
骨骼信息的人体行为识别综述
2023-12-23 10:13卢健李萱峰赵博周健
中国图象图形学报 2023年12期
卢健,李萱峰,赵博,周健
西安工程大学电子信息学院,西安 710600
0 引言
随着视频获取设备的普及和互联网技术的发展,视频数据的规模呈爆炸式增长,为视频理解技术的快速发展提供了丰沃土壤(Turaga 等,2008;Das Dawn 和Shaikh,2016)。人类是社会活动的主体,视频数据更多记录的是人类的行为活动,如何利用海量的视频数据理解人体行为具有重要的研究价值和广泛的应用需求。
行为识别的主要目标是在输入的包含一个或多个行为的数据中,正确地分析出行为的种类。基于骨骼信息的行为识别是一种以骨骼数据为建模对象的方法。骨骼数据通常由一组关键点组成,用于描述人体的姿态和动作,这些关键点对应人体的关节,如头部、肩膀、手肘、手腕、膝盖和脚踝等。此外,骨骼数据可以从高性能姿态估计算法或深度传感器中方便获取。与RGB 数据相比,骨骼信息具有以下优点:1)特征表示明确。骨骼信息能够清晰地表示出人体的结构,且对背景、服饰、光照和视角变化等具有很强的鲁棒性。2)时空信息丰富。在单帧数据内,相邻关节点之间的几何连接意义明确,能够表现出丰富的肢体信息。在相邻帧之间,同一关节点的状态具有很强的继承性,存在丰富的依赖关系。3)数据量小。因其只包含描述人体关节点的坐标信息,轻量简洁,从而减小了研究负担。
基于骨骼信息的行为识别取得了较大的研究进展,但目前相关综述性文章较少。Lo Presti 和La Cascia(2016)的工作作为第1 篇关于3D 骨骼的行为识别综述,重点关注了传统方法,并未涉及深度学习的方法。Ren 等人(2020)虽然对基于深度学习的骨骼行为识别方法进行了综述,但是有关图卷积方法的介绍不够全面,也未对相关数据集进行归纳总结。王帅琛等人(2022)同时关注了多种模态信息的行为识别,分别从骨骼数据、深度数据和RGB 数据进行了综述,但未提及近期流行的Transformer 技术。本文首先探讨了不同数据集的特点和用法;然后,将基于骨骼信息的行为识别方法分为基于手工制作特征的方法、基于循环神经网络(recurrent neural network,RNN)的方法、基于卷积神经网络(convolutional neural network,CNN)的方法、基于图卷积网络(graph convolutional network,GCN)的方法以及基于Transformer的方法,系统地进行了综述,重点介绍了具有里程碑意义的、开创性以及突破性工作;最后讨论了该领域目前存在的研究难点并针对性地提出工作展望。
1 数据集
为了评估行为识别方法的性能,研究者们创建了大量的公开数据集。早期的数据集主要以单视角为主,随着深度学习的兴起,尤其是人机交互方式的更新、无人驾驶技术的发展以及元宇宙概念的兴起等因素促进了研究者们对多视角数据集的研究。与单视角数据集相比,多视角数据集有以下特点:同一种行为在不同视角下所展现的特征是多样的,通过多视角下同一行为对应特征表示的一致性进行信息互补,可以弥补某一视角的观测缺陷,从而学习到更加鲁棒的行为表达。表1 和表2 分别给出了较为常用的两类数据集。
表1 单视角数据集Table 1 Single-view datasets

表2 多视角数据集Table 2 Multi-view datasets
1.1 单视角数据集
MSR Action3D(Microsoft Research Action 3D)数据集(Li 等,2010)是最早的基于深度传感器的单视角行为数据集,该数据集提供深度图像和20 个关节点的三维坐标两种模态信息。该数据集记录了20 种行为类别,每种行为由10 人执行2~3 次,总共567 个行为序列。MSR Action3D 数据集是一组无背景、纯人体运动的数据,适合用于研究基于光流数据的行为识别方法。由于其图像的分辨率较低,因此在超分辨的行为识别领域也具有一定的价值。该数据集的示例如图1(a)所示。

图1 单视角数据集示例图Fig.1 Sample graph of single-view datasets((a)MSR Action3D dataset;(b)MSR Daily Activity 3D dataset;(c)3D Action Pairs dataset;(d)SYSU 3DHOI dataset)
MSR Daily Activity 3D(Microsoft Research Daily Activity 3D)(Wang等,2012)数据集是由Kinect v1深度传感器采集的日常活动数据集,提供RGB 图像、深度图像和20 个关节点的三维坐标3 种模态信息。该数据集记录了16项日常行为,每种行为由10人完成,每个人以站姿、坐姿分别重复2次,总共320个视频序列。MSR Daily Activity 3D 数据集的样本数偏少,在训练时容易导致模型过拟合,不太适用于深度学习算法的验证。但是该数据集是在具有背景物体的真实环境下采集的,涉及人与物的交互,因此该数据集成为用来验证传统行为识别方法性能的标杆性数据集。该数据集的示例图如图1(b)所示。
3D Action Pairs(Oreifej 和Liu,2013)数据集和SYSU 3DHOI(Sun Yat-sen University 3D Human-Object Interaction)(Hu 等,2017)数据集都是具有交互性行为的数据集,两个数据集的示例图如图1(c)(d)所示。前者由Kinect v1 相机采集,提供RGB 图像、深度图像和20 个关节点的三维坐标3 种模态信息,包含了6 对高度相似的行为,例如拿起箱子、放下箱子、戴帽、摘帽,拉椅子、推椅子等,共计360 个序列。后者由Kinect v2 设备采集而来,同样提供3 种模态信息,该数据集包括由40 个人完成的12 种交互行为,共计480 个样本序列。12 种交互行为涉及到6 种操作物体:手机、椅子、书包、钱包、拖把和扫把。3D Action Pairs 数据集的最大特点是其包含的行为都是成对出现的,且行为的执行方向相反,因此该数据集可以用来验证算法对时序信息的挖掘和利用能力。SYSU 3DHOI 数据集的受试者数量多,有较大的类内差异,因此该数据集可以用来验证算法在人物多变情况下的泛化能力。
