
结构先验指导的文本图像修复模型
2023-12-23 10:13刘雨轩赵启军潘帆高定国普布旦增
中国图象图形学报 2023年12期
刘雨轩,赵启军,*,潘帆,高定国,普布旦增
1.四川大学计算机学院,成都 610065;2.西藏大学信息科学技术学院,拉萨 850011;3.藏文信息技术创新人才培养示范基地,拉萨 850011;4.四川大学电子信息学院,成都 610065
0 引言
图像修复是指基于图像已知部分,重建缺失区域,获得视觉完整且语义合理的图像的过程。图像修复可以应用在照片修复(Wan等,2020)、图像编辑(郭景涛,2021)等方面,且对于文化遗产数字化保护有着重要意义。近些年,由于深度学习的发展优势,基于深度学习的图像修复方法(强振平 等,2019)受到越来越多的关注。
最初基于卷积神经网络(convolutional neural network,CNN)的方法(Pathak 等,2016;Yan 等,2018)采用编码器—解码器架构从编码后的图像特征恢复完整图像,由于单一的重建损失会使图像产生模糊和语义错误,因而使用对抗性损失等各种损失联合约束训练网络,从而使得生成图像更加真实,细节更加逼真;也有些方法(Yu 等,2018)认为传统CNN 的感受野有限,修复时没有有效利用背景特征信息,提出利用注意力机制提取全局上下文信息,获得语义合理的修复结果。另一些方法选择先重建整体结构,例如边缘(Nazeri 等,2019)、用户草图(Yu等,2019)等作为先验来指导修复过程,生成结构连贯的结果。所有这些方法都通过学习大量图像,例如自然场景图像集Places(Zhou 等,2018)、ImageNet(Russakovsky 等,2015)和人脸图像集CelebA(celebfaces attribute)(Liu等,2015)来合成逼真的语义和复杂的纹理。
文本图像不仅具有丰富的静态信息,而且还具有笔划序列信息。文本图像修复旨在使模型更加关注文本本身,尽可能多地恢复有利于文本检测与识别等下游任务的文本笔划信息,上述方法并不能很好地解决文本图像修复问题。现有研究多集中在文本图像超分辨率以及文本图像检测与识别,对于破损文本图像的修复问题的研究也借鉴的是自然图像修复的方法(段荧 等,2021;王伟华,2021)。很多古籍文本图像从木头、墙壁或草纸上收集,大多是文字与背景图像的混合风格,存在文字断层,缺失的文本区域阻碍了古文献的数字化保护。因此,需要对文本图像修复进行研究。
针对以上问题,本文提出了基于结构先验的文本图像修复模型。首先,根据人类视觉感知系统,骨架结构可以描述文字笔划方向等形状特征,也是提取笔划顺序信息的基础,许多文本图像超分辨率方法(Yu 等,2021)使用文本骨架来提高其任务性能。因此,为关注文本结构本身且恢复整体图像结构,模型选择使用文本骨架和边缘作为结构先验来指导后续文本图像修复。由于之前的注意力机制不足以帮助合成文本结构的语义和静态纹理,通过假设文本的伪动态过程(如图1 所示),模型提出了一种静态到动态的残差模块来捕获文本图像序列特征信息,增强文本图像修复结果。最后,为约束网络生成更加清晰的文本笔划,模型还应用了梯度先验损失(gradient prior loss)作为修复损失函数之一。

图1 文本伪动态过程图(从左至右,以藏文为例)Fig.1 Text pseudo-dynamic process(from left to right,taking Tibetan as an example)
1 相关工作
1.1 图像修复中的注意力
很多图像修复模型采用注意力机制从未缺失的背景区域获取上下文信息,并在缺失部分和剩余部分之间建立联系,以辅助图像修复。
