
融合通道位置注意力机制和并行空洞卷积的人脸年龄合成
2023-12-23 10:14张珂于婷婷石超君娄文硕刘阳
中国图象图形学报 2023年12期
张珂,于婷婷,石超君*,娄文硕,刘阳
1.华北电力大学电子与通信工程系,保定 071003;2.华北电力大学河北省电力物联网技术重点实验室,保定 071003
0 引言
人脸年龄合成致力于在不改变特定人脸图像身份特征的基础上模拟人脸过去或未来的变化。随着科技不断进步,人脸年龄合成技术逐步应用于人脸识别(Zhang 等,2021)、电影特效(Pumarola 等,2018)和公共安全(封顺和高胜极,2022)等领域,具有广泛的应用场景。然而人脸衰老进程不仅受年龄影响,还受外界环境因素干扰,具有较大个体差异(张珂等,2019)。此外,受年龄样本数据收集困难等问题制约,人脸年龄合成任务富有挑战性。
近年来,基于深度学习模型的人脸年龄合成方法逐步取代传统基于物理模型和原型的方法(Fu等,2010),取得显著效果。其中基于生成对抗网络(generative adversarial network,GAN)的人脸年龄合成方法作为主流方法(Li等,2018;Liu 等,2019a),在合成高质量、年龄转换准确且自然的人脸图像上取得优异的成果。
国内外研究人员已开展丰富的人脸年龄合成模型研究。Yang 等人(2018)提出将生成对抗网络(GAN)应用于人脸年龄合成任务,可在规定年龄范围内实现年龄转换。为增强图像的身份一致性,Tang 等人(2018)提出了身份保存模块,旨在保证经过年龄合成后的人脸图像与输入人脸具有相同身份特征,但该模型的输出图像与原始输入相比,丢失了部分细节信息。针对以上问题,Li 等人(2021)将简单年龄估计器嵌入到常规编码器—解码器架构,通过与生成器联合训练年龄估计器来为面部年龄合成任务推导出个性化年龄嵌入。Zhu 等人(2020)引入了全局和局部注意力机制以替代像素损失,有效减少了图像模糊的问题,保留了背景信息和人脸身份信息。为进一步限制对年龄无关区域的修改,Alaluf等人(2021)提出了一种基于StyleGAN 的年龄转换方法(style-based age manipulation,SAM),该方法的生成器编码结构基于经过预训练的StyleGAN,将真实人脸图像映射到潜空间中。SAM将连续的老化过程作为输入年龄和期望年龄之间的回归任务,学习解耦的非线性路径,为生成的图像提供细粒度的控制。
上述方法在年龄合成任务中取得了一定效果,但仍存在一些共性问题。目前人脸年龄合成模型过多关注人脸纹理信息,但是人脸年龄特征不是单一特征,而是多尺度特征的集合,年龄改变进程在人脸上表现为轮廓、发色和纹理等多尺度特征的协同变化。由于卷积层感受野范围受限,卷积层难以捕获图像中长距离像素间的依赖性,对图像多尺度特征提取不充分。而随着卷积层堆叠,模型网络深度增加,有效信息淹没在冗余信息中,制约了网络对人脸年龄显著区域的编辑能力。
为解决以上问题,本文有效提取了人脸图像多尺度特征,并针对人脸年龄合成任务中关键特征筛选和对人物身份保持问题进行了更进一步的探究。本文贡献如下:1)提出了并行三通道空洞卷积残差块,采用3 种不同膨胀系数的空洞卷积核提取和融合不同尺度的人脸特征,让身份和细节特征更丰富,其中空洞卷积间共享参数。2)设计了通道—位置注意力机制,对人脸特征的长度、宽度和深度3 个维度,分别进行了显著性计算,增加了模型感知力,解决了特征冗余问题。3)在FFHQ(Flickr-faces-highquality)数据集上验证了本文提出的PDA-GAN(GAN composed of the parallel dilated convolution and channel-coordinate attention mechanism)具有优良的身份保持能力和年龄生成准确性。
1 本文方法
本文提出了基于并行三通道空洞卷积残差块(parallel three-channel dilated convolution residual block,PTDCRB)和通道—位置注意力机制(channelcoordinate attention mechanism,CCAM)的人脸年龄图像合成模型,结构如图1 所示。该方法引入了PTDCRB,在不增加参数计算量的同时可获得更大的感受野。同时,PTDCRB的3个不同膨胀系数的支路也融合了不同尺度人脸特征,弥补了单一卷积核感受野受限问题,提升了特征尺度上的多样性和总量上的丰富度,为人脸图像合成提供了丰富信息。此外,本文提出CCAM,使模型能够学习图像通道和空间位置的显著性特征——对人脸特征的长度、宽度和深度3 个维度,分别进行了显著性计算,增强了网络对整体面部图像以及面部纹理的分析能力。结合在FFHQ 数据集上预训练的生成器解码器,构建了一个端到端的人脸年龄图像合成模型。
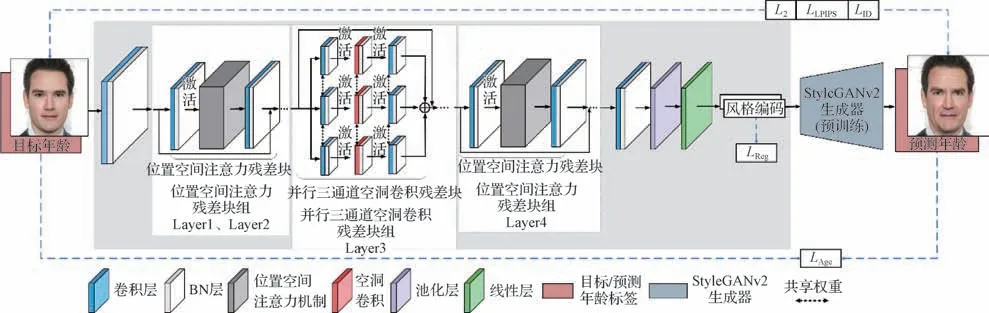
图1 PDA-GAN结构图Fig.1 Network structure diagram of PDA-GAN
1.1 并行三通道空洞卷积残差块(PTDCRB)
传统卷积神经网络如AlexNet、GoogLeNet 通过堆叠卷积层和池化层的方式构建网络结构,提取图像深层特征。然而随着网络加深,这种堆叠结构会不可逆地丢失人脸特征,且单一、尺度受限的卷积核难以对图像多尺度特征信息进行提取。而人脸年龄信息是由微观到宏观的多尺度特征组成,要求网络具有相应特征提取能力。
本文引入PTDCRB 用于提取图像多尺度信息,以解决目前存在的问题,结构如图2所示。

