
大模型视角下的中高职困难生大数据识别技术应用及实证分析
2024-12-14 00:00:00黄海宁罗伟泰林振程
广西糖业 2024年6期





摘要:我国教育领域对困难生的认定工作给予了极大的关注和重视,特别是在中等和高等职业教育中,已将困难生的认定及相应的资助措施,作为实现教育公平和正义的关键环节之一。文章以广西地区的中等和高等职业院校(以下简称中高职)学生为研究对象,通过查阅文献、设计并发放调查问卷,结合项目实施,运用大数据分析和人工智能(AI)技术,尤其是深度神经网络技术,深入探讨数据挖掘技术在困难生识别方面的应用潜力;构建基于深度神经网络的困难生识别(TabNet-Stacking)模型,并通过实证分析验证该模型在查准率、召回率和F1值3个关键指标上的表现。结果表明,TabNet-Stacking模型能准确无误地识别出困难生,为实现精准识别和资助提供了创新方法;提出在中等和高等职业教育中实施困难生大数据识别技术应用与发展的策略,包括加强数据整合工作、优化算法模型、完善资助体系、加强监管评估及推动技术创新,旨在确保困难生资助工作的精准性和有效性,进而促进教育公平,让每个学生均有平等接受教育的机会。
关键词:中高职;困难生;数据识别;深度神经网络;教育公平
中图分类号:TP391.4" " " " " " " " " " 文献标志码:A 文章编号:2095-820X(2024)06-0493-08
0 引言
困难生指的是生活必需资源不足导致个人生活水平未达到社会平均发展水平、生存状态被排除在正常生活方式和社会活动之外的学生[1]。困难生认定工作对我国教育事业高质量发展的影响不容忽视,因此一直受到教育界的高度重视,并将教育扶贫作为解决相对困难问题的主要路径。在中等和高等职业教育领域,困难生的经济状况和生活条件引起了社会各界的广泛关注[2-4],其相对困难主要体现在日常生活、学术追求及人际交往等方面相较于其他同学或同龄人面临更多的差异与挑战。查阅大数据识别技术应用与教育公平相关的文献发现,通过大数据技术的应用,可更公平地分配教育资源,促进教育公平。张茜[5]研究认为,在中等和高等职业院校(以下简称中高职)困难生扶贫工作中,传统的困难生认定方法存在依赖于单一、简单的机器学习模型及“隐形困难”和疑似“虚假困难”问题,而从促进教育公平角度出发,建立基于深度学习技术的智能化困难生认定模型,可智能化识别真正需经济援助的中高职困难生,从而提升资助工作的效率和针对性,促进教育公平。李秋芸[6]开展广西高职院校贫困生感恩教育研究发现,随着人工智能(AI)技术的不断进步及数据挖掘技术的应用,我国高校在困难生资助工作的精准化研究方面取得了新进展。从大模型视角出发,利用大数据和AI技术可显著提升困难生资助工作的精确度。刘海燕[7]研究表明,在面对中等和高等职业教育中困难生识别的挑战时,借助大数据分析和AI技术,通过综合考量学生的家庭经济状况、个人能力和未来发展潜力等多维度信息,可实现对困难生的精确识别和资助。上述研究结果表明,深度学习技术的充分利用及以大数据为支撑构建精准识别模型,对提升高校困难生资助工作精确度具有重要意义,特别在识别学生基本经济状况方面,可为资源相对匮乏的学生群体提供有力支持。但目前在大模型视角下将大数据识别技术应用于困难生认定以解决教育公平问题的研究仍显不足。文章以广西中高职学生为研究对象,通过大量查阅文献、问卷调查及《大数据背景下中高职院校家庭经济困难学生精准资助路径研究》项目实施,探讨数据挖掘技术在困难生识别上应用的可行性,并提出在中等和高等职业教育中实施困难生大数据识别技术应用与发展的策略,以确保困难生资助工作精准、有效,为构建和谐校园、促进教育公平贡献力量。
