
通道注意力嵌入的Transformer图像超分辨率重构
2023-12-23 10:13熊巍熊承义高志荣陈文旗郑瑞华田金文
中国图象图形学报 2023年12期
熊巍,熊承义,2*,高志荣,陈文旗,郑瑞华,田金文
1.中南民族大学电子信息工程学院,武汉 430074;2.中南民族大学智能无线通信湖北省重点实验室,武汉 430074;3.中南民族大学计算机科学学院,武汉 430074;4.华中科技大学多谱信息处理技术国家重点实验室,武汉 430074
0 引言
在如今数字化与信息化高度集中的时代,图像已经成为人们获取信息的重要途径之一。图像分辨率体现了图像反映物体细节信息的能力,相较于低分辨率(low-resolution,LR)图像,高分辨率(highresolution,HR)图像通常具有更优秀的视觉效果与更详细的纹理信息(蒋梦洁 等,2022)。单幅图像超分辨率(single image super-resolution,SISR)技术旨在单幅低分辨率图像的基础上重建出对应的高分辨率图像。SISR 技术目前成功应用于许多领域,例如安全监视、医疗以及卫星成像等(Wang等,2021)。
由于缺乏信息,对于给定的LR 图像,可能会有多个超分辨率结果,因此SISR 是一个具有挑战性的不适定问题。随着深度学习技术的快速发展和GPU(graphic processing unit)计算能力的大幅度提升,基于深度学习的超分辨率技术已经成为主流,并在重构效果上取得了巨大的飞跃(雷鹏程 等,2020)。Dong 等人(2014)提出了首个基于深度学习的超分辨率重建卷积神经网络(convolutional neural network for image super-resolution,SRCNN),采用了3 层的卷积神经网络(convolutional neural network,CNN)学习LR 图像与HR 图像之间的映射关系。Kim 等人(2016a)构建了具有20 层的深度网络VDSR(accurate image super-resolution using very deep convolutional network),获得了比SRCNN 更好的结果,表明增加网络的深度可以获得更好的SR 性能。EDSR(enhanced deep residual network for single image super-resolution)(Lim 等,2017)对ResNet(deep residual learning for image recognition)(He 等,2016)的残差块进行了适用于图像恢复任务的改进,并深化和拓宽网络的整体架构,大幅提升了重建效果。WDSR(wide activation for efficient and accurate image super-resolution)(Yu 等,2018)在EDSR 的基础上进行了宽度特征激活的改进,通过激活更多的特征提升重建性能。RCAN(image super-resolution using very deep residual channel attention network)(Zhang等,2018)将通道注意力(channel attention,CA)机制引入超分辨率任务,以学习不同通道之间的相关性,并大幅加深网络深度。虽然基于卷积神经网络(CNN)的模型已经取得了大幅的效果提升,但仍然面临一些卷积自身的限制。首先,图像和卷积核之间的交互与图像的自身内容无关,使用相同的卷积核来恢复不同的图像区域并非最佳的选择。其次,在局部处理的原则下,卷积无法对图像进行长距离关联性建模。为此,Transformer(Vaswani 等,2017)架构提供了一种可以捕获全局信息并利用图像的自相似特性的自注意力机制(Dosovitskiy 等,2021),已经应用于计算机视觉的多个领域,而SISR 任务也开始出现基于Transformer 模型的网络。IPT(pretrained image processing Transformer)(Chen 等,2021)构建了一个基于Transformer的超大图像处理预训练模型,依靠大规模的模型参数与大量的训练集取得了良好的性能。