
基于改进深度森林的旋转机械故障诊断方法
2022-11-21 03:38刘东川邓艾东卞文彬
振动与冲击 2022年21期
刘东川, 邓艾东, 赵 敏, 卞文彬, 许 猛
(东南大学 能源与环境学院 火电机组振动国家工程研究中心, 南京 210096)
随着旋转机械向着大型化、高速化和自动化的发展,其安全运行受到了广泛的关注。但是经过长时间的运行,旋转机械不可避免会出现故障、损坏等情况,造成严重的安全问题和经济损失问题。因此,实现旋转机械故障诊断是机械制造行业一直以来研究的重点[1-3]。
目前基于数据驱动方式,收集历史数据建立故障诊断模型是旋转机械故障诊断研究的一种重要方法[4]。其中较为常见的故障诊断模型有支持向量机、逻辑回归、朴素贝叶斯等。但这些传统模型框架过于简单,泛化能力较弱,限制了其故障诊断性能的提升[5]。深度神经网络由于其具有逐层处理机制以及表征学习能力,往往能实现比浅层机器学习更优良的诊断效果,其在旋转机械故障诊断中得到了广泛的应用。然而,深度神经网络的训练过程过度依赖人工干预,在超参数的设置上也极为繁琐,训练起来耗时严重[6]。
为实现高效的旋转机械故障诊断且减少超参数的设置,Zhou等[7]提出了一种全新的决策树集成方法——深度森林。深度森林由多粒度扫描和级联森林两个部分组成。其中多粒度扫描环节实现对输入数据的特征提取功能,级联森林则通过逐层处理的方式实现对输入数据的表征学习功能。
在深度森林的多粒度扫描环节中,通过滑动窗口对原始输入信号进行特征提取时,有可能将一些干扰信号的权重放大且忽视特征之间彼此存在的联系,影响最终诊断结果[8]。其次,在级联森林中,高维变换特征向量在与低维增强特征向量拼接时,巨大的维度差异引发特征淹没现象,造成级联森林诊断准确率下降的问题,降低了深度森林的诊断性能[9-10]。
