
深度特征融合注意力与双尺度的运动去模糊
2023-12-23 10:13陈加保熊邦书况发章照中
中国图象图形学报 2023年12期
陈加保,熊邦书,况发,章照中
南昌航空大学图像处理与模式识别省重点实验室,南昌 330063
0 引言
随着低成本成像设备的普及,图像获取日益方便,已经成为各行各业表达信息的主要方式。然而,自然图像在成像过程中,会受到天气雨雾、大气光线、镜头失焦、镜头抖动和物体运动等方面的干扰,造成图像模糊。图像模糊大致可以分为3 大类:大气模糊、散焦模糊和运动模糊。在工业运用上,由于相机拍摄时抖动或目标物体运动,经常产生运动模糊现象,这在一定程度上影响了计算机视觉任务(图像分类(Fish 等,2021)、目标检测(Oyedotun 等,2021)和图像分割(Liu 等,2018))的处理效果。因此,运动图像去模糊对计算机视觉任务十分重要。
运动图像去模糊(吴迪等,2020;Suin 等,2020;Wang和Su,2022)可以分为非盲去模糊和盲去模糊。非盲去模糊是模糊核已知的一种去模糊方法,其不需要求解模糊核,可在去除噪声后直接将模糊核与模糊图像进行反卷积,得到清晰图像。这类方法过程简单,效果好,但前提是模糊核已知。盲去模糊则是模糊核未知的一种去模糊方法,其需要先估计模糊核的大小,然后利用非盲去模糊方法进行去模糊处理。此类方法较为复杂,计算量大且耗时。由于真实场景下模糊核是未知的,去模糊的绝大多数情况都是盲去模糊,本文方法属于盲去模糊。
运动图像盲去模糊方法(Pan 等,2016;Yang 和Ji,2019)可分为两大类:间接去模糊和直接去模糊。间接去模糊方法是利用不同的图像先验信息,建立图像复原的约束条件进行复原图像的一类方法。Šroubek 和Kotera(2020)提出了非参数的模糊先验,由曲线段组成,可微、可嵌入到大多数模糊问题的优化中。Ju 等人(2021)提出一个局部线性先验,其与大气散射模型(atmospheric scattering model,ASM)结合,得到一个新的图像复原公式(recovery formula,RF),并引入了向导式滤波器来消除由于图像分块造成的负面影响。Liu 等人(2022)利用清晰图像的简化亮通道先验比模糊图像的次方根更小的原理,提出了简化极值信道先验(simplified extremal channel prior,SECP)。间接去模糊方法利用先验知识提升复原图像的效果,在某一程度上效果很好。但实际场景下的图像模糊因素复杂多样,且图像先验知识层出不穷(Bahat 等,2017;邱枫等,2019;Ahmad等,2021),计算量大且训练时间长,不利于真实场景下的测试。
考虑到上述问题,学者们开始逐渐使用直接去模糊的方法去除真实场景下的运动模糊。此类方法(Chakrabarti,2016;Zamir 等,2021)无需考虑某些特定的图像先验,利用深度学习算法的非线性特点,直接学习模糊图像到清晰图像的映射,达到去模糊效果。Nah等人(2017)采用3个不同的尺度结构,每个尺度使用连续19 个残差块,在不同尺度获取图像的空间信息,逐步恢复出清晰图像,有效增强了模型的去模糊性能。在多尺度网络基础上,使用了长短期记忆网络,获得了更好的特征保留效果,并设计了参数共享技术,减少了模型处理时间。Gao 等人(2019)在Tao 等人(2018)方法的基础上,利用参数全部共享会忽略特征的尺度变化的特性,提出了选择性参数共享策略,在特征进行上下采样时,网络不进行参数共享,特征进行增强操作时,进行参数共享,进一步提升了模型去模糊性能。Ye 等人(2020)提出了一种新的尺度迭代结构,与以前的固定级别架构相比,网络通过应用不同的迭代来进行训练和预测,并在不同的尺度上共享权重,从而更加灵活。Zhang 等人(2020)提出一个新方法,由两个生成对抗网络(generative adversarial networks,GANs)模型组成,一个用于生成模糊图像,另一个用于去模糊图像。用第1 个模型指导第2 个模型如何去模糊。