Yu 等人(2018)提出上下文注意模块,利用剩余区域的特征块作为卷积滤波器来处理矩形孔的特征块,以从遥远的背景区域中提取有用的纹理信息,帮助模型有效地处理缺失区域。该方法中的缺失区域为规则矩形且没有关注缺失区域内的特征信息的联系,因此,Liu 等人(2019)设计了一个连贯的语义注意层,可以建立空洞缺失部分的深层特征之间的关系,并确保不规则空洞区域的语义相关性和特征连续性。此外,还引入了一致性损失来指导注意力层和相应的解码器层学习真实的特征。Wu 等人(2022)引入了一个新的空间注意层,不仅对已知区域和填充区域之间的相关性进行建模,而且对填充区域内的相关性进行建模,使得修复结果的全局和局部一致性更好。但是单一尺度的注意力机制不能很好地处理多种混合场景下的图像修复。因此,Wang 等人(2019)提出了一种多尺度上下文注意模块,该模块使用不同尺度的块大小来计算注意分数,然后将它们组合起来以获得结构一致且细节清晰的图像。Li等人(2020)在不同尺度的跳跃连接和编码器—解码器层的中间使用多尺度自注意力结构,以考虑自相似性。
以上注意力机制都在自然图像或人脸图像基础上发掘建立缺失区域和背景区域的联系,或使用多尺度的结构结合不同尺度的特征信息以提高图像修复的性能。在文本图像中,文字是主要信息,然而以上方法无法对文本图像中的文本图像序列特征信息进行有效提取和利用。
1.2 基于先验指导的图像修复
为保证修复后图像的结构连贯性,越来越多的方法使用额外的先验来提高图像修复的性能,例如边缘、线条、用户草图、低分辨率图像、分割图和描述性文本等。
Nazeri 等人(2019)设计出用于图像修复的两阶段框架,先重建破损图像的边缘先验,后将边缘图像作为恢复图像纹理清晰和结构一致的指导。Guo 等人(2021)以耦合方式建模边缘结构约束的纹理合成和纹理引导的边缘结构重建,使两者相互促进,生成更加合理的图像。Dong 等人(2022)进一步结合边缘和线条图像,使用增量Transformer 结构和掩码位置编码提高大孔洞区域的图像修复效果。Yu 等人(2019)将用户草图作为孔洞区域中的结构先验信息,结合对抗损失,控制图像修复任务生成真实的且用户需要的修复结果。为了克服CNN 的缺点,Wan等人(2021)利用Transformer对整体图像先进行低分辨率先验重建,然后使用CNN 结合低分辨率先验修复图像。Liao 等人(2020)提出了一种渐近的方式生成越来越准确的语义分割图来指导精确修复结果的方法。由于图像的描述性文本标签可以充分理解图像语义信息,Zhang 等人(2020)将文本特征注入到修复网络中确保生成图像的局部和全局区域一致且符合语义。
以上图像修复采用的是比较通用的先验信息,在人脸和自然图像中都可以适用,然而对于本文特定的文本图像,这些先验信息不足以指导文本图像中的字符的修复。
2 本文方法
本文提出了一种基于结构先验的文本图像修复模型,整体架构如图2 所示。可以发现骨架结构包含静态文本笔画信息,边缘结构包含整体颜色和纹理信息,因此本文首先选择文本骨架和边缘为结构先验,设计了结构先验重建网络。该网络应用Transformer(Vaswani 等,2023)来捕获整体的长期依赖关系,重建健壮且可读的文本骨架图像以及边缘图像,并作为文本图像修复的指导先验。由于以往的图像修复网络中的注意力机制都是在自然图像修复或者人脸图像修复的基础上提出,而文本图像中文本本身的特征信息并没有被发掘且应用到修复过程中,因此本文提出一种静态到动态的残差模块(static-to-dynamic residual block,StDRB)提取先验中重要的序列特征并有效利用。通过假设静态的文本为从左至右、一个部分接着一个部分书写的伪动态过程(如图1 所示),设计了一个从静态到动态的转换模块来捕获文本笔划序列特征信息,然后将转换模块与残差连接结合,并将其嵌入到文本图像修复网络中以增强修复性能。

