
基于LDA模型的文本分类与观点挖掘
2017-03-27 10:54李晨曦
电子技术与软件工程 2017年4期
关键词:机器学习
李晨曦
摘 要 得益于信息技术的飞速发展,信息的传递效率不断提高,网络信息数量也呈现爆炸性增长趋势,这些信息大多文本的方式存在并且各种类别混杂在一起。使用人工方式对于分类并提取其中有用的观点信息效率低下并且浪费大量的人力资源,因此通过自动分析和提取的方式发展观点挖掘的新方法有着一定的研究意义,LDA主题模型作为无监督机器学习模型的典型应用有着快速、高效的特点而被众多学者广泛研究。
【关键词】LDA模型 机器学习 观点信息
1 引言
第38次《中国互联网络发展状况统计报告》显示,截至2016年6月,中国网民规模达7.10亿,互联网普及率达到51.7%。互联网已经成为现代人生活中的必需品,借助互联网的快速发展,信息的传递方式与效率日新月异。观点挖掘是指通过相关技术分析文本中表达的观点与情感极性,帮助用户快速地获取有用信息。当前国内外学者针对观点挖掘进行的相关研究工作聚集在以下两个方面:
(1)文本分类;
(2)观点抽取。
文本分类的主要任务是判定文本描述事物特征所属类别,观点抽取则是提取文本特征下对应的具体观点信息,其中根据情感的褒贬性又可以分为以下三类,正向表示情感倾向为褒义,负向表示情感倾向为贬义,而中性则表示没有明显的褒贬倾向。
当前观点挖掘领域主要有三种研究方法:基于规则、基于语言学和基于机器学习。基于规则与基于语言学的方法存在着依赖语法规则与领域适用度不高等缺陷,基于机器学习的方法由于具有很强的领域适应性和跨语言性,LDA主题模型作为机器学习模型在观点挖掘领域有着重要应用。
标准LDA模型由于采用词袋结构,割裂了词语的位置以及上下文的语义关系,另外LDA主题模型在进行观点挖掘研究时通常选择相同类别的文档形成一个语料库来保证观点挖掘效果,多类别文档混合时则必须选取其他方式进行文本分类。鉴于以上两点,本文对标准LDA模型进行改进提出了Document classification LDA模型(DC-LDA,文本自分类LDA模型),将文本分类模块引入后进行观点挖掘研究。
2 模型描述
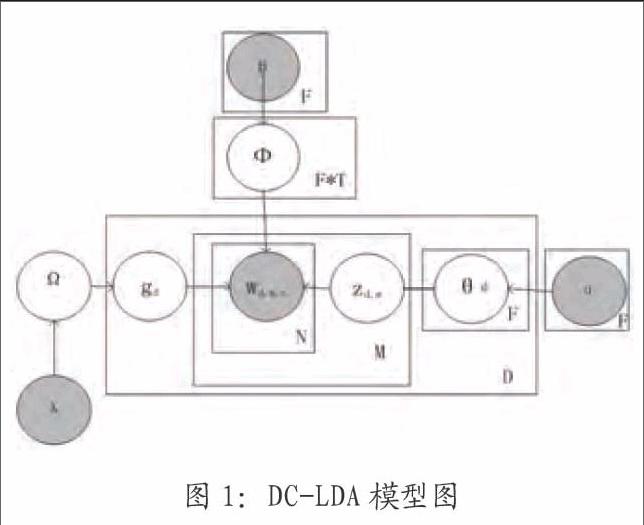
DC-LDA模型图如图1所示。
模型中参数列表如表1所示。
如图1所示,LDA模型是一个三层结构,完成了文档-主题-单词的三层映射,通过狄利克雷分布与多项式分布为每个单词选取一个特定的主题,同样的本文在文档层的基础上添加类别这一概念,将标准LDA模型扩展为四层结构,类别-文档-主题-单词,以此来完成文本分类的过程,在对语料库进行观点挖掘,同时为了克服词袋模型的缺陷,本文以句子为单位来采样主题标签,认为同一句子下的单词隶属于相同主题。
Document classification LDA模型的生成过程描述如下:
(1)对一个语料库:①由先验参数λ得到语料库下领域分布Ω~Dir(λ);②由先验参数β获得每个领域下的单词分布Φf,t~Dir(β)(其中f表示领域,取值1......F,t表示主题,取值1......T);
