
正交约束多头自注意力的场景文本识别
2023-12-23 10:14徐仕成朱子奇
中国图象图形学报 2023年12期
徐仕成,朱子奇
武汉科技大学计算机科学与技术学院,武汉 430065
0 引言
场景文本识别(scene text recognition,STR)是从自然场景图像中识别文本信息的广受欢迎的计算机视觉研究任务,在许多任务和应用中都具有重要的意义和价值,例如图像搜索(Tsai 等,2011)、机器人导航(Schulz 等,2015)、车牌识别(Wang 等,2017)和自动驾驶(Bojarski 等,2016)等。然而,自然场景中的图像充满了多样性(Zhang 等,2019),如透视、弯曲和旋转等,尤其是任意形状或严重扭曲的文本图像在场景文本识别任务中仍然具有挑战性(Luo 等,2019;Shi等,2019;Luo等,2020)。
大多数早期的STR 模型都适合Baek 等人(2019)提出的四阶段STR 框架,通常包括4 个阶段:图像预处理阶段、特征提取阶段、序列建模阶段和预测转录阶段(刘崇宇 等,2021)。如ASTER(attentional scene text recognizer)(Shi 等,2019)、SAFL(self-attention based scene text recognizer with focal loss)(Tran 等,2020)和MORAN(multi-object rectified attention network)(Luo等,2019)等场景文本识别器,它们通常由一个矫正网络和一个文本识别网络组成。STR 模型受到Transformer(Vaswani 等,2017)架构的启发,如HGA-STR(holistic representation guided attention network for scene text recognition)(Yang 等,2020)、Hamming OCR(optical character recognition)(Li 等,2020)、NRTR(no-recurrence sequence-to-sequence text recognizer)(Sheng等,2019)和SATRN(self-attention text recognition network)(Lee等,2020)等场景文本识别网络。HGA-STR 和Hamming OCR 使用基于卷积神经网络(convolutional neural network,CNN)的编码器和Transformer 的解码器共同构成场景文本识别网络,NRTR 和SATRN 使用一个定制的CNN 模块来提取图像特征,用于Transformer 编码器—解码器的文本识别。这些早期方法和近期基于Transformer架构的STR模型通常会带来复杂的模型结构以及较大的计算负载和内存消耗。
在STR 的大量工作中,关注的重点是识别的准确性,几乎没有强调速度和计算效率,而这些问题对于资源有限的移动机器来说同等重要,Atienza(2021)利用ViT(vision Transformer)(Dosovitskiy 等,2021)的简单性和效率,提出了一个简单的单阶段的模型结构ViTSTR(ViT-based STR),能够在精度与速度、内存和计算负载的前沿,表明最佳的权衡。然而,如果不使用专门针对STR 的数据增强,ViTSTR在准确性方面仍然有较大提升空间,导致准确性不足的一个原因就是,在ViT中简单地使用多头自注意力无法保证不同的注意力头能够捕捉到更具差异性的特征,特别是复杂场景文本图像中的多样性特征。