如此设计用于解决现在大多数的去模糊模型都是基于清晰与模糊的图像对的有监督训练,而模糊图像的生成是人为的,难以模拟真实场景下的模糊效果。Cho 等人(2021)提出基于单编解码器的U 型网络MIMOUNe(tmulti-input multi-output UNet),采集多尺度输入图像,引入不对称特征融合,提取不同尺度的特征,并在编码器和解码器之间融合多尺度信息流,实现了多尺度特征的有效融合。Kim 等人(2023)提出了一种新的多尺度阶段网络MSSNet(multi-scale stage network),使用反映模糊尺度的阶段配置、跨尺度信息和基于像素变迁的多尺度,在复原质量、网络大小和计算时间都有较好的性能。现有直接去模糊方法结构多样,但由于模糊在不同尺度上的特性,多尺度有更好的去模糊效果,但一直存在高低层特征信息融合不充分的问题,导致去模糊的效果仍有待提升。
针对上述问题,本文提出了基于深度特征融合注意力的双尺度运动去模糊网络(double-scale network with deep feature fusion attention,DFFA-Net)。首先,设计双尺度网络,在低尺度上增加对模糊区域的注意,在高尺度上提升网络的细节恢复能力。其次,设计深度特征融合注意力模块,通过融合全尺度特征、构建通道注意力,将高低层特征信息进行充分融合,使得模型在去模糊的同时也可以较好地保持细节。最后,为使网络更有效地恢复高频细节,将感知损失函数替换为频域损失函数,且引入多尺度损失,提升网络对模糊特征的敏感程度,增强了模型的细节恢复能力。对比实验结果表明,在3 个不同数据集上与12 种经典方法进行比较,本文算法复原图像清晰,泛化性好。
1 相关理论
1.1 运动模糊图像退化模型
图像成像时目标物体运动或是设备移动,会造成成像图像退化,得到运动模糊图像,该过程可建模为
式中,y表示运动模糊图像,x表示原始清晰图像,k为模糊核,n为噪声,∗为卷积操作。去模糊等效于求解式(1)中的x值,然而在真实场景下,式(1)中k与n均未知,求解是个病态问题,直接求解效果不好且计算量极大。由于深度学习方法可以学习数据的内在特征,自动构建出模糊图像和清晰图像之间的非线性映射关系,因此本文采用深度学习的方法进行运动去模糊。
1.2 多尺度网络
单尺度网络(Kupyn 等,2018;Purohit 和Rajagopalan,2020;Tsai 等,2021)结构如图1(a)所示,其为单输入单输出结构。输入固定分辨率的图像,通过网络得到一个输出。这种网络结构简单、易实现且计算速度快。但由于仅使用单个分辨率图像,网络的去模糊效果不佳。

图1 各网络结构示意图Fig.1 Schematic diagram of several networks structure((a)single scale structure;(b)multi-scale structure of multi-network;(c)multi-scale structure with single input and single network;(d)multi-scale structure with single-network and multiple inputs)
多尺度模型是指在模型中通过下采样方法,将图像转化为不同分辨率图像,再将所有分辨率图像依次作为输入放进网络,形成多输入多输出的模型设计结构。当对于不同的分辨率图像使用不同的模型时,结构如图1(b)所示。这种方法的优点是去模糊性能强,缺点是参数与计算量极大,如DMCNN(dynamic multi-pooling convolutional neural network)方法(Nah 等,2017)。当对于不同的分辨率图像使用同一个模型,结构如图1(c)所示。这种方法的优点是去模糊性能强,计算量得到了缩减,缺点仍然是参数与计算量较大,如SRN(scale-recurrent network)(Tao 等,2018)和PSSSRN(parameter selective sharing network)(Gao 等,2019)方法。如果在输入时一次将所有分辨率图像输入网络,结构如图1(d)所示。这种方法的优点是不需要重复对网络进行计算,计算量得到了缩减,不足之处是不能够获取不同分辨率图像的差异,如MIMOUNet方法。
