
基于实例的强分类器快速集成方法
2017-06-27 08:10:42许业旺王永利赵忠文
计算机应用 2017年4期
许业旺,王永利,赵忠文
1.南京理工大学 计算机科学与工程学院,南京 210094; 2.装备学院 复杂电子系统仿真重点实验室,北京 101416)(*通信作者电子邮箱381181495@qq.com)
基于实例的强分类器快速集成方法
许业旺1*,王永利1,赵忠文2
1.南京理工大学 计算机科学与工程学院,南京 210094; 2.装备学院 复杂电子系统仿真重点实验室,北京 101416)(*通信作者电子邮箱381181495@qq.com)
针对集成分类器由于基分类器过弱,需要牺牲大量训练时间才能取得高精度的问题,提出一种基于实例的强分类器快速集成方法——FSE。首先通过基分类器评价方法剔除不合格分类器,再对分类器进行精确度和差异性排序,从而得到一组精度最高、差异性最大的分类器;然后通过FSE集成算法打破已有的样本分布, 重新采样使分类器更多地关注难学习的样本,并以此决定各分类器的权重并集成。实验通过与集成分类器Boosting在UCI数据库和真实数据集上进行比对,Boosting构造的集成分类器的识别精度最高分别能达到90.2%和90.4%,而使用FSE方法的集成分类器精度分别能达到95.6%和93.9%;而且两者在达到相同精度时,使用FSE方法的集成分类器分别缩短了75%和80%的训练时间。实验结果表明,FSE集成模型能有效提高识别精度、缩短训练时间。
强分类器集成模型;基分类器评价方法;集成算法;样本分布;集成学习
0 引言
集成学习(Ensemble Learning)是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合从而获得比单个学习器更好的学习效果的一种机器学习方法。它可以有效地提高学习系统的泛化能力,因此集成学习作为机器学习界的研究热点,目前已经广泛应用于文本与语音识别[1]、协同过滤推荐[2]、辅助医疗诊断[3]、遥感信息处理[4]、系统故障诊断[5]等多个领域。
分类器集成是集成学习一个重要的研究方向,目前主要集成算法主要包括Boosting和Bagging,而不考虑数据集的影响,Boosting方法的集成分类器效果明显优于Bagging[6]。在大部分相关文献中,集成过程往往选择神经网络[7]、朴素贝叶斯[8-9]、决策树[10-11]等算法训练出成百上千个弱分类器(识别率稍高于0.5)再进行集成。这一做法存在以下不足:一方面,使用数量巨大的分类器将导致更大的计算和存储开销;另一方面,此类基分类器差异本身就很小,而当多次训练使得基分类器数目增加之后,分类器之间的差异会更小。周志华等已经验证,集成学习的效果取决于基分类器之间的差异性[12-15]。本文从参与集成的基分类器的分类准确性和差异性两方面考虑:准确性方面,本文选择识别率较高的强分类器作为基分类器,不仅能保障识别精度,还可以大幅提高集成效率;差异性方面,本文将差异性评价方法应用到分类器集成中,使集成系统的识别精度得到进一步提高。
