
方面级多模态协同注意图卷积情感分析模型
2023-12-23 10:14王顺杰蔡国永吕光瑞唐炜博
中国图象图形学报 2023年12期
王顺杰,蔡国永*,吕光瑞,唐炜博
1.桂林电子科技大学计算机与信息安全学院,桂林 541004;2.广西可信软件重点实验室,桂林 541004;3.大连海事大学信息科学技术学院,大连 116026
0 引言
随着社交媒体的不断发展,多模态情感分析日益受到关注。基于方面的多模态情感分析(aspectlevel multimedia sentiment analysis,AMSA)是一种面向实体的细粒度情感分析任务,旨在结合相关的模态数据源确定句子中给定方面指称实体的情感极性。与粗粒度多模态情感分析不同,AMSA 不仅要考虑模态内情感信息单元的潜在关联和模态间的相互对齐,而且要聚焦方面对不同模态情感信息单元的引导。图1 的左侧,文字中对实体“Blake Lively”并没有表达明显的情感,但在对应的图像中,“Blake Lively”的灿烂笑容却呈现了积极的情感,从而决定了对实体“Blake Lively”的情感判断。在图1 的右侧,图像信息并未明显表达情感,但句子中“happy”则明示了对实体“David Wirght”的情感极性。通常多模态数据之间的情感和语义具有一定的协同性,因此挖掘多模态数据之间的协同作用至关重要;特别需要从细粒度的角度聚焦方面引导的文本表征和方面引导的图像表征以及它们之间的情感和语义(下文也简称情感语义或情义)的协同与对齐,然而已有的AMSA 研究对此关注还不够。如对图文表征融合多是粗粒度关联,对方面引导的细粒度局部语义关联也考虑不足(Xu 等,2019;Yu 等,2020),且通常以一种模态为主,另一种模态为辅去建模关联,而对模态之间的协同性关联挖掘不足(Yu 和Jiang,2019)。
图卷积神经网络(graph convolutional network,GCN)基于图结构中的节点以及边关系来挖掘结构或语法等关联信息,不仅强调不同节点的局部表征,还能实现全局特征的传播汇聚。目前,GCN 在推荐系统(葛尧和陈松灿,2020)、目标分割(姚睿 等,2021),尤其在文本情感分析和图像情感分析上得到了较多的应用,其核心在于关联图的构建。将文本转换成文本图的方法主要有构建共现图(Chen 等,2019a;Yang 和Cui,2021)和句法图(Zhang 等,2019;Phan 和Ogunbona,2020)的方法,但是对句法依赖解析可能不准确,尤其是对句法结构不明显的简短句,使得以此方法构建的图来挖掘文本情感语义存在一定的不足。对于图像,研究者主要根据对象的情感值来定义图像中不同对象的情感距离,并基于此距离构建图像的对象关系图(Wu 等,2021;Chen 等,2019b)。然而情感语义具有高度复杂的多样关联,前述基于规则构建的关系图,一经确定在随后的模型学习中是不能更新的,即不能自适应地建模模态数据单元的情感语义关联的重要性,因而其建模尚有不足;而且多模态情感分析不仅要考虑模态内的语义情感关联,还要考虑多模态间的情感语义协同关联。因此,前述基于规则的方法对多模态情感分析任务并不够理想。
基于上述分析,结合最近注意力机制在自适应学习上的成功应用(Fukui 等,2019;Ye 等,2022),本文提出利用自注意力机制生成模态数据单元之间的关联权重,且以模态数据单元的潜在特征为节点,分别构建关联权重图,对基于视觉和文本模态数据所构建出的节点潜在语义关联权重图,下文分别称为视觉语义图和文本语义图。这些潜在语义关联权重的分布是连续且可更新学习的,从而可以自适应地建模模态内数据元素间的情义相关性,包括方面相关的模态内的局部情义关联;其次,提出跨模态协同注意力机制来自适应地挖掘图像和文本之间的局部协同情义关联。最后,采用掩码机制选择并融合两个模态语义图的方面词所在节点的情义表征用于情感分析。总之,本文构建了一个方面级多模态协同注意图卷积情感分析模型(aspect-level multimodal co-attention graph convolutional sentiment analysis model,AMCGC)用于方面级多模态情感分析,它不仅能够同时学习方面相关的模态内部的情感潜在关联和上下文传播,而且能跨层地建模方面引导的不同模态间的上下文细粒度语义关联对齐,增强了模态之间的协同性,从而降低模态间的异构鸿沟。
本文的贡献主要如下:1)提出自适应的语义图生成机制,并使用正交约束来减少模态内数据单元的语义重叠,从而更加精准地表征模态内的情义相关性;2)提出门控的局部跨模态交互机制,双向地将不同模态的图节点情义信息相互嵌入,以此实现细粒度的跨模态情义特征的协同与对齐;3)提出方面特定的掩码设置,增强方面的多模态情义指向性,并引入跨模态损失来学习异质模态的方面节点情义特征的一致性。
1 相关工作
1.1 方面引导的单模态特征学习
