
融合非临近跳连与多尺度残差结构的小目标车辆检测
2023-12-23 10:14张浩董锴龙高尚兵刘斌华奇凡张格
中国图象图形学报 2023年12期
张浩,董锴龙,高尚兵,刘斌,华奇凡,张格
1.淮阴工学院交通工程学院,淮安 223003;2.淮阴工学院计算机与软件工程学院,淮安 223003
0 引言
车辆检测是一项在复杂场景下对实时变化的目标进行分类和定位的计算机视觉任务,实现方法包括多步骤的传统检测方法和端到端的深度学习检测方法。传统检测方法需要人工手动设计目标特征,通过繁琐的滑动窗口策略由传统分类器对结果进行输出(Dalal 和Triggs,2005)。不仅识别率低,而且相当耗时,不能满足车辆检测准确率和实时性的需求(Azevedo 等,2014;Niknejad 等,2012)。而深度学习的检测方法由深度网络自动学习目标特征,通过候选框或直接回归得到结果,既准确又省时,包括两阶段的检测器,如R-CNN(regions with convolutional neural network)、SPP-Net(spatial pyramid pooling network)、Fast R-CNN、Faster R-CNN(Girshick 等,2014;He 等,2015;Girshick,2015;Lee 等,2016 )和单阶段的检测器,如YOLO(you only look once)、SSD(single shot multibox detector)(Redmon 等,2016;Liu 等,2016)。相较于两阶段的检测器,单阶段的YOLO 算法精度高、收敛快,可直接进行目标的定位和分类,较好地满足了实时性的需求。然而在小目标检测方面依然存在严重的漏检、误检和目标轮廓特征模糊的问题。
针对上述问题,相关研究分析了其主要原因并提出了相应的解决方案:1)由于现有模型缺少一种高效的特征融合策略,不同层次间的信息难以及时交互。为此,Dai 等人(2021)针对小目标检测,取代现有的跨层特征融合操作,设计了一种非对称的上下文调制模块(asymmetric contextual module,ACM),通过一个自下而上的调控途径集成上下文信息,以交换高级语义和微妙的低级细节。为了丰富深层次小目标信息,Li 等人(2023)提出了一种密集嵌套注意网络(dense nested attention network,DNA-Net),通过密集嵌套互动模块以实现高层和低层特征之间的渐进式互动,结合级联通道和空间注意模块以增强多层次特征。该方法在不同尺度、形态和信噪比条件下,使检测精度取得了显著的提升。戴坤等人(2022)提出一种融合策略优选和双注意力机制的单阶段目标检测算法FDA-SSD(fusion double attention single shot multibox detector)。结合特征金字塔(feature pyramid network,FPN)确定最优的多层特征图组合及融合过程,之后连接双注意力模块,通过对各个通道和空间特征的权重再分配,提升模型对通道特征和空间信息的敏感性,最终产生包含丰富语义信息和凸显重要特征的特征图组。2)遮挡、光照和远距离等场景严重影响了模型对图像特征的提取。为强化模型对车辆轮廓信息的利用,杜文汉等人(2022)提出一种基于改进Canny 算子的运动目标边缘提取方法,通过提取当前帧运动目标边缘,以解决因边缘细节缺失而漏识别的问题。Zhang 等人(2020)和Li 等人(2021)分别提出了一种基于区域注意力的三头网络和一种双注意融合模块,通过增加对小目标车辆边缘信息的关注,提高复杂环境下模型对小物体识别的敏感性。