
面向鲁棒学习的对抗训练技术综述
2023-12-23 10:13隋晨红王奥周圣文臧安康潘云豪刘颢王海鹏
中国图象图形学报 2023年12期
隋晨红,王奥,周圣文,臧安康,潘云豪,刘颢,王海鹏
1.烟台大学物理与电子信息学院,烟台 264002;2.上海交通大学电子信息与电气工程学院,上海 200240;3.武汉数字工程研究所,武汉 430205;4.中国人民解放军海军航空大学信息融合研究所,烟台 264001
0 引言
深度神经网络(deep neural network,DNN)在计算机视觉领域取得了巨大成功,如面部识别、语音识别、医学成像、自动驾驶汽车、机器翻译和恶意软件检测等,这些实际应用的飞速发展使深度学习的安全可靠性问题日益凸显。研究发现,模型参数量的庞大和对训练样本的极度依赖,导致DNN 具有严重的对抗脆弱性。具体而言,攻击者向原始数据添加人类视觉系统不可察觉的微小扰动,生成对抗样本,该对抗样本能让DNN 产生错误的输出结果,达到攻击DNN 的目的(Goodfellow 等,2015)。DNN 的这种对抗脆弱性诱发了恶意攻击的大量涌入,给深度学习在各领域的应用带来了严峻的安全性挑战(Sharif 等,2016;Wu 等,2020b;余正飞等,2022;吴翼腾 等,2022)。为应对恶意攻击的威胁,开展对抗性防御进而提升模型鲁棒性变得尤为重要。
针对DNN 的防御方法主要包括3 类:基于修正输入数据的方法、直接增强网络的方法以及对抗训练(Madry 等,2017)的方法。基于修正输入数据的防御方法旨在对输入DNN 的数据提前进行修正,在输入端减弱攻击强度,如去噪(Xie等,2019)、图像变换(Xie等,2018)等。该类方法具有一定的抵御攻击能力,但其不仅受攻击强度限制,而且存在对正常输入数据过度修正的问题。前者导致其难以应对人类不可感知的微小扰动,而后者极易造成其对正常数据亦给出错误判断,从而降低模型的分类准确率。直接增强网络的方法主要是通过添加子网络(Bai等,2022)、更改损失函数、激活函数(Singla 等,2021)、BN(batch normalization)层(Xie等,2020)或网络训练过程(Hendrycks 等,2019;Xiao 和Zheng,2020;Chen 等,2020;Cui 等,2021)等方式,直接增强网络的抗攻击能力。
相较前两类方法,对抗训练是典型的启发式防御方法(孔锐 等,2022;李前 等,2022;Liu 等,2020)。其核心是将对抗攻击与对抗防御注入一个框架,一方面利用对抗攻击已有模型,生成强干扰的对抗样本;另一方面利用对抗样本进一步训练目标模型,使其能够对对抗样本有准确的输出,进而提升模型抵御对抗攻击的鲁棒性。
尽管对抗训练具有一定的防御攻击能力,但其对模型鲁棒性的提升是以降低对正常数据的分类或识别精度为代价的。实践表明,模型越鲁棒,其对正常样本的分类或识别精度越低(Zhang 等,2019b)。此外,针对攻击方式多样化的强对抗攻击,目前的对抗训练防御效果依然不尽人意,并且标准对抗训练存在耗时长的问题。
研究工作从不同角度改进了标准的对抗训练,如在攻击阶段,使生成的对抗样本具有多样性或可迁移性,能够使模型抵挡其他更多种类的攻击;在防御阶段,标准对抗训练仅考虑了对抗样本的分类情况,忽略了原始样本的分类精度要求。为此,许多工作(Kannan 等,2018;Zhang 等,2019b;Wang 等,2020)不仅引入对抗样本与原始样本的空间或语义一致性约束,而且要求模型对原始样本及对抗样本均有准确的输出,从而保证模型同时兼具高鲁棒性与高准确性。
为进一步提升模型的鲁棒性,研究者提出将对抗训练与直接增强网络的方法进行结合。例如,许多工作将修改模型网络结构(Mustafa 等,2019;Xie等,2020;Bai 等,2022)、自适应调整模型参数(Chen等,2020;Xiong 和Hsieh,2020;Liu 等,2020;Ye 等,2021)、加速对抗训练(Zhang 等,2019a;Zhang 等,2019b;Shafahi 等,2019;Zheng 等,2020;Wong 等,2020;Kim等,2021)等嵌入对抗训练框架,增强模型抵御对抗攻击的能力。此外,为提升模型的迁移性,研究者将课程学习、强化学习、度量学习以及领域自适应等技术引入对抗训练(Cai 等,2018;Sitawarin 等,2021;Bashivan 等,2022;Jia 等,2022;钱申诚 等,2022)。例 如,CAT(curriculum adversarial training)(Cai 等,2018)通过引入课程学习的思想,使得对抗训练过程的扰动范围由小到大变化,增强了对抗攻击强度的多样性,使模型的迁移性能得到显著提升。
为此,本文围绕对抗训练,从对抗训练的基本框架入手,分别就对抗样本生成、对抗模型防御训练等相关技术进行详细分类与梳理,并对对抗训练性能评估涉及的数据集和对抗攻击方法展开介绍,最后通过对当前对抗训练所面临挑战的分析,对对抗训练未来的发展趋势进行了展望。
1 对抗训练的基本框架
深度学习模型的强大拟合能力,使其能够对数据产生丰富的表征。因此,当攻击者对原数据x施加轻微扰动δ,便可引起特征表达的显著变化,进而导致错误的分类或检测。这种人为添加扰动而生成的样本称为对抗样本(adversarial example)xadv,其与扰动δ的关系可简单描述为
式中,ε为攻击或扰动的幅值,‖ ⋅ ‖p代表p范数,p可取0,1,2,∞。