关于方面敏感的单模态数据特征学习研究中,Xu 等人(2019)利用注意力机制将单模态特征和方面词特征拼接后生成隐状态表示,并对注意力权值进行归一化,然后对单模态特征进行加权平均得到方面敏感的单模态表示。Gu 等人(2021)基于多头注意力机制实现了方面词引导的单模态特征学习,从而获得方面敏感的单模态特征表示。然而,Xu等人(2019)和Gu 等人(2021)并没有将方面信息融入到单模态上下文特征中,只是用方面特征去引导单模态特征,这会导致方面词语义信息的丢失。随后,Yu 等人(2020)将方面词信息融入单模态特征表示中,但却没有将方面词和单模态内容进行细粒度引导。虽然后来Yu 和Jiang(2019)将方面词和图像内容进行细粒度引导,但是却没有将方面词对文本内容进行细粒度引导,而是将方面词引导后的图像特征来引导文本特征。本文构建的AMCGC 利用自注意力机制和图卷积网络从细粒度的角度实现了单模态的局部语义关联,从而自适应地学习方面引导的单模态特征表示。每一个图节点特征不仅将方面信息融入局部单模态特征表示中,而且方面词所在的节点特征还聚合了各自模态的全局的上下文特征。
1.2 多模态特征融合
在关于多模态特征融合的研究中,Xu 等人(2019)提出多交互记忆(multi-interactive memory network,MIMN)模型,通过多次使用注意力机制学习方面引导的图像表征和文本表征以及它们之间的相互引导,从而实现图像和文本的融合。Yu 等人(2020)提出了一个实体敏感的注意力融合网络(entity-sensitive attention and fusion network,ESAFN),通过使用低秩双线性池化算子将多模态特征融合。但是,这些研究只是从粗粒度的角度实现多模态特征融合,并没有考虑模态中细粒度特征的潜在关联。Gu 等人(2021)提出一个注意力胶囊抽取和多头融合网络(attention capsule extraction and multi-head fusion network,EF-Net),通过使用多头注意力机制来细粒度地实现多模态的交互对齐。Zhou等人(2021)提出一个多模态方面极性预测网络(multimodal aspect polarity prediction,MMAP),通过一个可学习的参数矩阵和偏置参数将图文模态特征表示进行矩阵相乘操作来实现多模态之间的交互。Yu 和Jiang(2019)提出的目标导向的多模态BERT(bidirectional encoder representation from Transformers)模 型(target-oriented multimodal BERT,TomBERT)也从细粒度的角度去探索多模态之间的交互对齐。盛振涛等人(2023)提出了面向多模态的自监督特征融合方法,该方法通过构建多模态负样本空间,利用对抗对比学习能够将多模态特征有效融合。然而这些文献并没有充分探索不同模态的局部内容之间的交互对齐,也没有充分考虑不同模态之间的协同性,甚至会引起方面指向的多模态特征之间产生冗余和干扰噪声。本文通过构建交叉协同的学习机制以实现多模态之间的细粒度对齐与融合,从而增强了多模态特征之间的协同性。
1.3 基于图卷积网络的情感分析
GCN 是一种直接对图进行操作的传统卷积神经网络的变体(Kipf等,2016)。对于图结构的数据,GCN 对相连的节点进行卷积运算去编码局部信息,通过多层GCN 操作,图中的每一个节点都能学习到全局信息。利用图卷积的这种性质,一些方面级情感分析任务的工作(Zhang 等,2019;Sun 等,2019)通过编码依赖树和合并单词之间的依赖路径来建立邻接矩阵,通过图卷积操作来学习词汇之间的情感语义关联。后来一些工作将不同类型的图组合用于方面级文本情感分析任务,比如,Zhang 和Qian(2020)设计了句法图和词共现图,共同学习词汇之间的情感依赖关系。在视觉情感领域,也有采用图结构来捕获对象的情感依赖关系,比如,Wu 等人(2021)通过识别图像中的对象,并使用SentiWordNet(sentiment word wordnet)以及情感规则来构建这些对象的关系矩阵。Chen 等人(2019b)将GCN 与多标签图像识别相结合,基于数据集中标记的对象信息来设计加权策略构造GCN 的关系矩阵。然而以上提到的利用图卷积网络的情感分析工作,所构建的关系矩阵是人工设定的一些情感规则来构建关系矩阵,并不能够自适应地挖掘词汇之间或图像局部区域之间的情感依赖关系。受到注意力机制的启发,本文采用自注意力机制来构建关系矩阵,并正交地约束自注意力机制的学习,以自适应地挖掘抽象的情感语义特征关联。
2 方法描述
AMCGC 模型结构如图2 所示。它通过输入嵌入层(图2(a))来获得不同模态以及方面的嵌入表示,这些表示经过特征抽取层(图2(b))后生成包含方面的文本词的上下文特征以及融入方面的视觉局部上下文特征,然后将不同模态的上下文特征输入跨模态交叉协同注意的对偶图卷积层(图2(c))进行跨模态语义交互。具体地,根据不同模态的上下文特征构建正交约束的自注意力机制分别生成视觉语义图和文本语义图,基于不同模态的语义图,分别利用文本语义图卷积和视觉语义图卷积来挖掘方面指向的模态内的局部上下文关系;而第1 个门控的局部跨模态交互机制(右侧)用于在视觉局部特征的引导下,视觉局部特征和文本局部特征的融合;第2个门控的局部跨模态交互机制(左侧)用于在文本局部特征的引导下,文本语义对齐后的视觉局部特征和文本局部特征的融合,以此来双向地探索图像和文本之间的局部情感语义的协同关联。随后,方面掩码设置层(图2(d))用于(左侧)抽取方面节点的特征,且使用一个跨模态损失来学习异质方面特征的一致性。最后,融合不同模态的方面特征用于情感分类。接下来,将详细阐述AMCGC模型的细节。