3)由于下采样会导致图像特征的丢失,影响检测结果,Cheng 等人(2021)采用一种图像双重切割方法,将分割后图像的上层语义与下层位置信息进行融合来减少特征值的丢失。王红霞等人(2023)提出一种融合跨阶段连接与倒残差的目标检测方法NAS-FPNLite(neural architecture search-feature pyramid networks lite)。通过将不同特征层之间逐元素相加的特征融合方式替换为通道叠加的方式,使得进行深度可分离卷积时保持更高的通道数,并将输入的特征层与最终的输出层做跳跃连接,进行充分特征融合,减少特征丢失。此外,研究发现,先验框尺寸的大小和数量以及小目标物体在特征图和原图上感受野尺寸的无法对应也是导致漏检率和误检率高的重要原因(Luo 等,2022;Zhang等,2022;曹家乐 等,2022)。
基于以上,本文通过研究航拍场景下小目标车辆的视觉特征,提出一种融合非临近跳连与多尺度残差结构的小目标车辆检测算法。主要贡献如下:1)针对航拍场景下目标车辆微小,YOLOv5s 算法漏检严重的问题,设计4 种不同尺度的检测层,根据自身感受野大小,使每个网格单元对应到原图上的感受野更小,专门用于微小目标的检测。2)构建一种非临近跳连特征金字塔结构(non-adjacent hop network,NHN),通过并行策略促进网络深浅层的特征融合,完成相邻层次的特征提取,使用跳连相加策略强化非临近层次间的信息交互,减少特征丢失。3)引入反卷积和并行策略,在减少特征丢失的前提下,通过参数学习和突破每一维度下信息量的方式,扩充小目标车辆的细节信息,提高检测器的鲁棒性。4)设计一种多尺度残差边缘轮廓特征提取策略(multi-scale residual edge contour feature extraction strategy,MREFE),构建多尺度残差结构,采用双分支并行的方法捕获不同层级的多尺度信息,通过多尺度下的高语义信息与初始浅层信息的逐像素作差,实现图像边缘特征提取,降低极端环境(光照、雨、雪)对模型检测精度的影响。5)采用K-Means++聚类算法生成与数据集相匹配的先验框,提升检测精度。最后,通过在十字路口、沿途车道两个典型应用场景的实验验证,并与目标检测领域的几种主流算法进行对比分析。
实验结果表明,本文算法的综合性能最优,单位时间图像检测数量FPS(frames per second)为90.1帧/s,平均精度均值(mean average precision,mAP)为84.2%,在满足实时性的前提下,能够较好地平衡检测速度与精度。
1 数据采集与预处理
1.1 实验数据的采集
将不同场景下的航拍视频作为数据来源,分别以垂直和倾斜角45°的方式对十字路口和沿途车道进行拍摄,视频分辨率为1 080 p,待检测车辆的绝对像素均值约为30 × 15,符合MS COCO(Microsoft common objects in context)数据集对小目标的定义(Lin等,2014),如图1所示。

图1 部分数据样本Fig.1 Selected data samples
1.2 数据的预处理
为实现样本数据的多元化,对不同场景、不同环境和不同密集程度的车辆视频进行筛选和取帧处理。每30帧取1幅图像作为样本,共记1 900幅。使用开源软件对其标注,并按8∶1∶1 的比例设置训练集、验证集和测试集。将小型矫车和公交车、油罐车等大型车辆分别定义为vehicle 和bigvehicle,对于目标遮挡超过90%或目标像素小于8 × 8时进行舍弃,不做标注。