为了避免级联森林诊断准确率下降等问题,同时保留深度森林的优势,本文在多粒度扫描级联的地方增加一个stacking模型融合层,利用stacking层的多个初级学习器对输入特征进行整体分析得到另一组维度更低但表征能力更强特征向量。之后将通过多粒度扫描和stacking层得到的特征向量输入到级联森林中诊断,得到最终的诊断结果。在试验分析中将本文所提方法与原始的深度森林以及其他故障诊断模型进行了对比,验证了本文所提的改进深度森林故障诊断模型的可行性与有效性。本方法可为旋转机械的故障诊断提供一条新的路径。
1 深度森林
深度森林可分为多粒度扫描环节和级联森林环节。其中多粒度扫描环节采用滑动窗口扫描原始特征以增强样本多样性;而级联森林环节实现对输入数据的逐层处理达到表征学习的目的[11]。
1.1 多粒度扫描
滑动窗口用于扫描输入特征,如图1所示。假设有a维原始特征,使用的窗口大小为b,对于序列数据,将通过滑动一个特征的窗口来生成b维特征向量,总共生成(a-b+1)维特征向量。从正/负训练样本中提取的所有特征向量都被视为正/负实例,然后将其用于生成类向量,从相同大小的窗口中提取的实例用于训练随机森林和完全随机森林,然后生成类向量并将其作为变换后的特征串接。假设有c类,使用b维窗口,然后每个随机森林生成(a-b+1)个c维类向量,得到对应于a维原始特征向量的2·c·(a-b+1)维变换特征向量,见图1。
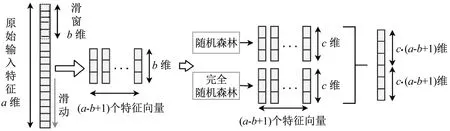
图1 多粒度扫描Fig.1 Multi granularity scanning
1.2 级联森林
深度神经网络中的表征学习主要依赖于原始特征的逐层处理。受这种识别的启发,深度森林采用了一种级联结构,如图2所示,在这种结构中,级联的每一级接收由其前一级处理的特征信息,并将其处理结果输出到下一级。每个层次是决策树森林的集合,即集合的集合。
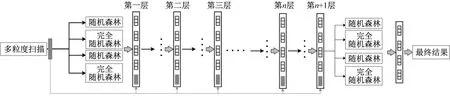