图2 并行三通道空洞卷积残差块Fig.2 Parallel three-channel dilated convolution residual block
每个PTDCRB 由并行的3 个空洞卷积通道构成,并行实现同时对特征进行提取。不同支路上的空洞卷积设置了不同的膨胀系数,分别为1,2,3,该参数的含义是指卷积核处理数据的间隔距离。空洞卷积通过在普通卷积核上按一定间距填0 构建新的卷积方式,示意图如图3所示。
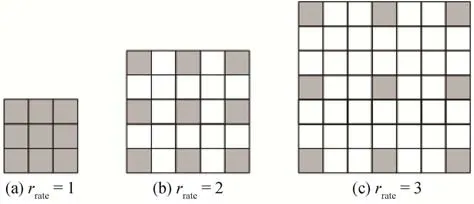
图3 空洞卷积Fig.3 Dilated convolution((a)rrate=1;(b)rrate=2;(c)rrate=3)
当膨胀系数等于1 时,即为普通卷积。膨胀系数大于1 时,在卷积核大小不变的情况下,空洞卷积不需要学习更多参数就能获得更大的感受野,以捕获更大尺度特征,且不会造成信息损失。图3(a)是普通卷积(即膨胀系数rrate=1 的空洞卷积),感受野为3 × 3;图3(b)采用膨胀系数rrate=2 的空洞卷积,感受野为5 × 5;图3(c)代表的空洞卷积膨胀系数为rrate=3,感受野为7 × 7。感受野计算式为
式中,k代表卷积核大小,rrate代表空洞卷积的膨胀系数,V代表感受野的大小。初始3 × 3 卷积核经过扩张后感受野为[3 × 3,5 × 5,7 × 7],在同一特征上采用多个膨胀系数的卷积核进行特征提取能获得不同尺度信息分量,有利于增强特征丰富度和对图像多尺度特征提取的准确性。最后再将3 个空洞卷积分支合并,对提取后的特征进行通道拼接和降维,防止信息冗余。
PTDCRB 每个分支共享权值,削弱网络参数量。将膨胀系数不同的空洞卷积提取不同尺寸的特征,并经过相同的特征提取网络来进行一致性变换。这样做的目的是在不增加参数计算量的同时获得更大的自适应感受野,而不同尺度的特征信息在同一层经过统一变化,有利于增强对图像多尺度特征丰富度,进而促进身份和图像细节信息保留。
PTDCRB 中每个支路第1 层采用1 × 1 的卷积层,第2 层为膨胀系数不同的空洞卷积,第3 层使用1 × 1的卷积层进行降维,提高计算效率。
引入PTDCRB 提取图像特征的优势在于,一方面在不增加计算量和不增加信息损失的同时保持空间分辨率,也减少了过拟合问题;另一方面通过膨胀系数扩大感受野,可以同时在不同感受野的分支上学习所有尺度特征,捕获了多尺度的上下文信息,随着样本数量增加,保留了全局语义层次更高的特征。对于人脸年龄合成任务来说,获得更大的感受野提取到的多尺度信息意味着能更好地捕获到整体的面部全局信息。
1.2 通道—位置注意力机制(CCAM)
注意力机制已广泛应用于各种计算机视觉任务中,例如图像分类、图像分割和图像合成,使网络学会关注重要特征而忽略不相关特征。近期的研究证明注意力机制对于提升模型性能有显著的效果。通过训练,注意力机制聚焦于重点目标区域,削弱不重要区域的信息。
本文提出的CCAM 如图4 所示。CCAM 分为两部分,即通道注意力(channel attention)机制和位置注意力(coordinate attention)机制。首先对特征向量的通道维度进行显著度筛选,保留特征中更有意义的通道信息,学习不同通道的重要性以解决特征冗余问题。再将位置信息嵌入到通道注意后的特征向量中,受直角坐标系定位的思想启发,分别沿长和宽两个正交方向进行注意力运算,将水平和垂直方向的注意力机制融合,方便捕获特征在不同位置的依赖关系。

