲神经网络的生物学原理
2个神经元之间通过一种叫突触的结构连接。突触间隙既保证了细胞之间不会走得太近,又保证了细胞之间的正常通信。当来自突触前神经元的动作电位达到轴突末端的时候,动作电位并不会直接引起突触后膜电势的变化,而是通过传递一种叫做神经递质的化学物质改变突触内外膜电势,形成电势差。随着动作电位的到达,突触小泡释放神经递质,神经递质穿过突触间隙到达突触后膜,并被突触后膜上的受体接收。随着受体和神经递质结合,引起通道蛋白打开,神经元和外界发生钠离子和钾离子交换,并引起突触后膜的电势发生变化。当突触后膜电势累加达到某1个阈值时,神经元激活并发出1个脉冲,随后突触后神经元会进入一段时间的不应期。脉冲会引起1个新的动作电位的产生,并通过轴突传导,引起下1次突触小泡的释放。
2.2 脉冲神经元模型
综合考虑算力和生物可解释性的需求,为了将脉冲神经网络部署在Jetson TK1开发板上,本文选用LIF神经元模型。
LIF神经元可以由如图1所示的电路图模拟。当电流流入细胞体(RC电路)时,突触后膜电势为ε(t),电流部分被电阻R消耗,部分给电容器C充电,如式(1)所示。
(1)

Figure 1 LIF neural model图1 LIF神经元模型
令时间常数τm=RC,就可以将式(1)变形为更常见的形式:
(2)
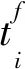
(3)
2.3 突触可塑性算法
为了实现低功耗网络,回避有监督学习必须的大量数据标注和复杂的学习方法,本文选用基于无监督的STDP算法。STDP是Hebbian学习[16]的一种重要形式,在该算法中突触前神经元和突触后神经元脉冲时间的精确计时将影响突触权重的变化[6]。SDTP遵循以下规则:如果突触前神经元的脉冲比突触后神经元的脉冲先到达,那么将产生长时间的兴奋刺激LTP(Long-Term Potentiation),同时2个神经元之间的突触权值将增大;如果突触前神经元的脉冲比突触后神经元的脉冲后到达,那么将产生长时间的抑制LTD(Long-Term Depression),同时2个神经元之间的突触权值将减小。突触权值的更新策略由式(4)描述:
(4)
其中,tpost为突触后神经元的脉冲产生时间,tpre为突触前神经元的脉冲产生时间;A+是可塑性增强学习率,A-是可塑性减弱学习率;τ+和τ-是时间衰减指数。
3 CUDA改进的脉冲神经网络
3.1 脉冲卷积
