
面向机器人导航的汉语路径自然语言组块分析方法研究
2016-06-16 21:16王浩景阳王鲜惠张超潘蔚陈奇
电脑知识与技术 2016年10期
关键词:自然语言处理
王浩+景阳+王鲜惠+张超+潘蔚+陈奇


摘要:通过汉语自然语言与机器人进行人机交互无疑是一种高效便捷的导航办法。主要针对汉语路径自然语言的处理方法进行研究。首先搭建了10个非结构化的3D环境,针对所构建环境下机器人的导航任务完成了自然语言导航语料的收集,该语料库的来源以在校大学生为主体,辅以各年龄段不同职业的社会人士;然后采用NLPIR汉语分词系统对有效语料进行分词以及词性标注处理,最后为了提取用于导航的语义信息,定义了9种基本组块,并采用条件随机场(CRF)实现了语料的组块自动标注,实验结果表明该方法的组块标注准确率较高,为进一步提取导航语义打下了基础。
关键词:自然语言处理;机器人导航;组块分析;条件随机场
中图分类号:TP242 文献标识码:A 文章编号:1009-3044(2016)10-0181-03
Abstract:Man-robot interaction by Chinese natural language is an efficient and convenient method for robot navigation. In this paper, we mainly study the natural language processing method for Chinese route language. Firstly 10 unstructured 3D environments for robot navigation tasks were built, and then the natural language navigation corpus was collected based on these robot navigation tasks. The most of corpus collectors are college students, in addition to some people with different age and career. Secondly the NLPIR Chinese word segmentation system was used for segmentation and tagging. Finally in order to extract the semantic information for robot navigation, nine basic blocks were defined, and the conditional random field (CRF) model was employed to achieve the data block automatic annotation. The experimental results show that the accuracy of this chunking method is higher, which laid the foundation for further extraction of semantic navigation.
Key words:natural language processing; robot navigation; chunking; conditional random field
1 概述
当移动机器人面对陌生环境的时候,可采用自然语言向其讲述行进路线,机器人通过理解自然语言,并在其指导下自动运行到目的地,这无疑是一种高效的导航方法。按照人类自然语言的指令进行自主导航的技术成为近年来机器人研究的核心之一,该技术不仅在工业,农业和军事中得到广泛应用,更在勘探,救援和机器人看护得到很好的应用,因含很高的实用价值,该技术受到世界的普遍关注。
本文主要针对汉语自然语言组块分析的处理方法进行研究,期望能够提高语义组块分析的准确率并对后续语义提取的准确率的提高有所帮助。
2 研究现状
在国外,基于自然语言处理的机器人问路导航方法已有初步研究。Marjorie Skubic[1]等人进行了室内路径自然语言处理的研究,他们首先收集了大量的路径自然语言语料,对语料进行词性标注和深度组块分析处理,最终在组块分析的基础上提取了特定的句法结构。通过参考-方向-目标(reference-direction-target,RDT)模型建立RDT链提取语义信息实现导航任务。
不同语言在空间词汇的语义关系划分上存在巨大差异,中文和英文自然语言处理方法也不同。国内汉语路径自然语言的研究相对较少,张秀龙等人[2] 提出一种基于组块分析的路径自然语言处理的方法。他们在特定的环境下收集了少量语料之后,对语料进行分词、名词实体识别和组块分析等一系列处理,再使用槽体填充的方法实现语义的提取,最后生成导航意向图。但是这种方法使用的语料数量较少,且用于搜集语料的基础环境中已经固定了路径,所以较难客观的评价该研究中所用语料的全面性与普遍性。