图2 方面级多模态协同注意图卷积情感分析模型的框架(Glove词嵌入)Fig.2 Framework of aspect-level multimodal co-attention graph convolutional sentiment analysis model(Glove embedding)((a)input embedding;(b)feature extraction;(c)pairwise graph convolution of cross-modality alternating co-attention;(d)aspect mask setting)
2.1 输入嵌入
给定一个多模态图像—文本对数据集D,每一个样本d∈D都包含一个文本句子s={w1,w2,…,wτ+1,…,wτ+m,…,wn-1,wn} 和方面词a={a1,a2,…,am}以及一个相关的图像I,并且a属于s的子序列,其中τ+1 代表m个方面词在句中开始的位置。如图2 所示,给出一条Twitter 句子“Fifth Harmony’s seats at the @ BBMAs !They are in front of Kelly Rowland and behind Kesha !”和所对应的图像以及方面词“Fifth Harmony”,模型可以预测出“Fifth Harmony”是积极的。不同模态的输入嵌入表示是多模态特征学习的基础,接下来分别介绍文本以及图像的嵌入表示。
本文将分别采用Glove 嵌入(Pennington 等,2014)和BERT 嵌入(Devlin 等,2018)来得到文本的词嵌入表示。对于使用预训练好的Glove 词嵌入矩阵来得到句子及方面词的初始嵌入向量,设初始词嵌入向量用表示,其中dt表示词向量的维度。因为句子中与方面词距离更近的一些词对方面情感的贡献程度更大,因此本文对每个词的初始词嵌入向量添加一个位置嵌入向量。每个词的位置权重qi的计算式为
式中,qi∈R 是第i个词与方面词的间隔距离,将这些位置权重转成数字编码,再通过位置嵌入矩阵得到每个词的位置嵌入向量,其中dp表示位置嵌入维度。通过将该词的位置嵌入向量拼接到该词的初始词嵌入向量得到该词的词嵌入向量其中de=dt+dp。下文中将融入位置信息的文本词嵌入矩阵记为
类似地,可以直接利用预训练好的BERT 来创建文本词向量矩阵。由于BERT 内部含有位置编码,因此不再需要拼接位置向量。为了适应BERT的数据处理方法,将给定的文本和方面词转换为“[CLS] +文本+[ SEP]”和“[CLS] +方面+[ SEP]”的形式。
对于图像,先进行预处理,即将其按中心剪切成尺寸为224 × 224 像素的图像I,并把像素值做归一化处理。然后采用ResNet-152(residual network-152)模型(He 等,2016)来抽取预处理好的图像I的高层语义特征,即V=ResNet(I),并将V划分成K个大小相等的视觉局部区域,即其中,dimg是每个视觉块的维度。
2.2 特征抽取
在获得文本的词嵌入矩阵Ec之后,使用双向长短时记忆网络(bidirectional long short term memory,Bi-LSTM )来生成含有方面词的文本特征的上下文序列表示,具体为
为了挖掘与方面词最相关的图像局部上下文情感语义,使用线性变换将方面特征和图像中不同的局部特征向量映射到同一空间,然后将它们拼接成一个序列向量Ga,具体为
为了明确视觉局部区域与方面词的具体位置,类似视觉Transformer 模型(Kolesnikov 等,2021),本文也随机初始化一个可学习的位置参数矩阵对应融入到Ga的序列特征中,具体为
在获得融入位置信息的序列特征表示Gs之后,类似式(2)—(4)使用Bi-LSTM来获得Gs的融入方面词的视觉局部特征的上下文序列Hg=其中表示视觉特征学习后的第i个局部区域或方面特征隐状态向量,dh表示单向LSTM的隐状态维度。
2.3 跨模态交叉协同注意的对偶图卷积
跨模态交叉协同注意的对偶图卷积层(图2(c))由正交约束的自注意力机制、文本语义图卷积、视觉语义图卷积以及两个不同方向的门控的局部跨模态交互机制构成,该层网络能够自适应地挖掘方面指向的模态内数据单元的局部情义关联以及图像和文本数据单元之间的局部协同情义关联。下面分别阐述这些组件。
2.3.1 正交约束自注意力机制
自注意力(Vaswani等,2017)能够计算每一对特征向量的注意力分数,它可以更好地建模不同模态的上下文语义依赖关系。在本文中,使用自注意力机制来计算注意力得分矩阵,并将其作为文本语义图卷积或视觉语义图卷积的输入。关于文本的注意力分数矩阵Tes∈Rn×n计算为
