
基于非参数回归的遗漏变量检验①
2016-05-18 07:43洪永淼
管理科学学报 2016年3期
关键词:非线性
王 霞, 洪永淼
(1. 中国科学院大学经济与管理学院, 北京 100190; 2. 康奈尔大学经济学系与统计学系, 纽约 14850;3. 厦门大学王亚南经济研究院, 厦门 361005)
基于非参数回归的遗漏变量检验①
王霞1, 洪永淼2, 3
(1. 中国科学院大学经济与管理学院, 北京 100190; 2. 康奈尔大学经济学系与统计学系, 纽约 14850;3. 厦门大学王亚南经济研究院, 厦门 361005)
摘要:基于非参数回归提出了同时适用于横截面和时间序列数据的遗漏变量检验统计量.与现有文献相比,该统计量不仅避免了模型设定偏误问题,而且具有更高的局部检验功效,能够识别出速度更快的收敛到原假设的局部备择假设.该文选择单一带宽估计条件联合期望和条件边际期望,允许二者的非参数估计误差共同决定统计量的渐近分布,不仅改善了统计量的有限样本性质,而且避免了选择多个带宽和计算多个偏差项产生的繁杂工作.蒙特卡洛模拟结果表明该统计量具有良好的有限样本性质以及比Ait-Sahalia等更高的检验功效.实证分析采用该统计量捕获了F统计量无法识别的产出缺口与通胀之间关系,验证了非线性“产出—通胀”型菲利普斯曲线在中国的适用性.
关键词:遗漏变量; 非参数回归; 非线性; 检验功效; 均值格兰杰因果关系
0引言
计量经济学者一般假设经济系统是个随机过程,该过程由某个未知的计量经济模型支配.由于研究人员无法知晓真实模型形式,只能选择一系列模型近似经济系统的动态特征,这使得模型选择成为计量经济学中的基本问题.尽管在通常情况下引入更多解释变量能够优化模型近似效果,但是,由于简单模型相对于复杂模型,具有更加明晰的经济含义,分析人员倾向于选择简单模型,即计量经济学中的“KISS” (keep it sophistically simple) 原则.
简化模型的重要方式便是通过严格检验剔除回归模型中的冗余解释变量.当样本容量有限时,在回归模型中引入过多解释变量,不仅会降低模型参数估计和假设检验效率,而且会导致过度拟合问题,使得具有良好样本内拟合效果的模型无法应用于经济预测中.特别是由于非参数模型存在“维数灾”(curse of dimensionality) 问题,解释变量个数的增加会对模型估计收敛速度产生严重影响,因此,在非参数模型中减少解释变量个数显得尤为重要.然而,盲目删减解释变量,不仅会忽略某些重要解释变量对被解释变量的影响效果,还有可能导致遗漏变量偏差问题,错误估计被解释变量对其它解释变量的反应程度.因此,在建模过程中合理判断是否应当删除某些解释变量,即检验遗漏变量问题,具有重要的理论意义和应用价值.
在线性高斯模型中,研究人员可以借助检验参数显著性的t统计量或者F统计量考察遗漏变量问题.然而,t和F统计量仅能识别线性影响关系,无法捕获经济系统中普遍存在的非线性特征.随着非线性建模技术在经济金融分析中的广泛应用,越来越多的计量分析人员注意到t和F统计量在遗漏变量检验中的局限性,并尝试构建适用于非线性分析框架的检验统计量.与线性模型形式单一不同的是,现有文献表明经济金融变量之间的非线性关系具有多种表现形式,这使得针对某一特定非线性模型的检验统计量极易受到模型设定偏误而得出错误的检验结论.为了避免这一问题,现有文献一般借助非参数方法研究非线性框架下的遗漏变量检验问题.在独立同分布数据生成过程的假定下,Fan和Li[1]以及 Lavergne和Vuong[2]基于非参数估计残差,构造了遗漏变量检验统计量.为了探讨时间序列分析中的遗漏变量问题,Ait-Sahalia等[3]在β-混合条件下,采用非参数核方法估计原假设和备择假设下的条件期望,并基于二者之差构造了遗漏变量检验统计量.这些研究在很大程度上丰富和完善了相关领域的理论研究成果,为研究人员探讨实际经济金融问题提供了重要的理论工具和建模依据.
本文基于非参数回归构造了遗漏变量的检验统计量,探讨了该统计量的渐近分布和局部检验功效,并采用蒙特卡洛模拟考察了统计量的有限样本性质.该统计量不仅避免了模型设定偏误问题,而且同时适用于横截面数据和时间序列数据,并且在原假设成立时渐近服从于标准正态分布,能够十分便利地应用到实证分析中.特别地,本文统计量相对于文献[1-3] 中的统计量,具有如下重要优势:第1,该统计量具有更高的局部检验功效,能够识别出速度更快的收敛到原假设的局部备择假设.文献[1-3] 中检验统计量的收敛速度依赖于备择假设下解释变量的个数,而本文统计量的收敛速度仅依赖于原假设中解释变量的维度,这使得本文统计量缓解了非参数检验中普遍存在的“维数灾”问题,具有更高的检验功效;第2,与现有文献不同的是,本文采用单一带宽估计条件联合期望和条件边际期望,允许二者的非参数估计误差共同决定统计量的渐近分布,这不仅改善了有限样本情况下检验统计量的水平性质,而且还避免了选择多个带宽以及考虑多个偏差项产生的繁杂工作.本文统计量的应用领域与t统计量或者F统计量在线性回归模型中的应用领域类似,如判断是否应当剔除某个解释变量等等.只是,与t和F统计量仅能捕获变量的线性影响关系不同的是,本文统计量避免了模型设定偏误对检验结果的影响,特别适用于考察变量之间的非线性影响关系.例如,作为遗漏变量的特殊应用,本文统计量还可以用于检验均值格兰杰因果关系,相对于Granger[4]构造的F统计量,它能够捕获线性以及多种形式的非线性格兰杰因果关系,可以用于探讨货币与产出的非线性格兰杰因果关系、金融市场的非线性溢出效应等经济与金融问题.
