
基于异构图分层学习的细粒度多文档摘要抽取
2024-03-21 08:15翁裕源许柏炎蔡瑞初
计算机工程 2024年3期
翁裕源,许柏炎,蔡瑞初
(广东工业大学计算机学院,广东 广州 510006)
0 引言
近年来,用户对从海量文本数据中挖掘重要信息的需求增大,使得文档摘要技术备受工业界和学术界的关注。文档摘要提取的目标是对给定文档进行重要信息提取,根据输入的不同,文档摘要提取可分为单文档摘要提取、长文档摘要提取和多文档摘要提取。多文档摘要提取需要在多个文档中对共同主题的信息进行提取,对比单文档、长文档摘要提取,其在完整性、可读性和简洁性方面有更高的要求。根据摘要提取建模方式的不同,文档摘要提取可分为生成式摘要提取和抽取式摘要提取。生成式摘要提取是对输入文档整体理解后逐字生成摘要,抽取式摘要提取则直接从文档中选择关键信息组成摘要。相比于生成式摘要提取,抽取式摘要提取选择原文关键语句,具备更高的完整性和可读性,其目标是在减少摘要冗余度的同时提高简洁性[1-3]。本文主要研究如何解决抽取式多文档摘要中的关键冗余问题。
主流抽取式多文档摘要研究大多在句子级别进行建模。文献[4]通过句子间余弦相似度构建句子相似图,以计算句子的重要性,选择句子组成摘要。文献[5]关注句子间的语篇关系和基于TF-IDF(The Term Frequency-Inverse Document Frequency)的相关性,通过构建3 种句子关系图并用图卷积网络学习句子表示以识别重要句子。文献[6]借助共有单词构建句子间关系,最终筛选出重要句子组成摘要。上述工作通过建模句子间的关系来有效选择重要句子,在多文档摘要提取中取得了较好的效果,然而这些工作的建模方式导致了简洁性上的性能瓶颈。句子层级建模方式组成的摘要不仅包含关键信息,还包含多余的信息。
近年来,为了突破基于句子层级建模的性能瓶颈,有单文档摘要抽取相关学者尝试研究细粒度的子句层级建模方式,以完成文档摘要抽取任务。子句是基于修辞结构理论[7]对文档进行分割而得到的,将文档中的句子分割为相邻的不重叠的基本语篇单元。文献[8]通过在单文档摘要数据集上的实验分析,证明采用子句层级建模的性能上限更高。文献[9]首次以子句为抽取单元构建端到端的单文档摘要模型,引入子句间的语篇关系和共指关系构建子句关系图,进一步通过图卷积网络[10]进行学习。由于多文档摘要抽取场景和单文档摘要抽取场景存在差异,因此基于细粒度子句层级建模的多文档摘要抽取存在以下未解决的问题:1)多文档摘要抽取从子句级别建模,是否能达到与单文档摘要抽取相同的性能提升;2)多文档摘要抽取需要考虑多个文档的共有重要信息,如何考虑更多层级异构关系学习存在挑战性。
为了验证问题1),本文参考文献[8]的工作,在多文档摘要数据集Multi-news 上对比句子层级Oracle 摘要和子句层级Oracle 摘要与标准摘要的ROUGE 值,其中,Oracle 摘要由文献[11]提出的基于自动评估标准ROUGE[12]进行贪心抽取而得到。统计后得到结论:通过子句层级建模最高可以提升5%的ROUGE-1 指标。本文对句子层级摘要进行语篇分割,分析句子层级摘要和子句层级摘要,发现选择子句组成摘要可以丢弃句子内部多余的细节信息,保留更多核心概念或者事件,从而得到更简洁和信息更丰富的摘要。
为了解决问题2)中的异构关系学习挑战,本文提出一种基于异构图分层学习的细粒度多文档摘要抽取框架。该框架通过层次化构建单词层级图和子句层级图,分别建模子句的语义关系和子句间的多种结构关系。进一步通过单词层级图学习层和子句层级图学习层,层次化地学习上述2 个异构图。2 个学习层基于图注意神经网络,分别针对异构图关系特性设计2 种不同的层次更新机制。单词层级图学习层的层次更新机制是基于文献[6]的工作应用到子句层级。在子句层级图学习层中,本文提出子句层次更新机制,分别对子句层次图的3 种结构关系进行学习更新,然后通过聚合函数得到子句结构化表示。最后,把获得的表示输入到子句选择层中以预测抽取目标摘要。本文的主要工作包括如下三点:
1)针对句子级别的多文档摘要抽取问题,本文通过实验验证子句建模的有效性,进一步提出异构图分层学习的细粒度多文档摘要抽取框架,有效建模单词、子句、文档之间的多层级异构关系。
2)多文档摘要抽取框架基于层次更新的思想,提出2 个层级学习层和层次更新机制,学习多文档摘要抽取的多种结构关系,降低图神经网络在学习复杂异构图时的难度。
3)在多文档摘要数据集Multi-news 上进行实验,验证该框架以及各个模块的有效性。
1 相关工作
1.1 基于图建模的抽取式文档摘要方法
图结构方法广泛应用于多文档摘要任务,以文本单元为节点、以它们之间的语义关系为边的图结构方法能够很好地建模文本单元之间的关系,对整个文本的信息进行排序,选择最突出的内容作为摘要。很多研究工作都是在句子层级进行建模,对句子进行重要性排序。
LexRank[4]引入一种基于句子词汇的相似图方法,以计算文本单元的相对重要性。文献[13]考虑到文档信息的重要性,进一步将文档级信息和句子到文档的关系纳入基于图的排序过程中。文献[5]将GCN 应用于从RNN 获得的含有句子嵌入的关系图中。文献[14]提出一种基于图的神经句子排序模型,该模型利用实体链接图来捕获句子之间的全局依赖性。文献[6]构建一个异构图网络进行摘要抽取,在句子级节点的基础上引入单词节点作为句子节点的中介,以丰富句子间的关系。文献[15]将文本多维度特征的融合问题转化为图集成方式,提高了句子间相似度计算的准确性,并在此基础上生成文本摘要。文献[16]借助预训练模型和余弦相似度创建句子间的边连接关系,提出基于关键词密度的句子评分方法以提取摘要。文献[17]提出一种基于多粒度语义交互的抽取式摘要方法,将多粒度语义交互网络与最大边界相关法相结合,捕获不同粒度的关键信息,保证摘要信息的完整性。文献[18]提出融合多信息句子图模型,将句子间的主题信息、语义信息和关系信息融入句子表示中,从而选择出重要的句子。文献[19]将原始文本转化为相应的抽象语义表示(AMR)图,利用综合统计特征对不具有权值的AMR 图节点赋予权值,筛选重要的部分构成语义摘要子图。
上述抽取式方法都是在句子层级构图来建模输入文档的结构,对句子进行重要性排序。与上述方法不同,本文模型以子句为建模单位,在多个层级建模子句间的依赖关系,对子句进行重要性排序。
1.2 冗余降低的文档摘要方法
有效选择重要内容同时提升摘要的简洁性,一直是抽取式文档摘要任务的难点。
一些工作致力于平衡句子的显著性和冗余性,如文献[20]将摘要抽取定义为语义匹配问题,通过匹配候选摘要的语义与标准摘要的语义来选择显著性高且冗余性低的句子子集以组成摘要。文献[21]建模句子间的冗余依赖性,指导冗余信息在句子表示之间的传播,学习不带冗余信息的句子表示,抽取出冗余度低的句子集合。文献[22]引入强化学习来考虑抽取摘要的语义,将最大似然交叉熵损失与政策梯度的奖励相结合,直接优化摘要任务的评价指标。上述方法在摘要级别提升简洁性,只能减少具有重复信息的句子,无法减少句子内部的不必要信息。
一些工作通过重写或者压缩候选句子来丢弃候选句子中的不必要信息。文献[23]提出包含删除等离散操作的句子压缩模型。文献[24]提出一种基于树结构修剪的两阶段神经网络模型用于选择和压缩句子,但2 个阶段之间不可避免地存在分离。