2 NHN-YOLOv5s-MREFE模型设计
2.1 网络架构
作为一种先进的单级检测器,YOLOv5s在速度、灵活性和模型的部署上具有极强的优势。这意味着它可以很容易地被嵌入到终端设备上,非常适合航拍场景下的实时小目标车辆检测。本文在YOLOv5s的基础上,提出了一种融合非临近跳连与多尺度残差结构的小目标车辆检测算法,其网络结构如图2所示。

图2 NHN-YOLOv5-MREFE网络结构图Fig.2 NHN-YOLOv5-MREFE network structure diagram
输入端以随机缩放、随机裁剪和随机排布的方式对输入图像进行数据增强。骨干网络C3 模块通过深浅层融合提取目标特征。SPPF(spatial pyramid pooling fast)模块通过对多个MaxPool 进行串联,增大网络感受野。在颈部网络,反卷积和并行策略分别通过增大图像分辨率和增加特征图维度的方式提升检测精度。
此外,并行策略通过共享卷积核有效解决了随着网络层数加深而导致参数量过大的问题,满足了实时性的需求。非临近跳连的特征金字塔结构(NHN)强化了模型对不同尺度物体的检测能力。多尺度残差边缘轮廓特征提取策略(MREFE),通过多尺度下的高语义信息与初始浅层信息的逐像素作差实现图像边缘特征提取,进而辅助网络模型完成目标分类。预测端则通过增加检测层来解决YOLOv5s 的漏检问题并负责输出类别概率、置信度和边界框坐标。
2.2 密集小目标检测层
YOLOv5s 通过3 个不同尺度的检测层可以针对性地预测大、中、小目标,但由于航拍场景下的车辆更加微小,YOLOv5s 漏检问题严重,已不能满足检测需求。因此,有必要增加一个检测层来负责微小车辆的检测。在NHN-YOLOv5s-MREFE 模型中,640 × 640 像素的输入图像分别经过4 倍、8 倍、16 倍和32 倍的下采样,生成了4 种不同尺度的特征图。Anchor 尺寸也随着下采样倍数的增大而增大,个数由原来的9 个增加到12 个,如图3所示。

图3 多尺度检测结构图Fig.3 Multi-scale detection structure diagram
在前向推断的过程中,4 个检测层分别输出对应的预测信息,包括预测框的中心点坐标(x,y)、宽度w、高度h和置信度参数c,通过与标签信息进行比对,计算预测值与真实值之间的损失,进而指导反向传播中参数的调整,从而在反复训练的过程中优化模型性能,其中整个损失包括3 个部分,具体为
式中,定位损失Lossciou用来计算预测框与标定框之间的误差;分类损失Losscls用来判断锚框与标定框的分类是否正确;Lossobj用来计算网络置信度损失。
2.3 非临近跳连的特征金字塔结构
多尺度的目标检测一直以来都是计算机视觉任务的一个难点,针对被测物体尺寸相差过大会导致模型精度下降的问题,特征金字塔网络(feature pyramid networks,FPN)(Lin 等,2017)及其改进方法PANet(path aggregation network)(Liu 等,2018)通过多尺度的拼接融合,使浅层的语义信息和深层的位置信息得到强化,进而提升模型性能。YOLOv5s 采用路径聚合网络构建的特征金字塔结构,虽然提升了模型的检测精度和推理速度,但由于受到拼接融合的影响,在信息传递的过程中(如图4(c)所示)浅层的位置信息会被逐渐稀释,导致预测结果的位置出现偏差。同时,顺序集成特征的方式更加注重相邻层次的特征提取,忽略了与其他层次的信息交互,容易造成目标的误识别。

图4 非临近跳连网络结构图Fig.4 Non-adjacent hop network structure diagram
