
基于AKAZE 的融合空间位置信息的视觉词汇树检索算法*
2023-12-09 08:50向姗姗陈永辉王赋攀王叶冰
计算机与数字工程 2023年9期
向姗姗 陈永辉 王赋攀 王叶冰
(西南科技大学计算机科学与技术学院 绵阳 621010)
1 引言
移动增强现实的目标是将增强现实技术有效地应用于移动设备终端,可分为两种主要应用形式:基于APP的增强现实和基于浏览器的增强现实(WebAR)[1~2]。以APP为载体的增强现实需要安装特定APP,存在跨平台难的问题,而运行在浏览器端的WebAR,用户通过访问网页即可使用AR 应用,将虚拟物体叠加到真实场景中,并能够随着用户位置和视线方向变化而实时变化,从而将交互扩展到整个环境,将自己自然地融合于周围的空间与对象,具有轻量级、跨平台、易传播等优势。WebAR可以广泛应用于广告、游戏、教育、娱乐等多个领域[3~4]。
WebAR 系统可分为三大功能模块:三维跟踪注册、虚实结合、实时交互。其中三维跟踪注册是关键技术,用于实现对现实场景中的图像或物体进行跟踪与定位[5~6]。WebAR系统的三维跟踪注册属于基于计算机视觉的跟踪注册技术,主要分为以下方法:1)基于标志物的三维跟踪注册方法:需要预先在现实场景中放置特定标志物,该方法对硬件要求不高,不需要先验知识,计算复杂度低,且具有较高的鲁棒性。2)无标志物的三维跟踪注册方法,该类方法又可分为基于自然特征的跟踪注册技术和基于模型的跟踪注册技术。基于自然特征的跟踪注册技术通过计算场景的自然特征完成跟踪注册,不需要标志物,计算复杂度高[7];基于模型的跟踪注册技术需要使用目标的虚拟模型信息作为先验知识,该方法主要用于解决缺少纹理或无纹理环境中无标志物的三维跟踪注册问题。
为了更自然地与现实场景融合,无标志物的三维跟踪注册方法是WebAR 系统发展的趋势,该类方法需要预先建立图像特征库。自然特征处理时间和图像匹配的准确率是影响用户体验的关键因素。常见的自然特征提取算法有SIFT[8]、SURF[9]、ORB[10]及AKAZE[11]等算法。SIFT、SURF 使用线性高斯金字塔构建图像尺度空间提取显著特征点,会损失局部精度,并且时间复杂度较高,不宜用于实时性较高的场景;ORB 算法使用基于模板的FAST算法快速提取特征点,执行速度快,但在旋转鲁棒性、模糊鲁棒性和尺度变化等方面匹配效果不理想。AKAZE 算法采用非线性扩散滤波策略建立尺度空间,不仅能够有效保持物体和目标的细节特征,而且在检测准确率和运算速度上具有较好的平衡性。2018年闫兴亚等[12]使用AKAZE算法提升了原有增强现实系统的实时性;2018 年闫兴亚和范瑶等[13]提出的一种改进ORB-SLAM 系统,提高了特征点检测和匹配的速度以及定位跟踪的稳定性。2020 年秦雪洲等[14]使用自然特征匹配估计相机运动,以检测平面作为参照物,实现虚拟物体的最终渲染。AR 模型首次加载时间的理想延迟是1秒,传统的图像检索方法较难满足用户可接受的延迟性要求[15]。2018 年张南等[16]将颜色融入词袋特征以提高图像检索的正确率。2019 年Pei 等[17]采用基于自然特征的改进词汇树将模型的首次加载时间缩短了0.26s。
