
融合小样本元学习和原型对齐的点云分割算法
2023-12-23 10:14邱云飞牛佳璐
中国图象图形学报 2023年12期
邱云飞,牛佳璐,2*
1.辽宁工程技术大学软件学院,葫芦岛 125100;2.中国科学院海西研究院泉州装备制造研究所,泉州 362216
0 引言
3D 点云在自动驾驶(Li 等,2021)、导航定位(Liu 和Siegwant,2014)、AR(augmented reality)看房(Liu等,2021)和模型重建(Wu等,2017)等诸多领域得到广泛应用。近年来,针对点云的研究有很多,如对其进行分类(Uy 等,2019;戴莫凡 等,2022)、配准(Yang 等,2021)、分割(邱云飞和朱梦影,2021)、补全和重建(Huang 等,2020;Mandikal 和Radhakrishnan,2019)等。其中,点云分割需要了解全局几何结构和每个点的细粒度细节,根据分割粒度,分为语义分割(场景级别)、实例分割(对象级别)和部件分割(部件级别)。语义分割较为常用,对于一个大型场景可以分割出其内部细节特征,能够很好地反映事物面貌,但是由于点云的不规则性,处理点云数据并将其应用是很有挑战性的,对此,点云的语义分割有两种研究范式,即基于投影的方法和基于点的方法。
基于投影的网络很多,最早的研究是用多视图(Guerry 等,2017)的方法表示点云,先从多个虚拟摄像机试图将3D 点云投影到2D 平面上,即在多个相机位置生成点云的多个RGB 和深度图像,然后使用2D 分割网络对这些数据进行逐像素标记,每个点的最终语义标签是通过将预测的分数使用残差网络融合到不同的视图上而获得的。为了实现点云的快速准确分割,Wu等人(2018)又提出了用球形表示的点云数据的方法,是一种基于SqueezeNet 和条件随机场(conditional random field,CRF)的端到端的网络,虽然与多视图投影相比,球形投影保留了更多信息,但是也不可避免地带来一些问题,例如离散化误差和遮挡。为了解决这样的问题,Riegler 等人(2017)提出体素化的处理方式,先将点云划分为一组占用体素,然后传输到3D 卷积网络中以进行体素分割,为体素内的所有点云分配与体素相同的语义标签,另外Tchapmi等人(2017)提出的SEGCloud实现细粒度与全局一致的语义分割,这种方法引入了确定性三线性插值法,将3D-全卷积神经网络(3D-full convolutional neural network,3D-FCNN)生成的粗体素预测映射回点云,然后使用全连接来增强这些推断出的点的标签的空间一致性。但是体积表示是稀疏的,因为非零值的数量只占很小的百分比,而且由于体素是空间的离散表示,因此该方法需要高分辨率的网格,对存储器的容量要求较高,且在稀疏的数据上应用密集的卷积神经网络会使实验效率低下。总体而言,体积表示保留了3D 点云的邻域结构,而且它还能直接应用3D 卷积,使得网络性能提高,但是通常高分辨率会导致较高的内存占用率和运算成本,低分辨率又会导致细节丢失,在实际应用中选择合适的网格分辨率并非易事。
