
面向屏幕拍摄的端到端鲁棒图像水印算法
2023-12-23 10:13吴嘉奕李晓萌秦川
中国图象图形学报 2023年12期
吴嘉奕,李晓萌,秦川
上海理工大学光电信息与计算机工程学院,上海 200093
0 引言
具有高鲁棒性不可见图像水印可在人眼无法察觉的情况下将一定容量的水印信息嵌入数字图像,且在含水印图像经过一定的噪声攻击后仍可被正确提取(秦娜 等,2007)。然而,随着数码相机、手机等移动设备的普及,传统用于抵抗数字信道噪声的鲁棒水印算法无法有效抵抗屏幕拍摄的噪声攻击。因此,具有屏摄鲁棒性的图像水印算法(如图1 所示)在版权保护、泄密溯源等应用场景具有重要的意义。目前鲁棒水印算法主要可以分为两类,即基于传统图像处理的鲁棒水印与基于深度学习的鲁棒水印。
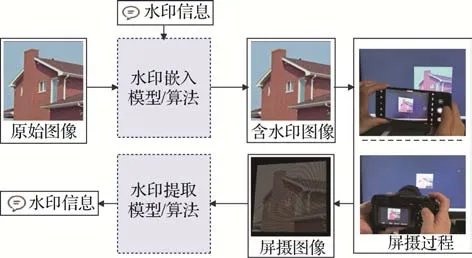
图1 抗屏摄鲁棒图像水印流程示意图Fig.1 Schematic diagram of screen-shooting robust watermarking
在图像的空间域或频率域进行设计。Katayama等人(2004)提出一种基于正交图案的水印算法,且建立了用于抵抗拍摄攻击的水印算法性能评价指标,为后续的抗屏摄鲁棒水印研究与改进提供了较完整的框架。随后,Nakamura 等人(2004)设计了一种具有鲁棒性的水印模板,将二进制水印即0/1信号分别对应预先根据规则制定的正交模板,随后嵌入图像。当含水印信息的图像经过打印拍照后,将图像经过特定的滤波器得到水印的模板信息,再根据模板映射获得二进制水印信息。为了抵抗由于拍摄角度不同带来的透视变换所引起的图像失真,Kang等人(2010)基于对数极坐标映射提出一种鲁棒水印图案嵌入算法,通过将鲁棒水印图案与图像的Fourier-Mellin 系数相加以实现鲁棒水印嵌入。随后Delgado-Guillen 等人(2013)对该算法进行了改进,使得该算法具有更好的抵抗几何失真的能力,Fang等人(2019)分析了屏摄信道中存在的各种具体失真,提出一种基于I-SIFT(intensity-based scaleinvariant feature transform)关键点定位的水印嵌入算法,并设计了基于交叉验证的水印提取算法,该算法对于打印拍摄和屏幕拍摄均具有一定的鲁棒性。
随着深度学习技术的发展及各种神经网络模型在图像处理领域取得的成功,基于深度学习的鲁棒图像水印近年来得到了广泛关注(郑钢 等,2021)。Zhu 等人(2018)搭建了一个端到端的鲁棒水印嵌入—提取框架HiDDeN(hiding data with deep networks),将对含水印图像的各种攻击操作视为噪声层并对其进行训练,实验证明该算法具有较高的鲁棒性。Tancik 等人(2020)将U-Net 结构的网络引入端到端网络的编码层(encoder),并使用对抗生成网络(generative adversarial network,GAN)鉴别图像是否含有鲁棒水印信息,进行对抗训练以生成更高隐蔽性的鲁棒水印嵌入模型;在解码层(decoder)使用空间变换网络进行图像矫正,以增强图像对小幅度旋转、裁剪的鲁棒性。该网络对打印和拍屏处理具有较强的鲁棒性,但水印图像视觉质量不佳。Fang等人(2021)结合基于传统图像处理的模板嵌入与基于深度学习的增强提取,设计了一种基于模板的鲁棒水印算法,该算法生成的水印图像既具有较好的视觉质量,又能抵抗一定程度的屏摄失真,但在某些屏摄条件(如距离1 m 以上)下,其鲁棒性会有明显的下降。
针对目前已有鲁棒水印算法存在的问题和不足,本文提出一种基于端到端网络的抗屏摄鲁棒图像水印算法。该算法可抵抗常用及部分极端条件下的屏摄攻击,对于深度学习领域常用的图像数据集在没有进行纠错解码的情况下,水印提取的正确率可达96%~99%;同时算法生成的含水印图像的峰值信噪比(peak signal-to-noise ratio,PSNR)在31 dB以上。本文主要贡献如下:1)设计了一个端到端的深度学习网络用于鲁棒水印的嵌入与提取,可自动生成具有良好的视觉质量及抗屏摄性能的含水印图像;2)设计了摩尔纹噪声模拟模块,有效提高了网络针对屏摄噪声的鲁棒性,同时引入最小可察觉失真(just noticeable distortion,JND)损失函数,提升了含水印图像的视觉质量;3)提出了两种图像区域定位方法,用于在水印提取时图像输入解码网络前的区域定位和矫正,实现了拍屏后的全自动水印提取。
1 基于端到端网络的抗屏摄水印算法
本文提出的基于端到端网络的抗屏摄鲁棒水印算法主要包括以下几个部分:用于水印嵌入和提取的编码端网络和解码端网络,用于保证鲁棒性的噪声模拟层,以及两个分别用于在屏摄和数字裁剪后定位含水印图像区域的定位模块。算法整体流程如图2所示。