图2 结构先验指导的文本图像修复模型框架Fig.2 Construction of structure prior guided text image inpainting model
2.1 结构先验重建网络
结构先验重建网络的输入由指示破损区域的二进制单通道掩膜(1 表示缺失区域)、被掩膜覆盖的3 通道RGB 图像、被掩膜覆盖的单通道文本骨架图像和被掩膜覆盖的单通道边缘图像共同组成,网络的输出为单通道文本骨架修复结果和单通道边缘图像修复结果,如图2所示。
由于文本图像丰富的细节信息以及复杂的背景纹理,CNN 模型通过卷积计算的感受野受限,无法很好捕捉图像中文本字符之间的长距离的全局依赖关系,且由CNN 设计的注意力模块无法很好地处理多个任务,因此本文采用N层仅编码器结构的Transformer 模块作为网络的主要架构,Transformer的特性使得网络可以利用全局的有效信息,其中的多头自注意力机制可以产生具有可解释性的模型,保证了网络可以关注到多个可执行区域,学会更好地执行边缘图像重建和文本骨架图像重建两个任务。
由于Transformer 计算复杂度很高,首先将输入图像送入编码器进行下采样操作后再送入Transformer 模块以减少计算成本,为保证网络的输入输出尺寸统一,最后将结果送入解码器进行上采样恢复图像的原来大小,编码器—解码器具体结构如表1所示。

表1 结构先验重建网络中编码器—解码器结构Table 1 Architecture of encoder-decoder in structure prior reconstruction network
具体操作流程如下:
1)对输入进行下采样;
2)将采样后特征向量投影到d维特征向量并为每个空间位置添加一个额外的可学习位置嵌入;
3)将特征向量输入Transformer模块。
在第n个Transformer层中
式中,MSA、LN和MLP分别表示多头自注意力层(multi-head self-attention,MSA)、层归一化(layer normalization,LN)以及多层感知机(multi-layer perception,MLP)。Transformer模块结构如图3所示。
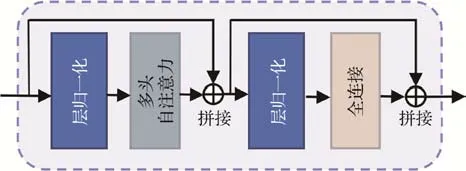
图3 Transformer模块结构Fig.3 Structure of Transformer module
2.2 文本图像修复网络
文本图像修复网络由生成网络和判别网络构成,生成网络以编码器—解码器结构(见表2 所示)为基础,其输入是单通道文本骨架图像、单通道边缘图像以及被掩膜覆盖的3 通道RGB 图像共同组成,输出为3通道的RGB图像修复结果。
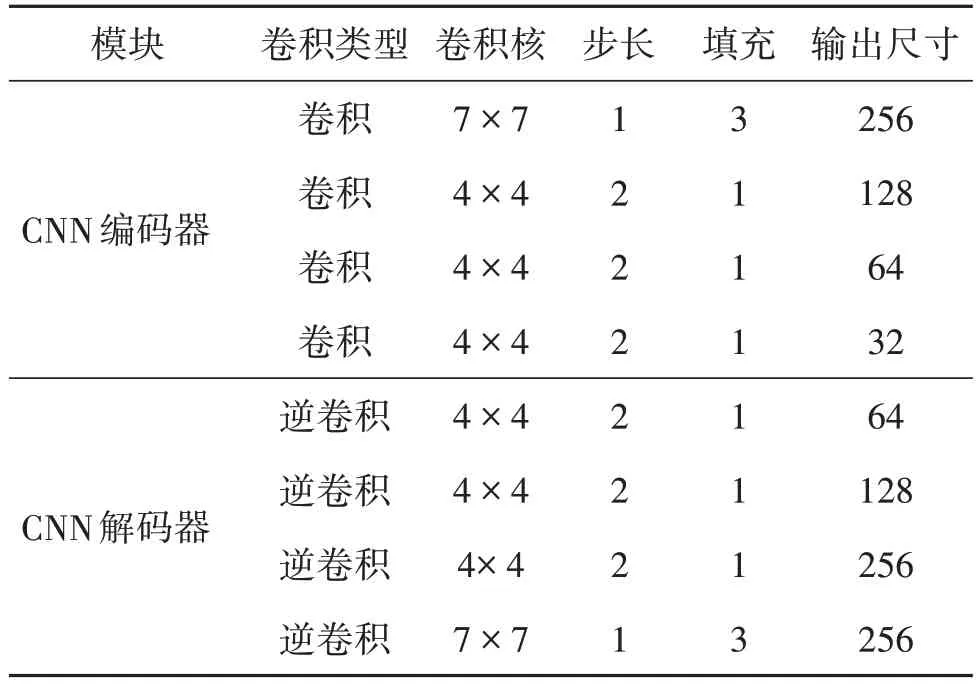
表2 生成网络的编码器—解码器结构Table 2 Architecture of encoder-decoder in generator network
首先将输入送入CNN 编码器中得到融合的静态文本高层语义特征,由于卷积的特性,卷积计算提取的局部感受野可以代表文本图像的块特征。从CNN 编码器中提取的静态特征图也可以假设为是由文本相应部分的块按照文本动态书写过程从左到右、从上到下组合而成。在文本识别任务中,经常使用循环神经网络(recurrent neural network,RNN)转换图像特征为时间序列特征,但由于RNN 结构无法很好处理远距离依赖,Cho 等人(2014)提出门控神经单元(gate recurrent unit,GRU),与长短时记忆网络(long short-term memory,LSTM)相比,既解决了长距离依赖下RNN 梯度消散的问题,又具有比LSTM更加简单的结构,是目前比较流行的循环神经网络。本文使用GRU 模块将静态特征图转换为动态序列特征。考虑到单向的GRU 往往用做预测,而本文需要转换利用完整的上下文序列特征,因此仿照文本书写过程,分别在垂直和水平方向添加双向GRU,从静态的特征图中提取文本图像序列特征。为了加深网络,提取等级更高的特征信息,同时简化网络的结构,让网络结构更加均匀化,本文将两个并行的模块进行残差连接,作为静态到动态残差模块(StDRB),该结构的自适应特性以及对网络深度不会过于敏感的特点,有利于网络收敛。