基于点的网络是直接在不规则的点云上工作的,因为点云的无序性和无组织性,直接应用卷积神经网络(convolutional neural network,CNN)是不行的,因为标准的深度神经网络模型需要具有规则结构的输入数据,为此Qi 等人(2017a)开创性地提出了PointNet,该网络使用共享MLP(multilayer perceptron)学习每点的特征并且使用最大池化收集全局特征,但忽视了点云的局部信息,没考虑邻域特征,因此,PointNet++对它进行了改进(Qi 等,2017b),增加了对局部邻域信息的采样特征提取,将PointNet分层应用到点云的多个子集上,不仅能够提取到局部信息,还综合了PointNet 提取全局信息的优点,然而它忽略了点之间的空间立体几何关系。为了解决这个问题,Phan等人(2018)和Wang 等人(2019b)在动态图神经网络(dynamic graph CNN,DGCNN)中提出了边缘卷积(edge convolution,EdgeConv),通过建立点与点之间的拓扑关系,增强数据表征能力,设计了边缘卷积,既可以保持点云的排列不变性,又能捕获局部几何特征。
以上这些方法的训练很大程度上依赖于大量有标签的数据,收集时会有很高的时间、人力成本,且都是闭集假设,在通过神经网络对模型训练后,泛化性差,很难用这个模型预测一些新的未知语义类别。与之形成鲜明对比的是,人类却可以在只看到一个类别的几个例子的情况下就能从很多类别中分辨出这个之前从不认识的新类别。这种对比激发了人们对小样本学习(Puri等,2020)问题的研究,其目的是在仅有一个或几个标记样本的情况下,就能够在测试集中准确地分割出新的未知语义类的目标。
单样本学习的概念很早就由Li 等人(2003)提出:当新的类别只有一个或几个带标签的样本时,已经学习到的旧类别可以帮助预测新类别。零样本学习(Socher等,2013;Cheraghian 等,2020)是指在没有训练数据的情况下,利用类别的属性等相关信息训练模型,然后识别出新类别。在小样本学习中由于样本量不够导致经验风险最小化带来的最优解和真实解之间的误差会变大,因此必须使用先验知识来解决此问题。
根据利用先验知识的方法的不同,一般将小样本学习分为基于模型微调、基于数据增强和基于迁移学习这3 种。基于模型微调的方法是在含有大量数据的源数据集上训练一个分类模型,然后在含有少量数据的目标数据集上对模型进行微调,但容易导致模型过拟合,因为少量数据不能很好地反映大量数据的真实分布情况。因此,基于数据增强和基于迁移学习的方法相继提出(汪荣贵 等,2019;Wang等,2020)。基于数据增强的方法是利用辅助数据集或辅助信息来扩充目标数据集或增强目标数据集中的样本的特征,从而使模型能更好地学习特征;基于迁移学习的方法是目前比较前沿的方法,将已经学会的知识迁移到一个新的领域中,其中元学习(Hospedales等,2022)的应用最为广泛。
针对点云分割需要大量监督信息的局限性,本文提出采用融合原型对齐和小样本元学习的策略对点云进行语义分割,将训练好的初始化模型经过少量样本微调后输出分割结果,并将优化好的最终模型应用在闽南古建筑数据集上,由于标记样本十分稀少,可在验证泛化性能的同时应用于闽南古建筑的统计、修缮等研究工作。实验证得本文方法在完成小样本点云分割任务时,模型的泛化能力有所提升,并在闽南古建筑数据集上有一定的分割效果。
1 模型介绍
将元学习与原型对齐(Wang 等,2019a)的融合算法运用于小样本点云分割上,原型对齐算法可以校对模型学习完的原型,从而更好地学习支持集的信息,以此来提高小样本学习的泛化能力。
1.1 模型框架
如图1 所示,对数据集进行预处理后投入元训练,利用元训练过程中的特征提取器提取原型,并运用原型对齐算法优化模型,直至达到能分割出理想效果的最优模型。