式中,Hs是含有方面词的文本特征的上下文序列表示都是可学习的权重矩阵。另外,d是输入节点的维度。
关于图像的注意力分数矩阵Ges∈R(k+1)×(k+1)计算为
然而,对于文本或图像,模态内部的数据单元局部情感语义关系应该被尽可能地明确建模,增强模态内局部特征的判别性。因此,本文在注意力分数矩阵的基础上设计正交约束的策略来实现这一目的。以文本为例,与每个词相关联的词位于句子中不同的局部位置,而将含有方面词的文本特征的上下文序列表示Hs通过自注意力机制生成的关系矩阵Tes往往包含一些重叠的情感语义。为了使Tes的情感语义分布尽可能地减少重叠,通过正交约束策略以调整Tes中的语义注意力关联分数,从而更好地捕获不同局部信息的关联性指向情义。对于图像中局部语义的建模亦是如此。
为了改进文本的语义关联矩阵的表示,给定文本的注意力分数矩阵Tes∈Rn×n,则关于文本模态的Tes的正交约束表述为
式中,I表示单位阵,下标F 代表Frobenius 范数。在模型训练过程中,通过Rc约束会让Tes(Tes)Τ的每一个非对角元素最小化,使得矩阵Tes趋于正交,微调文本模态的注意力分数矩阵Tes,从而得到更具判别性的文本特征表示。
同理,关于视觉模态的注意力分数矩阵Ges的正交约束表述为
式中,I和下标F 含义同等式(10)。类似文本模态,视觉模态注意力分数矩阵Ges在训练过程中通过Rg的约束学习以趋于正交,从而降低视觉区域之间的注意力重合,自适应地学习各自模态中不同局部区域的上下文依赖程度和视觉特征的判别性。
2.3.2 文本语义图卷积
基于文本语义图,利用图卷积操作,进一步抽取文本语义图节点表征集合,具体为
此时,文本语义图中方面词节点的表征聚合了全体文本的重要情义信息,从而可以缓解方面的情感极性通常是由关键短语而不是单个词决定的问题(Chuang等,2018)。
2.3.3 视觉语义图卷积
类似文本语义图卷积,基于视觉语义图,利用图卷积操作得到处理后视觉语义图节点表示具体为
此时,视觉语义图中节点表示不仅学习了方面与图像的局部区域之间的语义关联,而且方面词节点也学习到了图像中局部区域的上下文情义特征,建模了与方面有关的视觉区域。
2.3.4 门控的局部跨模态交互机制
门控的局部跨模态交互机制用来建模文本中的词和图像中不同区域之间的语义对齐,结构如图3所示。为了学习每个视觉局部区域中最相关的文本词,将经过一层视觉语义图卷积操作后的每个图节点表示依次与经过一层文本语义图卷积操作后的图节点表示进行交互。受到VQA(visual question answering)(Kim 等,2016)在跨模态关联学习的启发,将两个特征向量(即视觉模态中第i个图节点向量和文本模态中第j个图节点向量,分别来自)进行线性变换,然后融合两者的特征,具体为

图3 门控的跨模态局部交互机制Fig.3 Gated cross-modal local interaction mechanism((a)image-guided text alignment fusion;(b)text-guided image alignment fusion)
将融合后的向量Xij进行线性变换,通过softmax操作获得归一化的注意力分数αij,具体为
注意力分数αij可以用来关注视觉模态任一图节点特征对应的文本模态中所有图节点特征的注意力强度,则视觉模态中任一图节点特征所关联的文本模态的特征表示ti计算为
式中,Wf和bf表示权重矩阵和偏置参数。ui表示视觉模态图节点相对于该图节点的文本特征ti的重要性程度,而1 -ui控制视觉模态中该图节点特征的重要性。“∘”表示逐元素相乘。图3(a)展示了文本融入图像的门控的局部跨模态交互机制过程。与此类似,获得融入文本语义图表示信息的视觉图节点特征表示
为了充分探索文本局部情义融入视觉局部情义的协同关联,基于融入文本信息的视觉特征节点表示为又进行一次图卷积操作以更充分地学习跨模态情感语义关联,从而得到深层次的视觉语义图节点表示式(14)—(18)描述了以视觉模态中不同图节点为中心来引导文本上下文的交叉注意力,并门控地融合视觉模态中每个图节点和与其最相关的文本上下文信息。为了充分挖掘跨模态之间的交互,接下来,进一步探索文本模态中以不同的图节点特征来引导视觉上下文的注意力交互。
2.4 方面掩码设置
2.4.1 方面特定的掩码机制
为了明确地体现方面的语义指向性以及尽可能地减少特征的冗余,设计方面特定的掩码机制来提取不同模态中方面节点的特征表示。由于经过跨模态交叉协同注意的对偶图卷积学习后,不同模态中的方面节点信息已经聚合了模态内的上下文情义关联的信息,而且还包含了跨模态细粒度的上下文交互特征。因此,只选出方面节点表示用于情感判断。具体地,将方面特定的掩码机制作用于跨模态交互后的不同模态的特征
最后,将方面级多模态情义表示Ral输入到softmax层用以产生情感概率分布y,具体为
式中,Wp和bp是可训练的权重和偏置。
2.4.2 跨模态损失