针对上述问题,本文基于ViTSTR研究了正交约束在ViT中的应用,针对ViT中的多头自注意力机制提出了一种新颖的正交约束,并在场景文本识别任务上证明了所提出的正交约束的有效性。与已有的多头注意力中的正交约束和正则化研究不同,本文所提出的正交约束强调“自”注意力。“自”注意力的“自”体现在输入序列的3 种特征Q(query)、K(key)和V(value)内进行注意力运算,即体现的是在“自”身的3种特征上进行注意力操作。
具体来说,本文所提出的正交约束由两部分组成,1)针对不同自注意力头中Q、K和V特征的正交约束;2)针对不同自注意力头中Q、K和V线性变换权重的正交约束。Q、K和V作为注意力头的输入特征,在自注意力机制中扮演重要角色。不同注意力头上的特征正交,可以显式增强多个注意力头特征之间的差异性。针对Q、K和V特征的正交约束可以使不同的自注意力头关注到不同的查询子空间、键子空间和值子空间的特征,这将显式地使不同的自注意力头捕捉到更具差异的特征,并引导ViT 模型在极具多样性的场景文本识别任务中获得更高的性能。更进一步地对不同自注意力头上Q、K和V特征的线性变换权重添加正交约束,为Q、K和V特征的学习过程中权重空间的探索提供正交权重空间的解决方案,这将在网络训练中带来隐式正则化的效果,并更加充分地利用多头自注意力的特征空间和权重空间。在场景文本识别任务上的广泛实验表明,本文所提出的即插即用的特征正交约束和权重正交约束可以在单独使用时产生改进,也可以在组合使用时产生更进一步的改进。
1 相关工作
为了平衡准确性、速度和计算效率,利用ViT 的简单性和效率,一个单阶段且快速有效的场景文本识别模型ViTSTR 被提出。ViTSTR 首先将输入的图像分割成图像块,然后将图像块的线性嵌入序列作为Transformer 编码器的输入,一个可学习的图像块嵌入和每个嵌入的位置编码一起被添加。该网络被训练成端到端以预测一串字符。ViTSTR 的模型结构和ViT 一样,只使用了Transformer 的编码器,它们的唯一区别是预测头。本文工作是在ViTSTR 的基础上进行的。
Li 等人(2018)引入了分歧正则化,以明确地增强多个注意力头之间的多样性,并在多个翻译任务(Bahdanau 等,2016;Szegedy 等,2015)上证明了所提方法的有效性。具体来说,包括3 种类型的分歧正则化,分别促进与每个注意力头相关的子空间、所关注的位置和输出表示与其他头不同。本文工作同样是促进不同注意力头之间的多样性,不同的是本文针对多头自注意力模块的输入特征Q、K和V引入了正交约束,促进不同的自注意力头能够关注不同的查询子空间、键子空间和值子空间。
Lee 等人(2019)提出了一种正交约束的多头注意力机制,所提出的正则化技术能够提高关键词发现任务(Shan 等,2018;He 等,2017)中的检测性能。具体来说,所提出的正则化是由注意头之间的上下文约束和分数向量约束得到的,它们各自是正交的,惩罚了注意头之间的位置和上下文非正交性,促进从不同的子序列输出不同的表示,这与本文所做的工作是不同的。
Zhang 等人(2021)填补了Transformer 中正交约束研究的空白,并在多个机器翻译任务(Bahdanau等,2016;Szegedy 等,2015)和对话生成任务(Li 等,2017;Zhang 等,2018)上证明了在Transformer 中使用正交性约束的有效性。具体来说,所提出的正交约束用于自我注意和位置前馈网络中的线性变换以及自我注意中的亲和矩阵。从线性变换的边界Lipschitz常数的角度出发,提出了自我注意和位置前馈网络中的线性变换的正交约束,以实现训练中的数值稳定性。根据亲和矩阵的有界扰动理论提出了自我注意中的亲和矩阵的正交约束。本文所提出的正交约束中的权重正交约束和Zhang 等人(2021)提出的线性变换的正交约束类似,不同的是本文只对自注意力的线性变换权重添加正交约束。