在选定好基分类器之后,分类器之间的输出集成方法就成为实现集成学习系统的关键。目前常见的分类器集成方法有投票法[16]、线性组合法、证据理论法、模糊积分法等,它们在一定条件下均可以提高集成学习系统的性能。然而,这些方法都只是根据分类器的统计性能赋予分类器以相应的权值,而没有考虑各个样本的具体情况。比如投票法它的基本思想是:由基分类器对样本进行预测,每一个基分类器对自己所预测的类投一票,得到票数最多的类就是该样本的最终预测结果。这种集成方法往往会导致结果更倾向于那些易于识别的样本,而对于那些容易出错的样本,由于大部分分类器识别错误,导致最终结果也是错误的,无法发挥那些识别率较低,却具有很高差异性的分类器的作用。本文从基于实例的角度,采取多次改变样本权重以设定各分类器权重的思想,设
计了一种基于集成学习的强分类器集成模型,并提出了一种FSE(Fast Strong-classifiers Ensemble)集成算法来设定模型中基分类器的权重。最后通过算法分析和实验结果表明,本文模型的精度优于所有用于集成的基分类器以及常用集成方法,具有更优的精度以及更好的泛化能力,同时由于使用的分类器属于强分类器,极大地缩短了训练模型的时间,使其更具有实际应用价值。
1 定义与模型
差异性是高泛化能力集成的必要条件,为了使选择的基分类器具有很高的差异度,本文从识别率和差异性的角度设定了一种基分类器评价方法,从众多强分类器中选择最佳的基分类器集成组合。最后使用FSE算法集成所选的基分类器形成具有精度高、训练时间短的超强分类器。该模型包括训练模块和测试模块两部分,如图1所示。

图1 强分类器集成模型
训练模块主要分为五部分:1)提取特征;2)数据抽样;3)训练基分类器;4)挑选基分类器;5)设置基分类器权重。
测试模块主要分为四部分:1)提取特征;2)数据抽样;3)使用集成分类器;4)输出结果。
下面对模块中出现的各步骤进行详细说明:
提取特征 训练模块和测试模块均使用人工神经网络(Artificial Neural Network, ANN)对数据集进行特征提取。由于本文主要采用基于实例思想,更关注当前样本权值分配,使用ANN可以在面对新样本时快速而有效地建立新的目标函数。
数据抽样 训练模块的数据抽样部分对经过ANN提取特征后的有标签数据集进行分层抽样,得到训练数据集1和训练数据集2。其中训练数据集1供训练分类器使用;而训练数据集2供训练FSE集成分类器使用。测试模块的数据抽样部分对经过ANN提取特征后的无标签数据集进行分层抽样得到测试数据集,供测试FSE集成分类器使用。
训练基分类器 该部分使用训练数据集1对多种机器学习算法进行训练,得到对应的分类器。
挑选基分类器 该部分使用本文所提的基分类器评价方法在训练好的分类器中挑选用于集成的基分类器。
