
深度学习图像合成研究综述
2023-12-23 10:13叶国升王建明杨自忠张宇航崔荣凯宣帅
中国图象图形学报 2023年12期
叶国升,王建明,*,杨自忠,张宇航,崔荣凯,宣帅
1.大理大学数学与计算机学院,大理 671003;2.云南省昆虫生物医药研发重点实验室(大理大学),大理 671000
0 引言
图像合成一直是图像处理领域的研究热点,具有广泛的应用前景。传统的图像合成一般基于计算机图形学的方法实现(Szeliski,2011),聚焦于图像画质增强、图像滤波和画面锐化等任务。在图像合成中,传统方法主要通过对前景对象裁剪加粘贴的方法实现,但是在简单的裁剪粘贴方法中前景对象的大小、位置和旋转角度等因素完全由用户自主选择决定,十分费时费力,并且这些细节因素很大程度上也影响着合成图像的质量。除此之外,传统算法合成的图像在清晰度、自然程度方面效果有限,且工作量大、人工成本高昂。
得益于深度学习的快速发展,基于深度学习的图像合成算法逐渐成熟,图像合成领域的可用算法工具得到丰富和完善(何冀军,2020)。深度学习方法能够简化用户操作,其一般合成过程如图1 所示,通常基于前景来源图像、前景标签图像及待合成背景图像,就能自动进行图像合成,其中前景标签图可以是Mask图或alpha matting图等。

图1 图像合成过程(Cong等,2020b)Fig.1 Image composition process(Cong et al.,2020b)
通过图像合成技术,合成与真实图像自然语义完全一致的图像,是图像合成的最终目标。但当前传统及基于深度学习的图像合成技术,皆面临前景对象的位置确定、大小调整、边界细节模糊处理以及颜色差异调整等各种问题。上述图像合成面临的问题可归结为:1)几何、外观一致性的前景对象适应性问题(Chen 和Kae,2019;Zhan 等,2021b);2)色调不一致、阴影缺失的视觉和谐问题;3)前景对象与背景不符合现实逻辑的生境适应性问题等。
前景对象适应性问题主要指的是在图像合成过程中,前景对象可以自动地以最合理的大小出现在背景图的合理位置,最大程度地接近真实图像。这也是图像合成中关键的一步,在高效完成前景对象适应性后,则需要考虑下一步的图像效果优化。同时,在前景对象被提取并合成在背景图的过程中,边界信息往往因为不精确的标签图导致模糊,图像融合(Kaur 等,2021;Zhang 等,2020b)作为一种图像合成方法,使用各种数学模型将来自不同图像中的关键信息对齐以合成单一图像,一定程度上能够细化边界信息。
在完成图像前景对象合成后,能否达到真实图像的效果不仅需要同时考虑前景对象的大小、位置和边缘细节等情况,还需要关注图像视觉信息是否和谐。而基于深度学习的“图像和谐化”方法能够有效解决合成图像的视觉不和谐问题。同时,图像合成还需进一步考虑前景对象与背景图像的逻辑匹配问题,参考生态领域生境的相关概念,本文提出了图像合成中的生境适应性问题,具体表现为目标前景与合成背景之间是否逻辑自洽,如对于生物目标,其合成图像能否正确表达目标的真实生存环境,对于非生物目标,其合成图像能否正确表达目标存在的合理性。只有解决图像合成的上述问题,才能合成更接近“真实”的图像,从而进一步应用于影视特效、广告制作和图像处理等相关工作。
综上所述,本文系统地论述了目前图像合成任务中面临的各种问题,介绍了不同问题中所使用的公开数据集,同时总结了最新的深度学习研究成果与方法对比,介绍了图像合成技术的应用前景,以及对目前尚待解决的问题展开了深入探讨。为进一步推动图像合成的相关研究工作,提出了一些具有实际参考价值的建议,最后总结了未来工作中可能面临的挑战并对发展趋势提出展望。
1 前景对象适应性问题
在传统的图像合成过程中,手动选择前景对象的放置位置、调整大小比例等往往会占据整个工作的大部分时间,而这部分工作也是合成任务的关键内容,它作为全局任务的初步阶段,很大程度上影响着最终合成图像的质量。同样地,基于深度学习的图像合成方法也面临着类似的问题:模型如何学习才能完成最佳的前景位置选择,如何自适应地根据背景信息调整前景对象的大小等。而前景对象的自适应性能够解决此类问题并为后续工作奠定基础。前景对象适应性问题可细分为两个子问题:1)几何一致性问题;2)外观一致性问题(Chen 和Kae,2019)。其中几何一致性问题主要指图像合成时前景对象的大小调整、空间匹配(位置放置、几何角度确定等)和语义冲突等内容。外观一致性问题主要指合成时前景对象与背景的边界细节优化、前后景遮挡处理等内容。
1.1 几何一致性
几何一致性主要指前景对象在背景图中的几何信息是否匹配,主要表现为前景对象的大小、位置如何确定,前景对象是否需要几何旋转以匹配视角等方面,如图2所示(取自OPA数据集(Liu等,2021))。对于图像合成任务,几何一致是首先需要解决的问题。

图2 几何一致性描述(Liu等,2021)Fig.2 Description of geometric consistency from OPA datasets(Liu et al.,2021)((a)selection of position;(b)adjustment of the size;(c)adjustment of the angle)
对于前景对象的大小、空间匹配问题,Tan 等人(2018)提出语义感知人物图像合成网络,该网络首先通过预测潜在前景对象的边界框,随后检索与局部和全局场景外观相兼容的信息以完成图像合成任务,并通过alpha matting(Chen 等,2012)方法使合成效果更加自然顺滑,但是此网络也存在局限性,主要是合成图像中前景对象更倾向于出现在图像中心位置、无法明确图像和谐化任务、合成前景对象局限于人物以及无法进行端到端处理等。
考虑到空间转换网络(spatial Transformer network,STN)(Jaderberg 等,2015)具有良好的空间不变特性,能够解决图像合成时的空间几何角度问题,Lin 等人(2018)利用STN 提出ST-GAN(spatial Transformer network generative adversarial network),设计了一种STN 扭曲方案及线性训练策略,学习前景对象的高效几何变换以匹配背景图像信息,提高图像真实感,该网络能够应用于高分辨率图像合成任务。但是,网络的不足之处在于当出现数据不平衡时,或前景对象出现极端的平移或旋转时,ST-GAN会失去良好的性能。Tripathi 等人(2019)提出了TERSE(task aware efficient realistic synthesis example),同样利用STN在任务感知合成数据生成的概念上提出在背景图像中生成额外的伪影信息的策略,使得目标网络不受混合伪影的影响,同时目标网络会向合成器提供反馈以生成真实的合成样本。Lee 等人(2018)在STN基础上训练包括两个模块的端到端网络,不同模块分别预测前景对象合理的位置和形状,最后将二者相统一以完成图像合成任务。
为了使前景对象的放置更具合理性,Zhang 等人(2020a)提出了PlaceNe(tplacement network),对于给定前景对象和背景信息,模型预测出前景对象的不同位置分布,并通过判别器检测合成图像的合理性以提高图像合成质量,如图3 所示,但是他们的工作只能在前景对象与背景图像的域相似的情况下完成(Chen 和Kae,2019)。Azadi 等人(2020)进一步提出一种自一致性组合分解网络(self consistent composition-by-decomposition,CoDe),网络能够根据不同分布的前景对象与背景的纹理、形状等特征,通过计算联合分布生成真实图像,并且在合成过程中对每个对象进行了旋转、缩放、平移和对其他对象进行部分遮挡操作,最大程度满足几何一致性的要求。而在人像放置任务中,Li 等人(2019)使用端到端的生成模型,同时预测语义信息上合理且几何上可行的人体前景对象位置和相应的姿态动作,以提高人像合成图像的真实性。
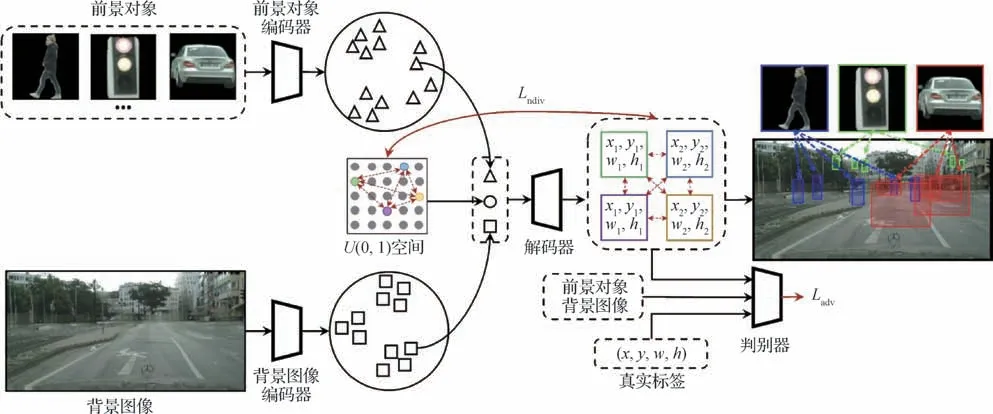
图3 PlaceNet网络结构图(Zhang等,2020a)Fig.3 The network structure of PlaceNe(tZhang et al.,2020a)
Zhu 等人(2022a)同时考虑了前景对象自适应与图像和谐化,提出了几何与照明感知网络(geometry-and-lighting-aware,GALA)。其使用的交替训练策略不仅保持合成图像中语义信息的兼容性,还能够自动检索前景对象最佳的放置位置和大小比例,并通过学习照明信息完成和谐化任务。Bazazian 等人(2022)采用分割引导的方法,提出双域合成(dual-domain synthesis,DDS)框架,将两幅图像分为源域与目标域,分别利用掩码确定待合成区域,将源域中的前景对象合成到目标域中,形成合成结果图。Zhou 等人(2022)将前景对象适应性任务视为图完成问题,提出GracoNet(graph completion network),通过设计图完成模块(graph completion module,GCM),将来自不同位置的不同感受野所提取的信息作为背景结点,并推断出前景对象缺失的位置与大小信息,从图完成的角度进行前景对象几何一致性调整。
1.2 外观一致性
在几何一致性的基础上,进一步对前景对象的外观信息优化,完成前景对象的外观一致性调整,也是图像合成的重要任务。在前景对象适应性(几何、外观一致性)合成的基础上,后续任务将能进一步提升图像真实性。外观一致性主要指前景对象本身的外观特征信息如何与背景图像相适应,如在前景对象合成至背景图中时,前景对象的边缘细节模糊处理、前景对象在背景图中被其他物体遮挡处理等,如图4所示。

