
深度神经网络的发展现状
2017-03-27 21:51胡聪丛
电子技术与软件工程 2017年4期
胡聪丛

摘 要 深度神经网络已经在语音、图像、文本等信息处理领域取得了巨大的成果,本文简述其起源及成果,并介绍现代深度神经网络模型的三种基本结构:序列到序列神经网络、卷积神经网络、对抗式生成网络,最后展望了深度神经网络研究领域所面临的挑战。
【关键词】深度神经网络 序列到序列网络 卷积网络 对抗式生成网路
1 深度神经网络起源
人工神经网络(ArtificialNeuralNetworks,ANN)研究是人工智能领域的一个重要分支,在对生物神经网络结构及其机制研究的基础上,构建类似的人工神经网络,使得机器能直接从大量训练数据中学习规律。其研究最早可以追溯到1957年Frank Rosenblatt提出的感知机模型,他在《The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain》建立了第一个人工神经网络数学模型,19世纪80年代末期反向传播(Back Propagation)算法的发明更是带来了ANN的学习热潮,但由于理论分析难度较大,训练方法及技巧尚不成熟,计算机运算能力还不够强大,这个时期ANN结构较为简单,大部分都可等价为单隐层神经网络,主要是进行浅层学习(Shallow Learning)研究。
2006年Geoffrey Hinton在《A Fast Learning Algorithm for Deep Belief Nets》中提出了逐层贪婪预训练(layerwise greedy pretraining),显著提高了MNIST手写数字识别的准确率,开创了深度学习的新方向;随后又在《Reducing the Dimensionality of Data with Neural Networks》中提出了deep autoencoder结构,在图像和文本降维实验上明显优于传统算法,证明了深度学习的正确性。以这两篇论文为开端,整个学术界掀起了对深度学习的研究热潮,由于更多的网络层数和参数个数,能够提取更多的数据特征,获取更好的学习效果,ANN模型的层数和规模相比之前都有了很大的提升,被称之为深度神经网络(Deep Neural Networks,DNN)。
2 深度神经网络的现代应用
2010年以来,随着理论不断创新和运算能力的增长,DNN被应用到许多领域并取得了巨大的成功。2011年微软和谷歌的研究员利用DNN将语音识别的错误率降低了20%~30%;2012年在ImageNet图像识别挑战赛(ILSVRC2012)中DNN更是将识别错误率从26%降到了15%;2016年3月DeepMind团队研发的围棋软件AlphaGO以4:1的巨大优势战胜了世界围棋冠军李世石,2017年1月初AlphaGO的升级版Master以60:0的战绩击败了数十位中日韩围棋高手。当前对DNN的研究主要集中在以下领域:
2.1 语音识别领域
微软研究院语音识别专家邓立和俞栋从2009年开始和深度学习专家Geoffery Hinton合作,并于2011年宣布推出基于DNN的识别系统,彻底改变了语音识别的原有技术框架;2012年11月,百度上线了第一款基于DNN的语音搜索系统,成为最早采用DNN技术进行商业语音服务的公司之一;2016年微软使用循环神经网络语言模型(Recurrent Neural Network based Language Modeling,RNN-LM)将switchboard的词识别错误率降低到了6.3%。
2.2 图像识别领域
早在1989年,YannLeCun和他的同事们就提出了卷积神经网络(Convolution Neural Networks,CNN)结构。在之后的很长一段时间里,CNN虽然在诸如手写数字问题上取得过世界最好的成功率,但一直没有被广泛应用。直到2012年10月,Geoffrey Hinton在ILSVRC2012中使用更深的CNN将错误率从26%降到15%,业界才重新认识到CNN在图像识别领域上的巨大潜力;2012年谷歌宣布基于CNN使得电脑直接从一千万张图片中自发学会猫脸识别;2013年DNN被成功应用于一般图片的识别和理解;2016年DeepMind团队基于CNN研发了围棋AI,并取得了巨大成功。
2.3 自然语言处理领域
2003年YoshuaBengio等人提出单词嵌入(word embedding)方法将单词映射到一个矢量空间,然后用ANN来表示N-Gram模型;2014年10月NEC美国研究院将DNN用于自然语言处理(Natural language processing,NLP)的研究工作,其研究员Ronan Collobert和Jason Weston从2008年开始采用单词嵌入技术和多层一维卷积的结构,用于POS Tagging、Chunking、Named Entity Recognition、Semantic Role Labeling等四個典型NLP问题;2014年IlyaSutskever提出了基于LSTM的序列到序列(sequence to sequence,seq2seq)网络模型,突破了传统网络的定长输入向量问题,开创了语言翻译领域的新方向;2016年谷歌宣布推出基于DNN的翻译系统GNMT(Google Neural Machine Translation),大幅提高了翻译的精确度与流畅度。
3 深度神经网络常见结构
DNN能够在各领域取得巨大成功,与其模型结构是密不可分的,现代DNN大都可归纳为三种基本结构:序列到序列网络、卷积网络、对抗式生成网络,或由这三种基本网络结构相互组合而成。