UTD-MHAD(The University of Texas at Dallas Multimodal Human Action)(Chen 等,2015)数据集由Kinect v1 相机和可穿戴惯性传感器(wearable inertial sensor,WIS)同时采集的,提供RGB图像、深度图像、惯性传感器信号(ID)和25 个关节点的三维坐标4 种模态信息,研究中最常用的是RGB 图像和关节点的坐标。该数据集包含27 种行为,由4 名男性和4 名女性重复执行每种行为4 次,共计861 个样本。该数据集的主要特点是所提供的模态信息丰富,适合用于对多模态信息融合的行为识别方法(姬晓飞等,2019)的相关研究。
1.2 多视角数据集
Northwestern-UCLA(Wang 等,2014)数据集是由美国西北大学和加州大学洛杉矶分校用3 个Kinect v1 相机从3 个不同的视角采集完成的,如图2(a)所示。该数据集由10个志愿者完成,包含10种日常行为,共计1 475 个样本,提供RGB 图像、深度图像和20个关节点的三维坐标3种模态信息。该数据集支持跨人物、跨视角和跨环境3种验证方式,可以评估算法是否对不同人物、不同视角和不同环境等变化因素具备鲁棒性。在跨人物验证方式中,来自9名志愿者的样本作为训练数据,来自另外1名志愿者的样本作为测试数据;在跨视角验证方式中,两个传感器采集的样本作为训练数据,另一个传感器采集的样本作为测试数据;在跨环境验证方式中重点关注模型是否具备在不同环境中识别同种行为的能力。

图2 多视角数据集示例图Fig.2 Sample graph of multi-view datasets((a)Northwestern-UCLA dataset;(b)NTU RGB+D 120 dataset)
Skeleton-Kinetics数据集是以从YouTube视频上搜集的Kinetics 数据集(Kay 等,2017)为基础而制作的,制作过程为:使用OpenPose 人体姿态估计工具(Cao 等,2017)对每一帧图像提取18 个关节点的二维坐标(X,Y)数据并给出置信度得分C。该数据集包含400 个种类行为共计30 万个视频剪辑片段,每个片段的长度大约10 s。由于Kinetics 数据集来源于真实场景,存在大量遮挡、摄像机运动等影响因素,因此该数据集具有较强的挑战性。
在基于骨骼的行为识别领域中,NTU RGB+D 60(NTU-60)(Shahroudy等人,2016)数据集是目前应用最为广泛的大型行为识别数据集之一。该数据集包含通过Microsoft Kinect v2深度传感器在室内场景下采集完成的56 800 个视频样本,其中包含由40 位志愿者完成的60个种类的行为。该数据集提供了4种不同的数据形式:深度图像、RGB 图像、3D 骨骼序列和红外序列。该数据集提供两个验证基准:跨对象(cross-subject,X-Sub)和跨视角(cross-view,XView)。跨对象基准以人物的编号来划分训练集和测试集,有40 320个训练样本和16 560个测试样本。跨视角基准以相机的编号划分训练集和测试集,3 个相机的水平视角设置有所区别,分别为-45°、0°和45°。编号为1 的相机采集到的样本为测试集,2号和3号相机采集到的样本为训练集。
NTU RGB+D 120(NTU-120)(Liu 等,2020a)数据集是对NTU-60 的扩展,包括120 个种类的行为,共计114 480 个视频样本。与NTU-60 不同的是,NTU-120使用跨对象和跨设置号(cross-setup,X-Set)两个基准。其中跨对象基准与NTU-60 相同。设置号是根据相机的高度和距离而规定的,跨设置号基准是将设置号为奇数的样本用于测试、偶数编号的用于训练。该数据集的示例图如图2(b)所示,采集场所均为室内实验环境。
1.3 数据集评估标准
评估标准用于算法之间的性能比较。在行为识别任务中,常见评价标准为Top1和Top5、网络的总参数量和每秒浮点运算次数(floating-point operations per second,FLOPs)等。其中,Top1 为预测得分排名第1 的类别与真实标签相符的情况,Top5 为预测得分排名前5 类别中包含真实标签的情况。一般而言,在Kinetics数据集中,用Top1和Top5准确率进行性能评估,其他数据集都仅采用Top1准确率表示。
2 基于手工制作特征的方法
传统行为识别方法所使用的特征主要是根据研究者的先验知识人工设计的,根据特征设计方式的不同可以分为基于关节点的方法和基于身体部件的方法。
2.1 基于关节点的方法
基于关节点的方法是将人体骨骼结构简单地视为关节点的集合,利用关节点位置特征、关节点相对于坐标轴的角度特征等建模单个关节点或多个关节点组合的运动来表征人体行为。Ziaeefard 和Ebrahimnezhad(2010)利用统计学知识,将行为特征表示为一个直方图,该直方图统计了分别处在CSI(cumulative skeletonized images)的48 个区域上的关节点数量,其制作过程如图3 所示。该方法使用多分类线性支持向量机进行初步预测,再根据显著特征对混淆类别进一步分类。然而这种方法只适用于一些行为区分度较大的数据对象,对相似行为的分类效果不佳。Xia 等人(2012)将直方图的思路扩展到三维空间,将三维关节位置量化为直方图,获得人体骨骼的视图不变性表示,然后使用隐马尔可夫模型(hidden markov model,HMM)进行分类,结果表明三维数据应用于人体行为识别时具备明显的优势。
