
混沌与对立学习正余弦算法及多阈值图像分割
2022-11-25 07:37:36杨淼
计算机工程与设计 2022年11期
杨 淼
(1.武汉科技大学 信息科学与工程学院,湖北 武汉 430080;2.常州工程职业技术学院 智能制造学院,江苏 常州 213164)
0 引 言
图像分割的目标是根据位置、纹理或灰度级将图像划分为特定区域[1],常用方法分为阈值法、区域法和边缘法[2-4]。阈值分割法具有较强鲁棒性和准确性,是图像分割的主流方法。阈值法又可以分为单阈值和多阈值。单阈值以独立阈值分割图像为前景和背景,多阈值则根据亮度信息将图像分割为若干类别。多阈值法中,Kapur熵和大津Otsu法是目前的主流方法。Kapur熵以最大化分割类别直方图熵为目标寻找最优阈值,而Ostu法则通过最大化类间方差寻找最优阈值。问题在于:随着分割阈值量的增加,分割算法时间复杂度呈现指数递增,搜索空间扩展太快。
群智能算法较强的全局寻优能力,被学者们利用于图像分割领域。如文献[5]采用PSO算法在多阈值图像分割中,文献[6]利用WOA对图像分割的多阈值进行寻优,文献[7]引入GWO设计熵最大化的多阈值图像分割算法,具有较好的全局搜索能力和收敛性能,图像分割质量更高。文献[8]引入智能ABC算法对灰度图像分割阈值进行寻优,表现良好的搜索能力。其它群智能算法[9-11]在求解多阈值图像分割问题上也展现出良好的分割性能。
正弦余弦算法SCA是一种新型群智能优化算法[12],利用正弦余弦函数的振荡波动进行全局寻优。因其参数少、结构简单且易于实现的优点,寻优性能优于遗传算法、粒子群算法和花授粉等算法。然而,处理复杂高维问题时,SCA算法依然存在寻优精度低、易得到局部最优的不足。本文将设计一种改进的正余弦算法并将其应用于多阈值图像分割问题求解问题上,并利用改进正余弦算法对分割阈值寻优,有效提升了图像分割精度和分割效率。
1 正弦余弦算法SCA
SCA算法是一种随机优化算法,利用数学中正弦余弦函数的振荡特性寻找最优解,波形向外扩展即为全局搜索,趋近最优解的波动即为局部开发。假设种群粒子数量为N,位置维度为d,第t次迭代时粒子i的位置表示为xi(t)=(xi1,xi2,…,xid)。 通过计算粒子的适应度,比较种群中粒子所处位置的优劣。令当前种群中最优粒子为pg(t)=(pg1,pg2,…,pgd), 粒子i的位置更新方式为
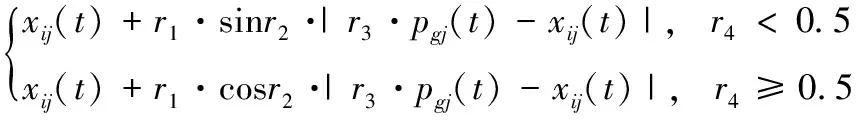
(1)
其中,j=1,2,…,d, 表示位置维度,d>0,r2∈[0,2π],r3∈[-2,2],r4∈[0,1], 3个参数均为随机量。r1为振幅转换因子,定义为
(2)
其中,Tmax为最大迭代数,a为常量,一般取值2。根据SCA算法的位置更新式(1)可知,算法的主要参数为r1、r2、r3、r4。振幅转换因子r1用于决定粒子迭代的位置区域,平衡算法的全局搜索和局部开发过程;r2用于决定粒子的移动方向,表明当前解是靠近目标解,或是远离目标解;r3用于决定目标位置的随机权重, |r3|<1 代表需要增强目标解对当前解的指导影响, |r3|>1 则代表需要削弱目标解对当前解的牵引;r4用于决定正弦函数sine()和余弦函数cosine()的随机切换概率。
2 融入混沌与对立学习机制的改进正弦余弦算法COLSCA
2.1 振幅转换因子非线性调整
