
偏转角度情况下MTCNN 人脸检测算法改进*
2023-12-09 08:50杨玉洁陈天星石林坤
计算机与数字工程 2023年9期
杨玉洁 陈天星 石林坤 袁 标
(西南交通大学机械工程学院 成都 610031)
1 引言
随着计算机视觉在行人检测[1~2],自动驾驶[3~4]和视频跟踪[5~6]等领域发展的广泛应用,人脸检测作为其中一个重要的分支也广泛地应用于各种场景下,目前已产出了许多成果[7],主要有Cascade R-CNN[8]、SAFD[9]、MTCNN[10]等算法。但目前将人脸检测应用于实际场景时还有很多的局限性,如在遮挡[11]、大偏转角度、复杂背景、低像素[12~13]等情况下人脸检测识别效果不佳。
MTCNN(Multi-task Cascaded Convolutional Networks)即多任务卷积神经网络,是由中科院深圳先进技术研究院2016 年发布的ECCV 论文[10]。该论文提出了一种在不受约束的环境中进行面部人脸框和关键点检测与人脸对齐功能。它可以将人脸对齐与人脸检测同时完成,相较于传统算法,能较实用、性能更好地进行人脸检测。但针对特定应用场景中大偏转角度、低像素等问题,此算法的检测性能会有所降低。
针对大偏转角度检测性能不佳的问题,本文提出了一种改进的MTCNN 算法,该算法能在提升原始MTCNN 算法检测速率、检测准确性的基础上有针对性地提升人脸存在大偏转角度的情况下的检测准确度。改进后的算法可为将人脸检测应用于复杂真实场景提供理论基础。
2 理论基础
MTCNN 的主要思路为级联卷积神经网络思想[14~15],并使用多任务的形式训练网络参数,对人脸实现由简到精的检测的过程[16]。其网络结构主要分为三部分,如图1所示。
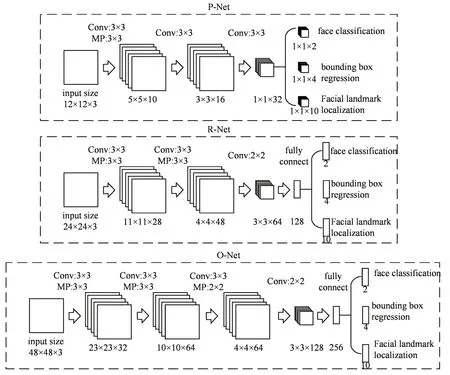
图1 MTCNN网络结构图
1)P-Net(Proposal Network)12×12:获取候选窗口框和边界框的回归向量,对候选窗口使用非极大值抑制(NMS),合并重叠度高的候选窗口。
2)R-Net(Refine Network)24×24:接收P-Net的输出候选窗口,筛选舍弃大量错误的候选框,并进行微调。再次使用NMS合并重叠度高的候选窗口。
3)O-Net(Output-Network)48×48:与R-Net 功能类似,但更为精确地预测人脸位置,并输出人脸关键框和五个面部关键点坐标。
由于P-Net 是一个全卷积神经网络。并且原始图片在输入后经过图像金字塔的放缩,从而实现了多尺度的人脸检测。也因此网络的结构较小,所以效率非常高,成为了工业界的人脸检测主流算法[17]。
3 算法改进
3.1 DIoU-NMS