为提高模型对抗攻击的稳健性,对抗训练的核心思想是利用具有攻击性的对抗样本进行模型训练,使学习到的模型能抵御攻击。这表明包含微小扰动δ的对抗样本生成是对抗训练的关键。其中,扰动δ一方面要保证对抗样本的强攻击性,另一方面要满足低幅性,具体为
式中,y为原数据x的真实标签,θ为模型参数,L 为度量模型预测结果与真实标签y之间一致性的损失函数。
为防御攻击,对抗训练在依据式(2)与式(1)获取对抗样本xadv后,将xadv作为训练样本输入模型并进行训练,则模型参数θ可通过最小化平均损失函数L(xadv,y;θ)进行更新,即
式中,(x,y)~D表示从分布D中采样的数据及标签对,E[ ⋅]表示期望。
基于这一思想,Madry 等人(2017)从鲁棒优化的角度,使用自然鞍点(最大—最小)公式将对抗攻击和防御训练同时纳入对抗训练,构建了对抗训练的基本框架,具体为
式中,B(x,ε)表示满足‖δ‖p≤ε的扰动集合。
由式(4)不难看出,对抗训练是集攻击与防御于一体的启发式方法。一方面,其通过内层损失最大化来生成具有攻击性的对抗样本;另一方面,其利用外层损失最小化来更新模型,进而增强模型的抗攻击能力。
为此,本文将分别就对抗样本生成与模型防御训练两方面展开介绍。
2 对抗样本生成
在对抗训练的攻击阶段,依据攻击的对象不同,可将现有的对抗样本生成技术分为3 类:基于图像空间攻击的对抗样本生成、基于特征空间攻击的对抗样本生成以及基于物理空间攻击的对抗样本生成。其中,基于图像空间的攻击是目前对抗训练采用的主流对抗样本生成方式(钱申诚 等,2022;赵宏等,2022)。其通过限制扰动幅度,能够生成人类感知不到扰动的对抗样本,具有较好的攻击隐藏性。因此,本文将重点对基于图像空间攻击的对抗样本生成方式展开分析。
2.1 基于图像空间攻击的对抗样本生成
基于图像空间的攻击方法首先基于损失函数最大化,获得满足幅值限制的扰动δ,然后将δ添加到原始图像x生成对抗样本,如式(4)所示。典型方法如FGSM(fast gradient sign method)(Goodfellow 等,2015)、FGSM 的迭代变体I-FGSM(iterative FGSM)(Kurakin 等,2017)、基于动量的迭代变体MI-FGSM(momentum-based iterative FGSM)(Dong 等,2018)以及PGD 方法(projected gradient descent method)(Madry 等,2017)等。这些方法均通过损失函数的梯度进行图像空间攻击,进而生成对抗样本。
表1 列出了一系列基于梯度的对抗样本生成方法,总结了它们的应用范围、算法思想和优点。图1简要给出了基于损失函数梯度攻击原始图像,然后生成对抗样本的演进过程。在图1 实线框内的方法是常用的基于梯度的攻击方法,而虚线框内的方法能够进一步增强对抗样本的可迁移性。

图1 基于梯度的攻击方法演变过程Fig.1 Evolution of gradient-based attack methods
由图1不难看出,FGSM 作为最基本的单步迭代方法,是其他基于梯度攻击图像的方法的基础。FGSM 是通过对原始数据添加与损失函数的梯度方向一致而幅度较小的微小扰动得到对抗样本,具体为
式中,J(x,y;θ)表示损失函数,而∇xJ(x,y)是损失函数关于x的梯度,sign(⋅)为符号函数,用于提取梯度的方向。特别地,为限制扰动的强度,δ需满足‖δ‖∞<ε。
显然,FGSM 通过单步计算损失函数的梯度完成对抗样本的生成,无需迭代,具有效率高的优势。然而,这种单步生成对抗样本的方式导致FGSM 缺乏对对抗样本多样性和合理性的探索,不利于提升模型的抗攻击能力。
为此,Kurakin 等人(2017)在FGSM 的基础上提出了迭代版FGSM,即I-FGSM。I-FGSM 沿着梯度增加的方向进行多步微小扰动,并在每次扰动后,重新计算梯度方向。若设初始的对抗样本为
则第t+1步更新后的对抗样本为
式中,Clipx,ε(A)表示将输入向量Ai,j中的每个元素裁剪到[xi,j-ε,xi,j+ε]之间的操作,用于控制扰动的强度。
为提高对抗样本的可迁移性,MI-FGSM(Dong等,2018)将动量整合到I-FGSM 中,实现了对抗样本更高的迁移性,具体为
式中,gt为前t次迭代后的累积梯度,μ为衰减因子。
此外,与I-FGSM 不同的是,目前最流行的PGD(Madry 等,2017)攻击是对原始样本添加其邻域范围内的随机扰动S作为初始对抗样本,具体为
PGD第t+1步迭代生成的对抗样本为
上述I-FGSM、MI-FGSM 以及PGD等方法均利用损失函数的梯度,将损失函数增加的方向定义为扰动更新的最优方向。显然,这有利于增加对抗样本的攻击性。然而,受扰动幅度限制,模型在该类方法所生成的对抗样本附近,具有高度非线性的损失表面,导致我们需要通过多次迭代更新扰动方向,进而找到合适的对抗扰动。这极大地降低了对抗训练的收敛速度。
为降低对抗样本的更新步数,Qin 等人(2019)将正则项引入目标函数,旨在通过提升局部线性,减少生成对抗样本所需的迭代步数。Sriramanan 等人(2020)通过引入正则化约束来寻找最优梯度方向,从而为对抗样本的生成提供可靠的扰动,使得单步迭代能产生更强的攻击。
另外,为加强对抗样本的多样性,进而增加模型的泛化性,集成对抗训练、多样性对抗训练等方法(Tramèr 和Boneh,2019;Jang 等,2019;Kariyappa 和Qureshi,2019;Addepalli 等,2022)相继提出。例如,集成对抗训练(Tramèr 等,2020)旨在利用不同模型生成的对抗样本进行目标模型训练。Pang 等人(2019)提出利用不同模型间的相互作用来提高集成模型的鲁棒性。Kariyappa 和Qureshz(2019)提出多样性训练,旨在训练基于输入梯度间余弦距离损失的模型集合。