图2 级联森林Fig.2 Cascade forest
级联森林的每一层都包含很多随机森林,而每一个随机森林又由若干决策树组成。给定一个实例,每个随机森林里的决策树将产生一个类向量的结果,然后将所有决策树中的类向量取平均值,即可得到随机森林的输出结果。然后将随机森林输出的类向量拼接在一起并与多粒度扫描后的特征向量串联起来输入下一级级联。假设有3个类,那么4个随机森林中的每一个都将产生一个三维类向量。因此,下一级级联将在原来的特征向量基础上额外接收12个增强特征。
2 stacking集成算法
为了实现对分类器准确性的提升,一种更为强大的集成学习策略便是应用学习法,即通过不同学习器之间的结合堆叠,而stacking算法是学习法的典型代表。
若stacking算法包含4个初级分类器学习器
M={M1,M2,M3,M4}
(1)
式中,Mi,1≤i≤4为第i个初级分类器
具体的试验步骤如下。
步骤1将训练样本一共分为4份即训练样本1,2,3,4。
X=X1∪X2∪X3∪X4
(2)
式中:X为训练样本;Xi为第i个训练样本。
步骤2保留训练样本X1,X2,X3训练,将训练样本X4作为验证集,并记录下M1训练样本X4的预测结果A11。
步骤3利用样本X1,X2,X3对测试数据预测,得到M1对于测试数据的预测结果B11。
步骤4分别将训练样本X2,X3,X4作为验证集数据,重复上面步骤2、步骤3,得到4组不同的训练样本的预测数值和测试数据的预测数值。将4组训练样本拼接起来得到新的训练数据A1,将4组测试数据的预测结果取平均得到新的测试数据B1。
A1=Agregate(A11,A12,,A13,,A14)
(3)
B1=Average(B11,B12,B13,B14)
(4)
式中:A1为通过k-折得到的新的训练数据;A1i为M1对样本Xi的预测结果;B1为通过k-折得到的新的测试数据;B1i为Xi作为训练集,M1对测试数据预测的结果。