图1 总体网络框架图Fig.1 Overall network framework diagram
1.2 算法流程
图2 为本文提出的融合原型对齐的元训练过程的算法流程图。元训练时,重新制作数据集为N-wayK-shot的模式,然后用特征提取器分别提取支持集和查询集的特征,得到每个类的原型,根据查询集特征与支持集求得的原型之间的欧氏距离来分割查询集点云,然后逆向回溯训练过程,利用查询集特征与分割掩码结合组成的“新支持集”通过特征提取器得到的新原型来分割原支持集的点云,通过这样的校对方式能够更好地学习支持集的特征,实验结合正、逆训练过程的交叉熵损失进行梯度下降优化参数直至最优,将训练好的初始模型微调后,应用于只有少量样本的新类的预测中。

图2 元训练过程的算法流程图Fig.2 Algorithm flow chart of meta-training process
2 原理及方法
模型在训练过程中采用元学习的算法,测试集与训练集类别互不相交,训练与测试都区分支持集和查询集,均是由支持集训练—查询集测试的训练模式,并且在训练过程中融合原型对齐的算法来校对支持集的原型,从而取得更好的分割效果。
2.1 小样本学习
小样本学习(few shot learning,FSL)的目标是开发一个分类器,它能够将很少的样本推广到新的类(例如最常见的一次使用1 个或5 个样本),特别是基于度量学习的方法,在推理过程中可以直接推断出不可见类的标签,具备泛化能力,目前较前沿的如Vinyals 等人(2016)提出的匹配网络(matching network)和Snell 等人(2017)提出的原型网络(prototypical network),两种方法都是利用深度神经网络将支持集和查询集映射到嵌入空间中,然后利用非参数方法对查询集进行类预测,区别在于表示类的方式不同。本文利用原型思想的同时还使用原型对齐的方法来增强对支持集的学习能力,这样能够更好地利用支持集的信息,提高模型的泛化能力。
2.2 元学习
元学习(meta-learning)的方法不仅在目标任务上训练模型,并且从许多不同的任务中学习元知识,当一个新的任务到来时,利用元知识调整模型参数,使模型能够快速收敛。用一部分类作为训练集Dtrain,不相交的另一部分类作为测试集Dtest,以此来检验元学习者的泛化能力,Dtrain和Dtest都包含支持集S和查询集Q。
支持集训练—查询集验证,在元训练过程中校对分割效果,元学习主要是学习这种“学习分割”的能力,主要用于分割新类,即使是没有学习过的样本,也依然可以在只学习很少的样本后做出对应的分割。
元学习主张跨任务学习,然后适应新任务。其目的是在任务级别上学习而不是在某类样本上学习,为了学习到任务未知的系统能力而不是学出特定于任务的模型。元学习是一种高级的跨任务学习算法,而不是特定的小样本学习(FSL)模型。任务型训练模式如图3所示。

图3 任务型训练模式图Fig.3 Task-based training pattern diagram
元学习分为元训练(meta-training)和元测试(meta-testing),这两个阶段都有支持集和查询集,但是彼此的标签空间是不相交的,元学习示意图如图4所示。

图4 元学习示意图Fig.4 Meta-learning diagram
2.3 N-way K-shot
元学习过程中的跨任务学习通常会被分成N-wayK-shot 问题,每个任务由N-wayK-shot 的数据模式组成,这里的N指的是元测试的过程中要测试的类别数,K指的是元测试的过程中每一类中有标签的样本数。常见的是1-way 1-shot和1-way 5-shot。N-wayK-shot示意图如图5所示。

图5 N-way K-shot示意图Fig.5 N-way K-shot diagram
3 原型对齐
3.1 原型学习
训练集Dtrain与测试集Dtest都包含支持集S与查询集Q,且训练集与测试集的类别是不相交的,表示为和Ntest分别表示训练和测试的集数,每个(Si,Qi)记为1 个episode,相当于1 个mini-batch,1 个episode 包含1 个N-wayK-shot的分割任务,对于每个测试集Dtest,在给定支持集Si的情况下,在查询集Qi上评估分割模型。
原型学习就是对支持集与查询集通过网络后得到的特征,进行平均池化,得到每一类的原型,由一个原型来代表一个类。
计算它们的特征嵌入的中心,作为每一类样本的原型(prototype),接着基于这些原型,使得新的样本X通过计算自身的嵌入特征与这些原型的距离来实现最终的分割。类原型示意图如图6所示。

