
ChatGPT支持的学生论证内容评价与反馈
2023-07-26 00:31:30王丽李艳陈新亚徐翎衲
现代远程教育研究 2023年4期
王丽 李艳 陈新亚 徐翎衲
摘要:在论证式教学中,由于学生生成的论证内容量大且复杂,教师评价与反馈往往滞后且难以保证质量。生成式人工智能聊天工具ChatGPT的出现为解决该问题提供了可能。与ChatGPT互动的质量取决于提问设计,如何向其提问成为获得有效反馈的关键。基于“初始提问”和“优化提问”两种提问设计,利用ChatGPT对50份学生论证内容进行评价与反馈,从反馈精准度和反馈类型两方面对其效果展开实证比较发现:“优化提问”下ChatGPT的反馈精准度(含精确度和召回率)高于“初始提问”,但在两种提问设计下的反馈召回率均低于精确度,且在量化评价维度上的精准度表现优于质性评价维度;基于两种提问设计,ChatGPT均能针对论证内容生成任务型反馈、过程型反馈、建议型反馈和情感型反馈,但相较于“初始提问”,其基于“优化提问”所生成的反馈更具组织性、解释性和针对性,而两种提问设计下的情感型反馈均表现出“就事论事”“中庸”的特点。为有效发挥ChatGPT在教学评价与反馈中的潜能,教师需做好提问设计,发挥其在情感反馈上的优势,并对机器反馈进行把关,同时注重培育学生的反馈素养。
关键词:ChatGPT;教学评价;教学反馈;论证式教学;提问设计
中图分类号:G434 文献标识码:A 文章编号:1009-5195(2023)04-0083-09 doi10.3969/j.issn.1009-5195.2023.04.010
一、引言
由OpenAI推出的生成式人工智能(Artificial Intelligence Generated Content,AIGC)聊天工具ChatGPT,自发布以来引发了教育界的持续热议。作为一种基于大规模语言模型的智能对话系统,ChatGPT采用提示学习与人类反馈相结合的训练方式,能够根据提问提供多轮次、流畅、自然的回答。这种基于自然语言的对话能力使其在教学评价与反馈中具备良好的应用潜力,能够对文本类型的学生作业进行评分和反馈,从而在减轻教师教学负担的同时,为学生提供更加个性化和便捷的学习体验(Guo et al.,2023;王佑镁等,2023;钟秉林等,2023)。可以预见,ChatGPT基于用户提问进行个性化知识生产的能力(沈书生等,2023),有可能颠覆以往“搜索就是学习”的模式,将古老的对话式学习重新带回当下的教育生态之中,而学生与ChatGPT对话沟通的能力将直接影响其学习效果与质量(焦建利,2023)。这也意味着如何向ChatGPT提问变得尤为重要——只有好的提问设计,才能激发ChatGPT生成质量较好的回答(Liu et al.,2023)。因此,有学者开始探索如何针对ChatGPT进行提问设计,并指出提问应结合领域知识,相较于一般性的提问,具体、明确的提问更能激发ChatGPT生成高质量的回答(White et al.,2023)。
论证式教学是指教师将论证活动引入课堂,让学生经历类似科学家的评价资料、提出主张、为主张进行辩驳等过程,从而培养学生的科学思维方式(何嘉媛等,2012)。论证式教学有助于学生进行知识建构、培养学生的论证能力和批判性思维能力(彭正梅等,2020)。然而,在传统的论证式教学评价中,由于学生在论证过程中生成的论证内容量大且复杂,教师需耗费大量时间甄别和梳理出论证内容中的评价要点,受到时间、精力、个人经验的限制,评价与反馈往往滞后且难以保证质量,容易出现评价要点遗漏以及反馈单一、片面、过于主观等问题。
鉴于此,本研究尝试使用ChatGPT对论证式教学中的学生论证内容进行评价和反馈。考虑到提问设计对ChatGPT反馈质量的影响,本研究借鉴前人文献中的提问设计原则,结合论证式教学评价的现实经验,尝试设计两种提问(“初始提问”和“优化提问”),比较ChatGPT在不同提问设计下对论证内容的评价与反馈存在何种差异,由此探索其在教学评价中的应用潜能,为AIGC技术和工具融入未来教育教学提供思路和参考。
二、文献综述
1.论证内容评价研究
所谓“论证”,是一种沟通和互动的活动,即论证者通过提供证据来证明其主张成立的过程,目的是消除受众之间的意见分歧(Van Eemeren et al.,1987)。图尔敏论证模型为论证内容的评价提供了基本依据。该模型由六要素构成,分别是:主张、论据、理据、支持、限定和反驳(Toulmin,1958)。一般认为论证结构中包含的要素越多,内容越复杂,论证的质量越好(Bell et al.,2000)。然而,有学者指出,利用图尔敏论证模型评价论证内容时,难以明确地区分以上六要素,尤其是界限较为模糊的论据、理据、支持三要素(Voss et al.,2001);另外,图尔敏论证模型更关注论证的结构而非论证的具体内容,且没有考虑特定人群和场景(Erduran et al.,2004)。