图4 外观一致性描述(Zhan等,2021a;Zhang等,2020a)Fig.4 Description of appearance consistency(Zhan et al.,2021a;Zhang et al.,2020a)((a)occlusion between foreground and background;(b)fuzzy of edge details)
1.2.1 前后景遮挡
前景对象在合成至背景图时,背景图中场景复杂,则不同对象间的相互遮挡极易使图像失真,导致任务失败。对于此类问题,Chen 和Kae(2019)在解决几何一致性问题基础上,进一步解决了外观一致性问题,他们提出了颜色和几何一致生成式对抗网络(geometrically and color consistent generative adversarial network,GCC-GAN),在对抗学习过程中学习几何一致和颜色一致,处理遮挡与色调和谐问题,同时也能自动合成不同来源的图像,但是不能处理不同姿势的物体。Zhan 等人(2019)提出了空间融合GAN(spatial fusion GAN,SF-GAN),该网络组合了几何与外观合成器,以合成满足几何与外观一致的图像,但是SF-GAN 结构简单,只适用于单一的前景对象合成,无法适用于多前景目标合成任务。Azadi等人(2020)提出CoDe(composition by decomposition network),通过计算联合分布一定程度上解决了几何一致性问题,进一步完成了外观一致性的统一。类似地,Tan 等人(2019)通过估计目标图像的深度信息,并基于深度信息与对象边界信息检测对象的支撑区域(如地平面),推断相互之间的遮挡关系,最终将前景对象自适应地插入背景图像中,然而其方法也存在不足之处:模型通过语义分割方法提取图像中的感兴趣内容(region of interest,ROI),但是在分割不精确的情况下,前景对象会出现伪影信息影响合成效果。
1.2.2 前景对象边缘细节模糊
由于不精确的前景对象提取技术导致前景对象在合成至背景图的过程中,前景对象边缘处仍有来自源图的背景信息,从而产生边缘细节模糊问题。对于此类问题,一般使用图像融合(Kaur 等,2021)方法,其能够将来自不同图像的有效信息进行合成,使前景对象与背景高度融合,如泊松图像融合可以保证合成图像在颜色上的无缝性,使合成图像在前景对象边界处不存在明显的变化(吴昊和徐丹,2012),有效解决前后景边界模糊问题,如图5所示。