与上述方法不同,本文在子句级别提升摘要的简洁性,以子句作为抽取单元,相当于在选择子句的同时变相对句子进行了压缩,不存在2 个阶段分离的问题,有效选择重要内容同时去除句子中的不必要信息,从而提升摘要的简洁性。
2 方法介绍
本文提出的基于异构图分层学习的细粒度摘要抽取框架如图1 所示,该框架包括如下层级:
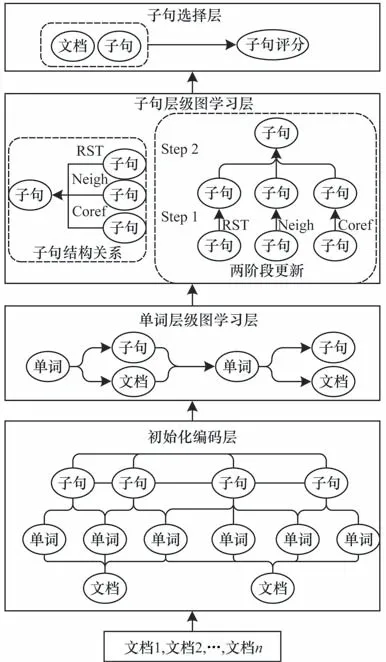
图1 基于异构图分层学习的细粒度多文档摘要抽取框架Fig.1 Fine-grained multi-document summarization extraction framework based on heterogeneous graph hierarchical learning
1)初始化编码层。层次化构建单词层级图和子句层级图,并对图上节点进行编码得到初始化节点表示。
2)单词层级图学习层。通过图注意网络的更新方式学习基于共有单词的子句间的语义关系。
3)子句层级图学习层。通过两阶段分步学习的更新方式学习子句层级的多种结构关系。
4)子句选择层。对子句节点表示进行评分,以预测摘要的标签。
2.1 图结构构建与初始化
首先对多文档摘要抽取任务进行公式化定义:给定一个多文档集合D={d1,d2,…,dk},共有k个文档。本文通过文献[25]提供的端到端神经分割器对多文档集合D中的句子进行分割得到相邻不重叠的子句集合S={s1,s2,…,sn},子句集合S包含的所有单词可构成单词集合W={w1,w2,…,wm}。为了提取若干子句组成摘要,本文将该任务设计为一个序列标记任务,目标是对子句集合S预测一个标签序列Y={y1,y2,…,yn}(yi∊(0,1)),yi=1表示第i个子句属于候选摘要。
为了建模子句间的语义关系和多种结构关系,本文层次化地构建单词层级图Gword和子句层级图Gsub-sent。其中,单词层级图Gword={Vword,Eword}以共有单词为载体建模子句间的语义关系,Vword是由单词、子句和文档3 种粒度节点组成的节点集,Vword=Vw∪Vs∪Vd,其中,Vw={w1,w2,…,wm}对应多文档集合中的m个单词节点,Vs={s1,s2,…,sn}对应多文档集合中的n个子句节点,Vd={d1,d2,…,dk}对应多文档集合中的k个文档节点。Eword是3 种粒度节点之间的边集合,eij≠0 表示第i个节点和第j个节点之间存在边。具体地,本文在单词节点和其他粒度节点间构建语义连接,在子句节点和其包含的单词节点间构建边,在文档节点和其包含的单词节点间构建边。在文本摘要中,尤其是新闻摘要中,核心概念(如关键人物或者事件)会贯穿整个摘要,多个摘要句通过关键人物或者事件进行交互构成完整的摘要。单词节点和其他粒度节点的连接越多,表明该单词在子句和文档中出现的频次越高。本文对词频top20 的单词进行统计,如图2 所示,单词词频越高,属于摘要句的概率越大,该单词越可能是贯穿整个摘要的关键词。
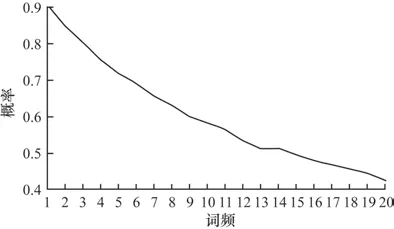
图2 词频top20 的单词属于摘要句的概率统计Fig.2 Probability statistics of words with a frequency of top20 belonging to summary sentences