为进一步提升对抗样本的多样性,插值对抗训练(Zhang 等,2021)引入插值的思想。具体来说,首先对输入图像与标签同时插值,然后最小化插值后的图像与原始图像的距离(此时,插值后的图像相当于对抗样本),同时,最大化插值后的标签与原始标签的距离。例如,双边对抗训练(Wang 和Zhang,2019)对输入与标签同时添加扰动。Lee 等人(2020)针对对抗特征过度拟合(adversarial feature overfitting,AFO)问题,提出了对抗顶点混合(adversarial vertex mixup,AVmixup)方法,即一种软标记数据增强方法。由于大多数插值方法仅在训练阶段进行,Pang 等人(2019)发现由于用于训练的插值对抗样本与测试数据间的差异,导致分类器训练所得最佳决策边界并不适用测试数据,并引发泛化误差增加的风险。这说明仅对训练数据进行插值不利于保证模型的泛化性能。为此,Pang 等人(2019)提出在训练与测试阶段均引入插值操作,使模型鲁棒性进一步得到提升。
表2 进一步总结了上述方法对输入样本和标签的具体插值公式。若C为类别总数,则对抗插值训练(Zhang 等,2020)进行标签平滑后的新标签为yˉ′=在双边对抗训练(Wang 和Zhang,2019)中,超参数β用于更新标签,而对抗顶点混合(Lee 等,2020)方法使用标签平滑函数ϕ更新标签。

表2 插值对抗训练方法对比Table 2 Comparison of interpolation methods
上述对抗样本生成方法均依赖手工设计的规则,因此,一定程度上限制了对抗样本生成。
为避免这一问题,有研究旨在通过网络直接生成对抗样本。Jang 等人(2019)用递归生成网络(采用基于U-Net 架构的卷积编码器—解码器)代替上述攻击方式生成对抗样本,损失函数由目标分类器的标准损失与多样性损失组成,可以产生更强和更多样的对抗样本;Xiong 和Hsieh(2020)同样提出了基于L2L(learning-to-learn)(Chen等,2021)的递归神经网络(recurrent neural network,RNN)对抗训练框架,如图2 所示,其框架可以与AT(adversarial training)或TRADES(trade-off between robustness and accuracy)相结合。为保证稳定训练,该框架还去除了标准RNN 的偏差项。Chan 等人(2020)提出利用雅可比矩阵替代对抗样本的对抗正则化网络(Jacobian adversarially regularized networks,JARN)。JARN 将目标分类器作为生成对抗网络(generative adversarial network,GAN)(Goodfellow 等,2014)中的生成器模型,通过优化目标分类器使其产生的显著雅可比矩阵能够欺骗鉴别器网络,并将其认定为输入图像,以此来提升目标分类器的鲁棒性。

图2 基于L2L的RNN对抗训练框架(Xiong和Hsieh,2020)Fig.2 L2L-based RNN adversarial training framework(Xiong and Hsieh,2020)
此外,由于相关研究表明对抗样本具有可迁移性(Liu 等,2017;Papernot 等,2017),有研究工作旨在通过对FGSM 进行优化来提升对抗样本的可迁移性(Lin等,2020;Wang和He,2021;Wang等,2022a)。如式(8)(9)所示,Dong 等人(2018)提出MI-FGSM,将动量项整合到迭代攻击中,以此稳定更新的梯度方向,进而提高对抗样本的可迁移性。而Lin 等人(2020)在此基础上提出NI-FGMS(nesterov iterative fast gradient sign method),通过引入NAG(nesterov accelerated gradient)α×μ×gt来校正累积梯度gt+1,加速跳出局部最优解的同时,使对抗样本获得更好的迁移性,具体为
与NI-FGSM 和MI-FGSM 等基于梯度进行动量累积不同的是,Wang 和He(2021)提出了一种称为方差调整的新方法。该方法通过在每次迭代中减少梯度的方差来提高对抗样本可迁移性,具体为
式中,θ为模型参数,J(x,y;θ)为损失函数,gt为前t次迭代后的累积梯度,μ为衰减因子,vt为方差。可以看出,利用方差的攻击可以在MI-FGSM或NI-FGSM的基础上更进一步提升对抗样本的可迁移性。
除了在时间动量上进行优化,Wang 等人(2022a)还提出了考虑空间动量的SMI-FGSM(spatial momentum iterative FGSM attack)。SMI-FGSM 将动量累积机制从时间域引入到空间域,使用来自不同区域的信息来生成稳定的梯度,最后在时间和空间域同时稳定梯度的更新方向,具体为
式中,Hi(⋅)表示对输入进行随机变换的函数,n表示空间域中进行随机变换的次数,λi是梯度的权重,∑λi=1,λi=1/n。
显然,不同于NI-FGSM 和MI-FGSM 等方法在时间域累积动量,SMI-FGSM 通过计算n种随机变换图像的平均梯度,得到空间域上的动量累积。
此外,Zheng 等人(2020)根据替代模型训练的思想,基于相邻训练epoch 的模型之间有高度可迁移性的特性,提出对抗训练可以由逐epoch 累积的对抗扰动来增强训练模型的鲁棒性,以更少的迭代生成相似(甚至更强)的对抗样本;还有研究提出对抗性变换网络代替传统的图像变换(Wu 等,2021),以此增强对抗样本的可迁移性。
