
用于多光谱和高光谱图像融合的联合自注意力Transformer
2023-12-23 10:14:32李妙宇付莹
中国图象图形学报 2023年12期
李妙宇,付莹
北京理工大学计算机学院,北京 100089
0 引言
高光谱图像(hyperspectral image,HSI)包含丰富的光谱信息,相比于多光谱图像(multispectral images,MSI),可以更好地反映出物体的材质信息,在目标探测(Liang 等,2013;Li 等,2015)、农业检测(Adão 等,2017)和人脸识别(Uzair 等,2015)等领域有着广泛的应用。但由于光通量和成像系统的限制,高光谱图像难于同时具有较高的空间分辨率和光谱分辨率。将低空间分辨率的高光谱图像(lowresolution hyperspectral image,LR-HSI)和高空间分辨率的多光谱图像(high-resolution multispectral image,HR-MSI)进行融合,从而获得高空间分辨率的高光谱图像(high-resolution hyperspectral image,HR-HSI),是一种行之有效的提升高光谱图像空间分辨率的方法。
目前已有的高光谱图像融合超分辨率方法主要分为两类,一类是基于优化模型的方法,另一类是基于深度学习的方法。基于优化模型的方法将各种图像先验知识与优化过程相结合(Peng等,2021;Zhang等,2018a),通过最大后验概率来融合高光谱图像和多光谱图像,实现高光谱图像的超分辨。其中,基于矩阵分解的方法(Kawakami等,2011;Liu等,2020;Li等,2021)将LR-HSI 和HR-MSI 分别进行解混,获得表征光谱信息的字典矩阵和表征空间信息的系数矩阵,根据字典矩阵和系数矩阵,恢复出HR-HSI。基于贝叶斯表示的方法(Akhtar 等,2015)使用非参数贝叶斯字典学习图像的光谱分布和空间分布来进行高光谱图像超分辨。Zhang 等人(2018b)通过流形聚类方法来保留多光谱的空间域信息,以此对后验高光谱图像进行约束和超分辨。此外,全变分正则约束(Wang 等,2017;Li 等,2022)、相似性约束(Han等,2018)和子空间约束(Simões 等,2015)也被用于高光谱融合超分辨中,以获得更好的融合效果。虽然这些基于优化模型的方法表现良好,但它们往往依赖于手工提取的先验特征,对多样性的场景适应有限,且融合模型复杂,需要长时间的迭代优化。
深度学习在高光谱图像融合超分辨领域开始得到广泛应用。其通过大规模的数据集来自动地学习网络输入到输出的映射,降低了图像融合过程对手工提取特征的依赖,因此,这类方法往往能取得比基于优化模型的方法更好的融合效果。根据优化方法和网络设计方式的区别,基于深度学习的融合方法又可以分为深度展开的方法和端到端的方法。
深度展开方法将深度网络和传统迭代模型相结合,将迭代过程中的部分环节用深度网络代替,使得整体网络具有更好的可解释性。Xie 等人(2022)利用图像的低秩先验信息,对网络进行多次迭代优化,从而获得高分辨率的融合图像。Dong 等人(2021)将高光谱图像的退化矩阵用网络来表示,利用迭代算法来优化融合网络和退化网络。
端到端的深度学习融合方法主要探索如何设计深度网络来提取多源图像的空间信息和光谱信息。Zhang 等人(2021)将退化矩阵的估计与深度网络相结合,实现高光谱图像的融合超分辨。此外,为了更好地融合光谱特征和空间特征,Yao 等人(2020)提出基于交叉注意力机制的无监督融合网络,对光谱分支的信息和空间分支的信息进行交互,但其融合结果受网络初始化影响大,且需要较长时间来进行优化。Hu 等人(2021)提出一种基于深度空间—光谱注意力的卷积网络,以保留图像的光谱信息和空间信息,但此方法获得的特征表征能力不足,容易出现过拟合现象。