步骤5利用剩余其他模型,重复步骤2~步骤4,分别得到新的训练数据和测试数据。
A=Agregate(A1,A2,A3,A4)
(5)
B=Average(B1,B2,B3,B4)
(6)
式中:A为通过初级分类器得到的新的训练数据;B为通过初级分类器得到的新的测试数据。
步骤6利用训练数据A对次级分类器进行训练,并对测试数据B进行预测,得到最终的预测结果。
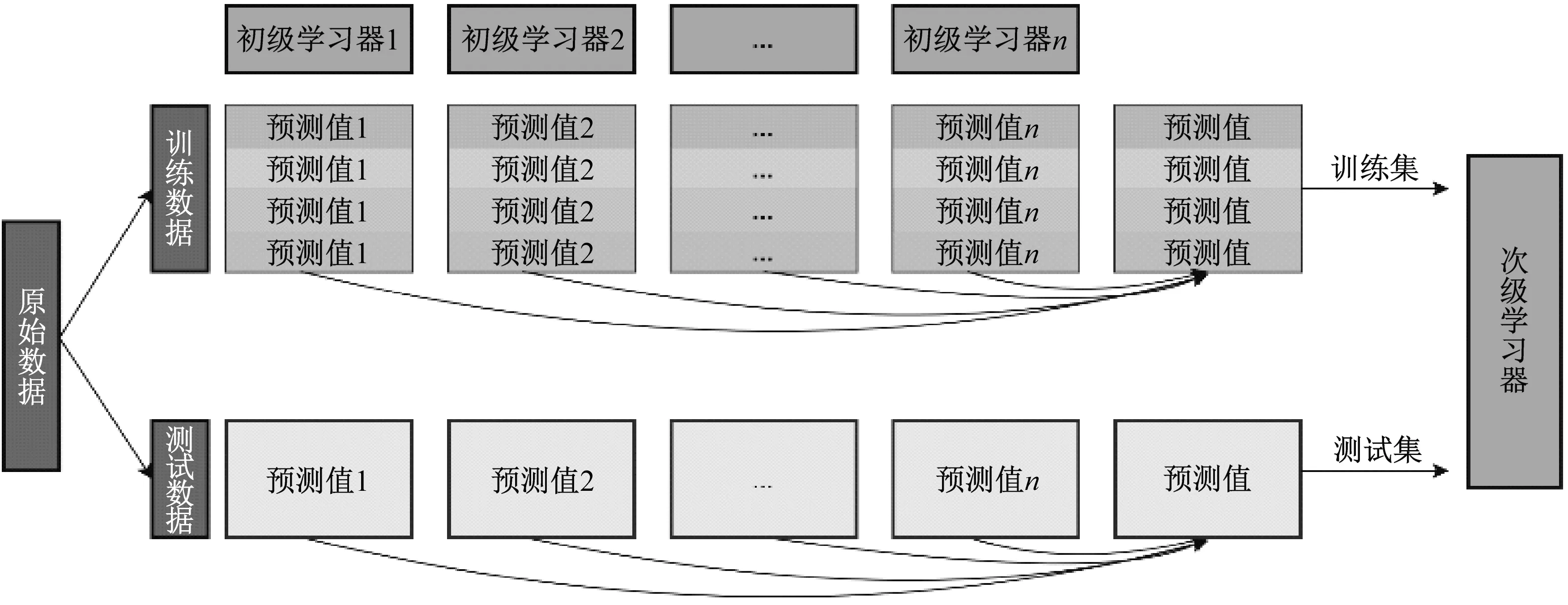
图3 stacking集成学习总体过程Fig.3 Overall process of stacking integrated learning
3 改进深度森林模型
本文在原有的深度森林上添加stacking算法,实现了一种改进深度森林的故障诊断模型。
3.1 改进深度森林设计框架
本文将stacking算法与多粒度扫描结合使用,得到一种基于stacking算法的改进深度森林模型,如图4所示。基于stacking算法的深度森林模型将多粒度扫描与stacking层级联在一起,将输入的原始特征向量通过stacking层和多粒度扫描处理得到两种不同新的特征向量,并将得到的新特征向量输入到级联森林。将级联森林的性能在k-折交叉验证的验证集上进行评估,取级联森林在所有k-折交叉验证的验证集上的准确率作为整体诊断精度,如果级联森林下一级的准确率与上一级相比没有增益,则验证性能收敛,训练过程将终止。
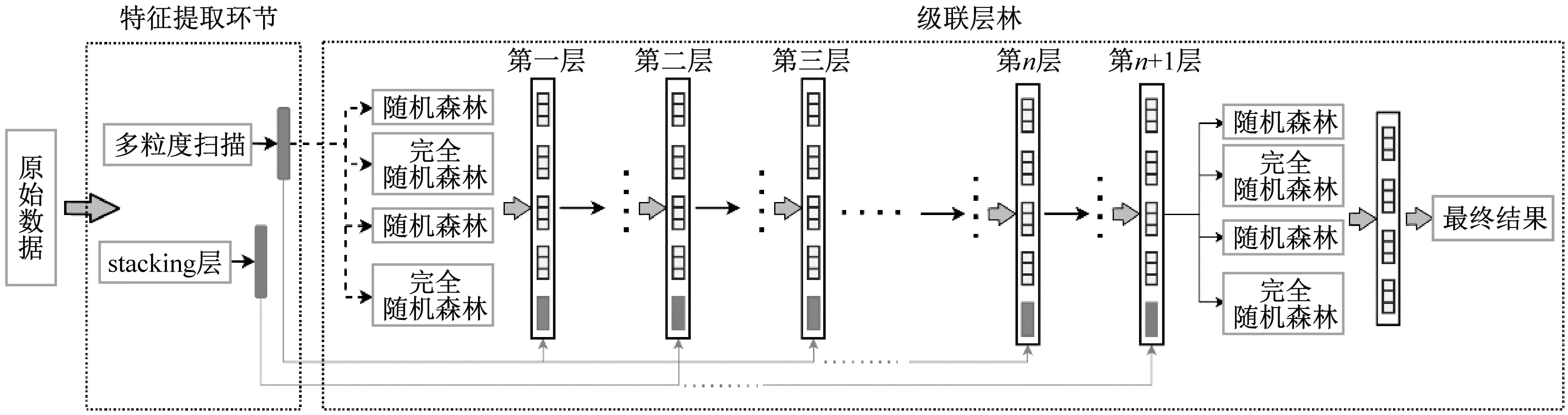
图4 改进深度森林结构Fig.4 Improved deep forest structure
3.2 基于改进深度森林模型的故障诊断方法
基于改进深度森林模型的故障诊断方法如图5所示,大致可以分为以下4个步骤。
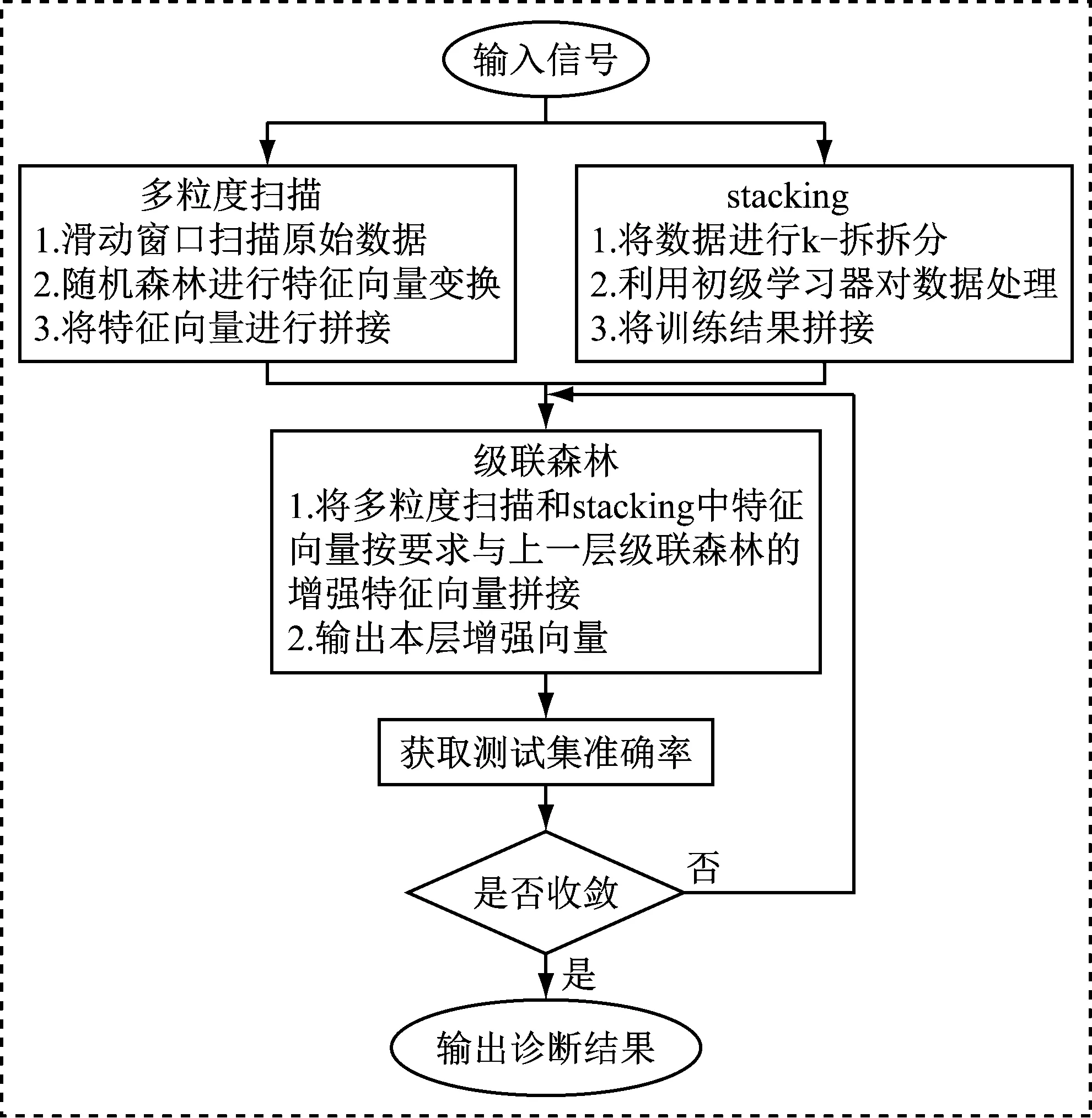