图5 泊松图像融合结果(Gkioulekas和Zhi,2017)Fig.5 Result of Poisson image blending(Gkioulekas and Zhi,2017)((a)foreground source image;(b)background image;(c)composite image)
Wu 等人(2019)结合生成模型和基于梯度信息的融合方法,将二者的优势互补提出了GP-GAN(Gaussian-Poisson GAN)模型,通过使用梯度滤波器获得图像梯度信息,混合GAN 以学习合成图像与融合图像间的映射关系,并利用来自拉普拉斯金字塔(Burt 和Adelson,1983a)的高斯—泊松方程解决高分辨率下的图像融合问题。模型的不足之处在于当合成图像数据分布远离训练数据集分布时,最终的图像合成效果会下降。类似地,受拉普拉斯金字塔混合(Burt 和Adelson,1983b)的启发,Zhang 等人(2021)针对人物肖像合成问题,提出密集连接多流融合网络(denseconnected multi-stream fusion network),以处理不同尺度的肖像前景对象和背景特征,不同于图像和谐化(Cong 等,2020a)的目的是协调前景对象和背景视觉信息,此网络着重于减轻由不完美的前景对象掩码和颜色去污引起的边界伪影问题,以进一步提升图像合成的效果。
考虑到常用的传统泊松图像混合(Pérez 等,2003)方法在合成图像时对梯度域平滑度进行加强,Zhang 等人(2020b)认为该方法只考虑了目标图像的边界像素信息,而不能适应合成背景图像的纹理信息,为此,他们提出了一种泊松混合损失函数,并使用内存限制BFGS(limited-memory BFGS)算法更新像素以重建混合区域,在平滑混合边界梯度域的基础上,进一步添加了一致性的纹理特征,以提高图像质量,其网络模型如图6所示。
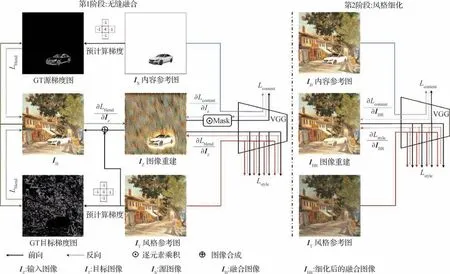
图6 两阶段融合网络结构图(Zhang等,2020b)Fig.6 The network structure of two-stage blending(Zhang et al.,2020b)
几何一致性着力于解决合成图像中前景对象的大小、位置和几何角度等问题;外观一致性着力于解决前景对象与背景图像的遮挡冲突问题和前景对象的边缘细节问题。上述前景对象适应性问题是图像合成技术面临的主要问题,为后续图像合成任务提供了关键基础。
2 视觉和谐问题
视觉和谐主要指合成图像与真实图像相比色调是否一致、合成图像的前景对象是否具有阴影及阴影是否合理等,上述内容可归结为视觉和谐问题。在几何、外观一致性的基础上,视觉和谐也很大程度上影响着合成图像的真实性。此类问题通常由于前景对象与背景图像之间不同的拍摄光照环境、生态环境和气候等因素的影响产生的视觉效果差异造成,一般表现为颜色的不一致性问题(Ling 等,2021),如在夜晚行驶的汽车前景对象合成至白天的背景图中,会出现色调不一致的情况,如图7所示。
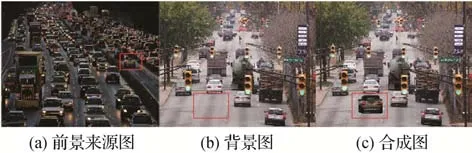
图7 色调不一致的合成图像Fig.7 Composite image with inconsistent tones((a)foreground source image;(b)background image;(c)composite image)
对于视觉和谐中的阴影问题,由于在利用图像分割、图像抠图等技术提取目标前景的过程中,一般不包含阴影信息,从而导致合成图缺失必要的阴影信息。同时,若目标前景所含阴影信息与背景中的其他物体阴影不一致时,也会导致视觉不和谐的问题。
2.1 色调不一致
对于合成图像,通常会出现前后景色调冲突的情况,一般使用“图像和谐化”方法解决合成图像的前景对象与背景色调信息的一致性问题,该方法通过改变前景对象的色调、对比度和饱和度等信息以匹配背景图,从而使全局图像在色调上满足一致性,达到视觉上和谐的效果,使得合成图像更加真实。传统的和谐化方法大都采用基于颜色统计的算法去匹配前后景的外观信息,而基于深度学习的图像和谐化方法能关注更多细节信息并自动和谐视觉效果。另外,图像风格迁移(Gatys 等,2016a,b;陈淑環等,2019)方法也能完成图像和谐化,此类方法尝试将背景图的视觉信息迁移到前景对象中以达到色调一致。
为了使合成图像达到视觉和谐的目的,Zhu 等人(2015)设计了一个卷积神经网络RealismCNN,通过一个判别模型估计合成图像的真实感以达到一定的和谐化目标,但其判别模型在图像合成过程中是固定的,不能做进一步改进。Hao 等人(2020)考虑通过背景调节前景对象的高级特征统计信息以提高和谐化程度,并在全卷积网络结构上提出一个易迁移的基于注意力机制的模块(attention-based foreground-background feature map modulation),此模块能够将前景对象特征的标准差与背景特征的标准差对齐,以捕获整个图像的全局依赖关系,从而使得图像更加真实。Tsai 等人(2017)认为在图像和谐化方法中通过学习前景对象和背景图像的外观特征统计信息存在着一定的不可靠性,为了避免这类问题提出了一个采用编解码器的端到端的卷积网络,可以在协调过程中捕获合成图像的上下文与语义信息,虽然此方法可以在图像和谐化问题上生成真实的构图,但在合成图像时仍须人工确定前景对象位置及调整大小。Cun 和Pun(2020)为进一步提升图像和谐化效果,设计了一个空间分离注意力模块(spatial-separated attention module,S2AM),并将其插入和谐化骨干网络U-Net 中,以学习低层次特征的区域外观变化。随后,在协调没有前景掩码的图像合成任务中,通过插入空间注意力模块和S2AM 的注意力损失完成图像和谐化。Sofiiuk等人(2021)利用预训练的分类网络学习图像高级特征空间,将已有的编解码器框架与预训练的高分辨率深度前景对象感知网络相组合,并提出FN-MSE 目标函数以提高图像和谐化程度。
从前后景域信息角度出发,Cong 等人(2020a)基 于GAN 提 出DoveNet(domain verification network),用域验证鉴别器分别提取前景对象和背景图像的域编码并加以区分,使用生成器将合成图像的前景对象迁移到背景图像所在的域,尽可能使前后景的域代码接近,并构建了用于图像和谐化任务的由HCOCO(harmony Microsoft common objects in context)、HAdobe5k(harmony mit-adobe5k)、HFlickr(harmony flickr)及Hday2night(harmony day2night)组 成的iHarmony4(image harmony datasets)公共数据集(Cong 等,2020b),但是DoveNet 存在训练过程不稳定的问题。为稳定训练过程,并提升和谐化效果,Cong 等人(2021)进一步提出了Bargain-Net(background-guided domain translation network),其使用一个域提取器与两个三元损失调节完成背景引导的前景对象域转换任务,同时模型还具备了预测合成图像和谐化程度的能力。但是,Valanarasu 等人(2023)发现BargainNet 的鲁棒性不足以完成更真实的人像和谐化任务,在其提出的交互式肖像和谐化框架(interactive portrait harmonization,IPH)中,用户可以灵活地选定背景图中的指定区域去引导前景对象的和谐化。虽然IPH 在室外的用户肖像合成图中的和谐化效果显著,但也存在不足之处,即在由人物肖像和物体合成的图像上进行和谐化时,网络性能会下降,在参考区域中出现闪光/反光或区域内容由眼镜、玻璃等特殊对象构成时,模型中样式编码器较难提取有意义的纹理、材料光照反射等信息以完成和谐化任务。同样是对人像合成图像的和谐化,Pandey等人(2021)同时考虑背景信息和人像光照信息,只需将简单的RGB 人像图和目标的高动态范围(high dynamic range,HDR)照明环境作为输入,在合成时不仅能够保持前景对象与背景的高频细节部分,而且能够使前景对象随着HDR 的改变而保持与背景中的照明一致,从而达到前景对象在任意环境光下的匹配,以完成和谐化的任务。但模型也存在不足,主要是光照反射率推断在服装上不准确、人像的眼睛部位无法完成局部和谐化、系统依赖HDR 光照环境作为输入会增加系统负担。
另一种解决色调不一致的方法是风格迁移(Gatys 等,2016a,b),其使用卷积神经网络(如VGG(Visual Geometry Group)(Simonyan 和Zisserman,2015))分别将输入图像的内容特征表示和风格特征表示进行分离与重组,在对高层抽象特征信息处理后完成风格迁移,即将输入的风格图像的风格特征作用于输入的内容图像上,形成最终风格迁移图,一定程度上可以完成图像和谐化的任务。Luan 等人(2018)在使用风格迁移技术的基础上,设计两遍扫描算法(two-pass algorithm),首先将图像的整体风格全部转移到前景对象中,其次细化结果图以准确匹配颜色与质感特征,然后依赖映射神经反应统计信息,保证了图像空间信息的一致性,最终完成前景对象的无缝合成与和谐化。Ling等人(2021)同样将图像风格和谐化视为图像风格迁移问题,设计区域感应的自适应实例归一化模块,提出了RainNet(region-aware adaptive normalization network),该网络能够明确地从背景图中确定视觉风格并将其迁移到前景对象中以完成合成图像的和谐化任务。但是Jiang 等人(2021)发现,风格迁移方法在和谐真实的摄影图像时并不合适,原因在于风格迁移任务中需要语义分割掩码指定特殊区域或需要前后景图像共享相似的布局(如建筑物到建筑物),而这在图像合成及随后的和谐化任务中具有局限性,为此提出无需用户标注的自监督和谐化框架(self-supervised harmonization framework,SSH),无须上述条件即可实现任意摄影合成图像的和谐化。
Guo 等人(2021b)认为合成图像前后景不协调的原因在于前景对象与背景图像不同的反射率与照明差异,为此提出一种自动编码器,将合成图像分为反射部分与照明部分分别进行和谐化:学习并迁移从背景到前景对象的光照信息以协调照明部分,通过材料一致性惩罚(material consistency penalty)协调反射部分,最终完成整体图像的和谐化。Guo 等人(2021a)又提出采用Transformer 的图像和谐化框架D-HT(disentangled-harmonization Transformer),利用Transformer 对上下文依赖的能力,调整前景对象光照与背景光照的和谐程度,同时也保持了结构与语义的稳定性,使合成图像更接近真实图像。
KLD-2Z两段式滚筒烘丝机从停机状态启动后,蒸汽经管路进入烘丝机滚筒薄板夹层,排出蒸汽在薄板夹层中形成的冷凝水,同时,随着烘丝机滚筒薄板夹层蒸汽压力的升高,滚筒薄板温度升高。当薄板温度达到预热温度设定值(由薄板夹层蒸汽压力换算得到)后,烘丝机自动切换至准备状态。当烘丝机收到来料信号并延时后,烘丝机由准备状态切换至启动状态,在此过程中,当出口水分仪检测到物料并延时后,烘丝机切换至生产状态;若烘丝机入口烟丝中断,但中断时间小于设定延时,则烘丝机切换至重启状态,若中断时间大于设定延时,则烘丝机切换至收尾状态。待收尾结束后,烘丝机即进入准备状态;当烘
近年来的深度学习图像和谐化方法主要于低分辨率图像上实现密集的像素—像素的转换,而传统的图像和谐化实现的是RGB-RGB的转换,通常会忽略局部上下文信息。Cong等人(2022)将RGB-RGB、像素—像素转换的两种方法统一组合到端到端的网络中,提出了基于高分辨率合成图像的和谐化网络CDTNe(tcollaborative dual transformation network),该网络不仅在高分辨的和谐化任务中效果显著,而且能有效降低资源消耗。但是,CDTNet的不足之处在于图像的局部和谐化容易失败。Zhu 等人(2022b)认为对前景对象的和谐化采取转移背景图中的全部外观信息是不可取的,为此他们首先根据背景信息调整前景对象的位置,并利用两种外观转移策略(location-to-location、patched-to-location)实现从粗到细的前景对象外观调整。Peng 等人(2022)认为现有的图像和谐化过程是对整个前景对象执行同样的和谐化过程,忽略了每个色块间的差异造成的细节信息丢失,为此提出了基于细粒度区域感知图像和谐(fine-grained region aware image harmonization,FRIH)的全部—局部两阶段框架。在第1 阶段完成全局粗粒度协调;第2阶段通过像素的RGB值将输入前景对象掩码自适应地聚类成子掩码,并将子掩码与粗粒度协调图像分别连接输入级联模块中,通过设计的融合预测模块关注具体细节信息,最终根据区域感知的局部特征调整完成全局的和谐化任务。
2.2 阴影缺失
合成图像中若缺少必要的阴影信息会严重破坏图像的真实感,如图8 中DESOBA(deshadowed object association)数据集(Hong 等,2022)所示。阴影生成(Liu 等,2020)是使合成图像更加真实的关键步骤,在单一前景对象合成任务中,通常面临阴影是否需要生成,如何根据背景光照信息等生成合理的阴影等问题;在多前景对象合成时,通常面临合成图像中前景对象阴影信息如何做到与背景图中的其他物体阴影保持一致、相互之间的阴影重叠如何处理等问题。上述阴影生成的相关问题将极大程度影响合成图像的最终效果(Zhang 等,2019b)。