TransENe(tTransformer-based multistage enhancement for remote sensing image superresolution)(Lei 等,2022)对于遥感图像的超分辨率任务提出了不同特征维度结合的Transformer 网络。Liang 等人(2021)则在ST(swin Transformer)模块(Liu等,2021)的基础上提出了适用于图像恢复任务的SwinIR(image restoration using swin Transformer)。
基于深度学习的超分辨率方法总体可以得到图像重建质量的显著提升,但目前大部分成果网络模型复杂,因此导致系统实现的高计算成本与资源需求难以满足实际应用需要。因此,如何平衡模型的复杂度和系统重构性能,设计更好满足实际应用需要的轻量化超分辨率网络一直是该领域关注的重要方面。以往的工作主要集中在基于卷积网络超分辨率模型的轻量化。比如,FSRCNN(accelerating the super-resolution convolutional neural network)(Dong等,2016)首次将卷积神经网络直接应用于低分辨率图像,大幅减少了计算复杂度。DRCN(deeplyrecursive convolutional network)(Kim 等,2016b)和DRRN(deep recursive residual network)(Tai 等,2017)采用了递归神经网络来减少网络深度,可以有效控制参数量。IMDN(information multi-distillation network)(Hui 等,2019)提出了一种信息蒸馏机制,可以逐步提取层次特征,并针对图像恢复改进了通道注意力。RFDN(residual feature distillation network)(Liu 等,2020)改进了IMDN 的体系结构,将信息蒸馏改为特征提取,提出了残差特征提取网络,获得了更好的重建效果。
ST 模块依靠其窗口局部注意力与移动交互的特性,相较于标准Transformer大幅减少了复杂度,在图像恢复任务上也展示了良好的性能。基于以上背景,本文提出了通道注意力嵌入的Transformer 超分辨率重构方法(image super-resolution with channelattention-embedded Transformer,CAET),以期利用卷积网络与Transformer 网络的各自优势,在保证图像超分辨率性能提升与网络模型轻量化方面得到更好平衡。一方面,利用Transformer 变换与卷积运算的交替,发挥两种变换网络在特征提取中的不同优势,并将对应特征进行不断融合增强;另一方面,采用通道注意力,实现图像Transformer 特征与卷积特征的自适应判别融合,进一步改善了网络的学习能力。在多个数据集的实验比较结果验证了本文方法在改善超分辨率重构图像质量及平衡网络模型轻量化方面的有效性。
本文的主要特点如下:1)提出了注意力嵌入的Transformer 模块(channel-attention-embedded Transformer block,CAETB),该模块有效结合卷积与Transformer 在图像特征提取的各自优势,并将通道注意力自适应地嵌入Transformer变换特征与卷积运算特征,有较好的提取特征能力。2)采用了基于通道注意力的卷积特征与Transformer特征的自适应判别增强策略,将不同层级和不同滤波器输出特征结合通道注意力判别加权处理,有效提升网络的学习能力。3)大量实验验证,与现有类似的图像超分辨率方法相比,CAET 以较小的模型复杂度在多个数据集上取得了明显的性能改进。
1 相关工作
1.1 轻量级超分辨率
