
基于BcGAN的水下图像增强方法
2022-11-25 07:37:40杨国为
计算机工程与设计 2022年11期
李 耀,于 腾,杨国为,2+
(1.青岛大学 电子信息学院,山东 青岛 266071;2.南京审计大学 信息工程学院,江苏 南京 211815)
0 引 言
水下图像承载着重要的水下环境信息,被广泛用于探索和监测水下世界。然而,受水下特殊环境的影响,水下图像往往会出现细节模糊、色彩失真、对比度低等质量下降问题。低质量的水下图像限制了它们在水下物体检测,水下3D重建等方面的进一步应用。为了获取高质量的水下图像,文献[1,2]提出基于暗通道先验的水下图像增强算法,以解决水下图像对比度低和色彩偏差的问题。由于这类基与水下成像模型的传统算法需要估计中间变量,并且适用场景较少,因此所报告的水下图像增强结果不太具有竞争力。随着卷积神经网络(convolutional neural network,CNN)和生成对抗网络(generative adversarial network,GAN)在许多视觉任务中的广泛应用[3-5],文献[6]提出基于CNN的水下图像增强模型,利用端到端和数据驱动的机制直接重建清晰图像。文献[7]提出基于GAN的水下图像增强模型,并引入组合损失函数来生成清晰图像。文献[8]提出基于条件生成对抗网络(conditional generative adversarial network,cGAN)[9]的水下图像增强模型,通过配置不同的组合损失函数进行水下图像的成对训练和不成对训练。尽管这类深度学习算法的性能整体优于基于水下成像模型的算法,但是由于网络结构的局限性,这类算法对水下图像的增强并没有达到理想效果,生成的图像仍然存在一定程度的模糊不清晰现象。
针对上述问题,本文提出基于Boosting条件生成对抗网络(Boosting conditional generative adversarial network,BcGAN)的水下图像增强方法。SOS(strengthen-operate-subtract)boosting策略[10]是去噪任务中一种对图像进行细化处理的技术。受其启发,本文结合SOS boosting策略和编码器-解码器结构设计了一个增强生成器。并提出双重判别器结构,使其联合训练从而提升增强生成器对图像的细节生成能力。通过在合成水下数据集和真实水下数据集上进行实验,验证了本文方法的有效性。
1 基本原理
1.1 SOS boosting策略
Boosting算法被证明是有效的图像去噪方法[10,11]。SOS boosting策略是将先前增强的图像作为输入来逐步完善结果,具体步骤如下所示。
(1)S:通过将先前去噪的图像添加到有噪声的输入图像中来增强信号。
(2)O:对增强后的图像进行去噪处理。
(3)S:从恢复后的信号增强结果中减去先前的去噪图像。
基于在相同场景的图像上去噪方法可以获得更好的信噪比结果这个原则,该算法已被证明可以进一步提高图像的信噪比,因此可以有效去除噪声。描述SOS boosting策略的核心公式如下所示
(1)

1.2 条件生成对抗网络
GAN是一个对抗性学习框架,由生成器和判别器组成。生成器和判别器的对抗训练可以使生成器学习如何从随机噪声中生成逼真的图像。然而,GAN的训练并不稳定,生成的图像会产生一些伪影和噪声。而cGAN通过纳入条件信息来解决此问题。增加信息的条件变量提高了GAN学习过程中的稳定性,并提高了生成器的表达能力。与原始GAN不同,cGAN的目标函数定义如下

(2)

2 本文方法
本文提出的水下图像增强方法BcGAN主要包括增强生成器结构的设计、双重判别器结构的设计、目标函数的设计和模型训练流程4个部分,在本章节中将进行详细的介绍。
刚入行的时候我就发现,没有必要融入进去。我倒不如做个村子里搜集信息的人,或者是来自火星、对一切都充满好奇的人。幸好,这世界上到处都是倾诉欲泛滥的人,他们都想把自己的故事告诉你,想把你不知道的东西告诉你。
2.1 增强生成器
本文增强生成器的功能是从输入的水下图像中生成清晰的图像。因此,它不仅要保留输入水下图像的结构和细节信息,而且应尽可能矫正色偏和消除雾度。增强生成器结构如图1所示。本文以残差密集块(residual dense block,RDB)[12]为基础块构建了一个编码器-解码器结构的生成器。并且受ResNet[13]和U-Net 的启发,在对称层中引入了可以增加信息含量的跳跃连接。本文不是简单地将对称层特征的所有通道拼接在一起,而是采用SOS boosting策略来增强和细化特征。其有效性在3.4节进行详述。SOS boosting策略的原则是基于先前估计的图像对增强图像进行细化处理。本文将编码部分的特征看作输入未处理的特征,将解码部分的特征看作输出处理过的特征,在解码阶段集成SOS boosting策略,以逐步细化编码阶段提取的特征i5(i5=j5)。