图2 本文抗屏摄鲁棒水印算法的整体流程图Fig.2 Flowchart of the proposed screen-shooting robust watermarking scheme
1.1 网络结构
1.1.1 编码端网络结构
本文算法编码端网络的前置骨干网络是一个U-Net 型的编码网络。其具体结构如表1 所示,表中k表示卷积核的大小,s表示卷积核的步长。

表1 网络编码端结构Table 1 The network structure of the encoder
整个U-Net 型网络由左侧的升维部分与右侧的降维部分组成。升维部分的作用是逐层学习并压缩提取到的图像与水印信息的特征,降维部分的作用是根据得到的图像与水印信息的高维特征进行解码和拼接,逐层获得最后用于附加在原始图像上的含有水印信息的残差图。升维部分与降维部分之间的拼接操作可使网络在不同尺度下学习不同层级的特征。编码网络的输出为两通道的残差图,与原图RGB中的GB两个通道进行加性融合后可得到嵌入水印信息后的图像。有关具体通道的选择以及生成两通道而非三通道残差图的原因将在1.4节进行讨论。
1.1.2 解码端网络结构
解码端网络由两部分组成,分别是空间变换网络(space transform network,STN)与由若干卷积层和全连接层组成的解码子网络,解码子网络的具体结构如表2所示。STN 的输出为一个长度为6的张量,代表了6 个参数Θ={a,b,c,d,e,f},当网络收敛后,这些参数可对输入的图像进行仿射变换,具体为

表2 网络解码端结构Table 2 The network structure of the decoder
式中,(xi,yi)与分别表示图像中像素点的原始坐标和变换后坐标。由于屏摄过程会对图像产生形变,式(1)的目的是为了对拍摄后存在形变的图像进行调整,消除形变带来的影响,故STN 模块的加入可在一定程度上提高网络最终收敛后的性能。
位于STN之后的解码网络结构为多层卷积层连接多层全连接层。卷积层的主要作用是对含水印信息的图像进行特征提取与降维操作;全连接层的作用是将这些特征由二维图像转换为一维的信息。由于嵌入的水印为二进制序列,故最后的全连接层仅需经过一层sigmoid 函数,即可表达最后输出的水印信息序列各位置上的比特信息为0或1的概率,实现水印的提取。
1.2 损失函数
本文通过损失函数来监督网络生成同时具有鲁棒性与高视觉质量的水印图像。本文构建的损失函数L由多个子损失函数加权构成,即
1.2.1 图像误差损失
图像误差损失l1使用均方误差(mean square error,MSE),即L2损失函数进行计算,可使监督生成的残差图尽可能少地对原始图像像素值进行修改,具体为
式中,M和N分别为图像的高与宽,本文算法中图像在输入编码网络前尺寸均被归一化为512 × 512 像素,即M=N=512;I表示原始图像,表示通过网络生成的残差图与原始图像之和,即含水印图像。
1.2.2 视觉感知损失
虽然L2损失可在一定程度上提高含水印图像的PSNR 指标,但其并不完全与人眼感知保持一致。因此,本文还额外引入了视觉感知LPIPS(learned perceptual image patch similarity)(Zhang 等,2018)损失函数以监督生成的含有水印信息的残差图更加不易被人眼察觉,具体为
式中,z为网络提取特征张量图像的层数分别为原始图像I与含水印图像的特征张量图,Hz与Wz为图像第z层特征张量图的长宽尺寸,wz∈RC为用于缩放特征张量图的维数。
1.2.3 信息交叉熵损失
为了能够从屏摄图像中正确解码出水印信息,即保证鲁棒性,需要引入有关信息解码正确与否的损失函数。这里本文使用二分类交叉熵损失函数对网络训练进行监督,具体为
式中,sig(⋅)表示sigmoid 函数为经过网络解码后第i位水印比特的预测值,bi为第i位水印比特的实际值,L表示二进制水印信息的长度,在本文中默认L=127。特别地,本文在网络训练的前期,即前次迭代时,只引入该损失函数参与梯度更新,不监督有关图像视觉质量的损失;在次迭代后再加入用于监督图像视觉质量的其他损失函数。这样可加速总体损失函数的收敛。
1.2.4 残差图JND损失
在经过L2图像损失、视觉感知LPIPS 损失与信息交叉熵损失监督后,编码端已可以生成一般意义上不易感知且含有鲁棒水印信息的图像。但仅通过上述损失函数,无法监督残差图的纹理附着在原始图像的高频区域,这可能导致水印信息在原始图像像素值变化较平坦的低频区域被嵌入,从而影响水印图像的视觉感知质量。为解决这一问题,使含有水印信息的残差图的纹理不过于涣散,本文在网络训练过程中引入JND损失函数进行监督。
图像的JND可通过基于心理学和生理学表征视觉冗余的最小可察觉失真模型来获得。JND 模型主要可分为两类:基于像素域的JND 模型(Ahumada 和Peterson,1992)和基于变换域的JND 模型(Yang 等,2005),本文采用的是基于像素域的JND 模型(Ahumada和Peterson,1992),具体为
式中,I(P)表示在图像中某个像素点P=(x,y)的亮度,f1表示计算空间域掩蔽分量的操作,其计算式为
f2表示计算图像背景亮度视觉阈值的操作,其计算式为
Ibg(x,y)表示平均背景亮度,即
Img(x,y)表示像素邻域亮度差异的最大加权平均,即
式中,Up表示像素P=(x,y)周围5 × 5 邻域的像素矩阵。若像素P=(x,y)位于图像边界处,则对缺失的像素进行镜像填充处理。Gk的4 种取值为
图3 给出了一个图像JND 的实例,其中,图3(a)为原始图像;图3(b)表示在JND 模型理论下的人眼不可察觉的图像最大失真图,即JND系数图;图3(c)表示原始图像经过编码网络生成的含有水印信息的残差图。本文的JND损失函数定义为编码端生成的残差图与原始图像JND 图的LPIPS 感知损失,具体为
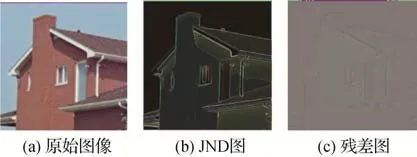
图3 图像的JND系数图与残差图示例Fig.3 Examples of JND map and residual image((a)origin image;(b)JND map;(c)the residual map)
式中,Ir为残差图,IJND为原始图像的JND 图,η为JND 图的权重系数,用于控制网络生成的残差图的强度。
在网络训练中,以上4 个损失函数l1,l2,l3与l4均被期望随着网络的收敛而逐渐变小。
1.3 屏摄噪声模拟
如图2 所示,在水印网络的编码端与解码端之间,编码端生成的含水印图像需经过一个噪声层以模拟噪声攻击。本文使用数学方法对各类型噪声进行模拟(Zhu 等,2018)。特别地,本文专门考虑了屏摄信道中特有的噪声,即摩尔纹失真。本节将分析讨论屏摄信道各类型噪声产生的原因及数学模拟方法。由于透视变换失真将通过1.4 节提出的定位模块进行矫正,故在本节中不进行讨论。各类型屏摄噪声示意图如图4所示。