脉冲卷积操作对象是表示点火时间序列的脉冲信号。1个典型的脉冲卷积运算可以由式(5)描述:
(5)

(6)
3.2 脉冲池化
对于脉冲池化,可以由式(7)描述:
(7)
其中各个参数的含义与脉冲卷积中的一样,值得注意的是,wij是突触前神经元j和突触后神经元i之间的突触权重,这里的权重来自于池化模板,且权值根据模板的类型(最大、平均、随机)是固定的,不需要通过学习算法更新。
3.3 脉冲卷积神经网络
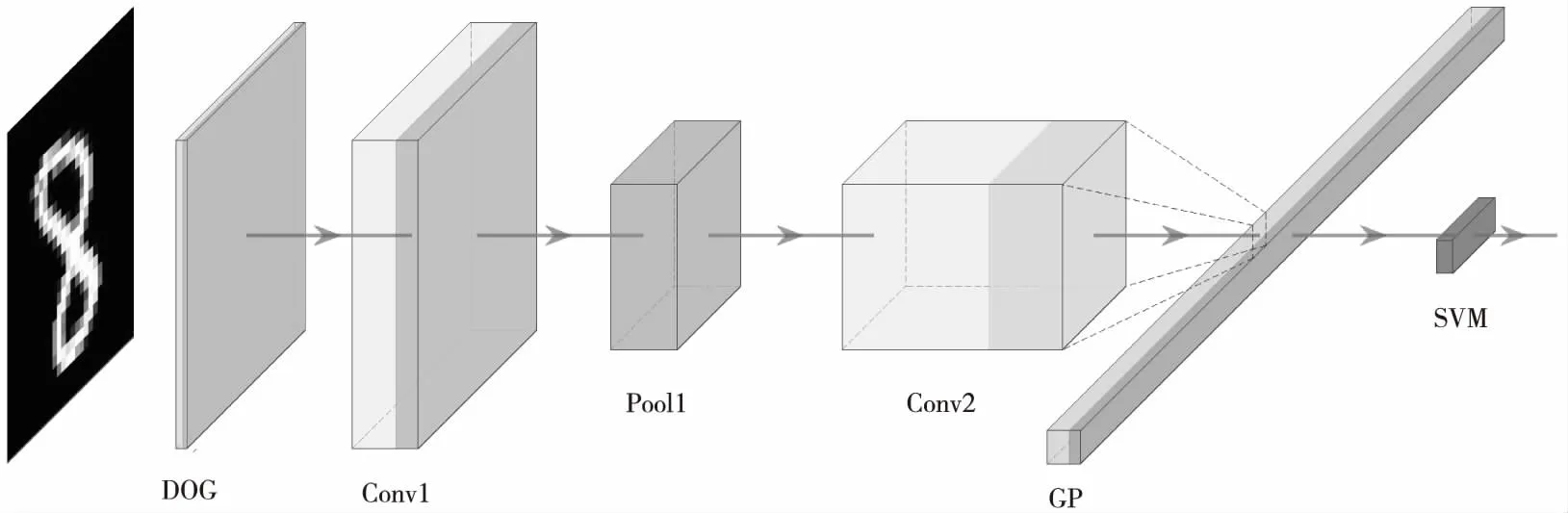
Figure 2 Structure of spiking convolutional neural network图2 脉冲卷积神经网络结构图
在生物学研究中发现,人的视觉系统通过简单视觉细胞(S cell)和复杂视觉细胞(C cell)来提取视觉特征。简单视觉细胞主要用于提取特征信息,能够最大限度地响应来自感受野的视觉边缘信息;而复杂细胞有更大的接受域,使网络获得了抗变形的能力,使得视觉系统对于某些确定位置的刺激具有局部不变性。通过复杂视觉细胞和简单视觉细胞的层叠组合,既能够控制网络连接的规模,又能约束特征子模式的响应级别。为了构建1个有效的视觉分类系统,本文用脉冲池化层模拟人视觉系统的复杂视觉细胞,用脉冲卷积层模拟简单视觉细胞,通过堆叠类似于传统人工神经网络的池化卷积模块,构建深度脉冲卷积神经网络模型。如图2所示是1个典型的脉冲卷积神经网络结构图,图2中模块从左往右依次为脉冲高斯差分神经元组(DOG)、脉冲卷积神经元组1(Conv1)、脉冲池化神经元组1(Pool1)、脉冲卷积神经元组2(Conv2)、全局最大池化(GP),最后通过支持向量机(SVM)完成分类。

Figure 3 Flow chart of CUDA improved spiking convolution algorithm图3 CUDA改进的脉冲卷积算法流程图
3.4 CUDA改进的脉冲卷积
为了充分利用Jetson TK1开发板支持CUDA编程的优势,本文提出并实现了CUDA改进的脉冲卷积神经网络,算法流程图如图3所示,该实现分为CPU和GPU 2个部分。
