
基于GPU改进的并行人工蜂群算法
2013-12-22 12:25王智广王文亮张同举刘伟峰中国石油大学
中南民族大学学报(自然科学版) 2013年4期
王智广,王文亮,张同举,鲁 强,刘伟峰(中国石油大学
(北京) 地球物理与信息工程学院,北京 102249; 2中国石油化工股份有限公司石油勘探开发研究院,北京 100083; 3中国石油化工集团公司 多波地震技术重点实验室,北京 100083)
人工蜂群算法[1](Artificial Bee Colony,ABC)是一种模拟自然界蜜蜂群体觅食行为而提出的、相对比较新的群体智能算法.该算法模拟了真实世界蜜蜂群体采蜜行为,蜜蜂根据各自的分工进行不同的采蜜活动.在采蜜过程中,由于独有的角色转换机制以及在自组织模式下实现信息的交流和共享,从而使蜜蜂寻找到最优蜜源.该算法可解决一系列优化问题,包括函数优化问题、组合优化问题等[2,3].
在文献[4]中,作者已经对于选择OpenCL并行编程模型来研究人工蜂群算法做了许多研究,并且文献[4]对于人工蜂群算法的基本原理进行了详细的论述.本文在文献[4]中提出的并行人工蜂群算法的基础上,对于先前的并行人工蜂群算法进行了很多改进,采用OpenCL的本地内存(local memory)、并行规约(reduction)等技术,提出了一种基于GPU改进的并行人工蜂群算法.通过实验结果的分析,改进的算法不仅提高了算法的执行效率,得到了很好的加速比,而且其收敛性能得到明显的改善,说明本文提出的基于GPU改进的并行人工蜂群算法是有效的.
1 人工蜂群算法性能分析
根据文献[4]中对于人工蜂群算法基本原理的研究,在采蜜蜂和跟随蜂阶段,需要对邻域进行搜索,并且需要计算大量的适应度值.随着问题维度的增加,需要耗费更长的时间来完成适应度值的计算和搜索.
如表1所示,通过对于ABC算法主要功能函数在三个不同函数优化问题(Griewank函数、Rastrigin函数和Rosenbrock函数)的测试,得到ABC算法主要功能函数的运行时间(单位为s).

表1 ABC算法分析
通过表1的结果和对人工蜂群算法的研究,得到最耗时的部分SendOnlookerBees函数和SendEmployedBees函数,下面基于GPU改进的并行人工蜂群算法主要针对采蜜蜂和跟随蜂阶段进行并行化研究.
3 并行人工蜂群算法
通过文献[4]对于人工蜂群算法基本原理的研究,结合GPU自身架构特点,采用本地内存、并行规约等技术来改进并行人工蜂群算法的执行效率.具体来说,基于GPU改进的人工蜂群算法并行化设计需要解决以下问题:GPU中数据存储、随机数的GPU处理、采蜜蜂搜索过程的GPU设计、计算最优适应度值、跟随蜂搜索过程的GPU设计.
3.1 GPU中的数据存储
设采蜜蜂和跟随蜂种群大小都为N,用D表示搜索的维度大小,用N×D的二维数组存储N个蜜源的位置信息(foods[N][D]),用N维度的列向量存储适应度值(fitness[N]).在文献[4]中,把蜜源和适应度值存储在GPU的全局内存(global memory),但这样读取数据耗费很多时间,计算结果很不理想.当考虑到GPU的计算效率,我们使用本地内存(local memory)来存储部分数据,如图1所示,具体过程如下.
步骤一:初始时,把全局内存中的数据(foods[N][D]和fitness[N])分配到本地内存中来存储,即每个工作组(work group)分配本地内存,用来共享存储数据——蜜源和适应度值(s_foods和s_fitness).
步骤二:工作组中每个工作项(work item)分配私有内存(private memory),并且每个工作项都有自己的编号tid,用solution来记录每个维度的蜜源信息(对应于每个tid编号).之后,通过solution来计算出相应tid所对应新的适应度值.
步骤三:每个工作项通过solution计算新的适应度值进行贪婪选择,即新的适应度值与之旧的适应度值(s_fitness)进行比较,如果新的适应度值大于旧的,则在全局内存中更新对应的蜜源的位置信息和适应度值.