图4 通道—位置注意力机制Fig.4 Channel-coordinate attention residual module
通道注意力的输入特征Fin通过全局平均池化和全局最大池化分别进行下采样聚合整个通道信息,两个池化操作将每个通道的全局信息压缩成两个C× 1 × 1 的标量作为空间特征统计,并进行级联拼接得到Fcat,具体为
将提取到的特征级联拼接后,经过1 × 1卷积运算后输入到sigmoid 激活函数中进行非线性变换,得到尺度为C× 1 × 1 的通道注意力掩膜Maskc,具体为
式中,掩膜上对应位置的激活度代表了该通道的显著系数。得到的通道注意特征图Fc是通过输入特征向量与激活后的通道注意力掩膜相乘获得的,计算过程为
通道注意力中的池化层帮助模型捕捉全局信息,构建通道之间的相互依赖性,增强模型对信息通道的敏感性。特征向量经过通道注意力机制加强后,再送入到位置注意力机制中对位置显著性和长程依赖关系学习能力进行加强。
位置注意力机制保留对捕捉图像结构和产生空间选择性注意力图至关重要的方向信息,通过融入水平和垂直方向的注意力向量捕获了特征的位置依赖关系,有利于定位和识别显著的区域,更有效地捕捉了空间位置信息。
为了促使注意力机制能够关注具有精确位置信息的空间特征向量,经过两个全局池化操作被分解为两个一维的特征向量。具体地,输入特征X的维度为H×W×C,采用2 个水平方向的池化核(H,1)和垂直方向的池化核(1,W),沿着输入特征图每个通道的水平方向和垂直方向分别进行池化操作,从而获得包含输入特征图的x、y轴方向相关位置信息的特征向量。
水平方向特征计算为
垂直方向特征计算为
式中,W和H分别为特征图的宽和高。通过两种变换可以沿着两个空间方向聚合特征,生成位置感知的特征。接着将zh和zw特征级联后,通过1 × 1卷积F获得位置注意力图f,其过程为
式中,F为1 × 1 卷积,cat为级联操作。随后对特征图f进行空间维度拆分并转置,结合1 × 1卷积,生成一对方向感知和位置敏感的注意力图gh和gw,经过1 × 1 卷积统一通道数,利用sigmoid 函数获得注意力的权重数据,具体为
最后对gh和gw展开用于注意力权重,得到注意力机制的输出坐标图为Y,计算为
CCAM 是一种利用通道信息和位置信息综合信息的注意力机制。网络加入CCAM 后,提供了额外的信息来增强注意力区域的视觉效果,提高对通道信息和位置信息的获取能力,降低下采样操作带来的影响,而不会造成信息丢失。注意力机制捕获位置信息和通道信息的内部相关性,提高网络对信息的敏感性。CCAM 通过突出重要信息和抑制不重要信息来增强特征的表达,强制网络直接学习特征图长、宽、深3 个维度上的残差。注意力机制中最关键的是能自适应地调整人脸特征和目标年龄集成的有效区域,使其参与人脸各个部位合成。
1.3 损失函数
本文的编码器整体使用如下几个损失函数加权组合进行训练。损失函数表达式为
式中,L2,LLPIPS,Lid,Lage,Ladv分别是像素损失、感知损失、身份损失、年龄损失和对抗损失,λ(·)是定义损失权重的常数,分别为λl2=1,λlpips=0.8,λid=0.1和λage=4。
1.3.1 对抗损失
为了生成更加真实的年龄合成图像,遵循生成对抗网络(GAN)的训练过程,将对抗损失同时应用到生成器G和判别器D,对抗损失计算为
1.3.2 身份损失
由于训练生成器时采用年龄标签进行约束,而非配对的真实图像监督,需要依靠身份约束保证输出图像中的人脸与输入图像身份一致。由于身份保持是年龄合成过程建模的一个关键挑战,本文采用多种身份损失对生成图像身份保留进行联合约束,以增强网络的身份保留能力。
常见的重建损失有来自像素级和特征级的两种约束。首先对生成图像进行逐像素的身份约束,计算合成图像和源图像之间的余弦相似性,缩小源图像x和其合成图像PDA(x,t)之间的差异,迫使生成器合成与输入图像的身份一致的图像。身份损失定义为
式中,R代表预训练的ArcFace(Deng 等人,2019)网络代表余弦相似度。其次,本文使用L2损失来学习生成和相似性,给定输入图像x和目标年龄t,L2损失函数为
式中,PDA代表本文模型。输入源图像x与目标年龄t,PDA模型目的是将源图像x转换为期望目标年龄t下的合成图像PDA(x,t)。
但仅采用像素级损失将导致重建结果模糊,且无法获得抽象特征的相似性,因此使用LLPIP(SZhang等,2018)损失来学习感知相似性,LLPIPS损失函数为
式中,F代表AlexNet特征提取器。
1.3.3 年龄损失
为了使经过年龄合成网络后的图像年龄与目标年龄相符,本文使用年龄损失,计算式为
式中,P表示预先训练的年龄预测网络(Rothe 等,2018),用于估计目标图像年龄。给定目标年龄t,计算合成图像年龄与目标年龄t的L2损失,年龄损失的引入可以提升年龄合成的准确性。
2 实验结果及分析
2.1 实验细节
本文以基于风格的年龄变换模型(SAM)(Alaluf等,2021)衍生模型为Baseline,其采用深度残差网络(residual network-50,ResNet-50 )为生成器编码器主干网络。训练集采用FFHQ,包含来自Flickr 网站70 000 幅分辨率为1 024 × 1 024 像素的高清人脸图像,涉及年龄、种族和光照等不同属性。本文所有评估均在CelebA HQ(large-scale celebfaces attributes dataset-high quality)(Karras 等,2018)测试数据集上进行。CelebA-HQ 数据集包含30 000 幅高清图像,随机选择2 000 幅高分辨率人脸图像作为测试集。测试集中图像年龄分布如图5所示。