距离度量学习是由 Xing 等人(2002)提出的,其思路是计算两个特征向量a和b的距离,通过描述它们之间的距离关系,从而度量它们的相似度。因此,为了探索异质的方面情义特征之间的一致性,本文利用跨模态损失来约束不同模态情义特征空间表征的相似性,使其在特征空间上更加接近,约束式为
式中,O表示异质的方面特征的距离,通过最小化O来探索不同模态的情义特征的一致性关联。
2.5 损失函数
AMCGC是一个端到端的学习过程,通过设计多损失函数来联合优化模型的参数,其优化的总目标函数为
式中,λ1,λ2为正则化系数。ℓ 是一个标准的交叉熵损失函数,其定义为
式中,N表示训练数据集的样本数。
3 实验分析
3.1 实验设置
3.1.1 数据集
采用Yu 和Jiang(2019)标注的两个公开基准数据集,即Twitter-2015 和Twitter-2017 来评估本文AMCGC 模型。这两个数据集均提供了每条推文的方面词以及3 种情感极性标签。两个数据集的详细信息如表1所示。

表1 两个多模态Twitter数据集的基本统计Table 1 The basic statistics of two multimodal Twitter datasets
3.1.2 参数设置
在实验中,对于文本,将最大填充长度设置为60,并分别使用不同词嵌入方式,即Glove 嵌入和BERT 嵌入。如果使用Glove 嵌入,词嵌入和方面嵌入向量的维度设置成100,在训练过程中保持固定。如果使用BERT 嵌入,词向量的维度设置成768,且在训练过程中进行微调。而每幅图像被分成49 个视觉块,每个视觉块的特征维度大小为2 048,且在训练过程中固定ResNet 中的所有参数。对于AMCGC 模型,使用预训练的100 维Glove 嵌入矩阵来初始化词嵌入向量。对于AMCGC+BERT 模型,使用预训练好的768 维的bert-base-uncased 来初始化嵌入向量。在训练过程中使用Adam(Kingma 和Ba,2014)优化器,其初始学习率设定为0.002。此外,batch size 大小设置为8。正则系数λ1和λ2分别设置成0.2 和0.15。基于PyTorch 来实现所提出的AMCGC 和AMCGC+BERT 模型,并在NVIDIA Tesla P100-PCIE GPU 上运行实验。通过准确率(accuracy,ACC)和Macro-F1 值作为实验的评价指标进行对比分析。
3.2 对比方法及实验结果
为了评估AMCGC 方法的性能,本文选择以下方面级情感分析模型作为基线用于对比分析。
1)Img-Aspec(timage-aspect)。该模型是本文所提模型中仅涉及视觉和方面的处理分支,即通过输入嵌入层和特征抽取层以及视觉语义图卷积模块来提取视觉情感语义特征,并利用掩码机制选出方面词的情义特征用于情感分类。
2)Res-Target(residual-target)。该模型是Yu 和Jiang(2019)提出的一个对比变体,仅将图像和方面词经过特征提取后,再拼接输入BERT 用于方面级情感分类。
3)Text-Aspect。该模型是本文模型中仅涉及文本的处理分支,即通过输入嵌入层和特征抽取层以及文本语义图卷积模块来提取文本情感语义特征,并利用掩码机制选出方面词的情义特征用于情感分类。
4)MemNet(deep memory network)(Tang 等,2016)。该模型使用方面词作为查询的记忆模型。在词嵌入和位置嵌入的基础上,采用多跳注意力机制更新存储的记忆,从而实现深度记忆。
5)RAM(recurrent attention network)(Chen 等,2017)。该模型采用多注意力机制来捕获距离较远的情感特征,然后将多个注意力的输出与GRU 网络结合来增强全局记忆的表达能力。
6)MGAN(multi-grained attention network)(Fan等,2018)。该模型采用注意力机制在词汇级别上学习方面和文本的交互,然后使用注意力学习方面和文本的整体交互,最后将两者拼接用于情感极性的预测。
7)Res-RAM(residual recurrent attention network)、Res-MGAN(residual multi-grained attention network)和Res-ESTR(residual entity sensitive textual representation)。这3 个模型是Hazarika 等人(2018)提出的多模态融合方法的3 种变体,它们首先在视觉特征上应用最大池化获得g=MaxPoo(lR),然后将g和RAM、MGAN 的文本表示相关联后用于情感分类。
8)Res-RAM-TFN(Res-RAM-Tensor fusion network)和Res-MGAN-TFN(Res-MGAN-Tensor fusion network)。这两个模型是多模态融合方法(Zadeh等,2017)的两个变体,它们使用双线性交互算子将g与MGAN 的文本表示通过复杂的融合矩阵相结合,并将得到的矩阵送入推理网络后用于情感分类。