图5 基于改进深度森林模型的故障诊断流程图Fig.5 Flow chart of fault diagnosis based on improved deep forest model
步骤1多粒度扫描环节。将输入的原始信号放入多粒度扫描环节,利用滑动窗口截取数据,然后将截取到的数据送入随机森林和完全随机森林处理。之后将随机森林处理后的概率进行拼接,得到高维度特征向量。
步骤2stacking层处理。利用k-折交叉验证将输入的原始输入信号拆分,得到测试集、训练集和验证集。然后利用stacking层中的初级学习器对数据进行处理并将结果拼接在一起,得到维度更低且表征能力更强的特征数据。
步骤3级联森林处理。将通过多粒度扫描得到的特征向量输入级联森林的第一级进行决策,之后将级联森林第一级的决策结果与通过stacking层得到的特征向量拼接输入到第二层。将第二层的决策结果再与多粒度扫描环节得到的特征向量拼接输入到下一层,以此类推。
步骤4收敛性判断。此时将级联森林得到的增强特征向量先进行平均处理,并选取其中概率最大的类别。此时,便可得到每一层级联森林对于测试集的诊断概率,并与上一层级联森林的诊断结果进行对比。如果诊断结果相差很大,则说明级联森林未收敛,重复步骤2~步骤4。如果诊断结果相差不大说明级联森林收敛,将结束训练过程,并输出诊断精度。
4 试验分析
为了验证本文所提方法的可行性,本文采用凯斯西储大学轴承数据集和千鹏公司齿轮箱数据集进行测试。
4. 1 试验模型
为了验证本文所提的改进深度森林故障诊断方法的可行性,本文选取现下5种主流的故障诊断模型与本文所提方法进行对比。本文选取的故障诊断模型分别为支持向量机(support vector machine,SVM),核函数选用高斯核;随机森林(random forest,RF),树的深度为11,数量为400,k近邻算法(k-nearest neighbor,KNN),距离计算选择欧拉距离;自适应增强算法(adaptive boosting,AdaBoost),学习率为0.1,学习器数目为400;高斯朴素贝叶斯分类器(Gaussian naive Bayes,GaussianNB),拉普拉斯平滑系数取1。