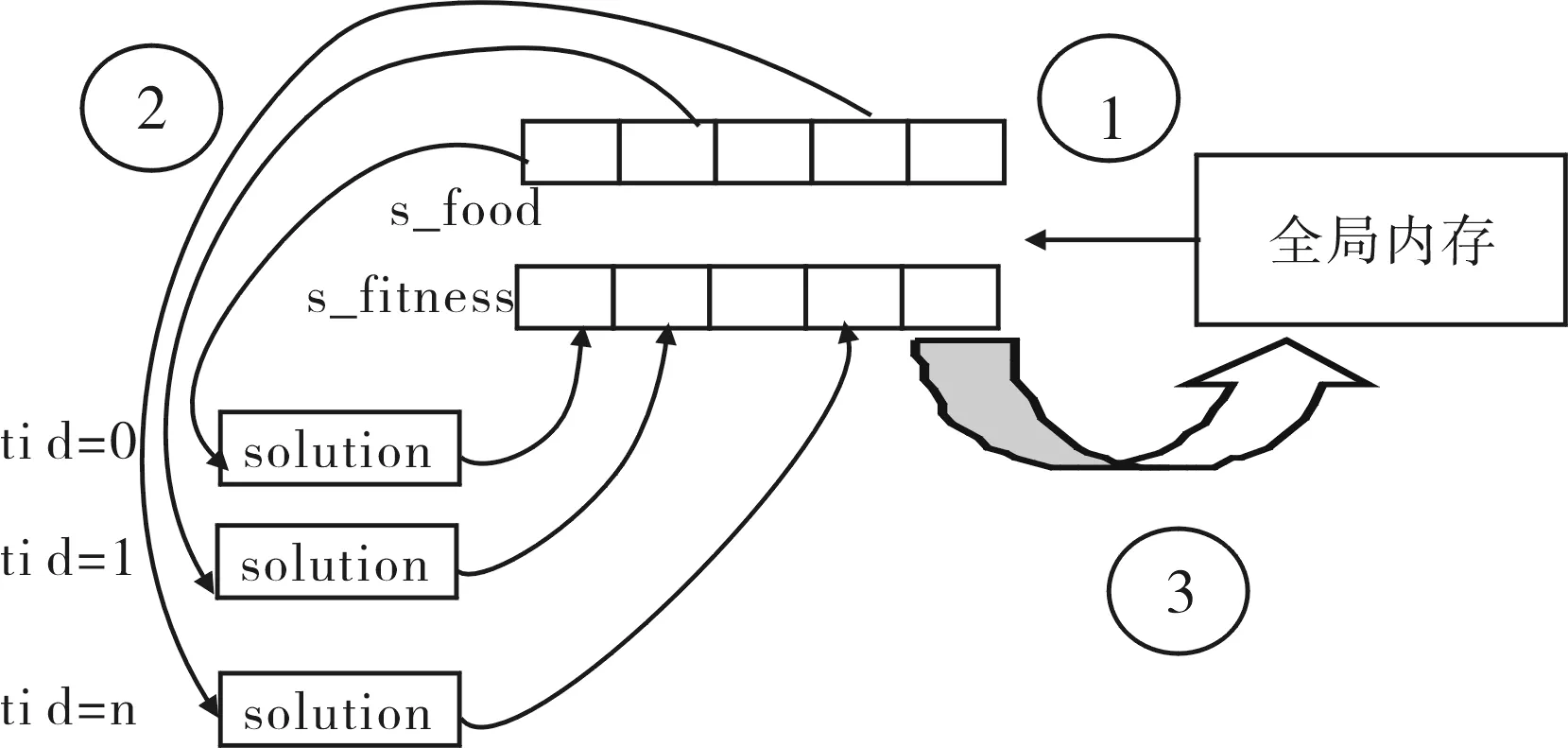
图1 数据存储
3.2 随机数的GPU处理
在人工蜂群算法采蜜蜂和跟随蜂的搜索过程都需要使用大量的随机数,而GPU本身不提供随机数生成函数,若利用CPU生成随机数,在传给GPU会进行大量的通信而影响效率.本文采用梅森旋转算法[5](Mersenne Twister,MT)在GPU中生成大量随机数.定义一张1024×1024大小的随机数数组rand,在CPU上初始化32个种子,并且传递到GPU,在GPU中生成随机数数组,之后在采蜜蜂和跟随蜂的搜索过程中进行使用.整个过程只调用一次梅森旋转算法来产生所需的随机数.