9)MIMN(Xu 等,2019)。该模型采用多跳记忆网络对方面词、文本和视觉之间的交互注意进行建模。
10)ESAFN(Yu 等,2020)。该模型采用注意力机制生成实体敏感文本表示和实体敏感视觉表示,并使用门控以消除带有噪音的视觉信息,然后将文本和视觉表示进行交互以用于多模态情感分类。
11)EF-Net(Gu 等,2021)。该模型采用自注意力获得模态内部动态,然后采用多头注意力将多模态特征进行融合。
12)TomBERT(Yu 和Jiang,2019)。采用经典的BERT 模型来实现方面引导多模态特征和多模态的交互融合。
13)AMCGC。本文提出的AMCGC 模型中,使用Glove嵌入得到文本嵌入表示。
14)AMCGC+BERT。本文提出的AMCGC 模型中,使用预训练的BERT来得到文本嵌入表示。
本文方法以及对比方法的实验结果如表2 所示。由表2 可知,对于基于Glove 词嵌入的模型,提出的AMCGC 取得最好的性能,说明该模型能充分捕捉方面指向的模态内部的局部语义关联以及多模态之间不同局部信息的情感语义协同性关联。另外,从表2 中可发现Img-Aspect 的性能相当有限,获得大约60%的准确率,这表明文本内容对于方面级情感分类是非常重要的,不应该忽略。其次,从表2中可以看出,Res-RAM、Res-MGAN 优于仅使用文本数据的RAM、MGAN,并且优于使用文本数据的MemNet模型,这意味着关联图像确实能够对文本提供互补信息。此外,Res-RAM、Res-MGAN 和Res-RAM-TFN、Res-MGAN-TFN 这4 个模型的区别是TFN 融合模块,然而使用TFN 融合方法的性能却出现下降,这说明基于TFN 的融合并不适合细粒度的方面级多模态情感分类。另外,MINI 效果也较好,这表明将方面引导的文本和方面引导视觉进行交互是有效的,但是由于MINI模型主要基于一个相对较弱的MemNet 模型,所以它的性能仍然略差于Res-ESTR。ESAFN 模型仅从全局的角度来进行方面引导多模态,而且缺乏细粒度的多模态之间的交互,所以它的效果并不理想。EF-Net模型总体上优于大多数基线方法,这表明注意力机制在方面级多模态情感分析中是不可或缺的。但是由于EF-Net 模型仅仅是使用注意力机制来进行多模态交互,而本文提出的AMCGC 模型的情感分类性能要好于EF-Net 模型,这表明更合理的注意力机制的设计是必要的。

表2 AMCGC和基线模型的性能Table 2 Performance of AMCGC and baseline models
对于使用BERT 预训练模型来得到向量表示而言,本文提出的AMCGC+BERT 模型的性能也好于TomBERT 模型。TomBERT 模型通过堆叠BERT 来对方面和图像进行对齐并捕捉模态内的动态和模态间的交互。然而TomBERT 只将方面引导图像,并没有将方面引导文本。而本文提出的AMCGC+BERT模型不仅将方面引导图像,而且将方面引导文本,而且利用图卷积网络从局部的角度来考虑多模态的交互对齐,这也表明AMCGC+BERT 中方面引导多模态的有效性以及以交叉协同的方式进行多模态交互的优势。另外,如表2 所示,基于BERT 预训练的AMCGC+BERT 要比基于Glove 的AMCGC 好,这表明基于大规模预训练的模型获得词的表示更具优势。总体而言,本文方法对方面级多模态情感分析是合理且有效的。
3.3 消融实验设计及结果
为了评估本文方法中不同模块的有效性,分别从正交约束、跨模态损失、交叉协同多模态融合方式的角度来对模型进行消融研究。在Twitter-2015 和Twitter-2017 这两个数据集上做消融实验,且保证所有的训练参数都一样,并选择准确率和Macro-F1 作为评价指标。消融方案如下:
1)CML(cross modal loss)。在方面掩码设置层中,无跨模态损失,其他模块保留。
2)OC(orthogonal constraints)。在跨模态交叉协同注意的对偶图卷积层中,文本语义图和视觉语义图没有使用正交约束规则,其他模块保留。
3)MLOC(cross modal loss and orthogonal constraints)。在方面特定的掩码机制中,无跨模态损失。文本语义图和视觉语义图没有使用正交约束,其他模块保留。
4)IGTF(image-guided text fusion)。在跨模态交叉协同注意的对偶图卷积学习中,针对门控的局部跨模态交互机制,没有使用图像引导文本的对齐融合机制,其他模块保留。
5)TGIF(text-guided image fusion)。在跨模态交叉协同注意的对偶图卷积学习中,针对门控的局部跨模态交互机制,没有使用文本引导图像的对齐融合机制,其他模块保留。
6)CMIM(cross-modal interaction mechanism)。在跨模态交叉协同注意的对偶图卷积学习中,针对门控的局部跨模态交互机制,既没有使用图像引导文本的对齐融合机制,也没有使用文本引导图像的对齐融合机制,其他模块保留。
7)NOPA(no average pooled aspect)。在特征提取操作中,将没有进行平均池化的方面词拼接到图像特征之后。