设置基分类器权重 该部分使用FSE算法和训练数据集2为上一步骤中得到的基分类器设置各自权重,最终加权得到FSE集成分类器。
使用集成分类器 使用测试数据集对得到的集成分类器进行测试,并输出数据集的类别标签作为结果。
2 算法描述
2.1 基分类器评价方法
集成学习的效果取决于基分类器之间的差异性,因此在选择基分类器之前必须先设定选择分类器的度量标准。为此,本文采用识别率和差异度来度量。
定义1 识别率。
设存在分类器Ci,非空样本集S被分类器正确分类的样本集合为Si,N(S)为S中所含样本的个数,T为分类器的识别率,其定义如式(1)所示:
Ti=N(Si)/N(S)
(1)
定义2 差异度。
设存在两个分类器Ci和Cj,非空样本集S被两个分类器正确分类的样本集合分别为Si和Sj,F为两个分类器的差异度,N(S)为S中所含样本的个数,则Cj对于Ci的差异度定义如式(2)所示:
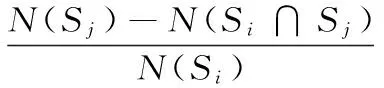
(2)
由定义2可知,Fj→i越大,则Cj与Ci间差异性越大;反之,差异性越小。
本模型中设定的分类器可能不止两种,这对于最终的集成分类器的泛化能力提高是有利的。不过也因此,需对式(1)的公式作进一步定义。假设在已有分类器Ci和Cj集成的基础上加上Ck,则Ck对于Ci和Cj集成分类器的差异度可定义为式(3):
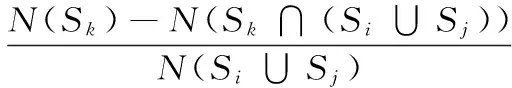
(3)
其中:Fk→ij越大,则Ck与Ci和Cj集成分类器差异性越大;反之,差异性越小。
根据上述的选择基分类器度量标准的定义,本文设计了一种基分类器评价算法(如算法1所示)。它的主要思想是先按照识别率在强分类器集合Q中对分类器进行排序,剔除不合格分类器,并得到识别率最高的分类器C1;然后在剩余分类器集合中找出与分类器C1差异度最大的分类器C2,将C1与C2进行集成。重复以上步骤,得到最终分类器组合。评价基分类器伪代码如下所示。
算法1 评价基分类器。
输入:Q{Qi|i=1,2,…,n}; 输出:C{Ci|i=1,2,…,l+1}
//所有分类器集合
1)
Fori=1 ton-1 do
2)
IfTQi≤T′ Then
3)
删除TQi
4)
End if
//设置阈值T′剔除集合中不合格分类器
5)
IfTQi+1≥TQiThen
6)
C1=Qi+1
7)
End if
8)
End for
//寻找识别率最高的分类器C1
9)
Q=1-C1
10)
C=C1
11)
Whilel≠0(1≤l≤n-1) do
12)
Forj=1 ton-ldo
13)
IfFQj+1→C≥FQj→CThen
14)
C2=Qj+1
15)
End if
16)
End for
//寻找与集成分类器C差异度最大的分类器C2
17)
C=C∪C2
18)
Q=Q-C2