4. 2 凯斯西储大学轴承数据集测试试验
4.2.1 试验条件
试验平台如图6所示,待检测的轴承有3种分别是支撑着电动机的转轴,驱动端轴承为SKF6205和风扇端轴承为SKF6203。试验设置采样频率为12 kHz,并且有4种试验工况:1 797 r/min/0,1 772 r/min/0.745 7 kW, 1 750 r/min/1.491 4 kW,1 730 r/min/2.237 1 kW,“1 730 r/min/2.237 1 kW”含义为转速1 730 r/min,电机所加负载为2.237 1 kW,试验选择0负责工况下的数据。故障类型分3类:滚动体故障(B)、外圈故障(OR)、内圈故障(IR),每种故障类型包含3种故障尺寸:0.007 in,0.014 in和0.021 in(1 in=0.025 4 m)。因此可以将轴承状态分为9种故障状态和一种正常状态。

图6 凯斯西储大学试验平台Fig.6 Case Western Reserve University experimental platform
4.2.2 数据说明及模型参数选择
在凯斯西储大学的数据集上,本文一共设置6 000个样本,10种健康状态,具体如表1所示。
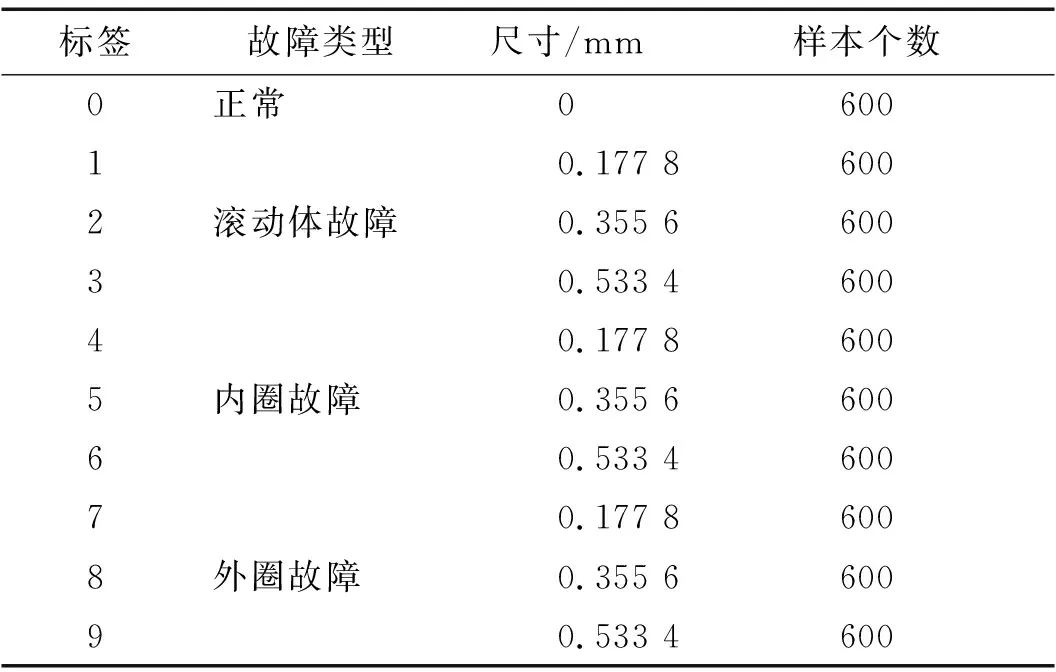
表1 数据集汇总Tab.1 Summary of datasets
其中原始数据集中的每一组数据由1 200个振动数据组成,本文利用Tsfresh库将此1 200个振动数据的全部特征进行提取,并转换为787维数据。针对振动信号的时间序列数据本文提取出一系列常用的特征,例如:最值、均方根、峭度、波形因子等。几种比较常见的时间序列特征计算公式,如表2所示。