CPU代码部分主要完成时间步的遍历。输入神经元组的维度是H×W×C×T,分别表示输入神经元组的长、宽、通道数和时间步。在CPU代码部分,如图3的C1(简称C1,下同)所示,代码将读取来自神经网络上1层的输出。在C2中,实现对时间步的循环遍历,当输出达到时间步尾时脉冲卷积结束(C3),否则对该时间步的特征进行卷积。在C4完成线程和线程块的分配。在C5处交互CPU与GPU之间的数据,CPU内存和GPU显存的存储形式差别很大,需要额外定义GPU上的显存变量,再将CPU上的内存变量转化成GPU显存变量。
GPU代码部分主要完成突触后膜电势加权求和以及脉冲序列的生成,该部分由多个GPU线程并行完成,因此只需要关注单个线程中的操作。在G1中定位当前线程的位置,即定位当前线程对应的突触后神经元。在G2完成C4处分配的冗余线程的越界检查,越界线程没有对应的突触后神经元,因此不应参加卷积计算。在G3处,每个突触后神经元唯一对应1个感受野,感受野的大小和卷积核尺寸相同,对感受野上的脉冲做加权求和形成突触后膜电势增量,并累加到突触后膜电势上。在G4中,由于突触后膜电势在时间步上的累加效应,当突出后膜电势累加并超过阈值时就会在当前时间步产生1个脉冲,同时突触后膜电势回到静息电位(G5),如果未达到阈值,则电势会被保留到下1个时间步。当GPU上的卷积操作结束时,将更新后的脉冲序列和突触后膜电势送回CPU内存。
4 实验结果及分析
本文选用Jetson TK1作为开发环境,这是一款被广泛使用的高性能嵌入式开发板,基于NVIDIA的Tegra®K1 SoC架构。虽然是1个小型嵌入式设备,但拥有基于ARM架构的Cortex-A15 CPU,4核主频2.3 GHz;以及NVIDIA的Kepler GK20a架构GPU,拥有192个CUDA核心,每秒浮点运算次数高达326 GFLOPS。由于Jetson TK1低功耗、高性能的特点,现在正被广泛应用于智能家居[18]、监控安防[19]、车载设备[20]等众多领域。
输入网络的手写数字图像维度是28×28×1,网络整体分为基本神经元组和特殊神经元组,其中基本神经元组为前4组,特殊神经元组为后2组,各神经元组具体参数如表1所示。在整个网络中,只有2个脉冲卷积神经元组是需要通过学习更新权重的。特征的提取和分类是完全分开的,使用脉冲时序依赖可塑性算法更新参数,本文对第1个卷积层和第2个卷积层各做50 000次权重更新。
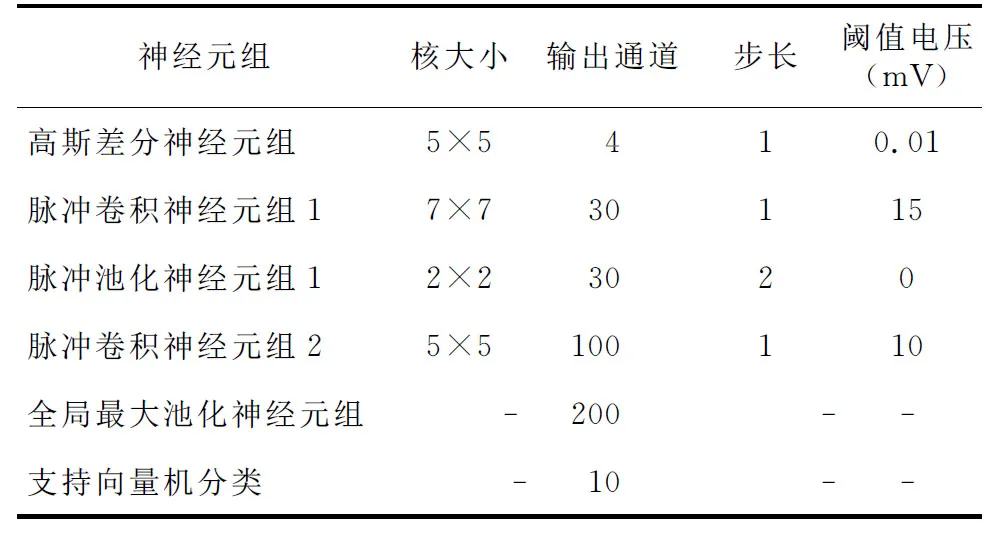
Table 1 Parameters of each neuron group表1 各神经元组参数