2 本文方法
基于深度特征融合注意力的双尺度网络如图2所示,受MIMOUNet 启发,在其基础上,采用双尺度结构(如图3 所示),同时引入了自提的深度特征融合注意力(图2 中M3),最后引入多尺度损失,改进了损失函数。
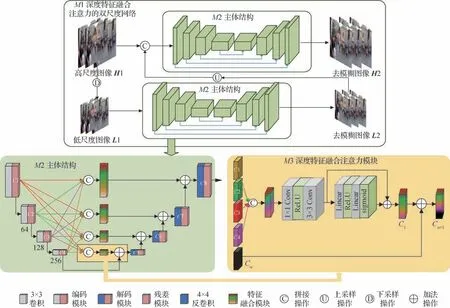
图2 深度特征融合注意力的双尺度网络结构图Fig.2 Improved double-scale network structure diagram for deep feature fusion attention
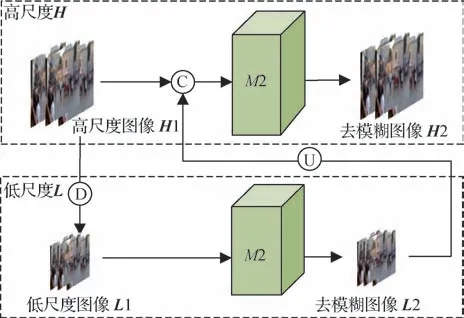
图3 双尺度网络结构Fig.3 The architecture of improved multi-scale network
网络整体结构如图2 中M1 所示,高尺度图像H1 下采样后得到低尺度图像L1,L1 经主体结构M2得到去模糊图像L2,L2 与高尺度图像H1 拼接后经M2 得到去模糊图像H2。这种双尺度结构利用了图像多尺度空间信息,使得网络精准把握图像的模糊信息,有效降低训练难度。
图2 中深度特征融合注意力模块M3 融合高低层特征信息。首先拼接全尺寸信息C1-C4,其次使用卷积和通道注意力得到融合信息C,将C与Cn叠加得到Cn+1。Cn+1很好地融合了各个尺度的特征信息,使网络的去模糊和细节恢复能力更好。
在双尺度的结构基础上,使用内容损失和频域损失计算总的损失量,并改进各个尺度的损失权重,使模型更加注重高尺度上的损失。
2.1 双尺度网络
本文设计了如图3 所示的双尺度网络,有低尺度L和高尺度H两个尺度。低尺度图像L1 经网络M2 得到去模糊图像L2,增加了对模糊的注意力,大幅度去除模糊;L2 与高尺度图像H1 拼接后,经M2得到去模糊图像H2,增加去模糊图像的高频细节,H2则为最后输出的去模糊图像。
M2具体结构如图4所示,使用编码器的多个残差块提取图像特征,得到不同尺寸的融合信息(Z12—Z43),作为解码器输入。解码器使用转置卷积与连续20 个残差模块恢复图像尺寸与通道,得到残差图像,最后将残差图像与模糊图像叠加得到去模糊图像。

图4 网络M2结构Fig.4 The structure of M2
图5 是模糊图像通过双尺度网络后得到的内部特征图。从图5 可以看出,图5(c)中去模糊图像L2与图5(a)模糊图像相比,去除了大部分的模糊,但存在高频细节的丢失,图5(d)中去模糊图像H2 相比图5(c)中去模糊图像L2更加清晰,说明高频细节恢复得更好。双尺度网络结构在低尺度上增加对模糊区域的注意力,在高尺度上提升网络的高频细节恢复能力,提升了模型的去模糊性能。

图5 双尺度内部特征图输出Fig.5 The output of multi-scale internal feature map((a)blur image;(b)clear image;(c)the ouput of scale L2;(d)the output of scale H2)
2.2 深度特征融合注意力模块
为减少特征信息丢失(Zhang 等,2019;Park 等,2020;Huang 等,2020),提升网络的特征提取能力,本文提出了深度特征融合注意力模块,如图6 所示。首先,通过全尺度特征提取结构,对不同尺度下的特征信息C1-C4进行拼接。其次,利用1 × 1卷积层对通道进行降维,3 × 3 卷积层提取特征。再次,通过通道注意力获取通道权重,得到全尺度特征注意力。最后,全尺度特征注意力与上一级的解码输出Cn相加,得到深度特征融合注意力Cn+1。该模块通过融合低层纹理信息和高层语义信息,显著提升了模型的去模糊效果。
图7 是深度特征融合注意力模块的去模糊效果对比图,从图7(b)和图7(c)的对比中可以看出,使用深度特征融合注意力模块在某些局部不会出现色度失衡,表明其在去除运动模糊上有较好的效果。