3.3 采蜜蜂搜索过程的GPU设计
在采蜜蜂寻找蜜源的过程中,每只采蜜蜂都在各自区域及其附近邻域的进行搜索,采蜜蜂之间依赖程度低,所以天然地存在并行性.在文献[4]中,每只采蜜蜂对应一个工作组(work group),这样计算效率很低.本文则采用每只采蜜蜂对应一个工作项(work item).如图2所示的OpenCL并行模型,一共有4个工作组,每个工作组有4个工作项,具体的过程如下.
步骤一:初始时,每个蜜源只有一只采蜜蜂,把蜜源的位置信息、适应度值等从全局内存拷贝到本地内存中.
步骤二:每只采蜜蜂对应一个工作项,并且独立地进行搜索工作,即通过本地内存中蜜源位置信息随机搜索,并计算出新的适应度值.

图2 人工蜂群算法GPU并行化模型
步骤三:等到搜索结束,对于每个蜜源通过适应度值贪婪选择,将新的适应度值与旧的进行比较,保留适应度值较高的蜜源信息,并将全局存储器中对应蜜源的位置信息、适应度值进行更新.
3.4 计算最优适应度值
在CPU中计算最优适应度值很简单,只需将全部适应度值进行比较,求出最大值.但将这样的算法移植到GPU则需要很长的时间交换数据,所以传统方法在GPU上无法直接计算.本文采用GPU并行规约(reduction)算法[6]来计算最优适应度值.并行规约算法可以将计算N个数的时间复杂度相对于原来串行算法O(N)降到O(logN).当N的规模很大时,算法效率提升显著.
3.5 跟随蜂搜索过程的GPU设计
在跟随蜂阶段,由于其选择过程是全局概率选择,是一种全局轮盘赌选择方式,相互之间有依赖,需要在整个种群搜集信息,不适合本文采用的GPU硬件进行细粒度并行算法.本文采用局部选择方式进行选择操作,相对于文献[4]的左右邻域选择几率相等的设计,本文采用优先右邻域的策略进行局部选择.将待处理的每只跟随蜂i对应搜索蜜源i,并选择其左右邻域.如图3所示,具体过程如下.
步骤一:初始化数据,将全局内存中蜜源位置信息和适应度值等信息拷贝到本地内存中.跟随蜂0对应蜜源位置0,其左右邻域为N-1、1,依此类推.

图3 跟随蜂局部选择
步骤二:根据采蜜蜂搜索结果,计算出对应的选择概率prob值.之后,对于这3个蜜源分别产生3个随机数(随机数范围[0,1]),如果“蜜源0”产生的随机数大于选择prob值,则把该蜜源标记成1,不在进行其他蜜源比较;否则选择右邻域“蜜源1”,同样比较随机数与prob值大小,如果满足条件,则把该蜜源标记成1.否则选择左邻域“蜜源N-1”进行同样操作,如果还不满足条件,则终止搜索,并把trail值加1.
步骤三:根据步骤二的结果,对于已经标记的蜜源及其附近进行搜索,即对于已经标记的蜜源计算相应的适应度值.等到搜索结束,通过适应度值贪婪选择,保留适应度值高的蜜源,并将全局存储器中对应蜜源的位置信息、适应度值等进行更新.由于跟随蜂的种群大小可能改变,可以根据实际情况设置邻域大小.
3.6 人工蜂群算法的GPU实现
在解决上述问题的基础上,根据OpenCL并行编程模型,具体实现过程如下.
步骤一:初始化参数.在CPU中,对foods[N][D]、fitness[N]、prob[N]、trial[N]以及梅森旋转算法种子等参数进行初始化.
步骤二:将数据和参数传输到GPU全局内存中.
步骤三:产生随机数.采用3.2节提到的梅森旋转算法一次性产生1024×1024大小的随机数数组rand,存储在GPU中.