图5 CelebA-HQ测试集年龄分布Fig.5 CelebA-HQ test dataset age distribution
实验环境中涉及到的模型均在图像工作站中完成,工作站搭载双通道Intel(R)Xeon(R)CPU E5-2620 v4 @ 2.10 GHz,以及双通道NVIDIA Geforce RTX 3090 24 GB,代码在pytorch 1.11.0 环境下运行,支撑其的是CUDA 11.4、cuDNN8.0。本文模型训练阶段迭代轮次均为500 k,初始学习率设置为0.001,采用ranger优化器。
将本文方法与当前最新公开代码的主流人脸年龄合成网络年龄寿命转换合成模型(lifespan age transformation synthesis,LIFE)(Or-El 等,2020)、高分辨率人脸年龄编辑模型(high resolution face age editing,HRFAE)(Yao 等,2021)和SAM(Alaluf 等,2021)进行比较,通过定性和定量对比实验以验证本文方法的有效性。
2.2 定性实验
本文中LIFE、HRFAE 和SAM 的结果均来自原作者提供的官方实现模型。由于以上3 个模型生成目标年龄(组)不同,对比样本组数也有差异,本文遵循以上3个模型的实验设置,分别进行比较。
PDA-GAN 模型与HRFAE 的定性实验结果展示如图6 所示。由图6 可见,PDA-GAN 具有较好的身份辨识度,且各年龄组的生成样本有较好的连续性。有清晰的老化特征,人脸随年龄变化较为自然。人脸随年龄变化过程包含着复杂的内部机理,反映在图像上是多尺度特征的变化集合。虽然HRFAE 能够生成高分辨率图像,但其聚焦于局部特征,在不同年龄之间产生纹理细微变化,如皮肤和眼周纹理,但其缺乏对宏观特征的学习。相比之下,本文采用了PTDCRB,融合了多尺度人脸特征信息,能建模从微观到宏观的人脸老化特征,能够更好地对头部形状(如下颚线)和纹理细节的变化进行建模。