借 鉴DenseNet(dense convolutional network)(Huang 等,2017)密集跳连的思想,本文构建了一个全新的非临近跳连特征金字塔网络结构NHN,用于对航拍场景下的小目标车辆进行实时检测,如图4所示。基于卷积神经网络固有的金字塔结构(如图4 中的路径(a)所示),通过并行策略分别构建了一条自顶向下(如图4 中的路径(b)所示)和一条自左向右的传播路径(如图4 中的路径(c)所示),使深层的语义信息向浅层传递,浅层的位置信息向深层融合。此外,跳连相加策略(如图4 红线部分所示)在强化各层次信息交互的同时融合了更多未被影响的原始信息,解决了位置信息在传递过程中被逐渐稀释的问题,有效降低了模型的误检率。
图4 路径(a)对应模型结构的骨干网路,由5 个阶段组成,每个阶段都是一种组合操作且具有相同的尺寸,如阶段1 为Conv+BN+SiLU,阶段2 为Conv+BN+SiLU+CSP1_1。不同阶段之间采用2 倍的下采样进行缩放,并将具有最强特征的最后一层作为该阶段的输出。最后使用1 × 1 的卷积运算对阶段5 的通道数进行控制,并在横向相加的协助下构建路径(b)。
在图4 路径(b)中,借鉴FPN 和PANet 的思想,NHN 网络在各阶段之间使用反卷积的方式重塑特征图尺寸,相比上采样的插值算法,反卷积不仅实现了像素的填充,还增加了参数学习的过程,在增大特征图分辨率的同时,还原了更多的小目标信息,如图5所示。并且每个阶段的输出都会与图4路径(a)中对应的特征进行横向相加,强化了语义信息在浅层的表达能力,但由于多尺度的目标检测需要在每个阶段分别进行预测,因此,通过对底层阶段进行1 × 1 卷积并结合下采样和横向相加构建了一条图4路径(c)去强化深层的位置信息。
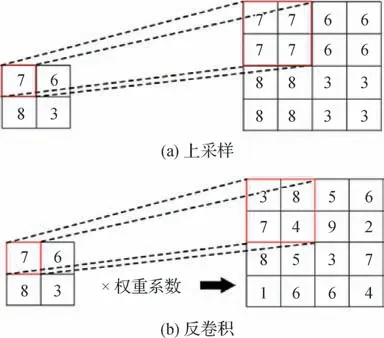
图5 上采样和反卷积的结构图Fig.5 Up-sampling and deconvolution structure diagram((a)up-sampling;(b)deconvolution)
通过特征层的横向相加,增加了特征图每一维度下的信息量,相比Concat拼接融合,并行策略改变了特征图增加维度的固有形式,更加专注于每一维度下信息量的突破,如图6所示。

图6 并行策略和Concat的结构图Fig.6 Parallel strategy and Concat structure diagram
同时,由于对应通道的特征图语义类似,并行策略使其共享一个卷积核,使参数量大大减少。如果只考虑单个通道输出,设两路输入的通道分别为A1,A2,…,Ac和B1,B2,…,Bc,具体为
式中,fConcat为拼接融合策略,fadd为并行策略,c为通道数,Ai和Bi分别为两个输入通道,Ki为对应通道的卷积核。
此外,在图4 路径(c)中,NHN 网络除了与相邻层次进行横向相加,在输出端还增加了与图4 路径(a)的跳连相加,使各层次的特征信息在空间维度上进行融合,实现特征重用,保证了每个阶段兼具语义和位置信息。
2.4 多尺度残差边缘轮廓特征提取
对车辆轮廓信息提取的好坏是取得优异结果的关键,尤其是存在遮挡或极端环境(光照、雨、雪)情况下。同时,由于边缘轮廓信息主要存在于目标与目标、目标与背景间,因此,现有算法大多采用Sobel算子或Canny 算子逐个检测像素邻域并通过灰度变换进行量化来判定边缘位置。该方法虽然可以有效定位、完成特征提取,但在算法复杂度和模型推理速度上有所欠缺。