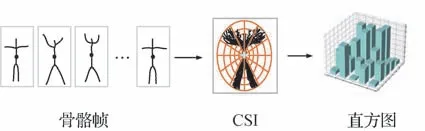
图3 直方图的计算过程(Ziaeefard和Ebrahimnezhad,2010)Fig.3 Histogram calculation process(Ziaeefard and Ebrahimnezhad,2010)
在不考虑关节点之间的相互联系下制作的特征虽然可以表示人体行为,但人体运动时各个关节点是相互关联的,这些关节点之间的依赖关系可能比独立的关节点更能准确地表征人体行为。因此Yang 和Tian(2012,2014)利用不同关节点的组合来表示人体的运动,结合静态特征、运动特征和偏移特征提出一种基于关节点位置差异的方法,并采用朴素贝叶斯最近邻方法进行分类。这种方法能够更好地包容行为的类内变化,具有更强的鲁棒性。
2.2 基于身体部件的方法
基于身体部件的方法是将人体骨骼视为一组连接的刚性段,并利用不同身体部位之间的几何关系进行行为识别。相比于基于关节点的方法,通过该方法制作的特征更能保留人体不同部位之间的几何关系,能够更全面地描述人体骨骼的结构特征。Fujiyoshi 等人(2004)提出一种“星型”骨骼表示方法,用5 个人体的关键节点(左手、右手、左脚、右脚、头)连接成的星状图来表示人体姿态,该方法不需要先验的人体模型,也不需要大量的人体目标像素,计算成本较低,适用于实际应用场景,但识别精度不高。Chen等人(2006)将星型骨骼定义为一个5维特征向量,随后将该特征向量映射为符号序列并与模板进行匹配,匹配度最高的模板类别即为识别结果。然而上述采用“星型”骨骼的方法会受提取到的人体轮廓的影响,此类算法较为依赖强大的人体轮廓提取器。为了建模出身体部位之间的三维几何关系,Vemulapalli 等人(2014)利用旋转和平移操作,将运动的关节点通过李群函数转变成曲线来描述人体的行为,并使用动态时间扭曲、傅里叶时间金字塔和线性支持向量机的组合对行为进行分类。此方法能够在多变的关节轨迹中提取到鲁棒性更强的特征,泛化能力强,普适性强。上述基于身体部件的方法没有考虑来自不同人体的部件之间的几何关系,所以仅适用于单人行为识别的场景,在复杂的多人交互场景下效果不佳。
传统方法的时间效率高,但特征提取规则由人工设计,没有充分挖掘数据中的信息,所提取的特征在维度和数量上较少;并且手工设计特征通常需要大量的领域知识和参数调优工作,过程复杂,易产生过拟合,导致适用范围受限。
3 基于深度学习的方法
在基于深度学习的方法中,模型自动完成行为特征的提取,省去了传统方法中特征工程的繁杂工序。根据所使用的骨干网络不同,基于深度学习的行为识别方法可以进一步分为基于循环神经网络的方法、基于卷积神经网络的方法、基于图卷积网络的方法以及基于Transformer 的方法,表3 展示了这些方法各自的特点。

表3 不同方法的特点比较Table 3 The characteristics of different methods
3.1 基于循环神经网络的方法
基于循环神经网络的人体行为识别方法的一般流程为:首先,使用向量序列表示关节点坐标集合;其次,使用以循环神经网络为主的人体行为识别模型对向量序列进行序列建模;最后获得行为分类得分。
Du等人(2015b)以躯干为基准,将人体分为5个部分,设计了子网络数量分别为5、4、2、1的4层分级融合架构,在充分提取局部特征的同时,保证了全局特征的有效,其网络结构如图4 所示。但该方法在挖掘输入序列的长期时间依赖性方面存在局限性。Shahroudy 等人(2016)延续Du 等人(2015b)划分人体结构的方法,将身体不同部分分别输送到长短时记忆(long short term memory,LSTM)网络的子单元中来建模每个身体部分的长期时间依赖性。该方法保留了独立的不同身体部分的上下文信息,性能得到显著提高。然而,上述两种方法都是利用循环神经网络对骨骼序列的整体时间动态信息进行建模,而没有学习到更加细致的时间表达。
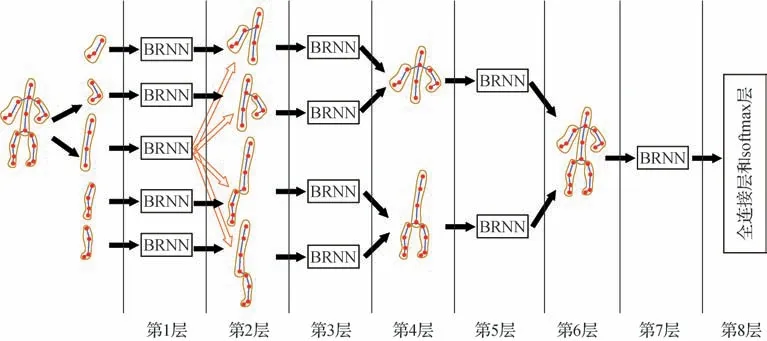
图4 基于骨骼的端到端循环神经网络结构(Du等,2015b)Fig.4 The architecture of end-to-end recurrent neural network for skeleton-based action recognition(Du et al.,2015b)
针对上述问题,Lee 等人(2017)提出了一种集成时域滑动LSTM 网络,该网络不再局限于对运动状态的长期时间依赖关系进行建模,而是通过改变时间步长分别捕获短期、中期、长期的时间依赖性,这有助于对行为进行完整而全面的时间建模,且对变化的时间动态具有鲁棒性。但该方法用到多个LSTM 模块,过于复杂,且没有充分考虑到骨骼数据的空间结构关系。Wang 和Wang(2017)借鉴双流网络的思想,在时间域上通过时间RNN 模块来学习行为的运动特征,在空间域上采用基于邻域关系的遍历方法,按依赖关系的强弱将关节点依次输入到空间RNN 模块中来学习空间特征。这种通过构建双流循环神经网络来学习关节点的时空信息的方法,相比于只注重时序信息的方法在识别准确率上有了大幅度提高。Li 等人(2017)根据CNN 和RNN 具有互补性原则提出并行网络模型,该模型将多种骨骼特征(相对关节点位置、关节点间距离等)作为3 个LSTM 网络和7个CNN网络的输入,识别准确率相比于单应用的CNN或RNN效果都好。