LR-HSI 在光谱维度上表现出高度相关性,HRMSI 则在空间纹理上有明显的自相似性,因此,待融合图像中像素或波段间存在着依赖关系。这种依赖关系不仅限于邻近像素,长距离像素间同样具有一定相似性依赖,充分利用这种内在依赖关系可以有效提高融合图像的空间质量和光谱保真度。现有的深度学习方法(Dong 等,2021;Hu 等,2021;Yao 等,2020)虽然表现良好,但是仍缺少对多源图像中内在依赖关系的联合探索。在HR-HSI 和HR-MSI 的融合阶段,往往使用退化估计模型(Dong 等,2021;Yao等,2020)或直接叠加(Hu等,2021;Xie等,2022)的方式,对图像的自相似性关注度不够,造成融合图像光谱细节或空间纹理的丢失;此外,在深度特征提取阶段,以往的方法大多基于卷积神经网络设计,其感受野受限于卷积核的大小,不能很好地表征长距离像素或波段间的依赖关系。此外,由于卷积核的参数固定,以往方法也难于动态地表达图像特征,融合表现也因此受限。
Transformer 网 络(Vaswani 等,2017;Wang 等,2021b)在自然语言、图像处理等领域取得了良好的效果,其核心为自注意力模块,利用自相似性度量矩阵,可以动态建模序列间的关联程度,从而有效地提取长距离依赖关系,更好地表达图像特征。然而,现有的Transformer 网络大多针对RGB 图像设计,没有明确考虑到高光谱图像和多光谱图像的特性,难于适配高光谱图像融合问题。
针对上述问题,本文提出一种联合自注意力高光谱图像融合超分辨Transformer 网络,有效地从光谱相关性和空间相似性对多源图像进行融合,利用融合特征间的长距离依赖关系充分挖掘融合特征的深度先验知识。首先,采用联合自注意力模块,从光谱维度和空间维度进行多源图像的融合,在保留全局光谱信息的同时,提高图像的空间分辨率。具体地,通过相似性度量矩阵,分别提取LR-HSI 的光谱相关性信息和HR-MSI 的空间相似性信息,从而保留光谱信息和空间信息;然后,利用提取的光谱相关性特征和空间相似性特征对融合过程进行引导,获得初步超分图像;最后,考虑融合特征也存在内在相似性,通过一系列堆叠的残差Transformer块对融合特征进行优化,增强网络长距离依赖关系表征能力,从而获得高空间分辨率的高光谱融合图像。
本文的主要贡献点如下:1)提出联合自注意力融合模块,有效地从光谱相关性和空间自相似性两个层面,对低分辨率高光谱和多光谱图像的信息进行融合;2)在模型中引入Transformer深度融合网络,通过对融合特征中长距离像素间依赖信息的探索,增强融合特征;3)实验结果表明,从定量指标和视觉效果上,本文的方法都取得了比当前先进方法更好的融合超分辨结果,在提升高光谱图像空间分辨率的同时,准确地保留了光谱信息。
1 问题建模
设Y∈RB×n表示LR-HSI,B、h和w分别表示图像光谱维的波段数目和空间维的长和宽。设Z∈Rb×N表示HR-MSI,N=H×W,b、H和W分别表示图像光谱维的波段数目和空间维的长和宽,其中,b≪B,n≪N。融合LR-HSI 和HR-MSI 获得的HRHSI 则表示为X∈RB×N。这些光谱图像之间的关系可以线性建模为
式中,D∈RN×N为空间模糊矩阵,S∈RN×n为空间降采样矩阵,P∈Rb×B为多光谱相机的光谱响应曲线。由于从LR-HSI和HR-MSI中观测到的值数量要远远小于HR-HSI 的未知值数量(Bn+bN≪BN),这类融合问题是一个病态的逆问题,往往需要通过先验知识来对融合过程进行约束。因此,高光谱融合超分辨问题的优化过程通常可以表示为