图6 PDA-GAN和HRFAE对比示意图Fig.6 PDA-GAN and HRFAE comparison diagram
SAM 合成图像有较为自然的纹理,但也存在和HRFAE 一样的问题,即不同年龄组之间变化较不显著,且对细节和背景信息保留做的不够充分。PDAGAN 在生成更多纹理细节的同时保留了更多与年龄无关的图像细节(如嘴型和瞳孔颜色)。引入CCAM 的网络具有更强的筛选能力和结构约束性,能够更加清晰地区分与年龄相关的空间区域,此外,对通道注意力计算也使得与年龄相关的通道信息更加显著,增强模型感知力。
如图7 所示,LIFE 在幼年年龄组上有较好的表现,这得益于其在原有数据集基础上,增加了幼年数据样本。模型能够成功捕获幼年时期的头部形状变化规律,但在后续的年龄组上效果逊色于PDAGAN。从图7 中可以看出,LIFE 过滤掉人物背景信息,只保留了核心区域。

图7 PDA-GAN和SAM对比示意图Fig.7 PDA-GAN and SAM comparison diagram
然而,背景分割会带来严重的图像割裂和伪影,如图8中样本1所示。此外,如样本3和样本4所示,PDA-GAN 能针对年龄自适应地去掉不恰当的属性(如胡须),而LIFE 则无法做到,这也进一步证明PDA-GAN年龄合成的真实度。

图8 PDA-GAN和LIFE对比示意图Fig.8 PDA-GAN and LIFE comparison diagram
2.3 定量实验
近年来,人脸年龄合成方面的一些杰出工作(Liu 等,2019b;Yao 等,2021;吴柳玮等,2020;Alaluf 等,2021;Li 等,2021;Jeon 等,2021)均采用旷视科技Face++人工智能开发平台作为年龄合成准确度的客观评价标准。为方便比较,本文也采用旷视科技Face++人工智能开发平台(Face++Application Programming Interface,Face++API)作为评价指标。为了从定量指标上进一步验证PDA-GAN相较于当前主流模型LIFE、HRFAE 以及SAM 方法的优越性,本节分别从年龄准确性和身份一致性两个维度进行定量实验,进而评价模型合成图像的质量。
2.3.1 年龄准确率
为了评估年龄图像合成精度,本文采用Face++人脸年龄估计API对生成人脸年龄合成图像进行评估。用年龄估计API 对合成图像进行年龄判定,并计算均值,其中合成图像预测年龄和目标标签之间差异越小,表明年龄合成效果越准确。考虑到模型适用年龄生成范围不同,且鉴于数据集中年龄小于5 岁或大于70 岁的样本量过少,与其余年龄段的样本量相差较大,因此选择PDA-GAN、LIFE 和SAM 的生成年龄范围为5~70 岁,每间隔5 岁产生一个分组;而HRFAE 生成范围为20~70 岁,每间隔5 岁产生一个分组。合成图像经过Face++年龄分类API得到预测年龄值,并将其与生成标签值进行比较,最终得到预测结果。上述4 个模型在各目标年龄标签下合成图像预测年龄分布以及和目标值之间的差值如表1所示。