在构建完单词层级图后,在图上3 种粒度节点进行交替更新的过程中,单词节点作为其他粒度节点交互的载体,聚合其他粒度节点的信息并在新一轮迭代中把聚合信息传递给其他粒度节点,由此借助单词节点完成其他粒度节点间的信息交流。但是,在单词节点把聚合信息传递给其他粒度节点的过程中,仅凭单词节点与其他粒度节点之间的边,无法使得其他粒度节点有效筛选单词节点中的聚合信息。而TF-IDF 可用于表示一个单词对于一个文档集合中一个子句或者一个文档的重要程度,其中TF(The Term Frequency)是单词在子句或文档中出现的次数,IDF(Inverse Document Frequency)是单词出度的逆函数。将TF-IDF 作为先验边权,可以在单词节点从其他粒度节点中聚合信息和传递聚合信息给其他粒度节点的过程中,依然保留单词节点与其他粒度节点先验的重要性关系,使其他粒度节点有效筛选单词节点中的聚合信息。因此,本文引入单词节点和其他粒度节点的TF-IDF 值,把它映射到多维嵌入空间中并作为边权E。
子句层级图在子句节点间建模子句间的多种结构关系,Vsub-sent={s1,s2,…,sn}对应多文档集合中的n个子句节点,Esub-sent是节点之间的边集合。具体地,本文在子句节点间构建3 种结构关系,包括相邻上下文关系(Neigh)、共指关系(Coref)和话语结构关系(RST)。其中:相邻上下文关系Neigh 是指各个子句节点与它们的相邻子句节点相连,从而保证相邻子句节点的语义连贯性;在文本摘要尤其是新闻摘要中,关键人物或者事件往往贯穿全文,这种远距离依赖关系往往容易被模型忽略,因此,本文使用开源的Standford Core 工具推理出文档集中的所有共指引用聚类,对于每个共指引用聚类,同一聚类提及的子句节点都创建相连的边来构建子句间的共指关系Coref;子句需要考虑一些限制以确保语法的正确性,本文利用文献[26]提出的RST 话语解析器将输入文档解析为RST 话语树,并通过文献[9]提出的转换方法把RST 话语树转换为子句间的RST 话语结构并构建边,进一步补充子句节点的语法信息。
通过上述过程可以完成单词层级图和子句层级图的构建,接下来将进行图节点信息初始化。设节点特征矩阵集X={Xw∪Xs∪Xd},其中分别表 示单词节点、子句节 点和文档节点的特征矩阵,dw、ds和dd分别表示单词特征向量、子句表示特征向量和文档特征向量的维度大小。具体地,本文使用已训练好的GloVe 嵌入作为单词节点的初始特征矩阵卷积神经网络(CNN)[27]可以通过不同卷积核的大小进行不同特征窗口的局部特征提取,双向长短期记忆(BiLSTM)神经网络[28]可以捕捉子句内部单词间的位置序列关系从而得到子句级别的全局特征。因此,本文对子句节点分别使用CNN 和BiLSTM 进行内容和位置的编码,使用不同核大小的CNN 捕捉每个子句的n-gram 局部特征l,使用BiLSTM 捕捉子句级别的全局特征g,拼接2 个特征得到子句节点的初始特征矩阵,充分考虑子句节点表示的内容信息和位置信息。然后对每个文档包含的子句节点的特征进行平均池化,得到文档节点的初始特征矩阵
2.2 单词层级图学习层
完成单词层级图和子句层级图的构建与初始化后,本节将对单词层级图Gword={Vword,Eword}进行节点更新。本文采用的单词层级图学习层的层次更新机制是将文献[6]的工作应用到子句层级,利用图注意神经网络(GAT),借助共有单词为载体学习子句间的语义关系,更新子句节点集的特征矩阵Xs,该层次的更新机制可表示为:
其中:3 个输入Hq、Hk和Hv分别为查询节点(query)特征矩阵、键节点(key)特征矩阵和值节点(value)特征矩阵,通常键表示等同于值表示。Hq、Hk和Hv均为单词层级图的节点特征矩阵集X。
在单词节点与其他粒度节点的交互中,将不同子句或者文档包含的同一单词设置为同一单词节点,同一单词节点对其他不同粒度节点的重要性是不同的,而传统图注意网络无法很好地在3 种粒度节点的交互过程中捕捉到相同单词的不同重要性。