如图2 所示,对于来自CNN 编码器的静态特征图的操作如下:
1)使用扩张卷积捕获比普通卷积更大的感受野,通过填充参数和卷积步长保证扩张卷积后特征图大小不变,以此保留全图的特征信息;
2)分别对扩张卷积后的特征图进行卷积,将卷积后的特征图分别变形为列向量和行向量后,送入对应的GRU模块中;
3)GRU 模块将两个向量作为顺序输入,并更新隐藏层中的内部状态。具体为
式中,ϕ1和ϕ2分别表示垂直方向和水平方向的GRU,Ht表示隐藏层,Ct和Rt表示输入列特征向量和行特征向量,t1和t2表示按照垂直方向和水平方向的循环连接。经过M层静态到动态残差模块后,将特征图送入一个由Hu 等人(2018)提出的SE(squeeze-and-excitation block)模块中,使用通道注意力机制对两个方向的全局特征进行加权,这使网络能够自适应地调整不同上下文的重要性,从而更有效地捕获文本图像中的上下文信息。最后将特征送入CNN 解码器恢复图像得到最终的结果。
判别网络可以判别图像是真实的原始图像还是修复后的图像,相当于是一个二分类网络。对于生成网络的造假图像和真实原始图像,首先利用多层卷积将输入的图像进行压缩,将压缩后的特征向量进行展开,使用sigmoid函数保证输出值范围在[0,1]之间,使用二分类交叉熵损失反向传播来更新判别网络的参数。判别网络的结构如表3 所示。经过多次交替训练、迭代更新后,生成网络输出的修复图像与真实原始图像间差异越来越小,使得判别网络判别错误。最后测试时仅使用生成网络生成修复图像。

表3 判别网络结构Table 3 Architecture of discriminator network
2.3 损失函数
为了使修复后图像更加真实、细节更加逼真,本文联合多个损失函数一起衡量纹理和结构差异,提高文本图像修复的性能。
2.3.1 结构先验重建网络损失函数
在结构先验重建网络训练过程中,由于文本骨架图像和边缘图像都是二值化图像,为了更好地分离背景与前景,本文采用二分类交叉熵损失(binary cross entropy loss,BCE loss)分别计算修复后的二值文本骨架图像和二值边缘图像与其相对应的原始图像的差异。二分类交叉熵损失计算为
由于文本骨架图像的重建对于后续文本图像的修复非常关键,因此要保证文本骨架的重建精度。然而文本图像中骨架和背景标签分布不平衡,在交叉熵损失中,损失按照每个像素损失的平均值计算,每个像素的损失值按离散的值计算,与其相邻的像素是否为骨架无关,导致重建出的文本笔划骨架容易产生模糊,边界不清晰。因此,交叉熵损失只考虑了微观意义上的损失,而不是全局考虑,不足以解决正负样本不平衡问题。因此,本文在骨架重建时搭配骰子损失(Dice loss)一起训练网络。Dice loss 在某个像素点的损失不仅和该点的标签有关,而且和其他点的标签也有关,且无论图像大小如何,固定大小的正样本区域计算的损失是一样的,更倾向于挖掘前景即骨架区域,可以有效解决不平衡问题。Dice loss计算为
式中,⊙表示逐像素相乘。训练结构先验重建网络的联合损失可以表示为
式中,∂为平衡系数,在模型中设为0.8。
2.3.2 文本图像修复网络损失函数