1遗漏变量的原假设与备择假设
记X和Z分别表示维度为dx和dz的随机向量,Y表示一维随机变量.对于每个随机向量,均有n个同分布的弱相依观测值(Xt,Yt,Zt),t=1,2,…,n.此处下标t在时间序列范畴下表示时间指标,在横截面范畴下,代表着横截面单元,如家庭、厂商等等.为了避免模型设定偏误对检验结果产生影响,本文在非参数框架下探讨遗漏变量检验问题.在Yt关于Xt的非参数回归模型中,随机向量Zt不是遗漏变量的原假设和备择假设分别为
(1)
对某些具有正概率测度的y∈
(2)
其中E(A|B)表示随机向量A基于B的条件期望.式 (1) 所示的原假设等价于在如下非参数回归模型中,检验引入Zt能否提高模型的拟合程度
Yt=f(Xt,Zt)+εt
(3)其中f(·)是个未知函数,εt是不可观测的随机误差项,满足E(εt|Xt,Zt)=0.根据式 (1),Ait-Sahalia等采用非参数核方法估计E(Yt|Xt,Zt)以及E(Yt|Xt),并基于二者估计值之差构造了遗漏变量的检验统计量.然而,由于E(Yt|Xt,Zt)的非参数估计涉及dx+dz维平滑,该统计量存在严重的“维数灾”问题.为了缓解“维数灾”问题,提高统计量的检验功效,给出如下引理.
引理1假设Y是实数空间上满足E|Y|<∞的严平稳随机变量,X和Z分别为实数空间dx和dz上的严平稳随机向量,则
cov(Yt,eiv′Zt|Xt)=0, ∀v∈dz
(4)
等价于
E(Yt|Xt,Zt)=E(Yt|Xt)
(5)
引理1可视为Bierens[5]的结论由无条件期望向条件期望的扩展,其具体证明过程在附录部分给出.
根据引理1,可以将式 (1) 和 式(2) 所示的原假设和备择假设等价地表示为
对任意v∈dz
(6)
对某些具有正概率测度的v∈dz
(7)
与原假设 (1) 相比,式 (6) 所示的原假设仅涉及dx维平滑,这使得基于式 (6) 构造的遗漏变量检验统计量能够缓解“维数灾”问题,具有更高的检验功效.关于本文统计量与Ait-Sahalia等统计量检验功效的详细探讨,参见本文3.2节.
2基于非参数回归的检验统计量
2.1非参数回归估计量
σ(v,x)=cov(Yt,eiv′Zt|Xt=x)
=E(eiv′ZtYt|Xt=x)-
E(eiv′Zt|Xt=x)E(Yt|Xt=x)
=0
(8)
由于3个条件期望的估计类似,本文以φyz(v,x)为例予以说明.为了估计φyz(v,x),考虑如下局部加权最小二乘问题
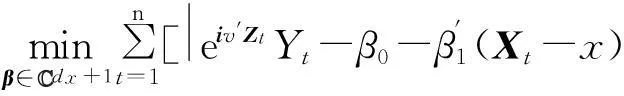
Kh(x-Xt)]
(9)
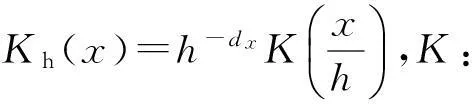
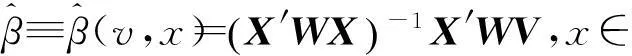
(10)
其中X表示第i行元素为[1,(Xi-x)′]的n×(dx+1)维矩阵;W=diag[Kh(X1-x),…,Kh(Xn-x)].φyz(v,x)的估计值由局部截距项估计值给出
(11)
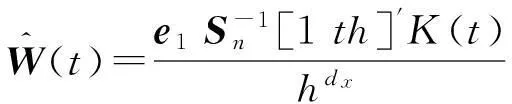
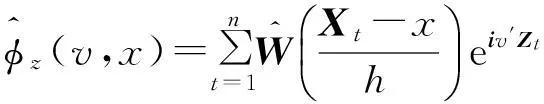
2.2基于非参数回归的检验统计量
根据式 (6), 在Zt不是遗漏变量的原假设下,σ(v,x)=0.因此,可以通过度量
与零之间的差异考察原假设是否成立.本文考虑构造如下二次方形式的检验统计量
(12)
在有限样本情况下,极端值附近的观测样本比较稀疏,这使得条件期望在该取值附近的非参数估计结果并不准确.为了避免或者降低不可信估计量对检验结果的影响,本文在式 (12) 所示的检验统计量中引入加权函数a(·)截断积分.这一处理方式已经在现有文献中得到了广泛应用[3,7-8].另外,由于原假设要求对任意v∈dz,σ(v,x)=0均成立,所以式 (12) 中进一步引入加权函数W(·)综合考虑在v的所有或者多个取值点处σ(v,x)与零之间的差异.相关文献一般采用标准正态累积分布作为加权函数W(·).事实上,W(·)未必是连续函数,任意可数个不连续点构成的非递减函数均符合本文对W(·)的基本假定.例如,采用离散多元累积分布作为离散型加权函数,允许研究者仅考虑v的有限取值点,从而可以避免计算检验统计量时面临的高维积分问题.
(13)
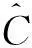
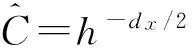
(14)
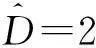
(15)
并且
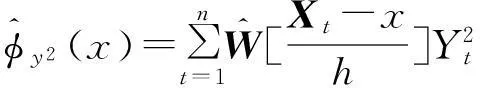
为了改善统计量在有限样本情况下的检验水平,本文进一步构造了如下有限样本形式的检验统计量
(16)
其中有限样本形式的均值表达式
(17)
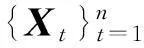
这与式 (6) 所示的原假设相同,因此,可以直接采用式 (12) 所示的统计量检验均值格兰杰因果关系.与Granger[4]基于F统计量的格兰杰因果检验不同的是,本文统计量不仅能够捕获线性格兰杰因果关系,而且能够识别多种形式的非线性均值格兰杰因果关系.