SCA算法中,振幅转换因子r1的作用是平衡算法的全局搜索和局部开发过程。r1>1时,粒子处于目标位置和当前位置之外,算法倾向于全局搜索;r1<1时,粒子介于目标位置与当前解之间,算法则倾向于局部开发。而式(2)表明,r1在区间[0,a]内将随着迭代次数的增加而呈线性递减趋势,使得在迭代初期,r1取值较大,搜索步长更长,算法具有更强的全局搜索能力,但参数递减太快,全局搜索不充分,易得到局部最优;而在迭代后期,r1取值较小,递减速度慢,算法无法快速收敛。为了均衡算法的全局搜索与局部开发能力,改进算法COLSCA采用基于对数函数的非线性调整策略,将振幅转换因子r1的更新方式定义为
(3)
其中,astart、aend分别代表参数a的初值和终值,astart>aend≥0,e为自然数常量,ζ为调节系数。根据式(3),r1将呈非线性递减,前期迭代次数更多,可以提升全局搜索能力,后期迭代会加速递减,加快算法收敛,进而有效提升SCA算法的寻优精度和收敛速度。
2.2 混沌搜索机制
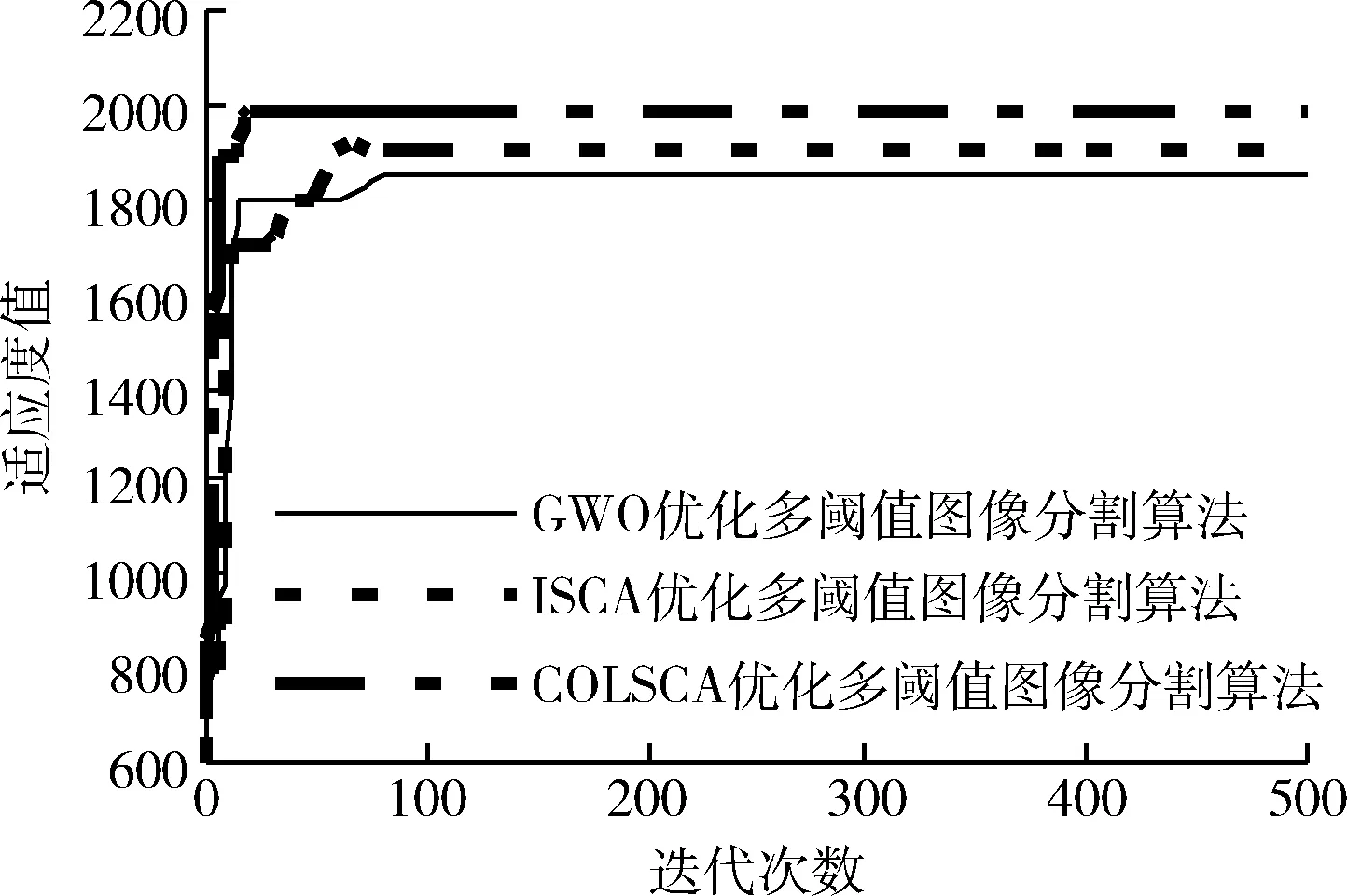
由式(1)可知,粒子位置的更新主要由精英个体(当前种群中最优粒子为pg)引导,为了提升种群的多样性,引入混沌搜索对种群的精英粒子进行混沌变异。令prob表示种群的精英粒子占比,0 eaj(t)=min(ex1j(t),ex2j(t),…,exmj(t)) (4) ebj(t)=max(ex1j(t),ex2j(t),…,exmj(t)) (5) 利用式(6)将精英粒子exi(t) 映射到区间[0,1],得到混沌变量Ci(t)=(Ci1(t),Ci2(t),…,Cij(t)), 有 (6) 利用式(7)对Cij(t)进行混沌迭代,有 Cij(k+1)=μCij(k)(1-Cij(k)) (7) 式中:k为混沌迭代数,μ为常量。 当混沌迭代次数到达最大值kmax时,可以得到种群中精英粒子i对应的混沌变量,表示为Ci(kmax)。 然后,可结合混沌变量将该精英粒子映射至区间 [eaj(t),ebj(t)], 得到相应的混沌粒子XCi(t), 具体映射公式为 XCi(t)=Ci(kmax)(ebj(t)-eaj(t))+eaj(t) (8) 根据原始精英粒子exi(t)和混沌粒子XCi(t),可得变异粒子候选解为 xi(t)′=λ·exi(t)+(1-λ)·XCi(t) (9) λ=(Tmax-t)/Tmax (10) 其中,λ为收缩因子。可见,λ将随迭代次数递减。 在侯选变异粒子与原始精英粒子间采用贪婪策略,选择适应度函数值f(·)更优的个体取代原始精英粒子,即 (11) 式中:f(·)表示适应度函数,也对应于实验分析中的基准函数(目标函数)。 根据式(9)、式(10)可知,收缩因子λ随着迭代增加而减小,此时,精英粒子exi(t)对变异粒子侯选解xi(t)′的影响将逐步降低,即代表精英粒子的边界会逐步缩小至目标解区域,侯选解xi(t)′越侧重于混沌粒子XCi(t),由于该粒子的随机性、遍历性更好,故此时局部开发能力变得更强。 对立学习可以在通过同步考虑当前解及其对立解的适应度的情况下,通过贪婪选择改善候选解的质量,提升种群多样性。为了提高SCA算法的寻优精度,进一步引入对立学习机制改进SCA算法中粒子位置的更新方式,使SCA算法的原始更新方法及对立学习机制交替执行,在确保种群多样性的同时,改善算法的寻优精度和收敛速度。 