本文借鉴Nazeri 等人(2019)的图像修复阶段的损失函数,使用了重建损失Lrec、感知损失Lprec、风格损失Lstyle以及对抗损失Ladv联合训练修复网络。重建损失使用平均绝对误差(mean absolute error,MAE)计算修复图像Iout和原始图像Igt像素级别的差异,计算式中用|| ⋅||1表示MAE 的计算,重建损失可以表示为
感知损失利用高级语义特征衡量图像差异,使用在ImageNet 上预训练过的VGG-19 网络(Visual Geometry Group 19-layer network),具体为
式中,Φi为预训练网络的第i层激活层输出的特征图。在模型中,选用VGG-19 网络的ReLU1_1,ReLU2_1,ReLU3_1,ReLU4_1,ReLU5_1层。
风格损失多用于风格迁移任务,计算图像特征之间的相似度,在图像修复任务中,由Liu 等人(2018)证明可以有效改善修复图像中的棋盘格伪影。风格损失与感知损失相似,都使用了在ImageNet上预训练网络的激活层输出,风格损失计算为
式中,GΦ是指从激活层输出的特征图创建的格雷姆矩阵运算。
对抗损失使用生成网络和判别网络串联训练,将网络优化问题转换为极小极大优化问题,使得生成器生成更加真实逼真的图像,对抗损失将Igt视为真图像,Iout视为假图像,计算为
式中,D表示判别网络。
由于文本图像修复主要目的是为了修复文本内容,方便下游的检测和识别任务,而上述损失适用于在自然图像以及人脸图像的修复中约束图像的纹理以及结构的生成,但对于文字的修复并没有特殊的约束。本文为生成更加清晰的文字,使用Sun 等人(2011)提到的梯度轮廓先验(gradient profile prior,GPP)作为梯度先验损失(gradient prior loss),联合其他损失函数一起训练网络。
梯度先验损失计算为
式中,δ(Iout)和δ(Igt)表示原始图像和修复图像的梯度场。梯度场指的是像素的RGB 值的空间梯度,在文本图像中,由于文字和背景区域RGB 值相差很多,因此文字与背景区域边界的梯度场很大,如图4所示,可以使用修复图像和原始图像的梯度场差异约束网络生成更加锐利的文本和背景的边界,从而使得修复后的文字更加清楚。

图4 文本图像梯度场示例Fig.4 Illustration of gradient field on the text image
训练文本图像修复网络的联合损失可以表示为
式中,βrec,βperc,βstyle,βadv,βgp为平衡系数,参考算法(Nazeri 等,2019)和实验调参结果,在模型中分别设置为1.0,0.1,250,0.1,0.1。
3 实验结果分析
实验在Ubuntu18.04 系统下,使用深度学习框架PyTorch 进行训练和测试,用Python 作为开发语言,实验采用的CPU 为Intel 酷睿 i7-8700F,GPU 为1 块NVIDIA GeForce GTX 1080Ti 11 GB 显卡。训练时,输入图像尺寸都调整至256 × 256 像素,且训练时随机对掩膜图像进行水平或竖直翻转等操作。模型分两阶段进行训练,在结构先验重建网络训练过程中,选用AdamW 作为优化器,batchsize 设置为8,初始学习率设定为0.000 3;在文本图像修复网络训练过程中,选用Adam 作为优化器,batchsize 设置为8,初始学习率设定为0.000 1。模型总参数量为31.07 MB。
3.1 数据集
实验使用两种语言的数据集,通过多种字体文件、网上公开的语料以及典型的英文书籍文字背景合成了英文文本图像数据集;还通过乌金体藏文字体、藏文语料和真实法藏敦煌藏文文献背景图像合成藏文文本图像数据集,分别生成了100 000幅图像用于训练,20 000 幅用于测试,数据集示例如图5 所示。生成图像时随机挑选字体文件以及语料中的单词、字符,在背景图像任意位置生成文本行,最后截取整个文本行,并将高度统一为32 像素,宽度在50~300 像素之间。掩膜图像采用了Liu 等人(2018)提出的12 000幅公开的不规则掩膜图像。文本骨架的原始图像使用Simo-Serra 等人(2018)提出的线条归一化工具生成,该工具可以在移除背景的同时保留并细化文本笔划。边缘的原始图像采用Canny 边缘检测算法生成。

