
基于堆栈集成学习的文档隐含语义相似度判断算法
2024-02-27 12:16杜洁梁国迪
电子设计工程 2024年3期
杜洁,李 芹,潘 媛,梁国迪
(云南电网有限责任公司信息中心,云南昆明 650214)
计算机处理技术的进步推动了自然语言的数字化发展,使得数字化自然语言在计算机运算中逐渐占据主导地位。由于网络数据的增加,文档信息的数量也随之增加。将一份新档案归入现有档案是一种有效的节约网络空间的方式,这其中就涉及到文档相似度的对比。
当前,文献间的相似性比较已有许多理论研究,蒋楚[1]等人提出了一种基于表达式树的gadget 语义分析算法,利用表达式树的变体形式描述其表达式信息,提高gadget 工具语义分析的效率,并设计能对多种gadget 工具的分析效率和效能进行判断的gadgetAnalysis 算法。该算法能够较好地衡量gadget工具的语义分析效率和效能,实现较好的语义分析效果,但是该算法在判断语义相似度方面的精准度仍有待提高。石彩霞[2]等人提出了一种多重检验加权融合的短文本相似度算法,使用三种方法分别计算短文本的相似度,对满足已设定的多重检验标准的短文本加权融合,再计算短文本的相似度。该算法在计算短文本相似度方面的准确率有所提高,但仍难以满足对语义相似度判断的需要。为了解决上述问题,提出了基于堆栈集成学习的文档隐含语义相似度判断算法。
1 构建隐含语义识别的堆栈集成学习模型
1.1 构建堆栈集成学习模型
堆栈集成学习是一种元学习方式,其主要思路是利用基础学习器生成问题数据,再利用元学习器的学习程序来处理。基于该原理构建堆栈集成学习模型,如图1 所示。
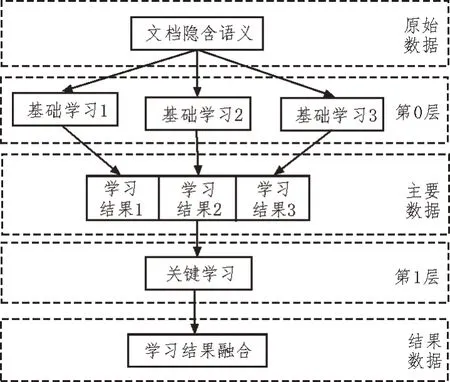
图1 堆栈集成学习模型
图1 中,第0 层表示基础学习层,第1 层表示元学习层。元学习层是在堆栈集成学习层之上进行学习的一种行为,在整个堆栈集成过程中,确定了定义组合规则,经过模型训练,融合学习结果[3-4]。
通常情况下,堆栈集成学习是一个简单的学习过程,能够有效避免过度拟合。
1.2 隐含语义识别
在堆栈集成学习模型中,输入文档隐含语义进行识别,步骤如下:
步骤1:对原始文档库进行预处理,获取与原文一一对应的词袋矢量[5];
步骤2:通过对输入文本的词袋矢量与初始语料库矢量之间的关系进行分析,得出与输入语料库相似度最高的原始文本[6];
步骤3:通过对原始文本中的虚词进行筛选,把虚词的赋值设为0,在虚词赋值之后,将名词赋值为1;取得与名词相匹配的动词,并把该动词分配到一个文本矩阵内,可表示为式(1):
式中,N表示动词与名词之间存在的单词数量。
步骤4:取得符合名词的副词,把它和名词再配成一个新的词组,把新的词组赋值为1,但是保持原有的名词,对原有的名词进行重新赋值,该过程可表示为式(2):
式中,m表示新词组与原始名词词组出现频率之比。
步骤5:获取与名词相匹配的形容词,并指定一个形容词赋值,可表示为式(3):
式中,p表示形容词赋值成名词的频率。