2.2 基于特征空间攻击的对抗样本生成
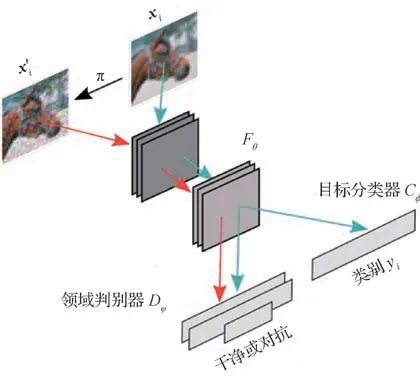
除了针对图像空间进行攻击生成对抗样本之外,还可以基于特征空间的攻击生成对抗样本,即在网络层添加噪声。如图3 所示,输入图像进入某一DNN 网络,可以在中间隐藏层的某几层或全部层添加噪声,将添加了噪声的特征图依次经过全连接层与分类层输出,得到最终的对抗样本。

图3 特征空间添加扰动方法Fig.3 Method of adding perturbation to feature space
参数噪声注入(He等,2019)旨在在网络每一层的激活或权重上注入可训练的高斯噪声,并嵌入对抗训练;在此基础上,Jeddi 等人(2020)提出了基于Learn2Perturb学习框架的扰动注入模块,如图4所示,并把模型训练分为两个部分:1)扰动注入网络训练:对特征注入扰动的情况下继续更新网络参数,以提高模型的对抗鲁棒性;2)扰动注入模块训练:更新扰动注入模块的参数,以增强针对改进网络的扰动能力。
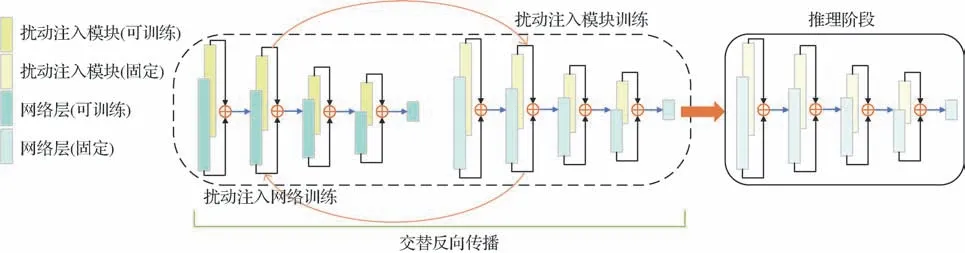
图4 扰动注入模块下的模型训练策略(Jeddi等,2020)Fig.4 Model training strategy under the perturbation injection module(Jeddi et al.,2020)
Yu 等人(2021)试图研究网络中间层的潜在特征,并研究了选择哪些中间层最适合攻击,使网络原始输出与特征空间的输出共同决定网络最终的输出预测,并使用替代损失函数来更新对抗样本。
逐层对抗训练(Chen 等,2020)得出结论:1)将扰动注入到网络的每一层(包括输入层)会得到最高的模型鲁棒性;2)接受对抗性训练的层次越多,防御性能越强;3)对抗性训练层越靠近网络输出层,防御性能越强。
此外,由于对抗训练的模型更偏向于全局特征,Song 等人(2020)试图研究对抗性训练的泛化和鲁棒的局部特征之间的关系。通过对对抗样本随机区块洗牌(random block shuffle,RBS)变换获得局部特征,然后将其迁移到正常对抗样本的训练中;特征级可迁移攻击(Zhang 等,2022)旨在生成更多可迁移的对抗样本,通过对神经元重要性进行估计,破坏正面特征或放大负面特征来生成对抗样本。
2.3 基于物理空间攻击的对抗样本生成
2.1 和2.2 节分别介绍了如何在图像或特征空间生成人类视觉系统察觉不到的微小扰动。但在实际情况中,DNN 还表现出对日常环境中常见自然破坏(如雪、雨、亮度等)的弱鲁棒性,这些人眼可识别的物理扰动的存在,对人们的日常生活造成了极大的干扰,不仅如此,Brown 等人(2018)在原始图像上添加看得见的物理补丁(Patch)作为扰动,同样能产生相同的后果。如在实际应用中,攻击者把这些恶意扰动应用在自动汽车驾驶上,可能会造成严重的交通事故。所以现实生活中更需要采取一系列有效防御措施,以在物理世界中建立同样鲁棒的深度学习模型(袁珑 等,2022)。
在这一领域,Salman 等人(2021)采用相反思路构建非对抗性扰动,如图5 所示,有两种方式生成非对抗性扰动:1)设计非对抗性补丁;2)设计非对抗性纹理。通过改变输入来强化正确的行为,而不是优化输入来误导模型。也就是说,当得到非对抗性样本后,与传统对抗训练内部最大化目标函数相反,本方法要使目标分类器的损失最小;类似地,Wang 等人(2022b)提出了防御性补丁生成框架,旨在通过利用局部特征与全局特征加强模型的泛化性与不同模型之间的可迁移性,与Salman 等人(2021)不同的是,其通过掩码的方式设计的补丁粘贴在目标图像周围,不会对其造成干扰,并且该框架可以与对抗训练结合,得到更高的鲁棒精确度。

图5 非对抗性扰动(Salman等,2021)Fig.5 Unadversarial perturbation(Salman et al.,2021)((a)an example unadversarial patch;(b)an example unadversarial texture)
3 防御性训练
对抗训练的防御阶段,其基本问题是利用已生成的对抗样本进行训练,并通过分类或检测损失最小化来更新模型,具体如式(4)的外部最小化学习过程。为进一步提升模型的鲁棒性,防御训练阶段还会结合以下技术:1)引入损失正则项。将正常样本与对抗样本的类别一致性、语义一致性或分布一致性等正则项引入损失函数,提升对抗训练的鲁棒性。2)增强模型。设计优化模块插入到网络模型结构中,或修改网络的某些部件,如BN层或激活函数,亦或是使用预训练模型训练。3)参数自适应。不再是手工设置某些具体的参数,而是根据训练情况使其参数自适应更改,如内部最大化时使用的步长、扰动约束,外部最小化使用的平衡参数等。4)早期停止。一般来说,模型训练收敛后的鲁棒性不是最佳鲁棒性(Rice等,2020),所以需要采取早期停止策略得到最佳鲁棒性。5)半监督或无监督扩展。对抗训练提升模型鲁棒性的核心思想是利用大量原始数据生成对抗样本,进而开展对抗训练,使得模型对添加一定扰动的输入数据仍能产生与原来一致的输出。因此,为增加模型鲁棒性,许多研究工作指出可利用无标记样本进行半监督或无监督扩充,然后用于对抗训 练(Carmon 等,2019;Najafi 等,2019;Zhai 等,2019)。Carmon 等人(2019)发现依靠有标签数据训练出的模型,能够获得无标签数据的伪标签,若利用这些伪标签数据进行对抗训练,依然能够提升模型的鲁棒性。6)加速对抗训练。对抗训练最棘手的缺点之一是训练时间过长。针对该问题,研究者们提出了一系列加速对抗训练的方法。下面将分别就上述技术展开介绍。
