
基于数学学科知识的语义理解技术研究
2024-03-04 12:00杨哲萍
科技风 2024年5期



摘 要:随着人工智能技术的发展,数学学科知识智能化服务系统越来越多地成为数学教育的辅助工具。结合数学学科知识的特点,本文对数学学科知识中的语义理解技术和应用做总结说明。首先阐述和分析数学学科知识语义理解的技术框架,包含其语义理解过程中知识存储、知识抽取和知识推理等研究;然后阐述用于语义表达通用语料库和数学领域常见的垂直语料库;同时,从数学智能问答系统、自动判卷系统阐述语义理解在数学学科领域中的应用;最后从数学学科语料库、数学学科知识点标注等方面对语义理解的研究趋势作了展望。
关键词:语义理解;自然语言处理;深度学习;数学智能问答
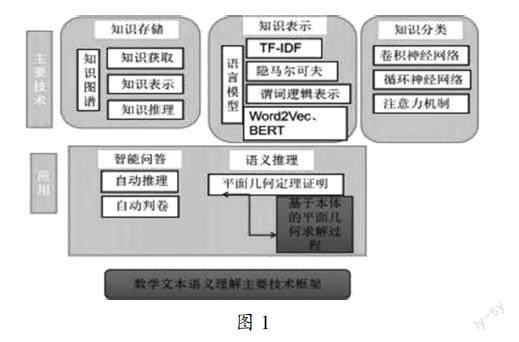
随着互联网和人工智能的发展,“互联网+教育”的方式成为学科教育的主流方式,互联网公司纷纷致力于将互联网技术应用到学科教育上,智能英语问答系统、智能知识百科平台、智能信息检索等智能平台应运而生。但当前的互联网技术仍处于人机交互阶段,许多模式还需要大量的人工干预。随着计算机性能的进一步提升,自然语言技术空前发展,计算机语义理解也广泛应用到各类学科的知识服务中,特别是数学这类基础性学科,很多的智能系统已经在实际场景中得到应用。所以,探索和学习数学学科知识的自然语言语义理解及逻辑推理技术是我们未来需要努力的方向。自然语言语义理解技术先后经历了基于语言学规则、基于统计学和基于深度学习的阶段。当前主要流行的方法是基于深度学习的语义理解。深度学习是通过构建多层神经网络(三层或三层以上),对语义数据进行表征学习和处理。随着LSTM、BERT等神经网络模型的提出,深度学习技术将自然语言的语义理解推至一个新的高度。本文结合数学学科的特殊性,探索和研究数学学科知识的语义理解,从知识获取、知识存储、知识表示等方面,对数学学科知识的知识图谱、知识表示等技术进行总结性研究,并对数学语料库,数学领域的语义理解及应用进行分析和阐述。如图1所示的主要技术框架。
图1
1 数学学科知识的语义理解技术
数学学科知识的语义理解从数学的知识存储、知识表示以及知识分类,实现数学学科知识的全理解。通常来说,知识图谱是经过语义化的网络知识库。它将散乱的数学文本数据经过知识获取、知识表示、知识推理后转化为能够表达领域知识信息的“实体—关系—实体”的三元组合,实现知识的结构化表示。与此同时,知识图谱还将文本数据进行语言模型的表示,形成计算机可理解的数据类型,通过诸如卷积神经网络技术,将带有明显特征的文本数据映射到多个类别上,从而实现文本分类。
1.1 知识图谱
知识图谱本质是个结构化的语义知识库,它揭示了知识实体之间的语义关系,即实体—关系—实体三元组结构形式。如图2(三元组基本形式):
图2 三元组基本形式
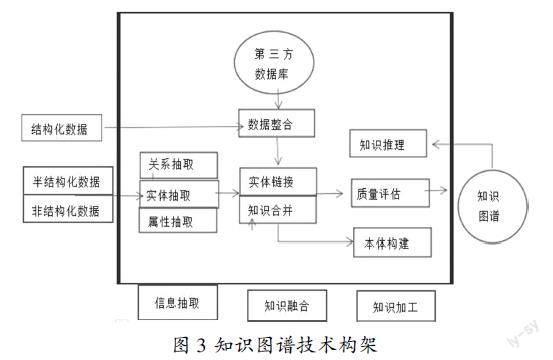
其实,知识图谱是谷歌在2012年为了提高用户搜索引擎查询速度,理解用户的语义信息提出的。知识图谱以现实世界的事物为研究对象,通过“实体—关系—实体”的结构化形式揭示事物内部语义信息。它不仅可以对知识进行查找、匹配、获取、推送和共享,还具有智能工具化和结构化的特点。通过知识图谱,可以将非结构化的文本内容提取出实体与实体关系,再将这些内容转化为相互连接的图谱结构。数学学科的知识图谱是把数学知识作为研究对象,通过语义网络结构化的方法展示数学知识内部存在的逻辑关系和知识点之间的关联。本文主要从数学学科的知识抽取、知识表示、知识保存及知识推理等技术来说明数学知识图谱的构架。图3表示数学知识图谱构架:
图3 知识图谱技术构架
1.1.1 知识抽取