图1 增强生成器结构
在解码阶段的第n级,对上一级的特征jn+1进行上采样后,遵循“Strengthen-Operate-Subtract”操作。首先利用同一级别编码阶段提取的特征in对其进行增强,然后通过一个RDB,最后减去先前上采样过的特征jn+1得到细化后的特征jn。 公式如下
jn=ϑn(in+(jn+1)↑2)-(jn+1)↑2
(3)
式中: ϑn表示第n级可训练的RDB,↑2为比例系数为2的上采样, (in+(jn+1)↑2) 表示增强的特征。式(3)以信号增强的方式细化了特征 (jn+1)↑2。
本文在增强生成器中没有引入批量归一化(batch normalization,BN)层,移除BN层有利于提升网络的泛化能力。同时也被实践证明了在GAN框架下训练时,移除BN层有利于减少伪影和降低训练的不稳定性[14]。增强生成器中除第一层和最后一层的卷积步长为1外,其余卷积层和反卷积层步长均为2。
2.2 双重判别器
判别器用于区分图像的真假,即判别图像是真实的还是由生成器生成的,本文提出双重判别器,其结构如图2所示。

图2 双重判别器结构
双重判别器由两个子判别器构成,它们具有相同的网络结构,但权重不同。双重判别器的目的是使判别器能够引导生成器生成全局语义级别和局部细节级别的图像。这种设计背后的原因是现有的判别器在引导生成器生成逼真的细节方面受到限制。因此,本文将不同分辨率的输入提供给不同的子判别器,以提高生成结果的视觉质量。子判别器采用全卷积结构[15],可在图像的一小块区域中进行鉴别,其输出的是N×N的特征矩阵,总体决策是通过平均所有小块区域的真实性来实现的。本文将增强生成器生成的图像和真实图像反馈给第一个子判别器D1, 然后对生成图像和真实图像进行比例系数为2的下采样,并将尺寸减半的输入反馈给第二个子判别器D2。 以此来实现对输入图像的多尺度判别。两个子判别器输出的特征矩阵为高频提供了度量,将联合推动增强生成器更多地聚焦于图像中的细节。其有效性在3.4节进行详述。子判别器中除最后一层卷积层步长为1外,其余卷积层步长均为2。
2.3 目标函数
由于原始GAN等价优化的距离衡量(KL散度、JS散度)不合理,导致GAN训练不稳定。WGAN(Wasserstein GAN)[16]利用Earth-Mover距离代替KL散度和JS散度从而解决了生成数据与真实数据之间的距离衡量问题。然后给定了一组近似为Earth-Mover距离且建模为神经网络的k-Lipschitz函数f。为了确保函数f满足k-Lipschitz限制条件,判别器的权重被裁剪到某个范围 [-c,c]。 而WGAN-GP(Wasserstein GAN with gradient penalty)[17]提出gradient penalty来对判别器的梯度实施软约束,即设置一个损失项来实现梯度与常数k之间的联系来确保函数f满足Lipschitz约束,从而解决了WGAN中权重裁剪会带来的梯度消失或爆炸等问题。因此,本文采用WGAN-GP损失作为对抗训练损失并结合cGAN损失进行修改得到如下对抗训练损失
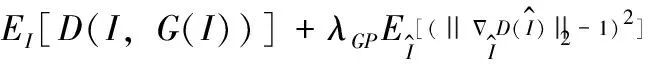
(4)

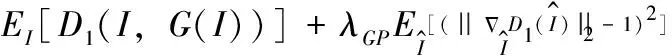
(5)