图5 藏文和英文数据集示例Fig.5 Examples of Tibetan and English datasets
3.2 定性比较
本文以4 个图像修复模型为基准,与本文模型进行对比。各模型的定性比较结果如图6所示,前3排为藏文测试集示例,后3 排为英文测试集示例,图6(b)为模型输入,图6(c)—(g)为对比模型与本文模型的修复结果。

图6 文本图像修复定性效果对比Fig.6 Comparison of qualitative effects of text image inpainting((a)original images;(b)masked images;(c)Liu et al.(2018);(d)Nazeri et al.(2019);(e)Wan et al.(2020);(f)Guo et al.(2021);(g)ours)
在两个数据集中,Liu等人(2018)的方法在修复时未采用任何先验信息和注意力机制增强图像修复效果,缺失区域修复纹理模糊有伪影,且图像上被遮挡的文本修复存在明显错误。Nazeri 等人(2019)和Guo 等人(2021)提出的方法在背景区域修复效果很好,缺失面积小时效果可以,但文字与背景边界模糊,有大面积文字缺失时,在文字的修复细节上效果不够好,文字修复有语义错误。Wan 等人(2020)的方法修复痕迹明显,修复结果缺失区域和背景区域文字衔接不一致,文字出现大量修复错误,没有达到文本修复的目的。
综合以上结果可见,本文方法可以更加精确地修复文本图像中的文本笔划,且在掩膜遮挡尺寸较大时效果更好。与其他模型结果对比,做到修复区域自然真实,人眼视觉感受效果较好。
3.3 定量比较
除以上定性比较外,本文也对模型修复后的结果进行了定量比较。本文采用峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似度(structural similarity,SSIM)以及平均绝对误差(mean absolute error,MAE)等图像修复任务中常用的图像质量评价指标对不同模型的修复结果进行评价分析。
在测试集上的实验结果如表4 所示。由表4 可知,无论是藏文数据集还是英文数据集,本文模型在3 种图像质量评价指标上均取得了好于其他图像修复模型的结果。
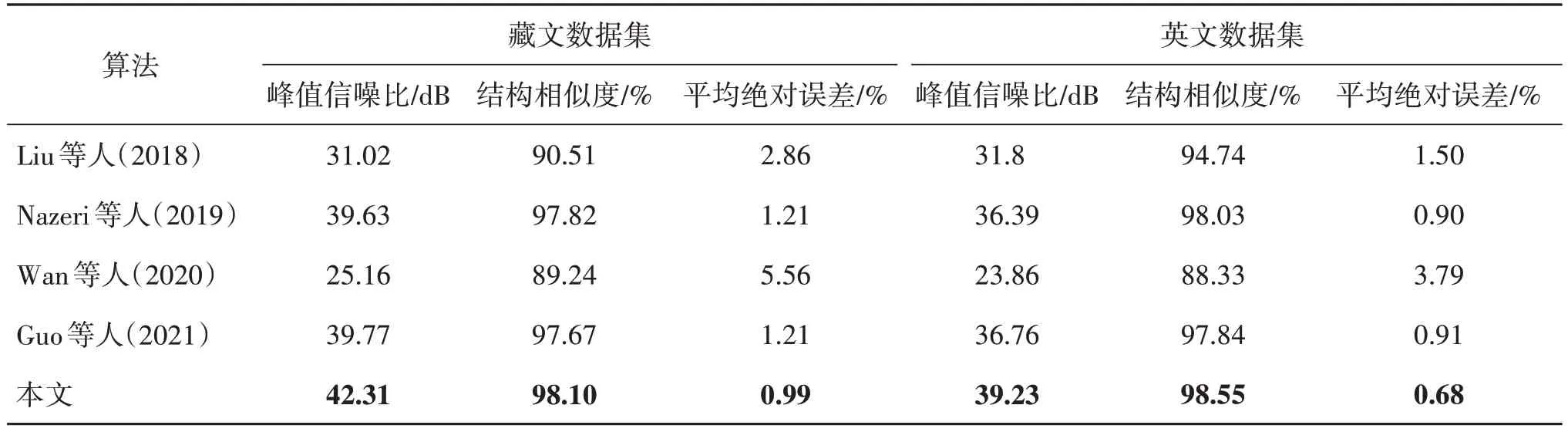
表4 图像质量评价指标上的修复效果对比Table 4 Comparison of inpainting effects on image quality assessment
Wan等人(2020)的方法在两个数据集上结果都很差,原因是其方法使用的先验是低分辨率图像,而在低分辨率图像中文字显然更加难以辨认,对于指导后续修复也没有很好的效果。Nazeri 等人(2019)的方法和Guo等人(2021)的方法都使用边缘作为结构先验,对于文本图像修复效果有一定作用,相比未使用任何先验的Liu 等人(2018)的方法在指标上优秀很多。
模型在藏文数据集上的指标比英文数据集好,原因是藏文数据集采用的字体为乌金体,在笔划结构上没有使用多种字体生成的英文数据集复杂,且藏文数据集使用的背景图像都是真实的法藏敦煌藏文文献文本图像的背景,其复杂程度没有英文数据集使用的文档背景图像复杂,如图5所示。