正交权重已在递归神经网络(recurrent neural network,RNN)(Dorobantu 等,2016;Mhammedi 等,2017;Vorontsov 等,2017;Arjovsky 等,2016)中得到广泛探索,以帮助避免梯度消失和爆炸问题(Dorobantu等,2016)。在CNN中,正交权重也被认为可以稳定激活的逐层分布(Rodríguez 等,2017)并使优化更有效。Huang 等人(2018)证明了矩形正交矩阵可以稳定网络激活的分布并正则化前馈神经网络(feed-forward neural network,FNN)。Bansal 等 人(2018)证明了在深度CNN 中使用权重正交正则化会带来显著的精度提升。Xie 等人(2017)表明了在正交性的约束下,学习权重的相关性被迫进入一致且相对较低的水平,并证明了正交约束的有效性。这些工作进一步引导本文探索权重的正交约束及其在基于ViT 的场景文本识别模型中的应用。本文的主要工作集中在将正交约束用于基于ViT 的场景文本识别模型中的多头自注意力机制。
2 本文方法
多头自注意力机制允许模型共同关注来自不同位置的不同表示子空间的信息。为了进一步保证多样性,本文提出了两种新颖的正交约束,来显式促进不同的头关注不同的子空间信息。具体来说,本文提出的正交约束包括两部分,1)针对不同自注意力头中Q、K和V特征的正交约束;2)针对不同自注意力头中Q、K和V线性变换权重的正交约束。特征正交约束和权重正交约束可以在单独使用时产生改进,也可以在组合使用时产生更进一步的改进。
2.1 多头自注意力
在ViT 模型中,将输入序列投影为查询矩阵Q、键矩阵K和值矩阵V,它们是输入序列投影得到的不同的特征表示,自注意力机制则是将Q和一组KV对映射到输出,然后计算Q与K之间的相似性作为注意力权重,并将注意力权重作用在V上,得到自注意力机制的输出。在ViT 中通常使用多头自注意力作为一个单头自注意力的扩展。在多头自注意力中,在每个头上单独计算自注意力,然后将每个头上的自注意力输出进行拼接,并将拼接结果做线性变换,得到与输入序列维度相同的输出作为多头自注意力的输出。这个过程可以表示如下:
对于一个输入序列z∈RN×D,一个标准的QKV(query,key,value)自注意力(self-attention,SA)(Vaswani等,2017)的计算方式可表示为
多头自注意力(multihead self-attention,MSA)是SA的扩展,计算方式为
式中,Umsa∈RD×D,多头自注意力并行地计算每个头上的自注意力,最后投影它们的联合输出。
2.2 基于ViT的STR模型
本文方法是对ViTSTR 的改进,在网络结构上与ViTSTR 相同,仅使用由L个编码器块堆叠的Transformer 编码器。在编码器块内,每个输入首先经过LN(layer normalization)层,然后进入MSA 层,再经过LN 层后进入MLP(multi layer perceptron)层。残差连接置于LN 和MSA/MLP 的输出之间。MLP 层由使用GELU(Gaussian error linear unit)激活函数的两个全连接层组成。
输入图像X∈RH×W×C调整为n个二维特征块图像为H×W,特征块为P×P,C是通道数,n=HW/P2。编码器的输入为
式中,l=1,2,…,L,L是编码器块的个数。
MLP层的输出为
式中,l=1,2,…,L。
最后的预测结果输出是一个线性投影序列,具体为
式中,i=1,2,…,S。S是识别文本的最大长度加上两个标记[GO]和[s]。
2.3 Q、K和V特征的正交约束