(6)
(7)
结合了上述损失之后,得到了本文网络的最终目标函数

(8)
2.4 训练流程
本文方法的训练流程如图3所示。增强生成器的输入为3.2节描述的合成水下图像,其目标是生成足够接近于真实图像的清晰图像。双重判别器的输入为合成水下图像分别与生成图像和真实图像组成的图像对,其目标是判别出这两组图像对的真假。训练时,增强生成器和双重判别器交替训练从而形成一个动态博弈的过程。当双重判别器无法判别出输入图像对的真假时,增强生成器达到最好效果。
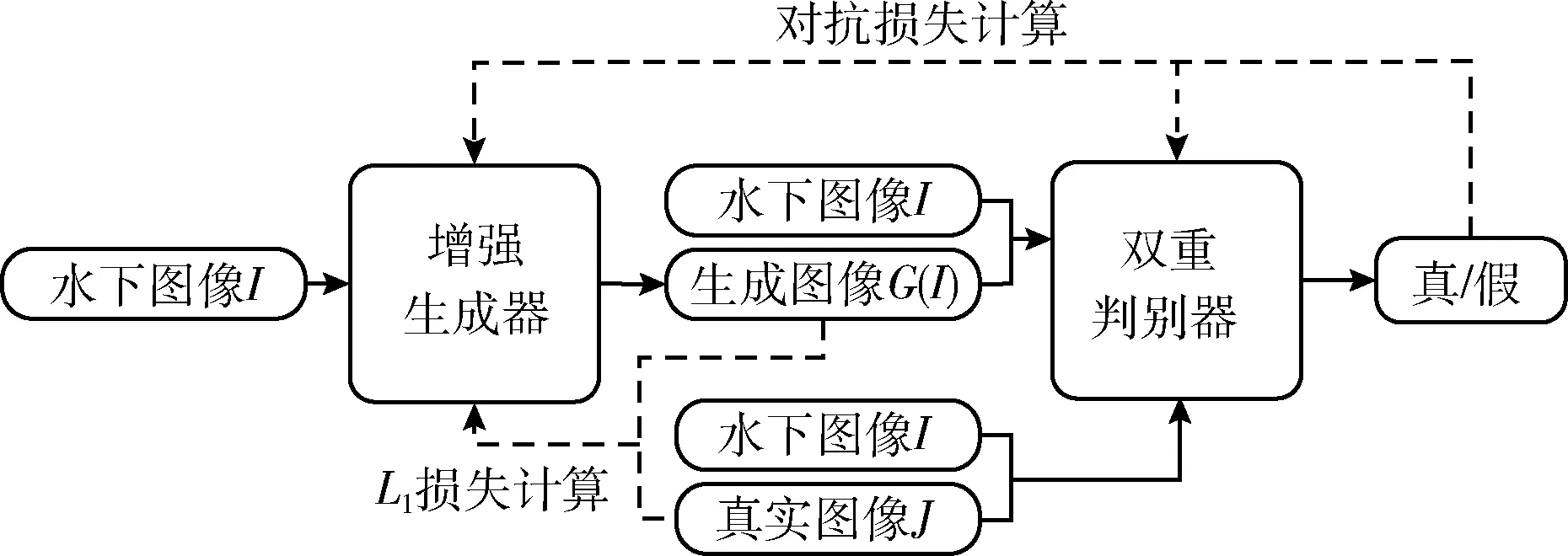
图3 BcGAN训练流程框架
3 实 验
3.1 实验设置
本文方法基于Pytorch深度学习框架实现,并在Ubuntu 18.04下完成实验。硬件设备为Intel(R) Core(TM) i9-10940X@3.30 GHz处理器,64 GB运行内存,NVIDIA GeForce GTX 2080 Ti (11 GB)显卡。在训练过程中,输入图像的尺寸设置为256×256,并根据经验设置参数λGP=10,λ1=10。 本文采用Adam优化器进行参数优化,学习率设为0.0001,batch_size设为8。网络训练100个epoch。
3.2 数据集
由于真实成对水下图像数据集的匮乏,本文遵循文献[18]提出的方法,并基于NYU-V2 RGB-D数据集来生成具有多种水类型的合成水下图像。该方法是基于文献[6]中合成方法的改进。它为了更好利用数据驱动的方式训练模型,对数据集中的每个图像生成6种不同水类型的图像,并且通过随机改变每种水类型图像的背景光系数和相机到物体的距离参数来额外生成6张图像,以此来扩充数据集。采用此方法合成的水下图像数据集包含52 164幅图像,本文采用其中的30 000张作为训练集,3000张作为验证集,3000张作为测试集。训练集、验证集、测试集之间没有交集。
为了验证所提方法在真实世界水下图像上的有效性,本文从互联网上收集了60张真实水下图像用于评估。在收集图像时,本文尽可能确保所收集的图像在内容、场景等多个方面的不同。所有图像的尺寸均调整为256×256。
3.3 对比实验