图4 各类型屏摄噪声示意图Fig.4 Various types of noises during screen-shooting process
1.3.1 色域失真
本文中色域失真的定义是指对比度失真和亮度失真,即图像整体的加性失真与乘性失真,具体为
式中,θ1与θ2为失真系数,当图像经过该层时,θ1与θ2会在一定范围内随机取值。为防止θ1与θ2取值过大,使过大的失真在网络训练前期被引入,导致网络无法学习到抵抗该类型失真的能力,故θ1与θ2的取值范围一开始可设为[0,0],即完全无色域失真,该范围会随着训练步数的增加而线性增大,即色域失真的程度会线性提升,直至某一上限。
对于加性失真(亮度失真)θ2,其取值可以是负数,故其取值范围可设定为对称区间(-M1,M1),其中M1的取值为
对于乘性失真(对比度失真)θ1,其取值不可为负数,故其取值范围设定为非对称区间(m2,M2),且
式中,xs为网络训练时的步长为网络训练的超参数。
1.3.2 饱和度失真
饱和度即原色的纯净度,表示色彩与中性色的距离。当饱和度降低为0 时,彩色图像便退化为灰度图像。彩色图像到灰度图像的映射计算式为
本文将饱和度失真定义为彩色图像与其对应的灰度图像的线性加权和,具体为
式中,IRGB为原始彩色图像,IG为其对应的灰度图像。可以看出,当θ3=1 时,表明图像的饱和度没有失真,即为原始彩色图像;当θ3=0 时,表明图像的饱和度完全失真,即为灰度图像。由于θ3的取值范围为[0,1],故在训练中其计算式可表达为
式中,σ[N(0,1)]表示标准正态分布下的随机取值,xs为网络训练时的步长为网络训练的超参数。
1.3.3 随机高斯噪声失真
由于屏摄过程中,在屏幕与镜头上以及CMOS在模数转换时均有可能出现不规则的噪声,该类随机噪声的效果可视为一个符合N(0,σ)高斯分布的噪声模板N与原始图像相叠加,具体为
σ的取值范围为(m3,M3),其计算方式与1.3.1节中的参数θ1相同,由超参数与网络训练时的步长xs共同计算得到。
1.3.4 运动模糊失真
屏摄图像中可能含有多种运动模糊失真。典型的模糊失真包括由于摄像设备与屏幕之间距离的变化导致已设定好焦距的镜头失焦造成的高斯模糊,以及由于在快门关闭过程中运动导致重复曝光的径向模糊,这些模糊均可由尺寸为Nk的卷积核实现。
对于镜头失焦所造成的高斯模糊,可直接采用高斯模糊核进行计算,具体为
对于径向模糊,设运动轨迹(x′,y′)在(x,y)坐标系的角度为θ,则可通过变换正交基得到对应的计算式,具体为
在获得相应的卷积核后,对图像进行卷积操作即可得到对应的失真图像,式中卷积核的尺寸Nk和高斯模糊核的标准差σ在某个范围内随机取值,取值范围的计算方法与1.3.2节相同。
1.3.5 摩尔纹失真
当拍摄设备感光元件CMOS 的像素与显示设备的像素空间频率较接近时,可能会产生一种波浪形的干扰图案,即摩尔纹(Yuan 等,2019)。本文通过数字管道来模拟摩尔纹的产生,具体步骤如下:
1)将图像重新采样成LCD(liquid crystal display)屏幕格式,即用3 盏单色亚像素灯表示1 个像素。考虑到LCD 屏幕的物理元件间隔,原始图像中的1个像素与重采样后图像中的9个像素相对应,即
2)对该重采样图像进行随机透视变换生成不规则的纹理,并对其使用高斯模糊卷积核进行模糊操作,以达到图像逆透视变换之后仍会保留部分摩尔纹纹理的目的。
3)使用Bayer CFA(color filter array)进行图像色彩插值,并转换回RGB 图像格式以模拟从原始图像文件(RAW)格式转换为普通数字图像格式的过程。
4)对图像进行逆透视变换,即可得到附带摩尔纹纹理的图像。
由于摩尔纹模拟模块引入的图像失真较大,故其在网络训练的中后期被加入。随着网络训练迭代次数的增加,图像经过噪声层时遭受干扰的强度一般会高于现实情况中屏摄所产生的噪声,故生成的含水印图像具有较高的屏摄鲁棒性。
1.4 水印图像区域定位
1.4.1 拍摄图像区域定位方法
在现实情况中,拍屏后的结果可能并非只包含屏幕显示的图像本身,很有可能会包含一些背景信息。这些背景信息不仅无用,甚至会干扰和影响解码端水印提取的结果。为此,本小节提出一种基于深度学习与传统图像处理相结合的区域定位方法。本文默认在屏摄结果图像中,需要提取水印的图像区域占大部分像素,且背景颜色相对单一,无明显突变,这样含水印图像区域的定位可等效为前景提取的问题。
需要注意的是,由于光照影响与含水印图像内容的丰富性,经过基于传统图像处理(如阈值分割)后得到的屏摄图像前景信息可能是不完整的,且会影响后续最大连通域的处理,如图5 所示。图5(a)为屏摄图像;图5(b)为对图5(a)理想的前景分割效果;而在经过基于传统图像处理的实际前景提取处理后,本应如图5(b)所示全白的前景掩膜会存在边缘的部分缺失,从而导致最大连通域不是完整的含水印图像区域,如图5(c)所示。故仅通过传统图像处理得到的图像前景区域结果不理想,且对水印的提取不利。