针对教育场景,已有研究将图尔敏论证模型中的要素进行优化,提出了不同形式的论证内容评价标准。库恩(Kuhn,1991)认为完整的论证结构应该包括三个部分:主张的陈述,指对某事所持的观点或态度;可靠的证据,用以支持主张的相关证据;推理的过程,用以解释主张与证据之间的因果关系。库恩等(Kuhn et al.,1997)认为评价论证内容的质量应从论证的功能性出发,功能性较好的论证能够对某事做出明确的判断,并给出可靠的证据和合理的解释,功能性较弱的论证则反之。库恩(Kuhn,2010)还特别關注论证过程中的反驳,认为反驳是评估论证内容质量的重要指标。克拉克等(Clark et al.,2008)同样强调反驳的重要性,但更强调解释或推理的充分性以及证据的充分性,认为高水平的论证内容应该包含充分的解释以及合理的证据。萨德勒等(Sadler et al.,2006)认为评价学生的论证内容需关注主张的合法性,为此,应通过提供足够的证据以及合理的解释使主张更具说服力。
此外,一些学者关注论证内容的完整性,依据论证内容所包含的观点、证据、反驳的次数对论证内容做出评价。泽德勒等(Zeidler et al.,2003)将论证内容的质量由低到高分为5个等级:第1级只包含观点;第2级由观点和至少一个证据组成;第3级由观点、至少一个证据和反驳组成;第4级由观点、多个证据和至少一个反驳组成;第5级由观点、多个证据和多个反驳组成。林树生(Lin,2014)让学生总结新闻观点并写出反驳理由,在对学生论证内容进行评分时,强调反驳次数越多则论证内容越清晰,因此加入了对反驳次数的计分。
通过以上文献梳理发现,现有对论证内容的评价存在质性评价与量化评价两种形式:质性评价强调论证内容的合理性,从解释充分性与证据充分性等方面进行评价;量化评价关注论证内容的完整性,依据论证内容中所包含的观点、证据、反驳的数量进行评价。
2.教学反馈有效性研究
教学反馈是指针对学习者的行为或表现提供的信息,使学习者能够了解当前学习状态,改进学习进程,缩小与学习目标之间的差距(Sadler,1989)。已有研究将教学反馈分为不同的类型,来探究其效果。利萨科夫斯基等(Lysakowski et al.,1982)通过对54个研究进行元分析,发现纠正性反馈是一种非常有效的反馈类型,它能够根据任务完成情况或学生行为表现,指出学生在特定任务中哪里做得对,哪里做错了,以便学生能够修正错误,提高学习效果。哈蒂等(Hattie et al.,2007)通过元分析发现,有效的教学反馈往往与任务目标相关,并基于此提出了有效的教学反馈应该回答的三个基本问题:一是“任务的目标是什么”,即帮助学生明确学习目标与评价标准;二是“目前进展如何”,即帮助学生了解执行学习任务过程中的行为表现和任务进展情况,及时发现问题并改进;三是“接下来该怎么做”,即为学生提供具体的指导与建议,支持其发展自我调节能力,以完成更高的学习目标。同时,哈蒂等强调自我调节型反馈是一种有效的反馈类型,能够为学生提供学习策略、认知层面更高的目标与建议(Hattie et al.,2007)。此外,情感反馈因其能够促进学生的学业表现和学习动机,也被认为是一种有效的反馈类型(Nelson et al.,2009)。情感反馈可分为表扬性反馈和批评性反馈:表扬性反馈有助于促进学业表现、提高学习动机、增强自信心和消除学业焦虑(Duijnhouwer,2010);批评性反馈则能够帮助学习者反思当前的学习表现并制定更高的学习目标,特别是当学习者面对并不热衷的学习任务时,批评性反馈更有助于其获得学习动力(Van-Dijk et al.,2000)。
随着在线教育的推广与普及,在线学习环境下的机器反馈质量及其评估日益受到关注。精准度是评估机器反馈质量的重要标准,具体包括精确度和召回率。两者均以人工标注为“金标准”,精确度是指系统正确识别出的人工标注项数除以系统识别出的总项数,召回率是指系统正确识别出的人工标注项数除以人工标注的总项数(Hoang et al.,2016)。精确度和召回率越高,则表明机器反馈的质量越好。通常情况下,精确度达到90%~100%被认为是可接受的阈值范围;相对于不能识别出更多的人工标注,错误的反馈可能对学生产生更大的负面影响,因此精确度比召回率更受重视(Chodorow et al.,2010)。
三、研究目的与问题
学界普遍认为,与ChatGPT互动的质量取决于提问设计,即好的提问设计会激发ChatGPT生成质量较好的回答。因此,本研究尝试通过“初始提问”和“优化提问”两种提问设计,从精准度和反馈类型两个层面来分析ChatGPT对大学生论证内容评价与反馈的效果和质量差异。“初始提问”指的是研究者参考论证内容评价标准,同时基于自身多年的教学经验进行的首次提问;“优化提问”指的是研究者在获得“初始提问”的反馈信息后,基于初始提问进行优化后的提问。研究通过对以上两种提问设计下ChatGPT产生评价和反馈内容的比较,来探究不同的提问设计下ChatGPT对学生论证内容的评价与反馈效果有何差异,具体问题包括:(1)基于“初始提问”与“优化提问”,ChatGPT对学生论证内容的反馈精准度有何差异?(2)基于“初始提问”与“优化提问”,ChatGPT对学生论证内容会产生哪些类型的反馈?这些反馈类型各自有什么特点?