多头自注意力机制允许模型的不同表示子空间联合关注不同位置的信息(Vaswani 等,2017)。然而,没有机制可以保证不同的注意力头确实捕捉到不同的特征。不同注意力头上的特征正交,可以显式增强多个注意力头之间的差异性。Q、K和V作为注意力头的输入特征,在自注意力机制中扮演重要角色。这些因素引导本文提出了针对Q、K和V特征的正交约束,强制的正交约束可以使多头自注意力机制关注到不同的查询子空间、键子空间和值子空间,关注到不同子空间信息可以显式地使不同的注意力头捕获到更具差异的特征。
对于一组输入序列有Z∈RB×N×D,B代表batch size的值,即一组输入的样本个数。有
ViT 中的Transformer 编码器由L个编码器块组成,本文对L个编码器块内的多头自注意力模块都计算特征正交约束,并将计算结果进行累加,作为最终的特征正交约束,FQ作为正则项添加在损失函数后面。
遵循同样的方式,对特征K和V的正交约束FK和FV,计算为
FQ、FK和FV可以分别反映出不同自注意力头之间查询子空间、键子空间和值子空间特征的正交性,式(10)—(12)中减去单位矩阵I是为了消除同一个自注意力头和自己的特征是重叠的影响。
FK和FV也同样作为正则项添加到损失函数后面,FQ、FK和FV共同构成特征正交约束的正则项。
2.4 Q、K和V权重的正交约束
将正交性引入权重空间同样具有重要意义,这不仅可以为Q、K和V特征的学习过程中权重空间的探索提供正交权重空间的解决方案,并在网络训练中带来隐式正则化的效果,也将更加充分地利用多头自注意力的特征空间和权重空间。因此,本文对Q、K和V特征的线性变换权重矩阵添加正交约束。以Q为例,使Q在不同自注意力头上的权重矩阵正交,这将为不同自注意力头上Q的权重学习探索正交投影空间。
用Uq、Uk和Uv分别表示Q、K和V特征的线性变换权重矩阵,即
式中,Uq、Uk、Uv∈RD×D。在多头自注意力中,把权重矩阵分配到不同的自注意力头上,以Uq为例,可以表示为
式中,I∈Rh×h是一个单位矩阵。
与FQ一样,本文对L个编码器块内的多头自注意力模块都计算权重正交约束,并将计算结果进行累加,作为最终的权重正交约束,LQ作为正则项添加在损失函数后面。
遵循同样的方式,对K和V的权重矩阵的正交约束,计算为
LQ、LK和LV可以分别反映出不同自注意力头之间查询权重子空间、键权重子空间和值权重子空间的正交性,式(16)—(18)中减去单位矩阵I是为了消除同一个自注意力头和自己的权重空间是重叠的影响。
LK和LV也同样作为正则项添加到损失函数后面,LQ、LK和LV共同构成权重正交约束的正则项。
最终的损失项可以表示为
式中,LCE表示交叉熵损失,是ViTSTR 中使用的损失,本文提出的正交约束作为正则项加在交叉熵损失后面。Foc表示特征的正交约束,Loc表示线性变换权重的正交约束。α,β,λ1,λ2,λ3,μ1,μ2,μ3为惩罚因子,是控制相应正则项的超参数。
3 实 验
3.1 数据集介绍
Baek 等人(2019)为大多数现有的STR 方法引入了一个统一的框架,以及一致的数据集以便进行公平比较,本文也使用相同的数据集来进行训练和评估。
3.1.1 训练集
为大量真实的场景文本图像添加标记以用于STR 模型的训练有着非常高的成本,因此,大多数STR 模型都使用合成数据集作为真实数据的替代来进行训练,下面首先介绍STR 论文中两个流行的合成数据集。
MJ(MJSynth)(Jaderberg 等,2014)是一个包含8.9 M幅图像,用于场景文本识别的合成数据集。
ST(SynthText)(Gupta等,2016)是另一个流行的合成数据集,它包含5.5 M 幅裁剪图像以用于场景文本识别。
按照Baek 等人(2019)的建议,本文采用了与Atienza(2021)相同的做法,在综合训练集MJ+ST 上训练,在训练时,每个batch 的训练集将有50%的图像来自MJ,50%的图像来自ST。图1 显示了训练集MJ和ST中的部分图像。