人的行为发生过程中,某些关节点对辨别是无效的,例如吃饭时,膝盖、脚踝等关节并不运动。此外,并不是所有时间段都对辨别该行为有效,例如跳远前的准备过程。鉴于此,Song 等人(2016)采用注意力机制,提出一种端到端的时空注意力模型,时间注意力子网络和空间注意力子网络自动挖掘出关键帧和关键关节点。该模型制定交替的联合训练策略以加速训练过程,并设计正则化交叉熵损失函数来防止模型过拟合。为了更好地、有选择地关注每一时间步上的关键关节点,Liu等人(2017)提出一个全局上下文感知注意力网络(global context-aware attention LSTM,GCA-LSTM)。如图5所示,该网络主要由两层LSTM 构成,第1 层生成全局上下文信息,第2 层使用一种循环注意力机制来迭代提升注意力模型的效果。该方法能对全局上下文信息进行细化,获得更细致的特征表达。
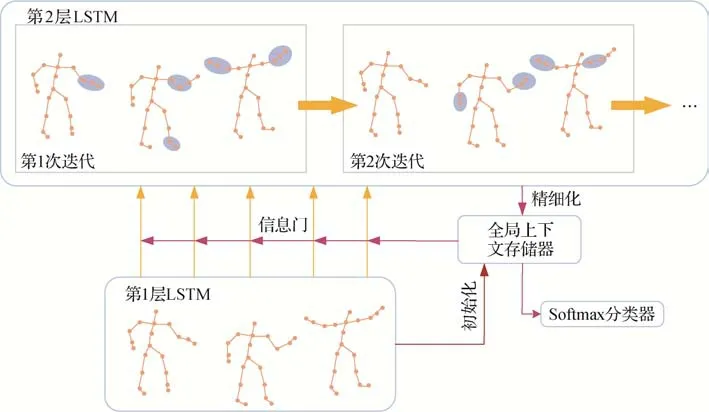
图5 全局上下文感知注意力网络(Liu等,2017)Fig.5 The architecture of GCA-LSTM(Liu et al.,2017)
同一种行为在传感器的不同视角下表现出多样的行为特征。为了减轻视角变化带来的影响,Zhang等人(2017,2019)提出一种视角自适应网络,并分别以RNN和CNN为基础,设计了视角自适应递归神经网 络(view adaptive recurrent neural network,VARNN)和视角自适应卷积神经网络(view adaptive convolutional neural network,VA-CNN)。该方法不需要先验准则来重新定位骨骼数据,而是通过网络学习得到三维空间下的坐标转换矩阵,使输入到特征提取网络的骨骼数据始终保持在最利于识别的观察视角。通过图6 可以看出,对于每帧骨骼,首先将坐标系转换到全局坐标系o下(以第1帧骨架的中心节点为基准),然后将全局坐标系下的骨骼通过平移、旋转的方式调整到坐标系o′下,其中平移的距离和旋转的角度均由网络学习得到。图6 中,dt表示平移量,Rt表示旋转矩阵。
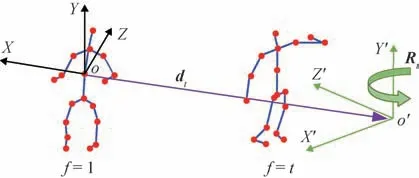
图6 视角转换过程(Zhang等,2017)Fig.6 The process of view conversion(Zhang et al.,2017)
由于RNN善于处理时间序列,基于RNN的方法在提取行为的时序信息上具有天然的优势,但该类方法对骨骼的空间特征提取能力较弱,经常忽略与行为相关的拓扑结构信息,导致空间特征提取不充分,影响识别精度进一步提高。
3.2 基于卷积神经网络的方法
受卷积神经网络(Krizhevsky等,2017)在图像分类领域取得成功的启发,研究者开始考虑将CNN 用于骨骼行为分类。为了满足CNN 的输入要求,一般将骨骼数据编码为2D 伪图像,其中,图像的行表示不同的关节,列表示不同的帧,X、Y、Z的3D 坐标值被视为伪图像的3 个通道,然后采用卷积核提取伪图像的特征,并将提取到的特征用于分类。
使用卷积网络建模骨骼数据的一个关键问题是如何在保留骨骼序列的时空信息的同时将骨骼序列转换为伪图像。Du 等人(2015a)将5 个身体部分的串联作为一帧,三维坐标对应R、G、B这3个通道,这样获得的伪图像非常清晰地表示出每个身体部分的运动特征的空间分布,人体结构的空间全局信息明显。但该方法无法挖掘关节的运动方向及运动速度信息,使得网络性能十分有限。与Du 等人(2015a)的做法不同之处是,Wang等人(2016)将关节点坐标在时间上的差分映射到3 个正交平面获得保留了空间信息的关节轨迹图像。然后使用色图(颜色映射表,是一种将数值映射为颜色的方法)将关节轨迹映射为颜色图像,颜色的变化表示关节运动的方向,颜色的饱和度和亮度模拟运动幅度和速度的变化。更进一步,为了描述不同的身体部分,使用3 种不同的色图分别映射3 个身体部位。最后使用卷积网络分别学习映射在3 个正交面上的图像,并融合最后得分,获得最终预测结果。Hou 等人(2018)的工作不再使用关节点坐标在时间上的差分,而是直接将关节点坐标映射至3 个正交平面,并采用与Wang 等人(2016)工作相同的颜色编码技术获得同时具有空间和时间信息的骨骼光谱图。上述两种骨骼数据的伪图像表示方法使得用标准的CNN 模型学习骨骼序列中的“动态”特征成为可能。图7(a)(b)分别是上述两种方法中将骨骼编码为图像的结果图。将关节点坐标编码为图像的方式尽可能多地保留了行为的时间和空间特征,并且可以直接使用现有的CNN 模型进行特征学习。

图7 骨骼序列编码图(Wang等,2016)Fig.7 The coding diagram of skeleton sequence(Wang et al.,2016)((a)trajectory coding;(b)spectral coding)
上述方法以自然的人体骨骼连接方式设计伪图像,还有一些工作提出具有新意的骨骼数据表示方法,以保留更多的人体结构信息。Ke 等人(2017)将骨骼序列剪切成3个片段,每个片段中包含4个灰度图,该灰度图通过计算参考点与每个关节点的相对位置而得到。该方法所构建的伪图像聚合了多个具有不同空间关系的帧,提供了关节空间结构的重要信息。Yang 等人(2019)认为以固定顺序将关节点拼接为矩阵会导致关节点的结构信息丢失,对此提出了一种保留空间关系的树结构骨骼图像表示法,采用深度优先的树遍历顺序重新设计骨骼表示,以增强伪图像的语义信息。Caetano 等人(2019)在树结构骨骼图像表示法的基础上,结合关节之间的不同空间关系,提出一种基于树结构和参考关节的三维行为识别的骨骼图像表示方法。该方法能够加强关节对的空间结构关系,获得更丰富的空间上下文信息。
CNN 利用局部感受野、权值共享以及空间聚合来实现对骨骼序列的特征表示。但由于CNN 卷积核具有局部性,很难有效地挖掘所有关节的共现性。为了突破这一限制,Li等人(2018a)提出一种时空共现性特征学习的端到端卷积神经网络模型。该网络先沿着关节维度学习关节的点特征,然后将该特征进行转置,把每一个关节都作为一个通道,随后逐步聚合所有关节的全局特征。该方法学习到了关节与关节之间的共现性特征,提高了特征的表示能力。在Li 等人(2018a)的基础上,Liang 等人(2019)提出三流卷积网络,该网络可以利用多个特征之间的互补性和多样性,联合处理关节点坐标、骨骼段和关节运动信息,网络的结构如图8所示。第1阶段独立提取特征;第2 阶段采用成对特征融合策略将特征两两相互融合;第3 阶段是多任务集成学习网络,其有效提高了模型的泛化能力。以上两种共现特征学习模型以其优秀的全局响应特性超越了多数基于卷积神经网络的方法。