步骤6:以名词为基础,其他词性名词为基础进行赋值,充分考虑各个关键词性特点获取单个关键词的赋值[7]。需要注意的是,赋值并不只是用来表示关键词的重要程度,其还可以用来区别不同的关键词。在考虑到关键词出现的频次后,经过阈值筛选,筛选的单词会极大地影响到文档隐含语义[8-10]。借助于一个辅助词库矢量,能够在基础文本中发现类似于输入文本的文件[11],可以得到更好的识别结果。
2 基于堆栈集成学习的隐含语义相似度判断
2.1 文档隐含语义向量模型构建
通过在堆栈集成学习模型上识别隐含语义,根据阈值筛选结果获取与输入文本类似的文档,构建文档隐含语义向量模型,保证文档隐含的关键词能够描述具有语义的关键词,并将其转换为向量形式[12-13]。文档隐含语义向量模型构建,具体如图2 所示。
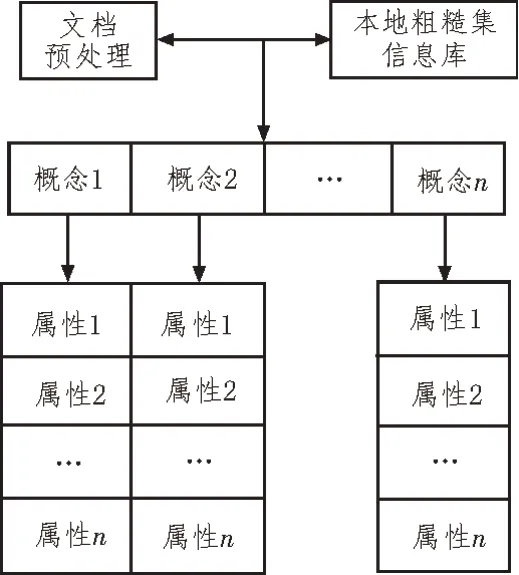
图2 文档隐含语义向量模型
图2 中,从文件中抽取出能够表达其主题内容的基本概念和特征[14]。在建立文件的语义矢量时,首先要对已处理过的文件进行预处理;其次,对文档中的概念词语进行抽取;最后,利用基于本体粗糙集的知识,从实例中抽取出与之相关的特征,从而构造出一个含有概念词语和属性描述的文件语义矢量[15]。
对于文档隐含语义向量的提取,首先确定文档抽取概念词O=(O1,O2,…,On),这组词在领域本体中的属性可表示为D1,D2,…,Dn,其中n表示领域本体属性个数。为了提取文档隐含语义向量属性,需在确保本体中包含所有实例的前提下,依次提取相关属性,由此形成一个属性集,以此类推,能够获取文档全部隐含语义向量。
2.2 基于文档隐含语义索引关键词提取
为方便检索,每一个文档都有一个语义矢量索引。首先,把从文档中抽取的关键词归类到索引文件中,按照一定的次序进行分类,并在此基础上创建一个指针来表示这个概念。每一种概念都有一个语义矢量,将相同的关键词向量聚类为一簇,而文本的语义特征矢量则指向相应的文件[16]。
为方便提取关键词,将文本划分为以标点为边界的小字符串,用最大公共字符串和传统分词的关键词抽取方法,使关键词尽量完整,过滤与标准要求不一致的关键词。
使用信息增益法提取关键词,从文档中直接提取相关信息,再将这些信息与标准信息对比,获取的信息熵之差就是信息增益。信息增益评估函数定义为式(4):
式中,n(tk)、n(hi)分别表示不同类的特征文档的数量;p(hi∣tk)表示特征hi中出现特征tk的文档概率,由此实现基于文档隐含语义索引关键词。
2.3 相似度判断
对于提取的文档隐含语义索引关键词,使用堆栈集成学习方法对关键词进行训练,由此产生的元数据经过反复堆叠后,产生一个完整的训练数据集和元数据。
根据训练结果,令文档f1与f2的属性集为E1、E2,设α是E1的导出路径,β是E2的导出路径,是通过α从文档f1中导出的一段文本,是通过β从文档f2中导出的一段文本,两个文本的相似度为:
式中,Lα,β表示路径α与β间最长的共同子路径长度;ω表示相似度的权重系数。
