
专有名词增强的复述生成方法研究
2024-03-21 08:15张雪陈钰枫徐金安田凤占
计算机工程 2024年3期
张雪,陈钰枫,徐金安,田凤占
(1.北京交通大学计算机与信息技术学院,北京 100044;2.北京天润融通科技股份有限公司,北京 100176)
0 引言
复述生成任务是给定一个原句生成与其语义相同但用词或句法不同的复述句,即生成与原句语义一致、表达具有多样性的句子。作为自然语言处理领域的基础研究课题之一,复述生成被广泛应用于其他下游任务中,如自动问答系统[1-2]、文本生成[3]、机器翻译[4]等,在这些场景下,复述生成可以作为一种有效的数据增强策略,通过生成高质量的复述句提高原始训练数据的多样性[5],进而提升下游任务中模型的性能和鲁棒性[6]。
近年来,随着GPT[7]、BART[8]等生成式预训练模型被提出,复述生成技术已经取得了长足的进步,能够生成自然流利的复述句。基于这些预训练语言模型,使用复述语料对其进行微调就可以得到一个可用的复述生成模型。尽管这些技术已经能够满足一般场景的需求,然而在实际中文应用场景下,当前中文复述模型的词汇约束能力仍然较弱,导致其在一些特定场景下的应用受限。例如,在实际对话系统业务下意图识别任务的冷启动中,试图针对一条原句生成多条近义的复述句来增强意图识别模型的训练语料,为了保证生成结果的多样性,通常会使用随机采样的解码策略进行多次解码。然而,这种解码的随机性在缺乏约束的情况下会造成专有名词丢失的问题,导致生成的复述句与原句产生语义偏移,从而影响意图识别模型的准确率。
针对上述问题,本文提出两种专有名词增强的复述生成方法,分别用于解决单个专有名词和多个专有名词的保留问题。针对原句中包含单个专有名词的场景,提出基于占位符的复述生成模型。对于训练数据中包含专有名词的复述句对,使用一个特殊占位符替换句对中的专有名词,使得模型在生成的复述句中能够保留原句中的占位符。之后,再将占位符替换回对应的专有名词,从而显式地保证专有名词生成的准确率。针对原句中包含多个专有名词的场景,提出词汇约束的复述生成模型,将句对中的多个专有名词依次拼接并标记后拼接在原句末尾,通过训练使模型学习从原句中保留专有名词的能力,从而隐式地赋予模型生成多个专有名词的能力。
同时,考虑到实际应用场景中通常缺乏参考复述句来评估生成复述句的质量,本文设计一种全新的参考句无关的评估指标,从语义相关性和表达多样性两方面综合评估复述句的质量,通过将原句与复述句之间基于BLEU 的卡方分布函数与基于文本向量余弦距离的线性函数进行加权求和,使得衡量下的最优复述句能够满足语义相似度高,同时表述相似度适中的要求。
为了更加全面且真实地验证本文所提方法的有效性,以真实对话系统业务中的意图识别冷启动作为下游任务,用本文提出的方法生成意图识别模型的训练语料,然后检验意图识别模型的识别效果。
1 相关工作
1.1 复述生成
近年来,随着各种深度神经网络模型的快速发展,复述生成的方法也逐渐从传统基于复述模板或规则的方法转为基于深度神经网络的方法[9]。目前的研究热点有对训练方法和模型结构的改进[10-12]、对可控复述句生成的探究[13-15]以及无监督场景下的复述句生成[16-18],本文重点关注可控复述生成。可控复述生成主要分为2 个方向,即显式可控和隐式可控。显示可控主要是句法可控的复述生成,是指通过给定的句子模板或者句法解析树,使模型生成指定格式的复述句。