19)
l--
20)
End while
21)
ReturnC{Ci|i=1,2,…,l+1}
在基分类器有数量限制的情况下,按照该算法在强分类器集合Q中得到识别率最高、泛化能力最强的基分类器组合C。其中:语句1)是分类器排序过程,执行了n-1次;语句11)执行了l次;语句12)作为11)的内层循环执行了n-l次。所以算法1的时间复杂度是O(n+l(n-l)),其中n是供选择的强分类器个数,l是需要的基分类器个数。
2.2FSE
通过算法1选定好基分类器之后,强分类器之间的集成方法就成为了实现集成学习系统的关键。本文提出了FSE算法——一种基于实例的强分类器快速集成算法。算法核心思想是:打破已有的样本分布, 重新采样使分类器更多地关注难学习的样本,并以此决定各分类器的权重。在描述算法之前,需要先作一些定义。
定义3 错分率。
ER=1-T
(4)
其中:ER表示分类器对样本错误分类的比例;T是分类器识别率。
定义4 权重。
W=I/N
(5)
其中:W表示某样本d在总样本D中的重要程度;I表示单体样本训练最终分类器的能力;N表示所有样本训练最终分类器的能力。
FSE算法开始时,所有样本被赋予相同的权重1/N,训练算法1中得到的基分类器,并挑选出最佳分类器。每一轮结束后更新样本权重:增加被错误分类样本的权重,减少被正确分类样本的权重,这样迫使分类器在随后的迭代中更加关注那些难以分类的样本。重复以上步骤,直到算法满足结束条件为止。算法的输入为N对训练样本与标签的集合{(Xj,Yj)|j=1,2,…,N},其中X为样本,Y为类标签;最终分类器C*作为算法的输出;分类器C{Ci|i=1,2,…,l}为算法1中得到的基分类器集合。FSE伪代码如下所示。
算法2 FSE。
输入:{(Xj,Yj)|j=1,2,…,N}; 输出:C*
//最终集成分类器
1)
w={wj=1/N|j=1,2,…,N}
//初始化各样本权重
2)
t=l
//根据算法1选择的基分类器数目确定循环次数
3)
Whilet≠0
4)
Fori=1 tol-1 do
5)
IfERCi+1≤ERCiThen
6)
7)
End if
8)
End for
9)
10)
Ifεi=0 Then
11)
Break
12)
End if
13)
14)
//在下一次循环中更改wj样本权重,其中Zj是规泛化因子,
//使所有样本和为1
15)
t--
16)
End while
17)
本文提出的FSE算法主要有如下优势:
1)通过基分类器评价方法选取多个具有差异性的强分类器组合,并在FSE算法中将其作为基分类器,增加了分类器的多样性,在保证精度的情况下,提高了最终集成结果的泛化能力。
2)FSE算法使用算法1中得到的强分类器作为基分类器,让迭代次数等于选取的基分类器个数,使得训练时间大幅度缩减。