3检验统计量的渐近性质
3.1渐近分布理论
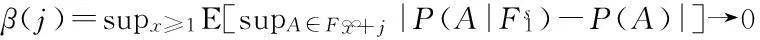
(18)
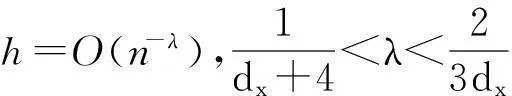
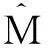
需要特别强调的是,本文采用相同带宽估计条件联合期望φyz(v,x)和条件边际期望φz(v,x)、φy(x),允许二者的非参数估计误差是同阶项,进而共同决定了统计量的渐近分布.这一处理方式与文献[1-3]存在一定差异.上述文献选择了两个不同的带宽估计条件联合期望和条件边际期望,并且对两个带宽的相对阶数施加一定约束,使得条件边际密度函数的非参数估计误差收敛速度更快,从而不会影响统计量的渐近分布.然而,尽管在渐近理论上边际期望的估计误差是联合期望估计误差的高阶项,二者在有限样本情况下可能十分接近.此时,忽略边际期望估计误差可能会影响统计量的有限样本性质,产生严重的水平扭曲问题.Ait-Sahalia等[3]为了改善统计量的有限样本性质,在构造统计量时引入了3个估计偏差项.尽管其中两项是另一项的高阶项,但是在有限样本情况下,三者十分接近,若仅保留首项,则会严重影响统计量的检验水平性质.
3.2局部检验功效
由于本文统计量和Ait-Sahalia等统计量均是在β-混合条件下构造的,因此,有必要详细比较二者的局部检验功效.
Ait-Sahalia等采用如下局部平滑备择假设考察了统计量的检验功效性质
E(Yt|Xt=x,Zt=z)=E(Yt|Xt=x)+
anΔ(x,z)
(19)其中Δ(x,z)满足∬Δ2(x,z)f(x,z)a(x,z)dxdz<∞,并且∫Δ(x,z)f(x,z)dz=0.Ait-Sahalia等证明了在局部备择假设式 (19) 中,其构造统计量的检验功效为an=n-1/2h-(dx+dz)/4.
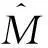
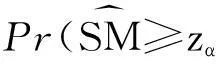
(21)
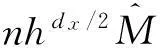
D=2∭a2(x)[φy2(x)-|φy(x)|2]2×
|Φz(v1+v2,x)|2dW(v1)dW(v2)dx×
(22)
其中
Φz(a1+a2,x)=φz(a1+a2,x)-
φz(a1,x)φz(a2,x)
4蒙特卡洛模拟
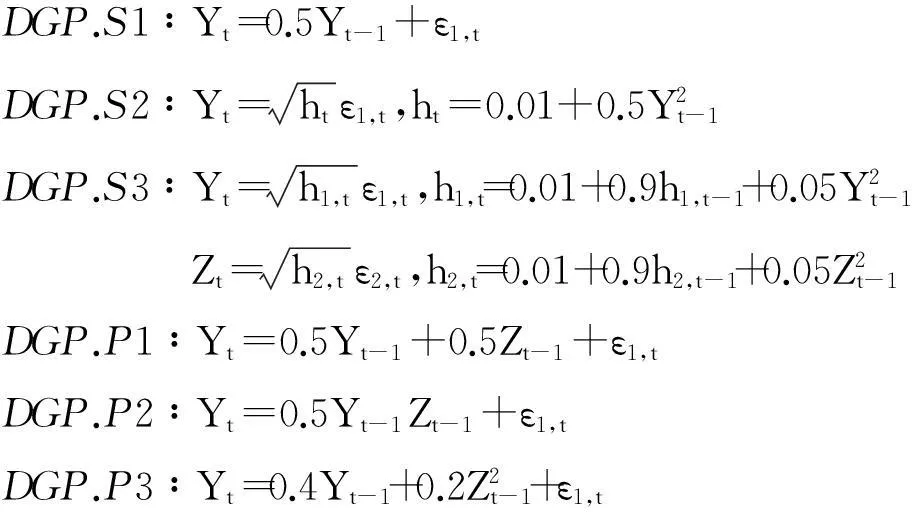
Zt=0.5Zt-1+ε2,t
以上数据生成过程涵盖了文献中应用较为广泛的线性和非线性模型.Su和White[11]曾采用上述数据生成过程探讨条件独立性检验问题.本节需要检验的原假设是,在Yt关于Yt-1的回归方程中,Zt-1不是遗漏变量
(23)
即,检验在一阶滞后情形下,Zt-1是否为Yt的均值格兰杰原因.在上述6个数据生成过程中,DGP.S1-S3满足式 (23) 所示的原假设,从而可以考察统计量的检验水平性质,DGP.P1-P3则用于探讨统计量的检验功效性质.特别地,在DGP.P1-P3中,除DGP.P1之外的其它所有数据生成过程都是非线性的.
5实证应用
如前所述,均值格兰杰因果检验可视为遗漏变量检验的特殊应用,因此,本节将采用前文构造的统计量考察产出缺口在均值上是否为通货膨胀率的格兰杰原因,即考察文献中得到广泛探讨的“产出—通胀”型菲利普斯曲线能否用于预测我国通胀率*预测分为样本内预测和样本外预测两类,此处探讨的是样本内预测.由于本文的研究目的不是构造样本外预测的检验统计量,故不再对样本外预测效果的评价展开讨论..Phillips[14]指出,失业与通货膨胀之间存在着反向变动关系;奥肯(Okun[15])定律则说明产出缺口与失业率之间也存在着反向变动关系.二者结合起来,便形成了“产出—通胀”型菲利普斯曲线,表明通胀率与产出缺口呈正向关系,即当产出缺口为正时,整个经济体面临通胀压力;反之,存在通缩压力.根据宏观经济学理论,若出现正的产出缺口,意味着总需求大于总供给,则通胀压力将会增大;反之,若出现负的缺口,即总供给大于总需求,则通缩压力增加.这为“产出—通胀”型菲利普斯曲线的存在提供了一定的经济理论依据.