表1 LIFE、HRFAE、SAM和PDA-GAN在测试集上合成图像的预测年龄分布Table 1 Predicted age distribution of synthetic images on the test set by LIFE,HRFAE,SAM and PDA-GAN
鉴于HRFAE 模型生成年龄范围为20~70 岁,为了客观公平,同时选取4 个模型在2 000 幅测试集图像上分别生成的20~70 岁年龄段的11 组图像。计算每幅图像的预测年龄与目标年龄差值平均值,结果如表2 所示,PDA-GAN 在合成的年龄图像的准确度上表现最佳,平均预测差值达到4.09。

表2 不同模型预测年龄分布与目标年龄的平均差异Table 2 Different models predict age distribution and mean difference from target age
图9 展示了上述4 个模型的年龄预测误差随着年龄的变化趋势。PDA-GAN 在各分段上均优于HRFAE 和SAM 模型,而LIFE 模型在幼年、青年段(5~15 岁)上优于以上3 个模型,但是其在后续年龄上的生成年龄准确度并不佳,尤其是在老年图像中年龄误差高达16.9。这是由于LIFE 增加了幼年图像样本数,增强了模型合成幼年、青年图像的准确度。然而这并不能从根本上提升年龄合成精确度,其在增加年轻样本数量的时候,不可避免地会造成样本偏差,制约其生成其他年龄的能力。

图9 不同模型预测年龄准确性对比Fig.9 Comparison of the accuracy of different models for predicting age
2.3.2 身份一致性
为了客观、有效地验证人脸相似性,人脸验证实验同样在旷视科技Face++人工智能开发平台提供的API上进行人脸比对。置信度即代表两个样本为同一身份的概率,数值范围从0%~100%,数值越高代表两个样本身份越相似。本文将判定阈值设置为76.5%(He 等,2019),验证置信度高低表明模型身份信息保存能力好坏,即合成图像和其对应原始图像是同一个人的准确性高低。
本文采用深度学习方法,而非人工方法作为评判样本身份验证置信度标准。深度学习方法能够批量验证大量数据,且具有客观公平的衡量标准。在对比实验中,PDA-GAN、LIFE 和SAM 的生成年龄范围为5~70岁,每隔5岁产生一个分组;而HRFAE生成范围为20~70岁,每隔5岁产生一个分组。
表3和图10给出了从原始年龄到目标年龄的年龄合成图像的平均身份置信度分数。以验证各个模型在不同年龄的身份保留能力。

表3 LIFE、SAM、HRFAE和PDA-GAN在测试集上合成图像身份置信度Table 3 LIFE,SAM,HRFAE,and PDA-GAN synthesize image identity confidence on the test set