SUN等[14]利用BART 模型在原句后拼接原句句法解析树和目标句句法解析树作为编码器的输入,训练模型对目标句法的生成能力。YANG等[15]基于Tree-Transformer,设计了句法解析树编码器同时捕捉句法节点的父子关系和兄弟关系,从而充分利用句法解析树的信息来指导复述句的生成。隐式可控复述生成方法中不需要人为指定复述句的模板或句法树,而是通过简单的控制机制来控制模型生成符合特定质量要求的句子。BANDEL等[19]提出了质量约束的复述生成模型,通过给定原句及代表语义、句法、词汇距离的质量控制三维向量,模型可以生成符合质量约束的句子,根据具体任务的不同要求来改变质量控制向量的取值即可生成指定质量特性的句子。这些论文基于句法层级或复述句质量层级研究可控的复述生成,本文主要针对如何保留复述句中的专有名词探究合理的复述生成模型。
1.2 复述句质量评估
复述句的质量评估是复述生成领域的研究热点和难点,评估指标主要分为2种类型,分别是基于统计的评价指标和基于预训练模型的评价指标[20]。基于统计的评价指标有BLEU[21]、ROUGE[22]、METEOR[23]和chrF++[24]等,基于预训练模型且不需要微调的评价指标有BERTScore[25]、MoverScore[26]等,基于预训练模型且需要微调的评价指标有BLEURT[27]、ParaBLEU[20]等。一般情况下,基于统计的评价指标和不经过微调的评价指标使用更方便且对领域变化不敏感,经过微调的评价指标对特定领域的复述句评估效果更好。上述指标在应用时大部分是与参考复述句进行计算,而在实际应用时并无参考复述句。本文综合考虑语义一致性与表达多样性提出一个无需参考句的评价指标,通过与原句进行相关的计算来评估生成复述句的质量。
2 方法介绍
本文采用BART 模型[8]作为复述生成的基础模型,模型由编码器和解码器构成,结构图见图1,编码器对原句进行编码,解码器则根据编码后的向量化表示自回归地生成复述句。本节介绍无约束条件下的复述生成模型、基于占位符的复述模型和词汇约束的复述模型,同时介绍提出的参考句无关的评价指标。
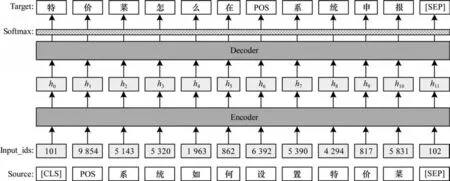
图1 BART 模型结构Fig.1 Structure of BART model
2.1 基准复述模型
本文的基准复述生成模型(PG)不考虑专有名词[14]在复述过程中的保留,该模型基于图1 所示的编码器-解码器架构实现。给定原句X=(x1,x2,…,xL),长度为L,以及目 标复述句Y=(y1,y2,…,yT),长度为T,PG 模型的学习目标为最小化损失函数:
经过训练得到PG 模型后,给定原句生成对应的复述句时,在解码器端采用随机采样的解码策略,就可以生成多条复述句。
2.2 基于占位符的复述模型
为了解决单个专有名词的保留问题,本文首先提出基于占位符的复述生成模型(PBPG)。该模型的核心思想是在复述之前,将原句中的专有名词替换为一个占位符。PBPG 模型能够在生成的复述句中保留这个占位符,再通过后处理将占位符替换回原来的专有名词,实现专有名词的保留。训练时,本文将训练数据中源端和目标端同时出现的专有名词替换为占位符[key],如图2 所示,构造出含有占位符[key]的专有名词训练句对。
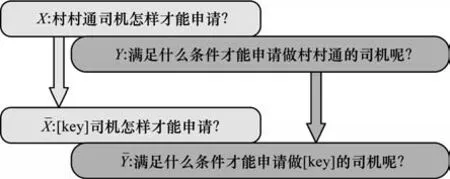
图2 PBPG 模型的训练数据Fig.2 Training data of PBPG model