WebAR 在博物馆、美术馆、图书馆等领域有着广阔的应用前景,但受到光照、拍照角度、拍照距离、待识别物大小等客观因素影响,目标识别的准确率和识别速度难以得到保障。针对WebAR 在图书馆和艺术馆中的应用问题,本文利用AKAZE 算法提取图像局部特征,提出了一种融合空间位置信息的视觉词汇树检索方法,增强了图像局部特征的辨识度,从而提高了图像检索的准确率。以此为基础,构建了面向图书馆和艺术馆的WebAR 系统,实验表明该系统具有良好的实时性和鲁棒性。
2 基于AKAZE 的融合空间位置信息的视觉词汇树检索算法
基于视觉词袋模型[18]的图像检索方法是目前图像检索领域的主流方法,通过对训练集图像的局部特征(通常使用SIFT 算法提取)进行聚类,将聚类中心定义为视觉词汇,生成“词袋”,再将图像局部特征量化为与其最相似的视觉词汇,并统计出现频数,生成出视觉词汇直方图,以此作为图像的检索特征。查询时,计算查询图像和图像库图像的相似度,由高至低排序,生成检索结果。
2.1 图像特征提取
基于AKAZE 算法提取训练集图像(即图像库中所有图像)的局部特征。
AKAZE 算法构建的非线性尺度空间,每层图像的分辨率等同于原始图像,共有O组,每组S层,每层的尺度参数计算公式为式(1):
其中δ0为尺度参数的初始基准值,P=O*S是整个尺度空间中图像总数。将σi转化为时间单位,以表示尺度参数,映射公式可表示为式(2):
AKAZE算法计算不同尺度归一化后的Hessian值,以各个尺度下Hessian 局部极大值点作为稳定的特征点。当前尺度下Li利用Hessian 矩阵检测方法为式(3):
特征点检测完成后,AKAZE 算法引入M-LDB特征描述算法生成描述子,M-LDB 描述子以网格为子区域,以尺度δ为间隔重采样,将采样点的导数均值信息作为子区域的导数信息,增强描述子的可区分性和尺度不变性。
2.2 视觉词汇树构建
视觉词汇树的两个重要参数,即树的深度L和树的分支数K,词汇树的每个节点对应一个视觉词汇,具体的构建过程如下:
1)采用K-Means 聚类方法将所有特征划分成k个簇,使簇类具有较高的相似度而簇间相似度较低。
2)对每个簇类再进行K-Means聚类,重复此过程,直到一个簇中的局部特征数量小于给定的阈值或树的深度达到第L层时,聚类结束。
词汇树的叶节点即为视觉词汇。视觉词汇树构建过程如图1所示。