为了解决上述问题,本文对图注意网络模型进行改进,在3 种粒度节点的交互过程中引入单词节点与其他粒度节点的TF-IDF 值,用于表示单词节点对其他粒度节点的相对重要性,将TF-IDF 值映射为边权向量,指导3 种粒度节点的表示学习。具体地,在计算单词节点与其他粒度节点的注意力权重时,将TFIDF 边权向量与键向量和查询向量一起拼接后通过映射函数转换为注意力权重,让TF-IDF 边权向量直接指导单词节点和其他粒度节点间注意力权重的学习,进而使模型考虑到同一单词节点对于其他不同粒度节点的相对重要性。具体计算公式如下:
其中:hi∊Hq为查询节点i的特征表示;hj∊Hk为键节点j的特征表示;eij是节点i和节点j的边权特征向量;Wa、Wq和Wk都是可 训练的参数;LeakyReLU 是一种激活函数;aij表示节点i和节点j的注意力权重;ui表示K个注意力头的结果;FFN 为2 个线性变换组成的位置前馈层是节点i的输出特征表示。
基于上述改进的图注意神经网络,本文对单词、子句和文档3 种粒度节点进行统一的交替更新,以有效学习基于共有单词的子句间的语义关系。更新顺序如图3 所示。
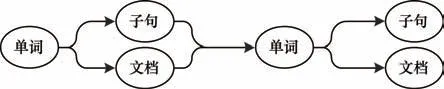
图3 多粒度交互更新顺序Fig.3 Multi-granularity interactive update order
单词层级图学习层对单词、子句和文档3 种粒度节点交替更新,以聚合了子句信息和文档信息的单词节点为载体,传递子句间的语义信息,从而有效学习基于共有单词的子句间的语义关系。
2.3 子句层级图学习层
除了在单词层级图学习层中学习子句间的语义关系,本文所提框架将进一步在子句层级图Gsub-sent={Vsub-sent,Esub-sent}上学习子句的结构化表示。
由于本文在子句层级图上引入了3 种结构关系Esub-sent,而传统图注意网络GAT 无法同时有效学习多种结构关系,因此本文针对子句层级图学习层设计一种两阶段分步学习的更新机制,以学习子句层级图的多种结构关系并聚合多种结构信息,最终得到子句的结构化表示。具体地,第一阶段对子句间的多种结构信息分别进行学习,学习子句节点集Vsub-sent关于3 种类型关系的特征向量Utype;第二阶段对多种结构信息进行聚合,分别学习子句节点各种类型关系的权重SScore,type,并聚合3 种关系类型的特征向量Utype,最终得到子句的结构化表示2 个阶段具体计算如下:
1)第一阶段。
基于图注意神经网络GAT 分别学习子句节点3种关系的特征向量Utype,可表示为:
其中:3 个输入Hq、Hk和Hv分别为查询节点(query)特征向量、键节点(key)特征矩阵和值节点(value)特征矩阵,Hq、Hk和Hv是单词层级子图更新后的子句节点特征矩阵
具体地,由于不同类型关系包含的信息不同,本文将子句节点集Vsub-sent和其邻居节点的3 种结构关系通过不同的线性映射函数映射到不同的边类型向量空间中,对具有相同类型的边类型邻居节点映射到相同的边类型向量空间中。由于子句节点对同种关系下的不同邻居有不同重要性,因此本文使用点乘注意力机制学习该关系下不同邻居节点的重要性,并聚合该关系下的不同邻居节点得到该关系下子句节点的特征向量Utype。第一阶段具体计算过程如下:
其中:hi∊Hq为查询节点i的特征向量;hj∊Hk为键节点j的特征向量Wtype是可训练参数;type ∊{Neigh,Coref,RST};Wtype是将特 定关系 类型映射到对应向量空间的映射参数表示特定关系类型下节点i和邻居节点j的注意力权重表示特定关系类型下邻居节点j归一化后的注意力权重;ui,type表示特定关系类型下子句节点i的语义表示。
2)第二阶段。