步骤四:采蜜蜂阶段.根据3.3节采蜜蜂搜索过程并行化方法,从全局内存将蜜源的位置信息、适应度值拷贝到本地内存中,让每只采蜜蜂在对应的蜜源及其附近进行搜索,并计算适应度值,按照适应度值大小进行贪婪选择,对于满足条件的蜜源进行更新蜜源的位置信息及其适应度值,把数据拷贝回GPU全局内存中.
步骤五:跟随蜂阶段.根据3.5节跟随蜂搜索过程并行化方法,从全局内存将蜜源的位置信息、适应度值拷贝到本地内存中,并按照可能性概率进行右邻域优先的局部选择,然后每只采蜜蜂在对应的蜜源及其附近进行搜索,并计算适应度值,按照适应度值大小进行贪婪选择,对于满足条件的蜜源进行更新蜜源的位置信息及其适应度值,把数据拷贝回GPU全局内存中.
步骤六:侦查蜂阶段.若搜寻次数超过一定限制limit,仍没找到具有更高适应度值的蜜源,则放弃该蜜源,并且在GPU全局内存中随机产生一个新的蜜源.
步骤七:记录到目前的全局最优解,并跳转至步骤四,直到满足算法结束条件,把最终的全局最优解等信息从GPU传回CPU,进行输出显示.
4 实验及其结果
4.1 测试的基准函数
为了评价算法性能,我们利用本文的GPU人工蜂群算法执行D. Karaboge和B. Basturk[7]中介绍的3个经典基准函数,分别为Greiwank函数、Rastrigin函数和Rosenbrock函数,具体函数表示以及取值范围等可以参考文献[4]实验及其结果部分.
4.2 实验环境及参数设定
本实验CPU采用Intel Xeon E5504处理器,8GB内存.GPU为NVIDIA Tesla C1060处理器.操作系统为Red Hat Enterprise Linux 5.4,OpenCL 1.0 CUDA 3.2.串行和并行人工蜂群算法都设置最大循环次数为2000次.
4.3 实验结果及其分析
(1) 问题维度的增加.实验中,假定蜜蜂种群的数量一定时(测试的时候选择种群规模为6000),问题维度从30变化到90.如表2所列数据,f1、f2、f3分别表示Griewank函数、Rastrigin函数和Rosenbrock函数,表中的数据是3个函数在串行算法(CPU计算)和并行算法(CPU-GPU异构计算)运行时间(单位为s).通过表中的数据可以看出,在不同维度下,随着问题维度的增加,串行算法运行时间也相应的增加,在维度为90时,Griewank函数和Rastrigin函数运行时间可以达到100 s以上;而并行算法运行时间只在10 s左右变化,当维度大于60时,运行时间还有下降的趋势,说明GPU硬件适合进行大规模密集型计算.

表2 维度与运行时间关系表
如图4所示,3个基准函数随着问题维度的增加,加速比也相应的增加,加速比变化范围从0.5到16.从图4中很直观地看出,Griewank函数和Rastrigin函数加速比的效果比较显著,Rosenbrock函数相对低一些,说明本文的并行算法是有效的.同时,从图4上可以看出,当问题的维度大于90时,加速比仍有增长的趋势.

图4 维度与加速比关系图
(2) 种群规模的扩大.实验中,假定问题的维度一定时(测试的时候选择问题维度为60),种群规模从600变化到6000,串行算法(CPU计算)比并行算法(CPU-GPU异构计算)需要更多的时间.如图5所示,f1、f2、f3分别代表Griewank函数、Rastrigin函数和Rosenbrock函数.当问题规模增大时,由于算法中计算适应度值等操作花费大量的时间,串行算法Griewank函数和Rastrigin函数的运行时间显著上升,在种群规模为6000时运行时间达到70~90 s之间;而并行算法3个函数的运行时间增长很缓慢,几乎只在10 s左右变化.这说明并行算法在种群规模增加的情况下,运行时间不会受到很到影响,同时也说明并行算法有很好的执行效率.