知识抽取是一种自动地从不同结构的数据中抽取可用知识单元的技术。这些知识单元包括从结构化或非结构化的数据中抽取知识的概念、实体、事件,以及其相关的属性和之间具有关联关系等结构的信息[1] 。早期的知识抽取技术采用基于规则的方法抽取。而规则的构建往往需要通过人工归纳总结来完成,然后通过模式匹配的方式进行实体、关系、属性的挖掘。这种方法不需要模型训练,简单高效,但可移植性差。一旦文本结构有所改变,就需要重新构建新的知识抽取规则,人工成本和时间成本耗费较大。
针对规则的抽取方法带来的问题,自动化和半自动化的知识抽取被提出。BiLSTM就是当前一种主流的知识抽取模型。但该种模型对长序列有前端语义信息丢失的问题。后来引入注意力机制,使注意力机制集中在关键部位,生成不同的语义向量,可以解决该模型存在的问题。李思儒[2] 提出将注意力机制用在BiLSTM+CRF的模型之上,获取了不同语境下高中数学知识的实体标签,从而构建高中数学的知识图谱。张晓彤等[3] 在BiLSTM+CRF的基础上,采用SCIBERT预训练模型进一步对数学领域的实体特征提取进行改进,极大提升了模型的F1值。
知識抽取是构建大型知识图谱的关键技术,对知识的语义理解具有重要功能。近年来,语言模型的训练效果随着深度学习的发展得到了很大的提升,特别是神经网络模型和注意力机制的引入,使基于弱监督学习的知识抽取技术得到了快速发展,实体信息、语义特征的抽取都得到了极大的提升。
1.1.2 知识表示
知识表示在知识图谱中起纽带作用,它是把数学描述语言经过处理转化为特定的知识形式,在计算机中进行一系列的存储、传递等操作。数学知识表示的内容是数学概念、数学定理、数学试题等。当前,表示数学学科知识的方法有:框架法、语义网络法、谓词逻辑法、面向对象法等。张文迪[4] 根据立体几何实体及关系知识表示特点,采用面向对象的方法很好地描述立体几何实体及关系知识中的从属关系,并使用Drools规则匹配方法恰当地表示立体几何相关定理公理、概念性质和求解方法。
1.1.3 知识推理
知识推理主要围绕知识内部的实体关系展开,它是通过已有知识推断出未知知识的过程。推理的方法主要包括基于规则的、基于图结构的、基于分布式表示学习的、基于神经网络的和基于混合的等推理方法。张春霞等[5] 构建了数学课程知识推理类型分类体系。从数学语义理解角度给出了知识推理的类型和在数学课程知识图谱中的定位关系,提高了数学知识服务的质量。郭晓冬等[6] 提出将深度学习用于图推理系统中,在初等数学解题系统上实现了部分功能的深度图推理,提高推理引擎进行匹配管理的效率。目前,知识推理作为知识图谱的一种结构化和语义化的表示方式,引发广泛关注。随着深度网络技术的发展,推理规则也向着神经网络技术发展。
2 语料库
随着神经网络技术的发展,构建大规模高质量的语料库是模型训练的基石,直接决定了数学学科知识的语义理解技术的实现效果。
2.1 通用语料库
通用的语料库一般体量庞大,目前国内已开源的语料库如表1:
在数学文本语义理解的过程中,部分处理方式需要依赖大规模语料库,如数学文本分类、数学知识点标注等任务。
2.2 数学领域语料库
作为自然语言处理垂直领域的数学语料库,除了具有通用语料库的离散、抽象、概括、语义等语言特点,同时还具有鲜明的领域特点:即(1)内含大量的数字、公式、符号。(2)语言内部隐含一定的逻辑关系,且不同的数学语言描述在语义理解上是等价的。如等式“1+1=?”和“一加一等于几”以及“小明有一个苹果,妈妈又给他一个苹果,问小明有几个苹果”在描述上完全不同,但在语义理解上又是一样的。这些鲜明的特点使得在处理数学语言文本数据时只能构建自适应范围内的小型语料库。所以,数学通用的垂直语料库鲜少可见。具有代表性的语料库如表2所示:
3 语义理解在数学领域的应用
3.1 数学智能问答