因在现实常用的设备上实现超分辨率任务的需求,轻量级超分辨率模型受到了广泛关注。FSRCNN(Dong 等,2016)取代了SRCNN(Dong 等,2014)先上采样图像后输入到网络的方式,将网络的主体直接应用于LR图像,大幅减少了网络所需的计算资源。DRCN(Kim 等,2016b)与DRRN(Tai 等,2017)引入了递归神经网络,这种方式虽然可以减少参数量和网络深度,但重复的递归也导致了模型的计算量大幅增加。LapSRN(deep Laplacian pyramid network for fast and accurate super-resolution)(Lai 等,2017)采用了渐进式逐步提高图像分辨率,以获得更稳定的高倍率放大结果。IMDN(Hui等,2019)提出了一种轻量级信息多蒸馏网络,该网络利用信息蒸馏机制有效提取不同层次特征。LatticeNet(image super-resolution with lattice block)(Luo等,2020)受快速傅里叶变换的启发,设计了一种晶格网络,可以有效利用并调整不同层级的信息。ECBSR(edgeoriented convolutional block for real-time super resolution)(Zhang 等,2021)基于重参数化技术提出了一种结合边缘信息的卷积块,在提高模型学习能力的同时减少了推理时间。尽管轻量级的超分辨率算法已经取得了较大的进展,但在重建效果上仍需要进一步的提升。
1.2 基于Transformer的图像恢复
来自自然语言处理领域的Transformer依靠长距离建模与自注意力的特性,得到了计算机视觉领域的广泛关注。随着Transformer模型开始应用于计算机视觉的各个领域,与本文相关的图像恢复领域也出现了许多采用Transformer架构的算法。IPT(Chen等,2021)针对各种类型的图像恢复任务,提出了主干Transformer预训练模型,依靠大量参数、大规模的训练数据集和多任务学习获得了良好的性能。TransEnet(Lei 等,2022)对于遥感图像超分辨率任务提出了不同维度结合的Transformer 网络。SwinIR(Liang 等,2021)将ST 模块引入到图像恢复领域,在多个任务上取得了良好的成绩。Uformer(U-shaped Transformer for image restoration)(Wang等,2022)则将Transformer 与经典卷积网络U-Net(convolutional network for biomedical image segmentation)(Ronneberger 等,2015)相结合,在图像去噪任务上取得了优秀的效果。ESRT(efficient superresolution Transformer)(Lu 等,2022)设计了efficient Transformer,通过压缩通道的方式进行特征输入,相较于标准的Transformer,大幅减少了参数量与运算时间。总体来说,Transformer 在图像恢复领域的研究与应用,特别是以此为基础的轻量化实现上仍处于初级阶段。
2 本文方法
2.1 整体结构
基于Transformer与卷积结合的轻量化超分辨率网络方案的具体设计框图如图1所示,主要由4部分组成,包括浅层特征提取阶段、深度特征提取阶段、多层特征融合阶段和图像重建阶段。其中,深度特征提取阶段由注意力嵌入的Transformer 模块(CAETB)组成,将在2.2 节做详细介绍。网络对于给定的ILR和ISR作为输入的低分辨率图像和预测的高分辨率图像。
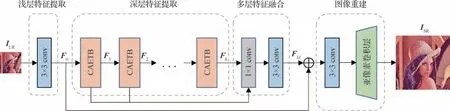
图1 通道注意力嵌入的Transformer网络整体结构Fig.1 Overall structure of channel-attention-embedded Transformer network
1)浅层特征提取阶段。此阶段采用了一个卷积核大小为3 × 3 卷积层从给定的LR 图像中提取浅层特征F0,其过程可以表示为
式中,HSF代表卷积操作,提取的浅层特征F0会进一步用于深层特征提取。同时,特征F0会直接传输到重构模块,以保留图像的低频信息。
2)深层特征提取阶段。此阶段以浅层特征F0作为输入,并使用多个CAETB 提取深度特征信息。假设CAETB 的数量为k,则对于第i个CAETB 的输出Fi(1 ≤i≤k) 可以表示为
式中,HCAETB代表CAETB 的操作,用于提取图像的深度特征,其结构如图2所示。