3.1 引入损失正则项
对抗训练防御阶段的核心是通过已生成的对抗样本来训练,基于损失最小化来更新优化模型。由于标准对抗训练的损失函数仅由生成的对抗样本与原始标签决定,没有考虑到原始样本和相应的对抗样本之间的关系。所以Kannan 等人(2018)通过增加目标函数正则项,鼓励两对样本的输出逻辑(logits)相似,进一步增强了二者的相关性。
Tsipras等人(2019)发现模型鲁棒性和泛化性在本质上是矛盾的,存在权衡。为找到二者之间的平衡点,缩小鲁棒泛化差距,即在提升模型鲁棒性的同时,不会大幅度损害模型的泛化性,Zhang 等人(2019b)把标准对抗训练的鲁棒误差分为自然误差和边界误差,并设计了一个新的优化目标,即目标分类器原始样本的目标函数与使用了KL(Kullback-Leibler)散度测量对抗样本与原始样本之间距离的组合;与上文类似,在单步训练的基础上,Sriramanan等人(2020)在标准对抗训练中引入了松弛项,旨在找到最优的梯度方向。
Wan等人(2020)考虑了对抗样本与原始样本之间特征分布的差异性,旨在通过训练来学习数据的特征分布。对抗样本应该遵循不同于干净数据的分布。为了缩小不同类别之间的鲁棒精确度差异,Xu等人(2021)提出了公平性约束,但在差异减小的同时,一定程度上降低了对抗训练的最高准确度。表3列出了不同防御方法的损失函数,可以明显看出,标准对抗训练(PGD-K)仅考虑了对抗样本的分类损失,而后续基于梯度优化的方法增加了原始样本的分类损失以及对抗样本与原始样本的距离损失等正则项,或使用了替代损失函数;基于特征空间优化的方法还考虑了特征空间中类别之间的联系,即有效增加类间聚敛以及类内损失正则项,或通过添加辅助分类器得到了特征空间隐藏层的损失正则项。

表3 不同防御方法的损失函数Table 3 Loss functions for different defense methods
此外,由于上述方法仅在正确分类的原始样本上生成对抗样本,不可避免地存在部分样本在训练中会被错误分类,Ding 等人(2020)与Wang 等人(2019)考虑了这种情况,其中,Ding等人(2020)从边际(输入到分类器的决策边界的距离)最大化的角度研究神经网络的对抗鲁棒性;而Wang等人(2019)提出了错误分类感知对抗训练,使用了替代损失函数进行训练。
3.2 增强模型
增强优化对抗训练过程的防御方法可以分为3个方面:
1)引入即插即用优化模块。不需改变网络原始结构,具有轻量级且有效的优点,对于提高模型鲁棒性有十分重要的意义。例如Pang 等人(2020b)设计了超球嵌入(hypersphere embedding,HE)机制来扩充AT 框架,具体来说,该HE 模块包括3种典型的操作:特征归一化(feature normalization,FN)、权重归一化(weight normalization,WN)和角度余量(angular margins,AM),其中角度余量通过归一化网络逻辑(logits)输出层的特征和softmax层中的权重。
Mustafa 等人(2019)通过在网络不同深度添加辅助分类器,同时添加了损失正则项,包含一个简单的最大分离约束,如图6 所示,加强了模型的类间分离性,可以使攻击者的任务变得困难。
与之相似的是,Bai等人(2022)同样在网络中间层部分增加辅助分类器,其损失作为标准对抗训练目标函数的正则项,可以使网络自适应学习不同通道对类别预测的重要性,抑制不重要的通道,从而提高模型的鲁棒性。Xu 等人(2020)提出了自适应网络,引入了以输入为条件的归一化模块,该模块允许网络针对不同的样本“调整”自身。此外,前文提到的对网络中间层添加辅助分类器(由全局平均池化层与全连接层组成)(Bai 等,2022)也属于即插即用模块。
2)修改模型内部结构。Xie 等人(2020)改进了网络BN层,提出Dual-BN,使原始样本与对抗样本分开利用不同的BN,如图7所示。而Singla等人(2021)旨在研究不同的激活函数与模型鲁棒性的关系;此外,除了在输入上添加扰动,Wu等人(2020a)还在模型权重上添加扰动。除了上述方法,Singh等人(2019)提出鲁棒的子网络方法,即首先微调网络前几层生成的扰动,然后对网络剩余层数进行对抗训练。

图7 Dual-BN(Xie等,2020)Fig.7 Dual-BN(Xie et al.,2020)
3)添加预训练模型或使用双模型训练。研究发现,即使是仅使用干净样本进行预训练,也可以提高模型的鲁棒性,并且使用对抗预训练的模型效果更好(Hendrycks 等,2019;Xiao 和Zheng,2020;Chen等,2020),如图8 所示,Xiao 和Zheng(2020)使用了轻量级网络预训练输入的干净样本,之后利用此网络生成对抗样本,最终输入到目标网络进行训练与测试。除此之外,Cui 等人(2021)提出双模型训练,同时训练自然模型与目标对抗模型。

图8 使用轻量级对抗预训练模型(Xiao和Zheng,2020)Fig.8 Using lightweight adversarial pretrained models(Xiao and Zheng,2020)
3.3 参数自适应