四、研究设计
1.研究对象
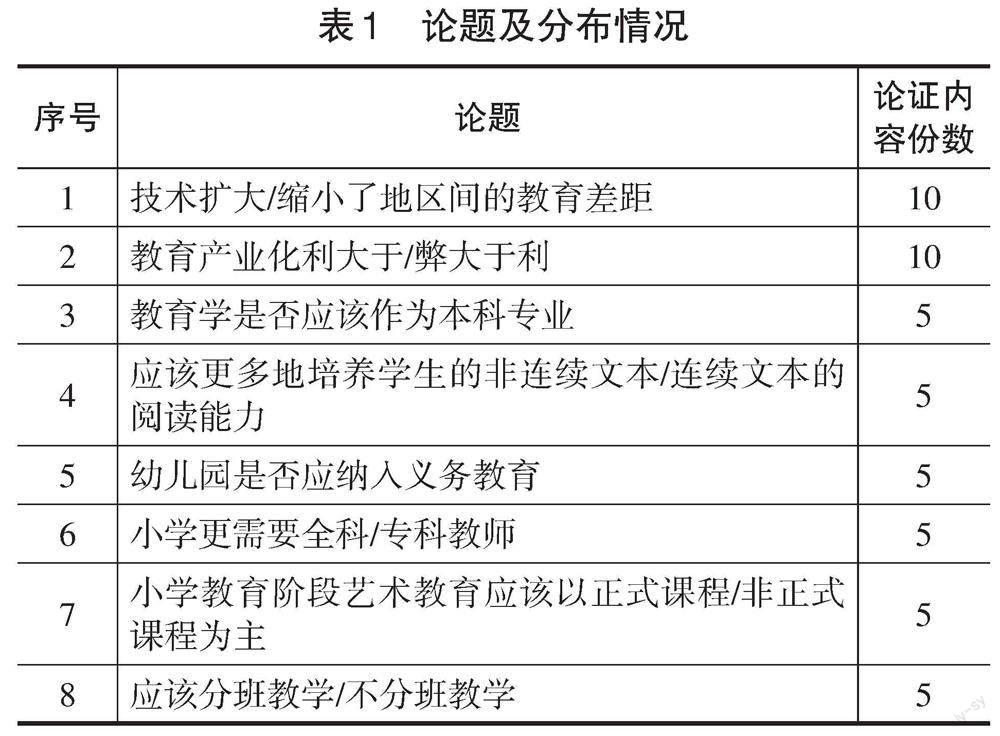
本研究以Z校42名大二本科生在“浙大语雀”平台上完成的50份论证内容为评价样本。所有学生以自由组合的方式分为10个4~5人的论证小组,每两组(分为正反方)在“浙大语雀”的辩论区进行论证,历时8周。期间,由A教师引导学生选定论题,并制定学习目标。学生围绕表1所示的8个论题进行论证,共产生50份论证内容,共计约8.4万字,其中,短篇论证内容(800~1300字)13份,中篇论证内容(1300~1800字)16份,长篇论证内容(1800~2300字)21份。论题及分布情况如表1所示。
2.提问设计
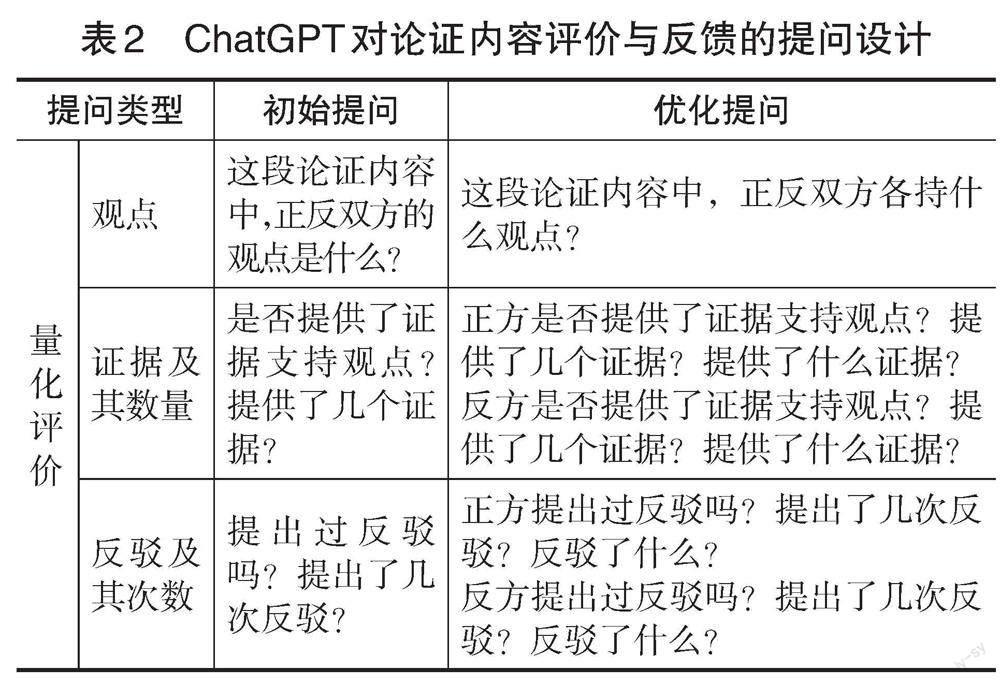
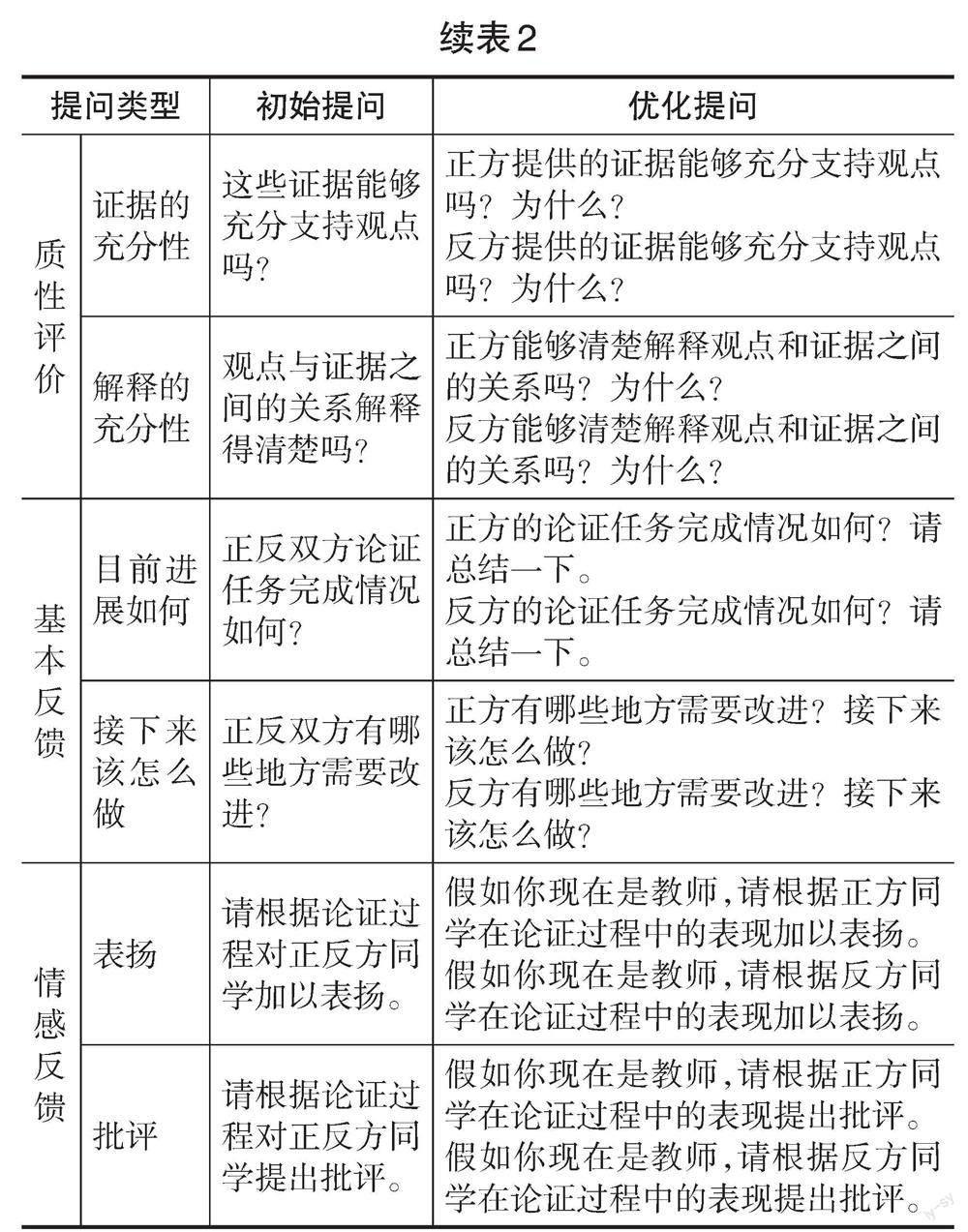
研究者采取以下四个步骤进行提问设计:(1)参考泽德勒等人(Zeidler et al.,2003)和库恩等人(Kuhn et al.,1997)的评价标准,分别从量化评价和质性评价两个方面进行提问设计。其中,量化评价的维度包括有无观点、有无证据及其数量、有无反驳及其次数;质性评价的维度包括证据的充分性、解释的充分性。(2)参考哈蒂等人(Hattie et al.,2007)所提出的有效反馈须回答的三个问题设计提问,即“任务的目标是什么”“目前进展如何”“接下来该怎么做”,考虑到任务目标的设定已在论证活动开始前完成,因此,研究只针对后两个问题进行提问设计。(3)参考尼尔森等人(Nelson et al.,2009)对表扬性反馈与批评性反饋的研究,要求ChatGPT做出表扬性与批评性反馈。(4)基于以上三个步骤,研究者首先完成了“初始提问”设计,并在获得“初始提问”的反馈信息后,再根据怀特等人(White et al.,2023)的“提示语模式分类框架”对初始提问进行优化,产生“优化提问”设计,具体采用指明所问对象、不断追问、设定角色三种优化策略。根据以上程序,最终确定了如表2所示的“初始提问”与“优化提问”两种提问设计。
3.数据收集与分析
(1)ChatGPT的反馈信息收集
基于两种提问设计,研究者将50份学生论证内容(编号为A01至A50)依次输入ChatGPT获取其对论证内容的反馈信息。具体操作程序如下:研究者首先将论证内容与“初始提问”合并输入ChatGPT,逐一获得反馈信息后,将反馈信息录入Excel文档,获得50份ChatGPT对论证内容的反馈信息(编号为P1F1至P1F50);接着遵循前人文献中反馈单元的拆分操作程序(Hayes et al.,2010),将反馈信息拆分为586个反馈单元;遵循同样的步骤,研究者基于“优化提问”获得50份反馈信息(编号为P2F1至P2F50),并将其拆分为965个反馈单元。
(2)对论证内容的标注与分析
为了建立客观科学的论证内容检验标准,研究者与A教师合作对50份学生论证内容进行标注,操作程序如下:首先,研究者与A教师参考泽德勒等人(Zeidler et al.,2003)和库恩等人(Kuhn et al.,1997)的评价标准,先抽取5份论证内容,分别对其中的观点、证据及数量、反驳及次数、证据的充分性和解释的充分性等评价要点进行标注;随后,研究者与A教师比对标注结果,对不一致的标注进行协商并达成共识;最后,研究者与A教师独立对其他论证内容进行标注。经一致性计算发现,论证内容评价要点的标注一致性达到0.81,表明人工标注结果较为准确。
研究者将ChatGPT对两种提问设计的反馈信息与学生论证内容的人工标注结果进行逐一比对,根据观点、证据、反驳、证据的充分性、解释的充分性进行分类统计,计算出两种提问设计下,ChatGPT对论证内容反馈的精确度和召回率。本研究对精确度和召回率的计算以人工标注结果为金标准,即精确度为ChatGPT正确识别出的人工标注项数除以其识别出的总项数,召回率为ChatGPT正确识别出的人工标注项数除以人工标注的总项数。
(3)反馈类型的扎根分析
研究者分别将ChatGPT对“初始提问”和对“优化提问”的反馈信息分别输入Nvivo 12进行编码分析。具体步骤如下:首先,对反馈信息进行开放式编码,即对反馈信息进行逐句归纳与总结,提炼出初始概念;接着,对初始概念进行主轴式编码,将初始概念归纳为范畴化类属;最后,对所有类属进行分析与比较,梳理出两种提问设计下ChatGPT针对学生论证内容所生成的反馈类型及其差异。
五、研究发现
1.基于两种提问设计的反馈精准度比较
基于两种提问设计,ChatGPT对学生论证内容的反馈精准度如表3所示。整体而言,“优化提问”的反馈精确度(91.8%)与召回率(63.2%)高于“初始提问”的反馈精确度(79.6%)与召回率(38.4%)。可见,ChatGPT对论证内容的反馈精准度受到提问设计的影响。