该算法中,语句1)执行了N次,语句3)执行了l次,语句4)作为语句3)的内层循环执行了l-1次。所以算法2的时间复杂度是O(N+l*(l-1))。其中:l是算法1中挑选出的基分类器个数,N为训练样本个数。
3 实验及结果分析
3.1 实验环境及数据集
本文的实验是用MatlabR2010b在CPU为2.53GHz、内存容量为4GB计算机上进行。实验中使用UCI数据库[17]中的chess数据集作为实验样本,基本情况见表1。该数据分为获胜和非获胜两类。数据集已提取完特征,每组36维特征数组。数据抽样阶段,抽取2 000个样本作为分类器训练集;抽取400个样本作为集成训练集;抽取600个样本作为集成测试集。
由于本文模型处理的是原始数据,实验数据集还使用了真实数据集chair,基本情况见表1。数据分为椅子和非椅子两类,图片分辨率为800×800。提取特征阶段,使用ANN自主进行特征提取,每个样本形成一组64维特征数组。数据抽样阶段,抽取600个样本作为分类器训练集;抽取300个样本作为集成训练集;抽取100个样本作为集成测试集。
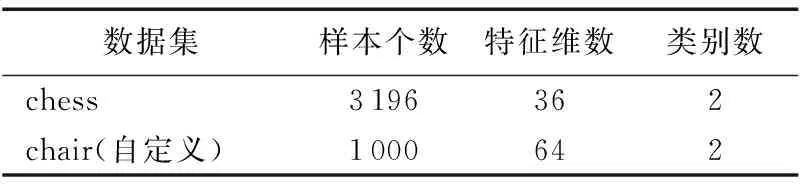
表1 数据集的基本情况
3.2 挑选基分类器与未挑选集成分类器精确度对比
由于机器学习算法有很多,对应的推广更是不计其数,所以穷举所有强分类器并挑选最佳分类器显然是不现实的,因此,仅针对常用机器学习分类器以及chess数据集,使用本文所提的基分类器评价方法得到分类器组合方案,部分结果见表2。
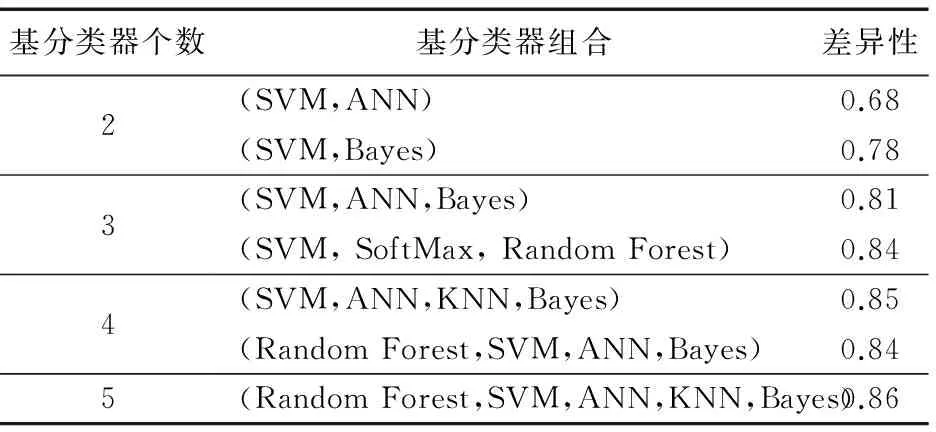
表2 分类器集成方案
由于Boosting方法的集成分类器效果明显优于Bagging,对比实验中,采用Boosting算法来训练并产生新基分类器,即重复地随机选择样本子集作为训练集;采用的基分类器是CART树。利用Boosting算法从训练样本中随机选取一些样本组成10、15、20、25个样本子集,并用它们生成的10、15、20、25个基分类器组合,分别计算它们识别率并用其对集成训练样本进行识别,根据识别率进行排序,挑选识别率最高的一组。利用基分类器评价算法在常用分类器中选出对应数量的差异性最大的基分类器组合,最后分别计算各自识别率。两者均用投票法和线性组合法完成分类器集成,表3给出了使用Boosting方法和使用基分类器评价方法构造的不同分类器组合的识别率。
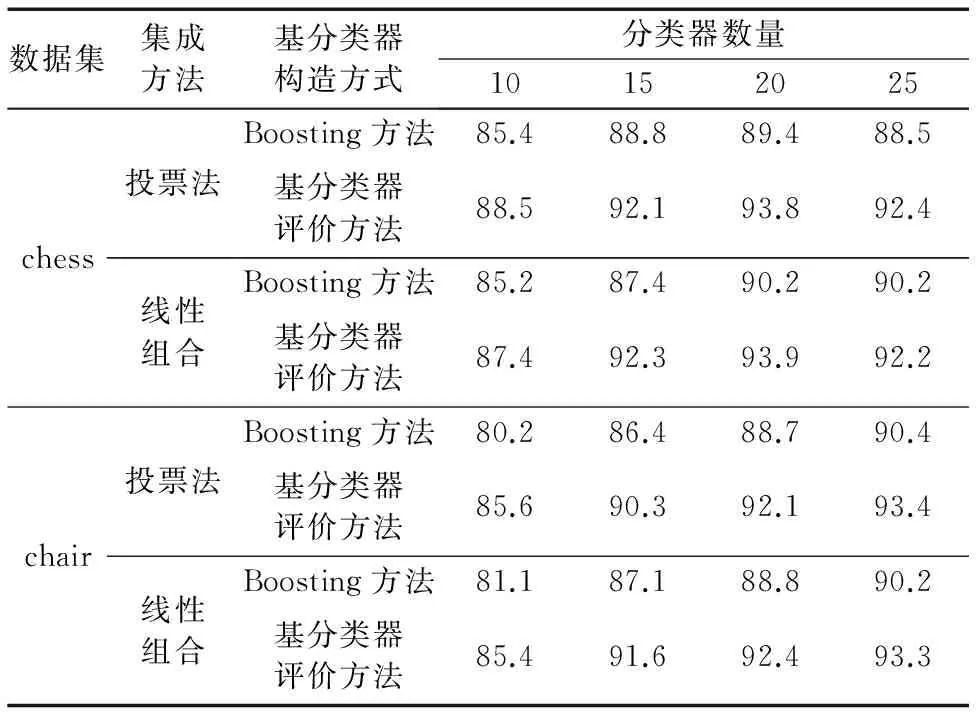
表3 使用不同方法构造的不同集成分类器识别率 %
由表3可以看出,在chess数据集下,未利用基分类器评价方法的集成分类器精度在分类器数量为20和25时最高达到90.2%;相同数量的基分类器组合情况下,利用本文的基分类器评价方法的集成分类器识别率最高达到93.9%和92.2%。在chair数据集下,集成方法为投票法情况下,利用基分类器评价方法的集成分类器分类精度比未用的集成分类器在分类器数量为10时最高提高了5.4%;集成方法为线性组合情况下,识别率在分类器数量为15时最高提高了4.5%。由此可见,利用基分类器评价方法可以有效提高集成分类器的识别率,而且构造多分类器集成系统时,分类器数量并非越多越好。