图7 深度特征融合注意力去模糊对比图Fig.7 The deblurring comparision of deep feature fusion attention model((a)blur image;(b)no-adding deep feature fusion attention model;(c)adding deep feature fusion attention model)
图8 是深度特征融合注意力模块内部的各输出特征图。图8(a)—(d)分别表示图6 中C1、C、Cn和Cn+1位置上的特征图;图8(e)—(h)分别是对应的第4通道图像。从图8(e)和图8(h)的对比中可以看出,经过深度特征融合注意力模块,特征更加尖锐稀疏,集中于模糊区域,说明深度特征融合注意力模块可以强化网络特征提取能力,使特征信息融合更加充分,增强去模糊效果。

图8 深度特征融合注意力模块内部各输出特征图Fig.8 The internal feature map of deep feature fusion attention module output((a)the output of C1;(b)the output of C;(c)the output of Cn;(d)the input of Cn+1;(e)the output of C1 in the fourth channel;(f)the output of C in the fourth channel;(g)the output of Cn in the fourth channel;(h)the input of Cn+1 in the fourth channel)
2.3 损失函数
为解决复原图像存在均值模糊和高频细节信息少的问题(Fuoli 等,2021),本文将内容损失和频域损失结合作为总的损失函数,具体为
式中,Ltotal表示全部损失,Lcontent表示内容损失,Lfrequency表示频域损失,α是频域损失的权重,值为0.1。为进一步增强高频细节,本文改进了损失权重,使模型对不同尺度的损失有不同的关注度,形成了多尺度损失。
内容损失的计算有平均绝对误差(mean absolute error,MAE)和均方误差(mean square error,MSE)两大经典方法。由于均方误差MSE 在误差较大时,模型会增大惩罚力度,导致对异常点敏感,不利于恢复模糊图像的细节。因此,本文选择平均绝对误差MAE 作为内容损失函数,结合多尺度,计算清晰图像与复原图像各像素绝对差值,得到多尺度内容损失为
式中,K是复原尺度,取值区间为[1,2],尺度1(K=1)损失占比为0.5,尺度2(K=2)损失占比为1;M是图像高度,N是图像宽度,f(i,j)是清晰图像,f′(i,j)是复原图像。
为了减少复原图像与清晰图像在频域空间的差异,得到更多细节图像,使用频域损失。首先对复原图像与清晰图像进行二维傅里叶变换,然后计算两者之间的平均绝对误差,最后与多尺度权值相乘,得到多尺度频域损失,计算为
式中,F′(i,j)是复原图像的傅里叶变换,F(i,j)是清晰图像的傅里叶变换。
3 实验结果与分析
3.1 数据集与评价方法
本文使用接近真实模糊情况的GoPro 数据集进行训练与测试,该数据集共包含3 214对模糊和清晰的图像,图像尺寸为720 × 1 280 像素,其中2 103 幅图像对用于训练,1 111幅图像对用于测试。
本文采用峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似度(structural similarity,SSIM)作为图像去模糊质量的评价指标。PSNR 从像素层次上衡量复原图像与真实图像的差异,值越大代表效果越好。SSIM 从亮度、结构信息和对比度3 个方面衡量复原图像与真实图像的相似度,值越接近于1,图像越相似。
3.2 实验参数设置