图2 CAETB内部结构图Fig.2 Internal structure of the CAETB
3)多层特征融合阶段。不同阶段的分层信息有助于最终重建结果。因此,网络在多层特征融合阶段结合了所有来自深层特征提取阶段的低层和高层信息,可以将融合结果FM记为
式中,HMFF代表多层特征融合操作,为最终的信息重建提供充分的参考与引导。
4)图像重建阶段。上述的融合结果FM与浅层特征F0会进一步输入到图像重建阶段,以恢复出适应于不同任务的高分辨率图像。最终的高分辨率图像ISR获得过程可以表示为
式中,HREC表示重建阶段的操作,选择了一个3 × 3卷积层和ESPCN(Shi等,2016)中的亚像素卷积层将特征上采样到对应尺寸的超分辨率图像。
2.2 注意力嵌入的Transformer块
卷积层在前期视觉处理上会有更稳定的优化与更好的提取结果,而且具有空间不变滤波器的共解层可以增强网络的平移等效性(Liang 等,2021)。卷积层的叠加可以有效地增大网络的感受野。因此,将3 个级联的卷积层放置于CAETB 的前端,以接收前一个模块输出的特征,为了更好地调整不同层级与不同变换单元输出的特征,网络采用了基于通道注意力特征判别增强策略,将Transformer 特征与卷积特征进行通道注意力判别增强与交互融合。即对输入的Transformer变换特征与卷积处理后的特征进行可学习的通道注意力特征增强与交叉融合。通道注意力的生成方式将在2.4 节中进行详细介绍。将特征的输入设置为Fi,通道注意力特征判别增强的过程可以表示为
式中,A与D代表通道注意力参数,HCL表示级联的卷积层操作,3 个卷积层的通道数为60-45-60,中间采用LeakyReLU(leaky rectified linear unit,LReLU)函数进行特征激活。随后使用一个核大小为1 × 1 的卷积层将级联的特征调整为原通道数,其输出FR可表示为
式中,Concat代表特征级联操作,HC表示1 × 1 的卷积层操作,在经过注意力嵌入部分后,特征将输入到ST 模块进行进一步特征提取,模块的输出FS可表示为
式中,HSwin代表ST 模块的操作,STL(swin Transformer layer)在CAETB模块中的层数设置为4。
CAETB 的具体结构如图2 所示,由于CAETB 采用了残差连接结构,模块的最终输出Fi+1可以表示为
2.3 ST模块
ST 模块改进于标准Transformer 架构的多头注意力。标准Transformer架构会对图像进行全局自注意力计算,但全局注意力机制在图像尺寸增大时会出现复杂度急剧增长的情况,所以标准Transformer在视觉里的下游任务中,遇到较大尺寸的图像,会出现显存需求过高的问题。为了解决这个问题,ST 模块进行了局部注意力机制和窗口移位机制的改进。STL(swin Transformer layer)的总体结构如图3所示。
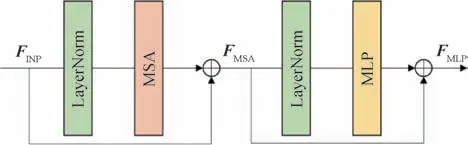
图3 STL内部结构图Fig.3 Internal structure of STL
对于给定大小为H×W×C的输入,ST 首先使用不重叠大小为M×M的局部窗口,将输入特征重塑为式中代表窗口总数,然后分别计算每个窗口的标准自注意力。对于本地窗口特征,查询、键和值矩阵Q、K和V的计算分别为
式中,PQ、PK和PV是跨不同窗口的共享可学习投影矩阵,且Q,K,V∈RM2×d。注意力矩阵Attention(Q,K,V)是通过局部窗口中的自注意力机制计算的,可以表示为
式中,B代表可学习的相对位置编码,d代表多头注意力的维度。多头自注意力(multi-head selfattention,MSA)的结果会串联起来,以保持特征的维数不变。接下来,使用多层感知器(multilayer perceptron,MLP)进行进一步的特征增强,该感知器具有两个全连接层,层之间使用了GELU(Gaussian error linear unit)函数以激活特征。在MSA和MLP之前添加LN(layer normalization)层,两个部分都使用残差连接。将特征的输入设置为FINP,则整体过程可用数学表达式描述为