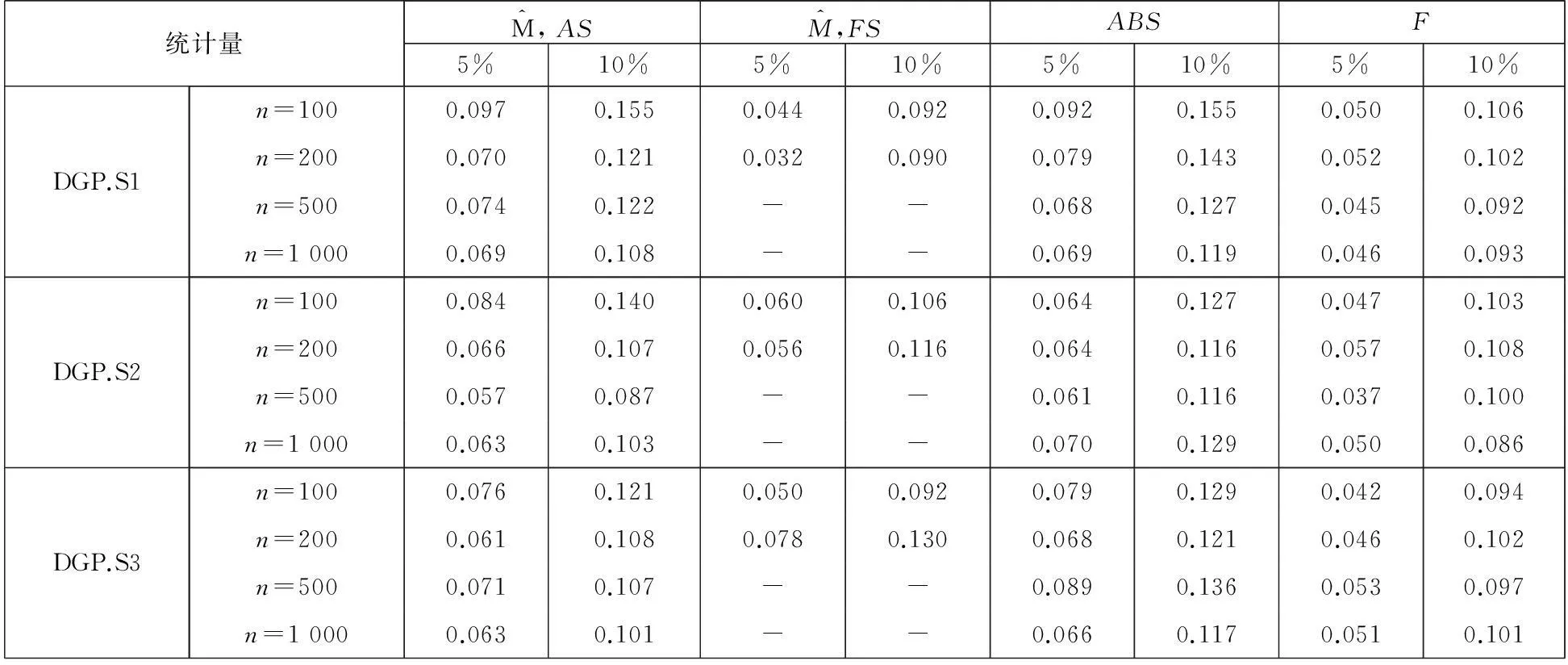
表1 DGP.S1-S3的检验水平性质
注: 1.F表示Granger[4]线性格兰杰因果关系检验的F统计量计算结果,ABS表示Ait-Sahalia等[3]遗漏变量检验统计量的计算结果;
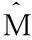
2. 表中渐近分布的计算结果均是基于标准正态分布单边临界值得到的1 000次蒙特卡洛模拟的拒绝概率.
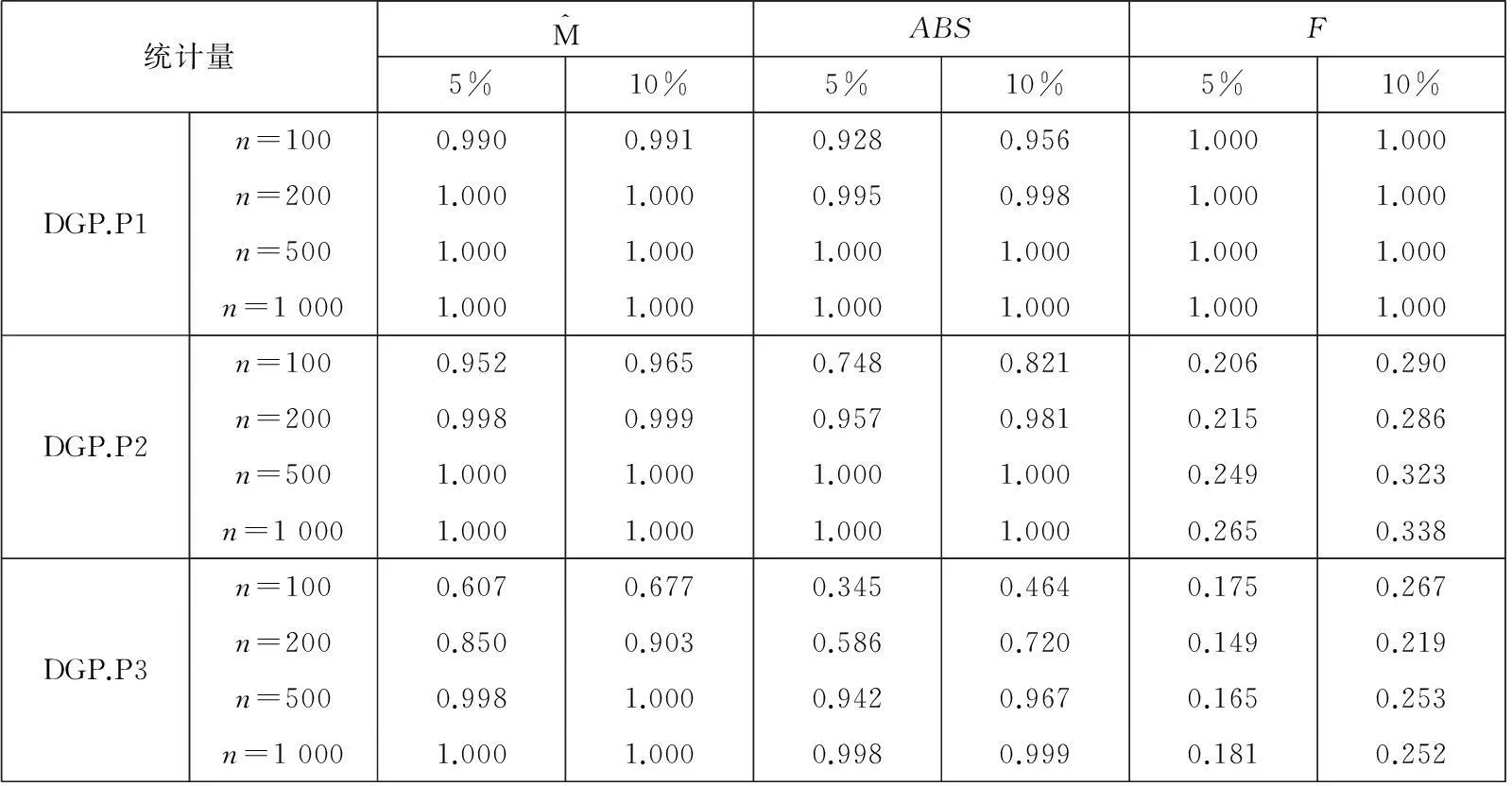
表2 DGP.P1-P3的检验功效
注: 1.F表示Granger[4]线性格兰杰因果关系的F统计量计算结果,ABS表示Ait-Sahalia等[3]遗漏变量检验统计量的计算结果;
2. 表中报告了基于标准正态分布单边临界值得到的1 000次蒙特卡洛模拟的拒绝概率.