本文模型基于PyTorch 深度学习框架,使用Python 语言实现,在配有NVIDIA GeForce GTX 1080TI GPU 的Linux 系统上进行训练与测试。训练过程中使用Adam优化器,训练周期数量为2 000,学习率从10-4到10-7线性衰减,使用水平与垂直翻转进行数据增强。为了加快训练,将输入图像裁剪为256 × 256像素的图像块,像素值进行归一化。
3.3 消融实验
为验证本文方法中双尺度网络结构、深度特征融合注意力模块DFFM 和本文损失函数Lossour的有效性,进行消融实验。表1 给出了不同模型结构对模型性能的影响,从表1 可看出,加上双尺度和DFFM 的方法比单独加上双尺度和单独加上DFFM 的方法,在PSNR、SSIM 上都有提升,这表明双尺度和深度特征融合注意力模块DFFM 可以带来更好的去模糊性能,细节恢复效果更好。当使用本文损失函数时,从表1 中可以看出,该损失函数对复原图像的高频细节信息有较好的复原效果。
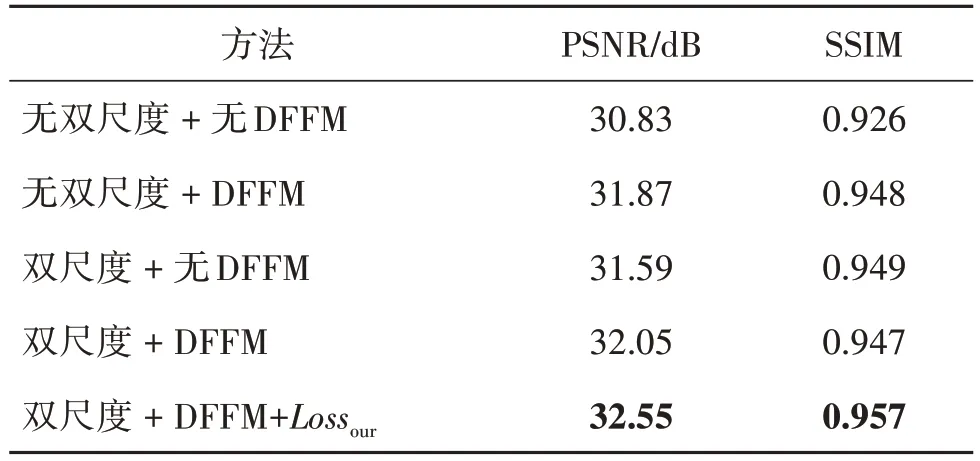
表1 不同模型结构对模型性能的影响Table 1 Influence of different model structures on model performance
在训练过程中,多尺度会需要大量的显存来保存临时参数,同时多尺度间的信息融合操作(通道叠加或逐元素相加)会大大影响速度。表2 给出了模型的参数对比情况,双尺度在参数量与推理时间上表现出一定的优势,说明双尺度可以有效降低训练难度。
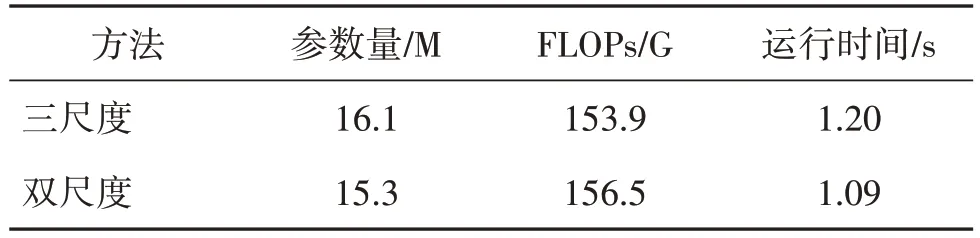
表2 双尺度与三尺度模型参数对比Table 2 The comparison of double-scale with three-scale on model performance
3.4 经典方法对比
3.4.1 GoPro数据集
与12 种经典的图像去模糊方法进行对比,验证本文方法的有效性。包括DMCNN、DeblurGAN(deblur generative adversarial network)、SRN、DMPHN(deep stacked multi-patch hierarchical network)、SVRNN(structured variational recurrent neural network)、DeBlurGANv2、PSSSRN、SIUN(scale-iterative upscaling network)、MTRNN(multi-temporal recurrent neural networks)、BANet(blur-aware attention networks)、MIMOUNet 和SharpGAN(sharp generative adversarial network)。表3给出了各方法的去模糊对比结果,可以看出,DMCNN、DeblurGAN、SVRNN、DeBlurGANv2 和SharpGAN 的PSNR 与SSIM 都比较小,说明这些方法的去模糊性能较差。在PSNR 上,本文方法比DMCNN 方法提高了3.61 dB,比SRN 方法提高了2.29 dB,比PSSSRN 方法提高了0.98 dB;与BANet 方法相比,PSNR 提升了0.11 dB,SSIM 提升了0.002;与最新的MIMOUNet方法相比,PSNR提升了0.10 dB,SSIM 提升了0.001,说明本文方法在去模糊效果与高频细节的恢复有最佳表现。

表3 在GoPro数据集上各方法的去模糊数据Table 3 Defurring data of several methods on GoPro dataset
为验证本文方法的去模糊效果,选取GoPro 测试集中两幅具有代表性的图像,选择了9 种经典方法与本文方法进行去模糊性能对比,结果如图9 所示。可以看出,对于模糊图像1 中的车牌号,DMCNN、SVRNN 和DeBlurGANv2 方法的复原图像仍然存在明显的模糊情况,其他5 种方法也都存在些许模糊感,而本文方法的清晰程度最佳;对于模糊图像2中的电话号码,只有PSSSRN、MIMOUNet以及本文方法这3 种方法可以清晰地复原出数字872-3300,且本文方法的复原结果最清晰。上述结果说明,本文方法在公共数据GoPro 上,与其他9 种主流方法对比,去模糊效果最好。