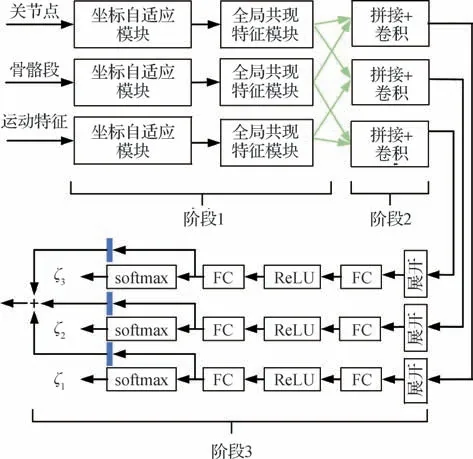
图8 三流卷积网络结构(Liang等,2019)Fig.8 Three stream CNN for skeleton-based action recognition(Liang et al.,2019)
虽然基于CNN 的方法能够同时处理时空信息,但CNN 在处理具有拓扑属性的人体骨架图时并不完全适用,图卷积的出现改变了这一现状。
3.3 基于图卷积网络的方法
人体骨骼是自然的拓扑图,如果先把骨骼数据处理成序列向量或伪图像再送入到以RNN 或CNN为主的模型中进行特征学习,必然会导致部分空间语义信息的丢失。且由于拓补图节点间结构及节点数量的变化特性,很难使用规则的卷积核提取特征。图卷积神经网络(Kipf 和Welling,2017)的提出使得直接学习不规则数据成为可能。Yan 等人(2018)根据人体动力学知识,首次将图卷积应用到基于骨骼信息的人体行为识别中,提出一种时空图卷积网络(spatial temporal graph convolutional network,STGCN)。ST-GCN 模型的设计如图9 所示,首先构造图结构:将人体的关节点作为图的节点,节点的属性是关节点在空间中的位置坐标。图中的边分为两种类型:空间边和时间边。空间边是关节点之间的连接,反映它们在人体中的自然结构。时间边是同一关节点在相邻帧之间的连接,反映它们在时间上的连续性;其次,将骨骼数据送入到以S-GCL 和T-GCL交替连接的时空图卷积网络中提取空域和时域特征;最后通过全连接层和softmax 层获取行为种类。图9 中,S-GCL 表示空间图卷积层(spatial graph convolutional layer),T-GCL 表示时间图卷积层(temporal graph convolutional layer)。关节点vi处的空间图卷积为

图9 时空图卷积网络结构(Yan等,2018)Fig.9 The pipeline of ST-GCN(Yan et al.,2018)
式中,fout表示输出特征图,fin表示输入特征图,Di表示关节点vi的邻居节点vj的集合,w为类似于卷积操作的权重函数,li表示映射函数,1/Zij为可学习矩阵,用来平衡每个子集的贡献。
如图9 所示的分区策略,按照人体结构将Di划分为3 个子集:根节点、向心节点和离心节点。其中,根节点是节点本身,向心节点表示到人体重心的距离比根节点到重心的距离更近的关节点的集合,离心节点表示到人体重心的距离比根节点到重心更远的关节点的集合。
后续大量工作在Yan 等人(2018)的基础上进行了改进,根据改进工作针对的角度不同,可将这些工作划分为4 类,具体为:1)图结构的优化;2)网络的轻量化;3)时空特征的优化,即针对辨别性时间和空间特征的提取进行深入研究;4)关节缺失和噪声的优化,即针对关节点缺失、噪声这类特殊场景下的问题展开研究。
3.3.1 图结构的优化
时空图卷积模型ST-GCN 的高效性能为行为识别开辟了新的思路。ST-GCN 所使用的图结构是启发式预定义的人体自然连接图,挖掘不到没有物理连接的关节点间的关系,例如喝水时手和头的依赖关系。且ST-GCN 设计的图结构固定在网络的每一层,对数据变化的敏感度弱,这导致网络对不同种类行为的建模缺乏灵活性,建模多层语义信息的能力较差。受到基于部分的可变形模型(deformable partbased models,DPMs)(Felzenszwalb 和Huttenlocher,2005)的启发,Thakkar 和Narayanan(2018)基于人体的结构将人体骨骼图分成4 个子图,使用基于身体部分的图卷积网络捕捉每个身体部件的高层语义表达,同时学习身体部件之间的依赖性,但该方法设计的图结构仍是预定义的,缺乏灵活性。对此,Shi 等人(2019a)提出的二流自适应图卷积网络(twostream adaptive graph convolution network,2s-AGCN)将图结构参数化,骨骼图可随着网络参数一起优化,这种方法增加了网络的通用性,相比于固定的图结构,可优化的图结构更能适应不同数据样本。Li 等人(2019)同样扩展了现有的骨骼图,提出AS-GCN(actional-structural graph convolutional network),设计了动作链接和结构链接两种图结构,学习没有物理连接的关节点之间的依赖性。该模型过于复杂,但是该模型开创性地扩展到行为预测领域,为后续基于骨骼信息的行为预测研究提供了新思路。
为了充分利用人体关节和骨骼段之间的关系,Shi 等人(2019b)以关节为节点、骨骼为边计了一个有向无环图,建模关节点和骨骼段之间的空间依赖性以及它们之间的方向信息,并根据有向图的结构更新节点和边的信息。该方法虽然取得了很好的效果,但其参数及计算复杂度远超先前的研究。
Peng 等人(2020)转向神经体系结构搜索(neural architecture search,NAS),第一个提出用于骨骼行为识别的自动设计的GCN。具体来说,NAS-GCN探索了节点之间的时空相关性,并构建了一个具有多种动态图模块的搜索空间。此外,该方法引入了多跳跃模块,并希望打破一阶近似所带来的表示容量的限制。该工作证明了高阶近似和分层动态图模块的有效性。Gao 等人(2019)引入图回归思想,求解在连续帧上对图拉普拉斯矩阵建模的优化问题,最终得到最优的图拉普拉斯矩阵,优化后的图不仅增强了图的稀疏性,而且能够充分表示关节点分别在时间和空间上的连通依赖性强弱。