5.1指标选取与数据处理
由于我国官方统计资料仅对季度GDP予以核算,没有直接可获得的月度GDP统计资料,本文采用季度频率予以建模,选取的样本区间为1983年1季度至2012年4季度,共120个样本点,所有数据均来源于中经网统计数据库和国家统计局网站.数据选取与处理简要描述如下:
1)通货膨胀率的选取本文通过消费者价格指数的月度同比数据计算年化的季度通胀率,其中1983年至1989年的消费者价格指数采用商品零售价格指数替代.由于官方CPI数据为月度同比数据,本文通过3项移动平均计算出季度同比CPI数据,并根据(季度CPI-1)×100%获得季度通货膨胀率πt,季度通货膨胀率时间序列图如图1(a)所示;
2)产出缺口的测算首先根据官方统计资料公布的同比累计GDP增长率和名义GDP水平值推算出1992年—2012年以1992年为不变价的季度实际GDP;其次,为扩充数据样本,使得检验结果更加可靠,按照刘金全等[16]、陈浪南和刘宏伟[17]等采用的方法对我国1978年—1991年度实际GDP进行季度分解 (具体分解方法可参考Abeysinghe和Gulasekaran[18]),将实际GDP数据样本扩展到1978年1季度;再次,采用Tramo-Seats方法对实际GDP数据进行季度调整,并计算对数百分化数据y=100×lnGDPt;最后,参考郑挺国和王霞[19],采用HP (hodrick-prescott) 滤波、QT (quadratic trend) 滤波、BK (baxter-king) 滤波、CF (christiano-fitzgerald) 滤波,以及基于不可观测成分 (UC) 模型的CL (Harvey[20]; Clark[21]) 模型和HJ (Harvey和Jäger[22]) 模型6种退势方法估算出我国1978年—2012年的产出缺口.图1(b)-(d)给出了6种不同退势方法得出的产出缺口时间序列图.
5.2实证检验结果

图1(a) 通货膨胀率Fig. 1(a) Inflation rate
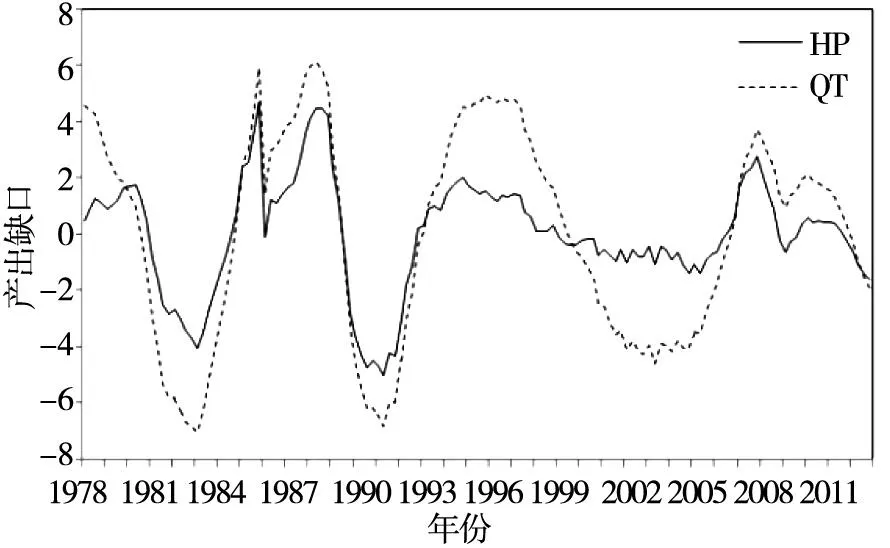
图1(b) 基于HP滤波和QT滤波的产出缺口Fig. 1(b) Output gaps based on HP and QT filters
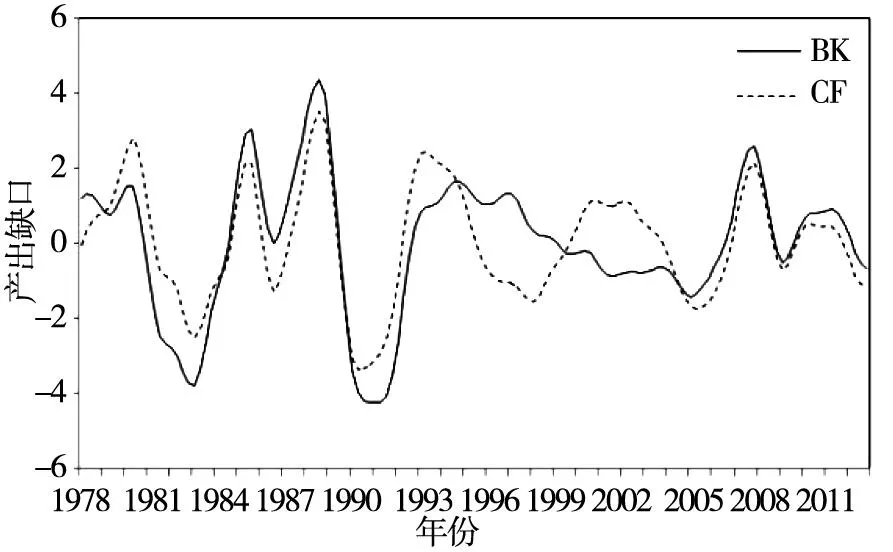
图1(c) 基于BK滤波和CF滤波的产出缺口Fig. 1(c) Output gaps based on BK and CF filters
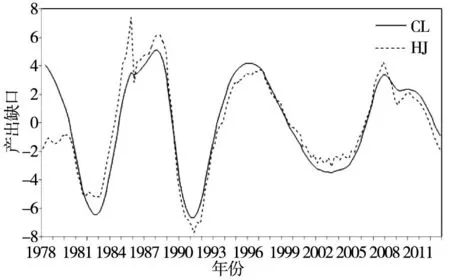
图1(d) 基于CL滤波和HJ滤波的产出缺口Fig. 1(d) Output gaps based on CL and HJ filtes
表3 均值格兰杰因果关系检验结果
Table 3 Results of Granger causality tests in mean

HPQTBKCFCLHJGRF0.01560.34150.00950.00000.62260.33700.2027M^0.00000.00000.00000.00000.00000.00000.0000
2.表中前6列分别为采用6种滤波的产出缺口估计值的检验结果,最后一列为GDP同比增速的检验结果.