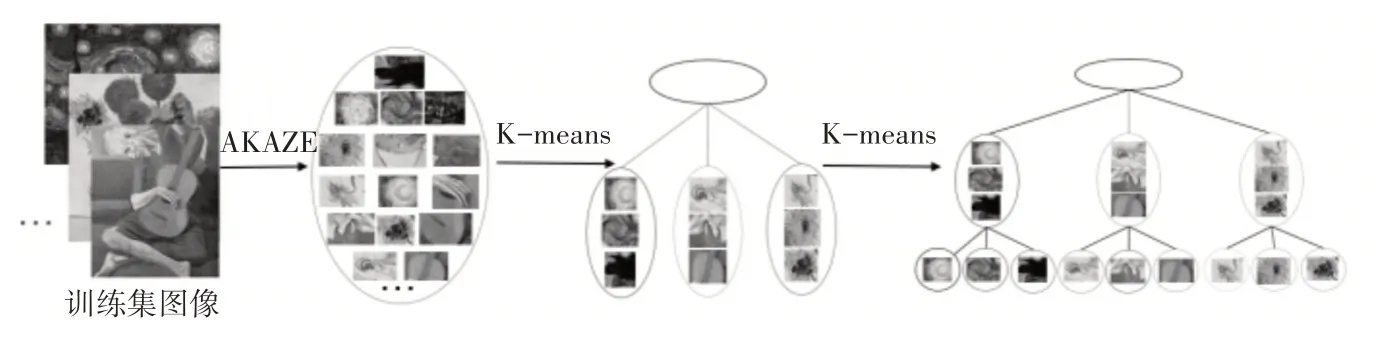
图1 构建词汇树
在实际应用中,为了达到较好的效果,单词表中的词汇数量K往往非常庞大,一般情况下,K的取值在几百到上千,目标类数目越多,对应的K值也越大。
2.3 视觉词汇量化
图像经过词汇树的映射,其局部特征可以量化为视觉词典中与其最相似的视觉单词,通过统计视觉词汇在该图像中出现的频率(即:视觉词汇直方图),可将图像表示为一个K维数值向量,该向量即为图像的最终表示形式,其本质是图像局部特征量化的全局统计结果。
由于视觉词汇树中每个视觉词汇的重要性不同,需要采用TF-IDF[19](Term Frequency-Inverse Document Frequency)方法为视觉词汇赋予权重,进一步强化重要性高的视觉词汇。TF-IDF 是一种用以评估某个语料库中一个词汇对于其中一份文档的重要程度的统计方法。将该方法应用到视觉词汇树中,TF表示视觉词汇xi在图像dj中出现的频率,若一个视觉词汇在某图像中出现频率高并在其他图像中出现频率较低,则表示该视觉词汇在这个图像中的重要性越高,能够较好表示该图像的内容,计算公式为式(4):
IDF 是逆文件频率,表示视觉词汇xi在整个图像训练集中的重要程度,在图像中认定一个词汇是重要的词汇,则不应该经常出现在其他图像中。因此,想要IDF 高,该图的图像频率就必须低,可表示为式(5):
其中|D|表示训练集图像的总数量,1+|j:xi∈dj|表示至少有一个包含词汇xi的图像的数量。
TF-IDF的计算公式为式(6):
但传统TD-IDF算法没有考虑视觉词汇的位置信息,无法有效区分具有以下特征的图像,如图2所示。两幅图像的视觉词汇直方图完全一致,而两幅图的呈现内容可能是完全不同的。
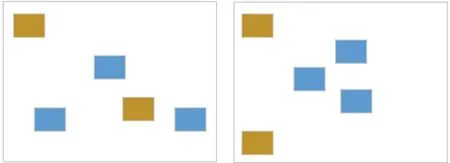
图2 具有相同视觉词汇直方图的不同图像
同时,通过艺术类常用的构图法可知,图像中的每个元素的重要性与其在图像中的位置有较密切的关系,用户最感兴趣的区域往往在中心位置,可将其当看作图像最重要部分,与中心区域相邻的图像区域,则被当作次要部分;偏离中心区域最远的图像区域,可作为不重要部分。
根据艺术类构图法,本文在TF-IDF的基础上,提出了一种融合位置信息的非均匀分块加权TF-IDF 算法,能够对图画的重点区域赋予相对较大的权重,而相对边缘部分赋予较小的权重,从而有利于突出重点特征值,图像分块策略如图3(a)所示。对应权值分配为

图3 图像非均匀分块策略
融合位置信息的TF-IDF计算公式为式(7):
如图3(b)所示,油画的特征点主要集中在中心区域的建筑物和右侧区域的树木,其中边缘区域特征点明显多于中心区域的特征点,会对图像的视觉词汇直方图带来较大的偏差,采用本文提出的非均匀分块加权策略后,能够较明显地降低边缘区域特征对视觉词汇直方图的影响,从而提高后续识别的准确率和速度。