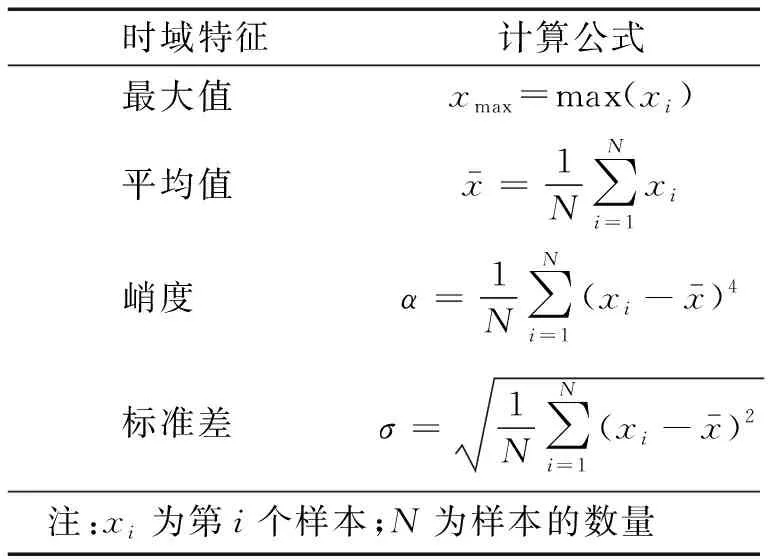
表2 时域特征计算公式Tab.2 Time domain characteristic calculation formula
在凯斯西储大学轴承数据集中多粒度扫描环节选取的滑动窗口长度为40,在多粒度扫描中随机森林数目为2,级联森林中每一层包含两个随机森林和两个完全随机森林,而原始的深度森林模型和改进深度森林模型的具体参数均为上述值。其中随机森林中树的深度为11,数量为400。
而在改进深度森林的stacking层中,所选模型分别为随机森林、Lightgbm、XGBoost、逻辑回归。其中随机森林的参数选择跟4.1节一致;Lightgbm学习率为0.03,学习器数目为50;XGBoost学习率为0.05,学习器数目为600;逻辑回归中分类阈值为0.5。
4.2.4 与其他故障诊断模型对比
不同模型在凯斯西储大学数据集下的分类准确性和训练时长,如表3所示。其中DF(deep forest)是传统深度森林模型,S-DF(stacking-deep forest)是本文所提改进后的模型。

表3 0.8训练-总数据比例下不同诊断方法对比Tab.3 Comparison of different diagnostic methods under 0.8 training-total data ratio
在凯斯西储大学轴承数据集的故障诊断中,现下主流的故障诊断模型如AdaBoost和KNN算法诊断准确率较低,均低于90%,而 SVM、RF和GaussianNB表现相对良好,诊断准确率均达到了95%以上。传统的深度森林模型因为只考虑部分特征而忽视特征之间的关联性[12-15],导致其诊断精度相对较低,仅有90.25%。本文所提的基于stacking算法的改进深度森林模型,实现了99.59%的诊断准确性,在原始深度森林基础之上提升了9.34%,大幅提升深度森林的诊断准确性。另外,本文所提改方法的诊断性能也要优于其他主流模型,印证本文所提方法的可行性。