考虑算法的实时性并结合强化特征提取的目的,本文提出一种多尺度残差边缘轮廓特征提取策略(MREFE),与传统灰度变换和控制阈值的方式不同,MREFE 策略遵循特征逐渐细化的原则,融合并行策略,构建了一种多尺度残差结构,主要通过多尺度下的高语义信息与初始浅层信息的差异实现图像边缘特征提取,如图7所示。

图7 多尺度残差边缘轮廓特征提取Fig.7 Multi-scale residual edge contour feature extraction
经过非临近跳连特征金字塔网络NHN 强化的特征图Fi,j具有丰富的细节信息,而骨干网络由于对车辆轮廓信息的低敏感度,使特征图Xi,j保留了更多除边缘信息以外的特征。因此,MREFE 采用双分支并行的方法捕获不同层级的多尺度信息,通过Fi,j与Xi,j逐像素作差,达到提取车辆边缘特征的目的。进而辅助NHN-YOLOv5s-MREFE 模型实现目标分类,提升模型的检测精度,降低漏检率和误检率。具体步骤如下:
1)通过2D 卷积、反卷积对NHN 输出的特征图Fi,j的尺寸和通道数进行调整;
2)对多尺度下的高语义信息与初始浅层信息作差,完成车辆轮廓信息的提取,具体为
式中,Ei,j表示提取到的边缘轮廓信息;Fi,j表示通过执行步骤1)得到的高语义信息特征图,其尺寸和通道数与Xi,j相同;Xi,j表示特征提取阶段由主干网络输出的特征图;W、H分别表示特征图所对应的网格单元(grid cell)。
3)将边缘轮廓信息Ei,j与丰富的高语义信息Fi,j进行多尺度特征的相加融合,使车辆轮廓更加明晰,具体为
式中,Outi,j表示边缘轮廓信息Ei,j与特征图Fi,j相加融合之后的输出。
4)分别由SiLU 函数和1 × 1的卷积对Outi,j完成激活操作和特征压缩后,输出结果。
2.5 K-Means++聚类算法
选取合适的先验框,能够加快模型收敛,提升检测速度和精度。然而,随着场景的变化和检测层的增加,基于MS COCO 数据集确定的Anchor个数和尺寸已不能满足检测需要。但YOLOv5s 仍采用与YOLOv2 相同的K-Means 算法随机初始化聚类中心,导致初始值过于集中,进而出现了局部最优解。为此,NHN-YOLOv5s-MREFE 模型采用K-Means++聚类算法尽可能使聚类中心更加分散,生成了12 组不同宽高比的Anchor,促使结果达到全局最优,如表1 所示。结果表明,相比于原始尺寸[5,6,8,14,15,11]、[10,13,16,30,33,23]、[30,61,62,45,59,119]、[116,90,156,198,373,326],重新聚类后的结果更为集中,宽高比更加符合小目标车辆数据集的分布特点。

表1 K-Means++聚类结果Table 1 K-Means++clustering results
3 实验结果分析
3.1 实验环境及实施细节
为验证NHN-YOLOv5s-MREFE 模型的有效性,以YOLOv5s-6.0 版本作为基础框架设计消融实验,并与目标检测领域常见的几种主流算法进行对比分析,实验硬件环境如表2所示。

表2 实验环境配置Table 2 Experimental environment configuration
在NHN-YOLOv5s-MREFE 模型的训练和测试阶段,输入图像被缩放到640 × 640 像素,并由主干网络(CSPDarkNet-53)完成图像特征的提取,然后输出的特征图送入非临近跳连特征金字塔网络(NHN),用于强化各层之间的信息交互,并结合多尺度残差边缘轮廓特征提取策略(MREFE),提升模型性能,最终得到4 种不同尺度的特征图(20 × 20、40 × 40、80 × 80 和160 × 160)。因为数据集中均为小目标车辆,存在大量的标签信息,直接训练即可达到理想的效果,且由于模型结构的改变,官方发布的预训练权重将不再适用于本模型。