具体来看,“初始提问”的反馈中,观点的反馈精确度达100%,其次是证据及其数量(88.2%)、反驳及其次数(81.3%),证据的充分性与解释的充分性相对偏低,分别是68.0%与53.0%。“优化提问”的反馈中,观点的反馈精确度达100%,其次是证据及其数量(95.8%)、反驳及其次数(91.0%),最后是证据的充分性(85.3%)与解释的充分性(85.0%)。可见,两种提问设计下,ChatGPT对论证内容的量化评价表现均优于质性评价表现。
然而,从反馈的整体召回率来看,“优化提问”只有63.2%,这意味着36.8%的评价要点没有被识别。具体来看,观点的反饋召回率最高(100%),其次是证据及其数量(89.2%)与反驳及其次数(75.9%),在证据的充分性和解释的充分性两方面的召回率均较低,分别是47.4%和29.8%。相较而言,“初始提问”反馈的整体召回率更低,只有38.4%,这说明ChatGPT忽略了61.6%的评价要点。基于“初始提问”,ChatGPT在观点上的反馈召回率高达100%,其次是证据及其数量(53.9%)与反驳及其次数(36.8%),证据的充分性与解释的充分性的反馈召回率仅有22.2%和18.6%。这意味着基于“初始提问”,ChatGPT没有识别出绝大多数论证内容中的质性评价要点。总体而言,ChatGPT对论证内容评价的反馈召回率还有较大的提升空间。
2.基于两种提问设计的反馈类型比较
通过对两种提问设计的反馈信息进行梳理与分析,研究发现ChatGPT生成的反馈信息包括4种类型:任务型反馈、过程型反馈、建议型反馈和情感型反馈。在两种提问设计下,上述4类反馈的占比情况如表4所示。整体上看,两种提问设计下的各类反馈占比差异不大。研究分别对两种提问设计下的4类反馈信息进行比较后发现,相较于“初始提问”下的反馈信息,“优化提问”下的反馈信息更具组织性、解释性和针对性,而两种提问设计下的情感型反馈均表现出“就事论事”“中庸”的特点。
(1)任务型反馈
任务型反馈是ChatGPT针对论证任务的完成情况所做出的评价与反馈。相较于“初始提问”,基于“优化提问”生成的任务型反馈更能按照一定的逻辑顺序梳理和列举出论证内容的评价要点,总结和提炼出论证内容的基本框架,呈现出更强的组织性。例如,基于“优化提问”,ChatGPT针对论证内容A30输出的反馈中,首先对正反双方观点进行陈述,接着列举出正反双方所提供的观点以及证据、反驳及其数量。“正方观点:幼儿园不应该被纳入义务教育。反方观点:幼儿园应该被纳入义务教育。正方提供了三个证据支持观点:学前教育产品的部分私有性与义务教育产品为纯公共产品存在冲突;幼儿园教育的成本不应且不能做到政府单方面承担,而应由家庭、社会各方面分担;强制进行幼儿园教育不利于部分幼儿成长。反方提供了两个证据支持观点:幼儿园员工招聘参差不齐;学前教育产品本质上拥有更多的公共产品特征。正反双方都提出了反驳,各提出了至少一次反驳。”(P2F30)同样是针对A30,ChatGPT根据“初始提问”所给出的反馈虽然能够明确指出正反方观点,但却将正反方证据混为一谈。“这段论证内容存在明确的观点,正方认为幼儿园不应纳入义务教育,反方认为幼儿园将来一定会纳入义务教育的范畴。这段论证内容提供了多个证据支持观点,例如幼儿园师资、质量和设备的不足,家长选择学前教育机构的私人性质等。”(P1F30)
除此之外,ChatGPT输出的任务型反馈还表现为对论证任务的完成情况进行了总结性评价。根据“优化提问”,针对A14的反馈中,ChatGPT对双方的任务完成情况做出了总结。“正方的论证比较全面,既强调了教育学的重要性,也回应了反方的质疑和批评。反方的论证较为简单和片面,没有很好地回应正方的质疑和批评,也没有提出充分的证据来支持自己的观点。”(P2F14)相应地,基于“初始提问”,ChatGPT对A14所做出的反馈并未具体指出双方各自的任务完成情况。“双方都完成了他们的论证任务,虽然其中可能存在一些可以改进的地方。”(P1F14)
(2)过程型反馈
过程型反馈是ChatGPT针对论证学习目标实现的过程所做出的评价与反馈,具体包括针对证据使用情况、推理过程的反馈信息。基于“优化提问”,ChatGPT所生成的过程型反馈能够针对证据使用情况、推理过程进行评价与反馈,且能够给出合理的解释,呈现出较强的解释性。例如,ChatGPT针对论证内容A10输出的反馈中提到:“双方观点和证据之间的关系解释得较为清楚,但反方提到的一些证据并不能完全支持其观点,例如非洲地区的互联网使用率的例子并没有直接证明技术的发展能够缩小教育差距。”(P2F10)如P2F10所示,ChatGPT所提供的过程型反馈不但能够对证据使用情况和推理过程进行评价,并且能够通过举例的方式来解释证据的充分性。而基于“初始提问”的反馈并未给出明确的解释,相对笼统。“这些证据部分能够支持观点,但还不够充分,正反双方需要更多的数据和事实来支持这个观点。”(P1F10)
(3)建议型反馈