式中,HLN表示LN 层操作,HMSA表示多头注意力操作,HMLP表示多层感知机操作。
虽然基于窗口分割的局部注意力机制可以降低计算的复杂度,但固定的窗口分区并没有相互的信息交流。ST 模块采用了移位窗口分割和交替使用规则以实现跨窗口连接。其中,移位窗口分割表示在进行特征窗口分割之前将特征移位(M/2,M/2)像素,交替使用规则表示移位与非移位的STL 会交替使用。这种方式解决了不重合的窗口之间不能进行信息交流的问题,显著增加了ST模块的感受野。
2.4 通道注意力机制
本节对2.2 节中的通道注意力参数A与D的计算进行详细介绍。通道注意力机制(Hu等,2018)通过建模特征通道间的相互依赖性,可以自适应调整不同通道的特征响应,为其分配相应的权重。通道注意力的嵌入可以将CAETB 中卷积与Transformer的对应特征进行自适应增强与融合。此外,由于卷积的局部操作特性,每个输出值不能概括整个图像的整体信息,为了在完整图像中选择最有效的特征,需要通道注意力的全局信息作为指导(Xiong等,2021)。
通道注意力机制的具体操作如图4 所示,将输入记为X=[x1,x2,…,xc],其包含c个通道平面大小为H×W的特征图。为了得到特征通道之间的全局特性,采用全局平均池化(global average pooling,GAP)以获得每个通道特征的统计特性,记为Z=[z1,z2,…,zc],则有

图4 通道注意力模块结构图Fig.4 Architecture of channel attention module
式中,xc(i,j)代表特征图xC中的位置(i,j)的数值,HGAP代表全局池化操作,用于计算代表每个特征图全局信息的平均值。
将上述信息输入第2 个过程,即权重学习(weight learning,WL)过程。权重学习过程包含两个全连接层、一个 ReLU函数和一个sigmoid函数,前者通过通道的挤压与激励以学习通道间的非线性交互关系,后者则将通道复原并对参数进行归一化,以保证网络能够同时关注多个重要的通道,该过程可以表示为
式中,HWL代表权重学习的整体过程,r(⋅)和s(⋅)分别代表ReLU 函数和sigmoid 函数,f1和f2则代表两个全连接层。
将学到的权重W=[w1,w2,…,wc]与原输入特征相乘。将调整后的结果记为X′=[x′1,x′2,…,x′c],则对应于第c幅特征图的调整结果可以表示为
式中,wc表示权重因子,用于改变原特征的权重比例,使得重要特征信息的权重能够增大。
2.5 损失函数
为了对比的公平性,仅使用L1 函数作为损失函数来优化网络,其中给定N对图像作为训练数据集可以将优化的过程表示为
3 实验结果及分析
3.1 实验设置
对于模型训练部分,本文的训练数据集采用了广泛应用于图像超分辨率任务的DIV2K 数据集(Agustsson和Timofte,2017)。其中,在800幅训练图像上以3 个比例因子(×2、×3 和×4)进行双三次下采样,以获得低分辨率输入图像,并通过随机垂直旋转与水平翻转来增强训练图像的数据多样性。网络的优化器采用了Adam 优化器(Kingma 和Ba,2017),其中,β1=0.9,β2=0.999,ϵ=10-8。训练的初始学习率为2 × 10-4,并分别在第150 000、300 000、400 000、450 000 批次减少到原学习率的一半,总共训练500 000 个批次。网络训练时每次输入32 幅(batchsize=32)尺寸为64 × 64像素的随机裁剪低分辨率图像。对于×3,×4 放大倍数的超分辨率网络,将在×2 放大倍数的预训练模型基础上进行训练,并将总训练迭代次数减半。
对于模型评估部分,本文采用了5 个常用的公共基准数据集:Set5(Bevilacqua 等,2012)、Set14(Zeyde 等,2010)、BSD100(berkeley segmentation dataset 100)(Timofte等,2014)、Urban 100(Huang等,2015)和Manga 109(Matsui 等,2017),它们涵盖了各种类型的图像特征与分辨率。峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似度(structure similarity index measure,SSIM)将作为客观评价标准,并在亮度通道上对数值进行定量评估。与此同时,采用模型的参数量与乘加量衡量各个模型的复杂度。其中,乘加量表示输入单个图像时,模型所需乘法与加法的累积操作数量,以输出图像为1 280 ×720像素作为基准值。所有实验都是在PyTorch平台上进行的,实验显卡为NVIDIA GTX 1080Ti GPU。