3 WebAR系统实现
本文设计并实现了一个面向图书馆和艺术馆的WebAR 系统,系统的训练集图像数据来源于搜集到的图书馆和艺术馆中的书本和画作,共800幅,使用基于AKAZE 的融合位置信息的视觉词汇树建立视觉词汇字典。
系统采用混合编程实现。交互时,用户通过浏览器打开手机摄像头,获取实时视频流,使用opencv4nodejs库从实时视频流中捕捉关键帧,计算关键帧的特征点;利用视觉词汇树进行检索,返回匹配度最高的图像作为匹配结果;根据匹配的结果,前端使用three.js 生成带有嵌入式网页的AR 模型,而不是从后端或移动边缘传输AR模型[20],能够有效减少传输延迟;AR模型实时渲染时,根据视频帧与训练集图像匹配成功的特征点,实时计算摄像机坐标系与视频帧中目标的图像坐标系之间对应关系,求解渲染模型变换矩阵,实现真实场景中的三维注册。该系统的处理流程图如图4 所示,并可以将可视化结果直接作为增强现实模型进行高效的交互和展示。

图4 系统流程图
当图像识别成功后会显示增强现实效果。图5(a)会显示相关书画的图片,可以放大缩小图片尺寸以更好展示书画的信息获得高质量的体验;图5(b)会显示相应书画的相关信息,如出版年、书名、作者、出版社和摘要等信息。在交互方式方面,用户可以通过缩放、拖动、旋转的方式进行交互,其视觉效果和交互如图5(a)、(b)所示。

图5 视觉效果和交互图
4 测试结果
4.1 客观评价
测试设备主要包括智能手机GLK-AL00(安卓手机,运行内存8GB)、电脑(运行内存32GB)和阿里云服务器,测试过程中使用的浏览器是火狐浏览器。
在测试中,视频流中截取的视频帧的大小是320*240 像素,训练集是100 张图片,测试为50 张图片,对照组分别采用ORB、SIFT、SURF 算法。实验默认情况是在实验室的室内,光照良好、场景宽阔、手机摄像头距离识别目标1m 以内和拍摄时垂直于识别目标。在进行光照的对比实验时,通过开关灯控制光照的改变且其余条件不变。尺度变化实验时只改变图片的像素大小,其余保持不变。分别对四种算法在实验默认情况、尺度和亮度变化的情况下,对比平均检索时间和检索准确率,平均检索时间以微秒为单位,实验结果如表1和表2所示。

表1 亮度变化(训练集100片,测试50张)
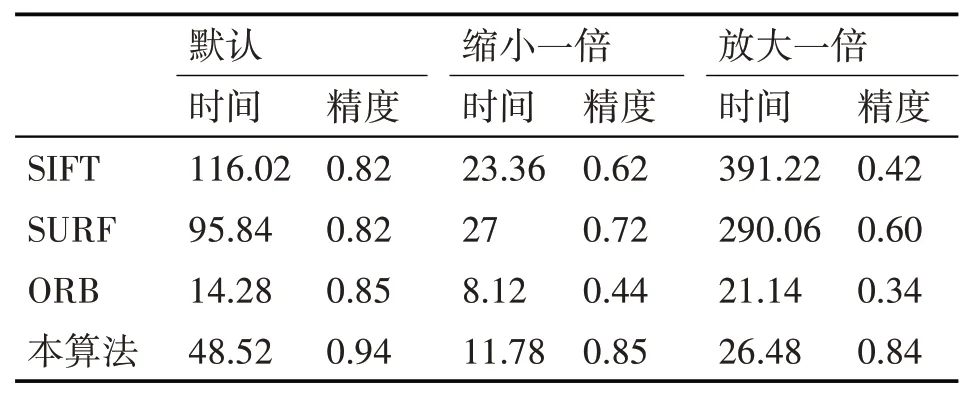
表2 尺度变化(训练集100片,测试50张)