以上3 种评价指标是图像修复质量的通用评价指标,为比较修复后文字的准确率,本文进一步使用了由HP 实验室开发、Google 维护的开源OCR(optical character recognition)引擎Tesseract OCR 对修复后的藏文文本图像进行文字识别,使用Tesseract OCR、CRNN(convolutional recurrent neural network)(Shi 等,2017)和ASTER(attentional scene text recognizer)(Shi 等,2019)等识别模型对修复后的英文文本图像进行文字识别,并使用字符识别准确率评价识别结果,字准确率越高,表示修复效果越好。字准确率(character accuracy,C.Acc)计算为
式中,Llev表示识别出的文本字符串和真实文本字符串之间的莱温斯坦距离(Levenshtein distance),其定义为将一个字符串变换为另一个字符串所需删除、插入和替换操作的次数。Lgt表示真实文本的字符长度。
将修复后的测试集图像送入识别模型进行识别,实验结果如表5 所示。由表5 可知,本文模型修复后图像的文字识别结果要好于其他修复模型,证明了本文模型可以合理地修复破损文本的结构,做到了更加关注文字本身,有利于文字识别等下游任务的执行。
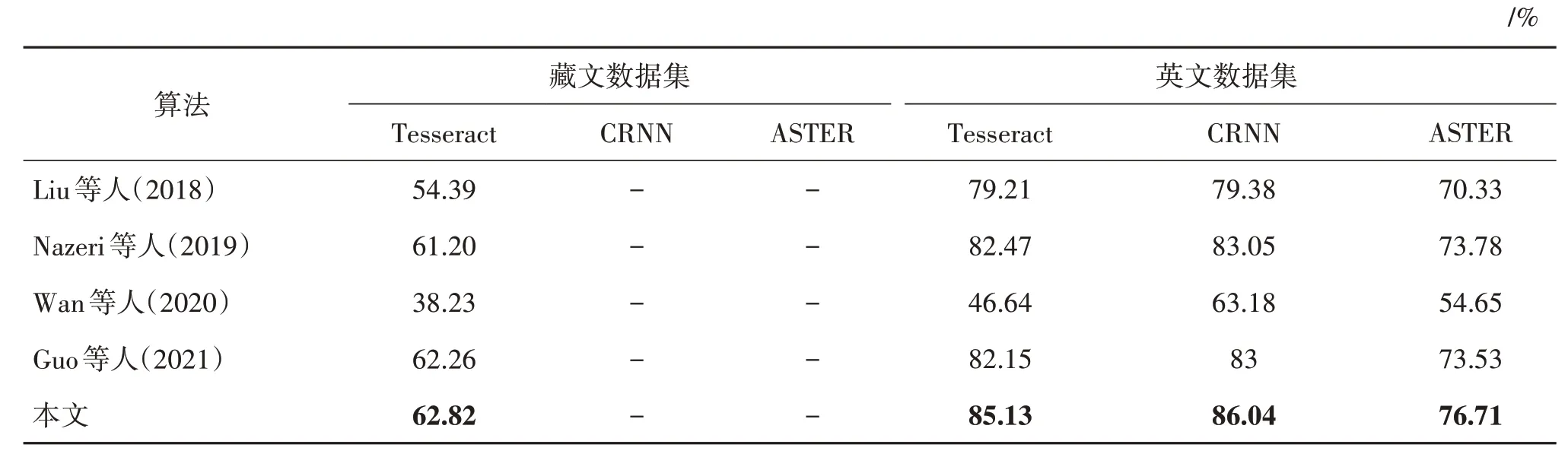
表5 修复效果在OCR结果上对比Table 5 Comparison of inpainting effect on OCR results
Wan等人(2020)方法修复后图像的文字识别效果提升很小,说明该方法修复时并没有考虑到图像上的文本信息。Liu 等人(2018)、Nazeri 等人(2019)和Guo等人(2021)方法对图像上文字修复有一定效果,但因为没有充分利用文本图像序列特征,修复的文字语义有误。
3.4 消融实验
1)静态到动态残差模块。为验证文本图像修复网络中静态到动态残差模块的有效性,本文在藏文数据集上,使用普通残差模块替代静态到动态残差模块,结果如表6 所示。结果表明,不使用静态到动态残差模块修复时,在修复指标和识别指标上均有所下降,证明了静态到动态残差模块的有效性。

表6 消融实验验证结果Table 6 The evaluation results of ablation studies
2)Transformer 模块。为验证结构先验重建网络中使用Transformer模块重建边缘和文本骨架先验的有效性,本文在藏文数据集上,使用卷积替换Transformer 模块,结果如表6 所示。结果表明,不使用Transformer 模块,文本图像的修复效果有所下降,证明了Transformer模块的有效性。
3)结构先验。为验证在文本图像修复中使用结构先验是否有效,本文在藏文数据集上进行了仅使用边缘先验指导、仅使用文本骨架先验指导和不使用任何结构先验指导3种实验,结果如表6所示。结果表明,同时使用两种结构先验的方法优于仅使用一种结构先验和不使用结构先验的方法,证明了结合两种结构先验的有效性。
4)Dice loss。为验证结构先验重建网络中Dice loss的有效性,本文在藏文数据集上仅使用BCE loss约束文本骨架图像的重建,结果如表6 所示。结果表明,不使用Dice loss 约束文本骨架训练,修复后的结果在图像质量评价指标和OCR 识别结果上均不如结合两个损失的方法,证明了有Dice loss 的联合约束使得文本骨架重建更加精确,从而使得修复结果更好。
5)梯度先验损失。为验证梯度先验损失(gradient prior loss)在图像修复阶段的有效性,本文在文本修复网络训练过程中不使用梯度先验损失。由表6中实验结果可以看出,不使用梯度先验损失修复后的结果在图像质量评价指标和OCR 识别结果上均有下降,证明了梯度先验损失在文本图像修复过程中的有效性。
3.5 模型限制