6结束语
考虑到遗漏变量问题在模型选择和估计中发挥的重要作用,本文借助非参数回归方法,构造了同时适用于线性以及非线性回归模型的遗漏变量检验统计量.该统计量既适用于横截面数据又适用于时间序列数据,并且在原假设成立时渐近服从于标准正态分布,能够十分便利地应用到实证研究中.特别地,与文献[1-3] 基于非参数方法构造的检验统计量相比,本文统计量至少具有如下两点优势:
第1,本文统计量的收敛速度仅依赖于原假设成立时解释变量的维度,能够识别出收敛到原假设速度更快的局部备择假设.文献[1-3] 检验统计量的收敛速度依赖于备择假设下解释变量的维度,涉及更高维度的平滑.因此,与之相比,本文统计量不仅在一定程度上缓解了“维数灾”问题,而且还因收敛速度更快而具有更高的局部检验功效;
第2,与现有文献不同的是,本文采用单一带宽估计条件联合期望和条件边际期望,允许二者的非参数估计误差共同决定统计量的渐近分布,使得推导渐近分布时忽略的高阶项更少.这不仅改善了统计量的有限样本性质,而且还避免了在实际应用中选择多个带宽以及计算多个偏差项带来的繁杂工作.
此外,本文采用蒙特卡洛模拟考察了统计量的有限样本性质.数值模拟结果表明本文统计量具有合理的检验水平以及良好的检验功效.特别地,与Ait-Sahalia等以及F统计量相比,本文统计量不仅能够同时捕获线性以及多种非线性回归模型中的遗漏变量问题,而且具有比它更高的检验功效,这与本文理论部分的分析结论相一致.最后,本文还应用该统计量考察了我国产出缺口在通胀预测中的作用,验证了非线性“产出—通胀”型菲利普斯曲线在我国通胀预测中的适用性.
本文未来的研究方向包括但不仅限于如下几点:第1,最优带宽的选取.本文定理1给出了带宽的许可阶数,但是在实际操作中如何选择带宽,并没有给出进一步的建议.Gao和Gijbels[29]基于给定显著性水平最大化检验功效的原则探讨了其检验统计量带宽的选择问题,但是,Gao和Gijbels的结果依赖于统计量的形式、数据生成过程、核函数等多种因素,无法直接应用到本文检验中,因此,本文将最优带宽的选取作为下一步的研究方向;第2,长记忆过程的条件独立性检验.本文假设1的β-混合条件约束了时间序列的相关程度.对于不满足该条件的长记忆过程,检验统计量的均值和方差表达式都会发生改变.构造适用于长记忆过程的条件独立性检验统计量,将是笔者的第2个研究方向;第3,样本外预测的非参数检验.本文检验统计量可用于考察均值格兰杰因果关系,即样本内预测,但是并不适用于样本外预测.如何构建样本外预测的非参数检验统计量,将是笔者的第3个研究方向.
参 考 文 献:
[1]Fan Y, Li Q. Consistent model specification tests: Omitted variables and semiparametric function forms[J]. Econometrica, 1996, 64(4): 865-890.
[2]Lavergne P, Vuong Q. Nonparametric significance testing[J]. Econometric Theory, 2000, 16(4): 576-601.
[3]Ait-Sahalia Y, Bickel P J, Stocker T M. Goodness-of-fit tests for kernel regression with an application to option implied volatilities[J]. Journal of Econometrics, 2001, 105(2): 363-412.
[4]Granger C W J. Investigating causal relations by econometric models and cross-spectral methods[J]. Econometrica, 1969, 37(3): 424-438.
[5]Bierens H J. Consistent model specification tests[J]. Journal of Econometrics, 1982, 20(1): 105-134.
[6]Fan J, Gijbels I. Variable bandwidth and local linear regression smoothers[J]. Annals of Statistics, 1992, 20(4): 2008-2036.
[7]Hastie T J, Loader C. Local regression: Automatic kernel carpentry (with discussion)[J]. Statistical Science, 1993, 8(2): 120-143.
[8]Hjellvik V, Yao Q, Tjostheim D. Linearity testing using local polynomial approximation[J]. Journal of Statistical Planning and Inference, 1998, 68(2): 295-321.
[9]Chen B, Hong Y. Characteristic function-based testing for multifactor continuous-time Markov models via nonparametric regression[J]. Econometric Theory, 2010, 26(4): 1115-1179.
[10]Su L, White H. A consistent characteristic function-based test for conditional independence[J]. Journal of Econometrics, 2007, 141(2): 807-834.
[11]Su L, White H. A nonparametric hellinger metric test for conditional independence[J]. Econometric Theory, 2008, 24(4): 829-864.
[12]Fan Y, Li Q. Root-n-consistent estimation of partially linear time series models[J]. Journal of Nonparametric Statistics, 1999, 20(1): 245-271.
[13]Tenreiro C. Loi asymptotique des erreurs quadratiques integrees des estimateurs a noyau de la densite et de la regression sou des conditions de dependance[J]. Portugaliae Mathematica, 1997, 54(2): 187-213.
[14]Phillips A W. The relationship between unemployment and the rate of change of monetary wages in the United Kingdom: 1861-1957[J]. Economica, 1958, 25(100): 283-299.