纵观图结构优化的工作,其主要思路是打破固定图结构带来的限制,使图能够动态、高效地更新,以适应不同的行为类别。
3.3.2 网络的轻量化
基于GCN 的模型取得了令人满意的识别精度,然而此类方法普遍存在参数量大、计算复杂度高、推理速度慢等问题,通常一个动作样本的计算复杂度超过15 GFLOPs,有些模型甚至达到100 GFLOPs。针对这个问题,Cheng 等人(2020)提出移位图卷积网络,该网络使用移位图运算和轻量级逐点卷积代替正则图卷积,计算复杂度降低了数十倍。在空间域上通过移位操作使每一个关节都能与其相应的邻域相关联,增大了空间感受野,从而增强了无物理连接的关节点的相互依赖关系;在时间域上,通过通道移位操作将相邻特征图上的时间信息混合在一起,时间感受野相应地被扩大,从而达到增强时间特征建模的目的。Song等人(2020)将瓶颈结构应用到图卷积网络中,提出的ResGCN(residual graph convolutional network)大大减少了可学习参数的数量,最多比其他模型少34 倍。ResGCN 使用的残差结构和瓶颈结构虽然极大地降低了训练难度、模型复杂度,但该方法为了弥补准确率上的不足设计了较为复杂的基于身体部分的注意力机制,使得模型的可读性降低。Song等人(2023)进一步将深度可分离卷积应用到对时间建模的模块上,并与MS-G3D(multi-scale G3D)(Liu 等,2020b)的空间模块相结合,提出了EfficientGCN(efficient graph convolutional network),该方法相比于ResGCN 的准确率进一步得到提升,并涉及更少的参数量和计算复杂度。
3.3.3 时空特征的优化
探索骨骼序列的时空特征对行为识别任务至关重要。然而,如何有效地提取辨别性的时空特征一直是一个具有挑战性的问题。
Si 等人(2019)提出的注意力增强图卷积LSTM网络(attention enhanced graph convolutional LSTM network,AGC-LSTM)将GCN 算子嵌入至LSTM 算法中,因此,该方法不仅能捕获具有辨别性的时间和空间特征,而且能探索到空域和时域中的共现关系,提高了模型的高层时空语义信息的学习能力。此外,AGC-LSTM 在空间维度上,利用注意力机制增强活跃关节点的特征;在时间维度上,利用时间分层结构增大时域感受野,进一步提高了模型的时空建模能力。类似地,Ding 等人(2019)将GCN 与双向递归神经网络相结合,提出注意力增强的循环图卷积网络(attention-enhanced recurrent graph convolutional network,AR-GCN)。
此外,一些研究将CNN 中的优秀工作引入到图卷积中,以获得更细致的骨骼时空表达。Wu 等人(2019)在ST-GCN 的基础上,引入了空间残差层和密集连接模块,利用空间残差层来提取更精确、更有意义的时空特征,并通过融合时空特征来增强时空信息。密集连接模块能够充分利用骨骼的全局信息,提高模型的鲁棒性。Chen 等人(2021)提出一种双头时空图卷积网络,该网络能够同时提取粗粒度的上下文信息和细粒度的局部特征,以高效的方式联合捕捉行为的动态模式。此外,交叉注意机制的提出,使两个粒度上的时空特征相互交流、相互增强。Liu 等人(2020b)将多尺度思想引入至GCN 中,分别使用多个不同尺度的卷积对时间和空间建模,获得的特征具有跨时空维度的多尺度感受野,实现了有效的多尺度时间和空间建模。
上述工作忽视了语义的重要性,且高度依赖于大体量的网络进行行为识别。Zhang 等人(2020)将关节点的类型(头、手、膝盖等)和帧的索引作为网络输入的一部分,以增强特征的高级语义信息表达能力。此外,该方法引入关节级模块和帧级模块的串联结构,分别挖掘关节点间的空间依赖关系和帧间的时间依赖特性。该方法首次引入高级语义信息,设计的网络更高效,可解释性更强。
3.3.4 关节缺失和噪声的优化
在使用基于骨骼信息的人体行为识别方法时,通常假设获取的骨骼数据是准确的、完整的。然而,无论是通过姿态估计算法还是高精度深度相机捕捉关节点,得到的关节点坐标往往是不完整的或具有噪声的,这将影响到模型的识别性能。针对上述问题,Song 等人(2019)提出一种多流关节点激活图卷积神经网络。首先,该网络采用注意力机制计算每一流的激活图,激活图用来表示关节点是否活跃。然后通过累加前一流的激活图来指导新一流的学习过程,网络的每一流只负责从当前未激活的关节中学习特征。该方法虽然可以更全面地捕捉不活跃关节点的特征,提高对有噪声或缺失数据的识别能力,但所采用的多流结构给训练、推理过程带来了计算负担。相比之下,Li 等人(2021)提出的姿态改进图卷积网络不仅可以对具有噪声或缺失的关节进行矫正,而且在网络早前采用降低时间分辨率的方式,实现网络的轻量化。Yoon 等人(2022)提出的PeGCN(predictively encoded graph convolutional network)是一种对潜在空间进行预测编码的图卷积网络。在训练阶段,PeGCN 通过从潜在空间上的噪声样本中预测完整样本来学习特征,获取噪声骨架的鲁棒表达。该方法更适用于骨骼数据中存在较多不完整或较多噪声的行为识别任务。
3.4 基于Transformer的方法