3.3FSE集成方法与常用集成方法识别率对比
为了对比使用FSE集成方法与常用集成方法的区别,在3.2节使用基分类器评价方法构造的分类器实验基础上增加本文所提的FSE集成方法,具体结果见表4。
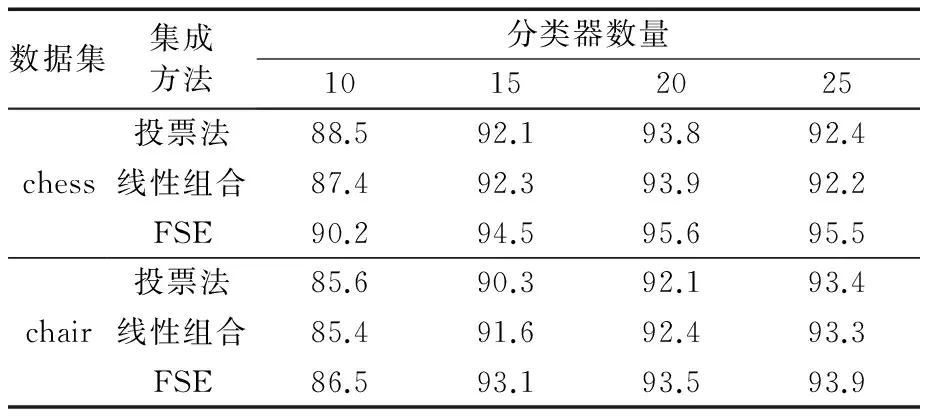
表4 FSE集成方法与常用集成方法识别率 %
3.4FSE集成模型与Boosting分类器+常用集成方法实验时间对比
为了检验FSE集成模型的性能,本实验以FSE模型和Boosting算法训练时间为标准,比较两者达到相对稳定识别率时的时间消耗,具体结果见图2、3。
由图2可以看出,由于Boosting使用的是识别率略高于50%的弱分类器,所以在实验1开始集成分类器的识别率仅略高于50%,但随着时间增加,其识别率有显著提高。chess数据集下,Boosting+常用集成方法训练到4min时识别率达到90%左右,不过识别率变化大幅减小,但仍然保有上升趋势;而FSE集成模型在1min左右即达到90%的高识别率,后续部分仅为了对比让其继续执行相应时间,虽然偶尔出现轻微的过学习状态(识别率下降),但实际应用过程中,当达到稳定识别率且不需要继续提高识别率情况下,后续的过程是没有必要的。图3也保有此类规律。
本实验中chess数据集下FSE集成模型的比Boosting+常用集成模型缩短了75%训练时间,chair数据集下缩短了80%训练时间。由此可得,FSE集成模型有效地加快了训练速度。
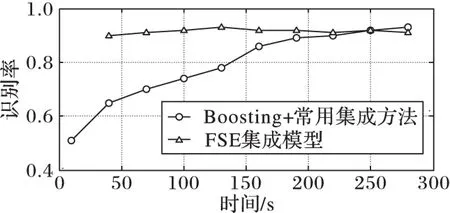
图2 chess数据集下时间消耗对比
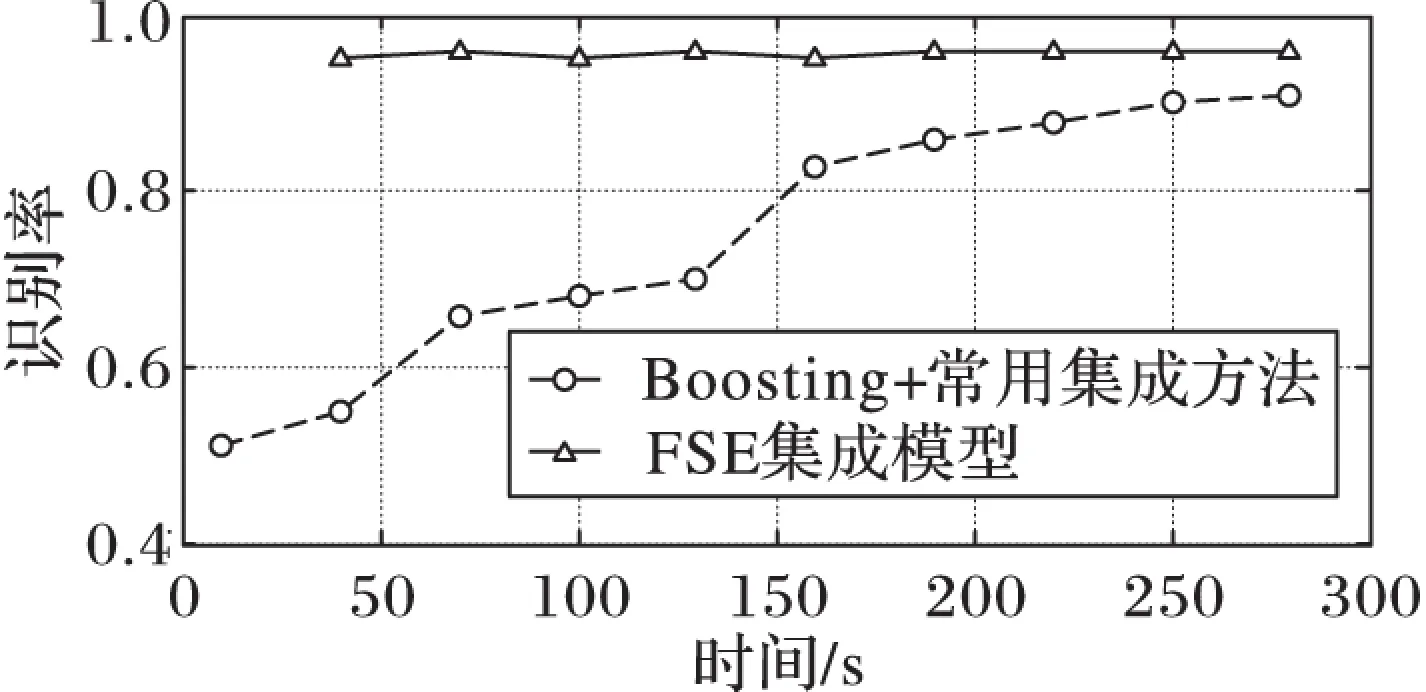
图3 chair数据集下时间消耗对比
4 结语
针对集成分类器牺牲存储和计算来提高精度的问题,本文提出一种基于实例的强分类器快速集成方法。该方法通过基分类器评价方法挑选差异性最大的分类器组合,然后利用FSE算法对分类器进行集成。本文采用了2个真实数据集进行验证,结果表明FSE不仅提高了识别精度,还大幅度缩短了训练时间。今后的研究工作中,将着重考虑利用深度学习知识改进分类器评价方法和集成算法。
)
[1]SILVAC,LOTRICU,RIBEIROB,etal.Distributedtextclassificationwithanensemblekernel-basedlearningapproach[J].IEEETransactionsonSystems,Man,andCybernetics,PartC:ApplicationsandReviews, 2010, 40(3): 287-297.