基于加权平均的思想学习子句节点3 种语义表示Utype的权重SScore,type,并聚合子句节点的3 种关系语义表示Utype,得到最终的子句节点结构化表示
本文充分考虑子句节点集Vsub-sent对3 种类型关系中每个邻居节点的重要性,通过将子句节点在同类型关系下的邻居节点映射到对应的值向量空间中,利用tanh 激活函数和归一化函数得到同类型关系下所有邻居节点的初始注意力权重,接着采用平均池化方式得到子句节点在该关系类型下语义表示的最终注意力权重,并根据最终注意力权重聚合子句节点的3 种关系语义表示Utype。具体计算方式如下:
其中:Ws和是可训练参数;tanh 是激活函数;MeanPooling 表示平均池化操作;sscore,i,type表示节点i的type 类型关系语义表示的注意力权重;是节点i在多种关系语义表示聚合后的表示;FFN 为2 个线性变换组成的位置前馈层是节点i的最终特征表示。
通过子句层级图学习层,用两阶段分步学习的更新机制学习子句间的多种结构关系并聚合多种结构信息,得到最终的子句节点语义表示
2.4 子句选择层
3 实验验证
为了验证本文所提模型的有效性,在公开多文档摘要数据集Multi-news 上,将其与基准模型进行实验对比。本文所提模型首次在多文档摘要任务中使用细粒度建模和抽取方法,通过将其与经典基准模型、近两年在句子层级进行建模和抽取的粗粒度强基准模型、生成式强基准模型等进行比较,从而验证本文细粒度子句层级建模框架对多文档摘要抽取的有效性。此外,通过消融实验验证2 个层级学习层和层次更新机制是否能够降低图神经网络学习复杂异构图时的难度。
3.1 数据集
Multi-news 是文献[29]提出的一个大规模多文档摘要数据集,由来源不同的新闻文章和人工书写的摘要组成。数据集被分割为44 972、5 622、5 622 个样本,分别用于训练、验证和测试。其中,每个样本由2~10 个源文档和1 个人工书写摘要组成。本文参照文献[11]的方法,通过计算候选摘要与人工摘要的ROUGE-1、ROUGE-2、ROUGE-L 的平均分数构建标签序列。
3.2 基准模型
本文将每个源文档的前3 个句子进行拼接作为基线,使用由文献[29]发布的经典模型代码,并将这些经典模型作为基线。经典模型包括:LexRank[4]是一种在提取摘要中计算句子相对重要性的基于图的方法;TextRank[30]是一个基于图的排名模型,句子重要性得分通过基于语料库中全局图的特征向量中心性而计算得到;最大边际相关性(MMR)[31]计算句子与原始文档的相关性以及与文档中其他句子之间的相似度,基于相关性和冗余度对候选句子打分,根据得分排名选择句子生成摘要;PG[32]是一种基于循环神经网络的生成式摘要模型,通过注意力机制允许指针从文档中复制单词,也可以从词汇表中生成单词,能够缓 解OOV 问 题;CopyTransformer[33]对Transformer 进行扩展,使用一个内容选择器从源文档中筛选出应成为摘要中内容的短语;Hi-MAP[29]将PG 网络模型扩展为一个分层网络,能够计算句子级别的MMR 分数。
近年来出现的强基准模型包括:GraphSum[34]将文档编码为已知的图表示形式,捕捉句子间的相似度或语篇关系,并利用图结构来指导摘要生成过程;HDSG[6]在多文档摘要中首次引入异构图,利用句子的共有词建立句子之间的关系从而抽取句子;EMSum[35]借助实体构建句子间的关系,并使用两阶段注意力机制来解决解码过程中的显著性和冗余问题;MatchSum[20]将摘要提取定义为语义文本匹配问题,其匹配从语义空间原始文本中提取的源文档和候选摘要。
3.3 实验设置