令迭代t时粒子i的位置为xi(t)=(xi1,xi2,…,xid),lj、uj分别表示j维位置上的下边界和上边界,则粒子i的对立位置为 xij(t)′=lj+uj-xij(t) (12) 若对立解xi(t)′的适应度优于原始解xi(t), 即f(xi(t)′)≥f(xi(t)), 则可以对立解替换原始解;否则,依然保留原始解在种群中。则采用对立学习机制后,种群的生成思想是:通过对立学习生成种群的N个对立解,改进算法COLSCA将在2N个种群粒子中利用贪婪选择策略选择N个粒子至下一代种群,确保较强的全局搜索能力的同时,丰富种群多样性。 以下是COLSCA算法的详细执行过程: 步骤1 参数初始化,包括:种群规模N、最大迭代数Tmax、参数a的初值astart和终值aend、调节系数ζ、精英粒子概率prob、混沌系数μ; 步骤2 种群初始化,在搜索空间内随机生成N个粒子组成初始种群,表示为NP; 步骤3 利用对立学习机制求解种群NP的对立种群NP′,计算合并种群NP∪NP′中的粒子适应度并按降序排列,选择适应度排序前列的N个粒子构成初始种群,表示为NP″;并记录当前种群生成的最优粒子x*(t); 步骤4 若迭代次数t为奇数,种群NP″根据标准SCA算法执行位置更新形成新种群(按适应度降序排列),且根据式(3)更新振幅转换因子r1;若迭代次数t为偶数,根据对立学习机制生成种群NP″的对立解,然后将原始种群NP″和对立种群合并(按适应度降序排列),选择适应度前N的粒子形成新种群; 步骤5 对步骤4中新生成的种群按精英概率prob选择精英粒子,根据混沌搜索机制对精英个体变异; 步骤6 迭代是否达到Tmax,若满足,返回步骤4;否则,输出种群最优个体(最优解)。 COLSCA算法的时间复杂度。令种群规模为N,粒子维度为d,最大迭代次数为Tmax,COLSCA算法执行主要由初始化、对立学习和混沌搜索3个部分组成。种群初始化和对立学习过程的时间复杂度均为O(N×d×Tmax), 混沌搜索需要区分奇数迭代和偶数迭代两种情形,并按概率对精英粒子进行变异,因此,该过程的最差时间复杂度也为O(N×d×Tmax)。 综上结果,COLSCA算法的最差时间复杂度为O(N×d×Tmax), 这与标准SCA算法的时间复杂度是相同的,说明改进算法COLSCA在提高寻优精度和收敛速度的同时,并未降低算法的运行效率。 令图像I具有L个灰度级,分割阈值TH={th1,th2,…,thnt} 可将图像I分割为K个类别,表示为C1,C2,…,CK, 其中,nt=1,2,…,K-1,th1 (13) 令z为给定像素的灰度级,则0 Phz=hz/CP (14) (15) 每个阈值对应的图像Kapur熵值为 (16) (17) … (18) 每个类别的累积分布函数定义为 (19) COLSCA算法以式(13)Kapur熵作为适应度函数,迭代对最优分割阈值进行寻优,具体思想是:利用COLSCA算法在给定图像的灰度空间内寻优,根据式(13)定义的Kapur熵函数评估COLSCA算法中粒子的适应度优劣,通过粒子的迭代寻优,寻找使得Kapur熵值达到最大的分割阈值TH*,并以TH*做图像分割。以下是算法具体步骤: 步骤1 读取待分割图像I,生成图像灰度直方图; 步骤2 算法参数初始化; 步骤3 生成初始种群。