经过训练得到PBPG 模型,将含有占位符[key]的原句输入模型进行解码,就可以生成含有占位符[key]的复述句,再将占位符[key]替换回原始专有名词,即可得到专有名词保留的复述句。当原句中含有单个专有名词时,PBPG 模型可以很好地保留专有名词。
2.3 词汇约束的复述模型
当原句中含有多个专有名词时,如果全部替换成占位符[key],在生成句子反向替换回专有名词时无法确定专有名词的顺序,导致PBPG 模型不适用于多个专有名词保留的复述句生成,本文提出词汇约束的复述生成模型(LCPG),将多个专有名词作为控制元素指导复述句的生成,模型的输入见图3。通过引入专有名词分隔符[sp],将需要保留的专有名词用分隔符[sp]相连拼接到原句末尾。同时为了对专有名词和原句作区分,引入segment_id,在训练时对原句和专有名词赋不同的segment_id 值,确保模型对原句和专有名词的区分能力,从而学到对专有名词的复制能力。

图3 LCPG 模型编码器的输入Fig.3 Input of LCPG model encoder
假设原句中需要保留的专有名词列表为K=(k1,k2,…,ke),模型编码器端输入单词序列为(x1,x2,…,xL,[sp],k1,[sp],k2,…,[sp],ke),对于上 述引入的segment_id,形式化地,对于LCPG 模型,其编码器端每个位置的输入ri可以表示为:ri=xi+pi+si,其 中,pi为第i个位置 的位置编码,si为xi对应的segment 向量。解码器端的输入为Y=(y1,y2,…,yT),LCPG 模型的学习目标为最小化损失函数:
当句子有多个专有名词时,为了防止专有名词之间的顺序限制生成复述句的多样性,在实际构建训练语料时,本文会把专有名词列表随机打乱顺序再和原句拼接作为编码器的输入。同时,由于LCPG生成的结果即为复述句本身,因此相比于PBPG 减少了后处理的步骤。
2.4 评价指标
为了评估在在无参考复述句场景下生成复述句的质量,本文综合考虑语义一致性和表达多样性,设计了RFSM 评价指标,计算公式如下:
其中:sim(x,p)是生成复述句p与原句x用同一编码模型编码后得到句向量的余弦相似度,取值范围为[-1,1],代表生成复述句p与原句x的语义一致性;div(x,p)则反映的是生成复述句的多样性,函数图像见图4,其中的selfbleu(x,p)是生成句子p与原句x的BLEU-1 值和BLEU-2 值的几何平均值,取值范围为[0,100]。
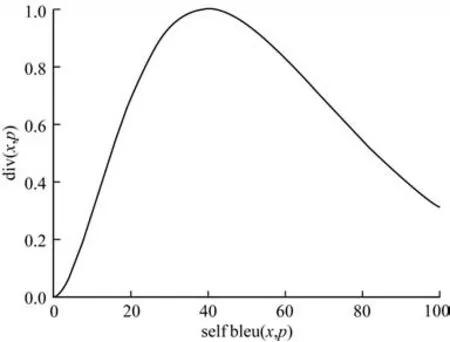
图4 div(x,p)的函数图像Fig.4 Function image of div(x,p)
为保证与余弦相似度的最值在一个量级,本文通过设置u=0.1×selfbleu(x,p),调整div(x,p)的取值范围为[0,1],其设计思想是一个高质量的复述句与原句的字面相似度,即selfbleu(x,p)应保持在一个适中的范围内,过大或过小时对应的复述句质量都不高:过大时说明生成的复述句与原句重复字过多,表达可能不具有多样性;而过小时生成的复述句可能与原句有一定的语义偏移。可以通过调整u的取值,选择出符合预期的复述句,这里本文设置u=4。确定u的取值后可以计算得到C和T的表示,即C=此外,α是权重参数,用来调整语义一致性和句子多样性的权重贡献比,这里本文设置α=0.4。最终RFSM 的值越大,代表生成复述句的质量越高。