实验结果表明,在亮度变化时,本文提出的算法检索准确率高于ORB、SIFT、SURF 算法,平均检索时间稳定,低于ORB 算法,明显高于SIFT、SURF算法。在测试图像和训练图像特征匹配的过程中本算法的匹配率最高,其次是ORB 算法;SIFT 算法和SURF 算法的匹配率相对其他两种算法较低。表1表明了图像亮度的变化对图像识别率的影响。
实验结果表明,当图像尺度变化时,本算法平均检索时间优于SURF 和SIFT 算法,平均在48ms左右,ORB 算法的运行时间最短,但在相同情况下ORB的检索精度低于本文算法。
再将本算法和ORB 算法进行单独对比,随着图片数量增加,准确率、识别时间变化如表3所示。
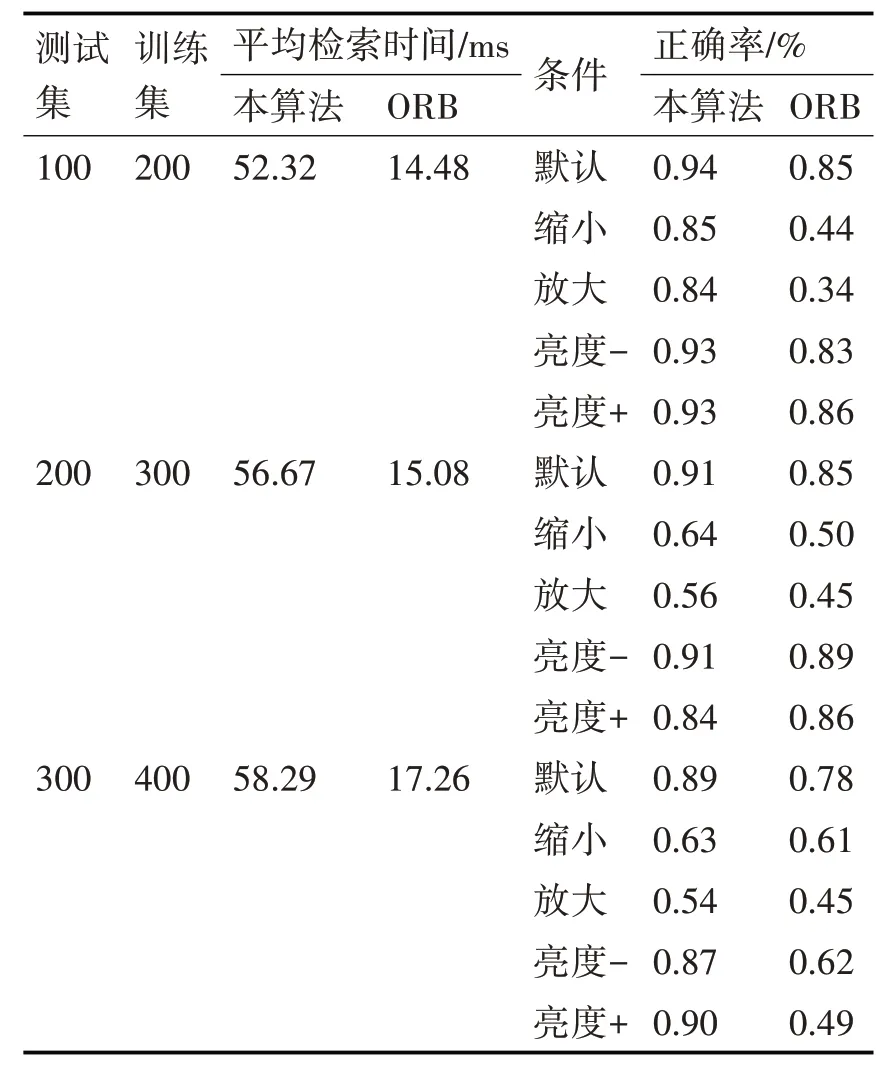
表3 不同图像数量下平均检索时间、准确率变化
实验结果表明,本文算法在光照、尺寸变化的情况下,平均检索时间和检索正确率上达到了很好的平衡,并且随着训练集数量的增加,性能没有出现明显下降。为后续增强现实系统中的跟踪注册、实时渲染提供了良好基础。
4.2 主观评估
为验证系统的有效性,邀请40 名测试人员,均是西南科技大学的学生,通过图书馆和艺术馆中书画的作者姓名、创作时间(出版年)、书画名称、出版社和摘要(历史意义)等方面和首次加载AR 模型的响应时间、识别书画的准确性、交互效率和界面布局等来评估系统的有效性(系统是否能帮助用户快速理解图书馆和艺术馆中书画的相关信息)。得分越高,表示满意度就越高,分数从0~10 表示。评分结果如表4所示。
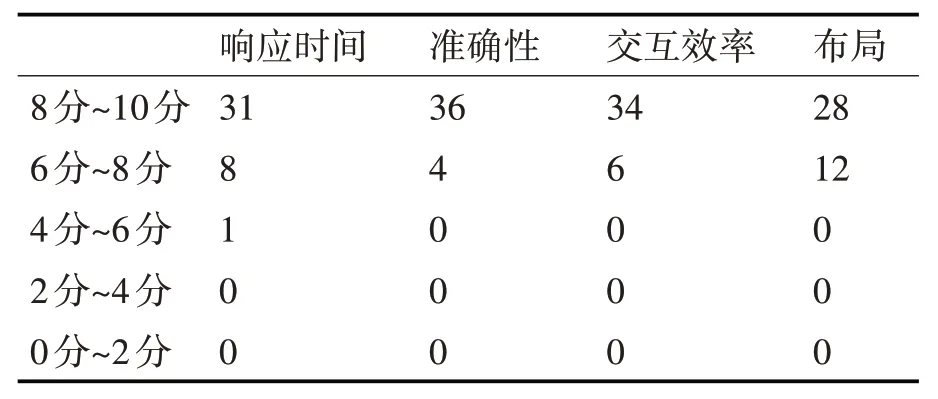
表4 用户满意度评估
表4 的统计结果说明了该系统可以有效地帮助用户快速理解内容,提升对书画的了解程度。不仅符合用户在观看书画时搜索作者、书本摘要(历史意义)的习惯,也体现出系统满足了用户对于实时性和交互效率方面的需求,因此该评估间接验证了系统的有效性。
5 结语
本文面向图书馆、艺术馆、美术馆等应用场景,提出了一种基于AKAZE的融合位置信息的视觉词汇树检索算法,在平均检索时间和检索正确率上达到了很好的平衡,对于较大规模的数据集,仍具有良好的适用性。以此为基础构建了WebAR 展示系统,实验结果表明,本系统在明暗变化、尺度缩放等情况下能保持很高的检索准确率和较低的平均检索时间,具有良好的实时性和鲁棒性,提升了WebAR的互动性,可以进一步应用在室内外以及更复杂的交互环境中。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
意林图解作文(小学版)(2019年6期)2019-07-16
中国交通信息化(2018年5期)2018-08-21
太空探索(2016年5期)2016-07-12
专利代理(2016年1期)2016-05-17
时代英语·高三(2014年5期)2014-08-26
质量与标准化(2010年5期)2010-05-03