本文研究的主要内容为:1)路径自然语言语料库的获取;2)对语料的分词、组块处理。第三章主要阐述路径自然语言语料库的搭建方法及成果,介绍了语料的收集情况及对语料的初步分析处理;第四章主要阐述了对语料的分词、组块处理工作。针对上一章的分析自定义一些组块单元,然后对这些组块标注的准确性进行了实验检验。
3 路径自然语言语料库的建立
本文主要以基于统计的自然语言处理方法对语料进行处理。统计方法的最大特点就是可以摆脱规则的束缚,不需要专门的知识,通过大规模的学习即可获得较好的结果.但是目前没有专门的汉语路径自然语言语料库.张秀龙等的研究所搭建的语料库仅有214句,收集到的语料太少,影响了语料库的一般性。为了解决这个问题,本文搭建了一个大规模的汉语导航语料库。
3.1路径自然语言语料收集环境的建立
为了提供良好的语料收集平台,本文采用了“Webots for Nao”软件来搭建机器人导航的模拟环境。共搭建了10个非结构化的3D环境(包括7个室内环境,3个室外环境)用于语料收集。由于实物模型有限,又考虑到不同的家庭生活习惯不同,室内布局不同,所以将一些常用的家具做位置上的改变以改变室内的整体布局,并针对不同的环境对机器人下达不同的导航任务以确保我们将要获得的语料的全面性与普遍性。例如:
室内环境选取了实际生活中常见的家具等物品模型进行搭建,将机器人置于不同的初始位置,在每个环境下完成不同的任务,力求覆盖各种类型的家居任务来更全面的搜集自然语言;室外环境选取了灌木丛,油桶,垃圾桶,集装箱,石头等障碍物来模拟实际生活中机器人行走可能出现的障碍。
本文没有对机器人的行进路径作规定,其行进路径是自由可变的,可依据使用者的语言习惯及空间习惯而定,从而增加了我们语料的全面性与普遍性。
3.2路径自然语言语料的收集
本文以在校本科生为主体,辅以其他各年龄段的不同职业的社会人士共寻找了100位志愿者通过观看10个环境的视频和俯视图选择一条可以完成导航任务的路径并给出路径描述。一共收集到1000条语料。
以下为语料库中比较典型的语料:
1) 机器人向右走到门,进门后沿墙向右走到墙角附近的灯旁。
2) 机器人先向东走,发现卧室的门后向北走进入卧室,继续向北直走到床,找到床上的书。
3) 机器人直走到门,进门左转走到冰箱前。
4) 机器人向后转,沿着墙向左走,进门,沿着墙向右走,找到台灯。
5) 机器人直走至墙,绕过沿途障碍物,左转直行至门,右转穿过门继续前行至桌边。
4 语义组块处理方法
4.1路径自然语言语料的分词及词性标注处理
所谓分词,就是把一个句子按照其中词的含义进行切分[3]。本文使用目前国内分词准确率最高的NLPIR汉语分词系统对收集到的语料进行分词和词性标注处理,其分词精度达98.13%,词性标注精度达94.63%。
例句:机器人向左走到墙,然后直走到墙角,沿墙向右走到门,进门直走到凳子旁。
分词和词性标注结果:机器人/n 向/p 左/f 走/v 到/v 墙/n ,/wd 然后/c 直/d 走/v 到/v 墙角/n ,/wd 沿/p 墙/n 向/p 右/f 走/v 到/v 门/n ,/wd 进/vf 门/n 直/d 走/v 到/v 凳子/n 旁/f 。/wj
但是由于自然语言的随机性与随意性,造成利用该系统进行分词时部分标注出现错误,采用人工方法对所有分词及词性标注结果进行了检查,并将错误部分进行修改以保证后续工作的准确性。
例句:机器人右转直走到门。
NLPIR分词及标注结果:机器人 /n 右转直 /n_new 走 /v 到 /v 门 /n。
其中“右转直 /n_new”明显分词和词性标注出现了错误,修改为:“右 /f 转 /v 直 /d”。
4.2路径自然语言语义组块分析
组块分析是一种浅层句法分析,是词法分析和语义分析中间的桥梁。组块分析不要求得到完整的句法树,且可以减少句法分析准确率不高对语义角色标注结果的影响。
组块识别是一个序列标注的问题,本文选择了一种序列的表示法:IOB2。共有三种符号:B,I,O。这三种符号表示的意义是:
B 当前词是一个组块的开始。
I 当前词在一个组块内部。
O 当前词不在任意一个组块中。
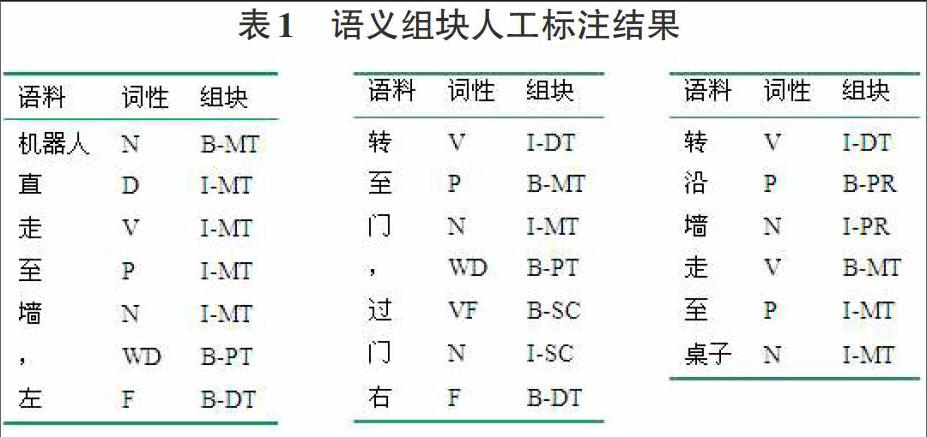
张秀龙等人的研究中采用了语义组块的处理方法进行研究,他们在定义组块时,更多的是从词和词性出发定义了13个组块,且张秀龙等人的研究中涉及名词短语的组块误判率较高,而且有部分组块的识别率为0。为了避免这种情况,本文更多的是从语料本身的意思和其可以实现的功能出发来分析定义组块,从句子语义出发更有利于提取导航语义。经过分析收集到的语料,发现可以将一条复杂的语句根据其语义转化为众多简单的小语义块。通过对所有语料的分析,发现所有语义基本分为转换方向,转换空间,寻找目标,向目标行进四大部分,根据该特点并基于要保证既要覆盖所有语义又不能出现重复的现象的原则,本文定义了9个组块:
1)DT 方向转换,例如“机器人向左转”。
2)SC 空间转换,例如“进门直走”、“穿过门”。
3)MT 无参考向目标行进,例如“走到墙”。