3 实验设置与结果分析
为了验证本文提出的方法在实际应用场景中的有效性,以真实对话系统业务中的意图识别冷启动作为下游任务,通过实验来评估本文方法生成语料的有效性。
3.1 数据集
对于复述模型的训练语料,本文从开源的中文复述语料[28]中共收集40 万个的问题簇,其中每个问题簇包含若干的相似语料,每个问题簇内的所有语料互为复述句,经过排列组合等处理后,共生成1 192 万个复述句对。为了得到符合要求的高质量复述句对,本文采用一定的过滤策略对得到的复述句对进行过滤,最终构成原始复述句对训练集D1,共包含709 万个句对。过滤策略从句子的语义一致性和表达多样性两方面考虑:语义一致性通过计算句对向量的余弦相似度得到,阈值为0.8,即余弦相似度大于0.8 的句对保留;表达多样性通过计算句对的BLEU-1 和BLEU-2 值的几何平均值得到,阈值为85,即BLEU 值小于85 的句对保留,通过过滤可以在舍弃掉训练集中重复字过多或语义不一致的句对。
在构建PBPG 模型的训练数据时,基于原始训练集D1,对于每个句对,本文首先对句对中的2 个句子进行分词,通过词性判断,找出2 个句子的公共名词之一作为该句对的专有名词,分别将其替换为占位符[key],构建291 万条含有占位符的复述句对数据集D2,最终PBPG 模型的训练集为D1∪D2。
在构建LCPG 模型的训练数据时,由于涉及到多个专有名词,综合实际项目中真实数据的表现情况,设置原句中支持保留的专有名词最多为4 个。基于原始训练集D1,本文首先计算每对复述句的全部公共子串集,然后对集合中的子串进行过滤,选出适合作为约束词汇的子串,构造带有约束词的复述句对,得到342 万条带有多个词汇约束的复述句对D3,最终LCPG 模型的训练集为D1∪D3。
3.2 实验配置
本文中的所有复述模型均以huggingface 库中开源的BART-base-chinese 模型(https://huggingface.co/fnlp/bart-base-chinese)为主干网络并进行微调,相关训练参数如表1 所示。
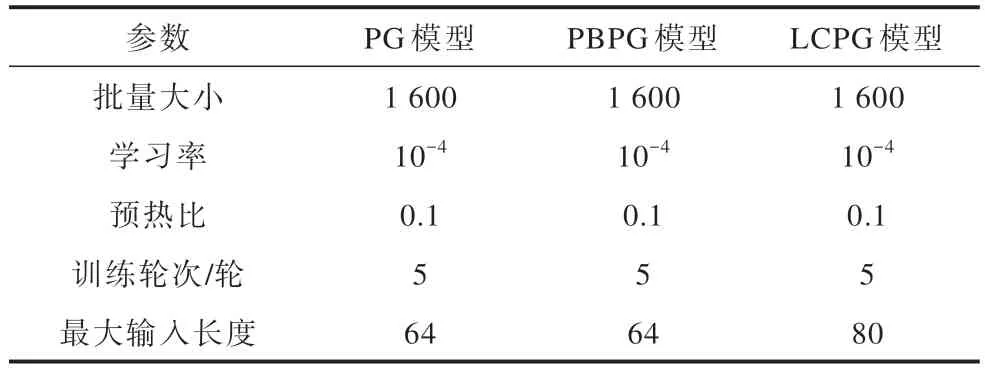
表1 模型的训练参数Table 1 Training parameters of the model
3.3 复述效果对比
为了更好地探究模型对不同类型句子的复述能力,从不同领域、不同长度以及是否含有专有名词这3 个角度考虑,挑选句子40 条句子用PG 模型、PBPG模型和LCPG 模型分别进行复述句生成,部分例句见表2,分别从语义一致性和表达多样性两方面对生成的复述句进行质量评估,对比不同模型的复述能力。在表2 中,加粗代表为专有名词。

表2 复述效果评估的部分原句Table 2 Part of the original sentence for evaluating the effectiveness of paraphrasing
在生成复述句时,通过设置batch size=100 使模型对每条句子同时生解码生成100 条复述句,经过去重后分别得到每个句子的复述句候选集,通过计算候选集中复述句与原句的句向量余弦相似度cosine、self-BLEU 值以及RFSM 的取值 来衡量生成复述句与原句的语义一致性和表达多样性,对于含有专有名词的句子,同时计算生成复述句的专有名词保留率(KRR),最终结果见表3,其中加粗表示最优数据。