图1 合成数据集中的部分图像Fig.1 Samples from datasets with synthetic images((a)MJ;(b)ST)
3.1.2 测试集
7 个主要的真实自然场景下的STR 数据集已广泛用于评估STR模型,这些数据集可以分为两类:规则数据集和不规则数据集。规则数据集包含水平排列的字符的文本图像,通常有着较小的弯曲度和形变量;不规则数据集则包含大量弯曲、垂直、透视和模糊以及严重变形的文本。
1)规则数据集。IIIT(IIIT5K-words)(Mishra等,2012)包含3 000幅用于测试的图像,这些图像是从谷歌图像搜索中抓取的数据集,大多来自街道场景,如招牌、广告牌、路标、海报等。
SVT(street view text)(Wang等,2011)包含647幅用于测试的图像,这些图像收集自户外街道图像,有些是模糊或低分辨率的。
IC03(ICDAR2003)(Lucas等,2005)包含 1 110幅用于ICDAR2003 鲁棒阅读竞赛的图像,这些图像是从自然场景中采集的。在去除长度小于3 个字符的单词后,剩下867 幅图像。该数据集还有一个包含860幅图像的版本。
IC13(ICDAR2013)(Karatzas 等,2013)是IC03的扩展,继承了IC03 的大部分图像,是为ICDAR2013 鲁棒阅读竞赛而创建的,包含1 015 幅图像。该数据集还包含另一个857 幅图像的版本。
2)不规则数据集。IC15(ICDAR2015)(Karatzas等,2015)是为ICDAR2015 鲁棒阅读竞赛而创建的,包含2 077 幅图像,这些图像是由谷歌眼镜(Google Glasses)在佩戴者的自然运动状态下拍摄的,包含很多模糊、旋转和低分辨率的图像。同样,该数据集也有另一个1 811 幅图像的版本(Bai 等,2018;Cheng等,2017)。
SVTP(SVT perspective)(Phan 等,2013)包含了645 幅从谷歌街景中收集的图像,大多是在非正面视角下拍摄的带透视投影的图像。
CT(CUTE80)(Risnumawan等,2014)包含288幅从自然场景中收集的文本图像,其中大多是弯曲的弧形文本图像。
图2 显示了7 个测试集中的部分图像。图2(a)第1—4 行分别来自规则数据集IIIT、SVT、IC03 和IC13;图2(b)第1—3 行分别来自不规则数据集IC15、SVTP和CT。

图2 真实场景数据集中的部分规则和不规则图像Fig.2 Examples of regular and irregular real-world datasets((a)regular datasets;(b)irregular datasets)
3.2 实验设置
为了快速验证本文方法的有效性,首先在ViTSTR-Tiny(Atienza,2021)的基础上进行实验,表1列出了本文推荐的训练配置。
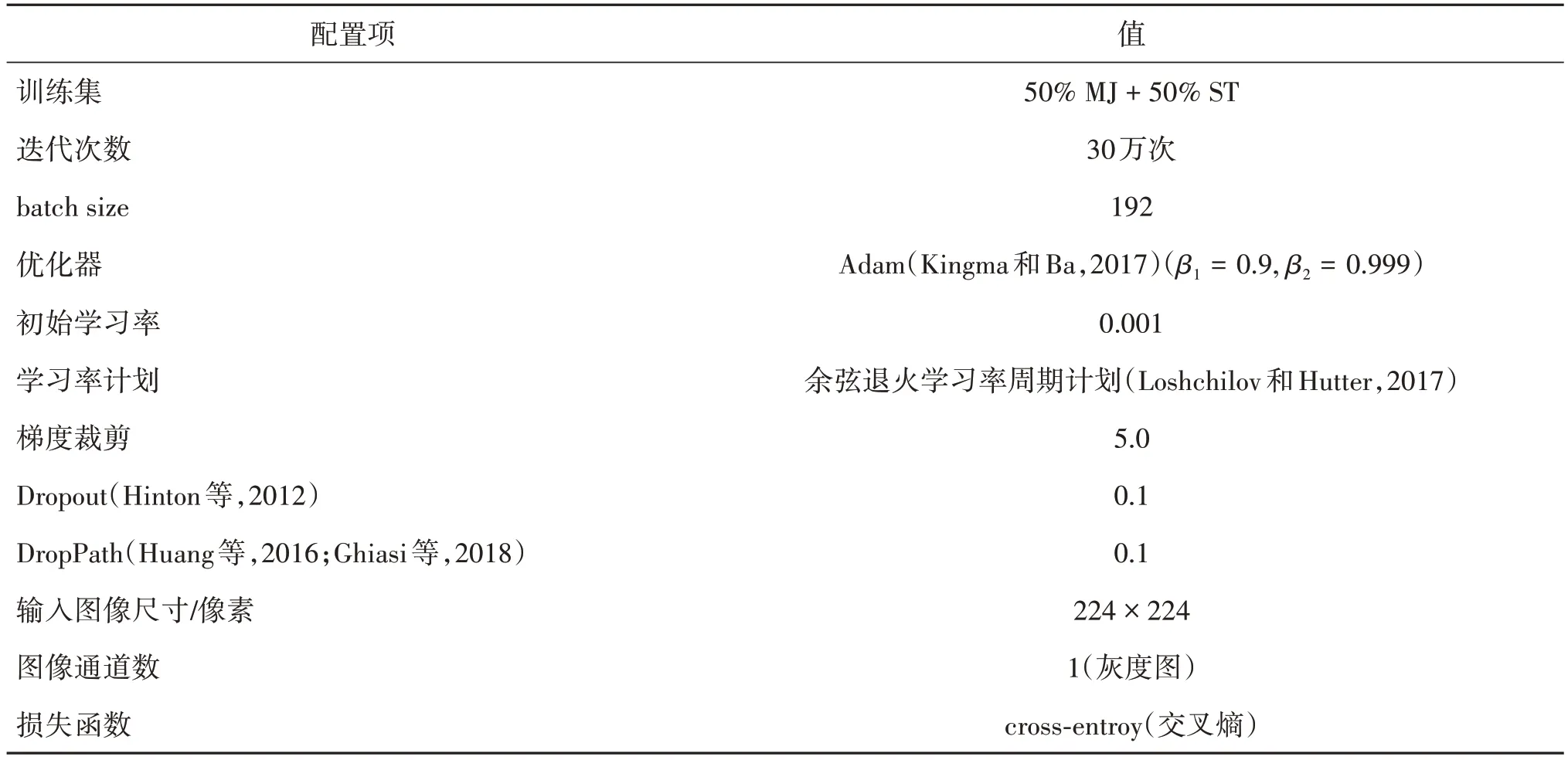
表1 训练配置Table 1 Train conditions
与ViTSTR 相同,使用DeiT(data-efficient image Transformers)(Touvron 等,2021)的预训练权重和He等人(2015)的方法进行初始化,每迭代2 000次后在Baek 等人(2019)提供的验证集上进行验证,以选择在验证集上精度最高的模型用于在测试集上评估,这一点与Atienza(2021)不同,本文和Baek 等人(2019)保持一致。为了区别,在本文的推荐训练配置和评估方案选择上得到的模型命名为XViTSTR。