脉冲神经网络通过精确的脉冲点火序列驱动,可以可视化各层输出的脉冲序列。以输入手写数字“6”为例,可以得到如图4所示的脉冲点火序列,这些图将三维神经元组的长、宽、通道3个维度合并平摊成1个维度作为y轴,将脉冲点火时间作为x轴。
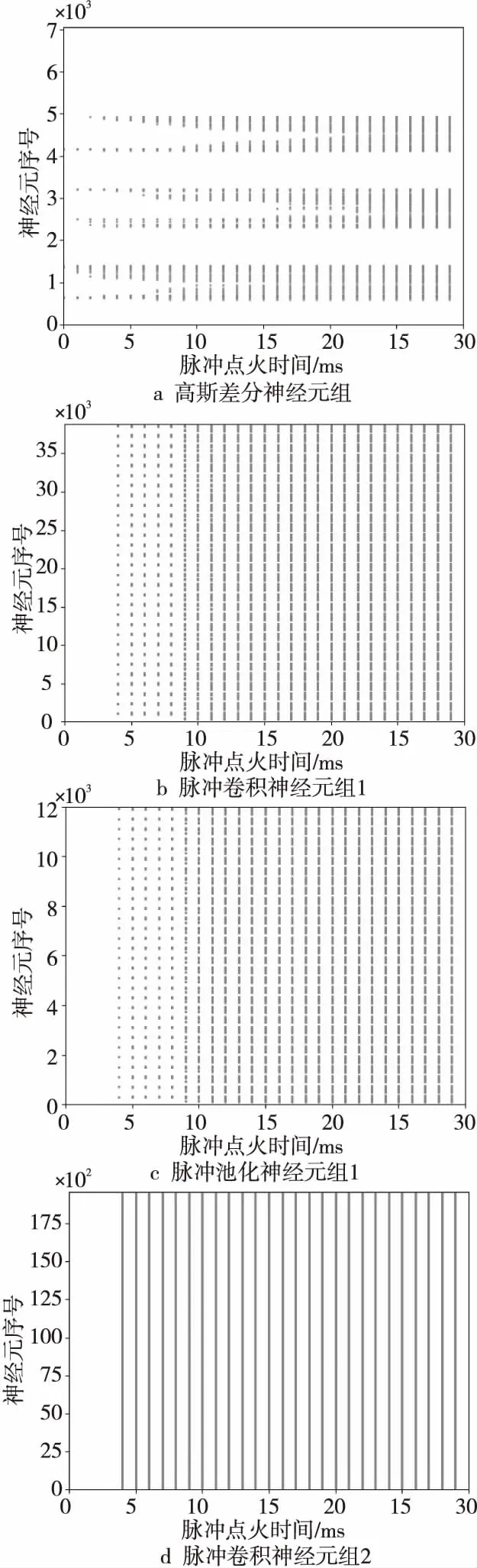
Figure 4 Spatiotemporal relationship of spiking sequences produced by neural group图4 各神经元组产生脉冲的时空关系图
首先,本文将分析CUDA改进的脉冲卷积神经网络在Jetson TK1开发板上的表现,将分类准确率、网络单次运行耗时和图像分类帧率作为评价指标。网络单次运行耗时把网络的运行分为配置状态、初始化状态以及运行状态3个部分;而图像处理帧率分析实验则是建立在网络已经完成初始化基础上,只关注在运行状态1 s能够处理多少幅图像(FPS)。本文使用MNIST数据集,该数据集包含60 000幅大小为28×28的手写数字灰度图像,取其中50 000幅作为训练集训练网络,取其中10 000幅作为测试集测试算法性能。
首先分析网络单次运行耗时,Jetson TK1开发板在CPU状态、GPU状态以及PC机上CPU状态下进行对比,实验结果如图5所示。网络配置状态(Config State)主要读取网络结构和各种超参数,这个状态用时是最少的,在各平台上该步骤用时都保持在0.01 s之内;其次是初始化状态(Setup State),初始化状态主要构建网络结构,申请CPU内存以及GPU显存;最后是运行状态(Run State),运行状态将完成脉冲神经网络的仿真。可以看出,在Jetson TK1上,GPU模式下CUDA改进的脉冲神经网络相比于CPU模式提升较大,GPU模式下的运行时间为3.87 s,而CPU模式下用时9.53 s。
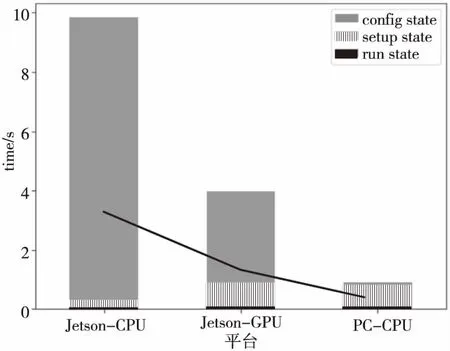
Figure 5 Time consuming comparison of spiking neural network of different states on different plaforms图5 脉冲神经网络在不同平台上各阶段耗时比较
接下来做帧率分析,同样选取来自MNIST数据集中的图像,由于帧率分析时需要1次性处理多幅图像,这将反复执行运行状态的代码,而配置和初始化状态只需执行1次。为了节省开发板资源,本文将网络的训练阶段放到PC机上执行,然后将训练的权重保存在开发板上,这样开发板上的脉冲卷积神经网络只需要专注于图像分类的前向传播工作,而可以忽略费时费力的网络训练工作。