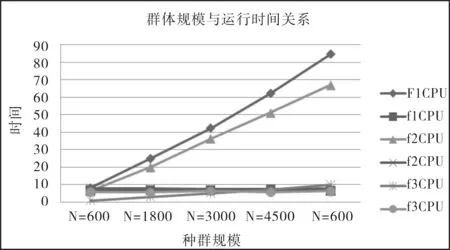
图5 种群规模与运行时间关系图
(3)算法的收敛情况.在精度相同的情形下,并行算法的收敛速度比串行算法快.本实验以Griewank函数、Rastrigin函数和Rosenbrock函数为例,设定维度为60、种群规模为6000情况下,如图6所示,三个函数的并行算法基本在200次迭代就能到达比较好的效果,而串行算法要用至少500次迭代才能到达比较好的效果.事实上,并行算法比串行算法原本运行时间就短,加之收敛速度快,非常有助于提高算法的执行效率,减少算法的迭代次数和运行时间.
但3个函数并行算法过程中,有时会出现陷入波动情况,尤其在图6(b)最为显著,并行算法在迭代次数为500次左右,出现了波动,有可能是在算法侦察蜂过程中达到limit限制,放弃原来蜜源,随机初始化新蜜源产生的情况,对于并行算法有待进一步研究和实验.
总体来说,并行算法的收敛性能方面好于串行算法,运行时间有大幅缩减.

图6 函数性能比较
4.4 本文算法实验结果与文献[4]实验结果的对比分析
本文实验环境采用GPU为NVIDIA Tesla C1060处理器,文献[4]中采用GPU为ATI Mobility Radeon HD 5470处理器,由于GPU架构等方面的不同,实验数据没有完全在相同的实验环境下进行比较,此处只给出在加速性能结果方面的比较,如图7所示.图中f1、f2、f3分别代表本文中Griewank函数、Rastrigin函数和Rosenbrock函数,f1[4]、f2[4]、f3[4]表示文献[4]中的实验结果.从图中可以看出,本文中Griewank函数、Rastrigin函数的实验效果明显好于文献[4],本文Rosenbrock函数的实验效果略低于文献[4]的结果,但随着维度的增加,Rosenbrock函数会有所增长,而文献[4]中3个函数的变化趋于平缓.总体讲,本文提出的改进算法与文献[4]相比有较大提升.

图7 加速比较
5 结语
本文在作者已发表的文献[4]的基础上,对于并行人工蜂群算法进行了改进,提出了一种基于GPU改进的并行人工蜂群算法.该算法提高了算法的执行效率,得到了很好的加速比,并且解决了之前并行版本收敛速度变慢的问题.
对于本文并行人工蜂群算法的进一步研究,可以从以下几方面考虑:(1)虽然提高了算法的收敛速度,但收敛过程中,产生的波动情况有待进一步的深入的研究和实验;(2)进一步优化算法,提高算法的执行效率;(3)本文图7中阐述的Rosenbrock函数的实验效果略低于文献[4]结果的问题将在后续的研究中加以完善.
[1] Karaboga D,Basturk B.A powerful and efficient algorithm for numerical function optimization: artificial bee colony (ABC) algorithm[J]. Journal of Global Optimization,2007,39(3): 459-471.
[2] Karaboga D,Akay B. A survey: algorithms simulating bee swarm intelligence[J]. Artificial Intelligence Review,2009(31): 61-85.
[3] Karaboga D,Akay B. A comparative study of artificial bee colony algorithm[J]. Applied Mathematics and Computation,2009,214(1):108-132.
[4] 王文亮,王智广,刘伟峰. 基于GPU加速的细粒度并行人工蜂群算法[J]. 微电子学与计算机,2013,30(3):110-114.
[5] Matsumoto M,Nishimura T.Dynamic creation of pseudo-random number generators[J]. Monte Carlo and Quasi-Monte Carlo Methods,1998(1):56-69.
[6] 吴恩华,柳有权. 基于图形处理器(GPU)的通用计算[J]. 计算机辅助设计与图形学学报,2004,16(5): 601-612.
[7] Karaboga D,Basturk B. On the performance of artificial bee colony (ABC) algorithm[J]. Applied Soft Computing,2008,8(1): 687-697.
猜你喜欢
计算机仿真(2022年8期)2022-09-28
林业与生态(2022年5期)2022-05-23
小哥白尼(军事科学)(2020年4期)2020-07-25
河北省科学院学报(2020年1期)2020-05-25
高中生·天天向上(2018年1期)2018-04-14
郑州大学学报(工学版)(2018年2期)2018-04-13
学苑创造·B版(2015年12期)2016-06-23
现代计算机(2016年17期)2016-02-28
舰船电子工程(2010年1期)2010-04-26