[15]Okun A M. Potential GNP: Its measurement and significance[C]// Proceedings of the Business and Economics Statistics Section, American Statistical Association (Washington D. C.: American Statistical Association), 1962, 7: 98-103.
[16]刘金全, 刘志刚, 于冬. 我国经济周期波动性与阶段性之间关联的非对称性检验—Plucking 模型对中国经济的实证研究[J]. 统计研究, 2005, 22(8): 38-43.
Liu Jinquan, Liu Zhigang, Yu Dong. The non-symmetric test of linking between volatility and phase of economic cycle of China: The experimental analysis of application of plucking model to China economic analysis[J]. Statistical Research, 2005, 22(8): 38-43. (in Chinese)
[17]陈浪南, 刘宏伟. 我国经济周期波动的非对称性和持续性研究[J]. 经济研究, 2007, 42(4): 43-52.
Chen Langnan, Liu Hongwei. Empirical investigation on the asymmetry and persistence of Chinese business cycle[J]. Economic Research Journal, 2007, 42(4): 43-52. (in Chinese)
[18]Abeysinghe T, Gulasekaran R. Quarterly real GDP estimates for China and ASEAN4 with a forecast evaluation[J]. Journal of Forecasting, 2004, 23(6): 431-447.
[19]郑挺国, 王霞. 中国产出缺口的实时估计及其可靠性研究[J]. 经济研究, 2010, 45(10): 129-142.
Zheng Tingguo, Wang Xia. Real time estimates of the Chinese output gap and the reliability analysis[J]. Economic Research Journal, 2010, 45(10): 129-142. (in Chinese)
[20]Harvey A C. Trends and cycles in macroeconomic time series[J]. Journal of Business and Economic Statistics, 1985, 3(3): 216-227.
[21]Clark P. The cyclical component of U.S. economic activity[J]. Quarterly Journal of Economics, 1987, 102(4): 797-814.
[22]Harvey A, Jäger A. Detrending, stylized facts and the business cycle[J]. Journal of Applied Econometrics, 1993, 8(3): 231-247.
[23]Dickey D A, Fuller W A. Distribution of the estimators for autoregressive time series with a unit root[J]. Journal of the American Statistical Association, 1979, 74(366a): 427-431.
[24]Turner D. Speed limit and asymmetric inflation effects from the output gap in the major economies[J]. OECD Economic Studies, 1995, 24: 58-87.
[25]Debelle G, Laxton D. Is the PhillipsCurve Really a Curve: Some Evidence for Canada, the United Kingdom, and the United States[R]. IMF, 1997, 44: 249-282.
[26]Stiglitz J. Reflections on the natural rate hypothesis[J]. Journal of Economic Perspectives, 1997, 11(1): 3-10.
[27]刘金全, 金春雨, 郑挺国. 中国菲利普斯曲线的动态性与通货膨胀率预期的轨迹: 基于状态空间区制转移模型的研究[J]. 世界经济, 2006, (6): 16-28.
Liu Jinquan, Jin Chunyu, Zheng Tingguo. The dynamic of China’s Phillips curve and the track of expected inflation rate: A study based on state space regime switching model[J]. The Journal of World Economy, 2006, (6): 16-28. (in Chinese)
[28]Chung K L. A Course in Probability Theory (Third edition)[M]. New York: Academic Press, 2001.
[29]Gao J, Gijbels I. Bandwidth selection in nonparametric kernel testing[J]. Journal of the American Statistical Association, 2008, 103(484): 1584-1594.
1.引理1的证明
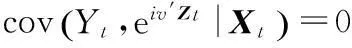
对eiv′Zt关于Zt在原点附件做泰勒展开可得
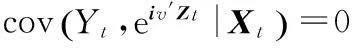
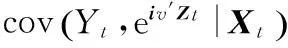
根据Chung[28]中的定理9.1.2可知,在实数空间上存在一个布莱尔可测的实函数,不妨设为q,满足
E(Yt|Xt)=q(Xt)
(A.1)
E(Yt|Xt,Zt)-q(Xt)=r(Xt,Zt)
(A.2)
令r1(·)=max{r(·),0},r2(·)=max{-r(·),0},则r1和r2均为实数空间上的非负布莱尔可测实函数,并且满足
r=r1-r2
令c1(X)=Ez[r1(Xt,Zt)]>0,c2(X)=Ez[r2(Xt,Zt)]>0,其中EZ(·)表示关于Z求条件期望.显然,r1(Xt,Zt)和r2(Xt,Zt)关于Z的条件期望为Xt的函数.由于
由上式以及cov(Yt,eiv′Zt|Xt)=0可得
E[r(Xt,Zt)eiv′Zt|Xt]=0∀v∈dz.
另外,在欧几里得空间上的布莱尔域B定义两个概率测度F1以及F2满足
Fj(B,X)=∫Brj(X,u)dF(u|X)/cj(X),j=1,2(A.3)
其中F(u|X)是由随机向量Zt生成的条件概率测度,B是Β上的任意布莱尔集.据此可得
由于E[r(Xt,Zt)eiv′Zt|Xt]=0,故有
c1(Xt)∫eiv′ZtdF1(u|Xt)=c2(Xt)∫eiv′ZtdF2(u|Xt)
进一步令u=0可得
c1(x)=c2(x)c1(Xt)=c2(Xt),∀Xt∈G
(A.4)
由以上两式可知
∫eiv′ZtdF1(u|Xt)=∫eiv′ZtdF2(u|Xt), ∀v∈dz
上式意味着概率测度F1和F2是等价的,即,对任意布莱尔集B,F1(B|X)=F2(B|X)均成立.根据式(A.3)和式(A.4)可得
∫Br1(u,X)dF(u|X)=∫Br2(u,X)dF(u|X)
对任意X∈G,定义布莱尔集
B1(X)={Z∈dz∶r(X,z)>0}
并且
B2(X)={Z∈dz∶r(X,z)<0}
则有
∫B1(X)r(u,X)dF(u|X)=0
并且
∫B2(X)r(u,X)dF(u|X)=0
即
∫B1(X)∪B2(X)r(u,X)dF(u|X)=0
这表明对任意X∈G,B1(X)∪B2(X)={Z∈dz∶r(X,z)≠0}在概率测度F上为空集,即r(X,u)=0a.s.