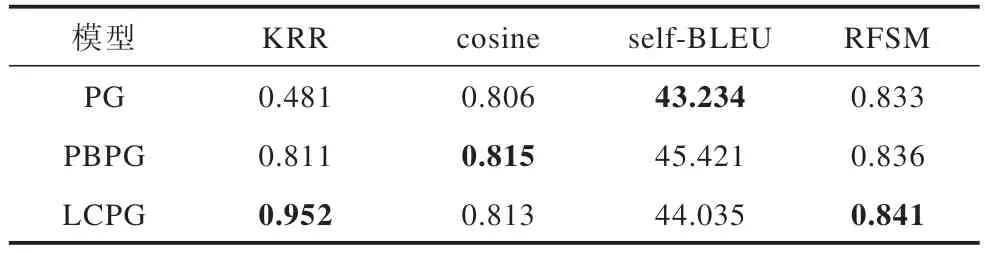
表3 不同模型复述效果对比Table 3 Comparison of paraphrasing effects of different models
KRR 的结果表明,在专有名词的保留程度上LCPG 模型优于PBPG 模型,同时两者均显著优于PG 模型,直接证明了本文方法解决专有名词丢失问题的有效性。由于PG 模型的专有名词保留能力最差,因此PG 模型的self-BLEU 值最小。余弦相似度cosine 的值代表了不同模型生成的复述句与原句的语义一致性,结果表明,PBPG 模型生成复述句的语义偏移最小,但综合评价指标RFSM 的结果中LCPG模型的表现最好。综合表3 结果可知LCPG 模型生成的复述句中专有名词保留率最高,语义损失最小,生成的复述句质量最高。
3.4 意图识别准确率对比
在现存任务型对话系统的意图识别模块内,针对每个项目下设置的意图或标准问题,真实对话场景下不同用户关于同一意图的表达方式是多样的,为了提高意图识别的准确率,在冷启动时项目实施人员必须在一个意图下配置大量的相似语料作为意图识别模型的训练语料,这个过程往往会耗费大量的时间和精力。通过引入复述生成模型,给定原句,模型可以生成一批与原句语义相同且表达具有多样性的复述句直接作为意图识别模型的训练语料,从而解决意图识别模块的冷启动问题,提高项目实施的效率。
为了验证本文提出的方法在实际应用场景中的有效性,以真实业务下的意图识别任务作为下游任务,通过实验来评估本文方法生成语料的有效性。意图识别数据集的原始意图类别从真实项目中自行抽取构造得到,主要来自金融和餐饮两个领域,共107 个意图,其中包括27 个含专有名词的意图和80 个不含专有名词的意图,每个意图包含人工配置的3 条种子句,即用来输入复述生成模型的原句。对应的意图识别任务的测试集来自于真实业务中收集的历史对话数据,通过对连续7 天收集的对话历史中用户的问题进行提取、去重和人工标注,得到包含1 746 个问题的测试集。
分别用PG 模型、PBPG 模型和LCPG 模型对每个意图下的种子句进行复述语料生成,对生成的语料经过去重降噪后直接作为意图识别模型的训练语料。意图识别模型基于TextCNN 模型[29]实现了融合种子句权重的分类模型。本文综合考虑了Accuracy、Micro-F1、Macro-F1 和Weight-F1 作为意图识别模型的评价指标,对比结果见表4,其中加粗表示最优数据,第一行Seed 代表未使用复述模型做训练语料增强,即每个意图下只有种子句作为训练语料,其余3 行则是用不同的复述生成模型根据种子句对每个意图进行语料扩充后训练得到的意图识别模型。
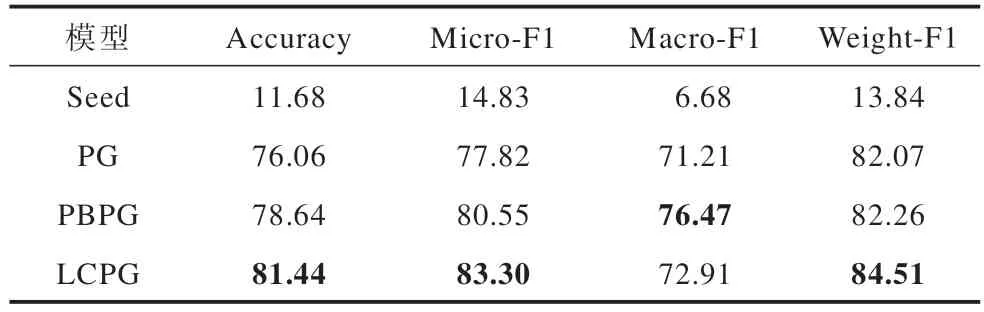
表4 不同模型意图识别结果对比Table 4 Comparison of intention recognition results of different models %
对比未经过数据增强的模型的识别结果可知,经过复述语料增强后的模型识别效果有显著提升,这说明了复述生成模型解决意图识别任务冷启动问题的有效性。分别对比不同复述模型的具体识别结果可知,LCPG 模型生成的复述句作为训练语料训练得到的意图识别模型识别准确率最高,综合考虑不同的F1 值,LCPG 模型也优于PBPG 模型和PG 模型,即加入专有名词约束的LCPG 模型生成的复述句质量较高,这进一步证明了本文提出的模型能生成高质量的复述句,同时减少相似意图下混淆语料的比例,提高意图识别模型的准确率,解决意图识别任务的冷启动问题,提升新项目的实施效率。