根据式(6)计算结果可知,向量融合了隐含语音基本结构和内容特征,同时也反应了文档中相似的部分。根据该计算结果,可体现出语义相似度判断结果。
3 实验
3.1 实验数据
为了验证基于堆栈集成学习的文档隐含语义相似度判断算法的准确性,选择某省电力企业数据库中的文档集作为实验对象,原始文本如图3 所示。

图3 原始文本
原始的文本都属于电力工单,提取其中的关键词,结果如图4 所示。

图4 关键词提取结果
由图4 可获取全部关键词提取结果,以此为研究对象进行实验验证分析。
3.2 实验指标
用关键词个体提取结果准确率和召回率作为评价标准,可表示为式(7)、(8):
式(7)和(8)中,fA表示语义相似度计算结果大于零且判断为同一属性的同类文档;fB表示语义相似度计算结果大于零且判断为不同属性的同类文档;fC表示语义相似度计算结果等于零且判断为同一属性的同类文档。计算结果越大,相似度判断结果越精准。
3.3 实验结果与分析
以图4 所示关键词为研究对象,分别使用基于表达式树的方法、基于多重检验加权融合方法和堆栈集成学习算法,对比分析关键词个数提取结果,如表1 所示。
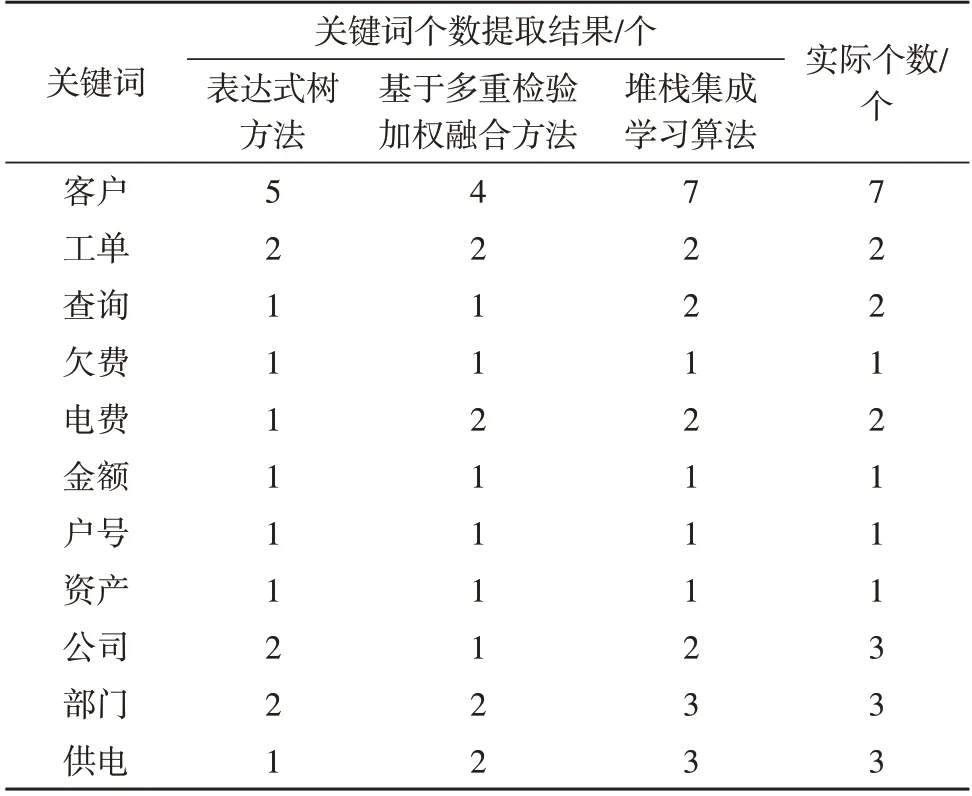
表1 三种方法关键词个数提取结果对比
由表1 可知,应用基于表达式树的方法后,关键词个数提取结果与实际个数最大误差为两个;应用基于多重检验加权融合方法后,关键词个数提取结果与实际个数最大误差为三个;应用堆栈集成学习算后,关键词个数提取结果与实际个数最大误差为一个。通过上述分析结果可知,应用堆栈集成学习算法后,关键词个数提取结果与实际个数基本一致,说明使用该方法语义相似度判断结果更精准。
三种方法的召回率对比分析结果如图5 所示。
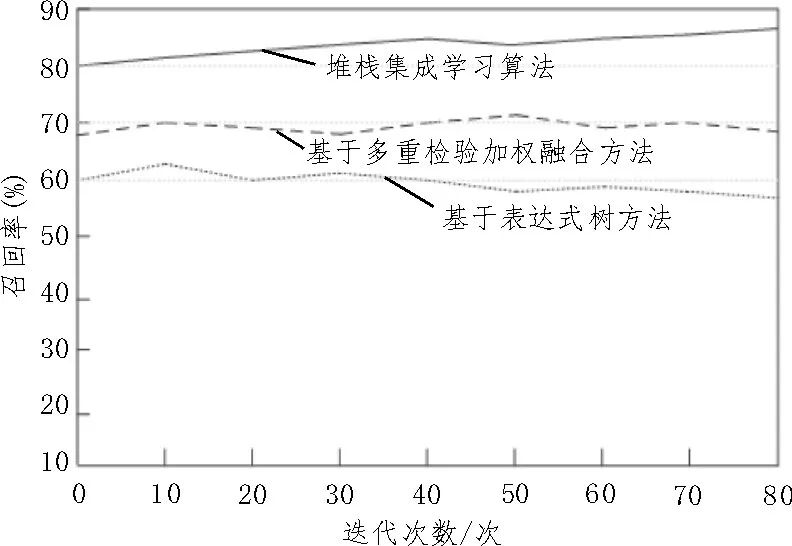
图5 三种方法召回率对比分析
由图5 可知,基于表达式树方法的最高召回率为64%,最低为58%;基于多重检验加权融合方法的最高召回率为72%,最低为68%;基于堆栈集成学习的相似度判断算法的最高召回率为86%,最低为80%。由此可知,应用基于堆栈集成学习的相似度判断算法召回率较高。
4 结束语
基于堆栈集成学习的文档隐含语义相似度判断算法考虑了文档隐含语义的结构特点和文档内容特性,对文档隐含语义的相似性展开具体分析。该算法可以更好地支持多源、异构信息集成和个性化信息服务。
猜你喜欢
榆林学院学报(2022年4期)2022-08-02
小学生学习指导(低年级)(2021年9期)2021-10-14
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
计算机与生活(2018年8期)2018-08-15
单片机与嵌入式系统应用(2018年2期)2018-03-01
军事运筹与系统工程(2017年1期)2017-07-31
理科考试研究·高中(2016年9期)2016-05-14
绍兴文理学院学报(自然科学版)(2013年2期)2013-12-19