建议型反馈是ChatGPT在对学生论证内容进行分析与评价的基础上,提出的具有针对性的建议类反馈。基于“优化提问”,ChatGPT输出的建议型反馈涉及论证内容中多个要素,包括观点、证据、反驳、证据的使用情况以及推理过程等,可以识别出论证过程中存在的问题和不足,能够为学生提供更有针对性和更具个性化的指导和建议。例如,“正反双方可以在论证过程中提出更多的反驳,进一步强化自己的观点。例如,反方可以提出更多的反驳来回应正方关于评价体系和学业压力的担忧,正方可以提出更多的反驳来回应反方关于多样化需求的担忧。”(P2F50)从P2F50来看,ChatGPT根据论证内容,建议正反双方分别以“反方关于多样化需求的担忧”和“正方关于评价体系和学业压力的担忧” 为切入口进行反驳。这说明ChatGPT能够理解反驳在论证过程中的作用,可以结合论证内容的具体情况,为正反双方提供具有针对性和个性化的建议,帮助他们更好地运用反驳策略和方法,强化自己的观点,提高论证的说服力和效果。然而,基于“初始提问”,ChatGPT生成的建议型反馈常会流于表面,没有具体和有深度的内容。例如,“正反双方需要更清晰地说明观点和证据之间的关系,提供更多证据来支持观点。同时,正方需要更明确地对反方观点进行反驳。”(P1F50)
(4)情感型反馈
根据提问设计,ChatGPT能够针对学生论证内容做出包括表扬性反馈和批评性反馈的情感型反馈,但此类反馈也表现出“就事论事”的特点。例如,基于“优化提问”,针对论证内容A22生成的表扬性反馈中,ChatGPT先以教师的口吻,对正反方同学加以鼓励,随后对正反方同学的论证表现加以总结,最后就双方的能力优势加以肯定。“作为教师,我要为正反方同学的表现点个赞。正方同学在陈述观点时运用了大量的数据和案例,凸显了独立思考和自主学习的能力。反方同学也在论证中采用了大量的个人经验,体现了对现实问题的理解和思考。这些都是优秀论证所需要的要素,值得肯定和表扬。”(P2F22)相比之下,在“初始提问”的反馈信息中,虽然出现了“值得肯定”“值得表扬”“讨论得很好”等类似于教师在评价过程中常用来表达情感的语句,但ChatGPT更多关注论证内容中观点的优劣,而非关注正反方的论证过程、策略及个人表现。例如,“正方主张应该更多地培养学生阅读非连续性文本的技能,并指出非连续性文本阅读具有明显的实用性,正方的观点值得表扬。反方认为小学生对文字的理解能力较差,非连续性文本对学生阅读要求较高,不适宜编写进课本进行统一教授,反方的观点值得部分肯定。”(P1F22)
两种提问设计下,ChatGPT所生成的批评性反馈数量较少,且遵循一种“中庸之道”,鲜少有明显的情感表达,类似于一种“建议性”的批评。例如,在要求ChatGPT针对论证内容A16给出的批评性反馈中,基于“优化提问”其反馈“正方同学在反驳反方同学的观点时,存在不够全面、甚至是一些错误的理解和表述,在今后的辩论中,正方同学需要更加注重论据的准确性和全面性,同时需要更好地理解和反驳反方同学的观点”(F2F16);基于“初始提问”则反馈“正方同学在辩论过程中存在过于僵化的现象,只是坚守自己的观点,缺乏对反方观点的充分理解和对话。在未来的论证中,建议正方同学更开放地接受对方的观点,积极地展开对话。”(F1F16)
六、研究结论与启示
1.研究结论
通过比较两种提问设计下ChatGPT对学生论证内容的评价与反馈效果,得出以下结论:
第一,ChatGPT对学生论证内容的反馈精准度受到提问设计的影响,良好的提问设计有助于ChatGPT生成質量较好的反馈。首先,基于“优化提问”的反馈精准度高于“初始提问”,这说明根据提问设计原则,采用指明所问对象、追问、设定角色等策略能够有效地提高ChatGPT生成回答的质量(White et al.,2023)。其次,基于“优化提问”,ChatGPT对论证内容评价的精确度已达到智能反馈工具的有效阈值范围(90%~100%)(Burstein et al.,2003),这说明良好的提问设计有助于ChatGPT针对论证内容做出较为准确的评价。尽管两种提问设计下的反馈召回率相对偏低,但也已超过多个智能反馈工具的召回率(Dikli et al.,2014;Hoang et al.,2016;Liu et al.,2016)。以往的智能反馈工具多运用自然语言处理和机器学习技术,通过基于已有语料库的训练和学习,为学生提供评价与反馈。这些工具高度依赖于人工标注,只能针对特定情境进行反馈,例如错别字、标点格式、句式语法等可以指定语义特征的文本,其适用范围受到局限。相比之下,ChatGPT因其基于大语言模型构建的优势,对文本具有更强的理解能力。因此,ChatGPT较少受到论证内容主题的限制,能够通过理解论证内容的上下文,从中提取观点、证据、反驳等评价要点,在评价过程中表现出良好的潜力。总体上看,两种提问设计下,ChatGPT对论证内容的量化评价表现均优于其对论证内容的质性评价表现。这反映出ChatGPT在本质上依然是一个语言模型,其底层工作原理基于数学概率,当面对“证据是否充分”和“解释是否充分”等问题时,ChatGPT遵循一种“中庸之道”,从文本数据中提取更为常见和能被普遍接受的观点以提高答案的适用性。ChatGPT虽然在某些方面表现出良好的性能,但它仍然难以像人一样充分理解信息与分析信息的内在逻辑关系,因此会生成不合理甚至违反事实的错误回答。这也反映出生成式人工智能的运算过程仍然是“黑箱”,其生成的内容不具备可解释性与明确的依据(卢宇等,2023)。