1 数据来源及分析方法
近年来,智能识别技术已受到社会广泛关注,其应用领域不断拓展,其中,图像识别、语音识别和自然语言处理等技术尤为引人瞩目。作为智能识别技术的关键应用领域之一,自然语言处理随着社交媒体和在线客服平台的广泛使用而得到普及。同时,自然语言处理技术不断取得进步,处理效率和语义理解能力持续提升。
1.1 数据来源
以广西中高职全体在校学生为研究对象,从识别相对困难生的角度,收集影响其家庭年度可支配收入、学生个人年度收入及在校基本生活保障支出等因素的数据,构建一个包含相对困难生数据集的大模型[8],在构建模型过程中,引入深度神经网络(一种包含多个隐藏层的神经网络,亦称为深度前馈网络或多层感知机),以提升模型的表达能力。根据神经网络层的不同功能,可将其划分为信息输入层、信息隐藏层和特征输出层。在特征信息提取过程中,以输出层为起点,通过前向传播算法对输入向量执行一系列线性和激活运算,最终获得输出结果。当输出信息与预期特征不符时,深度神经网络通过损失函数的梯度迭代不断优化自身,以确定与隐藏层、输出层适合的对应偏倚向量b和线性系数矩阵W,确保所有训练样本的输入尽可能地与标签相匹配。通过深度学习网络架构图(图1)可清晰地识别深度神经网络模型主要由输入层、隐藏层和输出层构成,各层次间形成一个完整的全连接网络结构[9]。其中,输入层承载影响中高职困难生识别的关键因素,输出层对应于中高职相对困难生的认定标准,该标准进一步细化为非困难、一般困难、中度困难和特别困难4个等级。深度神经网络之所以能显著提升中高职相对困难生信息特征的提取效率,核心在于其非线性结构。新型激活函数Xwish定义如下:
f(x)=x[arctan(βx)+0.5π]/π
式中,β表示可修正参数,在实数范围内是光滑的,在β=0、Xwish成为线性函数f(x)=x的情况下,Xwish趋近于[0~1]函数值(类似于ReLU函数)。
1.2 分析方法
通过运用大数据分析技术、循环神经网络及其他先进的智能技术,致力于构建一套专门针对高校学生经济困难状况的识别模型。①搜集一系列影响家庭年度可支配收入、学生个人年度收入及在校基本生活保障支出的因素。这些因素包括但不限于家庭经济状况、学生的学习成绩及课外活动参与度等。②运用词频分析法对各因素进行深入分析,筛选出与困难状况关联性较高的关键因素,并将其作为建立困难生认定标准指标体系的基础。③以循环神经网络模型为核心,将识别出的困难生相关指标作为输入层数据,以杨钋等[1]提出的困难生认定标准为输出层数据,通过模型判定学生的经济困难状况。所构建的基于大数据和深度学习技术的高校学生经济困难认定模型,不仅能满足乡村振兴战略对困难生资助的新要求,而且能解决当前高校在困难生认定准确性方面存在的问题,从而为高校提供一个更科学、合理的困难生资助决策支持系统。