从表2可以看出,将网络改变成CUDA版本并部署在Jetson TK1开发板上时检测准确率达到了98%,检测帧率达到了0.34,相比于基于CPU的原始算法,CUDA改进的脉冲神经网络在保证准确率不变的情况下帧率增加3倍。与基于单层脉冲神经网络[14]的算法比较,本文算法由于增加了网络的层数,使用了CUDA改进,在准确率和帧率上均有所提升。
5 结束语
本文提出了一种脉冲卷积神经网络,先使用脉冲高斯差分层提取输入脉冲的时空特征,再通过堆叠脉冲卷积层和脉冲池化层提取脉冲序列的高层特征,使用基于无监督学习的脉冲时序依赖可塑性算法训练网络权重,最后由支持向量机分类特征。实验表明,该方法在MNIST数据集上有较好的分类准确率。
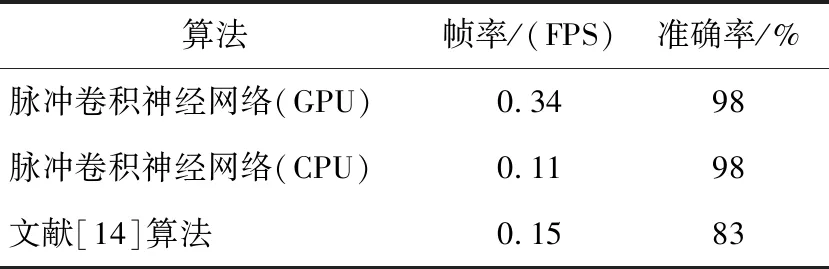
Table 2 Performance comparison among our algorithm and other algorithms on MNIST data set in Jetson TK1 environment 表2 在Jetson TK1环境中本文算法与其他算法在MNIST数据集上的性能比较
在所提的脉冲卷积神经网络基础上,本文提出了一种CUDA改进的脉冲卷积神经网络模型,并将该模型成功部署在了Jetson TK1开发板上,实现了在移动GPU上的基于脉冲神经网络的图像处理以及图像分类算法,并与传统单层脉冲神经网络的性能进行了对比。总体来说,本文提出的基于脉冲神经网络与移动GPU计算的图像分类算法有较强的生物可解释性、较高的鲁棒性和较快的运算速度。
猜你喜欢
数学物理学报(2022年3期)2022-05-25
防爆电机(2020年4期)2020-12-14
河北理科教学研究(2020年1期)2020-07-24
舰船电子工程(2020年5期)2020-07-09
数学物理学报(2019年5期)2019-11-29
中成药(2017年12期)2018-01-19
电子制作(2017年22期)2017-02-02
物联网技术(2015年11期)2015-11-26
高中生学习·高二版(2014年5期)2014-07-03
汽车与新动力(2013年3期)2013-03-11