表2展示了XViTSTR 不同版本的配置和精度对比。其中,精度是指对模型进行端到端训练后,选取在验证集上精度最高的模型,在测试集上测试得到的整体精度。与ViTSTR 一样,本文识别的重点是96 个拉丁字符,在评估前不旋转垂直文本,只对字母和数字进行评估,对于相同的英文字母,不区分大小写。

表2 XViTSTR不同版本的配置和精度对比Table 2 Comparison of the configuration and accuracy of different versions of XViTSTR
3.3 消融研究
表3 展示了添加Foc和Loc在XViTSTR-Tiny 模型上的精度对比结果。
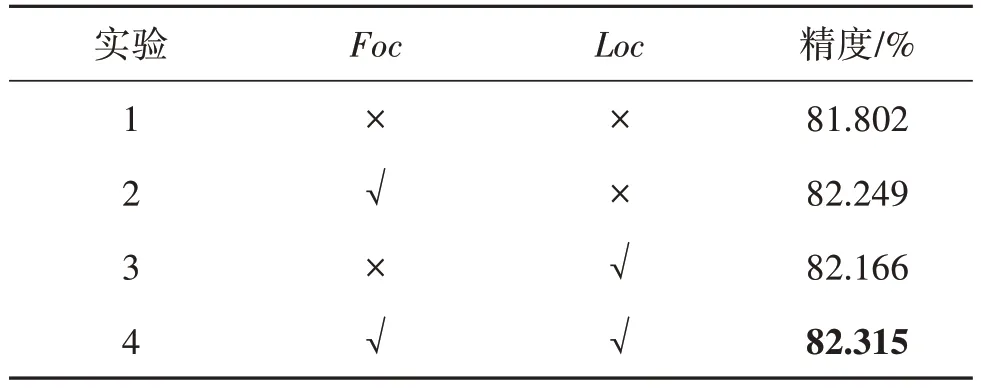
表3 添加Foc和Loc在XViTSTR-Tiny模型上精度对比Table 3 Add Foc and Loc for accuracy comparison on the XViTSTR-Tiny model
为了验证特征正交约束和权重正交约束的有效性,首先对XViTSTR-Tiny 版本按表1 推荐的实验配置进行端到端训练,然后选取在验证集上精度最高的模型在测试集上进行测试,得到在测试集上的整体精度为81.802%,并以此作为本文的基准。如表3中实验1 所示,实验1 仅使用交叉熵作为损失函数,其他实验除在损失函数中添加正交约束项外,都与实验1保持相同的实验条件。
为了验证特征正交约束Foc的有效性,在实验1的基础上,仅在损失函数中添加Foc正交约束项,这时在实验2 中的超参数α和β分别设置为1 和0,λ1,λ2,λ3分别设置为1,2,1,μ1,μ2,μ3均设置为0。
图3 显示了实验1 和实验2 训练过程中不同自注意力头之间Q、K、V特征的正交性的变化对比图。实验中计算了实验1—实验4 中每次迭代时FQ、FK和FV的值,并取每2 000 次迭代时的值。图3 中实验2 的蓝色实线和实验4 的绿色实线在部分区域的变化是重叠的。

图3 不同自注意力头之间Q、K、V特征正交性变化对比图Fig.3 Comparison of the orthogonality changes of Q,K and V features among different self-attention heads((a)comparison of FQ changes;(b)comparison of FK changes;(c)comparison of FV changes)
图3 中FQ、FK、FV的值越趋近于0 就表示不同自注意力头之间对应特征空间的正交性越好。从图3(a)可以看出,在不添加Foc时(实验1),不同自注意力头之间Q特征的正交性在训练过程中整体处于1.0左右,这表明在不添加Foc时不同自注意力头之间的Q特征空间学习的特征存在一定冗余。在添加Foc(实验2)后,从图3(a)中可以看出,强制的正交约束Foc可以使得不同自注意力头之间的Q特征空间的正交性迅速变好,并在整个训练过程中始终保持良好的正交性。从图3(b)(c)中也可以得出相同的结论,这表明本文提出的正交约束Foc能够在训练中发挥作用,使不同的自注意力头能够关注到正交特征子空间,包括正交查询特征子空间、正交键特征子空间和正交值特征子空间。实验2 所得到的模型在测试集上的表现也证明了本文所提出的特征正交约束Foc的有效性,如表3 中的实验2 所示,添加Foc的正交约束后精度相比实验1 提高了0.447%,达到82.249%。
为了验证权重正交约束Loc的有效性,在实验1的基础上,仅在损失函数中添加Loc正交约束项,这时在实验中的超参数α和β分别设置为0 和1,μ1,μ2,μ3分别设置为10,20,10,λ1,λ2,λ3均设置为0。