图8 前景对象阴影生成(DESOBA(Hong等,2022))Fig.8 Foreground object shadow generation(DESOBA(Hong et al.,2022))((a)composite image;(b)foreground mask image;(c)shadow generate target image)
在前景对象阴影生成中,常用的方法可以分为使用渲染方法和图像到图像的转换方法。其中使用深度学习的渲染方法(Liu 等,2017;Garon 等,2019;Weber 等,2018;Hold-Geoffroy 等,2019)大都需要用户进行交互,从低动态范围(low dynamic range,LDR)的图像中估计高动态范围(HDR)照明信息或场景几何信息以产生阴影信息(Liu等,2020)。在给定环境光配置和2DMasks 的条件下,Sheng 等人(2021)设计了交互式软阴影网络(soft shadow network,SSN),为用户选择下的前景对象生成阴影。但是不足之处在于模型无法处理大视野的阴影信息,并且假设物体总是位于地平面上,无法解决物体悬浮在地面上方或更加复杂场景的情况。而无需用户交互的渲染任务(Liao 等,2019;Gardner 等,2019;Zhang等,2019a)尝试从单一图像恢复照明条件和场景几何信息,但这种估计十分困难且结果并不能完全达到预期效果(Zhang等,2019b)。
生成式对抗网络(generative adversarial network,GAN)(Goodfellow 等,2014)及其变体,如CGAN(conditional GAN)(Mirza 和Osindero,2014)和WGAN(Wasserstein GAN)(Arjovsky 等,2017)广泛应用于各种生成式任务中,如阴影检测、阴影去除等任务,在阴影生成任务中也应用广泛(Liu等,2020)。阴影生成任务作为图像到图像的转换任务之一,这组方法学习了从没有前景对象阴影的输入图像到有前景对象阴影的输出图像间的映射关系,与需要明确光照、反射率、前景对象材料特性以及场景几何等信息的渲染方法不同(Hong 等,2022),此类方法无须上述信息即可生成对应的阴影。Hu 等人(2019)针对阴影去除的任务设计了Mask-ShadowGAN 网络,其能够自动根据输入图像生成前景对象掩码,并利用循环一致性(cycle-consistency)约束通过阴影掩码引导生成前景对象阴影,但模型难以生成复杂场景中的前景对象阴影。Zhang 等人(2019b)使用渲染技术和公共3D 模型生成数据集,设计了ShadowGAN模型,其采用局部—全局条件对抗方案进行前景对象阴影的形状和方向监督,最终在合成图像中生成阴影,但是该方法只限于单一前景对象的阴影生成,无法适用于多前景对象的阴影生成任务,并且模型也没有考虑背景图像照明信息的影响,同时数据集也是通过软件渲染生成,并非采用真实的场景图像,因此模型无法保证真实图像的阴影生成效果。上述部分方法需要使用环境光照明信息作为辅助,一定程度上增加了成本消耗。而在不使用照明条件等其他信息的情况下,Liu 等人(2020)构建了大规模的Shadow-AR数据集,并充分利用空间注意力机制引导的残差网络(He 等,2016)研究对象遮挡及其阴影间的关系,在为插入的前景对象生成粗略阴影后,通过细化模块进一步优化阴影信息。同样基于注意力机制,Hong 等人(2022)在SOBA(shadow-object association)数据集(Wang等,2020)基础上,构建真实复杂场景下的阴影生成数据集DESOBA,并设计出两阶段的阴影生成网络SGRNet(shadow generation network),如图9所示。图9中第1阶段使用交互集成注意力机制(cross attention integration,CAI)完成前景对象特征与背景特征的信息交互,以生成前景对象的阴影掩码;第2阶段进行阴影填充最终完成前景对象的阴影生成任务。SGRNet的不足之处在于无法获得复杂前景对象的详细信息,因此无法生成相对应的阴影。

图9 SGRNet网络结构图(Hong等,2022)Fig.9 The network structure of SGRNe(tHong et al.,2022)
前景对象的阴影生成需要考虑的因素较多,包括背景光照信息、背景图中其他对象的阴影信息以及相互遮挡等,如何准确高效且简便地生成合成图像中的前景对象阴影信息仍需进一步研究。
2.3 色调一致与阴影生成
在视觉不和谐问题中,同时解决色调不一致问题和前景对象阴影缺失问题能达到更好的合成效果,但是同时解决上述两个问题的深度学习方法较少。Zhan 等人(2021b)提出端到端对抗图像合成网络AICNe(tadversarial image composition network),在将前景对象合成到指定区域后,通过阴影生成模块和纹理处理模块生成局部图像,通过照明模块推断并生成照明图辅助前景对象阴影生成,最终结合空间转换模块桥接局部和全局信息进行联合优化,以合成全局图像,同时完成阴影生成与图像和谐化的任务,但是网络需要额外的Laval Indoor 数据集(Cheng 等,2018;Gardner 等,2017)。Hu 等人(2021)将图像和谐化任务分为背景图像的光照估计和前景对象的协调两个任务,其设计了神经渲染框架(neural rendering framework,NRF)和阴影模块,从光照图中学习方向感知光照信息,并通过阴影模块为前景对象进行阴影生成。但其前景对象局限为人体对象,且模型无法扩展至其他物体。
在前景对象适应性问题解决的基础上进一步解决视觉和谐问题,最终的合成图像便能够达到与真实图像无异的视觉效果。但是在图像合成过程中,仍有“生境适应性”问题需要解决,生境适应性问题是从逻辑层面考虑前景对象与背景图像是否合理匹配,而这也是用户判别图像真假的关键步骤。
3 生境适应性问题
通过图像合成技术,合成与真实自然语义完全一致的图像,是图像合成的最终目标。也就是要通过图像合成技术,合成目标前景与背景完美匹配,无上述外观、几何、阴影、色调和风格等不一致性问题的图像。对于非生物目标,上述合成技术已经能够合成逼近真实的图像,达到以假乱真的效果。可以将符合上述技术性指标要求的图像合成称为技术适应性合成。但对于部分生物目标而言,如未受人类行为过度干扰或驯化的野生动物,要合成具有生态学意义、真实美学价值,或进一步满足作为图像识别的数据增强需求而言,图像合成除了应满足技术适应性条件的同时,还需要考虑生物目标的生境适应性问题。本文引入生态学中生境的概念,提出了图像合成中的生境适应性问题。生境是指具体的生物个体的群落生活地段上的所有生态因子构成的目标生物的生态环境,这里的生态因子是指环境中对生物生长、发育、生殖、行动和分布有直接或间接影响的环境要素,如光、温度、湿度和风等气候因子,包括土壤的各种特征如土壤理化性质等土壤因子,包括各种地面特征如坡度、坡向等地形因子,包括同种或异种生物之间各种相互关系的生物因子,及其他各类生物和非生物因子(左玉辉,2011)。因此,对于部分生物目标的图像合成来说,只有在满足技术适应性要求的同时,进一步满足生物目标前景的生境适应性,才能合成与前景生物目标对象实际情况一致的“真实”图像,这样的合成图像才具有生态学意义,如图10(iHarmony4 数据集)所示,才能进一步应用于影视特效、广告制作、图像处理以及图像数据增强等应用领域中。进一步地,可扩充生境概念的外延至其他需要真实模拟的非生物对象中,如家用汽车的“生境”指一般道路或路面平整的陆地,而不是海洋或天空等。

图10 生境适应性比较(iHarmony4数据集(Cong等,2020b))Fig.10 Comparison of habitat adaptation(iHarmony4(Cong et al.,2020b))((a)foreground source image;(b)foreground;(c)background image of snow scene;(d)composite image of snow scene;(e)background image of grassland scene;(f)composite image of grassland scene)
3.1 约束前景对象的搜索方法
为解决图像合成任务中生境适应性问题,获得逻辑合理的前后景图像,一种方法是针对待合成的背景图像,制定前景对象约束条件并设计搜索方法得出符合该背景图像的前景对象,用于后续的图像合成任务。
Tan 等人(2018)在人像合成任务中使用卷积神经网络从背景图像的特征信息中检索合适的人物前景,其需要额外在背景图像中标记出前景对象的放置框以及前景对象局部背景框,网络从局部背景框中学习出更详细的特征信息并以此从人物前景数据集中得出合理的前景对象。该方法不足之处在于前景对象选择局限为人,同时额外的标注信息也增加了成本。与之类似,Zhang 等人(2020a)在合成任务中添加了数据增强方法,即分别构建特定类别的前景对象数据集、无前景对象的“干净”背景数据集,并使用K近邻方法从前景数据集中筛选出与先前在背景图像中的前景对象相近的K个前景,随后在K个前景中进行随机挑选输入图像合成模型。这种方法简单地实现了前景对象的搜索,但是其局限性在于其前背景数据集的域信息必须接近,如背景为城市道路,那么前景数据集需要是汽车、红绿灯、行人等,因为K近邻选择需要根据背景图像中的原始前景对象得来,所以此方法的前景对象选择无法扩展到其他类别。
Zhao 等人(2018)提出一种图像感知搜索技术(compositing aware image search,CAIS),对于给定待合成背景图像、前景对象类别信息和前景对象在背景图中的位置信息,CAIS 通过学习前景对象与背景图像的特征表示并使用余弦相似度计算前后景的兼容性得分,最终返回该类别的合适前景对象。但是其不足之处在于任务中仍然需要额外的前景对象类别标注与背景图中的前景空间位置标注,并且需要提供统一的前景类别数据集,同时前景搜索结果的类别较为单一。
3.2 无约束的前景对象搜索方法
与约束前景对象的搜索方法不同,无约束的前景对象搜索方法不需要额外指定前景对象类别,能够返回更多的不同类别的前景对象,增加了图像合成的内容多样性。
Zhao 等人(2019)提出无约束前景对象搜索模型(unconstrained foreground object search,UFO),如图11 所示。其克服了CAIS 检索结果类别单一的问题,模型通过计算余弦相似度,并使用K近邻算法返回合适背景图像的多个类别的前景对象。但是该任务仍然需要在背景图像数据集中标记出前景对象的空间位置。