式中,‖ · ‖F为Frobenius 范数。式中前两项为优化过程的保真项,ϕ(X)为先验正则项,λ是权重系数。
基于传统优化模型的高光谱融合方法使用不同的先验项来迭代优化目标融合图像。基于深度学习的方法则不需要显式地引入手工设计的先验项,其往往在有监督框架下,通过深度网络,从大量数据中学习图像的内在先验知识。在训练过程中,可以认为HR-HSIX是已知的。令fθ表示网络从双输入到单输出的映射,θ为网络参数,基于深度学习方法的优化过程可以表示为
本文通过设计并训练更为合适的深度网络fθ,对LR-HSI和HR-MSI进行融合,获得目标HR-HSI。
2 联合自注意力Transformer网络
本文所提出的网络结构如图1 所示。网络整体主要包括3 部分,第1 部分为联合自注意力融合模块,对双输入光谱图像进行初步融合;第2 部分为深层的Transformer 融合网络,以获取更具有代表性的图像先验知识;最后,输出特征通过卷积层映射为目标高分辨率的高光谱图像。具体地,给定LR-HSIY和HR-MSIZ,模型首先对输入进行空间维度和光谱维度上的对齐。Y通过插值操作进行空间上采样,从而获得与HR-MSI 空间大小一致的上采样图像YU。随后YU和Z都通过1 × 1 卷积层进行光谱维度的对齐,对齐后的初步特征通过联合自注意力模块进行融合,再通过一系列堆叠的Transformer 网络,进一步恢复空间细节和光谱信息。最后,输出特征通过3 × 3 卷积将融合特征映射为HR-HSIX。
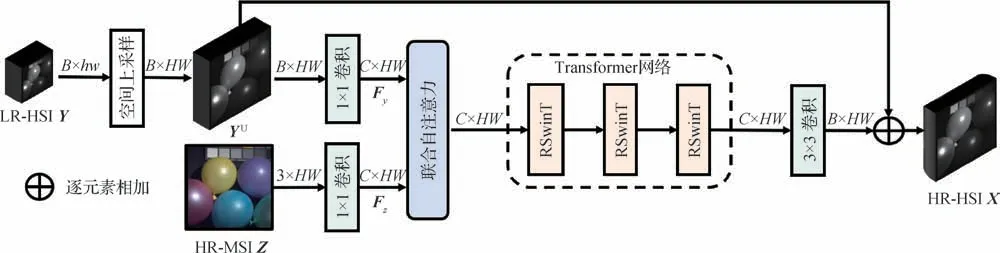
图1 联合自注意力的Transformer高光谱融合超分辨网络示意图Fig.1 Architecture of the joint self-attention-based Transformer for hyperspectral image super-resolution
2.1 联合自注意力融合模块
高光谱图像融合超分辨的目标是在保留丰富的光谱信息的同时,提高图像的空间分辨率。因此,有效地利用LR-HSI的光谱信息和HR-MSI的空间信息是提高融合图像质量的关键。高光谱图像具有光谱带多、带宽窄的特点,其波段间具有高度相关性;同时,多光谱图像本身在空间上存在纹理的自相似性。直接对LR-HSI和HR-MSI进行拼接并输入到深度网络中,易导致空间细节和光谱信息的丢失。从图像内在特性出发,本文采用联合自注意力模块,充分利用多源图像的光谱相关性和空间自相似性。通过光谱注意力机制,从LR-HSI 中提取出光谱相关性特征;使用空间注意力机制,从HR-MSI 中提取出空间相似性特征;利用相似性特征,指导多源图像的融合,更有效地融合LR-HSI和HR-MSI。
如图2 所示,本文提出的联合自注意力融合模块首先利用3 × 3卷积层对来自LR-HSI的特征Fy和来自HR-MSI 的特征Fz进行初步融合,获得注意力模块共享的输入Fv;光谱注意力模块的查询向量Qy和键向量Ky由Fy得到,空间注意力模块的查询向量Qz和键向量Kz由Fz得到,它们的键向量由共享的输入Fv得到;最后,将并行的光谱注意力模块和空间注意力模块的输出拼接,通过3 × 3 卷积层,从而获得光谱—空间融合特征。

图2 联合自注意力融合模块示意图Fig.2 Architecture of the joint self-attention fusion module((a)overall architecture of the proposed module;(b)architecture of spectral attention module;(c)architecture of spatial attention module)