MTCNN 中使用三层网络在传入下一层网络结构前均使用NMS(Non-Maximum Suppression)合并重复候选框。NMS为非极大值抑制,顾名思义就是通过抑制局部置信度不为最大值的候选框来实现局部最大值搜索以及相似候选框的合并。NMS 筛选候选框时先依据置信度得分对候选窗口进行排序,挑出置信度最高的候选框并计算其余候选框与此候选框的IoU(Intersection over Union)。通过删除阈值nms_threshold 大于一定值的候选框来实现候选框的筛选,原论文中nms_threshold 分别设置为0.5、0.7、0.7。
MTCNN 原始论文中作者使用经典NMS 算法对候选框进行合并。但NMS 去除候选框时只选用置信度得分高低作为筛选依据而没有将定位是否准确考虑入内,这样可能会出现置信度高但位置信息不够精确的候选框将置信度低但位置信息精确的候选框排除掉。经过不断的迭代回归,原本能够准确定位的边界框会偏离目标人脸实际所在位置。在有角度偏转情况下,人脸中五官可能无法收集完整图像信息,从而使定位框大幅度偏离原有位置,再将这些定位框输入NMS 进行候选框筛选后得到的最终候选框将进一步偏离真实定位位置。为弥补上述缺点,本文使用DIoU-NMS[19]代替原论文中使用的NMS 算法。DIoU-NMS 在NMS 过程中使用DIoU的计算方法代替传统IoU计算,不仅考虑两个候选框的重合度,还将两个候选框中心点的距离考虑在内,其计算公式如式(1):
其中,RDIoU是两个Box 中心点之间的距离,计算公式如式(2):
其中,ρ(b,bgt)是b和bgt两Box中心点之间的距离d,c是包含两个Box的最小Box的对角线长度,如图2 所示。由计算公式可知,DIoU-NMS 的核心思想是在NMS 的基础上,不直接删去IoU 较大的候选框,而是通过两候选框的中心点距离进一步判断是否为同一检测目标的冗余框。在有角度偏转情况下的人脸检测中,人脸五官关键点通常有所缺失、遮挡,使用DIoU-NMS 可以在保证置信度高的同时最大程度地保留同一人脸检测出的多个候选框中较为准确的位置信息。
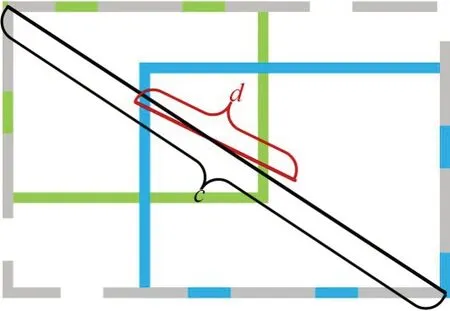
图2 DIoU计算示意图
3.2 注意力机制
卷积神经网络中,卷积核的计算是其核心计算。本文希望在卷积操作时可以在空间上和通道间进行更多的特征融合。但传统通道间卷积操作默认对输入特征图的所有通道进行融合。SENet[20]网络提出的SE(Squeeze-and-Excitation)模块则对通道间的相关性进行学习,可以自动在卷积池化的过程中学习到特征图中不同的通道重要程度,如图3所示。
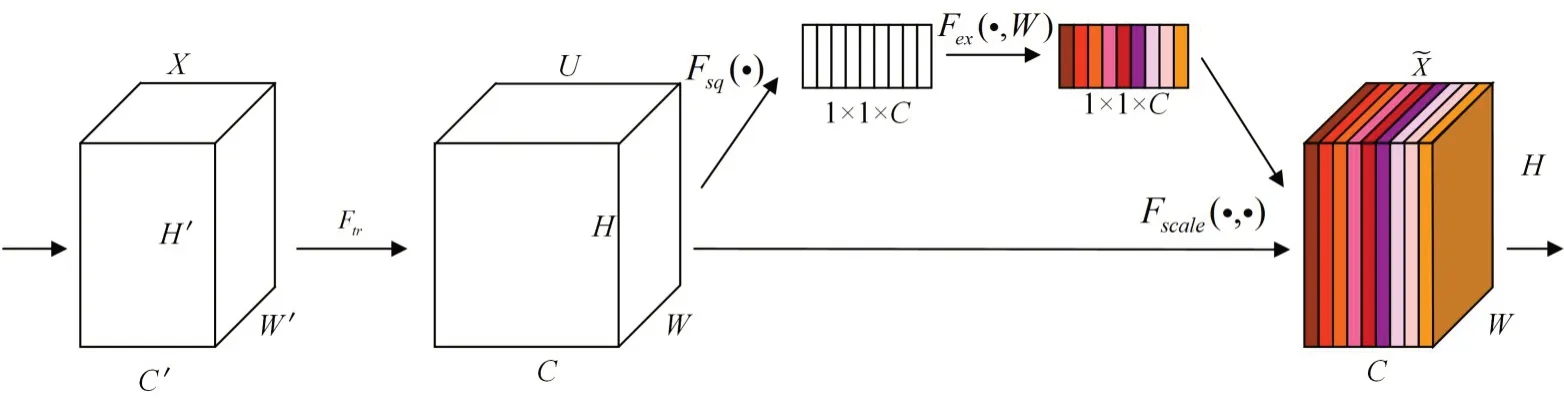
图3 SE结构图
SE 模块主要操作分为Squeeze 和Excitation、Scale三个步骤:
1)Squeeze:对输入的特征图(h*w*c)进行全局池化操作得到1*1*c的特征图,公式如下。在输入数据的所有空间特征中,Squeeze 可以将数据的特定通道编码为一个特定的全局特征。
2)Excitation:使用两个全连接层和sigmod激活函数对Squeeze 操作的结果进行一个线性变换,得到特征图不同通道间的权值,公式如式(4):
其中z为Squeeze 操作获取的全局特征描述,W1、W2为两个全连接层,,r为缩放参数。
3)Scale:将得到的通道权重参数与原始特征图进行二维矩阵相乘,将得到的结果输出,公式如式(5):
整个操作重新训练了一个对各通道更为敏感的权重系数模型,从而实现了注意力机制。并且由于SE 模块是轻量级的,具有易于集成的优点,可以直接应用于现有的网络结构中。使用SE 模块可以在只增加较少的计算量的前提下就获得很大的性能提升。本文改进前后的P-Net网络结构如图4所示。
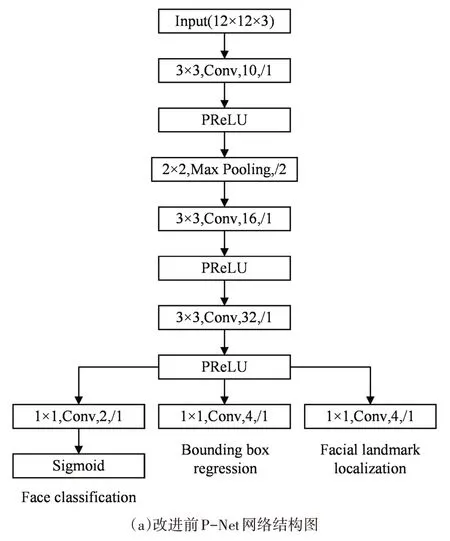
图4 改进前后P-Net网络结构图对比
4 实验与结果分析
4.1 数据预处理
为验证上述改进方法使MTCNN在具有偏转角度情况下的人脸检测准确率和识别率方面有了较好的提升,本文设计了相关实验进行验证。
本文实验以AFLW[21]数据集为基础,对算法进行训练与测试。AFLW(Annotated Facial Landmarks in the Wild)数据集是一个包括多姿态、多视角的大规模人脸数据库。图片中每张人脸标注了21 个关键点,由于是肉眼标记,其中不可见关键点不进行标记。此数据集因具有人脸姿态角度标示,被广泛应用于头部姿态估计及关键点定位领域。
AFLW 数据集中人脸偏转角度标注标准为面向镜头左偏为正,右偏为负,使用弧度制计量。实验之前,先提取数据集中人脸角度姿势数据,将人脸图像根据左右偏转角度范围进行分类。这样便于逐个研究分析各角度范围内人脸检测识别率与准确率。
4.2 实验环境
本算法实验所在实验环境为Ubuntu18.04,搭载Intel-Core i3-9300k 处理器,内存为16G,采用GeForce RTX2060 Super,显存为8G,搭配CUDA、OpenCV 图形库,采用Pytorch1.2、Python3.6 进行代码编译。
4.3 实验结果分析
在上述实验设计中,通过将改进前后的算法应用于分类后的AFLW 数据集进行一系列实验来验证模型的可行性,以下是模型评价的相关指标:
1)交并比(IoU)
IoU是图像分割与检测领域的标准性能检测指标。IoU分数可以检测出该图像的预测区域与真实标定区域之间的相似度。本文分别对比了各个角度算法改进前后的检测结果,并计算其IoU,结果图5所示。