第二,基于两种提问设计,ChatGPT能够生成包括任务型反馈、过程型反馈、建议型反馈和情感型反馈在内的四类反馈信息。相较于“初始提问”,ChatGPT基于“优化提问”所生成的各类反馈信息更具组织性、解释性和针对性,具体表现为:在任务型反馈方面,基于“优化提问”,ChatGPT能够针对论证内容提供更为具体、准确的反馈信息,帮助学生了解论证学习目标的完成情况,这种针对任务细节做出的反馈能够帮助学生建立对当前学习状态的认知,是学生进行自我调节学习的基础(Lysakowski et al.,1982)。在过程型反馈方面,基于“优化提问”,ChatGPT生成的反馈信息能够针对证据使用情况、推理过程进行评价与反馈,且能够给出合理的解释,有助于促进学生重新评估并调整论证策略,进而促进他们进行自我反思、调整计划并提高达成任务目标的可能性(Carver et al.,1990)。在建议型反馈方面,ChatGPT基于“优化提问”的反馈信息具有个性化、可操作性强等特点,有利于提高学生的自我调节能力和自我效能感,帮助学生实现更高的任务目标。已有研究指出,有效的建议型反馈不但能够提出策略层面的更高目标与建议,还能够改善通常反馈只关注当前问题的局限性,把目标扩展到更加关注学习者长远发展的全局视野(Hattie et al.,2007;董艳等,2021)。不过,值得注意的是,在情感型反馈方面,ChatGPT虽然能够针对论证内容提供此类反馈,但无法像人类教师那样关注到学生的日常表现和情感需求,给出真正具有意义的表扬或批评。然而,情感型反馈是教育中至关重要的因素,它不仅涉及师生之间的有效互动和协作,还直接关系到学生的学习情绪和心理状态,对于促进学生的情感投入和提高教学效果至关重要(Nelson et al.,2009;Duijnhouwer,2010)。虽然ChatGPT可以在文字层面上生成某些情感反馈内容,例如语气词、表情符号、情感词汇等,但是这些反馈缺乏情感深度,距离真正有价值的情感反馈还有较大差距。
2.研究启示
基于以上研究发现,针对ChatGPT等AIGC技术和工具应用于教学评价与反馈的可能潜力,本研究得出以下两方面的启示:
第一,教师需扮演好“提问设计者”角色,注重发挥在情感反馈上的优势,并做好机器反馈的“把关人”。首先,在将AIGC工具应用于教学评价与反馈的过程中,教师应当扮演好“提问设计者”的角色,通过优化提问设计来充分发挥AIGC工具的潜能,使其更为准确地生成反馈信息。例如,教师在使用ChatGPT对学生论证内容进行评价时,需结合评价标准以及教学情境进行提问设计,通过指明所问对象、不断追问、设定角色等优化策略对提问设计进行迭代优化,以确保提问设计的针对性和实用性。其次,教师应注重补充情感型反馈与前馈。在将AIGC工具融入教学评价时,教师需强化在情感反馈上的优势,成为“情感型反馈专家”;由于机器反馈更关注学生当前的学习状态和效果评估(董艳等,2021),AIGC工具也只能针对实际的学习成果(如文本)生成反馈,却无法关注到学习任务之前学生的表现,因此教师应注重补充前馈(董艳等,2023),帮助学生获得全方位的评价与反馈。最后,教师应做好机器反馈的“把关人”。例如,在利用ChatGPT对学生论证内容进行评价时,教师需要将精力转移到对反馈信息的评估、筛选与完善中去,基于反馈信息进行再反馈,进而提升反馈的质量和效果。
第二,学生需提升反馈素养,以便可以更加积极主动地参与到学习评价环节中并从中获益。反馈素养是指学生理解、解释和应用反馈信息的能力,它能保证学生更好地利用反馈信息达到提高学习效果的目的。首先,AIGC工具能够为学生提供实时、大量且多元的反馈信息,这需要学生具备较高的反馈素养,才能快速地理解这些反馈信息并对学习策略进行有效的调整。其次,将AIGC工具应用于教学评价与反馈,也要求学生主动参与评价过程,能够基于反馈进一步提出问题和寻求帮助。提升学生反馈素养有以下三种路径:一是教学过程中加强对学生反馈素养的培养,引导学生更好地理解、解释和应用人机反馈的各种有价值信息。二是组织开展有针对性的培训,指导学生正确解读反馈信息,掌握根据反馈信息调整学习策略的方法。三是为学生创建反馈词汇表、反馈信息指南等工具,有针对性地解决学生在理解反馈中可能遇到的困难。
参考文献:
[1]董艷,李心怡,郑娅峰等(2021).智能教育应用的人机双向反馈:机理、模型与实施原则[J].开放教育研究,27(2):26-33.
[2]董艳,吴佳明,赵晓敏等(2023).学习者内部反馈的内涵、机理与干预策略[J].现代远程教育研究,35(3):55-64.
[3]何嘉媛,刘恩山(2012).论证式教学策略的发展及其在理科教学中的作用[J].生物学通报,47(5):31-34.
[4]焦建利(2023).ChatGPT助推学校教育数字化转型——人工智能时代学什么与怎么教[J].中国远程教育,43(4):16-23.
[5]卢宇,余京蕾,陈鹏鹤等(2023).生成式人工智能的教育应用与展望——以ChatGPT系统为例[J]中国远程教育,43(4):24-31,51.