2.1.1 光谱注意力模块
如图2(b)所示,光谱注意力模块通过光谱注意力矩阵,提取LR-HSI的光谱信息。为增强模型表征能力,来自LR-HSI 的特征Fy∈RC×HW首先分别通过两个1 × 1 卷积层,获得查询向量Qy和键向量Ky;初步融合的特征Fv∈RC×HW同样通过一个1 × 1 卷积层,获得值向量Vy。C表示特征维度,H和W为特征的长和高。这一过程可表示为
式中,α为可学习的缩放参数。
在网络实现中,为获得更加具有多样性的特征,增强网络泛化性,在矩阵乘法计算时,将Qy、Ky和Vy按照通道维度划分为Nh头的形式,在不改变计算量的同时,提高了自注意力机制的表达能力。最后,基于光谱注意力机制获取的特征fy通过1 × 1 卷积层,进行线性映射后输出。
2.1.2 空间注意力模块
多光谱图像一般具有较大的空间分辨率,直接在多光谱图像上使用基于全局空间的注意力机制将会带来极大的运算量。为了在融合质量和运行时间中取得平衡,本文使用基于窗口的空间自注意力模块,对HR-MSI 的空间信息进行提取。如图2(c)所示,在空间注意力模块中,首先将输入的特征Fz∈RC×HW和Fv∈RC×HW拆分为不重叠的块,分别表示 为其 中,且K表 示空 间降采样倍数。
式中,β为可学习的缩放参数。
在空间注意力模块中,同样使用多头并行的方式来进行计算。与光谱注意力有区别的是,空间注意力模块计算出的空间相似性矩阵为KK×KK,表征了窗口中像素的相似程度。此外,基于窗口获得的注意力矩阵在通过1 × 1 卷积后,需要通过合并窗口操作,合并为fz∈RC×HW。
2.2 Transformer融合网络
联合自注意力模块对LR-HSI和HR-MSI从空间信息和光谱信息两个维度进行融合,但这种融合特征仍然比较浅层,需要后续网络对融合特征进一步挖掘。以往的深度学习融合方法大多基于卷积神经网络,缺少对特征间长距离依赖的探索。近年来,Transformer 网 络(Chen 等,2021;Dosovitskiy 等,2021;赵琛琦 等,2022)在图像处理领域取得了良好的效果,可以有效利用图像的自相似性,在建模长距离依赖关系上相比于卷积操作,更具有优势。本文将Transformer 网络作为融合网络的主干,其包含3 个基于偏移窗口的残差Transformer 块(residual shifted windows Transformer,RSwinT),每个RSwinT模块的具体结构如图3 所示。在初步融合特征的基础上,进一步探索深度特征间的长距离依赖信息,从而实现更好的融合效果。给定初步融合特征,Transformer深度网络可表示为
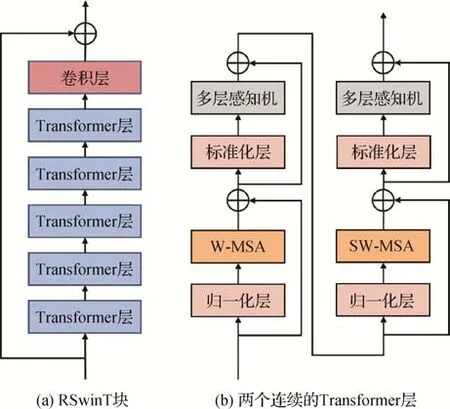
图3 基于Transformer的深度融合网络示意图Fig.3 Flowchart of deep Transformer fusion network((a)RSwinT block;(b)two successive Transformer blocks)
每个RSwinT 模块包含6 个Transformer 层和1 个卷积层。具体地,来自上一模块的输入首先通过连续的Transformer层,再通过卷积层输出,即
式中,P=6,表示第i个RSwinT 模块第j层的输出表示第i个RSwinT 模块的最终输出。此外,为了使得不同层级模块的输出可以更好的融合,防止网络梯度弥散,在模块中引入了残差连接。
Transformer 层由空间注意力模块(multi-head self-attention,MSA)、归一化层(layernorm,LN)、多层感知机(multilayer perceptron,MLP)构成。假设Transformer 层的输入为I,输出为I′′,包含残差连接的Transformer层的计算为