粒子位置矢量代表图像的灰度值组合,将矢量中的分量约定为递增序列,分量范围为灰度组范围,即[0,255],表示图像分割阈值; 步骤4 以Kapur熵函数作为适应度函数,执行COLSCA算法的寻优过程; 步骤5 判断算法迭代是否达到Tmax,若未达到,返回步骤4;否则,输出种群最优粒子,即代表分割的最优阈值TH*; 步骤6 以步骤5生成的最优阈值TH*做图像分割,并评估分割图像质量。 实验分两组进行。第一组:验证COLSCA算法的寻优性能,利用表1所示的基准函数进行测试,4个基准函数即为需要寻优最优解的目标函数,搜索空间为寻优时粒子的寻优范围,fmin为函数理论可达的最优值。f1(x)、f2(x) 是单峰函数,f3(x)、f4(x) 是多峰函数,单峰函数在整个搜索区间内只有一个极值点,利于探测算法求解精度;而多峰函数在整个搜索区间内呈现多个谷底,有多个极值点,利于探测算法是否能够跳离局部最优解,而继续搜索其它区域。第二组:为了验证COLSCA算法优化Kapur熵最大化多阈值图像分割求解问题上的性能,利用图1中的6幅伯克利图库中的经典图像Lena、Butterfly、Hunter、Cameraman、Mandrill和Jet作为测试对象,并分别进行双阈值、三阈值、四阈值和五阈值图像分割实验。算法参数中,最大迭代数Tmax=500,振幅调节系数ζ=2,a的初值astart=2,终值aend=0,种群精英粒子占比prob=20%,混沌系数μ=4,种群规模N=30。实验在Matlab R2015b平台下进行,操作系统为Win10 OS,CPU主频率为2.8 GHz,内存容量为8 GB。选择灰狼优化算法GWO的多阈值图像分割算法[7]、改进正余弦算法ISCA的多阈值图像分割算法[13]及融入混沌与对立学习机制的改进正余弦算法COLSCA优化的多阈值图像分割算法进行性能对比。 表1 基准函数 图1 测试图像 利用峰值信噪比PSNR、结构相似度SSIM和特征相似度FSIM这3个指标评估分割图像性能 (20) (21) 其中,R、I分别表示大小为M×N的原始图像和分割图像。对于分割图像,PSNR值越大,分割图像质量越好 (22) 其中,ρR、δR分别表示原始图像的像素均值和方差,ρI、δI分别表示分割图像的像素均值和方差,δRI表示原始图像与分割图像间的协方差,R1、R2为常量,实验中设置R1=R2=6.5025。对于分割图像,SSIM值越大,分割性能越好 (23) 其中 SL(x)=SPC(x)SG(x) (24) (25) (26) PCm(x)=max{PC1(x),PC2(x)} (27) 其中,Ω表示全部图像空间域,SL(x) 表示图像相似性,SPC(x) 表示图像的特征相似性,SG(x) 表示图像的梯度相似性,T1、T2为常量,实验中设置T1=0.85,T2=160,G1(x)、G2(x) 分别表示参考图像和被测试图像的梯度幅值,PC1(x)、PC2(x) 表示参考图像和被测试图像的相位一致性。对于分割图像,FSIM值越大,性能越好。 第一组实验结果的分析。 表2统计了在30次实验中GWO算法、标准SCA算法、ISCA算法以及本文的COLSCA算法在4种基准函数上寻优得到的函数均值、标准方差、最小值和最大值。基准函数中f1(x)、f2(x)是单峰函数,f3(x)、f4(x)是多峰函数。前者由于整个搜索区间内只有一个极值点,所以可以测试算法收敛速度和求解精度;而后者在整个搜索区间内呈现多个谷底,有多个极值点(局部最优解),所以更加利于测试算法跳离局部最优解的能力。