3.2 CAETB结构与数量的分析
为了验证CAETB 结构的有效性,将对通道注意力与Transformer进行不同的嵌入组合对结果带来的影响进行探究。
图5 展示了通道注意力嵌入于Transformer 之后的情况,通道注意力嵌入于Transformer 之前的情况则与CAETB相同。
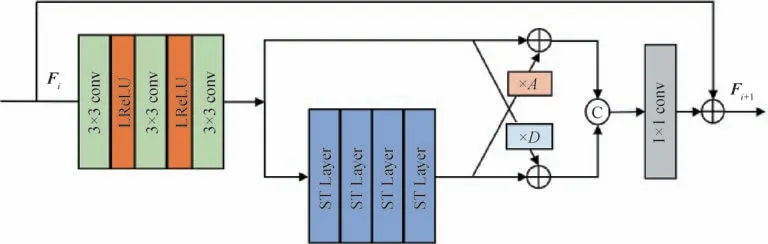
图5 通道注意力(CA)嵌入在Transformer层后Fig.5 Channel attention(CA)after Transformer layers
表1 显示了不同组合方式在放大比例因子×2时,对Urban100 与Set5 数据集重建质量的影响。可以看出,通道注意力嵌入于Transformer 层之前可以获得更好的重建性能。
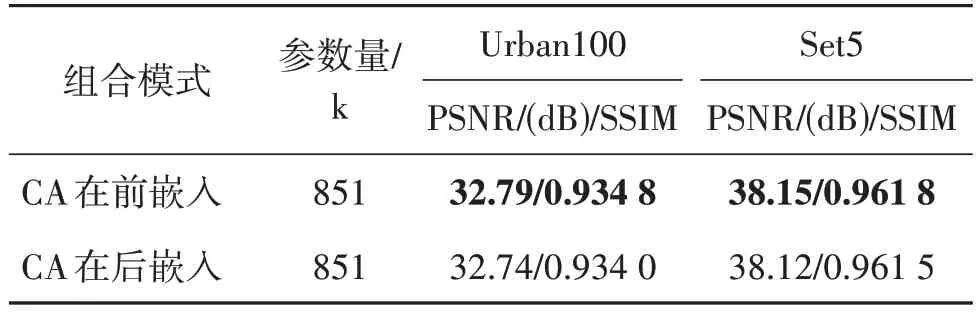
表1 CAETB的组合方式对重建性能的影响Table 1 Effect of the combination style in CAETB on the reconstruction performance
针对网络深度对提高重建性能起着重要作用,因此探究了CAETB 的个数从2 增加到5 时,对于网络重建效果的影响。表2 显示了在Set14 数据集上具有不同CAETB 数量的网络比例因子×2 的重建效果以及所需参数量的分析。如表2 所示,由于深度网络良好的非线性抽象能力,模块的数量越多,网络的性能也会随之提升。但同时也可以观察到,随着CAETB 个数的增加,恢复效果的提升会出现放缓的情况,这称为深层网络的饱和现象。为了平衡模型的复杂度与性能,选用4 个CAETB 组成基本的重建网络。

表2 CAETB数量对参数规模和在Set14上的重建质量影响Table 2 Effect of the number of CAETBs on parameter size and reconstruction performance on Set14
3.3 与其他算法的比较
为了验证算法的有效性,本文与双三次插值法、SRCNN 网络(Dong 等,2014)、CARN 网络(Ahn 等,2018)、IMDN 网络(Hui 等,2019)、LatticeNet 网络(Luo 等,2020)和SwinIR 网络(Liang 等,2021)等轻量级网络在不同放大因子(×2、×3、×4)下进行对比,这些算法性能优越并具有一定的代表性。
3.3.1 客观指标分析
本文算法与其他算法的PSNR和SSIM对比结果如表3—表5 所示。可以看出,CAET 的客观指标PSNR 和SSIM 在所有数据集的不同上采样因子上均处于领先地位。其中,在Urban100 数据集上,在上采样因子为2 时PSNR 领先第2 名0.03 dB,在上采样因子为3 时领先0.08 dB,在上采样因子为4 时领先0.09 dB。在Manga109 数据集的提升最为明显,在上采样因子为2 时领先第2 名0.13 dB,在上采样因子为3 时领先0.33 dB,在上采样因子为4 时领先0.30 dB。在模型复杂度方面,CAET 的参数量与乘加数均处于较低水平,并在模型复杂度小于同样使用Transformer 模型的SwinIR 的情况下,具有更好的恢复效果。为了进一步体现本文算法的有效性,网络将CATB 的数量减少到2 作为CAET-M,在复杂度明显小于IMDN 等基于卷积轻量级SR 算法的情况下,仍有一定的性能提升。结果表明,本文算法与这些轻量级方法相比,具有更好的综合性能。