数学智能系统研究伴随人工智能的发展一直存在。早在20世纪60年代,由Bobrow等开发的STUDENT系统就能够理解并自动求解用英语表述的代数问题。90年代后,在自然语言理解领域研究中,基于统计的经验主义方法逐渐被人们所重视。通过建立大量语料库的统计方法,自然语言理解取得了较好的效果。中国研究学者马玉慧以Kintsch等提出的问题表征模型为基础,利用汉语言中句模的研究成果,构建了能够求解中小学数学第一阶段应用题的问题自动问答系统。2012年,Google公司推出的Google Knowledge Graph,目的是为了改善Google搜素引擎的性能,增强用户搜索体验,但深度学习技术的深入,知识图谱在数学领域的智能问答系统发挥巨大作用。冯轩闻[7] 以中学数学学科为例,通过构建面向智能教育的中学数学学科知识图谱,设计并实现了一种基于数学学科知识图谱的自动问答系统。
3.2 自动判卷
自动判卷系统目前是一个正在研究的课题,在我国处于一个比较初级的领域。国外在这方面研究从20世纪60年代开始。最早研究主观题自动评判系统是美国杜克大学的Ellis Essay Grade(PEG)系统。随着自然语言处理技术的发展,该系统越来越完善,目前部分系统已投入商业运行。Intelligent Essay Assessor(IEA)系统是目前已被证明对作文评估与人工评分一致的基于互联网的智能作文评估软件。国内自动判卷系统起步较晚,且没有成熟的应用案例,但相关的研究正在热议。在数学学科方面,针对初中数学学科错误类型,陈显玲等[8] 基于Drools规则推理引擎和符号计算工具,构建错误模型知识库,对学生答题内容进行准确正误判断和错误类型判断,判卷结果6904%与人工判卷结果一致。
4 展望
语义理解技术已广泛应用到数学知识服务领域,在当前现有研究成果的基础上,总结数学语义理解技术的重点问题和发展趋势,认为该领域还存在如下问题:
(1)数学知识库标准化程度低的问题,通过数学百科数据、专家知识库等构建数学统一标准的知识库,可以有效语料库数据泛滥的问题。
(2)目前的数学类文本标注知识点还是以人工标注为主,费时费力,且人工标注存在主观因素导致的标记偏差,影响后续工作。探索适合数学文本知识点标注的模型,提升模型的普适性,帮助科研人员进一步探索数学学科相关的知识智能产品。
(3)随着多模态信息技术的发展,进一步研究图像—文本、视频—文本以及多模态组合内容的模型以及统一维度的映射,完成多模态语义处理问题。随着计算机的算力提升,自然语言处理技术的发展,面向数学知识的智能化服务会有更广阔的发展空间与应用价值。
参考文献:
[1]Guo,X.Y.and He,T.T.Survey about Research on Information Extraction.Computer Science,42,1417.
[2]李思儒.基于深度学习的高中数学知识图谱构建研究[D].长春:东北師范大学,2021.
[3]张晓彤.面向数学领域的命名实体识别算法研究[D].吉林:吉林大学,2021.
[4]张文迪.类人答题系统中立体几何问题自动求解的研究及实现[D].成都:电子科技大学,2015.
[5]张春霞.数学课程知识图谱构建及其推理[J].计算机科学,2020.
[6]郭晓冬.深度图推理研究及其在初等数学问题求解中的应用[D].成都:电子科技大学,2018.
[7]冯轩闻.面向智能教育的学科知识自动问答系统研究与实现[D].西安:西北大学,2021.
[8]陈显玲.初中数学错误模型研究及其在自动判卷系统中的应用[D].成都:电子科技大学,2018.
项目:银川能源学院科学技术研究项目资助,一般项目,项目名称:基于自然语言理解的数学智能问答系统的应用研究,项目编号:2022KYY17
作者简介:杨哲萍(1985— ),女,回族,硕士研究生,助教,研究方向:自然语言处理。
猜你喜欢
计算机应用(2016年12期)2017-01-13
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
电脑知识与技术(2016年10期)2016-06-16
求知导刊(2016年10期)2016-05-01
电脑知识与技术(2016年5期)2016-04-14