8)MGN(multimodal graph nodes)。在方面特定的掩码机制中,将文本图节点表征和视觉图节点表征的所有节点分别进行平均池化,然后融合用于情感分类。
表3 展示了本文模型消融实验的对比结果。首先为了证明在方面特定的掩码机制中跨模态损失的有效性,在模型中去掉跨模态损失,如表3 所示,CML 在Twitter-2015 数据集和Twitter-2017 数据集上的准确率分别达到74.15%和67.59%,而提出的AMCGC 模型在这两个Twitter 数据集上的准确率分别达到75.41%和68.96%,这表明跨模态损失对于拉进异质方面词特征的一致性是有效的,从而提高方面级多模态情感分析的准确率。另外,为了证明跨模态交叉协同注意的对偶图卷积模块中,对注意力矩阵进行正交约束的有效性,本文分别移除了文本语义注意力矩阵和图像语义注意力矩阵中的正交约束,OC 在Twitter-2015 数据集和Twitter-2017 数据集上的准确率分别下降了1.84%和0.89%,而且Macro-F1 值分别下降了2.76%和0.43%,这表明对语义注意力矩阵进行正则化是有益的,这也说明了降低语义重叠是非常有必要的。更重要的是,当既不使用跨模态损失也不使用正交规则的时候,MLOC 的准确率和Macro-F1 值在Twitter-2015 数据集上,MLOC 的准确率和Macro-F1 值分别下降1.83%和2.95%,而在Twitter-2017 数据集上仅仅只能达到65.15% 和61.27%,性能指标分别下降3.81%和4.09%,这说明在多模态情感分析中,多模态之间的异质性非常影响模型性能,而且模态内更加明确的语义依赖对模型性能的提升也非常必要。

表3 在Twitter-2015和Twitter-2017上的消融实验Table 3 Ablation experiments on Twitter-2015 and Twitter-2017
此外,本文还验证了跨模态交叉协同注意的对偶图卷积层中两处门控的局部跨模态交互机制的影响,无论删除其中的哪一个门控的局部跨模态融合,在Twitter-2015 数据集还是在Twitter-2017 数据集上,模型的性能都有所下降。而且当两个门控的局部跨模态融合都不使用时,在Twitter-2015 和Twitter-2017 数据集上,CMIM 的准确率相比AMCGC 分别下降0.87%和2.91%,这说明基于交叉协同方式进行多模态情义交互是有用的,且文本和图像的多重交互对齐能挖掘更丰富的跨模态的局部细节信息,从而提升方面级多模态情感分析的准确率。通过以上分析,本文所提出的AMCGC 模型的性能优于所有的消融实验,这表明AMCGC 模型中的每一个模块都是有用且合理的。
另外,在特征提取操作中,AMCGC 将方面平均聚合后融入到视觉序列特征后面来挖掘方面导向的视觉上下文特征,为了表明该策略中方面平均聚合的有效性,如表4 所示,在特征抽取中,当不把方面词进行平均池化去融入图像序列时,在Twitter-2015数据集和Twitter-2017 数据集中,NOPA 的准确率相比本文AMCGC 模型分别下降了1.83%和1.38%,Macro-F1 值分别下降了2.82%和4.52%,这说明方面词的处理对模型的性能影响比较大。当不把方面词序列进行平均池化时,引入的噪声会更大,不利于方面词注意到与其更具关联的图像区域。

表4 在Twitter-2015和Twitter-2017上的方面聚合融入图像的有效性Table 4 Effectiveness of aspect aggregation incorporating images on Twitter-2015 and Twitter-2017
为了验证在方面特定的掩码机制中,将文本图节点特征和视觉图节点特征全都用于情感判断,是否会带来特征冗余,开展实验,结果如表5 所示,MGN 的效果相比AMCGC 在Twitter-2015 和Twitter-2017 数据集上的准确率分别下降了1.93% 和1.46%,这说明将多模态图节点表示全部用于情感判断,会带来特征冗余,从而降低模型的性能。

表5 在Twitter-2015和Twitter-2017上的异质方面节点融合的有效性Table 5 Effectiveness of heterogeneous node fusion on Twitter-2015 and Twitter-2017
3.4 超参数设置分析
为了研究AMCGC 中几个关键成分的影响和敏感性,本文进一步分析了一些超参数的设置。
3.4.1 图像区域数量K的选择
为了探索图像区域数量K对模型性能的影响,分别将K设置为16、36、49 和64,在Twitter-2017 数据集和Twitter-2015 数据集进行实验,结果如图4 所示,随着K的变化,模型的性能也会发生变化。当K=49 时,分类效果最好。K越小或越大,性能都不好。这主要是因为较少的视觉区域将导致视觉特征局部粒度的缺乏,影响多模态细粒度的对齐。而视觉区域数量较多时,会导致视觉特征的局部粒度过于细腻,文本局部特征和图像局部特征之间的对齐紊乱,产生视觉噪声,从而影响模型的效果。因此在最终的实验中,将图像区域的数量K设置为49。