表3 放大比例因子×2时,不同算法的平均PSNR/SSIM 对比Table 3 Average PSNR/SSIM comparison of different algorithms under magnification is 2

表4 放大比例因子×3时,不同算法的平均PSNR/SSIM 对比Table 4 Average PSNR/SSIM comparison of different algorithms under magnification is 3

表5 放大比例因子×4时,不同算法的平均PSNR/SSIM 对比Table 5 Average PSNR/SSIM comparison of different algorithms under magnification is 4
3.3.2 视觉效果分析
为了进一步验证网络的优势,将继续对标准数据集测试的一些代表性图像进行可视化结果分析。图6 展示了测试集图像Urban100_img012 放大因子为4 时的局部放大效果。可以看出,其他算法的建筑纹理均出现了恢复方向错误的情况,而CAET(本文)则准确地保留了建筑物的纹理结构。图7 则展示了图像B100_253027 中放大因子为4 时的局部放大效果。可以看出,相较于其他算法,本文算法恢复出的斑马条纹更加清晰准确。图8 展示了图像Set14_barbara 放大因子为4 时的局部放大效果,本文算法可以准确地恢复出书本的摆放情况,而其他算法均出现了不同程度的失真。结果表明,本文算法不仅在客观数值处于领先,也可以获得比所有比较方法更清晰的超分图像。

图6 不同算法对 Urban100中img012在尺度为4时重建效果对比图Fig.6 Comparison of reconstructed HR images of img012 in Urban100 by different SR algorithms at the scale factor ×4((a)Urban100_img012×4;(b)HR;(c)bicubic interpolation;(d)SRCNN;(e)CARN;(f)IMDN;(g)LatticeNet;(h)SwinIR;(i)ours)

图7 不同算法对 BSD100中 253027在尺度为4时重建效果对比图Fig.7 Comparison of reconstructed HR images of 253027 in BSD100 by different SR algorithms with the scale factor ×4((a)BSD100_253027×4;(b)HR;(c)bicubic interpolation;(d)SRCNN;(e)CARN;(f)IMDN;(g)LatticeNet;(h)SwinIR;(i)ours)

图8 不同算法对 Set14中 barbara在尺度为4时重建效果对比图Fig.8 Comparison of reconstructed HR images of barbara in Set14 by different SR algorithms with the scale factor ×4((a)Set14_barbara×4;(b)HR;(c)bicubic interpolation;(d)SRCNN;(e)CARN;(f)IMDN;(g)LatticeNet;(h)SwinIR;(i)ours)
3.4 消融实验
为了有效调整不同层级的特征,本文采用了基于通道注意力的判别增强策略。将不同层级的特征以通道注意力参数进行可调节的加权处理,不同于LatticeNet(Luo 等,2020)采用基于通道平均值与标准差作为调节参数,本文以通道注意力参数对不同层级的特征进行加权处理。
表6展示了放大因子×3时在多个数据集上两种不同权值生成策略的重建效果以及模型参数量的比较。实验数据表明,相较于Luo 等人(2020)基于通道平均值与标准差(mean pooling and standard deviation pooling,MSD)的特征增强策略,本文基于通道注意力(CA)判别增强的方法可以更好地将Transformer 特征与卷积特征进行交互融合,获得了更出色图像重建能力。