在中等和高等职业教育领域,准确识别相对困难生本质上是一个多类别的分类问题,可进一步细化为若干个二分类问题进行详细阐述。因此,可通过运用多个二分类问题的混淆矩阵来具体展示分类结果,并通过整合这些二分类问题的评价指标来全面评估困难生识别模型的效能。由困难生识别的混淆矩阵(表1~表4)可知,TP(真正例)、FP(假正例)、FN(假负例)和TN(真负例)等指标能帮助量化模型在识别困难生时的准确性、召回率(Recall)及F1分数等关键性能指标,从而为模型的优化和调整提供数据支持。
基于困难生识别混淆矩阵,采用查准率(Accuracy)、召回率和F1-Score的宏平均值来对比评价困难生识别模型的性能。
Macro-Recall=1/n[t=1nTP]/(TP+FN)
Macro-Precision=1/n[t=1nTP]/(TP+FN)
Macro-Fl=1/n[t=1n(2]↔Preciosion↔Recall)/(Precision+Recall)
式中,Macro表示宏量概念(通常指一个较大的、宏观的量度或一个整体的度量标准),Precision表示精确度(描述测量或计算结果的精确程度,即结果与真实值的接近程度),n表示样本数量、次数或其他计数相关的数值,i表示索引(用于区分不同元素或迭代过程的步骤),F1表示特定函数或特定参数。
2 中高职困难生相对困难的识别及大数据识别技术应用的实证分析
2.1 困难生相对困难的智能识别
2.1.1 数据采集与预处理
在AI应用领域,数据采集与预处理环节扮演着至关重要的角色。通过运用各种先进技术手段,如各类传感器和网络爬虫,能采集原始数据。但原始数据通常不能直接用于机器学习算法,必须经过一系列细致的预处理步骤,确保数据能适应特定的格式要求,才能满足机器学习算法的需求。预处理工作通常涵盖数据清洗、特征提取及数据变换等关键步骤。在数据清洗过程中,专注于排除那些可能影响数据质量的异常值、缺失值和重复值,从而显著提升数据的整体质量和可信度。本研究遵循一套严格的困难生认定标准,将家庭年度可支配收入、学生个人年度收入及在校基本生活保障支出作为核心识别指标。为了高效解析、遍历和维护HTML文本,利用Python编程语言中的lxml库,特别是其中的xpath语言,对链接进行分类汇总,并进一步爬取正文内容,最终将这些内容按类别保存至文件中。在解析爬取的HTML文本时,同样使用lxml库中的xpath语言,以便从中提取出所需要的信息。
2.1.2 相对困难生资料关键词提取
本研究通过网络爬虫技术搜集了91000篇文本资料,经过关键词挖掘和词频统计分析,采用词频—逆向文件频率(TF-IDF)算法(一种高效的文本分析技术),从中筛选出53479个词汇。计算公式为:
TFij=nij /[n]j
IDFi=log[D] / [j:tiϵdj]
TF-IDF=TF↔IDF=nij /[n]j↔log[D] / [j:tiϵdj]
式中,TF表示词频(特定词条在文档中出现的次数),IDF表示逆向文档频率(反映词条在语料库中的分布情况),nij表示特定文本dj中某个字词出现的次数,nj表示文本dj中所有字词出现次数的总和,j表示语料库中的文件总数,D表示语料库中的文件总数,[j:tiϵdj]表示在语料库中包含特定词语ti的文本总数。一个词语在语料库中分布越稀疏,则其IDF就越大,说明该词语具有较高的区分度。