[2]BARA,ROKACHL,SHANIG,etal.Improvingsimplecollaborativefilteringmodelsusingensemblemethods[C]//Proceedingsofthe11thInternationalWorkshoponMultipleClassifierSystems,LNCS7872.Berlin:Springer, 2013: 1-12.
[3]ZHOUZH,JIANGY,YANGYB,etal.Lungcancercellidentificationbasedonartificialneuralnetworkensembles[J].ArtificialIntelligenceinMedicine, 2002, 24(1): 25-36.
[4]BORGHYSD,YVINECY,PERNEELC,etal.Supervisedfeature-basedclassificationofmulti-channelSARimages[J].PatternRecognitionLetters, 2006, 27(4): 252-258.
[5]ZUOL,HOUL,WUW,etal.FaultdiagnosisofanalogICbasedonwaveletneuralnetworkensemble[C]//ISNN2009:Proceedingsofthe6thInternationalSymposiumonNeuralNetworks,LNCS5553.Berlin:Springer, 2009: 772-779.
[6]POLIKARR.Ensemblelearning[M]//ZHANGC,MAY.EnsembleMachineLearning.Berlin:Springer, 2012: 1-34.
[7]LIUCL.Classifiercombinationbasedonconfidencetransformation[J].PatternRecognition, 2005, 38(1): 11-28.
[8]SHIPPCA,KUNCHEVALI.Relationshipsbetweencombinationmethodsandmeasuresofdiversityincombiningclassifiers[J].InformationFusion, 2002, 3(2): 135-148.
[9]JIANGL,CAIZ,ZHANGH,etal.NaiveBayestextclassifiers:alocallyweightedlearningapproach[J].JournalofExperimentalandTheoreticalArtificialIntelligence, 2013, 25(2): 273-286.
[10]YUKSELSE,WILSONJN,GADERPD.Twentyyearsofmixtureofexperts[J].IEEETransactionsonNeuralNetworksandLearningSystems, 2012, 23(8): 1177-1193.
[11]SHIL,WANGQ,MAX,etal.Spamemailclassificationusingdecisiontreeensemble[J].JournalofComputationalInformationSystems, 2012, 8(3): 949-956.
[12]SCHAPIRERE,FREUNDY,BARTLETTPL,etal.Boostingthemargin:anewexplanationfortheeffectivenessofvotingmethods[J].AnnalsofStatistics, 1998, 26(5): 1651-1686.
[13]LIUY,YAOX.Ensemblelearningvianegativecorrelation[J].NeuralNetworks, 1999, 12(10): 1399-1404.
[14]ZHANGY,BURERS,STREETWN.Ensemblepruningviasemi-definiteprogramming[J].JournalofMachineLearningResearch, 2006, 7(3): 1315-1338.
[15]LIN,ZHOUZH.Selectiveensembleunderregularizationframework[C]//Proceedingsofthe8thInternationalWorkshoponMultipleClassifierSystems.Berlin:Springer, 2009: 293-303.