[6]彭正梅,伍绍杨,付晓洁等(2020).如何提升课堂的思维品质:迈向论证式教学[J].开放教育研究,26(4):45-58.
[7]沈书生,祝智庭(2023).ChatGPT类产品:内在机制及其对学习评价的影响[J].中国远程教育,43(4):8-15.
[8]王佑镁,王旦,梁炜怡等(2023).“阿拉丁神灯”还是“潘多拉魔盒”:ChatGPT教育应用的潜能与风险[J].现代远程教育研究,35(2):48-56.
[9]钟秉林,尚俊杰,王建华等(2023).ChatGPT对教育的挑战(笔谈)[J].重庆高教研究,11(3):3-25.
[10]Bell, P., & Linn, M. C. (2000). Scientific Arguments as Learning Artifacts: Designing for Learning from the Web with KIE[J]. Intrnational Journal of Science Education, 22(8):797-817.
[11]Burstein, J., Chodorow, M., & Leacock, C. (2003). CriterionSM Online Essay Evaluation: An Application for Automated Evaluation of Student Essays[C]// Proceedings of the Fifteenth Annual Conference on Innovative Applications of Artificial Intelligence. Acapulco, Mexico: Association for the Advancement of Artificial Intelligence:1-8.
[12]Carver, C. S., & Scheier, M. F. (1990). Origins and Functions of Positive and Negative Affect: A Control-Process View[J]. Psychological Review, 97(1):19-35.
[13]Chodorow, M., Gamon, M., & Tetreault, J. (2010). The Utility of Article and Preposition Error Correction Systems for English Language Learners: Feedback and Assessment[J]. Language Testing, 27(3):419-436.
[14]Clark, D. B., & Sampson, V. (2008). Assessing Dialogic Argumentation in Online Environments to Relate Structure, Grounds, and Conceptual Quality[J]. Journal of Research in Science Teaching, 45(3):293-321.
[15]Dikli, S., & Bleyle, S. (2014). Automated Essay Scoring Feedback for Second Language Writers: How Does It Compare to Instructor Feedback?[J]. Assessing Writing, 22:1-17.
[16]Duijnhouwer, H. (2010). Feedback Effects on StudentsWriting Motivation, Process, and Performance[D]. Utrecht: Utrecht University:12-62.
[17]Erduran, S., Simon, S., & Osborne, J. (2004). TAPping into Argumentation: Developments in the Application of Toulmins Argument Pattern for Studying Science Discourse[J]. Science Education, 88(6):915-933.
[18]Guo, B., Zhang, X., & Wang, Z. et al. (2023). How Close Is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection[J/OL]. https://doi.org/10.48550/arXiv.2301.07597.
[19]Hattie, J., & Timperley, H. (2007). The Power of Feedback[J]. Review of Educational Research, 77(1):81-112.