TF-IDF算法已广泛应用于文本挖掘、信息检索和搜索引擎优化等领域[10]。TF-IDF算法得出的TF-IDF值既考虑了词条在文本中出现的频率,又考虑了词条在整个语料库中的分布情况,通过计算每个词条的TF-IDF值,可对文本中的词汇进行排序和筛选,从而提取出最具文本内容代表性的关键词汇。随着自然语言处理技术的不断发展,TF-IDF算法也在不断优化和改进。如一些研究者提出基于词向量的TF-IDF变体,通过考虑词汇间的语义关系来进一步提高文本表示的准确性,使TF-IDF算法在处理大规模、复杂文本数据时更得心应手。IDF中包含ti的文本总数越少,则IDF越大,说明词语[ti]在该语料库中具备较好的文本区分能力。TF与IDF作为文本分析中的2个基础而重要的指标,为理解文本内容、挖掘文本价值提供了有力的工具。
2.2 模型构建与训练
模型构建与训练阶段是机器学习流程中不可或缺的核心环节,在机器学习领域扮演着至关重要的角色,要求精心挑选适当的算法及科学确定模型架构,并运用多种策略以全面提升模型效能,确保模型能精确地捕捉输入数据的特征,并在面对测试集时表现出卓越的性能。一旦模型经过严格的训练和全面评估,便能应用于实际情境有效解决各类机器学习问题。
2.2.1 中高职相对困难生识别指标体系的构建
通过利用Python的Gensim库实现TF-IDF算法,构建相对困难因素集合U,因素集U={u1,u2,…,um}。相对困难因素集可划分为2个层次:第一层为三大相对困难影响因素,记为U={u1,u2,u3},其中,u1表示家庭年度可支配收入,u2表示学生个人年度收入,u3表示学生在校基本生活保障支出;第二层为子目标因素集,每个一级指标均由若干个二级指标构成,二级指标是每个一级指标的具体子指标。
TF-IDF算法获取的关键词显示,涉及家庭年度可支配收入因素的主要方面为相对困难家庭父母的职业和就业状况、家庭所在地、上学人口数、劳动人口数及父母学历,分别记为u1={u11,u12,u13,u14,u15,u16};涉及学生个人年度收入因素的主要方面为学生性别、奖助学金、获奖、校内勤工俭学和社会资助,分别记为u2={u21,u22,u23,u24,u25};涉及学生在校基本生活保障支出因素的主要方面为学生在校一卡通消费次数、工作日在校就餐次数、周末节假日在校就餐次数、校内消费单价最高前30个地点的消费次数、在线支付交易次数、图书馆预期缴费次数、学杂费预期缴费次数和助学金贷款金额,分别记为u3={u31,u32,u33,u34,u35,u36,u37,u38,u39}。最终,提取到1584个关键词,剔除对研究相对困难无明显作用的高频干扰词汇后,筛选出900多个与风险相关的词汇。经过进一步筛选,选取词频最高的268个词汇代表中高职学生最关注的困难领域。运用扎根理论对中高职学生面临的困难影响因素进行深入分析,通过开放性编码、主轴编码和选择性编码对这些因素进行系统归纳和阐述。在理论饱和度得到验证后,构建中高职学生相对困难影响指标体系(表5)。