在基于梯度生成对抗样本时,参数的设定对模型鲁棒性的提升有着重要影响,如使用PGD 攻击时,其迭代次数K、攻击步长α与扰动约束ϵ都需要人为设置。下列方法针对在设置此类参数时,采用一系列自适应方法,能够更好地提升模型鲁棒性。
Cheng 等人(2020)提出自适应扰动约束ϵ,根据每个训练样本与决策边界的距离来分配相应的ϵ,即自适应寻找能让模型错误分类的最小的ϵ,具体来说,初始化扰动约束为0,每次迭代后增加一个具体的常数,直到模型产生误判即停止。此外,还提出了自适应标签平滑方法,以反映每个样本上的不同扰动容限;Xiong 和Hsieh(2020)采用PGD 攻击方式生成对抗样本,对原始的固定攻击步长进行改进,采用了回溯线搜索(backtracking line search,BLS)方法自适应步长;Croce 和Hein(2020a)同样提出自适应步长,具体来说,设置初始步长η(0)=2ϵ,设定检查点w0=0,w1,…,wn,根据以下两个条件判断是否需要使当前步长减半,具体为
受学习率预热的启发,Liu等人(2020)提出了自适应扰动约束ϵ,同样采用预热的方法,具体来说,定义了一个余弦调度器ϵcos和一个线性调度器ϵlin,由ϵmax和ϵmin参数化,具体为
把ϵcos(d)和ϵlin(d)裁剪到0 和ϵtarge(t扰动约束的目标值),如果ϵmin≤0 且ϵmax>ϵtarget,ϵ的值从0 逐渐增加到ϵtarget,然后保持不变。
Ye 等人(2021)为减少与对抗训练相关的开销,采用了退火机制,由于神经网络在训练初始阶段专注于学习特征,这可能不需要准确的对抗样本。因此,在训练开始时设置大步长α与迭代次数K进行内部最大化,然后逐渐增加K和减少α以提高内部最大化解的质量,第t次迭代产生的退火数量Kt和攻击步长αt具体为
式中,Kmax和Kmin分别为对抗扰动的退火数量上限与下限,τ为某一常数。
此外,对于一些经典的对抗训练,如TRADES(Zhang 等,2019b)、MART(misclassification aware adversarial training)(Wang 等,2020)等,其目标函数中的参数λ组合了两部分准确度,当调节λ时,需要重新训练模型。为了避免这种繁重的过程,Wang等人(2020)提出了在推理阶段调节λ,使模型不需要因为参数的改变而反复训练。
3.4 早期停止
与标准训练不同,对抗训练会产生鲁棒过拟合现象,即过度适应对抗性强的训练会导致更差的测试集性能。Rice 等人(2020)对对抗训练中的过拟合现象进行了全面的研究,发现鲁棒过拟合现象是普遍存在的。如图9 所示,训练在初始阶段正常进行,但在学习率衰减之后,测试误差会短暂降低,随着训练进行,训练误差会持续降低,但是测试误差会增加,也就是说,训练结束后的误差不是最佳的,即训练结束后的模型鲁棒性不是最佳鲁棒性。

图9 鲁棒训练模型的学习曲线(Rice等,2020)Fig.9 Learning curves for robustly trained models(Rice et al.,2020)
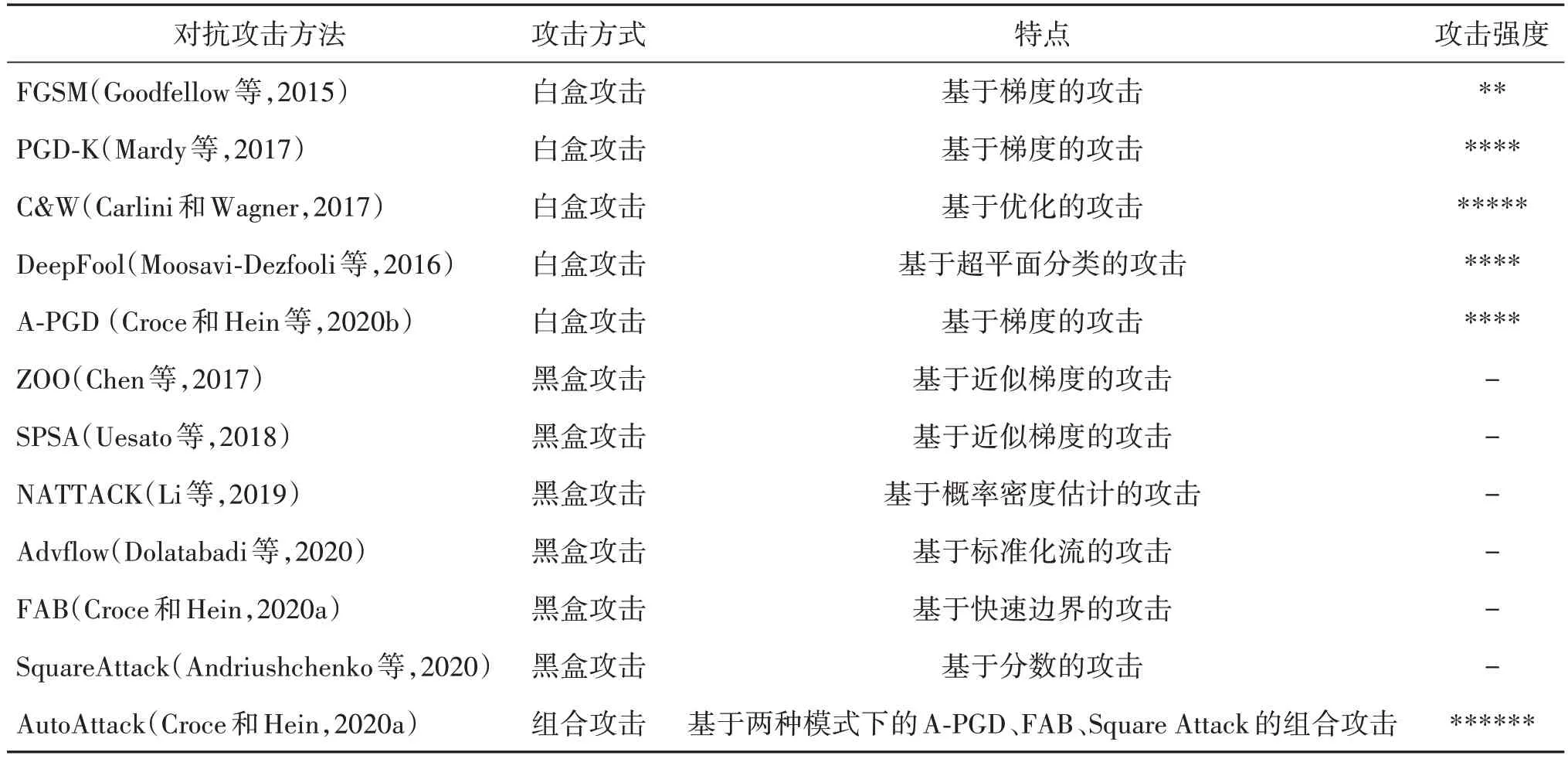
针对鲁棒过拟合现象,采用早期停止策略是有必要的,而早期停止可以分为学习率早期停止和攻击强度早期停止(Pang 等,2021),如Zhang 等人(2019b)在代码中将学习率设置为在75 epoch 处衰减,并且训练在76 epoch 处停止;Zhang 等人(2020)设置了固定的攻击迭代次数τ(τ 图10 早期停止方法(Sitawarin等,2021)Fig.10 Early-stop mothod(Sitawarin et al.,2021) 理论证明,对抗训练需要使用比标准训练大得多的数据集,而这需要巨大的成本。因此,有研究希望仅通过增加无标注的数据来提升模型的对抗鲁棒性,即使用半监督或无监督扩展训练,如Carmon 等人(2019)使用半监督自训练的方式提升模型鲁棒性。Zhai 等人(2019)同样采用大量无标注数据,提出PASS算法来提高模型的对抗鲁棒泛化性;上文中提到的MART 等方法同样可以推广到半监督训练,而Uesato等人(2019)则使用无监督训练与监督训练加权结合的方法。 具体来说,通过设计不同的目标函数,作者提出3 种策略:1)Online Targets 的无监督对抗训练(unsupervised adversarial training with online targets,UATOT);2)无监督的固定目标对抗训练(unsupervised adversarial training with fixed targets,UAT-FT);3)二者结合训练(UAT++)。Zhang和Wang(2019)使用了无监督训练方式,将注意力放在样本间结构上,采用最优传输(optimal transport,OT)距离衡量原始样本与干净样本的距离。 为了提升标准对抗训练的速度,Zhang 等人(2019a)提出了一种能够减少计算正反向传播次数的新方法;Shafahi 等人(2019)提出同步更新扰动和模型参数,连续m次在同一小批次(minibatch)上训练,并在前一阶段的训练结果上继续训练;Zheng 等人(2020)通过逐epochs 累积对抗扰动,以更少的迭代次数生成相似(甚至更强)的对抗样本。与此同时,有研究旨在利用单步对抗训练来加速,即对FGSM 进行优化来生成对抗样本。