为了实验的科学性,在消融实验和对比实验中均不加载预训练权重,且经过多次实验,发现迭代400 次为最优,并设置每次输入10 个样本(batch size=10)。为加速模型收敛,使用Adam 优化器替代传统随机梯度下降法对模型参数进行自适应调整,设置初始学习率为0.01,学习率动量为 0.937,权重衰减系数为0.000 5。为促进模型实现全局最优,前10 个epoch 使用warm up 训练预热,训练预热之后采用余弦退火算法再次调整学习率。除此之外,其余均为6.0版本的默认参数。
3.2 实验评估指标
为准确评估NHN-YOLOv5s-MREFE 模型的性能,本文将精确率(precision,P)、召回率(recall,R)、平均精度(average precision,AP)、平均精度均值(mean average precision,mAP)、单位时间图像检测数量(frames per second,FPS)和模型参数量(Params)作为评估指标,设置交并比(intersection over union,IoU)为0.5,当预测框和真实框的交并比大于等于0.5时,则认为成功预测到目标位置。
3.3 实验对比分析
为验证NHN-YOLOv5s-MREFE 模型所提及的NHN、反卷积、并行策略、MREFE 和K-Means++聚类算法是否有利于提升航拍场景下小目标车辆的检测精度,设计消融实验对网络模型进行客观评价,并结合实验结果进行分析。
表3 所示为NHN-YOLOv5s-MREFE 的消融实验结果,展示了以YOLOv5s 为基准和施加不同策略的组合模型迭代400 次的准确率、召回率和mAP 值。表3 中,NHN 为非临近跳连特征金字塔网络,MREFE 为多尺度残差边缘轮廓特征提取策略。可以看出,引入各改进策略后的模型7,即本文提出的NHN-YOLOv5s-MREFE 模型性能提升最为显著,与模型1(YOLOv5s)相比,精确率(P)、召回率(R)和平均精度均值(mAP)分别提升13.7%、1.6%和8.1%,验证了本文算法在航拍场景下对小目标车辆识别的有效性。
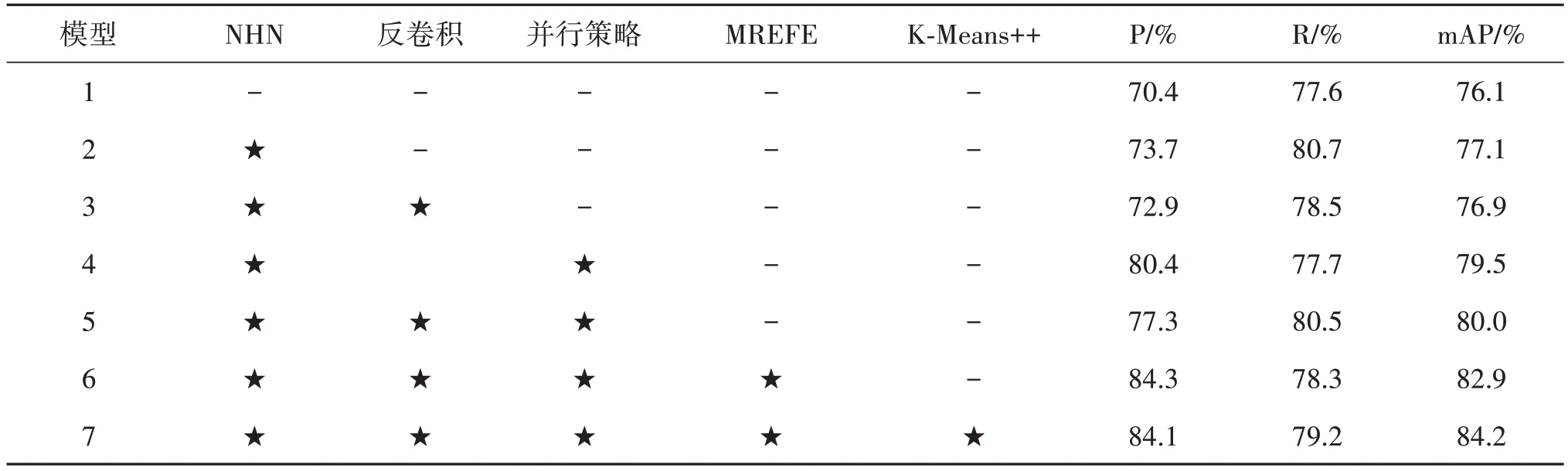
表3 NHN-YOLOv5s-MREFE消融实验Table 3 NHN-YOLOv5s-MREFE ablation experiment
从表3 可知,NHN(非临近跳连特征金字塔网络)的施加对模型1(基准模型)性能的提升具有积极的影响。通过NHN 的跳连相加,强化了模型对深层语义与浅层位置信息的融合能力,使非临近层次的特征在空间维度上实现重用,有效解决了因特征的低效融合而导致的预测框位置偏差问题,与模型1(YOLOv5s)相比,NHN 的精确率(P)提升3.3%。并且在NHN 结构中,预测端微小目标检测层的增加,实现了感受野与原图小尺寸目标的对应,使模型的召回率(R)提升3.1%,减少了微小车辆的漏检问题。但由于复杂的场景信息和较少的成像像素,为模型后续的特征提取带来了极大的困难。为此,本文在模型3 和模型4 中分别施加反卷积和并行策略。
消融数据表明,相较于模型2(NHN),模型3(反卷积)的各指标均有所下降,模型4(并行策略)以牺牲3%的召回率,换回了精确度6.7%的提升。而同时引入反卷积和并行策略的模型5,在确保召回率基本不变的情况下,使模型精确度提升了3.6%。可见,反卷积通过参数学习虽然可以自适应学出一种最优的上采样方法,但在kernel size无法整除strides 或卷积核权重不均匀的情况下,会使图像产生棋盘效应,且此效应不可根除,严重影响了模型的性能(王建明 等,2021)。而并行策略能显著提升模型的检测精度,通过扩充特征图每一维度下的信息量,一定程度上削弱了棋盘效应的影响。