图5 基于传统图像处理的屏摄图像前景分割示例Fig.5 Examples of foreground segmentation of screen-shooting image based on conventional image processing((a)screen-shooting image;(b)ideal foreground mask;(c)real foreground mask)
为此,本文以DeepLab V3+语义分割网络(Chen 等,2018)为基础框架训练了一个二分类语义分割网络,该网络的输入为如图5(c)的基于传统图像处理提取的前景信息,输出为如图5(b)的补全后的前景。该语义分割网络训练数据集的构建方式为:选择非纯色图像在经过透视变换后置于不同纯色背景中,再通过传统图像处理算法进行前景与背景分割,即利用自适应阈值二值化处理求出边缘的最大连通域,得到若干含有残缺或完整的前景信息标签图像,如图6(a)所示;同时生成其对应真实的前景信息标签图像,如图6(b)所示。该语义分割网络被期望通过分析前景信息标签并通过训练后,可正确地分割出完整的图像前景。

图6 语义分割网络训练集的构建Fig.6 Construction of training set for the semantic segmentation network((a)label images with incomplete foreground in the training set;(b)the label images with complete foreground corresponding to(a)in the training set)
拍摄图像区域定位方法的整体流程如图7 所示,具体步骤如下:

图7 拍摄图像区域定位方法流程图Fig.7 Flowchart of our captured image region localization method
1)为降低算法复杂度,将屏摄图像转为灰度图像并进行中值滤波处理;
2)利用传统图像处理进行前景与背景分割,即基于自适应阈值二值化处理求出边缘的最大连通域;
3)将经过步骤2)初步提取出含有残缺前景信息的图像通过训练好的语义分割网络进行前景区域补全;
4)将补全后的前景信息图像进行后处理,应用中值滤波进行平滑处理并使用Canny 算子提取二值化图像边缘,即含有水印信息的图像区域的边缘;
5)对上述提取边缘后的图像利用Hough 变换检测边缘直线,求出所有直线的各个交点,对各簇交点进行k-means++聚类,得到4 簇交点的4 个中心位置;
6)将4 个聚类交点按顺时针排列后进行透视变换,可得到定位并矫正后的含水印图像。
1.4.2 抗裁剪区域定位方法
水印算法的鲁棒性不应只局限于对拍屏过程鲁棒,对于数字环境下的攻击,如图像滤镜、图像加噪和数字裁剪等,也应具有一定的鲁棒性。绝大多数数字攻击均可被屏摄过程引入的噪声所等效,但数字裁剪攻击的失真是屏摄噪声所没有涵盖的,故对此类攻击需要专门进行考虑(Fang 等,2021)。为此,本文引入了基于对称性噪声模板的抗裁剪区域定位方法。
本文将图像分为左上、左下、右上和右下共4 个子图,并分别生成双通道水印信息残差图,在绿色(G)和蓝色(B)通道进行嵌入,这样即在一幅图像中嵌入了4 份相同的水印信息。同时,本文在红色(R)通道嵌入对称性的噪声模板用于抗裁剪定位。当含水印图像遭受裁剪攻击时,只要有1/4以上的图像区域存在,通过定位方法仍可正确提取水印信息,如图8 所示。对称性噪声定位模板的嵌入步骤如下:

图8 抗裁剪区域定位方法流程图Fig.8 Flowchart of our cropping-resistant region localization method
1)将原始图像I切分为左上、右上、左下和右下4幅大小相同的子图像,记为I1—I4;
2)将I1—I4分别通过1.1 节设计的水印编码网络,生成双通道残差图Ir1—Ir4,并分别叠加至子图像的G,B 通道,再将4 幅嵌入了水印的子图像组合成一幅完整图像;
3)生成一个大小与I1相同的高斯白噪声矩阵,将该矩阵水平翻转,拼接之后再垂直反转,得到与原始图像I大小相同的对称噪声模板;
4)将该对称性噪声模板叠加在原始图像的R通道上。
值得注意的是,由于嵌入4 幅子图像的残差图之间没有相关性,故在图像的每个子图边界处会出现不连续的颜色跳变,导致视觉质量受到影响。为解决该问题,本文使用基于Fast-Matching 的图像修复技术(Telea,2004)进行视觉效果改善处理,在此不再赘述。
当接收方收到一幅可能遭受过数字裁剪攻击的含水印图像时,在进行水印解码前,需要先进行水印区域的定位提取操作。对称性噪声定位模板的提取步骤如下:
1)首先提取该图像的R通道,记为Iloc。
2)为得到原有的噪声模板,需要将其从R 通道Iloc中滤出,即
式中,fw表示Wiener滤波操作。
3)得到经过滤波并提取的噪声模板It后,按列求取对称性S(j)。该操作将图像分为3 部分:J1与J2为大小相等的列切块,J3为剩余的列切块。其数学表达式为
式中,M和N分别表示图像的高与宽,j表示图像像素的列数表示图像第j列与图像边界距。将J2进行水平翻转,得到ψ(J2),则列j的对称性S(j)即可定义为
式中,C(⋅)表示标准化操作,即
式中,E(·)和std(·)分别表示求平均值和标准差。
通过逐列检测对称性,最大值所在列即为可能的含水印图像子图的边缘。在理想情况下,所有的列对称性只会出现一个峰值;同理可按照相同的方法检测行对称性。
4)按行列对称性峰值为界,对图像进行切分,对切分后的4 幅子图尝试进行水印解码,只要有一幅子图解码成功即可。
需要注意的是,一般理想情况下才会只出现一个峰值;实际情况中,可能在图像边界的行列处也会出现对称性峰值,其原因是由于在边界行列处dj过小,导致即使不在真实的对称峰值处,S(j)也会很大。针对该问题,可将检测结果的对称性序列经过高通滤波器以滤除该虚假峰值。
2 实验结果与比较
2.1 实验设置
实验中本文采用多种拍摄设备与显示设备作为不同的屏摄条件。拍摄设备包括手机、数码相机等;显示设备包括电视、玻璃屏显示器、雾面屏显示器等。实验拍摄设备与显示设备的具体种类与型号如表3所示。

表3 屏摄实验环境硬件配置Table 3 Hardware configuration of the experiments for screen-shooting robust watermarking
实验过程为将通过编码网络嵌入水印后的图像利用各种显示设备显示,再使用拍摄设备进行屏幕拍摄,最后通过解码网络得到水印信息,并计算相关指标。实验中,用于进行消融实验的各模型的网络使用除实验超参数之外,相同的一组超参数进行训练。与其他文献方法进行对比实验的模型的网络超参数取值如表4 所示。本文使用的训练集为Flickr1M(Flickr-1-million)(Huiskes 和Lew,2008)的前100 000 幅图像,测试集为Flicker2K(Flickr-2-thousands)(Timofte等,2017)的前2 000幅图像。

表4 网络训练超参数及取值Table 4 The hyperparameter setting in network training
2.2 算法性能分析
2.2.1 JND损失函数消融实验
实验中,首先对算法采用的JND 损失函数是否对提高水印图像视觉质量有效进行消融实验分析。本文在Flicker2K-HR 数据集中随机选取500 幅图像进行测试,并以第1 节的网络结构为基础依次训练以下3 种网络:1)NET1:不加入JND 损失函数,生成3 通道(R,G,B)残差图;2)NET2:加入JND 损失函数,生成3 通道残差图;3)NET3:加入JND 损失函数,生成2 通道(G,B)残差图。3 种网络除式(13)中的权重系数η不同外,其余网络训练超参数均相等。
本文分别统计NET1,NET2,NET3这3 个网络生成水印图像的视觉质量指标,包括PSNR、SSIM(structural similarity)和LPIPS。另外,实验中还统计了这3 个网络生成的水印图像在正面且距离屏幕40 cm的情况下进行屏摄提取水印的误码率ε,如表5所示。可以看出,引入JND损失函数可以明显提高编码后图像的PSNR 和SSIM,降低LPIPS,即嵌入水印后图像的视觉质量得到提高,验证了JND 模块的有效性。

表5 JND损失函数消融实验结果Table 5 Results of ablation study for JND loss function
图9 为不同JND 损失函数设置下生成的水印图像及对应的残差图。可以看出,随着η的降低,生成残差图的整体强度越低,屏摄噪声越有可能破坏残差图的结构,导致误码率ε的上升。因此,为平衡图像质量与误码率(鲁棒性),本文最终选取生成两通道残差图,引入JND 损失函数,且权重系数η=1 来作为最终的网络结构,并以此进行后续的鲁棒性分析与性能对比。