图4 显示了实验1 和实验3 训练过程中不同自注意力头之间Q,K,V权重的正交性的变化对比图。实验中计算了实验1—实验4 中每次迭代时LQ、LK和LV的值,并取每2 000次迭代时的值。图4中实验3 的红色实线和实验4 的绿色实线在部分区域的变化是重叠的。

图4 不同自注意力头之间Q、K、V权重正交性变化对比图Fig.4 Comparison of orthogonality changes of Q,K and V weights among different self-attention heads((a)comparison of LQ changes;(b)comparison of LK changes;(c)comparison of LV changes)
图4 中LQ,LK,LV的值越趋近于0 就表示不同自注意力头之间对应权重空间的正交性越好。从图4可以看出,在不添加Loc时(实验1),不同自注意力头之间Q、K、V权重的正交性在训练过程中整体趋于稳定。在添加Loc后(实验3),相应的正交性迅速变好,并在之后的训练中能够保持正交性的稳定。这表明本文提出的正交约束Loc能够在训练中发挥作用,使不同的自注意力头能够关注到正交权重子空间,包括正交查询权重子空间、正交键权重子空间和正交值权重子空间。实验3 所得到的模型在测试集上的表现也证明了本文所提出的权重正交约束Loc的有效性,如表3 中的实验3 所示,添加Loc的正交约束后精度相比实验1 提高了0.364%,达到82.166%。
事实上,Foc和Loc不仅在单独使用时能够带来精度的提升,组合使用时也可以带来精度的进一步提升,如实验4 所示,同时添加Foc和Loc时,超参数α和β都设置为0.5,λ1,λ2,λ3分别设置为1,2,1,μ1,μ2,μ3分别设置为10,20,10。从图3 和图4 中实验4 的绿色实线变化都可以看出,这时,FQ,FK,FV和LQ,LK,LV的值都会迅速下降,并在训练过程中始终保持趋近于0,说明这时Foc和Loc同时发挥了作用,使不同的自注意力头之间的Q,K,V特征空间和权重空间都保持正交。
值得关注的是,如图4所示,当只添加Foc时(实验2),会导致LQ,LK,LV整体呈现下降趋势,LQ先增加到一个较大的值,然后稳步下降到接近不添加任何约束时(实验1)LQ的值,LK和LV的值整体比实验1 要小且稳步下降。这表明,当添加特征的正交约束时,会对权重空间的正交性产生一定的影响,并使得相应的正交性整体上保持变好的趋势,特别是LK和LV的变化。
同样值得关注的是,如图3 所示,当只添加Loc(实验3)时,会导致FQ,FK,FV的值相比实验1 在整体上呈现更明显的下降趋势。这表明,当添加权重的正交约束时,会使对应特征空间的正交性也变好,这也可以解释为什么添加权重的正交约束也可产生一定的改进,但产生的改进比直接添加特征的正交约束要小。
总的来说,单独添加Foc或Loc只会使特征空间或权重空间正交,而同时添加则会使特征空间和权重空间都能保持正交。如表3的实验4所示,同时添加Foc和Loc时的精度更高,相比实验1 提高了0.513%,达到82.315%。
图5 显示了由实验1 和实验4 得到的模型对CT数据集中部分图像的注意力可视化图。其中,第1列和第2列是由XViTSTR-Tiny模型得到的注意力图和识别结果,第3 列和第4 列是由XViTSTR-Tiny+Foc+Loc模型得到的注意力图和识别结果。下划线字符是识别错误的字符。从图5可以看出,添加正交约束的模型在注意力区域上相比基准模型关注到了更多的信息,这对识别出正确结果来说是有帮助的。