4)FR 根据参考向目标前进,例如“直走到与右侧门平行”。
5)ST 直接寻找目标,例如“找到桌子”。
6)RT 根据参考寻找目标,例如“取茶几上的苹果”。
7)PR 介词参考,例如“沿着墙”。
8)PT 标点符号,例如“,”、“。”。
9)O 不属于任何组块,例如“继续”、“然后”。
基于上述组块进行了人工标注,下面是典型的标注结果:
4.3基于条件随机场的语义组块训练与测试
条件随机场(conditional random fields,简称CRF或CRFS)由Lafferty等人于2001年提出,是近几年自然语言处理领域常用的算法之一,具有表达长距离依赖性和交叠性特征的能力,能够较好地解决标注(分类)偏置等问题的优点。基于此,为了实现语义组块的自动标注,本文选取了CRF算法。
本文将一部分语料作为输入序列对CRF模型进行训练,CRF模型的训练采用 LBFSG方法, CRF++开源工具包实现了LBFSG参数估计办法。CRF将根据训练得到的概率值对测试语料进行自动标注,经过与人工标注的对比得到自动标注的准确率。
将标注好的语料库按照4:1的比例进行分配。80%的语料作为训练语料使用,余下的20%的语料作为测试语料使用。首先进行CRF的训练得到相应的训练模型,表2是使用CRF进行组块分析的输入语料;再用得到的训练模型对测试语料进行测试操作,并得到最后的结果如表3所示。
为了分析自动组块标注方法的性能,定义了以下性能指标:
下表即为使用crf进行组块分析的实验结果。
由表4和表5可见,组块分析的准确率,召回率,F1值都较张秀龙等人的研究结果有显著提高,虽然与张秀龙等人的组块划分方法不同,但能够说明本文划分的组块类型是合理的,基于CRF的自动组块标注方法是可行的。较高的组块标注准确率为下一步的语义角色标注打下了基础。
5 结论
本文主要研究了处理汉语路径自然语言的组块分析方法,为抽取导航语义进而完成导航工作奠定了基础。为了最终实现基于路径自然语言的机器人导航系统,本文首先为了获取大规模语料库利用“Webots for NAO”搭建了10个非结构化的3D模拟环境,针对每个环境提出了不同的导航任务,并基于此收集到了1000条非受限路径自然语言语料,搭建了导航语料库;在经过对语料进行分词与词性标注处理后,基于对语料的语义分析,定义了9种基本组块;经过人工标注和CRF训练之后,测试结果显示组块标注准确性有了较大的提高。实验结果表明本文定义的组块类型以及采用的组块标注方法具有较高的可行性,为接下来的导航语义提取奠定了良好的基础。
参考文献:
[1] Zhiyu Huo,Tatiana Alexenko,Marjorie Skubic. Using Spatial Language to Drive a Robot for an Indoor Environment Fetch Task[C]// 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS2014) September 14-18,Chicago,IL,USA,2014.
[2] 张秀龙. 一种面向室内智能机器人导航的路径自然语言处理方法[J]. 自动化学报,2014(2):1-51.
[3] 吴靓.基于自然语言理解的3D场景构造研究[D]. 汕头:汕头大学,2011.
[4] 蒋文明.面向中文文本的空间方位关系抽取方法研究[D].南京:南京师范大学,2010.
[5] 刘瑜,高勇,林报嘉,等.基于受限汉语的GIS路径重建研究[J].遥感学报,2004,8(4):323-330
[6] 张雪英,闾国年.自然语言空间关系及其在GIS中的应用研究[J]. 地球信息科学,2007(6):77-81.
[7] 张雪英,闾国年.自然语言空间关系及其在GIS中的应用研究[J]. 地球信息科学,2007(6):77-81.
[8] Kollar T,Tellex S,Roy. A Discriminative Model for understanding Natural Language Route Directions[C]//Proc.AAAI Fall Symposium on Dialog with Robots.Arlington.VA,USA:2010:147-152.
[9] Uchimoto K, Ma Q, Murata M, et al. Named Entity Extraction Based on A Maximum Entropy Model and Transformation Rules[C]//Proceedings of the 38th Annual Meeting of the Association for Computational Linguistics, HongKong, China.2000.
猜你喜欢
计算技术与自动化(2017年3期)2017-10-26
魅力中国(2017年24期)2017-09-15
计算机应用(2016年12期)2017-01-13
求知导刊(2016年10期)2016-05-01