除上述工作外,还有一些工作将近期流行的Transformer 技术应用到基于骨骼信息的行为识别中。Plizzari 等人(2021)引入空间自注意力模块动态构建骨骼的空间特征,引入时间自注意力模块学习骨骼在时间方向上的动态信息,同时,时间自注意力模块克服了标准时间卷积的局部性,使跨帧的远距离依赖特征提取成为可能。该工作证明了空间自注意力模块可以取代空间图卷积操作,并且获得的特征更灵活、动态表示能力更强。然而,该方法只关注到帧内不同关节点之间的相关性,不同帧上的不同关节点之间的依赖性没有被考虑到。为此,Qiu等人(2022)首先将骨骼序列划分为几个不重叠的部分(元组),然后使用时空元组自注意力模块捕捉连续帧之间不同关节的相关性。此外,该方法提出的帧间特征聚合模块,在由元组构成的时间维度上聚合特征,进一步提高了模型的识别能力。与上述方法直接使用Transformer算子替代图卷积算子不同的是,Bai 等人(2022)提出一种层次图卷积Transformer,同时利用图卷积的局部拓扑性和Transformer的全局上下文捕捉能力。该方法充分发挥了图卷积和Transformer的优势,其识别效果远超上述方法。
此外,Pang 等人(2022)针对多人交互行为,提出一种新的基于Self-Attention 的方法来建模交互人物身体部位之间的相关性。具体地,图交互多头Self-Attention 模块在人体交互部位的语义信息和距离信息两个角度上进行建模。该方法首次聚焦人体交互部分,为以后的多人交互行为识别提供新思路。
4 算法性能对比
表4 显示了主流模型在NTU-60、NTU-120 以及Skeleton-Kinetics 3 个骨骼行为数据集上的分类结果、模型的参数量和计算复杂度。可以看出,NTU-60 数据集是普遍应用的骨骼行为数据集,随着图卷积技术的出现,研究重心逐步向图卷积方法转移。ST-GCN 作为基于图卷积方法的开山之作,在NTU-60 数据集的X-Sub 和X-View 两个基准上的识别准确率分别为81.5%和88.3%。后续算法分别在图结构的优化(如PB-GCN、2s-AGCN)、改进模型的速度(如PA-ResGCN、EfficientGCN)、提高模型建模辨别性时空信息的能力(如AGC-LSTM)以及针对缺失关节点的改进(如PR-GCN)等方面展开了深入研究。目前为止,在NTU-60数据集上识别率表现最好的算法是HGCT,在X-Sub 和X-View 两个基准上的识别准确率分别为92.2%和96.5%。该方法采用先进的Transformer 技术替代传统卷积算子来提升网络性能,并取得了较高的识别率。在模型的参数量和计算复杂度方面,表现最好的算法是EfficientGCN,该方法同时兼顾速度与精度,参数量和计算复杂度与ST-GCN 持平,精度却比ST-GCN 高出10.2%(NTU-60数据集的X-sub基准)。

表4 不同算法的结果比较Table 4 The comparison results of different methods
上述方法虽然在NTU-60 和NTU-120 数据集上取得了优异的识别效果,但是在Skeleton-Kinetics 数据集上的效果不佳。主要原因是Skeleton-Kinetics数据集为真实场景下所采集的,存在大量遮挡、光照变化以及摄像机运动等影响因素,导致提取到的骨骼数据精度不高,影响行为识别效率,且该数据集包含的种类较多,具有多种人—物交互的行为。
5 展望
虽然基于骨骼信息的人体行为识别已经有了多年的技术积累,但仍然面临许多困难和挑战。在总结目前存在的问题和挑战的同时,对今后的研究做出展望。
1)人体结构高度复杂,现有采用少量关节点表示人体行为特征的识别模型,限制了其对非典型运动等复杂行为的识别能力,可以考虑采用结构性和局部性增加关节点的方法,加强人体目标性结构的特征表示,提升对复杂行为的识别度。
健康成年人的身体结构包括206块骨骼、200多个关节,为了维持人体在静态和动态时的平衡,关节之间存在着复杂的关联。在行为识别中,通常采用15~30 个关节点的坐标表征人体空间结构,识别一些如跑步、走路、蹦跳等简单的行为时,识别率几乎可以达到100%。但当识别一些如玩手机、玩魔方等复杂行为时,即使是目前最先进的算法,识别效果仍然不佳。未来的研究可以考虑增加细粒度关节(面部、手、脚等),例如Trivedi 等人(2021)提出的NTUX 数据集,在25 个关节点之外增加了51 个面部关节和42 个手指关节,该骨骼表示方法在现有的算法上表现出色。
2)目前很少有模型能够很好地调适人体外观多样性带来的不利影响,可以考虑引入关节点间的相对位置特征应对个体差异带来的挑战,增强模型的鲁棒性。
不同个体之间存在着明显的差异性,例如男人和女人之间的差异、成人和小孩之间的差异,这些差异主要体现在骨骼的尺度差异。这些差异将给行为识别算法提出更高的要求。在NTU 数据集的跨人物验证基准上的识别效果习惯性地比跨视角验证基准低可以证明这一点,如表4 所示。可能的解决方案是结合各种丰富的骨骼特征,不局限于关节点的位置信息,考虑关节间的相对位置或关节之间的角度信息,对抗人体尺度的变化。例如Qin 等人(2022)以3 个关节点之间的角度信息作为输入特征,相比于坐标特征,该特征更能反映人体部位的相对运动,增强了对个体变化的鲁棒性。
3)图卷积网络体量大、结构复杂,训练和推理速度慢,实时性不好,识别模型应用的限制性大,可以考虑引入具有“高保真”的轻量化机制,提高实时性的同时兼顾精度。
现有的基于骨骼的行为识别方法普遍存在模型复杂、计算量巨大等缺点,尤其是图卷积相关方法。目前已有研究团队针对图卷积方法参数量大的缺点进行改进,如Song 等人(2020,2023)提出的ResGCN和EfficientGCN,虽然降低了模型的复杂度和参数量,但准确率有限,且均需嵌入复杂的注意力机制去弥补精度上的缺陷。对此可以尝试其他一些应用在图像分类任务中的方法,如分组卷积(Krizhevsky等,2017)或通道洗牌(Zhang 等,2018)等,将图卷积方法与上述机制相结合,提升通道之间的信息交互的同时降低模型复杂度,获取更多的上下文信息,在不损失甚至提升精度的同时轻量化网络。
4)图卷积网络相对来说层数都较浅,导致提取特征的丰富性受限,可以考虑通过结构性地加入归一化和残差网络等层深拓展手段,加深模型层数以提取更深层次特征。