均值和标准方差可以同步观察算法的寻优精度和稳定性。结果表明,COLSCA算法在两类基准函数测试中的寻优精度和稳定性都是最好的,如在单峰Schwefel1.2函数中可以比对比算法提升平均约5个数量级,在多峰Rastigin函数中可以平均提升约8个数量级,这说明COLSCA算法引入的混沌搜索与对立学习机制对标准SCA算法中的搜索与开发的均衡、提升收敛速度和寻优精度的改进是有效可行的。 表2 算法在基准函数上得到的统计结果对比 图2是算法的寻优收敛曲线。可见,本文的COLSCA算法可以在所有基准函数上最快收敛在最优精度上,具有最快的收敛速度。与此同时,无论是针对单峰函数或是多峰函数,算法都能稳定取得最佳性能。同时,对于多峰函数来说,由于存在多个波峰点,极其考察算法的拓展能力。图中结果表明,COLSCA算法可以脱离局部最优点。 图2 收敛曲线 第二组实验结果的分析。 图3~图8是COLSCA算法优化Kapur熵的多阈值图像分割结果,图中分别展示了双阈值、三阈值、四阈值和五阈值图像分割结果。依据分割结果可知,分割阈值数越大,越能显示原图像目标对象和区域边缘,这表明分割图像中的灰度信息更加丰富。 图3 COLSCA算法对Lena图像进行双阈值、三阈值、四阈值和五阈值的图像分割效果 图4 COLSCA算法对Butterfly图像进行双阈值、三阈值、四阈值和五阈值的图像分割效果 表3是不同算法在求解Lena图像、Butterfly图像、Hunter图像分割时得到的最优分割阈值。明显地,若分割阈值数较少,算法所选取的分割阈值区别不大,基本保持一致。但随着分割阈值数的增加,算法求解的分割阈值显现出不同。然而, COLSCA算法是否能够求解更优的阈值此时还无法判断,因此,继续引用峰值信噪比PSNR、结构相似度SSIM和特征相似度FSIM这3个定理指标对算法的分割效果做一步对比分析。 图5 COLSCA算法对Hunter图像进行双阈值、三阈值、四阈值和五阈值的图像分割效果 图6 COLSCA算法对Cameraman图像进行双阈值、三阈值、四阈值和五阈值的图像分割效果 图7 COLSCA算法对Mandrill图像进行双阈值、三阈值、四阈值和五阈值的图像分割效果 图8 COLSCA算法对Jet图像进行双阈值、三阈值、四阈值和五阈值的图像分割效果 表4、表5、表6和表7分别是算法进行多阈值图像分割时得到的PSNR、SSIM、FSIM及算法计算时间表现。综合结果可以看出,在分割阈值选取越多时,图像失真更少、图像一致性保留更加完整,图像分割越准确,所以PSNR、SSIM、FSIM这3个指标均会递增。对比之下,本文的COLSCA算法可以进行阈值分割得到的PSNR、SSIM、FSIM这3个指标值是最高的,说明在COLSCA算法中采用的非线性对数振幅参数调整机制、混沌搜索精英个体变机制以及对立学习机制对改进SCA算法的寻优精度是有效可行的。此外,由于分割阈值量较少,算法的分割阈值选取相差并不大,所以此时3个指标上相差也不大。但随着分割阈值量的增加,算法差距逐步体现,说明在多阈值情形下,COLSCA算法所得到的阈值更加能够准确做出图像分割。 表3 分割阈值 表4 PSNR 表7表明,增加分割阈值量,会增加算法的计算时间,这是由于算法在寻优空间上的维度增加所导致的。此外,当阈值量较少时,COLSCA算法的计算时间会略高于其它算法,但并不明显。