[20]Hayes, J. R., & Berninger, V. W. (2010).Relationships Between Idea Generation and Transcription: How the Act of Writing Shapes What Children Write[M]// Bazerman, C., Krut, R., & Lunsford, K. et al. (Eds.). Traditions of Writing Research. New York: Routledge:166-180.
[21]Hoang, G. T. L., & Kunnan, A. J. (2016). Automated Essay Evaluation for English Language Learners: A Case Study of MY Access[J]. Language Assessment Quarterly, 13(4):359-376.
[22]Kuhn, D. (1991). The Skills of Argument[M]. Cambridge, UK: Cambridge University Press:22-43.
[23]Kuhn, D. (2010). Teaching and Learning Science as Argument[J]. Science Education, 94(5):810-824.
[24]Kuhn, D., Shaw, V., & Felton, M. (1997). Effects of Dyadic Interaction on Argumentive Reasoning[J]. Cognition and Instruction, 15(3):287-315.
[25]Lin, S. S. (2014). Science and Non-Science Undergraduate StudentsCritical Thinking and Argumentation Performance in Reading a Science News Report[J]. International Journal of Science and Mathematics Education, 12(5):1023-1046.
[26]Liu, S., & Kunnan, A. J. (2016). Investigating the Application of Automated Writing Evaluation to Chinese Undergraduate English Majors: A Case Study of WriteToLearn[J]. Calico Journal, 33(1):71-91.
[27]Liu, P., Yuan, W., & Fu, J. et al. (2023). Pre-Train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing[J]. ACM Computing Surveys, 55(9):1-35.
[28]Lysakowski, R. S., & Walberg, H. J. (1982). Instructional Effects of Cues, Participation, and Corrective Feedback: A Quantitative Synthesis[J]. American Educational Research Journal, 19(4):559-572.
[29]Nelson, M. M., & Schunn, C. D. (2009). The Nature of Feedback: How Different Types of Peer Feedback Affect Writing Performance[J]. Instructional Science, 37(4):375-401.
[30]Sadler, D. R. (1989). Formative Assessment and the Design of Instructional Systems[J]. Instructional Science, 18(2):119-144.
[31]Sadler, T. D., & Fowler, S. R. (2006). A Threshold Model of Content Knowledge Transfer for Socioscientific Argumentation[J]. Science Education, 90(6):986-1004.
[32]Toulmin, S. E. (1958). The Uses of Argument[M]. London: Cambridge University Press:87-99.
[33]Van-Dijk, D., & Kluger, A. N. (2000). Positive (Negative) Feedback: Encouragement or Discouragement[EB/OL]. [2023-04-18].
https://scholars.huji.ac.il/testmihal/publications/gative-feedback-
encouragement-or-discouragement.
[34]Van Eemeren, F. H., Grootendorst, R., & Kruiger, T. (1987). Handbook of Argumentation Theory: A Critical Survey of Classical Backgrounds and Modern Studies[M]. Dordrecht: Springer:260-273.
[35]Voss, J. F., & Van Dyke, J. A. (2001). Argumentation in Psychology: Background Comments[J]. Discourse Processes, 32(2-3):89-111.
[36]White, J., Fu, Q., & Hays, S. et al. (2023). A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT[J/OL]. https://doi.org/10.48550/arXiv.2302.11382.
[37]Zeidler, D. L., Osborne, J., & Erduran, S. et al. (2003). The Role of Argument During Discourse About Socioscientific Issues[M]// Zeidler, D. L. (Ed.). The Role of Moral Reasoning on Socioscientific Issues and Discourse in Science Education. Dordrecht: Springer:97-116.
收稿日期 2023-04-19 責任编辑 谭明杰
Effectiveness of Feedback on StudentsArgumentation Contents Based on ChatGPT:
Comparison of Two Types of Prompt Designs
WANG Li, LI Yan, CHEN Xinya, XU Lingna
Abstract: In argumentative teaching, due to the large volume and high complexity of students argumentation contents, teachers evaluation and feedback often lag behind and are difficult to ensure the quality. The emergence of such chat tools based on generative artificial intelligence as ChatGPT provides the possibility to solve this problem. The quality of interaction with ChatGPT depends on the prompt design. How to design prompts becomes the key to obtaining effective feedback. Based on two types of prompt designs (“initial prompts”and“optimized prompt”), ChatGPT was used to evaluate and provide feedback on 50 copies of students argumentation contents. Empirical comparison was conducted on its effectiveness from two aspects: feedback accuracy and feedback type. It was found that ChatGPTs feedback accuracy (including precision rate and recall rate) under “optimized prompt” was much higher than that under “initial prompt”. The feedbacks recall rates under both types of prompt designs were lower than corresponding precision rates. The feedbacks precision rates of the quantitative evaluation dimension were higher than those of the qualitative evaluation dimension under both types of prompt designs. Based on the two types of prompt designs, ChatGPT could generate four kinds of feedback for argumentation contents: task-oriented feedback, process-oriented feedback, suggestion-oriented feedback, and emotion-oriented feedback. However, compared to feedback based on the“initial prompt”, the feedback generated based on “optimized prompt” was more organized, explanatory, and targeted. The emotion-oriented feedback under both types of prompt designs exhibits such characteristics as “confining merely to the facts” and “the doctrine of the mean”. To effectively unleash the potential of ChatGPT in teaching evaluation and feedback, teachers need to improve their prompt designs, leverage their advantages in emotion-oriented feedback, monitor feedback from ChatGPT and focus on cultivating students feedback literacy.
Keywords: ChatGPT; Teaching Evaluation; Teaching Feedback; Argumentative Teaching; Prompt Design
猜你喜欢
考试周刊(2017年7期)2017-02-06 21:12:57
课程教育研究·中(2016年11期)2017-01-04 18:21:45
未来英才(2016年1期)2016-12-26 21:17:43
电脑知识与技术(2016年24期)2016-11-14 01:43:07
考试周刊(2016年85期)2016-11-11 01:23:32
人间(2016年28期)2016-11-10 00:09:37
知音励志·社科版(2016年8期)2016-11-05 03:23:01
考试周刊(2016年76期)2016-10-09 09:08:16
考试周刊(2016年67期)2016-09-22 14:10:01
考试周刊(2016年32期)2016-05-28 20:51:43