图10 不同模型身份置信度对比Fig.10 Comparison of identity confidence of different models
从表3 中可以看出,PDA-GAN 的平均身份置信度相较于对照组的3 个主流模型要高,SAM 和HRFAE次之,LIFE模型置信度最差。结合图5和图10可知,在原数据集集中分布的年龄组附近,各模型生成图像身份验证置信度较高,而远离分布中心的生成样本身份验证置信度则较低。合成图像置信度曲线趋势也符合原数据集分布特点。本文及对照的3个模型中,LIFE的身份验证置信度受年龄组影响最大,其次是本文模型和SAM,HRFAE则最为平稳。
LIFE模型的身份保留能力明显低于另外3个模型,其主要原因是LIFE 模型用分割算法裁剪了背景部分,但是分割方法容易将人脸区域误裁,进而导致人脸残缺和伪影;此外缺失背景信息导致原图像和生成图像差异扩大。综合以上原因,最终导致图像的置信度低。HRFAE 模型虽然平稳,但是其身份保持能力并不高,尤其是在20~50 岁年龄段中身份合成置信度并不优秀。HRFAE 具有稳定的身份保持能力,代价是较差的年龄合成精度。
PDA-GAN 采用PTDCRB 提取了人脸图像中的多尺度特征,丰富了人脸多尺度细节信息,增加了图像真实度。而SAM 和HRFAE 模型专注于面部纹理产生,但忽略了其他年龄特征,如宏观面部轮廓和微观发色信息。此外,PDA-GAN 引入CCAM 帮助模型筛选出显著特征,使身份、年龄等与图像质量相关的特征能够获得高激活度,避免了信息冗余。两个模块之间协作,提高了各尺度特征丰富度,也提高了网络感知和筛选能力,同时促进了模型身份保留能力和年龄合成准确度。此外,本文采用包括L2、Lid和LLPIPS共3个身份相关的损失函数,促进了身份保留能力。
2.3.3 年龄无关属性保留度
人脸图像不仅包含年龄,还有其他与年龄无关的属性,如性别和面部情绪等。通过考察人脸年龄变化后的图像和原始图像的面部情绪和性别保留率,能够体现出模型对属性的甄别能力,只操控年龄相关属性,同时充分地保留其他属性。
选取的人脸面部情绪包括:惊喜、害怕、厌恶、高兴、伤心、生气和平静共7 类,涵盖了日常情绪变化,此外还选取了性别属性用于评价模型对无关属性的保留率。实验中选取年龄2~50 岁,共1 751 幅人脸图像,生成目标年龄为70 岁的老化图像,并对比其年龄老化前后面部情绪和性别的保留情况。Face++人脸情绪API 能够客观地验证人脸情绪保留率,本文将置信度阈值设置为76.5%(He 等,2019),置信度数值越高代表两个样本属性保留越精准。本文还比较了性别保留率,将修改后的图像与原始输入图像的性别属性进行比较。表4 给出了不同模型年龄无关属性的保留度。实验结果表明,本文模型在改变年龄属性时能够更好地保留与年龄无关的属性,有区分脸部细粒度属性的能力。
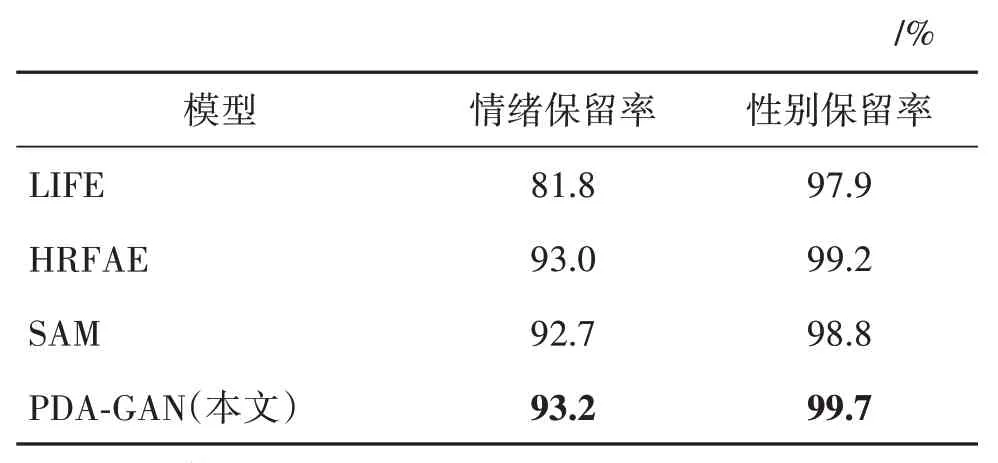
表4 不同模型年龄无关属性保留度Table 4 Different models age independent attribute retention
2.4 消融实验
为证明PDA-GAN 各个模块的有效性,全面分析模型各个组成成分,即PTDCRB 和CCAM 的贡献,本文在Celeba-HQ 数据集2 000 幅测试图像上分别设计了不同模块的对比消融实验。
2.4.1 PTDCRB引入位置分析
为了验证在不同位置嵌入空洞卷积对于特征提取效果的影响,本文在SAM(Alaluf 等,2021)基础上进行修改,设计了使用ResNet-50作为生成器编码器的主干网络,于不同位置嵌入PTDCRB 的改进网络,对人脸身份验证置信度进行对比。实验结果如图11 所示,PTDCRB 在不同层的引入均对模型有不同程度的贡献。其中PTDCRB-4 比PTDCRBi(i∈[1,3])表现更差,可能原因是,在深层特征图中,人脸图像信息已经高度抽象,此时应用大尺度卷积核也难以提取到更多有效信息。而在较浅的卷积层中加入PTDCRB,能够同时捕获浅层和深层的融合信息,因此能更好地促进模型的身份保留能力。在实验中PTDCRB-3 的平均身份验证置信度最佳。因此,其他实验中将第3 残差块组替换为提出的PTDCRB组,构成并行三通道空洞卷积残差网络。