输入特征首先通过归一化层,从通道维度对特征进行归一化,随后,通过基于窗口的注意力层,有效地探索融合特征中的长距离依赖信息;随后再次进行归一化,防止训练过程中的梯度消失和梯度爆炸问题;最后,通过多层感知机进行输出。
受Liu 等人(2021)方法的启发,使用基于偏移窗口的Transformer 结构,如图3(b)所示,分别包含表示基于窗口的空间注意力模块(window-based multi-head self-attention,W-MSA)和基于偏移窗口的空间注意力模块(shift window-based multi-head selfattention,SW-MSA)。
3 实验结果和分析
3.1 数据集
为了验证本文方法的有效性,本文在CAVE 数据集和Harvard 数据集上进行8 倍降采样和16 倍降采样上的对比实验及分析。CAVE 数据集由通用像素摄像机拍摄,包含32 幅室内真实场景下的高光谱图像。每幅图像的空间分辨率为512 × 512 像素,包含31 个光谱通道,以10 nm 的间隔覆盖了400 nm 到700 nm 的波长。Harvard 数据集中有50 幅真实场景下的高光谱图像,其光谱范围为420 nm 到720 nm,具有31 个光谱通道。相较于CAVE 数据集,Harvard数据集的空间分辨率更高,每幅图包含1 392 ×1 040像素,因此相邻像素间的光谱信息更加平滑。
本文选用CAVE 数据集的前20 幅图像用于训练,后12 幅图像用于测试。对于Harvard 数据集,使用前30 幅高光谱图像作为训练,后20 幅用于测试。为了降低传统方法的测试时间,在测试时,将来自Harvard 测试数据从中心裁剪为512 × 512 × 31 的图像。训练图像被交叠裁剪为96 × 96 × 31的图像,通过例如翻转和旋转等数据增强方法,获得更多的训练数据。参照Dong 等人(2021)的设置,这些真值图像先通过8 × 8的高斯模糊核进行平滑,然后进行空间均值降采样,获得低空间分辨率的高光谱图像;通过尼康D700相机的响应曲线,对真值图像进行光谱降采样,获得RGB 图像。这些成对的低分辨率高光谱图像和RGB 图像将作为LR-HSI 和HR-MSI,输入到网络中。其对应的未经过降采样处理的真值高光谱图像作为HR-HSI,与网络的输出进行损失函数计算,从而对网络进行训练。
3.2 参数设置及实验环境
本文的融合网络使用Adam(Kingma 和Ba,2017)优化器进行训练,采用均方误差作为损失函数,其中学习率设置为1 × 10-4,50轮次后下降为1 ×10-5,总训练轮次为100,训练批次为16。本文网络由PyTorch 实现,并在NVIDIA GeForce 3090 下进行训练和测试。
3.3 对比方法及评价指标
为了评估所提出方法的性能,将本文提出的方法与NSSR(non-negative structured sparse representation)(Dong 等,2016)、MHF-Net(MS/HS fusion network)(Xie 等,2022)、UAL(unsupervised adaptation learning)(Zhang 等,2020)、CUCaNe(tcoupled unmixing cross-attention network)(Yao 等,2020)、MGD(model-guided deep network)(Dong 等,2021)、EDBIN(enhanced deep blind hyperspectral image fusion network)(Wang 等,2021a)和HSRNet(hyperspectral image super-resolution network)(Hu 等,2021进行比较。NSSR是基于模型的传统方法,其余方法为基于深度学习的方法。MGD 和EDBIN 采用深度展开的方式,CUCaNet 采用无监督的方式,对网络进行训练。