在提取中高职相对困难生识别的影响因素时,大多数指标为类别变量,在计算特征间距时可能会出现不合理的特征间距。因此,需对反映家庭年度可支配收入、学生个人年度收入和在校基本生活保障支出等特征的指标进行适当的编码处理。针对同一指标所描述的不同客户性质,将指标按照A、B、C和D进行编码,最终以特征向量形式综合反映中高职相对困难生影响因素特征指标。如家庭父母的职业可细分为农民务农、农民兼营小生意、城镇农民工、个体工商户、离退休人员、下岗待业人员、下岗再就业人员、无业人员及其他职业,对此9种职业进行编码后转化为特征向量,以确保数据处理的科学性和准确性。
2.2.2 中高职相对困难生的认定
经过细致的比较分析,将学生家庭经济状况与教育成本间的差异或比例作为关键参考指标,从多个角度、全面地精准识别经济条件相对困难的学生群体,充分考虑了困难生群体的实际情况及教育公平的深层含义。在评估经济困难生准确性的支出法、收入法及综合收入与支出双指标比值法中,综合收入与支出双指标比值法具有明显优势,其构建的经济生活困难指数能综合考量家庭年度可支配收入与学生个人年度收入及在校基本生活保障支出间的比例关系,为精准识别和帮助经济困难生提供科学依据。进一步通过聚类分析法,将构建的相对困难生指数进行无监督学习,从而划分出非困难、一般困难、中度困难和特别困难4种困难生类别[相对贫困生认定=(家庭年度可支配金额+学生个人年度收入)/学生基本生活保障支出]作为模型的输出层,最终完成基于深度神经网络的困难生识别(TabNet-Stacking)模型构建。
2.3 大数据识别技术应用的实证分析
本研究选取朴素贝叶斯模型、支持向量机(SVM)分类模型和随机森林模型作为基准,对TabNet-Stacking模型进行效能评估。通过应用困难生识别分类模型,并利用广西中高职学生数据构建的学生数据集,将相关特征项的值输入深度神经网络分类模型,以完成分类任务。最终,根据模型输出结果判定困难生的类别,从而为困难生认定工作提供技术支持。
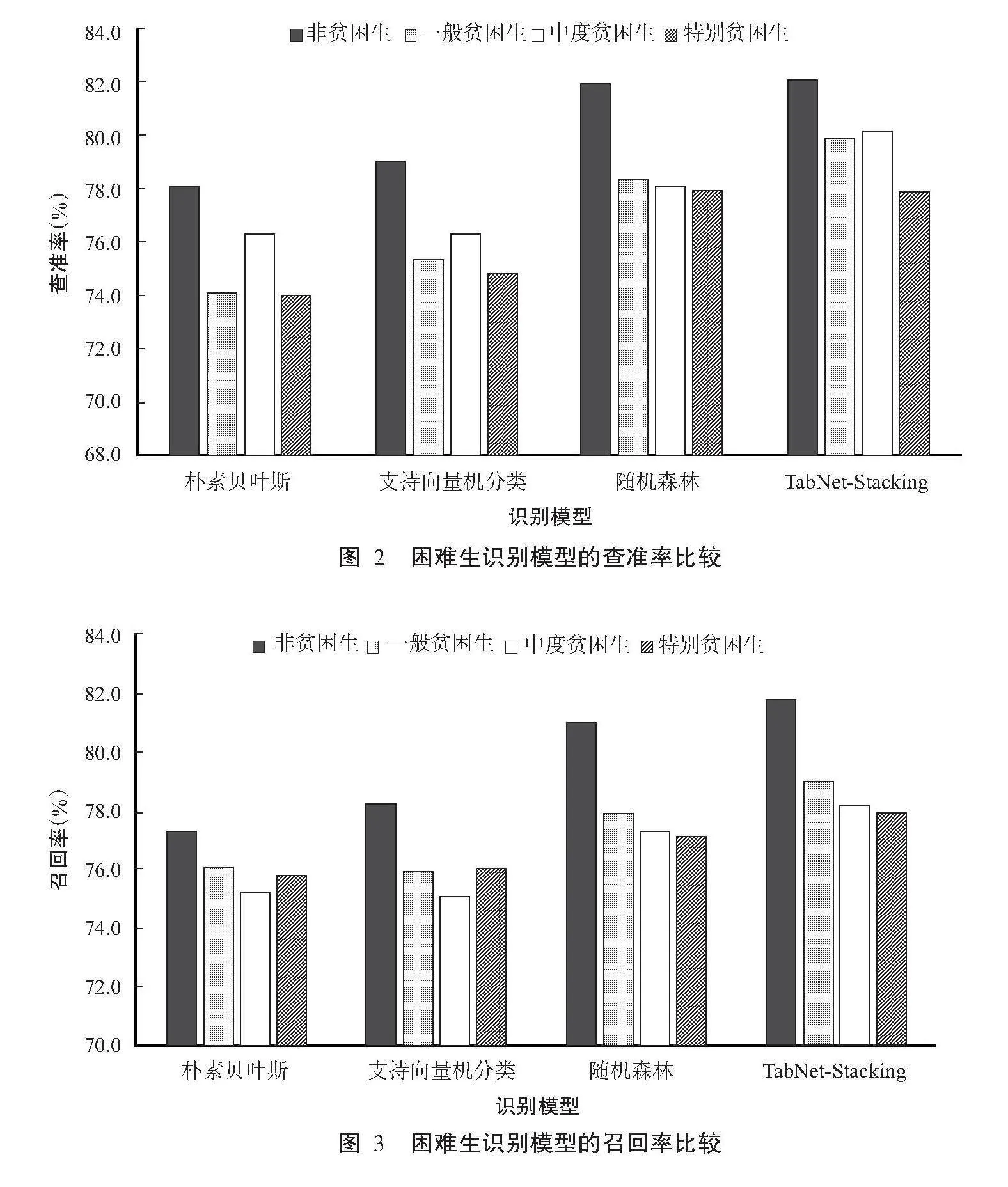
从图2可看出,各困难生识别模型对困难生识别的查准率均表现出色,其中,TabNet-Stacking模型表现更优秀,对困难生的查准率达82.0%,对一般困难生的查准率为79.8%,对中度困难生的查准率为80.0%,对特别困难生的查准率为77.7%,均明显高于朴素贝叶斯模型、支持向量机分类模型和随机森林模型相应的困难生查准率。
从图3可看出,TabNet-Stacking模型对非贫困生、一般贫困生、中度贫困生和特别贫困生识别的召回率分别为80.7%、78.1%、77.6%和77.4%,说明该模型识别出各类别困难生的数量明显多于朴素贝叶斯模型、支持向量机分类模型和随机森林模型,即在查全性能上优于朴素贝叶斯模型、支持向量机分类模型和随机森林模型。经计算,TabNet-Stacking模型对非贫困生、一般贫困生、中度贫困生和特别贫困生识别准确的F1值均达82.00%,明显高于朴素贝叶斯模型、支持向量机分类模型和随机森林模型识别准确的F1值。此外,在本研究构建的2层TabNet-Stacking模型中,TabNet-XGBoost模型所挑选的TOP15特征在模型分类过程中表现优于随机森林模型,进一步证实TabNet-XGBoost模型在特征抽取方面的卓越能力,同时,也凸显F1值作为衡量模型查准率与召回率综合性能的核心指标的重要性。
3 应用与发展中高职困难生大数据识别技术的策略