分割阈值量增加后,COLSCA算法的计算效率稳步提升,说明COLSCA算法在寻优精度和收敛速度上的改进可以提升图像分割效率。 为了验证COLSCA算法在标准SCA算法上所做改进工作的有效性,本节比较分别利用COLSCA算法和标准SCA算法进行Kapur熵多阈值图像分割后的PSNR值在显著性水平为5%的情况下,进行Wilcoxon秩和检验的结果。 建立假设条件为:H0:定义COLSCA算法和标准SCA算法进行图像分割后得到的PSNR值没有明显差异;H1:定义COLSCA算法和标准SCA算法进行图像分割后得到的PSNR值存在显著差异。 表5 SSIM 表8为Wilcoxon秩和检验结果。可见,P值均小于5%,表明结果拒绝H0,接受H1,COLSCA算法相对SCA算法得到的PSNR值具有显著性差异,不具偶然性,说明COLSCA算法所做改进是有效的。 图9、图10和图11是算法在Lena图像、Butterfly图像、Hunter图像上进行四阈值分割时得到的适应度。COLSCA算法具有更快的收敛速度,基本在30次迭代之后即可得到最优适应度,这说明此时的Kapur熵值更大,对应其分割阈值更加精确,也进一步验证将本文设计的融合混沌搜索与对立学习机制的改进正余弦算法COLSCA应用于图像分割问题的可行性。 表6 FSIM 表7 算法计算时间 表8 Wilcoxon秩和检验值 图9 Lena图像适应度收敛曲线 图10 Butterfly图像适应度收敛曲线 图11 Hunter图像适应度收敛曲线 本文提出了一种融入混沌与对立学习机制的改进正余弦算法COLSCA,并利用该算法对Kapur熵最大化的多阈值图像分割问题进行了求解。利用伯克利图像对COLSCA算法的阈值寻优准确性和寻优效率进行了实验分析,验证该算法可以有效提升图像分割精度和分割效率,说明COLSCA算法所做的工作在提升算法的全局搜索与局部开发间的均衡、避免局部最优解方面具有良好的效果,可以增强算法的寻优精度和收敛速度。今后的研究工作将进一步将图像分割实验扩展至其它领域,如医学图像中的MRI图像、红外图像等,进一步验证算法的寻优能力。2.3 对立学习机制
3 利用改进正弦余弦算法COLSCA求解Kapur熵多阈值图像分割
3.1 Kapur熵最大化的多阈值图像分割模型
3.2 图像分割算法设计
4 实验分析
4.1 实验环境和参数配置


4.2 图像分割的评估指标
4.3 实验结果分析
















5 结束语
猜你喜欢
计算机仿真(2022年8期)2022-09-28 09:53:02数学小灵通·3-4年级(2020年9期)2020-10-27 03:26:14NBA特刊(2018年11期)2018-08-13 09:29:14中学数学杂志(高中版)(2016年6期)2017-03-01 18:53:58海外星云(2016年7期)2016-12-01 04:18:01世界汽车(2016年8期)2016-09-28 12:11:11中国塑料(2016年11期)2016-04-16 05:26:02北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27 06:31:40职业技术(2015年8期)2016-01-05 12:16:46声学技术(2014年1期)2014-06-21 06:56:26