图11 不同位置引入PTDCRB的身份置信度对比Fig.11 Identity confidence comparison of PTDCRB introduced in different locations
2.4.2 PTDCRB膨胀系数分析
本文选取4 组膨胀系数组训练网络,分别为[1,2,3],[1,2,4],[1,3,5] 和[ 3,4,5]。对测试集图像进行身份置信度和预测年龄分布的实验,选取其中10、30、50、70 这4组作为展示。从表5和表6中可以看出,与其他膨胀系数组相比,本文选取[ 1,2,3] 作为膨胀系数的模型身份置信度和预测年龄分布最优。因此,该实验表明设置适当的膨胀系数对于空洞卷积网络保持合理的精度水平至关重要。

表5 PTDCRB不同膨胀系数合成图像身份置信度Table 5 PTDCRB identity confidence of composite images with different dilation rate /%

表6 PTDCRB不同膨胀系数合成图像预测年龄分布Table 6 PTDCRB synthetic images with different dilation rate predict age distribution /%
2.4.3 不同注意力机制对比分析
为验证本文通道—位置注意力机制的有效性,分别测试了标准生成器结构和引入通道—位置注意力机制的生成器结构的网络在年龄合成准确度和身份验证置信度上的表现。从表7 和表8可以看出,在加入通道—位置注意力机制后,最终的身份验证置信度和生成年龄准确度都得到了一定提升,能有效提升身份保留能力和年龄合成能力。

表7 CCAM消融实验身份验证置信度Table 7 CCAM ablation experiment verification confidence

表8 CCAM消融实验预测年龄分布Table 8 CCAM ablation experiments predict age distribution
为进一步验证CCAM 的有效性,以及不同注意力机制对模型的影响,将本文模型中的CCAM 移除,替换为主流的挤压激励(squeeze-and-excitation,SE)、位置注意力模块、卷积块注意力模块(convolutional block attention module,CBAM)作为对照组与PDA-GAN 进行性能测试比对,并测试其身份置信度属性以验证其信息筛选能力。从图12 可知,采用CCAM 注意力机制的PDA-GAN 具有最高的身份保留能力,平均身份验证置信度达到96.9%,高于其他注意力机制的对照模型。采用位置、通道结合的混合注意力机制CCAM、CA 和CBAM 的表现要优于只采用单一注意力机制的SE,用恰当的方式让多种注意力机制协同工作能有效促进模型对特征的筛选能力和感知能力。

图12 不同注意力机制消融实验身份置信度对比Fig.12 Comparison of identity confidence in ablation experiments with different attention mechanisms
3 结论
本文针对人脸年龄合成任务中生成图像伪影严重和人脸特征保留效果不佳的问题,提出了一种基于并行三通道空洞卷积残差块和通道—位置注意力机制的人脸年龄合成网络。由于现有模型聚焦于合成人脸纹理以模拟年龄合成进程,忽略对多尺度特征的提取,因此,本文提出了共享权值的并行三通道空洞卷积残差块,捕获各尺度特征信息,增强模型细节特征丰富度。此外,为了增强模型对敏感特征的表达能力,本文提出通道—位置注意力机制,可同时学习通道和空间维度的特征显著性。最后,在并行三通道空洞卷积残差块和通道—位置注意力机制的共同作用下,模型的人脸身份保留能力和年龄合成精度都得到了提升,解决了生成图像伪影问题。实验结果表明,本文方法在人脸年龄合成任务上的表现优于对比方法,能够合成具有较高真实度和准确性的自然逼真的目标年龄人脸图像。
本文方法在合成儿童人脸图像时仍然存在不足。儿童的面部轮廓以及五官的比例与成人有较大差别,并且数据集中的人脸样本主要集中在青壮年群体。而幼年图像样本少,导致与不同年龄组的样本数量存在偏差,缺乏训练样本的年龄组难以取得好的表现。受制于以上因素,本模型在幼年的年龄组中表现并不出色。为此,在今后的研究中需要进一步改进模型,提升模型对小样本数据的学习能力,提升模型在各年龄组的表现。此外,当下硬件的算力已经有了长足的进步,作为科学研究付出一定的算力为代价是有意义的。但当模型落地应用时,如何在进一步简化模型复杂度的同时提升效率,也是今后重要的研究方向。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
核科学与工程(2021年4期)2022-01-12
少儿美术·书法版(2021年9期)2021-10-20
动漫星空(2018年9期)2018-10-26
计算机应用(2018年5期)2018-07-25
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
轴承(2015年2期)2015-07-25
发明与创新(2015年33期)2015-02-27
奇闻怪事(2014年5期)2014-05-13