图5 不同模型对CT数据集中部分图像的注意力可视化Fig.5 Attention visualization of the images in the CT dataset part by different models
3.4 对比实验
本文还在几个流行的基准上与一些先进方法进行了比较,结果显示见表4。可以看到,本文方法相比基准,在规则和不规则数据集上均有提高,在规则数据集IIIT、SVT、IC03(860)上都提升了0.5%,在不规则数据集IC15(1811)和IC15(2077)上分别提升了0.5%和0.6%,在SVTP上提升了0.8%,在CT上提升了1.1%,在所有测试集上的整体精度提升了0.5%。这说明本文方法能够提高多头自注意力机制对不同子空间信息的捕获能力,特别是在特征多样性极强的场景文本识别任务上。表5 展示了流行方法和本文方法在精度、速度、参数量和计算负载上的对比。其中,参数量反映了内存的要求,每秒浮点运算次数(floating point operations per second,FLOPS)估计了处理一幅图像所需的指令数量。可以看出,本文方法在速度和参数量接近或相同的情况下获得了有竞争力的表现。以上实验结果证明了本文方法的有效性。

表4 在公共测试集上不同模型的精度对比Table 4 Accuracy comparison of different models on the public test dataset

表5 在2080Ti GPU上不同模型的精度、速度、参数量和计算负载(FLOPS)对比Table 5 Comparison of accuracy,speed,number of parameters and computational load(FLOPS)of different models on 2080Ti GPU
4 结论
场景文本识别在许多任务和应用中都具有重要意义,使用多头自注意力机制的ViT 模型用于场景文本识别可以实现速度和计算效率的平衡,然而面对多样性极强的场景文本识别任务,多头自注意力机制通常不能保证确实捕获到多样性的特征。本文提出了一种新颖的正交约束来显式增强多头自注意力机制捕获更具多样性的子空间信息。本文所提出的正交约束由两部分组成,即针对不同自注意力头之间Q、K、V特征的正交约束和针对不同自注意力头之间Q、K、V线性变换权重的正交约束。这将显式地使不同的自注意力头能够关注正交的查询子空间、键子空间和值子空间的特征,并为Q、K、V特征的学习提供正交权重空间的探索。实验证明本文所提出的即插即用的正交约束在STR 任务上的有效性,特别是能够提高ViT 模型在不规则文本识别任务上的精度。
本文工作不引入任何新的可学习参数,不影响模型的推理速度和计算效率,因为在推理测试时不需要计算正交约束,但会在训练过程中带来一定的计算消耗,在本文的实验中会带来7 h左右的额外训练时间。另外,本文工作只探索了多头自注意力的输入特征Q、K、V的正交约束,对于多头自注意力中的注意力特征和输出特征等其他特征的正交约束研究仍然是一个开放性的问题。未来的工作包括探索其他形式针对多头自注意力的正交约束,并将这一想法扩展到其他识别和分类任务中。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
加油站服务指南(2021年4期)2021-07-21
当代陕西(2020年17期)2020-10-28
数学年刊A辑(中文版)(2020年1期)2020-05-19
人大建设(2018年5期)2018-08-16
电信科学(2017年6期)2017-07-01
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
人生十六七(2015年6期)2015-02-28
河南科技(2014年15期)2014-02-27