但单步对抗训练会产生灾难性过拟合(catastroptic overfitting,CO)现象(Kim 等,2021),原因在于如果FGSM 的攻击步长过大,模型会产生扭曲的决策边界(图11),导致CO 现象的产生,因此,Wong 等人(2020)提出了随机初始化的FGSM 内部最大化攻击方式,在一定程度上缓解了CO 现象;Andriushchenko 等人(2020)认为,当攻击步长较大时,随机初始化依旧对CO 现象无效,在此基础上,他们提出了梯度对齐(GradAlign)方法,即在点x和围绕x的l∞-ball内的随机扰动点x+η处的梯度之间最大化梯度对齐。Vivek 和Babu(2020)旨在通过在网络层增加dropout 层来减轻CO 现象,与传统的仅在全连接层与ReLU(rectified linear unit)后增加dropout 层(typical setting)不同,作者还在模型的每个非线性层之后引入dropout 层(proposed setting);Kim 等人(2021)认为,单步攻击的主要问题是内部最大化的线性近似的失败,如图11 所示,因此,应重新考虑适当的攻击步长。 表4 为对抗训练加速方法的总结,可以看出,加速方法分为多步训练的加速以及利用单步训练加速。多步训练旨在达到同样的攻击强度时,使用更少的迭代次数;单步训练利用只需要迭代一次的优势加速对抗训练,但需要解决灾难性过拟合问题。 表4 加速对抗训练方法对比Table 4 Comparison of accelerated adversarial training methods 将标准对抗训练与其他领域相结合,如Cai 等人(2018)提出课程对抗训练,旨在将课程学习的思想融合进对抗训练中,使攻击强度逐步提升;同样,Sitawarin等人(2021)提出了将softmax概率差距作为课程学习的难度度量,将概率差距定义为除正确类别之外的任何类别中的最大softmax 概率与正确类别的softmax概率之差,旨在最小化其概率差距。 钱申诚等人(2019)希望使对抗样本远离错误类别,更接近真实类别,使用度量学习中的三元组损失(triple loss)函数,向模型添加了额外的约束。如图12 所示,通过设置三元组损失中的至少一个元素为对抗样本,其他为原始干净图像,模型使用交叉熵损失与三元组损失交替训练。 图12 度量学习的三元组损失(Mao等,2019)Fig.12 Triple loss for metric learning(Mao et al.,2019) Song等人(2019)考虑到原始样本与对抗样本的分布之间存在很大的领域差距,通过将原始样本与对抗样本分别划分为两个域,并将无监督和有监督的领域适应引入对抗训练中,以最小化原始样本和对抗样本分布之间的差距并增加它们之间的相似性。 Bashivan 等人(2022)同样引入领域适应,在网络的逻辑输出层添加领域判别器,如图13 所示,将训练数据区分为原始样本和对抗样本。Jia 等人(2022)将强化学习思想引入对抗训练,构建了目标网络与策略网络结合的框架,如图14 所示,前者使用对抗样本训练提高模型鲁棒性,后者通过学习自动产生依赖于样本的攻击策略,进而指导自动编码器生成器网络生成对抗样本。Dong 等人(2020)试图捕捉每个输入周围的对抗性扰动的分布,而不是像传统对抗训练一样寻找局部最具对抗性的点。 图13 为模型引入领域判别器(Bashivan等,2022)Fig.13 Introduce the domain discriminator to the model(Bashivan et al.,2022) 图14 目标网络结合策略网络框架(Jia等,2022)Fig.14 Target network combining policy network framework(Jia et al.,2022) 作为最有效的防御手段之一,对抗训练的评估必不可少,本节从两个方面介绍对抗训练的评估。 对抗训练最常用的数据集是CIFAR-10(Canadian Institute for Advanced Research)、CIFAR-100、MNIST(Modified National Institute of Standards and Technology)以及SVHN(street view house numbers),由于对抗训练在大型数据集(如ImageNet)上的效果不尽人意,有些研究使用了Tiny-ImageNet 数据集来验证其对抗训练的效果。图15、图16 和表5 总结了上述几种数据集的可视化与其基本信息。为了清楚起见,图15 中所有数据集的图像设置成同一大小,图16中的SVHN数据集为原始图像大小。 图15 数据集总结Fig.15 Summary of the datasets((a)CIFAR-10 dataset;(b)CIFAR-100 dataset;(c)MNIST dataset;(d)Tiny-ImageNet) 图16 SVHN数据集Fig.16 SVHN dataset 表5 常用数据集Table 5 Commonly used datasets 4.1.1 CIFAR-10 CIFAR-10 是一个用于识别普适物体的小型彩色图像数据集,共10 个类别,如飞机、鸟、汽车、猫等。每幅图像的尺寸为32 × 32 像素,每个类别有6 000幅图像,共有50 000幅训练图像与10 000幅测试图像,在训练时,该数据集将训练图像分为5 个批次,每个批次有10 000幅图像,而测试图像的每个批次包含了每个类别的1 000幅随机选择的图像。 4.1.2 CIFAR-100 与CIFAR-10 类似,CIFAR-100 同样是小型彩色图像数据集,每幅图像尺寸为32 × 32 像素。