为了评估本文方法,本文与一些最新的水下图像增强方法在合成和真实水下图像上进行了定性和定量比较,这些方法包括UDCP(underwater dark channel prior)、UGAN(underwater generative adversarial network)[7]、FUnIE-GAN(fast underwater image enhancement GAN)[8]和UIE-DAL(underwater image enhancement using domain-adversarial learning)[18]。本文使用作者提供的源代码或预训练模型进行测试,以产生最佳结果,从而进行客观评估。对于定量比较,本文采用峰值信噪比(PSNR)和结构相似性(SSIM)作为图像增强质量优劣的评价指标。PSNR值越大,表明增强后的图像失真越小;SSIM值越大,表明增强后的图像与真实图像结构越相似。
3.3.1 合成数据集上的比较和分析
在第一组实验中,将本文方法与几种最新的水下图像增强方法在合成数据集的测试集上进行了定性和定量比较。由于这些测试图像都具有地面真实图像,因此可以计算定量指标PSNR和SSIM。表1显示了基于这些指标的结果比较。该表清楚地表明,与其它水下图像增强方法相比,本文提出的方法在PSNR和SSIM值上达到了最优,能够实现出色的定量性能。
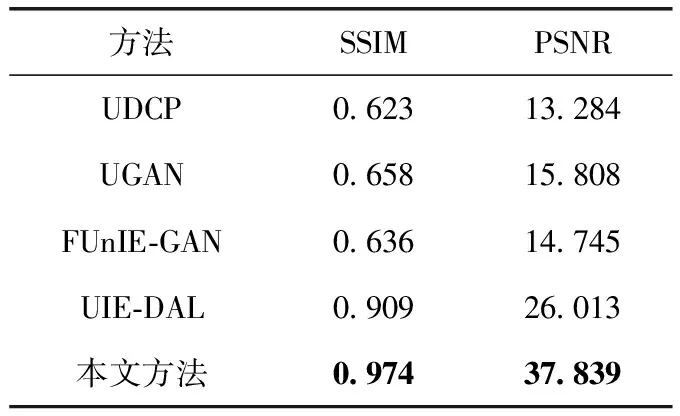
表1 本文方法与其它方法在合成水下图像上的定量结果
在图4中,本文展示了来自测试集的4个示例以进行定性比较。UDCP会产生严重的色彩失真,这主要是由于背景光系数和传输图的不正确估计造成的。UGAN和FUnIEGAN是基于深度学习的端到端方法,在一定程度上克服了UDCP的局限性,但是它们的去雾效果较差,增强过的水下图像仍然会存在一定程度的雾化模糊现象。其中,FUnIEGAN还是会有色彩失真的现象。UIE-DAL可以很好校正水下图像的色偏,去雾效果优于UGAN和FUnIEGAN,但是UIE-DAL增强的水下图像会存在伪影,破坏了图像的结构信息。相比之下,本文方法生成的图像更加清晰,这归因于SOS boosting策略对于特征细化的有效性。同时增强生成器中引入的RDB充分提取了图像的特征,在双重判别器的激励下能够促使网络学习更有效地映射,因此不会出现色偏和产生伪影的现象。