图11 UFO网络结构图(Zhao等,2019)Fig.11 The network structure of UFO(Zhao et al.,2019)
上述方法无论是否需要约束前景对象的类别信息,其在前景对象的生境匹配过程中都需要在背景图像上进行空间位置标记处理,而这则是在前景对象适应性任务中完成,因此上述方法并不能很好地与图像合成任务相结合。
3.3 前后景二分图匹配方法
生境适应性任务完成的是前景对象与背景图像的逻辑性匹配,可以将该任务视为解决二分图的多重匹配问题。前景对象类结点与背景图像类结点分别属于不同的集合,需要对不同集合中关联度较高的结点进行多重匹配。
Brasó 和Leal-Taixé(2020)在多目标追踪(multiple object tracking,MOT)任务中将二分图匹配的问题直接转换成图神经网络中的边分类问题,通过对边进行二分类判断该边是否被选中以完成相关结点的信息匹配。将此设计思想用于完成生境适应性匹配中,可以做到无需在背景图像上进行位置标记,同时能够得出符合现实逻辑的前后景图像对,网络结构如图12 所示。其通过对来自不同类(前景/背景)的图像进行特征提取,并作为图神经网络的结点,网络完成不同前后景结点之间的关联度信息学习,最终对边权信息进行分值筛选得出关联度高的前后景图像对,以此作为生境匹配依据或直接作为图像合成任务的输入数据。

图12 基于图的生境适应性匹配网络结构Fig.12 The network structure of adaptive habitat matching based on graph
针对生境适应性问题,无论是生物或非生物前景对象,通过判断其与待合成背景图像之间的现实逻辑关系,能够保证图像合成结果在逻辑、语义等方面是真实的,而其他部分则由前景对象适应性任务、视觉和谐任务完成,以最大程度地使合成图像接近现实图像。
4 评价指标
为了对最终的合成图像任务进行质量评估,判断其结果是否接近真实图像,常用的评价方法分为用户定性评价和指标定量评价这两类。
4.1 定性评价
1)Precision@K(P@K)。Zhao 等人(2019)为了对生境适应性问题中的前景对象检索的多样性进行评价,通过用户研究衡量K个检索结果中与背景相互兼容的前景对象百分比。具体地,通过向不同用户展示一幅背景图像和模型检索出的K个候选前景对象,要求用户挑选出与背景图像不兼容的前景对象。每幅背景图由3 个不同的用户进行评估,任意一个用户将任意一个前景对象标记为不兼容,则视该前景对象为不兼容。通过上述步骤,能够衡量模型生境适应性问题的解决能力。
2)Realism CNN。为了能够区分出真实图像与合成的图像,Zhu 等人(2015)通过设计RealismCNN虽然并不能够从图像语义、场景布局和视角等角度对图像真实性进行判断,但是已经可以做到从图像的颜色兼容性、照明一致性和纹理兼容性等方面判断图像的真实性,完成对合成图像真实性的质量评价。
3)AMT(Amazon mechanical turk)。研究人员将他们的合成图像放置于AMT 上,交由不同用户进行图像真实性判断与打分,最终根据得分结果评价合成图像质量。使用AMT 可以完成图像合成任务中的任一子任务的质量评价,但是该方法也因为不同用户之间的主体感官差异性对评价结果存在一定的影响。
4.2 定量评价
4.2.1 前景对象适应性问题评价方法
在解决前景对象适应性问题中的外观与几何一致后,有如下常用的定量评价方法评估图像合成质量:
1)直方图相关性(histogram correlation,HC)。Tan 等人(2018)通过计算图像中预测框和真值框分布的相关性分析合成图像的真实程度。
2)Frechet inception 距离(Frechet inception distance,FID)。通过计算合成图像与真实图像之间的FID 值(Dowson 和Landau,1982;Heusel 等,2017),同时计算成对的采样对象边界框间的欧几里得距离以获得前景位置的多样性分布,量化前景对象位置的合理性(Zhang等,2020a;Zhou等,2022)。
3)结构相似性指数(structural similarity index measure,SSIM)。衡量图像相似性的指标,可用来衡量合成图像与参考图像间的相似度,最终评价合成图像质量(Kaur等,2021;Guo等,2021b;Paramanandham和Rajendiran,2018;Wang等,2004)。
4)操作评分(manipulation score,MS)(Chen 和Kae,2019)。该分数由操作检测模型生成(Zhou 等,2018)。模型通过RBG 流提取特征,根据对比度差异,不自然的篡改边界等找到可能篡改的区域,通过噪声流发现真实区域与篡改区域间不一致的噪声,最后利用双线性池化层合并特征,得出检测结果。MS 中较高的评分表明该合成图像被用户操作(拼接、复制、移动和删除等)的可能性高,即图像可能是伪造的。
5)学习感知图像块相似度(learned perceptual image patch similarity,LPIPS)。也称为“感知损失”,用来度量两幅图像间的差别,同时可用于对象放置位置的多样性评价(Zhang等,2018;Zhou等,2022)。
在使用图像融合方法处理合成图像中前景对象边缘细节模糊问题时,常用如下定量评价指标:
1)通用图像质量指标(universal image quality index,UIQI)。在合成图像结构信息的基础上组合了相关损失、亮度畸变和对比度畸变。该指数能够有效地在参考图像与合成图像间测试合成图像质量(Du和Gao,2017;Wang和Bovik,2002)。
2)互信息(mutual information,MI)(Qu 等,2002)。该指标度量两个对象之间的相互性,它提供了合并到结果图中的输入图像的信息细节,越高的互信息指数表示图像合成越高效(Kaur等,2021)。
3)特征互信息(feature mutual information,FMI)。该指标在互信息MI(Qu 等,2002)和特征信息的基础上,进一步通过计算以检测合成图像的质量。
4)平均绝对误差(mean absolute error,MAE)。通过计算参考图像与最终合成图像的相关像素平均绝对误差值完成结果评价(Du和Gao,2017)。
4.2.2 视觉和谐化评价方法
在前后景视觉和谐问题中的色调不一致问题中,对于和谐化后的图像有如下常用定量评价指标:
1)均方误差(mean squared error,MSE)。在和谐化任务中,从数据集中所有像素中(数据集级别)评估合成图像的和谐化性能(Guo 等,2021b;Cun 和Pun,2020;Peng等,2022;Zhu等,2022b)。
2)前景对象均方误差(foreground mean squared error,fMSE)。不同于MSE 计算整幅合成图像,fMSE只考虑计算前景对象区域的MSE,且衡量在数据集上平均每个单幅图像(有不同大小前景对象)的和谐化效果(图像级别)(Cong 等,2020a;Guo 等,2021b;Peng等,2022;Zhu等,2022b)。
3)峰值信噪比(peak signal-to-noise ratio,PSNR)。常用于衡量和谐化后的图像质量(Kaur等,2021;Guo 等,2021b;Patil 等,2013;Cun 和Pun,2020;Peng等,2022;Zhu等,2022b)。
4)结构相似性指数(structural similarity index measure,SSIM)。在数据集所有像素中(数据集级别)评估合成图像的和谐化性能(Kaur 等,2021;Guo等,2021b;Paramanandham 和Rajendiran,2018)。
5)前景对象结构相似性指数(foreground structural similarity index measure,fSSIM)。同样衡量在数据集上平均每个单幅图像(有不同大小前景对象)的和谐化效果(图像级别)(Guo等,2021b)。
在前后景视觉和谐问题中的阴影缺失问题中,对于阴影生成后的合成图像有如下常用的定量评价指标进行评估:
1)结构相似性指数(SSIM)(Liu等,2020)。
2)全局结构相似性指数(global SSIM,GSSIM)/局部结构相似性指数(local SSIM,LSSIM)。越高的GSSIM 和LSSIM 表示阴影生成后的图像质量越接近真实的图像(Hong等,2022)。
3)均方根误差(root mean squared error,RMSE)。能够反映图像间的差异程度,该指标在MSE 的基础上取平方根得到(Sheng 等,2021;Liu 等,2020;Hu等,2019)。除此之外,在RMSE 指标的基础上,定量评价指标进一步使用全局均方根误差(global RMSE,GRMSE)与局部均方根误差(local RMSE,LRMSE),分别计算整个图像与阴影区域的RMSE 值(Hong等,2022)以完成质量评价。
4)局部均方误差(local mean squared error,lMSE)。为了解决MSE 对单个图像边缘进行错误分类破坏图像不同部分的阴影和反射率信息从而导致错误结果的不足之处,Grosse 等人(2009)进行了改进,以用于阴影生成任务的评价。
5)尺度不变均方根误差(RMSE-s)。在MSE(Patil等,2013)的基础上,进一步对像素角度进行加权处理(Sheng 等,2021;Barron 和Malik,2015;Sun等,2019)。
6)结构差异性指数(structural dissimilarity index measure,DSSIM)。用于计算不同图像间平均结点的距离分布差异(Sheng等,2021;Schieber等,2017)。
7)平衡错误率(balance error rate,BER)。在自然图像和合成图像中,阴影像素比非阴影像素少很多,造成图像阴影数据的不平衡。而通过计算生成的阴影中错误的像素数可以衡量阴影生成的质量(Nguyen等,2017;Liu等,2020)。
8)零均值归一化互相关(zero-normalized crosscorrelation,ZNCC)。能够对参考子区域和目标子区域进行相关性估计。ZNCC的范围位于-1与1之间,越接近于1 表示匹配性越好,即生成图像与真值图越接近(Sheng等,2021;Dematteis和Giordan,2021)。
9)准确率(Accuracy)。用于计算在所有样本中正确标记的样本。其表示为像素点中正确生成阴影信息的百分比,该值越高表示生成的阴影越接近真实的阴影(Liu等,2020)。
在图像合成的各任务中,对合成结果的评价往往同时采用定性评价与定量评价,一方面定量评价指标缺乏用户参与,没有用户主观判断存在一定局限性;另一方面大量地使用定性评价不仅需要耗费大量人力与时间成本,同时不用用户个体的主观差异容易对评价结果产生不同的影响。因此将二者结合使用能够合理且高效地反映合成图像的质量。
5 公开数据集
在图像合成任务中,由于不同的子任务解决的问题有一定针对性与特殊性,并且目前尚无适用于图像合成整体任务的大规模数据集,因此根据图像合成的任务性质划分为前景对象自适应、图像和谐化和前景对象阴影生成3 个任务场景,并分别针对上述场景介绍数据集。
5.1 前景对象自适应任务
5.1.1 OPA数据集
OPA(object placement assessment)数据集(Liu等,2021)主要用于解决几何一致性问题与外观一致性问题的任务中。其为了验证合成图像中的前景对象在位置、大小、遮挡和语义等方面是否合理,基于Microsoft COCO(Microsoft common objects in context)数据集(Lin 等,2014)构建而成,OPA 由前景对象图像、背景图像及合成图像组成,共包含47 个类别的前景对象,并通过将任意大小、位置和遮挡的前景对象剪贴至背景图像中,最终通过用户标注得到了62 074幅训练图像和11 396幅测试图像,共计73 470幅图像。同时数据集中也对合成图像进行了类别标注,positive 与negative 分表表示合理与不合理的前景对象放置,在训练集中,positive 与negative 数量分别为21 376 与40 698。而在测试集中,positive 与negative 数量分别为3 588 与7 808。OPA 中不同前景对象类别图像数量如图13所示。
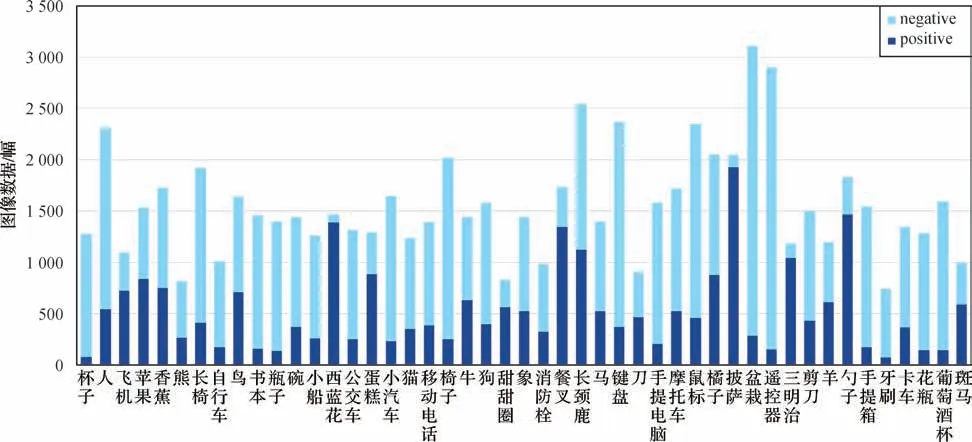
图13 OPA中不同前景对象类别图像数量(Liu等,2021)Fig.13 Number of category images for different foreground objects in OPA(Liu et al.,2021)
5.1.2 TA数据集
TA(transient attribute)数据集(Laffont 等,2014)可以用于解决外观一致性问题的任务中,能够帮助模型更好地学习合成图像中前景对象外观的调整。
Laffont等人(2014)为了获取长时间的静态视角高质量图像,并希望可以通过瞬态属性特征进行对象图像的索引,其挑选了101 个户外摄像头拍摄的图像数据并进行处理,在每个摄像头中,选择出能够代表场景外观变化的高质量图像,并交由人工审核,使得不会出现伪影信息,如过多噪声、量化伪影和脏镜头等。同时为了使数据集场景信息精确且多样化,数据集中场景选择包括从山地场景至城市场景多个场景,并且每幅图像在640 × 360像素至4 000 ×3 000像素之间变化,同时通过了手动指定每个摄像头以获得图像的对应关系,最终得到8 571幅图像构成TA数据集。
Wu等人(2019)考虑到TA数据集中图像数据包含了一天中不同时间与季节引起的明显外观变化信息,可以用于前景对象适应性问题中外观一致性的学习,因此其使用TA数据集作为图像融合任务的训练数据集。
5.2 图像和谐化任务
5.2.1 iHarmony4数据集
iHarmony4 数据集(Cong 等,2020b)主要用于解决色调不一致问题的任务中,因为其大规模的数据组成已成为图像和谐化任务常用的数据集。
iHarmony4 数据集包含了HCOCO、HAdobe5k、HFlickr 及Hday2night这4 个子数据集,由合成图像、合成图像的前景对象标签图像和其对应的真实图像组成。其中,HCOCO 子数据集由Microsoft COCO 数据集(Lin 等,2014)生成,Hadobe5k 子数据集由MITAdobe5K 数据集(Bychkovsky 等,2011)生成,Hflickr数据集通过Flickr网站收集生成,Hday2night子数据集由day2night 数据集(Zhou 等,2016)生成。iHarmony4 数据集提供了包含65 742 幅训练图像和7 404幅测试图像,其数据构成如表1所示。