CNN 深度学习模型往往可以通过堆叠大量的卷积层实现特征的精细化提取,以此提高模型的性能,例如Resne(tresidual network)模型(He等,2016),其深度可以达到上百层。用于行为识别的图卷积网络的层次普遍不深,且当层数过多时获取到的节点特征过于平滑(Li 等,2018b),而浅层结构影响对深层语义信息的挖掘,不利于识别。在未来工作中,可以考虑同时使用归一化和残差结构,除了减缓过平滑现象外,归一化和残差操作都能够提升训练的稳定性和收敛性,使得深层图神经网络的训练更加容易,损失曲线更加平滑。
5)由于数据源的限制,基于骨骼信息的模型对于人—物交互行为识别度不高,可以考虑引入多种其他模态信息,改善数据源的结构和内容,从而提升对交互行为的识别精度。
总体来说,目前基于骨骼数据的行为识别在NTU-60 和NTU-120 两个大型骨骼数据集上的识别准确率已经达到相当高的水准。骨骼数据比较适合辨别单纯的人体行为,当识别一些人—物交互的行为时,识别效果并不佳,例如,目前在Skeleton-Kinetics 数据集上的最佳识别精度为49.1%(Duan等,2022)。原因在于Kinetics 数据集中包含多种人—物交互的行为,例如吃汉堡、吃蛋糕等,仅使用骨骼数据就失去了对物体信息的关注,在辨别动作特征几乎相同但动作对象不同的行为时表现不佳。
传感器技术的发展,给多模态的行为识别带来更低成本、更高效的可能。人体的多模态信息包括RGB 视频、深度信息、红外信息和骨骼信息等,不同的模态信息之间具有强相关性,又具有一定的互补特性。例如,骨骼信息虽然在识别单纯的人体行为时表现出色,但由于其失去了对背景信息的关注,不适合用做识别人—物交互类行为,而RGB 视频包含背景信息,可以提供物体信息,给识别人—物交互类行为带来提升。未来,可以将骨骼信息和RGB 信息相融合,在保留骨骼信息的简洁性的同时,增加背景信息,获得更有益于识别人—物交互行为的特征。
6)行为数据标注难度大,可以考虑采用无监督学习、小样本学习等技术减少对标注数据的依赖度,增强算法对实际应用的适应性。
视频数据集的样本数量巨大,且人的行为种类丰富多变,对视频数据的有效而准确的标注需耗费大量资源。针对这一问题,可以使用无监督或小样本方法以消除对标注数据的依赖。且无监督方法和监督方法的性能差距正在不断缩小。例如Paoletti等人(2022)基于卷积自编码器和自适应拉普拉斯正则化学习未标注的骨骼序列的特征表示,并将该特征表示输入到一个分类器(例如,1-nearest neighbor),以验证及评估模型。另一个可行的方向是进行小样本行为识别研究,如Memmesheimer 等人(2020)通过度量学习方法,将行为识别问题简化为嵌入空间中的最近邻搜索问题,仅需对少量新类别(与训练集包含的种类不交叉)样本标注即能完成识别任务。但是,上述方法在NTU-120 数据集上的表现并不出色,在测试集上的准确率仅为50%左右,小样本的行为识别处于研究初级阶段。
7)现有行为识别方法不能满足事故突发等场景下的快速决策的功能需求,可以考虑引入轨迹预测等趋势性方法,以“识别+预测”的算法能力应对现实应用需求。
行为识别任务的主要目标是识别已经发生的行为,但是在一些场景中,如应用于反恐防暴监测系统、自动驾驶系统的行人行为监测技术,人们希望在行为发生之初就能预测到行为人下一步要做什么,然后留给人们更多的时间去应对突发的事件。Li等人(2019)在研究行为识别任务的同时,将模型扩展到对骨骼姿态预测的研究,但没有详细的定量分析研究,只有初步的定性分析,未来可以设计更精细化的指标对预测的姿态进行定量的评价,如类似行人轨迹预测所使用的平均位移误差和最终位移误差等。
8)现有方法都存在对并发性行为识别度不高的问题,可以考虑借鉴多标签文本分类方法的成功经验,将目前的单标签行为识别拓展到多标签模式,独立而后交互地识别并发性行为。
当前的行为识别所采用的数据通常是一个视频序列对应一种行为标签。然而,一个视频序列可能会对应多个类别标签,并且每个行为之间可能存在一定的关联性。行为可同时具有多种并列的标签类别,例如“边走路边打电话”;也可同时具有父子继承关系的多标签类别,例如“跳舞和跳芭蕾”。在未来,可以借鉴多标签文本分类任务所使用的方法进行多标签行为识别(Lan 等,2020)。例如,在多标签文本分类中,改变输出概率的计算方式和交叉熵的计算方式(Huang 等,2021),使每个类之间相互独立,而不是互斥的。此外,在输出层设置多个全连接层,使每一个全连接层对应一个标签,也可以完成多标签分类任务。
6 结语
基于骨骼信息的人体行为识别是人体行为识别领域的重要研究方向,也是计算机视觉领域的热门课题之一。随着深度学习的发展和大型数据集的提出,基于骨骼信息的人体行为识别在基础理论和技术方法等方面取得了显著的进步。本文首先整理了主流的用于骨骼行为研究的数据集,着重讨论了各种数据集的特点。其次,从模型所使用的基础网络角度将基于骨骼信息的行为识别方法分为基于手工制作特征的方法、基于RNN 的方法、基于CNN 的方法、基于GCN 的方法以及基于Transformer 的方法,全面分析了各类方法的优缺点,并以全新的分类方法重点讨论了基于GCN 的方法。最后对比不同算法的定量效果,总结出一些存在的问题和未来可行的研究方向。基于以上回顾和展望,希望能给研究人员提供一个完整的基于骨骼信息的行为识别领域知识,使相关研究人员能从中获得一些创新的思路和启发。
猜你喜欢
中老年保健(2021年5期)2021-12-02
北京航空航天大学学报(2021年9期)2021-11-02
中老年保健(2021年5期)2021-08-24
科学技术创新(2021年19期)2021-07-16
沈阳航空航天大学学报(2020年6期)2021-01-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
小布老虎(2017年1期)2017-07-18
军营文化天地(2017年6期)2017-06-28
智能系统学报(2017年1期)2017-06-01