3.5 结果分析
由于不同的解码策略会影响模型生成句子的数量和多样性,基于LCPG 模型对采用不同解码策略时生成复述句的质量变化进行探究,主要对比topn解码、核采样(topp)解码中不同参数的取值以及温度系数t的变化对生成复述句的影响。采用的方法是针对一个句子,使模型采用不同的解码策略解码生成同样数量的复述句,经过去重后计算生成复述句的RFSM 值,对不同的解码策略进行评估,对比结果见图5。从图5 中可以观察得到,n和p的取值越大,去重后所剩复述句的数目越多,意味着生成的复述句表达更具多样性,但同时也伴随RFSM 指标值的下降,这意味着生成的复述句质量偏离了理想情况,综合考虑生成复述句的数量以及评估指标RFSM 的平均值,本文在生成复述句时采用n=200 的topn解码策略。

图5 LCPG 模型在不同采样策略下复述句的质量变化Fig.5 The quality changes of paraphrases under different sampling strategies in the LCPG model
此外,在意图识别任务上探索评价指标RFSM的最优权重参数,基于LCPG 模型,采用网格搜索的方法寻找意图识别准确率最高时的最优权重参数,结果见图6。
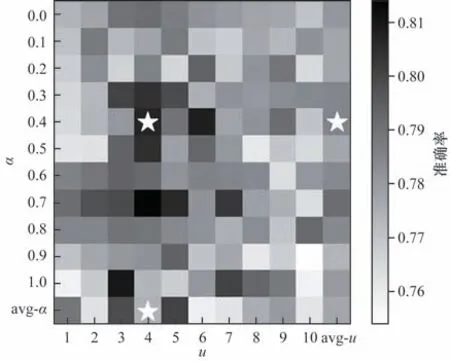
图6 LCPG 模型在不同参数下意图识别的准确率Fig.6 Accuracy of LCPG model in intention recognition under different parameters
从图6 中的最后一行和最右侧一列可以看出,随着u和α的不断增大,意图识别任务的准确率先增大后减小,在图6 中的标注处即当α=0.4、u=4 时取得最大值,表明在意图识别任务中表现更好的高质量复述句须同时满足与原句语义一致且表达具有多样性。
4 结束语
对于现有中文复述生成模型对原句中专有名词无法保留的问题,本文提出基于占位符的复述生成模型和词汇约束的复述生成模型,分别解决单个专有名词和多个专有名词的保留问题。实验结果表明,对比不同模型生成复述句的质量以及在意图识别任务中的准确率,词汇约束的复述生成模型能够生成与原句语义一致且表达具有多样性的高质量复述语料,对应语料训练得到的意图识别模型准确率最高。在实际对话系统业务场景中,通过复述生成模型增强意图识别任务的训练语料,可以解决冷启动问题,进而显著提高新项目的实施效率。在未来的工作中,将继续研究如何针对一条句子生成多条高质量的复述句,考虑将句法结构引入并改进生成策略,同时研究如何将通用的复述模型快速迁移到一个新的领域内。
猜你喜欢
中国石油石化(2022年12期)2022-07-16
中国外汇(2019年19期)2019-11-26
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
海外华文教育(2016年1期)2017-01-20
作文评点报·低幼版(2016年3期)2016-05-30
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
新东方英语(2014年4期)2014-04-09