本研究引入深度神经网络技术[11],通过运用网络爬虫技术和文本分析方法,从多个视角对分析流程进行梳理,并从多维度挖掘特征指标体系构建的TabNet-XGBoost模型,实现了数据挖掘技术在中高职困难生判定上的有效应用。通过构建的TabNet-XGBoost模型,能更准确地识别真正需要帮助的学生,提高资助资源的使用效率。本研究还开发了一套涵盖学生经济状况、学习表现、心理状态及家庭背景等方面的综合评估体系,通过多维度的评估,可更全面地了解学生的实际情况,从而提供更个性化的困难生支持方案。在实际应用中发现,尽管大数据和AI技术在困难生识别方面具有巨大潜力[12],但也面临数据隐私保护、算法透明度及模型泛化能力等方面的挑战。因此,建议在实际应用中应加强数据安全和隐私保护措施[13-14],以确保学生信息安全;加强对算法的解释,以便相关利益方能更好地理解和信任模型的决策过程。在乡村振兴和教育公平的大背景下,将TabNet-XGBoost模型应用于帮助地理位置偏远农村地区学生获得优质教育资源,可提高教育的公平性,促进乡村振兴战略实施,为农村地区的发展提供人才支持和智力保障。
在大模型视角下,针对中高职困难生的大数据识别技术应用与发展,提出有利于开展乡村振兴与教育公平研究的策略。①整合数字资源,构建一个完整的困难生资助数据平台,在此基础上建立一个全面整合困难生横向和纵向数据的统一数据库,并通过不同部门联网来确认学生数据的真实性和有效性。②注重数据的及时更新,保障数据的时效性;因不同级别用户对数据的访问权限不同,需对数据的备份和共享进行分级管理[15],以防数据泄露和滥用,确保困难生的隐私安全。③未来针对中高职困难生的研究可关注如何通过大数据分析,挖掘困难生贫困背后的原因和特点,以便制定更有效的教育政策和帮扶措施。④在实施上述策略时,需考虑伦理和法律问题,如确保数据收集和处理过程的合法性,以及如何在不侵犯学生隐私的前提下合理利用数据资源;同时,在技术应用过程中需对教师和学生进行适当的培训,以提高其对新技术的接受度和使用能力。通过实施上述策略,有望更好地识别和帮助中高职困难生,为困难生提供更多发展机会,使其能更好地融入社会,实现自身价值[16],有助于构建一个更公正和包容的教育环境,推动乡村振兴与教育公平实现。
4 结语
在中高职学生群体中,许多学生出身于经济条件较困难的家庭,其生活环境和经济状况通常不尽如人意,因此,迫切需得到社会各界的关注和援助。本研究通过运用大数据分析和AI技术,对传统的困难生识别方法进行优化与创新,构建了一个TabNet-XGBoost模型,能在简化资助流程的同时,有效避免“虚假困难”现象的发生,确保困难生获得更精准的资助,为中高职困难生的精准识别和资助提供新的视角和方法,为实现教育公平和乡村振兴战略实施提供重要技术支撑。未来需探讨构建针对中高职困难生的大数据识别技术应用与发展的动态实时监测识别系统,以进一步利用海量数据进行深入分析和预测,发展形成一个按需、实时、动态的精准资助新模式,从而提高困难生的资助效率和效果,确保资源的合理分配和使用。此外,还应探究将AI技术与教育大数据相结合的可能性,为高校提供更科学合理的资助决策支持,从而更好地服务于困难生群体。
参考文献:
[1] 杨钋,金红昊,刘海骅. 相对困难视域下“双一流”建设高校贫困生识别策略研究[J]. 中国高教研究,2022(3):45-51.