不同点在于CIFAR-100 有20 个超类,且被进一步区分为100 个类别(例如,鱼为超类;水族馆的鱼、比目鱼、射线、鲨鱼、鳟鱼为类别),每个类别有600 幅图像,且分为500 幅训练图像与100 幅测试图像。每幅图像含有两个标签,其一为100 个类别所在的“精细标签”,其二为20 个超类所在的“粗糙”标签。 4.1.3 MNIST MNIST 是传统的灰度手写字符数据集,由人口普查局的工作人员(SD-3)与大学生(SD-1)记录的共250 种不同笔迹组成,两种笔迹同样包含30 000 幅训练图像和5 000幅测试图像,该数据集共60 000幅训练图像和10 000幅测试图像。每幅图像的尺寸为28 × 28像素,且经过了归一化预处理。 4.1.4 SVHN 与MNIST 类似,SVHN 同样用于识别字符,但包含了更多数量级的标记数据。SVHN 是由谷歌街景彩色图像中的门牌号码组成的数据集,共73 257 幅训练图像,26 032 幅测试图像以及531 131 幅额外的、难度稍低的训练图像。经过预处理后的SVHN数据集图像为固定的32 × 32像素尺寸。 4.1.5 Tiny-ImageNet ImageNet 是目前世界上最大的图像识别数据集,可以用于目标分类、目标检测等各大领域。而Tiny-ImageNet 是ImageNet 的子集,共200 个类别,每个类有500 幅训练图像,50 幅验证图像和50 幅测试图像,每幅图像的尺寸为64 × 64像素。 对抗训练的评估方式可以分为白盒攻击与黑盒攻击,白盒攻击是指攻击者可以获得目标模型的一切信息,包括内部结构、训练参数和防御方法等;而黑盒攻击对模型一无所知,只能通过输入输出与模型进行交互。其中,白盒攻击又分为基于梯度的FGSM 与PGD-K攻击,K为攻击迭代次数。在PGD-K中,K通常设为20、50、100 等;基于超平面分类的DeepFool(fool deep neural network)攻击(Moosavi-Dezfooli等,2016);基于优化的C&W(Carlini and Wagner)攻击(Carlini和Wagner,2017)等。黑盒攻击可以分为基于近似梯度的攻击,如ZOO(zeroth order optimization)攻击(Chen 等,2017)、使用同步扰动梯度近似的多元随机近似(multivariate stochastic approximation using a simultaneous perturbation gradient approximation,SPSA)攻击(Uesato等,2018)以及使用替代模型(Papernot等,2017)进行攻击评估。基于替代模型的黑盒攻击较为普遍,其主要思想是先训练一个与目标模型具有相似决策边界的替代模型,之后对替代模型进行白盒攻击得到对抗样本,再利用其迁移性实现对目标模型的攻击。此外,Dolatabadi 等人(2020)将流模型引入对抗攻击,能够生成分布上与干净数据类似的对抗样本,因而具有较强的攻击性。表6总结了各种评估攻击方法以及对应的攻击强度。 表6 评估对抗训练的攻击方法比较Table 6 Comparison of adversarial attack methods for evaluating adversarial training 另外,针对攻击是否包含特定目标,Croce 和Hein(2020b)提出A-PGD 攻击,将其两种模式(目标攻击与无目标攻击)与FAB(fast adaptive boundary)攻 击(Croce 和Hein,2020a)、SquareAttack(Andriushchenko 等,2020)进行整合,得到相对复杂但攻击性强的AutoAttack 攻击(Croce 和Hein,2020a)。 由于深度神经网络脆弱、易受攻击的安全性问题,对抗训练这一典型的防御技术取得了重要进展,并在对抗样本生成、基于对抗样本的模型防御训练两大关键领域涌现出许多优秀的技术。本文不仅详细梳理了传统对抗训练框架下的典型对抗训练方法和关键技术,而且回顾了结合课程学习、度量学习等思想的新型对抗训练方法。 通过本文的梳理不难发现,由于对对抗攻击的本质成因仍不明确,现有的对抗训练技术仍面临缺乏强大有效的攻击方法来对对抗训练方法性能进行有效评估、难以应对多扰动综合的攻击及效率低等挑战,为此,对抗训练未来的发展趋势为: 1)探究数字空间及物理世界对抗样本的成因。针对数字空间与物理世界,探究导致模型输出错误的干扰类型、强度以及干扰方式等,为对抗样本生成提供可靠的理论指导; 2)设计更高效、强大的对抗攻击方法,一方面通过提升对抗样本的攻击能力,来增强模型的防御性能,另一方面提升对抗训练的效率; 3)构建能自适应防御多攻击类型的通用对抗训练框架与方法,推动深度学习对抗性安全的发展。
3.5 半监督或无监督扩展训练
3.6 加速对抗训练

3.7 其他防御方法


4 对抗训练评估
4.1 常用的数据集



4.2 常用攻击方法
5 结语
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2021年6期)2021-12-21
应用数学(2020年2期)2020-06-24
农业机械学报(2020年2期)2020-03-09
数学物理学报(2019年4期)2019-10-10
中华建设(2019年7期)2019-08-27
数学年刊A辑(中文版)(2018年2期)2019-01-08
贵州师范学院学报(2016年3期)2016-12-01
项目管理技术(2016年12期)2016-06-15
西南交通大学学报(2016年6期)2016-05-04