表1 iHarmony4公开数据集构成Table 1 The public datasets of iHarmony4
iHarmony4 的构建过程参考了Tsai 等人(2017)的方法,首先生成合成图像,利用颜色转换的方法随机挑选前景对象并编辑它的颜色外观信息,通过参考图像保证颜色转换的合理与真实。具体地,对于目标图像及其相应的对象掩码信息,搜索具有相同语义信息的参考图像,将参考图像的颜色外观信息转移到目标前景对象上,此时的前景对象看上去合理但是不匹配背景信息。在颜色转移过程中,使用直方图匹配方法,并计算亮度与色温的统计数据。同时为了生成多种不同类型的颜色转移结果,对一幅图像的亮度和色温使用不同的颜色转移参数,以扩大模型的泛化能力。
5.2.2 RHHarmony 数据集
RHHarmony 数据集(Cao 等,2022)主要用于色调不一致问题的任务中,不同于真实世界内容的数据集,其通过渲染方法最终生成大规模的人像图像和谐化数据集。
RHHarmony 中包括合成渲染图像与标签图像以及准确的前景标签图。其使用开源软件MakeHuman(Make Human Community,2022)创建不同属性的3D 人类角色,包括身高、体重、面部等身体特征,行走、跑步等行为姿势和各种服装,从Unity Asset-Store和CG网站(Cao等,2022)收集了30个包括市中心、街道、森林等室外场景图和体育馆、健身房等3D室内场景图,对不同3D 场景中获得的2D 图像进行实况渲染采样,并将3D 人类角色导入至3D 场景图中。通过改变角度拍摄2D场景信息,最终收集了来自30个3D场景中分别设置的50个摄像机视点的结果图,总计1 500幅2D真实渲染合成图像。
为进一步丰富渲染数据集的视觉信息,其在天气系统插件Unistorm(Cao 等,2022)的辅助下,为每个2D图像生成不同的气候条件图像。具体地,通过选择晴、部分多云和多云这3 个代表性天气,并划分出日出与日落、中午、晚上与其他时间这4 个时间段,将天气条件与时间段相组合,基于1 500幅2D渲染合成图像最终生成15 000 幅带有人类前景对象与不同视觉效果的渲染合成图像。最终有65 000对带有人类前景的合成图像与目标渲染图像用于训练。
5.2.3 RealHM数据集
RealHM(real-world harmonization)数据集(Jiang等,2021)主要用于解决色调不一致问题的任务中,不同于iHarmony4 数据集的图像内容丰富,RealHM主要是由人物图像构成。为了避免对前景对象使用简单的颜色转换生成和谐化数据集影响和谐化结果评估,Jiang 等人(2021)构建的RealHM 数据集用于和谐化结果测试,包括前景来源图像、前景来源特写图像、背景图像、合成图像及和谐标签图像总计216组1 089幅测试图像。
其使用的训练数据集是来自Microsoft COCO(Lin等,2014)、day2nigh(tZhou等,2016)等相关数据集与互联网,包括了不同光照条件下的山、河流、天空和人体肖像,并收集100 张3D 颜色查找表(lookup table,LUT),用于在训练中随机选择两种颜色,构成100 × 100 种组合图像颜色数据具有多样性,训练数据总计81 917幅。
在测试集RealHM 中,通过PhotoShop 工具对硬边界与软件界(如毛发)进行不同处理,将前景外观(颜色、亮度、饱和度和对比度)与背景进行匹配,并对特定的局部区域做进一步处理。最终获得了216组高质量、高分辨率的前景/背景图以及和谐化结果输出图。数据集图像中前景内容包括人体肖像和一般物体,背景包括山、河流、建筑和天空等。
5.2.4 HVIDIT数据集
HVIDIT(harmonization VIDIT)数据集(Guo 等,2021b)主要用于解决色调不一致问题的任务中,参考 了VIDIT(virtual image dataset for illumination transfer)数据集(El Helou等,2020)构建而成。
VIDIT数据集用于重光照(relighting)任务,其包括390 个不同的虚拟场景,分别在每个场景中使用40种照明条件捕获得到,其中300个用于模型训练,90个用于测试,Guo等人(2021b)使用了其公开可用的训练场景。同时,鉴于VIDIT 数据集与day2night(Zhou 等,2016)数据集的相似性,都是在不同的光照条件下捕捉相同的场景图像,因此参考了iHarmony4 数据集(Cong 等,2020b)中Hday2night 子集的构建方法,并去除明显会破坏背景语义信息的图像,构建了用于图像和谐化任务的数据集HVIDIT,最终有276个场景共3 007幅图像用于训练,24个场景共329幅图像用于测试。
5.2.5 ccHarmony数据集
ccHarmony(color checker harmony)数据集(Huang 和Niu,2022)主要用于解决色调不一致问题的任务中。Huang 和Niu(2022)认为在真实图像上通过调节前景对象的外观颜色信息构成图像和谐化数据集并不能真实地反映前景对象的自然照明变化,为此其基于颜色检查器(color checker)记录光照信息的数据集;NUS(National University of Singapore dataset)(Cheng 等,2014)与Gehler 等 人(2008),通过将真实图像的前景对象转换为标准照明条件,随后将其转换为另一种照明条件并与背景图结合构成新的合成图像,以此生成ccHarmony 数据集。
5.3 前景对象阴影生成任务
5.3.1 SOBA数据集
SOBA 数据集(Wang 等,2020)的创建主要是为了完成实例对象阴影检测任务,也可应用于解决视觉和谐问题中的阴影缺失问题的任务中。
Wang 等人(2020)通过从ADE20K(Zhou 等,2017,2019)、SBU(Stony Brook University)(Hou 等,2021)、ISTD(image shadow triplets)(Wang 等,2018)、Microsoft COCO(Lin 等,2014)数据集与互联网进行关键词搜索得到1 000 幅图像,并对图像进行粗标记,生成阴影实例掩码与阴影—对象关联掩码图,使用Apple Pencil 进行细化。随后通过从阴影—对象关联掩码图中去除每个阴影实例的掩码以获得对象实例掩码图,最终构成的数据集中共有3 623 对阴影—前景对象实例图。最终,SOBA 由带阴影的图像、实例对象及阴影标签图、缺少阴影的实例标签图与阴影标签图组成,数据图像内容对象包括动物、人、汽车和街道等。
5.3.2 Shadowed-AR 数据集
Shadow-AR(shadow augmented reality)数据集(Liu 等,2020)主要用于解决阴影缺失问题的任务中。为了弥补已存在的相关阴影数据集的不足之处,Liu等人(2020)在虚拟场景中生成与现实场景同等效果的对象阴影信息,通过相机拍摄与阴影渲染的方法构建Shadow-AR 数据集。其收集来自LogitechC920 相机通过不同姿势拍摄的原始图像,保留了真实世界的阴影与对象的遮挡物,将其作为阴影推断的信息。并从ShapeNet(Chang 等,2015)、Standford3D(Liu 等,2020)扫描库中分别选择9 个及4 个模型插入至图像中,以生成不同前景与背景的合成图像。
Shadow-AR 中包含3 000 组关联图像,每组图像中分别由无虚拟对象阴影的合成图像、虚拟对象标签图、原始场景图像中的对象标签图、原始场景中的对象阴影标签图及带有虚拟对象阴影的合成图这5类图像组成。
5.3.3 DESOBA数据集
DESOBA(DEshadowed SOBA)数据集(Hong 等,2022)主要用于解决阴影缺失问题的任务中。它在SOBA(Wang 等,2020)数据集的基础上去除了所有的阴影构建而成,同时DESOBA 提供了对象—阴影对掩码信息,能更有效地用于物体阴影生成任务。
对于给定的目标图像Ig,手动去除所有阴影信息产生无阴影图像Id,并在目标图像Ig中随机选择一个前景物体,将其阴影区域替换为Id中的区域(即无阴影区域)以产生无前景对象阴影信息的合成图像Ic,Ic与Ig构成输入图像和真实目标图像。
根据背景图中前景对象是否有其配对的阴影信息,DESOBA 数据集分为BOS(background object shadow)与BOS-free 两部分,在BOS 中,配对的物体及其阴影信息可以为图像光照信息推断提供一定的依据,其由合成图像、前景对象标签图像、背景对象标签图像、背景对象阴影标签图像和真实标签图像组成,而在BOS-free 中,可以根据天空、地面和物体阴影明暗变化等推断出光照信息,其由合成图像、前景对象标签图像和目标图像组成。
以上数据集分别为图像合成不同任务中常用的公开数据集,其具体数据信息如表2 所示,数据集获取地址如表3所示。