图9 不同JND损失函数设置下的水印图像和残差图Fig.9 Watermarked images and residual images under different JND loss settings((a)NET1;(b)NET2,η=1;(c)NET2,η=0.5;(d)NET2,η=0.2;(e)NET3,η=1)
2.2.2 摩尔纹噪声层消融实验
为了分析摩尔纹噪声模拟模块的加入对提高算法鲁棒性的作用,本文训练了两个网络:1)NET4:训练过程中加入了摩尔纹噪声模拟层的网络;2)NET5:训练过程中未加入摩尔纹噪声模拟层的网络。在40 cm 的距离条件下,使用手机对显示屏幕从不同角度拍摄,以进行网络鲁棒性的评估。记NET4和NET5的水印提取误码率分别为ε1和ε2,结果如表6 所示。可以看出,NET4在不同角度屏摄情况下的误码率均低于NET5,验证了本文提出的摩尔纹噪声层确实可以有效提升算法的鲁棒性。
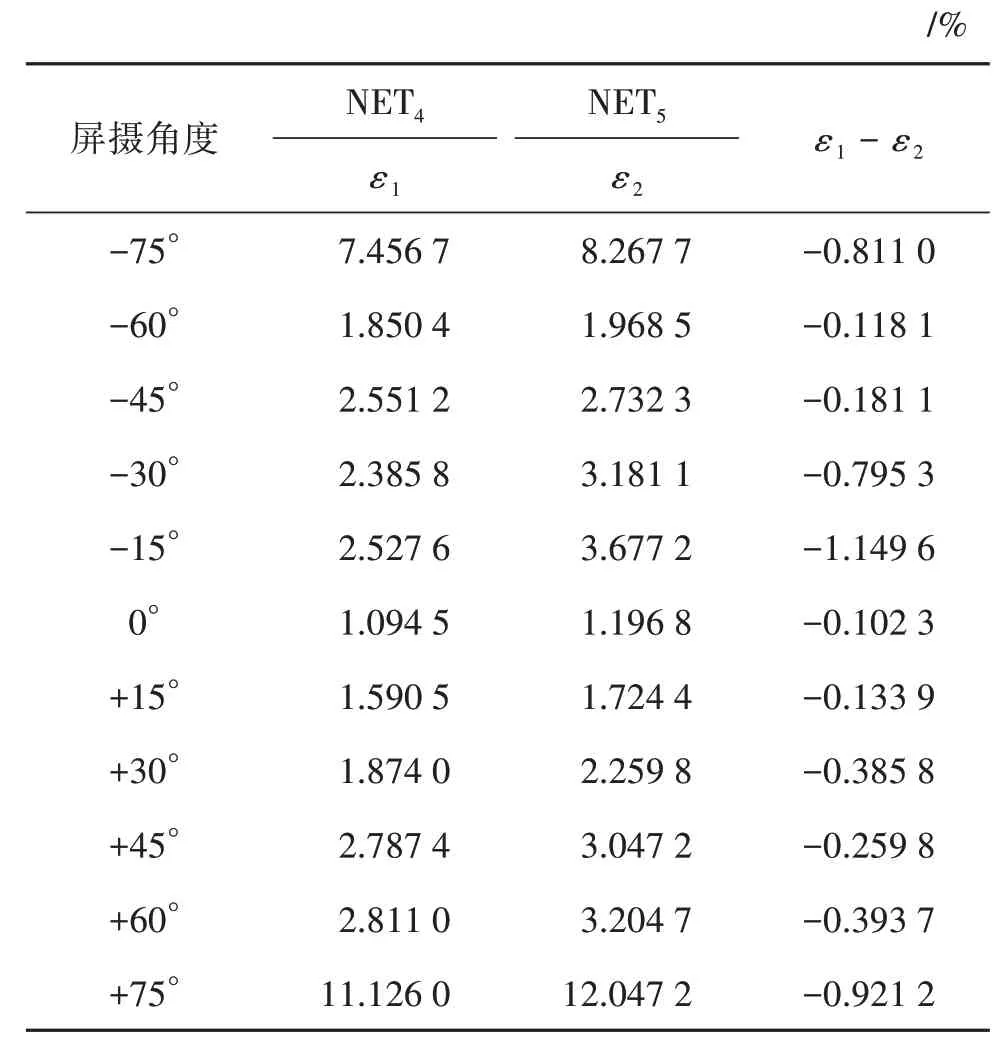
表6 摩尔纹噪声模拟层消融实验结果Table 6 Results of ablation study for the Moiré noise simulation layer
同时,本文对比了真实的屏摄图像与使用摩尔纹噪声层生成的模拟屏摄图像,如图10 所示。可以看出,图10(b)(c)中摩尔纹的纹路和色彩均有相似性,说明了摩尔纹噪声层生成的模拟屏摄图像可以有效地模拟真实屏摄图像。

图10 基于摩尔纹噪声层生成的模拟屏摄图像与真实屏摄图像示例Fig.10 Results of Moiré noise layers((a)original image;(b)simulated screen-shooting image;(c)real screen-shooting image)
2.2.3 拍摄图像区域定位实验
本文在1.4.1 节设计了一种基于语义分割的拍摄图像区域定位方法,用于从拍摄图像中提取含水印图像区域以降低网络解码的误码率。为验证该定位方法的有效性,实验中对屏摄后的图像进行如下3 种不同处理后,再输入解码网络进行水印提取并计算误码率:1)不引入图像区域定位;2)引入图像区域定位但不使用语义分割网络进行补全;3)引入图像区域定位且使用语义分割网络进行补全。另外,对于后两种处理,本文分别统计了定位出的含水印图像区域与实际含水印图像区域两者交集的面积占实际含水印图像区域面积的比例pr,即召回率。结果如表7所示。

表7 拍摄图像区域定位实验结果Table 7 Results of the captured image region localization
可以看出,在不引入拍摄图像区域定位时,将拍摄图像直接输入解码网络几乎无法正确提取水印信息。在引入了基于传统图像处理的自适应阈值分割进行前景定位后,含水印图像前景信息的召回率pr极低,水印提取误码率仍然较高,其原因是由于含水印图像本身内容与背景区域内容难以区分。在进一步引入语义分割网络进行前景信息补全后,含水印图像前景信息的召回率pr得到了大幅提升,水印提取误码率也下降到可以接受的范围。故实验结果说明了拍摄图像区域定位方法的有效性。
2.2.4 抗裁剪区域定位实验
为抵抗对含水印图像的数字裁剪攻击,本文在1.4.2 节设计了一种基于对称性噪声模板的抗裁剪区域定位方法。为验证其有效性,实验中本文从含水印图像四周进行不同比例的单边裁剪,再通过该定位方法定位后进行解码,并计算水印提取误码率,实验过程如图11 所示。其中,W1-W4表示嵌入图像的4 幅水印残差图,其含有相同的水印信息。实验结果如表8 所示,其中裁剪系数γ∈(0,1)表示图像被裁剪的部分占原图像大小的比例。从表8 可以看出,随着裁剪比例的增加,未经过抗裁剪区域定位的含水印图像的解码误码率显著上升;而经过抗裁剪区域定位后,含水印图像的解码误码率几乎保持不变,直至裁剪比例超过50%才呈现出上升趋势。也就是说,本文提出的抗裁剪区域定位方法可有效抵抗50%比例以内的裁剪攻击。