图6 类原型示意图Fig.6 Schematic diagram of class prototype
3.2 非参数度量学习
分割可以看做是在每个空间位置上的分类,计算每个空间位置上的查询特征向量与每个原型之间的距离,然后再在此距离上应用一个softmax 函数来产生一个分割的概率映射(包括背景),具体来说,给定一个距离函数d,求得原型P={Pc|c∈Ci}∪{Pbg}和查询集特征Fq之间的距离,对于每一个pj∈P,j表示某个类别,概率映射计算为
预测的分割掩码具体计算为
得出分割的概率映射后,计算分割损失Lseg,具体为
式中,Mq表示查询集的每个空间位置的点的地面真实分割掩码表示每个空间位置的点所对应的概率映射,N为所有空间位置的点的总数,通过对上述Lseg进行优化,为每个类得出最合适的原型,从而求得好的分割结果。
3.3 原型对齐算法(PAR)
直观地说,如果模型可以使用从支持集中提取的原型预测出查询集的良好分割掩码,那么基于预测出的掩码从查询集中学习到的原型也应该能够很好地分割支持集的数据。因此,原型对齐算法(prototype alignment algorithm,PAR)鼓励训练所得到的分割模型逆向进行小样本分割。原型对齐算法流程如图7 所示。其中,GT 为ground truth,Mask 为分割后的查询集特征掩码,L为损失函数,首先将支持集和查询集映射到嵌入特征中,并学习每个类的原型,然后通过将查询集的特征匹配到嵌入空间中最近的原型来对查询集进行分割。
原型对齐算法是对上述训练过程进行逆训练,即将查询集特征和所预测的分割掩码作为新的“支持集”,学习其原型并分割原支持集数据,使得模型能够更好地学习支持集的信息,注意,这里所有的支持集和查询集数据都来自训练集Dtrain。算法能够从支持集中提取鲁棒的原型,并使用非参数度量距离的方法来执行分割。
式中,Fs表示支持集特征。
原型对齐损失LPAR的计算式为
式中,Ms表示支持集的每个空间位置的点的地面真实分割掩码表示每个空间位置的点所对应的概率映射,模型总损失是L=βLseg+λLPAR,λ=0简化为没有PAR 的模型,在本实验中,多次调试后,最终β=0.7,λ=0.3。
4 实 验
4.1 实验配置
实验环境为Windows 10 操作系统,PyCharm 软件开发平台,Python 3.9 编程语言,TensorFlow 编程框架,GPU 为NVIDIA GeForce RTX 6000,内存为24 GB。
4.2 数据集
实验采用基准数据集S3DIS(Stanford largescale 3D indoor spaces dataset)(Armeni 等,2017)和ScanNe(tDai 等,2017),先在S3DIS 数据集上训练初始模型,然后在ScanNet 数据集上检验模型泛化能力,最终应用到自己采集并标注的闽南古建筑的点云数据集上进行实践应用。评价指标为平均交并比(mean intersection over union,mIoU),这是目前语义分割应用较多的标准度量。
4.2.1 S3DIS和ScanNet数据集
S3DIS 数据集共有6 个大的Area 场景,271 个小场景,包含会议室、走廊和办公室等,共13 个类别,每个小场景的点云由几万个点组成,每个点包含9个维度(x,y,z,r,g,b,xˉ,yˉ,zˉ),数据太大不能直接送入网络训练和测试,因此在采样前先将S3DIS 数据集按照房间信息裁剪成单个完整的房间以供后续处理,然后将房间沿着x轴和y轴进行1 m × 1 m 的分块。ScanNet 数据集共有1 513 个采集场景数据,其中1 201 个场景用于训练,312 个场景用于测试,共21 个类别,每个场景中点数不等,且场景的点云都较为稀疏,而点云的稀疏与密集会影响类别特征的提取,因此切块尺寸调整为4 m × 4 m,避免裁剪过程中缺失类别的整体形状,比如桌子只裁出一个角,所以采用重叠裁剪再进行随机2 048采样。
4.2.2 闽南古建筑数据集
闽南古建筑数据集由泉州装备制造研究所采集提供,福建有很多古旧建筑,将3D 激光相机所扫描的点云数据加以利用研究,有助于古建筑复原或改造等工作。实验中用到两个大场景,鸿兰堂和庙上村,如图8所示,鸿兰堂共18 555 099个点,庙上村共16 303 272 个点,由于室外场景太大且点云密集,因此在训练与测试时切分为几个小场景来实验。

图8 闽南古建筑数据集场景图Fig.8 Scene map of the Minnan ancient buildings dataset
4.3 骨干网络
DGCNN(Phan 等,2018;Wang 等,2019b)提出了边缘卷积(EdgeConv),得到描述点与其邻域点之间的边缘特征,显式地构造了一个局部图并学习边的嵌入,DGCNN 的每一层采样根据距离度量的方式来动态地选择节点的近邻,通过动态更新采样层之间的图结构来更好地学习点集的语义信息,对于点云信息能够有较充分的学习。设点云中有n个点,每个点由x表示,x=x1,…,xn,使用K最近邻算法(K-nearest neighbor,KNN)将x构造为图G=(V,E),其中V=(1,…,n),E∈V×V,设 点xi与xj之间的边缘特征为eij,eij=h(xi,xj),其中,h为特征提取函数。
计算点xi与其邻接点xj的边缘特征eij,eij一般来说是多维的,将与xi相邻的k个点的边缘信息综合后更新xi的特征(k=20),其余点均按照此方法更新自己的特征值,用xi与其邻域点xj的边缘特征eij对样本自身进行更新,然后送入卷积层提取特征的过程称为EdgeConv,如图9所示。