通过实验对参数进行设置,词汇表大小为90 000,在创建单词节点时过滤停止词、标点符号以及一些低频词,本文选择将输入截断至500 个token,因为当输入长度从500 增加到1 000 时,效果并没有得到显著改善。同时,将输入文档截断至最多150 个子句长度。初始化子句节点、文档节点和全局上下文节点的维度为64,多头注意力机制中的边特征维度为50,更新单词节点表示时头数量为6,更新其他节点时头数量为8,位置前馈层的隐藏状态维度为512。
在模型训练时,学习率e为5×10-4,学习率逐轮下降,新学习率为e(/轮次+1),每个批次为32 个样本,每100 个批次进行一次轮参数更新,使用Adam优化器进行优化,当验证集的损失3 次不下降就停止训练。根据人工摘要的平均子句长度,选择抽取前27 个子句作为最终的候选摘要。
3.4 细粒度子句层级建模框架有效性实验
本文使用ROUGE 得分对所提模型以及各种基准模型进行评估,基准模型包括传统经典基准模型和近两年的强基准模型,后者包括生成式强基准模型和抽取式强基准模型,实验结果如表1 所示。

表1 Multi-news 数据集上的测试结果Table 1 Test results on the Multi-news dataset
从表1 可以看出:
1)与粗粒度抽取强基准模型HDSG 相比,本文模型的ROUGE-1 提 升0.88,ROUGE-2 提 升0.23,ROUGE-L 提升2.27,说明在句子层级进行抽取组成摘要,句子内部存在多余信息,会在很大程度上影响摘要性能上限,而在细粒度子句层级进行建模,可以将句子中的关键信息和多余信息分开并选择关键信息,从而提高抽取式摘要的性能。
2)MatchSum 将摘要抽取任务定义为文本匹配任务,试图在摘要级别降低冗余信息,从而提高抽取性能,但是MatchSum 和未考虑冗余信息的抽取式强基准模 型HDSG 相 比,ROUGE-1 仅提升0.15,ROUGE-2 和ROUGE-L 持平,说明在摘要层级降低冗余并非提高抽取性能的最佳方法。本文模型和MatchSum 相比,ROUGE-1 提升0.73,ROUGE-2 提升0.23,ROUGE-L 提升2.27,说明细粒度建模和抽取优于在摘要层级降低冗余的方式。
3)与生成式强基准模型GraphSum 和EMSum 相比,本文模型ROUGE-1 分别提升0.86 和0.04,ROUGE-2 分别下 降0.84 和1.68,ROUGE-L 分别提升2.13 和1.80。ROUGE-1 和ROUGE-L 的提升说明与从词汇表逐字生成摘要的生成式方法相比,细粒度建模和抽取能够保持抽取式方法简单有效的特点,同时具备生成式方法低冗余信息的特点。
4)生成式强基准模型EMSum 的ROUGE-2 与抽取式基准模型相比都有大幅提升,本文认为这可能是因为Multi-news 数据集中参考摘要更倾向于使用新的单词或者短语来对源文档进行总结。
3.5 2 个层级学习层和层次更新机制有效性实验
为了验证2 个层级学习层和层次更新机制在降低图神经网络学习复杂异构图难度方面的有效性,在Multi-news 数据集上对所提模型进行消融实验。首先分别进行单词单一层级更新(Word level update)和子句单一层级更新(Sub-sentence level update),从而验证2 个层级学习层的有效性;然后在上述实验的基础上,进一步用传统GAT 来替代本文提出的两阶段分步学习的方式(Word+Sub-sentence level update with GAT),从而验证层次更新机制的有效性。实验结果如表2 所示。
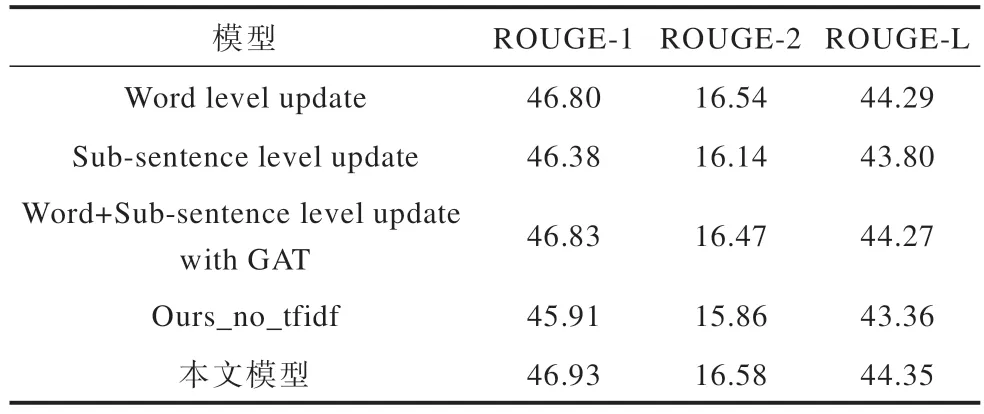
表2 消融实验结果Table 2 Results of ablation experiment