为了对融合结果进行定量评价,使用峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似性指数(structural similarity index,SSIM)、光谱角映射(spectral angle mapper,SAM)和相对全局融合误差(erreur relative globale adimensionnelle de Synthèse,ERGAS)四个指标对本文方法与对比方法进行评价。其中,PSNR、SSIM、ERGAS 对图像的全局融合质量进行评估,SAM 用于衡量图像光谱信息的完整程度。PSNR 和SSIM 越高,代表融合图像与真值高光谱图像差异越小。SAM 和ERGAS越大,代表融合结果与真值高光谱图像差异越大。
3.4 定量分析
表1 以数值结果的形式展示了CAVE 数据集上,8 倍降采样倍数和16 倍降采样倍数下本文方法与对比方法的融合结果。可以看到,本文方法在所有定量评价指标上都取得了最好的结果。相比于基于优化模型的传统方法NSSR,本文方法在8 倍采样率和16 倍采样率下,PSNR 提高了5 dB。相较于深度学习方法中表现比较好的EDBIN 和MHFNet,本文方法在16 倍采样率下,PSNR 提高了至少0.8 dB,ERGAS 下降了至少0.5。相较于其他对比方法,本文方法也取得了最低的SAM 值和ERGAS值,表明其具有更好的光谱信息保留能力。

表1 不同算法在8倍和16倍降采样的CAVE数据集12幅图像上的平均结果Table 1 Average results of the comparative methods over 12 testing samples of CAVE dataset for scaling factor 8 and 16
表2 展示了8 倍降采样率和16 倍降采样率下,本文方法与对比方法在Harvard 数据集上融合实验的数值结果。其中,无监督深度学习方法CUCaNet的融合结果不佳。在4 个评价指标上,本文方法都取得了最好的融合结果。相较于第二好的方法EDBIN,本文方法在PSNR 这一指标上提高了至少0.4 dB,说明本文提出的方法相较于其他融合方法,具有明显优势,能够更好地融合LR-HSI的空间纹理信息和HR-MSI的光谱信息。同时,对比CAVE 数据集上的结果,可以看到Harvard 数据集上,本文方法和对比方法的融合效果都普遍更好,说明在Harvard数据集上的融合更简单。

表2 不同算法在8倍和16倍降采样的Havard数据集20幅图像上的平均结果Table 2 Average results of the comparative methods over 20 testing samples of Harvard dataset for scaling factor 8 and 16
3.5 可视化分析
图4 和图5 分别展示了CAVE 数据集和Harvard数据集上高分辨率图像真值、低分辨率高光谱图像和可视化误差图像。其中,误差图由真值高光谱图像与融合图像的误差绝对值生成,误差越小说明融合结果越好。总体上,本文方法取得了最好的融合效果。以图4 为例,在图像边缘处,UAL 方法和HSRNet方法的融合结果误差较大,说明它的融合结果相比于目标高分辨率高光谱图像有一定差距,没有很好地保留空间纹理信息。虽然MGD 方法和EDBIN 方法整体上取得了比较好的融合效果,但在细节上,仍有空间信息的缺失。本文方法通过联合自注意力模块,有效保留了光谱信息和空间信息,并通过Transformer深度网络提取特征中的长距离依赖信息,从而在图像的整体视觉效果和空间细节保留上,都获得了更优的恢复结果。