图9 边缘卷积示意图Fig.9 Schematic diagram of edge convolution
DGCNN 采 用h(xi,xj)=h(xi,xj-xi)作为边缘特征提取函数,既考虑全局特征也考虑局部特征。为了避免小样本训练时易导致的过拟合,同时保证能充分学习到点云信息,故采用2 个EdgeConv 层与6 个MLP 交叉构造DGCNN 网络,作为本实验的特征提取器,骨干网络结构如图10 所示,其中ED(Edistance)代表点之间的距离。
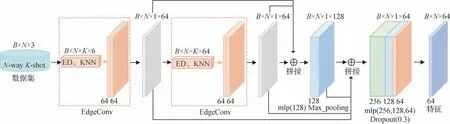
图10 骨干网络结构Fig.10 Backbone network structure
4.4 实验结果与分析
4.4.1 1-way 5-shot和2-way 2-shot点云分割
分割1-way,提出的方法与原型网络在S3DIS 数据集(Armeni 等,2017)上比较,切块大小为1 m ×1 m,结果如表1所示。由表1可知,综合所有类别的分割结果,本文方法的分割mIoU 相比原型网络平均提高了0.06,分割floor 时mIoU 最高,达到了0.95;分割table 时mIoU 达到0.92;分割wall 时mIoU 达到0.73,最高提高了0.12,最低提高了0.04。mIoU 相比匹配网络平均提高了0.33,匹配网络因为是将类别的所有样本作为该类特征,运行过程中产生的数据较大,且每个点云的特征值都需要与分割出的特征值进行近邻加权,所以运算耗时久,且不能很好地反映类别的根本性特征,分割准确性与泛化性较差,因此分割2-way时不考虑匹配网络。

表1 1-way 5-shot和2-way 2-shot分割结果Table 1 Segmentation results of 1-way 5-shot and 2-way 2-shot
图11 为1-way 5-shot 分割结果对比图。由图11可知,针对单一类别的小样本点云分割,模型学习不同类别的难易程度不同,因此分割结果不同,提出的方法在每块点云的学习上,注重颗粒度的同时关注了整体结构,运用原型对齐后使得学习效果提高,很好地辨识了类别特征,应用于点云场景的泛化能力与分割准确性有所提高。
分割2-way,因为匹配网络效果太差,考虑与原型网络对比,图12 从3 个侧重点(整体(ceiling 和floor)、地板(floor)、天花板(ceiling))分别展示了模型分割效果,且由表1 可知,方法比原型网络对于其他类别的抗干扰能力强,mIoU 相比原型网络提高了0.03。本文方法在学习并分割多个类别时,互相校对各自类别的整体结构,使得分割准确度更高,尤其在平面结构上更为凸显。

图12 2-way 2-shot分割结果对比图Fig.12 Segmentation result comparison diagram of 2-way 2-shot
4.4.2 特征提取器对比评估
在S3DIS 数据集(Armeni 等,2017)上对比两个特征提取器的学习能力,结果如表2 和图13 所示。可以看出,DGCNN(Phan 等,2018;Wang 等,2019b)作为特征提取器的分割效果较好,分割ceiling 和floor的mIoU相比于PointNet++(Qi等,2017b)分别提高了0.05和0.30。PointNet++虽然有考虑局部邻域信息和整体特征,但同样1 m × 1 m 切块后随机采样2 048 个点时样本特征提取不足,分割效果极差,改为采样4 096 后才勉强有分割效果。但是DGCNN中提出的EdgeConv,能够得到描述点与其邻域点之间的边缘特征,且每一层采样根据距离度量的方式动态地选择节点的近邻,可以更好地学习点集的语义信息。本文的特征提取器在DGCNN 的基础上进行优化调整后效果显著。
4.4.3 ScanNet数据集的1-way 5-shot点云分割
ScanNet数据集(Dai等,2017)中,场景点云较为稀疏,点云的疏密程度会影响类别特征的提取,因此切块大小调整为4 m × 4 m,避免裁剪过程中缺失类别的整体特征,且采用重叠裁剪再进行随机 2 048采样,1-way 5-shot 分割结果如表3 和图14 所示,分割mIoU平均在0.63左右。