为了进一步提升模型性能,减弱遮挡或极端环境的影响,本文在模型5(NHN+反卷积+并行策略)的基础上分别施加MREFE 策略(多尺度残差边缘轮廓特征提取策略)和引入K-Means++对标注框重新聚类的数据表明,MREFE 策略通过融合图像轮廓信息,能够大幅提升检测精度,只降低少量召回率。而K-Means++算法可以根据复杂场景信息重新聚类,确定Anchor 的个数和尺寸,加快模型收敛,提升检测速度与精度。
为了进一步验证NHN-YOLOv5s-MREFE 模型性能的优越性,引入单位时间图像检测数量(FPS)和模型参数量(Params)对比检测速度和模型大小,并与目标检测领域常见的几种主流算法进行对比分析,包括单阶段的YOLOv3、YOLOv4、YOLOv5s 和双阶段的Faster R-CNN。对于主干网络的选取,Faster R-CNN 为ResNet-50,YOLOv3 为DarkNet-53,YOLOv4、YOLOv5s 和NHN-YOLOv5s-MREFE 均 以CSPDarkNet-53 作为主干网络。此外,Faster R-CNN的输入图像尺寸最大,为800 × 800 像素。YOLOv3、YOLOv4 和YOLOv5s 的图像尺寸统一缩放为416 ×416 像素和640 × 640 像素,并分别输出了3 个不同尺度的图像特征。
为了对结果进行客观评价,实验在同等配置下使用相同的超参数(与消融实验相同)对模型进行训练,测试结果详见表4。另外,表5 给出了各算法在不同场景下的误检和漏检数据对比。

表4 本文算法与其他主流算法的性能对比Table 4 Performance comparison of this algorithm with other mainstream algorithms

表5 不同模型误检和漏检情况对比Table 5 Comparison of model misdetection and missed detection
图8 给出了各算法在不同场景下的可视化结果对比,第1、2、3 行分别是十字路口(垂直)场景、沿途车道(倾斜)场景和沿途车道(垂直)场景。其中,红色预测框和蓝色预测框分别表示vehicle 和bigvehicle 类别,黄色框和紫色框则代表误检和漏检目标。

图8 不同算法的效果识别图Fig.8 Effect recognition chart of different algorithms((a)Faster R-CNN;(b)YOLOv3;(c)YOLOv4;(d)YOLOv5s;(e)NHN-YOLOv5s-MREFE)
结合对表4 和图8 的分析可知,Faster R-CNN 作为双阶段目标检测的代表算法,对航拍场景下的小目标车辆具有一定的检测能力,相较于单阶段的YOLO 算法,虽然实时性远达不到实际应用的需求,但在多数场景下各类预测框的定位和大小正确且类别判断基本无误。这说明输入端图像分辨率的大小可以影响模型的检测性能,分辨率越大,越有利于图像特征的提取(江泽涛 等,2023)。相比于Faster R-CNN,单阶段的YOLO 算法总体性能得到了大幅优化,各项指标均有一定程度的提升,其中,检测速度提升最为显著,相比与Faster R-CNN,YOLOv3 和YOLOv4 提升了4 倍,YOLOv5s 更是提升了8 倍以上,但漏检和误检的问题严重,无法满足小目标车辆检测环节对准确率的要求。