表2 图像合成任务公开数据集Table 2 The public datasets of image composition task

表3 图像合成任务公开数据集地址Table 3 The address of public datasets about image composition task
6 深度学习方法对比
图像合成作为一项包含多个子任务的复杂任务,由于目前尚无一个基于深度学习的方法能够同时完成所有图像合成子任务,各任务主要方法如表4所示,因而无法进行统一的方法对比分析。同时,大多数的图像合成任务使用AMT 进行合成结果图像的主观评价分析,因此不同用户间存在的主观差异也对图像合成方法的对比造成一定的干扰。近年来得益于部分大规模基准数据集的构建,如iHarmony4图像和谐化数据集(Cong等,2020b)、DESOBA(Hong等,2022)阴影生成数据集等,在图像和谐化任务与前景对象阴影生成任务中才能够进行较为公平的方法对比与模型分析。

表4 图像合成各任务主要深度学习方法汇总Table 4 Summary of main deep learning methods for each task of image composition task
6.1 前景对象自适应任务
在OPA 数据集(Liu 等,2021)发布之前,由于没有统一的公开数据集用于图像合成中的前景对象自适应任务,同时不同的模型尝试解决不同的前景对象适应性问题,如关于用户肖像的眼镜、帽子、口罩等自适应合成问题(Zhan 等,2019,2021a),家具在房间内的自适应合成问题(Azadi 等,2020),汽车及红绿灯等在道路上的自适应合成问题(Zhang 等,2020a),人像与背景图的合成及软边界细化问题(Zhang 等,2021),文字图像与背景图的自适应合成问题(Zhan 等,2019,2021a)等,并且多数任务采用AMT 对合成结果进行定性评价。由于用户评价的主观性,且不同的前景对象自适应任务(几何一致性、外观一致性)、不同的深度学习方法之间的差异较大,同时缺乏统一使用的公开数据集,因此在前景对象适应性问题中无法进行相关深度学习方法的统一对比与结果分析,前景对象自适应方法如表5 所示,其中,NS(normalized similarity)表示归一化相似性,IOU(intersection over union)表示交并比。

表5 前景对象自适应合成方法总结Table 5 Summary of adaptive composition methods for foreground objects
6.2 图像和谐化任务
在图像和谐化任务中,Peng 等人(2022)基于iHarmony4(Cong 等,2020b)数据集,使用均方误差(MSE)与峰值信噪比(PSNR)作为评价指标,对主要的图像和谐化方法进行了对比,其定量结果如表6所示,定性结果如图14所示。

表6 图像和谐化方法对比(Peng等,2022)Table 6 Image harmonization method comparison(Peng et al.,2022)

图14 图像和谐化方法的定性比较结果(Peng等,2022)Fig.14 Qualitative comparison results of image harmonization methods(Peng et al.,2022)((a)composite images;(b)mask;(c)DoveNet(Cong et al.,2020a);(d)RainNet(Ling et al.,2021);(e)FRIH(Ling et al.,2021);(f)ground-truth)
6.3 前景对象阴影生成任务
在合成图像阴影生成任务中,Hong 等人(2022)基于构建的DESOBA 阴影生成数据集,在均方根误差(RMSE)与结构相似性指数(SSIM)的基础上,使用了全局均方根误差(GRMSE)、局部均方根误差(LRMSE)、全局结构相似性指数(GSSIM)与局部结构相似性指数(LSSIM)作为阴影生成任务的评价指标,分别进行了不同阴影生成方法的对比,其定量结果如表7所示,定性结果如图15所示。

表7 前景对象阴影生成方法对比(Hong等,2022)Table 7 Foreground object shadow generation method comparison(Hong et al.,2022)