根据式(A.2) 和 式(A.3) 可得E(Yt|Xt,Zt)=E(Yt|Xt)a.s.
证毕.
2.定理1的证明
(A.5)
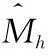
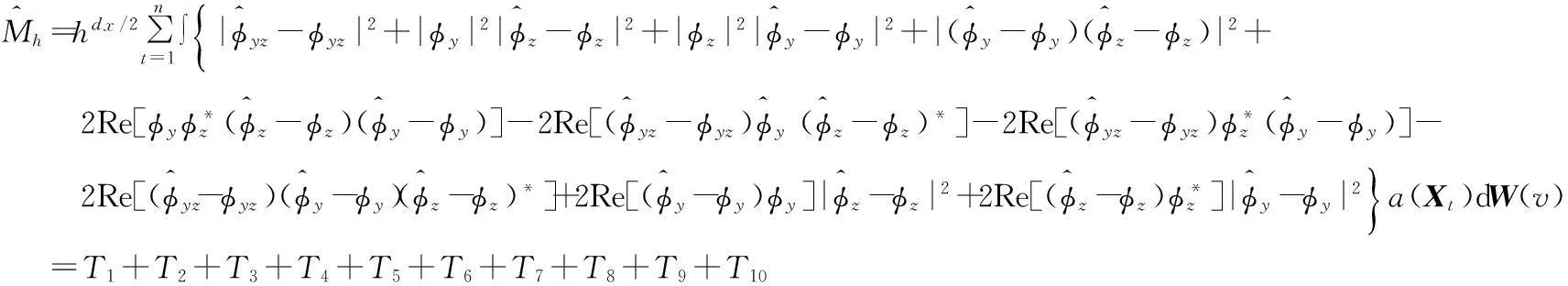
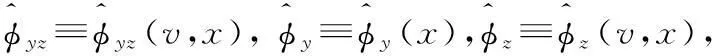
引理A.1在定理1的条件以及原假设成立的情况下
(A.7)
其中
式中ξs=(Xs,Ys,Zs).
引理A.2在定理1的条件以及原假设成立的情况下
(A.8)
其中
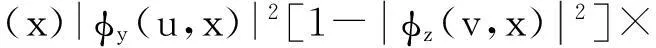
dW(v)dx∫K(τ)2dτ,
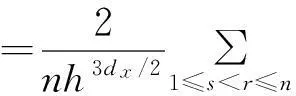
Re[εz(v,Xs)εz(v,Xr)*]dW(v)dx
引理A.3在定理1的条件以及原假设成立的情况下
(A.9)
其中
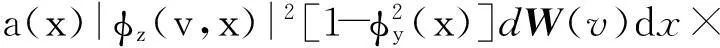
∫K(τ)2dτ,
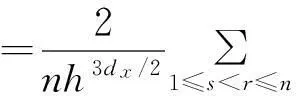
引理A.4在定理1的条件以及原假设成立的情况下
(A.9)
其中
引理A.5在定理1的条件以及原假设成立的情况下
其中
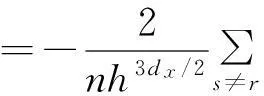
Re[φy(x)εyz(v,Xs)εz(v,Xr)*]dW(v)dx
引理A.6在定理1的条件以及原假设成立的情况下
其中
Re[φz(v,x)*εyz(v,Xs)εy(v,Xr)]dW(v)dx
引理A.7在定理1的条件以及原假设成立的情况下
T7+T8+T9+T10=oP(1)
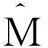
并且
Φz(v1+v2,x)=φz(v1+v2,x)-φz(v1,x)φz(v2,x)
根据引理A.1至引理A.9可知,定理1得证.篇幅所限,此处不再给出引理A.1至A.9的证明过程,感兴趣者可向作者索取.
3.定理2的证明
在局部备择假设式(20)成立的条件下
易证
以及
var(M1)=OP(hdx/2(n-1h-dx+h4))=oP(1)
根据契比雪夫不等式,即可得到M1=oP(1).根据大数定理,有
证毕.
附录:
Nonparametric-regression-based testing for omitted variables
WANGXia1,HONGYong-miao2,3
1.School of Economics and Management, University of Chinese Academy of Sciences, Beijing 100190, China;2.Department of Economics and Department of Statistical Sciences, Cornell University, NY 14850, USA;3.The Wang Yanan Institute for Studies in Economics (WISE), Xiamen University, Xiamen 361005, China
Abstract:This paper proposes a nonparametric-regression-based test for omitted variables, which is applicable in both cross-sectional and time series contexts. Our test not only avoids the model misspecification problem, but also are locally more powerful than the existing tests. Moreover, unlike many other nonparametric-based tests, we use a single bandwidth rather than two different bandwidths in estimating both the conditional joint and marginal expectations, which significantly improves the size performance of our test in finite samples. Monte Carlo studies demonstrate the well behavior of our test in finite samples, which could not only capture the omitted variables feature in linear and nonlinear regressions, but also is more powerful than Ait-Sahalia et al.’s (2001) test. In an application to testing the nonlinear Granger causality in mean, we document the existence of nonlinear relationships between theoutput gap and inflation,that is, the nonlinear “output-inflation” type of Phillips curve maybe is more suitable for China’s inflation forecast.
Key words:omitted variable; nonlinear; nonparametric regression; power; Granger causality in mean
中图分类号:F224.0
文献标识码:A
文章编号:1007-9807(2016)03-0077-15
作者简介:王霞 (1985—), 女, 山东济宁人, 博士, 讲师. Email: wangxia@ucas.ac.cn
基金项目:国家自然科学青年基金资助项目(71401160);教育部人文社会科学研究青年基金资助项目(14YJC790120):中国科学院大学校部教师与研究所科研合作专项基金资助项目.
收稿日期:(①) 2013-05-21;
修订日期:2013-12-25.
猜你喜欢
中国人口·资源与环境(2016年11期)2017-02-17
财经理论与实践(2016年6期)2017-02-09
价值工程(2017年2期)2017-02-06
汽车科技(2016年5期)2016-11-14
科技视界(2016年23期)2016-11-04
科学与财富(2016年28期)2016-10-14
科技视界(2016年24期)2016-10-11
中国市场(2016年29期)2016-07-19
电脑知识与技术(2016年14期)2016-06-30
软科学(2015年9期)2015-10-27