当遮挡掩膜面积很大且遮挡文字部分比例较多时,本文模型的修复效果不佳,如图7 所示,掩膜遮挡住文字前半段的大半部分,背景区域对缺失区域的约束减弱,导致在重建文本骨架和边缘图像时出现文字笔划部分的纹理模糊,使得后续修复网络并未充分提取文本图像序列特征,文字修复出现错误。
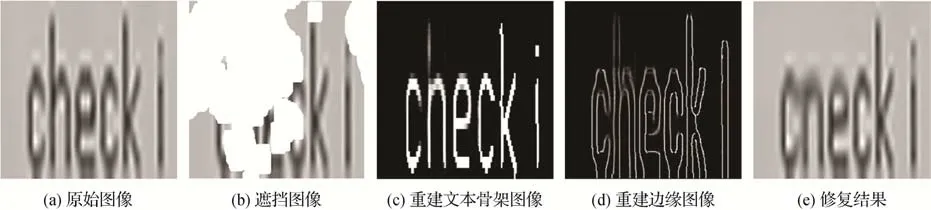
图7 修复失败示例Fig.7 Failure inapinting example((a)original image;(b)masked image;(c)reconstrcuted text skeleton image;(d)reconstructed edge image;(e)inpainting result)
3.6 实际应用
本文使用真实的法藏敦煌藏文文献中截取的文本图像对模型的修复效果进行了测试,使用随机掩膜进行遮挡,如图8(a)所示。修复结果如图8(b)所示,本文模型可以较好地修复真实文本图像破损区域的背景,修复出的文字与真实的文本标签一致,如图8(c)所示。

图8 真实敦煌藏文文本图像修复结果示例Fig.8 Inpainting results on real text images from Tibetan documents from Dunhuang((a)masked images;(b)inpainting results;(c)text labels)
4 结论
本文针对现有自然图像和人脸图像修复方法在修复文本图像时的不足,提出了一种基于结构先验的文本图像修复模型,能更好地解决文本图像修复的问题。模型关注文本图像的主要特征,使用Transformer 模块重构文本骨架和边缘等先验图像,对修复进行指导,设计从静态到动态残差模块提取文本图像中的动态序列特征,使得模型更加关注文字本身,并联合梯度先验等不同损失函数,有效修复破损的文字笔画和背景。本文选择了4 种图像修复方法,在两种语言的数据集上进行比较,结果表明本文方法修复的图像不仅在人类主观视觉效果和客观的图像质量评价上要好于其他图像修复的方法,并且在OCR 识别器的识别结果上也要优于其他模型,表明本文模型不仅关注了图像纹理细节的修复,而且可以有效修复具有正确语义的文字笔画。
本文模型在图像破损区域较大,导致被遮挡的文字比例较大时,修复的效果不佳,原因是由于较大的文字遮挡导致模型可以提取到的有效文本先验信息不足,重建先验图像时有效区域对于缺失区域的约束力减弱,导致重建的先验图像的纹理出现模糊甚至错误的情况,后续的文本特征提取模块提取到模糊甚至错误的文本序列信息,使模型理解的文本语义出现错误,导致修复效果差。对于此问题,本文未来将探索如何将强有力的文本先验信息,如文本标签等,应用到修复方法中。由于文本标签的先验信息不存在模糊或错误的问题,因此将文本标签信息融入文本图像修复的过程,将有效增强修复效果,修复出语义更加准确的文本图像。此外,本文还将探索如何应用文本图像修复方法修复更多语种的真实古籍文本图像,提高其应用价值。
致 谢:此次实验的数据得到了西藏大学人才创新团队与实验室平台建设“计算机及藏文信息技术创新团队”的支持,在此表示感谢。
猜你喜欢
电子乐园·上旬刊(2022年5期)2022-04-09
数学小灵通·3-4年级(2021年5期)2021-07-16
中国新技术新产品(2020年5期)2020-05-06
成都信息工程大学学报(2019年3期)2019-09-25
今日农业(2019年15期)2019-01-03
自动化学报(2017年5期)2017-05-14
探测与控制学报(2015年4期)2015-12-15
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
东南法学(2015年2期)2015-06-05
读者·校园版(2015年19期)2015-05-14