图15 阴影生成方法的定性比较结果(Hong等,2022)Fig.15 Qualitative comparison results of shadow generation methods(Hong et al.,2022)((a)composite images;(b)mask;(c)Pix2Pix(Isola et al.,2017);(d)Pix2Pix-Res(Isola et al.,2017);(e)ShadowGAN(Zhang et al.,2019b);(f)Mask-ShadowGAN(Hu et al.,2019);(g)ARShadowGAN(Liu et al.,2020);(h)SGRNet(Hong et al.,2022);(i)ground-truth)
7 图像合成的应用
图像合成技术的应用场景较为广泛,如在用户人脸合成(赵彬 等,2013)、车辆自动驾驶、目标检测,识别与分类和图像分割等领域。合成图像或合成数据的使用,一方面能够进行训练数据集的扩充,另一方面在一定程度上能够弥补真实世界数据的不足(数据集类不平衡、数据增强方法较少等(王建明等,2022)),同时也能改善网络模型极端情况下泛化能力差等。虽然生成式对抗网络也可以通过生成器与判别器的对抗训练生成真实的图像,但是,其生成方法有其局限性。首先,生成的结果往往不可控制,同时训练过程不稳定,另外网络的训练同样依赖大量的数据集(Miao 等,2021),所以人们尝试将合成图像数据用于学术研究与生产实践。
7.1 学术领域
在学术领域关于计算机视觉的研究工作中,开始使用合成图像数据,在保证模型效果的基础上降低了成本消耗。
Xu 等人(2017)使用图像合成技术构建大型数据集以训练抠图网络(matting network)。Miao 等人(2021)通过合成车辆3D 模板信息与“干净”的道路背景图形成真实多视角道路图像以构建CVIS(cooperative vehicle-infrastructure system)数据集,用于车辆自动驾驶领域。Shermeyer 等人(2021)在AI.Reverie 仿真平台的帮助下,通过图像合成技术制作飞机卫星影像数据集(rareplanes),用于飞机的检测与分类等任务,并且他们通过研究发现90%的合成图像数据与10%的真实图像数据混合使用能够达到与使用100%真实图像数据同样的效果。在图像分割领域,Sankaranarayanan 等人(2018)利用合成数据集SYNTHIA(synthetic collection of diverse urban images)(Ros 等,2016)中CITYSCAPES 子集进行模型训练以完成语义分割任务。Ward 等人(2018)使用合成图像数据集Arabidopsis来增强真实数据集完成对叶片的实例分割任务,效果超越了当时最先进的叶片分割方法。Abu Alhaija 等人(2017)在车辆实例分割任务中,通过合成车辆对象实例以增强真实世界的车辆图像。Tremblay 等人(2018)提出使用合成域随机化(domain random,DR)图像进行对象检测的深度神经网络,并发现使用合成图像数据的效果优于使用真实数据集训练的效果。
7.2 工业领域
在工业领域,越来越多的企业关注于使用合成图像数据进行相应的生产创作活动。
Nvidia 已经推出Omniverse Replicator,官方描述其为“用于生成具有基本事实的合成数据以训练AI网络的引擎”。工程副总裁Rev Lebaredian 表示“合成数据可以让AI(artificial intelligence)系统变得更好,甚至可能更合乎道德”(Strickland,2022),其他数据行业有:
1)OneView,其开发的虚拟合成图像数据集,用于通过机器学习算法分析地球观测图像。
2)Cvedia,通过创建合成图像,并简化真实视觉数据的收集流程,在平台中通过传感器合成逼真的环境图像,借此制作出丰富的实证数据集。
3)Anyevrse,使用传感器数据,通过汽车行业的定制激光雷达创建并进行图像处理以制成合成数据集,借此实现真实场景的模拟。
4)AI.Reverie,制作合成图像数据训练计算机视觉算法,借此实现活动检测、目标检测与划分。
不难看出,在图像合成技术越发成熟的前提下,合成图像的使用越来越广泛,不仅是在学术领域与工业领域,游戏创作、广告海报设计以及电影制作等各方面也能看到合成图像的身影,同时大规模的应用合成图像也推动着相关技术进步和发展。
8 存在的问题和展望
8.1 合成技术中存在的问题与不足
图像合成已由最初的手动制作到现在使用深度学习自动合成,并能一定程度上实现各个细节部分的优化,以达到真实图像的效果。尽管目前图像合成技术取得了不错的效果,但也存在着不足之处。
1)图像合成任务实际上可以视为结合前景对象的自适应、前景色调的调整、前景缺失的阴影生成以及前景对象生境适应性匹配等多个子任务的大型任务。目前已有的相关研究,均未能同时完成上述所有任务,多数工作着重于解决其中某一个具体的问题,少数工作能够同时完成2~3 个子任务。而从图像合成的任务要求来看,同时解决所有问题才符合图像合成任务的要求:产生一幅与真实图像无异、各个细节都经得起用户考验的“真图”。这也给图像合成领域带来不小的挑战,统一完成所有任务难免会降低部分子任务的输出效果(Niu 等,2021),结果就是整体合成图像效果不佳。
2)对于合成图像的评价方法各有不同,且大部分任务采用AMT 进行定性评估,但是其不足之处在于不同用户间主观性太强,主体间存在的差异容易影响合成效果评估结果,因此较难统一对比不同工作的合成结果。
3)由于没有统一的大规模基准数据集用于图像合成任务,容易造成各个方法间难以进行比较。近年来在前景对象放置、图像和谐化领域与阴影生成领域已有数据集如OPA(Liu 等,2021),iHarmony4(Cong 等,2020b)与DESOBA(Hong 等,2022)等公布,但是在整个图像合成任务中仍然没有适用于全部任务过程的数据集。
4)在大部分针对各个子任务的研究中,往往都只有一个前景对象参与,而考虑多前景对象的放置(Zhang 等,2020a)、图像和谐化等任务较少(Niu 等,2021)。同时多前景对象的合成也会产生新的问题,如前景对象相互间的遮挡问题,视觉效果上的多物体几何、大小调整及聚焦问题,阴影间可能存在的重叠等问题。
5)前后景图像生境不匹配。正如生境适应性问题所提出的,图像合成的最终目的是合成与真实世界无异的图像。尽管目前大多数任务着重于研究前景对象合成后的最终效果是否真实,但是若没有对前景对象及背景图像进行生境层面的逻辑适应,将严重影响图像的真实性。
6)前景对象的提取依赖精确的前景对象标签图(如Mask 图),若标签图中的前景对象边缘细节缺失,则合成后的前景对象将会存在严重的实体完整性问题,影响最终的图像合成质量。
8.2 展望
目前图像合成任务中各个子任务都有新的理论与技术出现,并且就所针对的研究方向取得了一定的进展,为了推动图像合成领域进一步发展,本文在已有工作不足之处的基础上,做出如下展望。
1)为了避免子任务之间相互独立,可以考虑协调统一所有子任务,将前景对象自适应、视觉一致性、生境适应这些问题串行处理,在保持局部输出结果不变的情况下最优化整体合成结果,实现更高效更全面的图像合成。
2)考虑构建用于全部子任务的大规模基准数据集,不仅可以促进解决全部任务方法的相关研究,而且有利于不同研究方法间的对比分析。
3)结合图像粗分割与精细分割等技术将前景对象标签图像的输入融合到合成任务中去自动生成,在端到端网络中实现前景来源图和背景图的联合输入,合成结果图的最终输出。
4)考虑实现多前景目标的合成任务,通过使用多目标检测、区域卷积等关注多前景对象间的关系,解决多前景独立调整以及解决相互遮挡、阴影重叠等问题,完成从一到多的扩展。
5)关于生境适应性问题,特别在生物目标的自然图像合成方面,由于生物的真实生存环境复杂多变,已有的方法很难完美解决生物的生境复杂性问题。可考虑结合智能决策支持系统的理论与技术,加入先验知识,构建生境环境适应性数据集、知识库、规则库等构件、图像数据匹配规则,通过高效的智能匹配策略解决逻辑冲突,提供现实依据。
综上所述,图像合成领域中,在解决前景对象自适应、前后景和谐化、前景缺失阴影生成以及前景对象生境适应性匹配等问题的同时,研究最终合成效果稳定、同时计算资源节约、泛化能力强的图像合成方法是未来技术发展的重点。
9 结语
本文详细论述了图像合成任务中面临的主要问题:前景对象适应性问题、前后景视觉和谐问题(色调不一致问题,前景对象阴影缺失问题)以及前后景生境适应性问题,分别阐述了目前为解决各问题所使用的公开数据集、深度学习方法及对应的合成图像质量评价指标,并展示了方法的对比结果,同时介绍了合成图像的应用场景,最后提出目前图像合成中存在的不足之处及对未来技术发展的展望。
越来越多的工作得出的合成图像已经达到了与真实图像十分接近的程度,但是生境适应性问题仍没有得到很好的解决,从而导致无论模型的效果多么“真实”,都会缺失真实图像所蕴含的生态学意义,在逻辑上失真,这也进一步限制了合成图像的应用范围。而完成多前景对象合成,使用精确的前景标签图避免边缘模糊,统一多个子任务将是未来图像合成领域的研究重点。总的说来,目前基于深度学习的图像合成方法具有非常广阔的研究空间与应用前景。
猜你喜欢
睿士(2023年2期)2023-03-02
建材发展导向(2021年6期)2021-06-09
今日农业(2020年17期)2020-12-15
文苑(2020年11期)2020-11-19
中国诗歌(2019年6期)2019-11-15
中国外汇(2019年11期)2019-08-27
意林(2018年3期)2018-03-02
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
厦门理工学院学报(2016年1期)2016-12-01
太空探索(2016年10期)2016-07-10