从表2 可以看出:
1)单词单 一层级更新(Word level update)的ROUGE-1、ROUGE-2 和ROUGE-L 分别为46.80、16.54 和44.29,子句单一层级更新(Sub-sentence level update)的ROUGE-1、ROUGE-2 和ROUGE-L分别为46.38、16.14 和43.80,表现都优于粗粒度抽取强基准模型,说明在单词和子句任一层级建模子句间的细粒度关系都优于粗粒度抽取效果。本文模型在2 个层级建模子句间的细粒度关系,和单一层级建模相 比,ROUGE-1、ROUGE-2 和ROUGE-L 都 得到了提升,说明层次化构建单词层级图和子句层级图能够有效建模语义关系和结构关系,2 个层级学习层可以降低复杂异构图的学习难度。
2)和用传统GAT 聚合子句间多种关系的模型(Word+Sub-sentence level update with GAT)相比,本文模型的子句层级图学习层使用两阶段分步学习的更新机制,进行2 次注意力学习过程,两阶段分步学习更新机制的运算成本如表3 所示,参数量约增加了17%,每100 轮迭代运算时间增加了5%。消融实验结果表明,ROUGE-1、ROUGE-2、ROUGE-L 分别提升了0.10、0.11 和0.08,这说明两阶段分步学习的层次更新机制通过首先聚合同种结构关系、然后学习不同结构信息的注意力权重、最后聚合不同结构信息的方式,使得模型在学习多种复杂结构信息的过程中,对多种结构信息的聚合过程进行拆分,各个阶段的学习更有针对性,能更有效地聚合子句间的多种结构信息。

表3 各模型的运算成本Table 3 Calculation cost of each model
通过以上实验说明,2 个层级学习层和层次更新机制可以有效降低图神经网络在学习复杂异构图时的难度,提高摘要的性能,进一步验证了本文所提框架的有效性。
3.6 实例分析
表4 展示了本文细粒度抽取模型和粗粒度抽取基准模型HDSG 的摘要实例。从表4 可以看出,本文细粒度抽取模型和HDSG 都与人工摘要的表达意思相近,不同的是,从划线内容来看,细粒度抽取模型在生成候选摘要时可以减少句子内部的冗余信息,说明本文细粒度抽取模型可以提高摘要的简洁性从而提升摘要性能上限。同时也可以看出,细粒度抽取模型的摘要存在一些独立的短语,可读性不如粗粒度抽取模型的摘要。

表4 抽取式摘要示例Table 4 Extractive summarization samples
4 结束语
本文提出一种基于异构图分层学习的细粒度多文档摘要抽取模型,通过层次化构建2 个异构图来有效建模子句的语义关系和结构关系,从而提升摘要抽取效果。实验结果表明,相比抽取式模型,该模型在多文档摘要数据集Multi-news 上有显著的性能提升,消融实验结果也验证了模型中各模块的有效性。下一步将优化多种复杂关系的聚合方式,探究基于语法限制的抽取方法,以提高抽取摘要的可读性。
猜你喜欢
四川师范大学学报(自然科学版)(2023年1期)2023-03-12
粉末冶金技术(2021年3期)2021-07-28
南京大学学报(自然科学版)(2021年1期)2021-01-30
航天工业管理(2020年9期)2020-12-28
军事运筹与系统工程(2020年1期)2020-09-11
计算机集成制造系统(2020年8期)2020-09-11
西夏学(2018年2期)2018-05-15
系统工程与电子技术(2016年12期)2016-12-24
系统工程与电子技术(2016年2期)2016-04-16
智能系统学报(2015年5期)2015-12-03