[2] 陈丽君,林伟婷. 高职院校扩招视角下家庭与人力资本对中高职贫困生就业质量的影响研究[J]. 高等职业教育探索,2020,19(5):38-44.
[3] 毕鹤霞. 国内外高校贫困生认定与研究述评[J]. 比较教育研究,2009,31(1):62-66.
[4] 黄海宁,罗伟泰,林振程. 乡村振兴战略背景下中高职院校困难生智能识别与精准帮扶策略分析[J]. 广西糖业,2024,44(5):391-396.
[5] 张茜. 多维贫困视角下中国农村困难家庭的识别研究[D]. 北京:首都经济贸易大学,2018.
[6] 李秋芸. 广西高职院校贫困生感恩教育研究[D]. 南宁:广西师范学院,2014.
[7] 刘海燕. 心理资本视角下高职贫困生心理扶贫路径研究[J]. 文存阅刊,2021(21):179-180.
[8] 王丽. 高职院校贫困学生挫折教育探析[D]. 济南:山东师范大学,2010.
[9] 刘艳,李纯斌. 对高职学院贫困生伦理关怀的实证研究[J]. 企业家天地(下半月刊),2014(3):116-117.
[10] 蒋承,张智鑫,李笑秋. 贫困生认定与本科生发展差异研究——基于首都高校的问卷调查[J]. 复旦教育论坛,2016,14(6):61-66.
[11] 林彬彬. 试论我国高校贫困生认定工作中存在的问题及对策[J]. 佳木斯教育学院学报,2011(8):64-65.
[12] 吴斌珍,李宏彬,孟岭生,等. 大学生贫困及奖助学金的政策效果[J]. 金融研究,2011(12):47-61.
[13] 杨钋,刘霄. 研究生收费前贫困资助政策的瞄准和减贫效果分析——以首都高校研究生为例[J]. 教育与经济,2019(2):78-87.
[14] 戴海辉. 基于Hadoop的校园卡数据挖掘的研究与实现[D]. 南昌:南昌航空大学,2017.
[15] 蒲飞,赵正辉,涂旭东,等. 基于校园一卡通数据的贫困学生消费异常数据检测分析[J]. 电子测试,2018(6):58-60.
[16] 王卫星,李斌. 智慧校园下利用机器学习算法实现高校贫困生的预测[J]. 三门峡职业技术学院学报,2019,18(1):133-140.
(责任编辑 思利华)
黄海宁,罗伟泰,林振程. 大模型视角下的中高职困难生大数据识别技术应用及实证分析[J]. 广西糖业,2024,44(6):493-500.
DOI:10.3969/j.issn.2095-820X.2024.06.015
收稿日期:2024-10-09
基金项目:广西教育科学“十四五”规划学生资助专项《大数据背景下中高职院校家庭经济困难学生精准资助路径研究》(2022ZJY2615)
通讯作者:罗伟泰(1983-),男,博士研究生,高级工程师,主要从事信息技术研究工作,E-mail:548580230@qq.com
第一作者:黄海宁(1972-),男,高级讲师,主要从事职业教育与思想政治教育研究工作,E-mail:115259816@qq.com
猜你喜欢
科教导刊·电子版(2017年13期)2017-07-24 08:26:51
电子技术与软件工程(2017年4期)2017-03-27 21:51:30
考试周刊(2016年84期)2016-11-11 23:23:26
知音励志·社科版(2016年9期)2016-11-09 05:25:39
知音励志·社科版(2016年8期)2016-11-05 02:23:22
人间(2016年26期)2016-11-03 17:18:07
电脑知识与技术(2016年22期)2016-10-31 20:23:56
成才之路(2016年25期)2016-10-08 10:24:37
成才之路(2016年25期)2016-10-08 10:20:01
中国科技博览(2016年8期)2016-04-25 06:51:25