3.4.2 Kohler数据集
Kohler 数据集(Köhler 等,2012)总共包含48 幅模糊图像,图像尺寸为800 × 800像素,其中有4幅基础图像和12 种不同的运动模糊核,每一幅模糊图像都由基础图像与模糊核进行卷积得到。使用Kohler数据集对在GoPro 上训练好的模型进行测试,同时与7 种经典算法对比,验证模型的鲁棒性。从数据集中选取最具代表性的模糊图像,与各方法的对比结果如图10 所示。从图10 可以看出,SRN、DMPHN、MTRNN 和MIMOUNet 方法在月亮与星星处都非常模糊。SIUN、PSSSRN 和本文方法都较为清晰,而本文的清晰程度最高,这表明本文方法对比其他主流方法,鲁棒性更好。

图10 各方法在Kohler数据集上的对比Fig.10 The contrast effects of restoration methods on Kohler dataset
3.4.3 Lai数据集
Lai 数据集(Lai 等,2016)是由不同拍摄者使用不同设备,在不同真实场景下获取不同尺寸的真实图像集,共100 幅图像。为进一步验证本文方法的去模糊性能,选取其中两幅最具代表性的图像进行测试,结果如图11所示。

图11 各方法在Lai数据集上的去模糊效果对比Fig.11 The comparison effect of restoration methods on Lai dataset
从图11 可以看出,对于模糊图像1,除了DeBlurGANv2、PSSSRN、SIUN 和本文算法外,其他算法如DMPHN、BANet、MTRNN 和MIMOUNet 均不能在真实模糊图像上有很好的去模糊效果。在DeBlurGANv2 方法中,字母BA 处存在明显凸现,数字5 的左下角有伪影,存在一定程度的模糊。在SIUN 方法中,字母ALCON 处出现了横条状波浪的模糊,而本文方法的复原效果看起来更加真实。对于模糊图像2,除DeBlurganv2和本文方法外,其他所有方法在五角星处都出现了伪影,同时在数字3 处,DeBlurGANv2 方法仍然出现伪影,而本文方法不存在任何形式的伪影,由此可以看出,本文方法在真实模糊场景下的图像中,去模糊的效果最佳。
4 结论
针对现有方法去运动模糊效果不佳,运动图像去模糊质量有待提升,本文提出了一种基于深度特征融合注意力的双尺度图像去模糊算法。1)设计了双尺度网络,利用低尺度图像具有更小尺度模糊的特性,增加了网络对模糊特征的注意力,利用高尺度图像加强了复原图像高频细节恢复,增强了模型去模糊性能与真实图像去模糊时的泛化性。2)构建了深度特征融合注意力模块,将高低层所有特征信息进行融合,有效利用了网络提取的所有特征信息,增强了模型去模糊性能。3)改进了损失函数,引入了多尺度损失,使模型更关注高频细节的恢复。实验结果表明,本文方法可以对模糊图像进行有效去模糊,同时与目前最新的方法MIMOUNet相比,不仅在公共数据集GoPro 上评价指标有较大提升,而且在真实图像上去模糊的泛化性也更好。
本文方法具有更好的运动去模糊性能,提升了复原图像的质量,但针对复杂场景下不同目标模糊程度不一时,复原图像存在模糊残影,对高频细节恢复不佳,这将是未来努力的方向。
猜你喜欢
疯狂英语·新悦读(2022年8期)2022-09-20
小雪花·成长指南(2022年1期)2022-04-09
陶瓷学报(2020年6期)2021-01-26
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
紫禁城(2020年8期)2020-09-09
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
雕塑(2000年2期)2000-06-22