3.1 序列到序列网络
序列到序列网络的最显著特征在于,它的输入张量和输出张量长度都是动态的,可视为一串不定长序列,相比传统结构极大地扩展了模型的适应范围,能够对序列转换问题直接建模,并以端到端的方式训练模型。典型应用领域有:自动翻译机(将一种语言的单词序列转换为另一种语言的单词序列),语音识别(将声波采样序列转换为文本单词序列),自动编程机研究(将自然语言序列转换为语法树结构),此类问题的特点在于:
(1)输入和输出数据都是序列(如连续值语音信号/特征、离散值的字符);
(2)输入和输出序列长度都不固定;
(3)输入输出序列长度没有对应关系。
其典型如图1所示。
网络由编码器(encoder)网络和解码器网络(decoder)两部分连接构成:
3.1.1 编码器网络
编码器网络通常是一个递归神经网络(Recurrent Neural Networks,RNN),网络节点一般使用长短期记忆模型(Long Short Term Memory,LSTM)实现,序列中里第t个张量xt的输出yt依赖于之前的输出序列(y0、y1…yt-1),输入序列(x0、x1、x2…)從前至后依次输入网络,整个序列处理完后得到最终的输出Y以及各层的隐藏状态H。
3.1.2 解码器网络
解码器网络是一个与编码器网络结构相同的RNN网络,以解码器的最终输出(Y,H)为初始输入,使用固定的开始标记S及目标序列G当作输入数据进行学习,目标是使得在X输入下Y和G尽量接近,即损失度函数f(X)取得最小值。
解码器网络属于典型的监督学习结构,可以用BP算法进行训练,而编码器网络的输出传递给了解码器网络,因此也能同时进行训练。网络模型学习完毕后,将序列X输入编码器,并将起始标记S输入解码器,网络就会给出正确的对应序列。
3.2 卷积神经网络
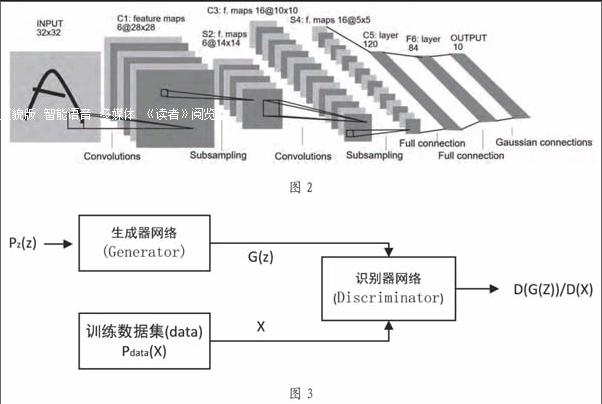
卷积神经网络将传统图像处理的卷积运算和DNN相结合,属于前馈神经网络,是在生物视觉皮层的研究基础上发展而来的,在大型图像处理上有出色表现。CNN一般由多个结构相似的单元组成,每个单元包含卷积层(convolution layer)和池化层(poolinglayer),通常网络末端还连接全联通层(fully-connected layer,FC)及Softmax分类器。这种结构使得CNN非常适合处理二维结构数据,相比其它DNN在图像处理领域上具有天然优势,CNN的另一优势还在于,由于卷积层共享参数的特点,使得它所需的参数数量大为减少,提高了训练速度。其典型结构如图2所示:
3.2.1 卷积层(Convolutional layer)
卷积层由若干卷积核构成,每个卷积核在整个图像的所有通道上同时做卷积运算,卷积核的参数通过BP算法从训练数据中自动获取。卷积核是对生物视觉神经元的建模,在图像局部区域进行的卷积运算实质上是提取了输入数据的特征,越深层的卷积层所能提取到的特征也越复杂。例如前几个卷积层可能提取到一些边缘、梯度、线条、角度等低级特征,后续的卷积层则能认识圆、三角形、长方形等稍微复杂的几何概念,末尾的卷积层则能识别到轮子、旗帜、足球等现实物体。
3.2.2 池化层(Poolinglayer)
池化层是卷积网络的另一重要部分,用于缩减卷积层提取的特征图的尺寸,它实质上是某种形式的下采样:将图像划分为若干矩形区块,在每个区块上运算池化函数得到输出。有许多不同形式的池化函数,常用的有“最大池化”(maxpooling,取区块中数据的最大值)和“平均池化”(averagepooling,取区块中数据的平均值)。池化层带来的好处在于:
(1)减小了数据尺寸,降低参数的数量和计算量;
(2)模糊了各“像素”相对位置关系,泛化了网络识别模式。
但由于池化层过快减少了数据的大小,导致,目前文献中的趋势是在池化运算时使用较小的区块,甚至不再使用池化层。
3.3 生成式对抗网络(Generative Adversarial Network,GAN)
生成式对抗网络最初由Goodfellow等人在NIPS2014年提出,是当前深度学习研究的重要课题之一。它的目的是收集大量真实世界中的数据(例如图像、声音、文本等),从中学习数据的分布模式,然后产生尽可能逼真的内容。GAN在图像去噪,修复,超分辨率,结构化预测,强化学习中等任务中非常有效;另一重要应用则是能够在训练集数据过少的情况下,生成模拟数据来协助神经网络完成训练。
3.3.1 模型结构
GAN网络典型结构如图3所示,一般由两部分组成,即生成器网络(Generator)和识别器网络(Discriminator):
(1)生成器网络的目标是模拟真实数据的分布模式,使用随机噪声生成尽量逼真的数据。
(2)识别器的目标是学习真实数据的有效特征,从而判别生成数据和真实数据的差异度。
3.3.2 训练方法
GAN采用无监督学习进行训练,输入向量z一般由先验概率概率pz(z)生成,通过生成器网络产生数据G(z)。来自训练集的真实数据的分布为pdata (x),GAN网络的实质是学习该特征分布,因此生成的数据G(z)必然也存在对应的分布pg (z),而识别器网络则给出数据来自于真实数据的概率D(x)以及D(G(z) )。整个训练过程的实质就是生成器网络和识别器网络的博弈过程,即找到
4 深度神经网络研究展望
DNN虽然在各大领域都取得了重大的成功,甚至宣告了“智能时代”的来临,但是与人类大脑相比,DNN在许多方面仍有显著差距:
4.1 识别对抗样本的挑战