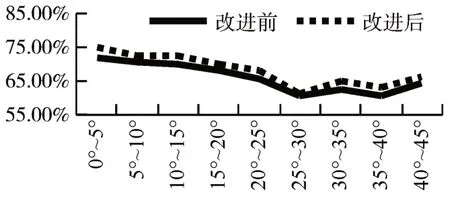
图5 算法改进前后各角度检测IoU结果
其中每个角度算法改进前后未检测出来的人脸占比如图6所示。
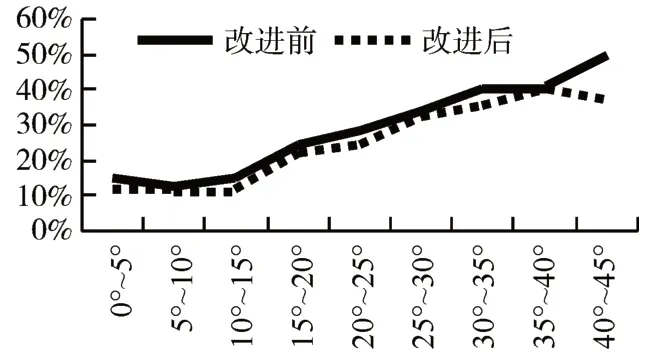
图6 算法改进前后漏检人脸数占比
由图五对比可知算法改进前后IoU 有所提升,证明将原始算法IoU 替换为DIoU 能使检测框位置信息更为准确。且由图六对比可知算法改进后漏检人脸数有所减少,并且各个角度范围人脸检测结果都有了平稳的提升。
2)FPS
为验证模型的检测速度,常采用FPS 作为评价模型检测速度的指标,其计算公式如式(6):
其中NumFigures 为1s 内所检测的图像数量,Times为单位时间(1s)。本文将训练前后的两个模型一起在分类后的测试集做了测试,得到的检测结果见表2。
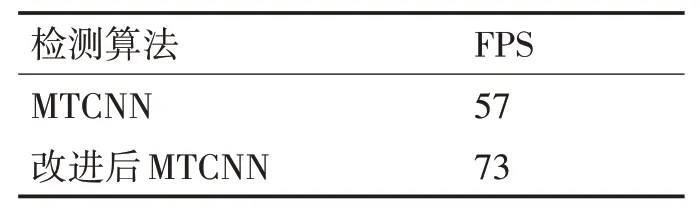
表1 改进前后模型检测速度对比结果

表2 改进前后模型大小对比结果
由表2 可知改进后模型在检测准确率提升的同时,检测速率也有所提升。
3)模型大小
改进前后MTCNN 算法模型大小对比如表2 所示。
由表3 可知,改进后算法模型大小未发生明显改变。证明本文中所改进的算法没有以增多计算量为代价提升检测速率以及检测正确率。
5 结语
针对人脸有角度偏转情况下人脸检测准确率低的问题,本文提出了一种基于MTCNN 人脸检测算法的改进人脸检测算法。该算法将原有MTCNN中NMS改为DIoU-NMS,此举可以在人脸有偏转角度导致五官关键点遮挡、丢失等情况下仍能保留得分高且位置信息准确的候选框。此外,本文还引进了SE 注意力机制。SE 注意力机制可以有效地提高对正样本的信息筛选能力,实现层级间信息利用的最大化。将改进前后算法应用于按角度分类后的AFLW 人脸检测数据集进行人脸检测。实验结果表明:改进后的算法各方面检测指标均优于原始MTCNN 算法。尤其在大偏转角度情况下,仍有较好的检测召回率以及检测准确率。改进后的算法为将人脸检测应用于人脸具有大偏转角度的真实场景提供了理论依据。
猜你喜欢
光学精密工程(2022年13期)2022-08-02
中学生数理化·中考版(2022年12期)2022-02-16
计算机工程与应用(2022年1期)2022-01-22
核科学与工程(2021年4期)2022-01-12
今日农业(2021年8期)2021-11-28
计算机工程与科学(2021年4期)2021-05-11
计算机应用(2018年5期)2018-07-25
火力与指挥控制(2018年3期)2018-04-19
轴承(2015年2期)2015-07-25
中国卫生(2014年2期)2014-11-12