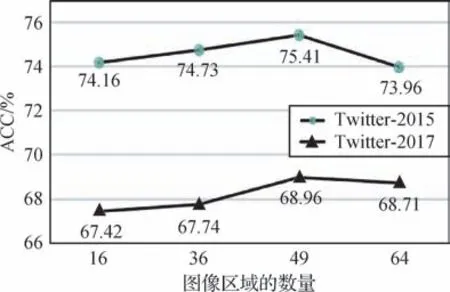
图4 图像区域数量的影响Fig.4 The effect of the number of image areas
3.4.2 正交约束项权重分析
在消融部分已经证明了在跨模态交叉协同注意的对偶图卷积层中,对文本语义图和视觉语义图使用正交约束是有用的。为了探索合适的正交约束系数,即总损失函数式(30)中,文本模态正交约束系数λ1和图像模态正交约束系数λ2的参数设置,本文在Twitter-2017 和Twitter-2015 数据集上进行一系列实验,并报告了在最终目标函数中各个模态的正交约束权重的结果。
实验结果如图5 所示,当λ1和λ2都小于0.1 或都大于0.3 的时候,模型效果欠佳。在这两个数据集中λ1和λ2的变化趋势是一致的,当λ1和λ2都等于0.15,AMCGC模型效果达到最好。这表明有必要探讨模态内局部特征的判别性分析,但过分强调它可能导致模型在基于方面的多模态情感分析任务中表现不佳。

图5 多模态正交约束权重对模型的影响(λ1=λ2)Fig.5 Influence of multi-modal orthogonal constraint weight on the model(λ1=λ2)((a)Twitter-2017;(b)Twitter-2015)
由于图像特征和文本特征在情感判断的贡献上是相辅相成的,但是情感贡献度应该是不一样的,因为文本的语义相比图像可能会更丰富。因此做出猜想,λ1和λ2的值应该是不一样的。假设文本模态内数据单元的正交化系数λ1稍大于图像模态的数据单元正交化系数λ2,并进行实验,实验验证了做出的猜想是正确的,即,当λ1=0.2,λ2=0.15 时,AMCGC 模型达到最佳性能。这可能由于文本模态的语义比图像模态的语义更加丰富,导致文本模态内数据单元的语义比图像模态内数据单元的语义相似度高,因此,文本模态的正交系数λ1比图像模态的正交系数λ2要更大一些,以使文本模态内数据单元更具判别性。
3.5 注意力实例展示
图6 展示了针对自注意力机制在视觉和文本的可视化的示例。对于文本“RT @ KatCallaghan:Thanks to Julie and everyone @ BioreCanada for the Welcome to @ Z1035Toronto gift !”,对应图像如图6(a)所示。句子中的方面词是“Julie”,从图6(b)可以看出,AMCGC 模型更加关注蝴蝶结。此外,“Thank”,“everyone”,“Welcome”,“gift”词的权重更大,如图6(c)所示。这表明在方面词的引导下,图像能关注到与方面相关的区域。同时,文本也能关注到与方面相关的词。显然,提出的AMCGC 模型能够捕捉到模态内的局部语义相关性,且更好地服务于随后的跨模态之间的细粒度对齐,进而准确地判断该条示例为“积极”的情感极性。

图6 视觉文本注意案例分析Fig.6 Visual text attention case study((a)sample image;(b)visual attention visualization;(c)text attention visualization)
4 结论
本文提出了AMCGC 模型用于方面级多模态情感分析,该模型主要包含特征抽取层、跨模态交叉协同注意的对偶图卷积层和方面特定的掩码层。其中,特征抽取层用来抽取文本和图像的特征隐状态,而且将方面词特征拼接到图像特征隐状态后面来增强图像模态在学习局部语义依赖过程中的方面指向的高响应情义特征。在跨模态交叉协同注意的对偶图卷积层中,分别构建含有正交约束的文本语义图和视觉语义图以建模各自模态内更明显的局部语义依赖。随后,通过图卷积网络来分别得到细粒度的多模态特征表示,并利用不同方向的门控局部跨模态交互机制来实现跨模态的情义协同交互和对齐。最后,通过方面特定的掩码模块,仅选出不同模态特征中方面词的节点特征用于情感分析,且引入跨模态损失使异质的富含情义的方面词特征保持一致性。在Twitter-2015 和Twitter-2017 数据集上的实验及与对比方法的比较表明AMCGC 模型的有效性,并通过一系列的消融实验证明了AMCGC 模型的每个模块设计的合理性。在未来的研究中,将设计更好的跨模态关联的学习策略来探索不同模态数据单元的一致性,以更好地服务方面级多模态情感分析。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
现代语文(2016年21期)2016-05-25
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
大连民族大学学报(2015年2期)2015-02-27
计算物理(2014年2期)2014-03-11
电视技术(2014年19期)2014-03-11