表6 放大因子×3时,不同权值生成方式的模型比较Table 6 Comparison of different weight generation methods of model at ×3 amplification factor
为了进一步探究通道注意力、线性加权以及特征聚合模块的作用,进一步对模型进行消融实验,以验证各个部分对系统性能的影响。具体来说,将线性加权结构更替为残差连接,并去除通道注意力与特征聚合模块作为Base 模型。本文将采用不同策略的模型分别记为 Base、A、B、C、D。
表7 展示了放大因子×4 时,在Manga109 数据集上,不同策略的模型对重建质量的影响。从表中可以看到,Base 模型表现稍差,仅获得 30.93 dB 的PSNR。而加入了多层特征融合的模型A有着0.19 dB的明显提升,这表明多层特征融合的方式在Transformer 为主的网络中依然适用。模型B 在模型A 的基础上采取串联的方式嵌入通道注意力,模型C 在模型A 的基础上加入了线性加权,但去除了可学习的通道注意力参数。模型B 与C 的PSNR 均有不同程度的提升,但同时添加了这两种策略的模型D 会有最显著的提升。因此,本文模型的设计策略不仅在单独使用时有效,在组合使用时更能有效地提升模型的恢复能力。本文的模型D 与Base 模型相比,PSNR 有0.29 dB 的大幅提升,参数量却仅有32 k 的提升。为了更直观地展示各部分的效果,本小节也对一些代表性的图像进行了可视化,其中重点关注通道注意力的嵌入对图像细节重建的改善。

表7 放大因子× 4时,在Manga109数据集上不同策略对模型重建性能的影响比较Table 7 Comparison of the effects of different strategies on model reconstruction performance on Manga109 at amplification factor ×4
图9 展示了图像Manga109_ARMS 中放大因子为4 时的局部放大效果。可以看出,相对于模型C,加入通道注意力的模型D可以更准确地恢复出图像的细节,这表明通道注意力的嵌入对图像重建效果具有积极意义。

图9 不同策略对 Manga109中ARMS在尺度为4时重建效果对比图Fig.9 Comparison of reconstructed HR images of ARMS in Manga109 with different strategy at the scale factor ×4((a)Manga109_ARMS×4;(b)HR;(c)model C;(d)model D(ours))
4 结论
为了有效实现网络重构性能与模型复杂度轻量化的平衡,提出了一种基于通道注意力嵌入的Transformer 图像超分辨率方法。通道注意力自适应嵌入Transformer变换特征及卷积运算特征并交互融合,不仅充分利用了卷积运算与Transformer 变换在图像特征提取上的各自优势,而且得到了特征的自适应增强。大量的实验结果展示,与目前主流的轻量级超分辨率算法相比,本文方法在轻量化网络模型与改进超分辨率重构性能方面均具有较好的效果。
本文网络在模型轻量化与超分辨率性能上均取得了一定效果。但是,本文实验是在双三次下采样退化模型基础上展开,而现实获取的图像会有压缩失真、噪声污染等更加复杂的退化因素。因此,在人工操作数据集上训练的模型对于真实图像的恢复效果会减弱。
针对现有方法的不足,未来工作将重点研究如何提升模型在现实中的通用性。目前,设计适应多个退化模型的盲超分辨率网络同样存在模型复杂的问题。下一步,将针对盲超分辨率网络模型的轻量化问题展开进一步研究。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
数学物理学报(2019年3期)2019-07-23
电子制作(2019年11期)2019-07-04
家庭影院技术(2018年9期)2018-11-02
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
第二课堂(课外活动版)(2016年2期)2016-10-21