(2)對语料库中每一篇文档d:①为文档选择对应领域标签,gd~Multinomial(Ω);②得出对应领域下文档的主题分布θfd~Dir(αf);
(3)对每一篇文档d中的第m个句子:选择对应领域下的主题zd,m,其中zd,m~ Multinomial(θfd);
(4)对句子m中每个词n(wd,m,n):选择具体的单词,wd,m,n~Multinomial(Φf,t)。
3 实验
本实验使用来自sougou实验室提供的中文语料库,使用的版本为SougouC .Mini,其包括汽车、财经、IT、健康、体育等10个类别的相关内容,每个类别下包含1990篇文档。
在进行实验之前先将语料库进行去停用词处理,本文采用中国科学院计算技术研究所提供的汉语词法分析系统ICTCLAS,其有着速度快、准确率高的特点因此在中文信息处理领域得到了广泛应用。
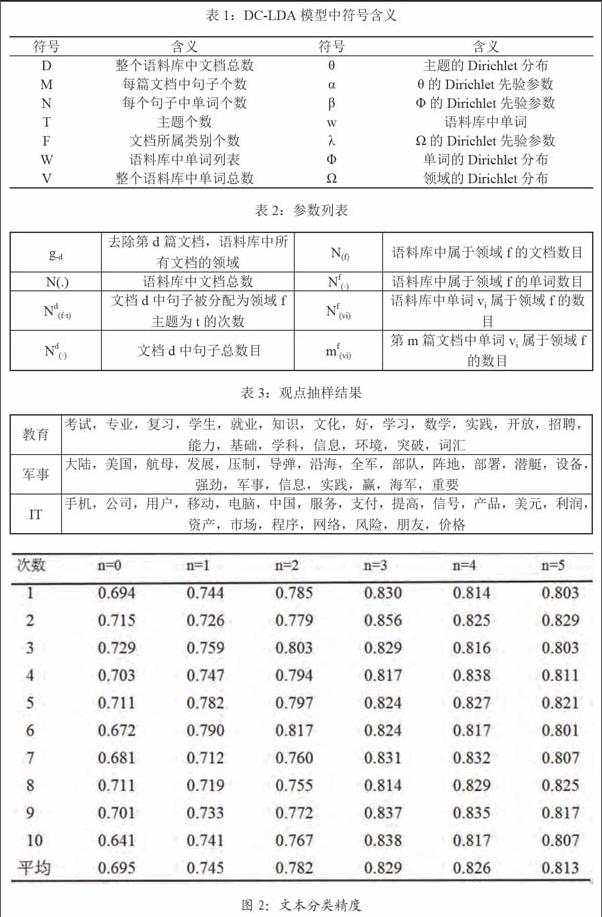
本实验以语料库中的IT、体育、健康、教育、旅游、军事这6个区分明显的类别进行类别采样分析,每个类别中选取800篇文档作为训练语料,再抽取200篇作为测试语料,本文对领域判别精度定义如下:
在DC-LDA模型中为每一篇文档采样领域标签时本文考虑到了高词频的单词对文档所在领域的贡献,在采样公式中取词频最高的前n个单词随着n取值的变化领域区分的精确度也会变化,对每个n的取值进行十次重复试验,结果如图2所示。
语料库观点抽样结果如表3所示。
参考文献
[1]http://www.cnnic.net.cn/
[2]Pang B,Lee L.Opinion mining and sentiment analysis[J].Foundations and trends in information retrieval,2008,2(1-2):1-135.
[3]Inui T.and Okumura M.A survey of sentiment analysis[J].Journal of natural language processing,2006,13(03):201-241.
[4]Li J.Summary of product reviews opinion mining[J].Modern Computer,2013(05):11-16.
[5]孙艳,周学广,付伟.基于主题情感混合模型的无监督文本情感分析[J].北京大学学报:自然科学版,2013,49(01):102-108.
[6]http://www.sogou.com/labs/
作者单位
1.湖北省孝感高中 湖北省孝感市 432100
2.湖北省襄阳四中 湖北省襄阳市 441000
猜你喜欢
科教导刊(2016年26期)2016-11-15
活力(2016年8期)2016-11-12
科学与财富(2016年28期)2016-10-14