图4 本文方法与其它方法在合成水下图像上的定性结果
3.3.2 真实数据集上的比较和分析
尽管所提网络是在合成水下图像数据集上训练的,但本文表明可以将其推广到处理真实世界的水下图像。在第二组实验中,将本文方法与几种最新的水下图像增强方法在真实水下图像上进行性能比较,其结果如图5所示。UDCP会使图像整体变暗,看不到太大的增强效果。UGAN可以纠正色偏,但是增强结果仍然包含严重的雾度残留。FUnIEGAN也存雾化模糊的问题,并且仍然存在色彩失真的现象。UIE-DAL则会产生噪声和伪影,且色彩恢复不自然。相反,本文方法完全不受水下特殊环境的影响,可以有效校正色偏和去除雾度,并且不会引入噪声和伪影,能够生成视觉上更具吸引力的图像。

图5 本文方法与其它方法在真实水下图像上的定性结果
综上所述,本文提出的水下图像增强方法BcGAN无论是在合成数据集还是在真实数据集上,都取得了远优于其它方法的增强效果,并且具有很好的鲁棒性。这也归因于本文提出的增强生成器和双重判别器结构的有效性。
3.4 消融实验
为了进一步验证本文提出的增强生成器和双重判别器对于水下图像增强的有效性,本文设计了以下消融实验。
(1)DcGAN:将增强生成器中的SOS boosting策略替换为U-Net中的跳跃连接,并使用单判别器。
(2)ScGAN:使用增强生成器和单判别器。
以上两种变体,均使用与本文方法相同的参数进行训练。表2和图6显示了两种消融变体的相应配置和实验结果。
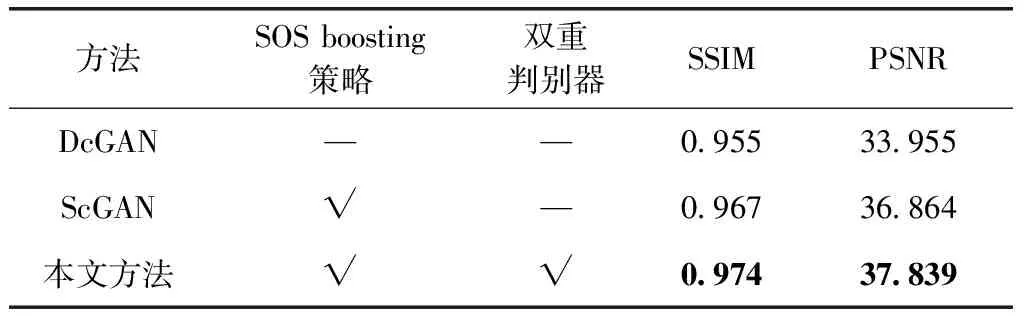
表2 消融设置和在合成水下图像上的定量结果

图6 消融实验在真实水下图像上的定性结果
从表2中可以看出,本文结构的平均PSNR和SSIM值最高,性能优于其它变体。相比于DcGAN的跳跃连接,ScGAN的SOS boosting策略可以取得更好的定量得分。SOS boosting策略在不引入任何外层的情况下提高了网络的性能。对比本文结构与ScGAN,可以发现双重判别器结构是有效的,性能优于单判别器结构。图6更是在视觉上表明了本文结构与其它变体的性能差异,SOS boosting策略能够有效消除水下图像的雾度部分,并逐步提高图像的清晰度。而双重判别器可以进一步促使增强生成器生成细节更加精细的图像。以上实验结果表明了SOS boosting策略有助于水下图像增强任务,本文提出的增强生成器和双重判别器是非常有效的。
4 结束语
本文提出全新的条件生成对抗网络(BcGAN)实现对水下图像的端到端增强,通过在生成器中集成SOS boosting策略和联合训练双重判别器的方法,大大改善了现有方法对水下图像的增强效果不甚理想,容易出现雾度残留和细节模糊的现象。对比实验结果表明本文方法具有更好的水下图像增强结果,能够生成更清晰的图像。消融实验也进一步表明所提出的增强生成器可以生成雾度更少的图像,SOS boosting策略能够细化特征;同时双重判别器也会促使生成器更加关注图像细节。由于合成数据集不能很好地模拟水下环境,未来将研究如何使本文方法适应真实水下图像的不成对训练。
猜你喜欢
作文小学高年级(2023年6期)2023-07-14 11:13:38
燃气涡轮试验与研究(2021年6期)2021-08-01 03:09:10
海洋信息技术与应用(2020年4期)2021-01-18 06:21:36
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
中国生物医学工程学报(2019年5期)2019-07-16 07:56:50
中国外汇(2019年7期)2019-07-13 05:44:56
当代陕西(2019年10期)2019-06-03 10:12:04
北京航空航天大学学报(2017年3期)2017-11-23 05:14:58
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
发明与创新(2015年1期)2015-02-27 10:38:26