[16]JIANGM,YIX,LINGN.Framelayerbitallocationschemeforconstantqualityvideo[C]//Proceedingsofthe2004IEEEInternationalConferenceonMultimediaandExpo.Piscataway,NJ:IEEE, 2004, 2: 1055-1058.
[17]FRANKA,ASUNCIONA.UCIMachineLearningRepository[DB/OL]. [2016- 03- 15].http://www.ics.uci.edu/?mlearn/.
ThisworkispartiallysupportedbytheNationalNaturalScienceFoundationofChina(61170035, 61272420, 61502233),theJiangsuProvinceScienceandTechnologyAchievementTransformationProjectsofSpecialFunds(BA2013047),theJiangsuProvinceSixTalentPeaksProject(WLW-004),theNnationalDefenseScienceandTechnologyKeyLaboratoryofBasicResearchProjects(DXZT-JC-ZZ-2013-019),theMilitaryAcademyofPre-ResearchProject(62201070151),theFundamentalResearchFundsfortheCentralUniversities(30916011328).
XU Yewang, born in 1991, M. S. candidate. His research interests include data mining, big data information security.
WANG Yongli, born in 1974, Ph. D., professor. His research interests include database, data mining, big data processing, intelligent service, cloud computing.
ZHAO Zhongwen, born in 1974, M. S., associate professor. His research interests include information system, multidimensional information, situation comprehension.
Fast ensemble method for strong classifiers based on instance
XU Yewang1*, WANG Yongli1, ZHAO Zhongwen2
(1. Department of Computer Science and Engineering, Nanjing University of Science and Technology, Nanjing Jiangsu 210094, China;2. National Key Laboratory of Complex Electronic System Simulation, Academy of Equipment, Beijing 101416, China)
Focusing on the issue that the ensemble classifier based on weak classifiers needs to sacrifice a lot of training time to obtain high precision, an ensemble method of strong classifiers based on instances named Fast Strong-classifiers Ensemble (FSE) was proposed. Firstly, the evaluation method was used to eliminate substandard classifier and order the restclassifiers by the accuracy and diversity to obtain a set of classifiers with highest precision and maximal difference. Secondly, the FSE algorithm was used to break the existing sample distribution, to re-sample and make the classifier pay more attention to learn the difficult samples. Finally, the ensemble classifier was completed by determining the weight of each classifier simultaneously. The experiments were conducted on UCI dataset and customized dataset. The accuracy of the Boosting reached 90.2% and 90.4% on both datasets respectively, and the accuracy of the FSE reached 95.6% and 93.9%. The training time of ensemble classifier with FSE was shortened by 75% and 80% compared to the ensemble classifier with Boosting when they reached the same accuracy. The theoretical analysis and simulation results show that FSE ensemble model can effectively improve the recognition accuracy and shorten training time.
strong classifiers ensemble model; base classifier evaluation method; ensemble algorithm; sample distribution; ensemble learning
2016- 07- 29;
2016- 09- 28。 基金项目:国家自然科学基金资助项目(61170035,61272420,61502233);江苏省科技成果转化专项资金资助项目(BA2013047);江苏省六大人才高峰项目(WLW-004);国防科技重点实验室基础研究项目(DXZT-JC-ZZ-2013-019);兵科院预研项目(62201070151);中央高校基本科研业务费专项资金资助项目(30916011328)。
许业旺(1991—),男,江苏淮安人,硕士研究生,主要研究方向:数据挖掘、大数据信息安全; 王永利(1974—),男,哈尔滨佳木斯人,教授,博士,主要研究方向:数据库、数据挖掘、大数据处理、智能服务、云计算; 赵忠文(1974—),男,北京人,副教授,硕士,主要研究方向:信息系统、多维信息、态势综合。
1001- 9081(2017)04- 1100- 05
10.11772/j.issn.1001- 9081.2017.04.1100
TP391
A
猜你喜欢
当代陕西(2020年17期)2020-10-28 08:18:18
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
人大建设(2018年5期)2018-08-16 07:09:00
中国交通信息化(2018年3期)2018-06-13 03:27:58
电子测试(2018年1期)2018-04-18 11:52:35
电信科学(2017年6期)2017-07-01 15:44:57
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
中国交通信息化(2016年2期)2016-06-06 07:28:02