图11 抗裁剪区域定位实验示意图Fig.11 Flowchart of the experiment for the cropping-resistant region localization
2.2.5 屏摄鲁棒性分析
在验证了JND损失函数模块与摩尔纹噪声模拟模块有效性的基础上,本文分别在不同拍摄角度、不同拍摄距离、不同显示和拍摄设备的条件下,对本文算法的抗屏摄鲁棒性进行测试,结果如表9 所示。实验结果表明,在各种屏摄情况与设备条件下,本文算法的误码率均处于较低的范围,并可在后处理中运用纠错解码实现水印信息的准确提取,证明了本文算法对屏摄噪声的高鲁棒性。
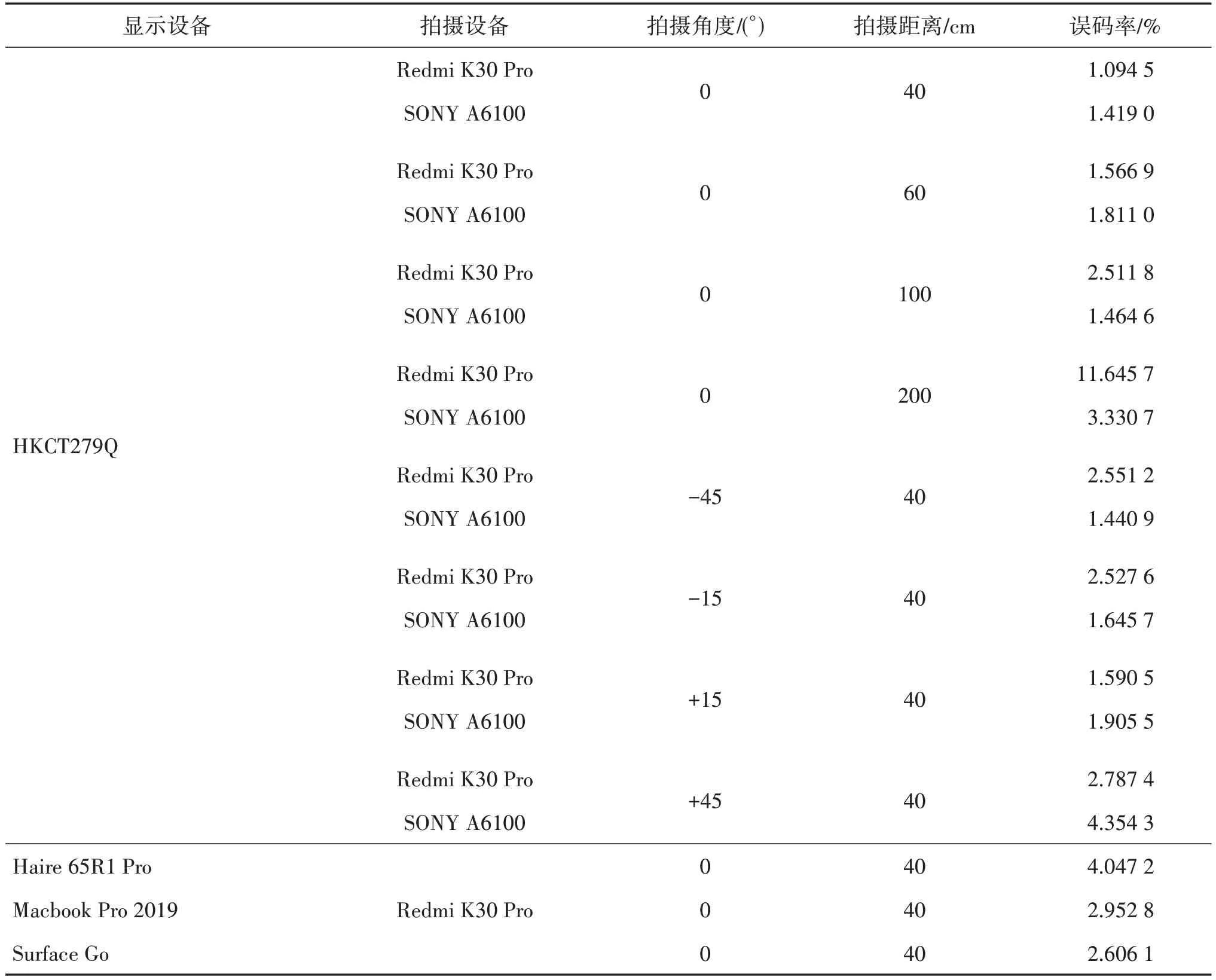
表9 本文算法抗屏摄鲁棒性(误码率)实验结果Table 9 Experiment results of robustness(bit error rate)of the proposed scheme
2.3 性能比较
实验中,本文算法与5 种典型的抗拍摄鲁棒水印算法进行鲁棒性和图像视觉质量方面的性能比较。其中,Pramila 等人(2012)、Nakamura 等人(2004)的方法和SSRW(screen-shooting resilient watermarking)算法(Fang 等,2019)为基于传统图像处理的算法;DTW(deep template-based watermarking)算法(Fang等,2021)与TERA(code with transpar-ency,efficiency,robustness and adaptability)算 法(Fang等,2022)为基于深度学习的算法。
表10 给出了不同拍摄距离和角度以及不同裁剪比例情况下的水印提取平均误码率。由结果可以看出,Pramila等人(2012)与Nakamura等人(2004)算法的误码率为10%~30%,本文算法的误码率为1%~3%,说明本文算法可有效抵抗非极端情况下