而本文提出的NHN-YOLOv5s-MREFE 在上述算法中mAP值表现最为优秀,相比于Faster R-CNN、YOLOv3、YOLOv4 和YOLOv5s 分别提升了10.5%、6.4%、22.6%和8.1%,且该算法预测框的大小和位置分布更加准确,对于其他主流算法均存在的漏检和误检问题也表现出更加令人满意的识别效果。从图8 中可以看出,由于拍摄距离较远、目标较小和目标与护栏之间边缘细节特征的不准确,导致其他算法均存在误检(黄色框),如:不能准确判断车辆类型(Faster R-CNN-c、YOLOv3-b-c、YOLOv5s-c),产生一物多框(Faster R-CNN-b、YOLOv3-a、YOLOv5s-a-c)或将护栏判定为车辆(YOLOv4-c、YOLOv5s-a-b),只有NHN-YOLOv5s-MREFE 算法能够准确地检测所有目标,且具有更低的漏检率。
由于非临近跳连特征金字塔网络(NHN)和多尺度残差边缘轮廓特征提取策略(MREFE)会消耗一定的计算时间,相较于YOLOv5s,本文模型检测速度虽有所减慢,但仍是Faster R-CNN 的6 倍,YOLOv3 和YOLOv4 的1.5 倍,可以满足实时性的需求。此外,模型参数量仅为Faster R-CNN 的1/3,YOLOv3 的1/6,YOLOv4 的1/5,易嵌入无人机等小型设备。综合实验结果来看,NHN-YOLOv5s-MREFE 算法可以较好地平衡检测速度与精度,略微降低检测速度,但显著提升了检测精度,并能够满足目标检测的实时性需求,更加适用于航拍场景下的检测任务。
4 结论
针对YOLOv5s 算法在小目标车辆检测中出现的漏检、误检和目标轮廓特征模糊等问题,本文创新性地提出了一种非临近跳连与多尺度残差结构的小目标车辆检测算法。构建非临近跳连特征金字塔结构(NHN)以强化非临近层次的信息交互,引入反卷积、并行策略丰富图像特征,设计多尺度残差边缘轮廓特征提取策略(MREFE)减少复杂环境对检测精度的影响,同时引入K-Means++聚类算法加速模型收敛,共同提升模型的检测性能。使用无人机对十字路口、沿途车道两个典型应用场景进行多角度拍摄获取实验数据,设计消融实验并通过多场景的对比分析,验证本文算法的检测性能。
实验结果表明,NHN-YOLOv5s-MREFE 模型的mAP 值达到84.2%,FPS 保持在90.1 帧/s,在有效减少漏检率和误检率的同时,能够精准快速地检测出形态多变、边缘模糊和尺寸微小的小目标车辆。相较于其他几种主流算法,NHN-YOLOv5s-MREFE 在综合性能上有着较大的优势,可以满足航拍场景下小目标车辆检测的速度和精度需求,在交通流量、密度等参数的测量和统计、车辆定位与跟踪等场景下有较高的应用价值。后续将对轻量化的网络模型进行研究,探求一种模块间的数据共享的方法,在保证网络轻量化的同时提升算法精度和泛化能力,使其能够广泛应用于多场景下的车辆检测任务。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年11期)2019-07-04
小太阳画报(2018年3期)2018-05-14
北京航空航天大学学报(2018年1期)2018-04-20
阅读与作文(小学低年级版)(2016年12期)2016-12-22
太空探索(2016年5期)2016-07-12
汽车文摘(2015年11期)2015-12-02
时代英语·高三(2014年5期)2014-08-26
电视技术(2014年19期)2014-03-11