图4 8倍降采样率下CAVE数据集在第20个波段上的重建结果误差图Fig.4 Error maps of reconstructed images at the 20-th band on CAVE dataset under scale factor=8((a)HR-HSI;(b)LR-HSI;(c)NSSR;(d)MHF-Net;(e)UAL;(f)CUCaNet;(g)MGD;(h)EDBIN;(i)HSRNet;(j)ours)

图5 16倍降采样率下Harvard数据集在第20个波段上的重建结果误差图Fig.5 Error maps of reconstructed images at the 20-th band on Harvard dataset under scale factor=16((a)HR-HSI;(b)LR-HSI;(c)NSSR;(d)MHF-Net;(e)UAL;(f)CUCaNet;(g)MGD;(h)EDBIN;(i)HSRNet;(j)ours)
3.6 光谱保真度分析
图6 展示了在CAVE 数据集和Harvard 数据集上不同融合方法获得的融合图像和真值图像在光谱维的均方根误差(root mean square error,RMSE)结果图。RMSE 越低,说明该融合波段越接近真实值。其中,图6(a)为CAVE 数据集上16 倍降采样下的结果,图6(b)为Harvard 数据集上8 倍降采样下的结果。从图6 中可以看出,CUCaNet 的融合结果与真实图像误差较大,没有很好地保留光谱信息。本文方法在各个波段都取得了较低的RMSE 值,说明本文方法有效地保留了高光谱图像的光谱信息。
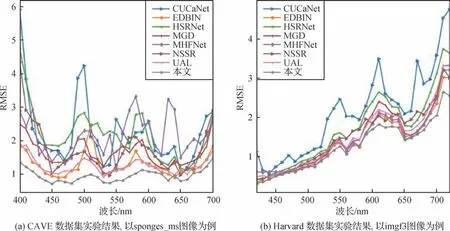
图6 本文方法和对比方法在光谱维度的重建误差结果图Fig.6 RMSE comparison results of our method and comparison methods in the spectral dimension((a)results on Cave datase(tsponges_ms image);(b)results on Harvard datase(timgf3 image))
3.7 运行时间和PSNR分析
表3 展示了本文方法与对比方法在单幅测试图像上的平均运行时间和PSNR 的对比。无监督高光谱融合超分方法NSSR和CUCaNet耗时最长,相比于有监督超分方法,PSNR 也更低。虽然HSRNet 方法的运行时间最少,但融合结果与其他有监督超分方法有较大差距。相较于UAL 和MGD,本文方法在PSNR指标上的结果提高了2 dB,并且以更少的运行时间,取得了比EDBIN和MHF-Net更好的结果。
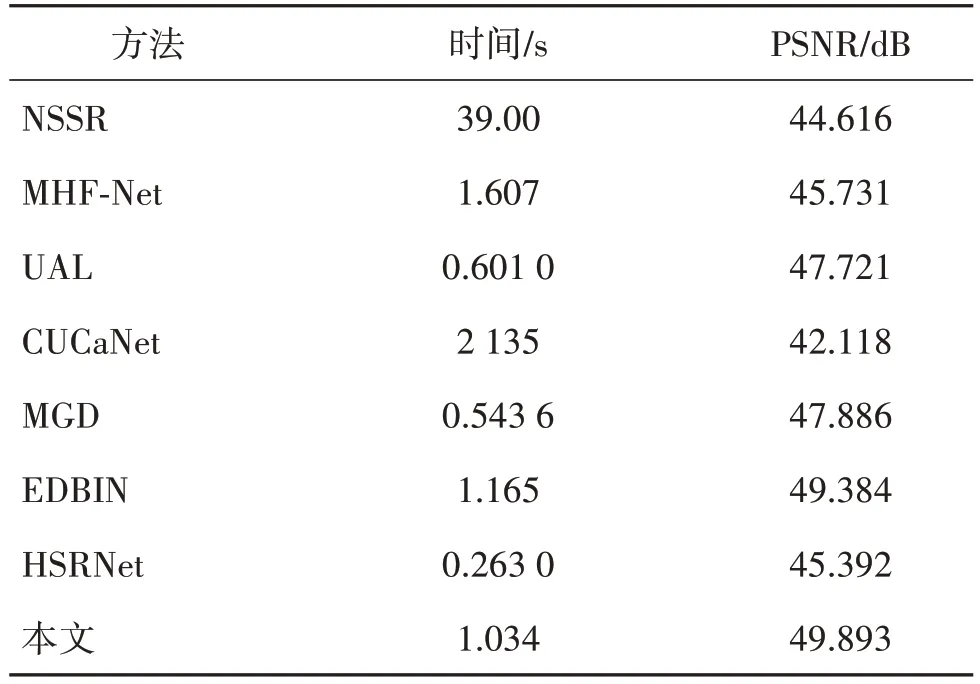
表3 不同融合方法的平均运行时间及PSNR对比Table 3 Inference time and PSNR comparison of different fusion methods
3.8 与Transformer方法对比