对抗样本是指在数据集中添加微小的扰动所形成的数据,这些数据能使网络以极高的置信度做出错误的判别。在网络实际使用过程中会带来非常大的问题,比如病毒制造者可能刻意构造样本来绕过基于DNN的安全检查网络。部分研究指出问题的根因可能在于DNN本身的高度非线性,微小的扰动可能在输出时产生巨大的差异。
4.2 构造统一模型的挑战
DNN虽然在很多领域都取得了巨大的成功,但无论是序列到序列网络、卷积网络、还是对抗式生成网络都只适应于特定领域,与此相对的则是,人类只用一个大脑就能完成语音、文本、图像等各类任务,如何构建类似的统一模型,对整个领域都是极大的挑战。
4.3 提高训练效率的挑战
DNN的成功依赖于大量训练数据,据统计要使得网络学会某一特征,平均需要50000例以上的样本,相比而言人类只需要少量的指导即可学会复杂问题,这说明我们的模型和训练方法都还有极大的提高空间。
参考文献
[1]ROSENBLATT F.The perceptron:a probabilistic model for information storage and organization in the brain [M].MIT Press,1988.
[2]HINTON G E,OSINDERO S,TEH Y W.A fast learning algorithm for deep belief nets [J].Neural Computation,1989, 18(07):1527-54.
[3]HINTON G E,SALAKHUTDINOV R R. Reducing the Dimensionality of Data with Neural Networks[J].Science, 2006,313(5786):504.
[4]SEIDE F,LI G,YU D.Conversational Speech Transcription Using Context-Dependent Deep Neural Networks; proceedings of the INTERSPEECH 2011, Conference of the International Speech Communication Association, Florence,Italy,August,F,2011 [C].
[5]OQUAB M,BOTTOU L,LAPTEV I,et al. Learning and Transferring Mid-level Image Representations Using Convolutional Neural Networks; proceedings of the Computer Vision and Pattern Recognition,F,2014 [C].
[6]SILVER D,HUANG A,MADDISON C J,et al.Mastering the game of Go with deep neural networks and tree search [J].Nature,2016,529(7587):484.
[7]XIONG W,DROPPO J,HUANG X,et al.The Microsoft 2016 Conversational Speech Recognition System[J].2016.
[8]LECUN Y,BOTTOU L,BENGIO Y,et al. Gradient-based learning applied to document recognition [J].Proceedings of the IEEE,1998,86(11):2278-324.
[9]BENGIO Y,DELALLEAU O, LE R N,et al.Learning eigenfunctions links spectral embedding and kernel PCA [J].Neural Computation,2004,16(10):2197-219.
[10]LEGRAND J,COLLOBERT R.Recurrent Greedy Parsing with Neural Networks [J].Lecture Notes in Computer Science,2014,8725(130-44.
[11]SUTSKEVER I,VINYALS O,LE Q V. Sequence to Sequence Learning with Neural Networks [J].Advances in Neural Information Processing Systems,2014,4(3104-12.
[12]WU Y,SCHUSTER M,CHEN Z,et al. Google's Neural Machine Translation System:Bridging the Gap between Human and Machine Translation [J]. 2016.
[13]GOODFELLOW I J,POUGETABADIE J,MIRZA M,et al.Generative Adversarial Networks [J].Advances in Neural Information Processing Systems,2014,3(2672-80.
作者單位
1.装备学院昌平士官学校 北京市 102200
2.辽宁大学生命科学院 辽宁省沈阳市 110031