表10 不同算法鲁棒性(误码率)实验结果比较Table 10 Comparisons of robustness(bit error rate)for different schemes
的普通屏摄失真。SSRW 算法(Fang 等,2019)虽然误码率与本文算法相近,但其仅能抵抗打印拍摄,无法有效抵抗屏幕拍摄,因为图像经过屏摄信道干扰后SIFT 特征点会产生较大失真。DTW 算法(Fang等,2021)与TERA 算法(Fang 等,2022)的误码率也均高于本文算法。这是因为在网络训练过程中,本文算法加入了对含水印图像造成较大程度失真的摩尔纹的噪声模拟层,准确地模拟了摩尔纹的纹理,同时其他噪声层所模拟的屏摄噪声强度也较大,超过实际屏摄时的噪声强度,所以网络一旦学习到并具有了可抵抗模拟屏摄噪声的能力,便可获得对实际屏摄噪声的鲁棒性。另外,本文预留了图像的R 通道用于抗裁剪的模板嵌入,使得本文算法可有效抵抗较大程度的裁剪攻击。
特别地,DTW 算法(Fang 等,2021)是先将提取的残差水印图像分割为t个单码元水印模板,再送入网络模型进行解码,最后将解码出的t个码元进行组合,即DTW 可以归纳为t个二分类问题;而本文算法将提取的残差水印图像直接送入网络模型进行解码,直接解码出t个码元,故解码过程相当于一个2t的多分类问题。相对于DTW 的二分类模型,本文的网络模型最后用于多分类判决输出的判决空间会相对狭窄,多分类判决输出造成误判的概率相较二分类判决输出的情况要大。在鲁棒性实验中,图像在较小比例裁剪条件下受到的噪声相较于大拍摄角度和距离范围的屏摄噪声,强度较小。故在此条件下,以二分类码元作为输出,随后进行码元组合的DTW算法的误码率会相对较低。然而,本文训练的模型在生成含水印图像时将码元信息均匀分布、交织融合在残差水印图像中,因此,当含水印图像整体因噪声丢失一部分信息时,DTW 算法只能解码出其余位置的码元信息;而本文算法在解码时可根据其余位置的信息对丢失的信息进行补充,从而解码出t个码元。也就是说,本文算法的优势集中在强噪声情况下,模型的抗噪声鲁棒性能。由表10 可见,本文算法虽然在裁剪比例小于50%时的误码率高于DTW算法,但是在裁剪比例继续增加时,本文算法的性能衰减会显著低于DTW 算法。同时,本文算法在多角度、多距离的屏摄实验中,性能表现也相对较为稳定,说明了本文算法在对抗多种噪声情况下的鲁棒性能较好。
表11 为不同算法可嵌入的水印容量与对应的含水印图像视觉质量结果。可以看出,本文算法在嵌入127 bit 的条件下,生成的含水印图像视觉质量指标PSNR 和SSIM 分别可达31.77 dB 和0.91,肉眼无法明显区分其与原始图像的差别,但相对其他嵌入水印信息比特较少的算法,本文算法仍有进一步提升空间。

表11 不同算法含水印图像视觉质量比较Table 11 Comparison of watermarked image quality for different schemes
2.4 算法实时性分析
抗屏摄水印在屏幕内容实时保护和信息获取等实际应用中,算法的计算效率非常重要。为了评估本文算法的实时性,本文针对水印嵌入、拍摄区域定位与水印提取过程分别统计了对每100 幅图像进行相关处理的平均时间,结果如表12所示。

表12 算法各阶段的处理时间Table 12 Execution time of each stage of our scheme
程序运行硬件环境的GPU 为Nvidia 2070 Super,CPU 为AMD R5 2600X,内存大小为32 GB。可以看出,本文算法对单幅图像进行嵌入、定位与提取操作的耗时均小于30 ms,总耗时小于0.1 s,表明本文算法的计算复杂度较低,无需耗费大量资源,可满足实际应用场景的实时性需求。
3 结论
本文设计了一个端到端的抗屏摄鲁棒水印的嵌入—提取网络,并在此基础上引入了摩尔纹噪声模拟层与JND损失函数模块以提高网络生成的含水印图像的鲁棒性与视觉质量。同时,为了在实际应用中可对含水印图像进行自动区域定位,本文还给出了拍摄图像区域定位方法和抗裁剪区域定位方法。进一步的研究工作包括:本文算法在抵抗屏摄信道噪声方面现阶段仍存在一定的局限性有待改进,如无法在只拍摄到屏幕图像部分内容(非数字裁剪)的情况下进行水印解码;如何进一步实现在高嵌入容量条件下达到更为理想的含水印图像视觉质量,也有待深入研究。
猜你喜欢
钻井液与完井液(2022年4期)2022-10-26
中国石油石化(2022年12期)2022-07-16
化工管理(2021年7期)2021-05-13
装备制造技术(2020年11期)2021-01-26
农业机械学报(2020年2期)2020-03-09
中国外汇(2019年19期)2019-11-26
中华建设(2019年7期)2019-08-27
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
水利规划与设计(2016年9期)2017-01-15