为进一步验证本文方法的有效性,将其与3 个Transformer 图像恢复方法对比,包括Uformer(Wang等,2022)、Restorme(rZamir等,2022)和SwinIR(Liang等,2021)。实验在8倍降采样率下的CAVE数据集上进行。为了适配多光谱和高光谱图像融合任务,通过插值对LR-HSI进行空间上采样,与HR-MSI拼接,作为对比方法的输入。结果如表4所示,本文方法以更小的参数量取得了更好的结果,验证了本文方法在高光谱图像融合任务上的优越性。

表4 与其他Transformer方法的对比结果Table 4 Comparison results of Transformer-based methods
3.9 消融实验
本文方法主要包含联合自注意力模块和Transformer 深度网络两部分。为了验证本文方法中这两部分的有效性,对其分别进行消融实验。实验统一在16 倍降采样的CAVE 数据集上进行训练和测试。对于每个实验,除了是否包含所需验证的模块这一区别,其他实验设置均保持一致。
首先,对联合自注意力模块进行单独实验,去除深度融合网络部分,将联合自注意力模块的融合结果直接输出。同样地,进行Transformer 深度网络的单独实验,为了进行LR-HSI 和HR-MSI 的图像初步融合,将联合自注意力模块替换为一层卷积网络,再输入到Transformer 深度网络中进一步融合。如表5所示,从实验结果可以看出,仅使用联合自注意力模块对多光谱和高光谱图像进行融合,也能以0.29 M的参数量,取得不错的融合效果。但相比于仅使用Transformer 深度网络的融合结果,PSNR 低了4 dB,说明提取深度特征的重要性。将联合自注意力模块与Transformer 深度网络相结合,可以进一步提高融合效果,PSNR 提高了0.27 dB,参数量却只增加了0.08 M,从而验证了本文方法的合理性和有效性。

表5 本文方法各模块的有效性验证Table 5 The effectiveness of modules in proposed method
此外,由于UNet 网络(Ronneberger 等,2015)在多种图像恢复任务都取得了不错的效果,将其作为消融实验中的对比网络,以突出本文所提出的Transformer深度网络的优势。同样采用联合注意力模块来初步融合特征,本文的Transformer 深度网络相比于基于卷积的UNet网络,能建模深度特征中的长距离依赖关系,因此,以更低的参数量,获得了更好的融合结果。
4 结论
本文提出用于多光谱和高光谱图像融合的联合自注意力Transformer 网络,有效地利用低分辨高光谱图像的光谱相关性信息和高分辨多光谱图像的空间相似性信息,探索深度特征中长依赖关系,对高光谱图像进行超分辨。首先,本文通过联合注意力模块对图像进行初步融合,通过光谱注意力机制提取低分辨高光谱图像的光谱相关性;同时,通过空间注意力机制提取多光谱图像的空间自相似性;将相似性信息用于指导图像的融合过程。然后,融合特征通过残差Transformer 融合网络,探索融合特征间的长距离依赖关系,获得更加深层的特征表示,进而重建出具有高光谱分辨率和高空间分辨率的融合图像。定量实验与定性实验表明,本文提出的多光谱和高光谱图像融合超分辨方法具有更好的光谱保真度和空间清晰度。本文方法建立在高光谱图像空间降采样函数和光谱降采样函数已知的前提下,因此,后续可以进一步针对盲高光谱图像融合问题,进行方法的改进和探索。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:58:58
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
中国光学(2015年5期)2015-12-09 09:00:28
食品工业科技(2014年23期)2014-03-11 18:18:54