图14 ScanNet数据集分割结果Fig.14 The segmentation result of ScanNet dataset
实验结果表明,模型确实具备很好的泛化能力,在点云数量特别稀疏的情况下,依然可以在仅学习少量样本后的基础上分割出新类,分割不同类别时因其学习的难易程度不同,使得分割效果不同,比如桌子和椅子较难区分,而沙发与地面较易区分,这也是小样本分割一直需要努力攻克的难点:在面对难区分的类别时,仅用少量样本学习特征如何取得准确度更高的分割效果。本文方法在此挑战下做的努力便是采用原型对齐算法,在支持集的特征提取过程中进行回溯校对以获取更好的支持集信息来分割查询集点云。
4.4.4 闽南古建筑数据集的1-way 5-shot点云分割将模型应用在室外的闽南古建筑数据集上,验证模型的泛化能力,点云场景很大且点集的信息密集,因此选用5 m × 5 m 的块来切分大场景,切分为如图15 的几个场景做测试,并且每一块切分后的小场景再随机采样2 048 个点作为微调样本,1-way 5-shot分割结果如表4所示,分割mIoU在0.51左右,通过少量样本分割出了新类,虽然是自己采集的数据且人为标注,但模型依然能很好地分割出房屋与地面的区别,证明本文方法不仅可以分割出室内场景点云,而且在元训练阶段测试室外场景的新类时,取得了一定的分割效果。

表4 闽南古建筑数据集分割结果Table 4 The segmentation result of Minnan ancient buildings

图15 闽南古建筑数据集分割结果Fig.15 The segmentation result of Minnan ancient buildings dataset
5 结论
针对点云分割需要大量监督信息所造成的时间成本高、计算效率低的问题,提出采用融合原型对齐的小样本元学习算法来对点云进行语义分割。本文能够在仅学习少量新类样本的情况下分割出该新类,不仅可以减少实验对监督信息的需求,而且在元训练阶段融合原型对齐算法可以更好地学习支持集的信息,从而得到一个具有很好的泛化能力的初始模型,在元测试阶段用少量样本进行微调后对查询集进行分割预测,能够提高元学习者的泛化能力与分割准确性。
实验通过与原型网络和匹配网络在S3DIS 数据集上的1-way 和2-way 的分割结果对比可知,本文方法可以显著提高对点云的分割准确性以及对新类分割的泛化性,且对于分割多个类别时,抗干扰性很强。实验分别将DGCNN 与PointNet++作为特征提取器时的分割结果进行对比,可知结合边缘卷积的DGCNN 能够更好地学习点云的全局特征和局部几何结构。实验通过将模型应用在ScanNet 数据集和室外的闽南古建筑数据集上进行分割,分割结果显示,本文方法在对新类的学习上具有很好的泛化能力。然而,实验结果中也存在某些类别的分割精度较低的现象,经过分析总结出两个原因:1)新类别的特征差异较大时,微调的模型没能学好其特征;2)方法未能对微调的支持集样本的均衡问题进行优化。
综上所述,下一步研究工作的重点是:1)更好地筛选出具有多样性和强表达能力的微调样本,改善微调样本不均衡情况下模型的学习能力,以适应对新类的学习;2)采用注意力机制有选择地学习新类特征,进一步提升分割精度和泛化能力;3)从稀疏度上对采样点进行改进,在设备及实验平台满足需求的情况下,尝试将完整空间场景投入训练与测试,检验模型对空间几何的整体分割能力。
致 谢:此次点云的闽南古建筑数据集获取得到了福建省泉州市晋江市中国科学院海西研究院泉州装备制造研究所遥感信息工程实验室的帮助,在此表示感谢。
猜你喜欢
小资CHIC!ELEGANCE(2021年45期)2021-01-11
电子制作(2018年19期)2018-11-14
英美文学研究论丛(2018年2期)2018-08-27
自动化学报(2017年11期)2017-04-04
剑南文学(2016年14期)2016-08-22
新校长(2016年8期)2016-01-10
人间(2015年20期)2016-01-04
噪声与振动控制(2015年4期)2015-01-01
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