在诊断时间上,因为传统故障诊断模型框架结构简单,运算量较少,训练时间要相对较短。而本文所提方法由于增添了网络结构使训练工作量加大,导致训练时间稍长,但总体上训练时间相差不多。
4.2.5 诊断结果分析
深度森林和改进深度森林在凯斯西储大学轴承数据集的准确率情况,如图7所示。图7中:predict为模型预测的健康状态类别;而true为实际数据的健康状态;“0~9”为10种不同的健康状态类别。由图7可知,基于stacking算法改进的深度森林故障诊断方法在每一种健康状态的诊断上都要优于传统的深度森林故障诊断模型,故障诊断性能更为优秀。

(a) 深度森林

(b) 改进深度森林图7 凯斯西储大学轴承数据集下准确率混淆矩阵Fig.7 Accuracy confusion matrix under Case Western Reserve University bearing data set
通过t-sne可视化显示原始输入数据和两个模型的输出情况,如图8所示。由图8可知,本文所提改进模型较原始深度森林模型分类情况更佳,分类更精准。
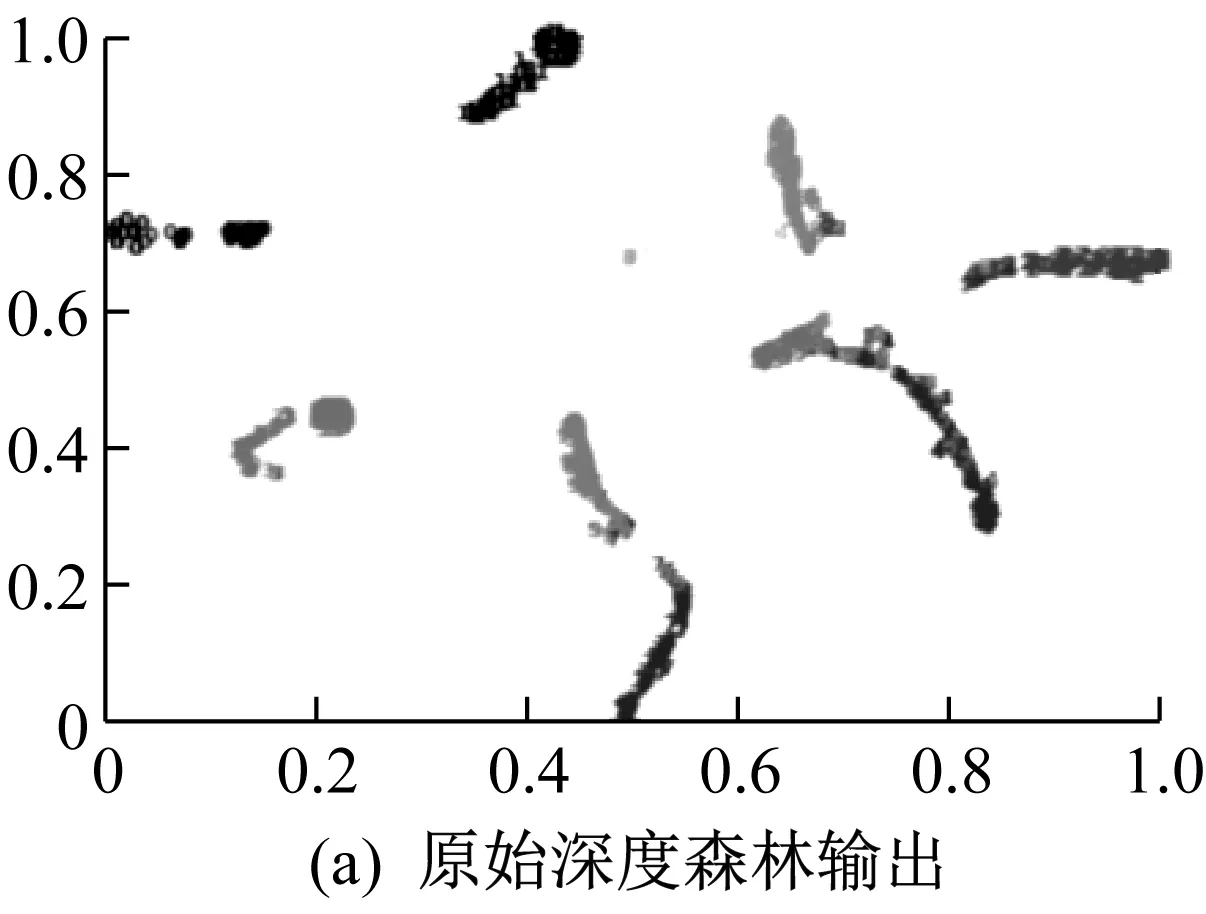
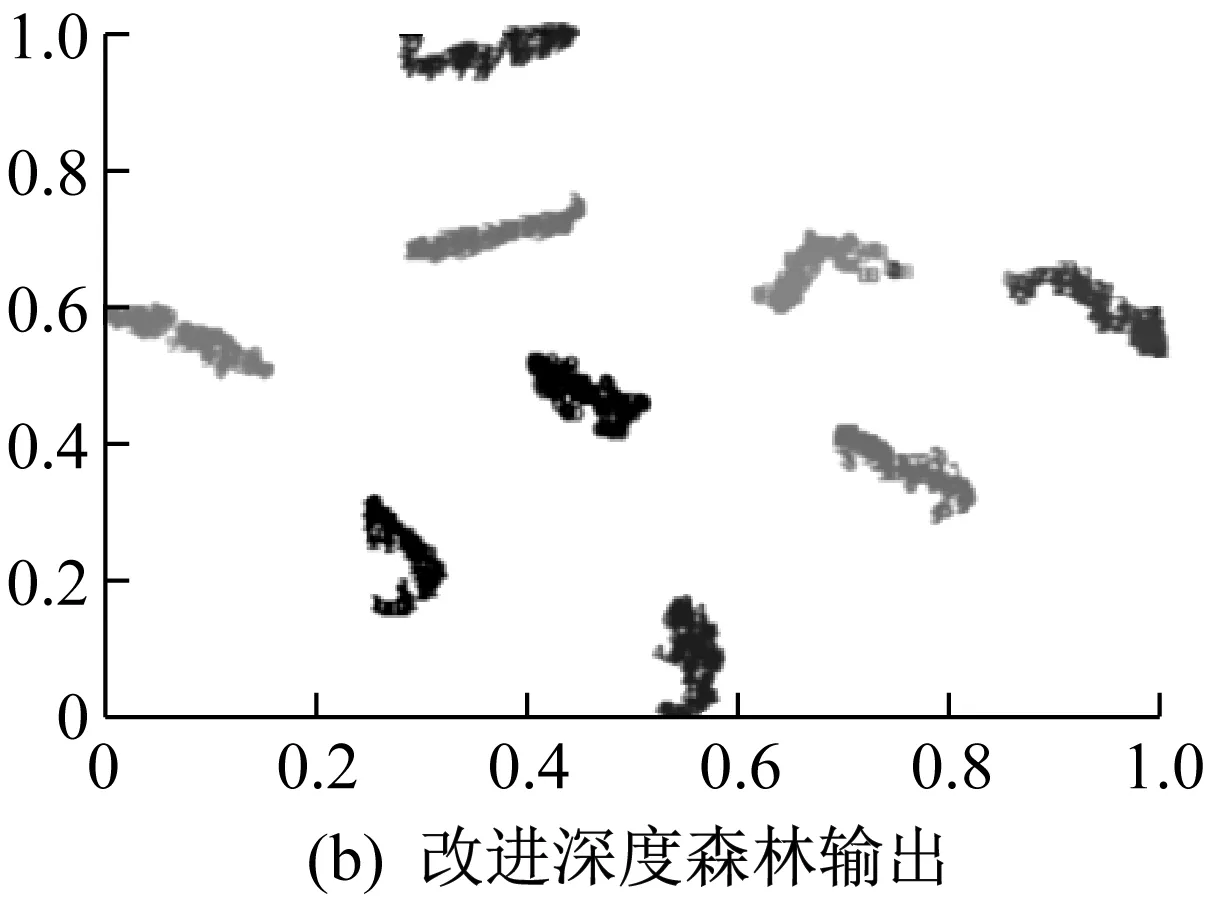
图8 可视化显示Fig.8 Visual display
在诊断准确率上面本文所提方法较传统深度森林提升幅度较大,到最终收敛本文所提方法提升了9.34%的准确率,对传统深度森林的诊断性能优化明显,如图9所示。与此同时,本文所提方法收敛速度较快,大约在4~5次迭代达到收敛,充分体现本文所提方法对传统深度森林诊断效率的提升。
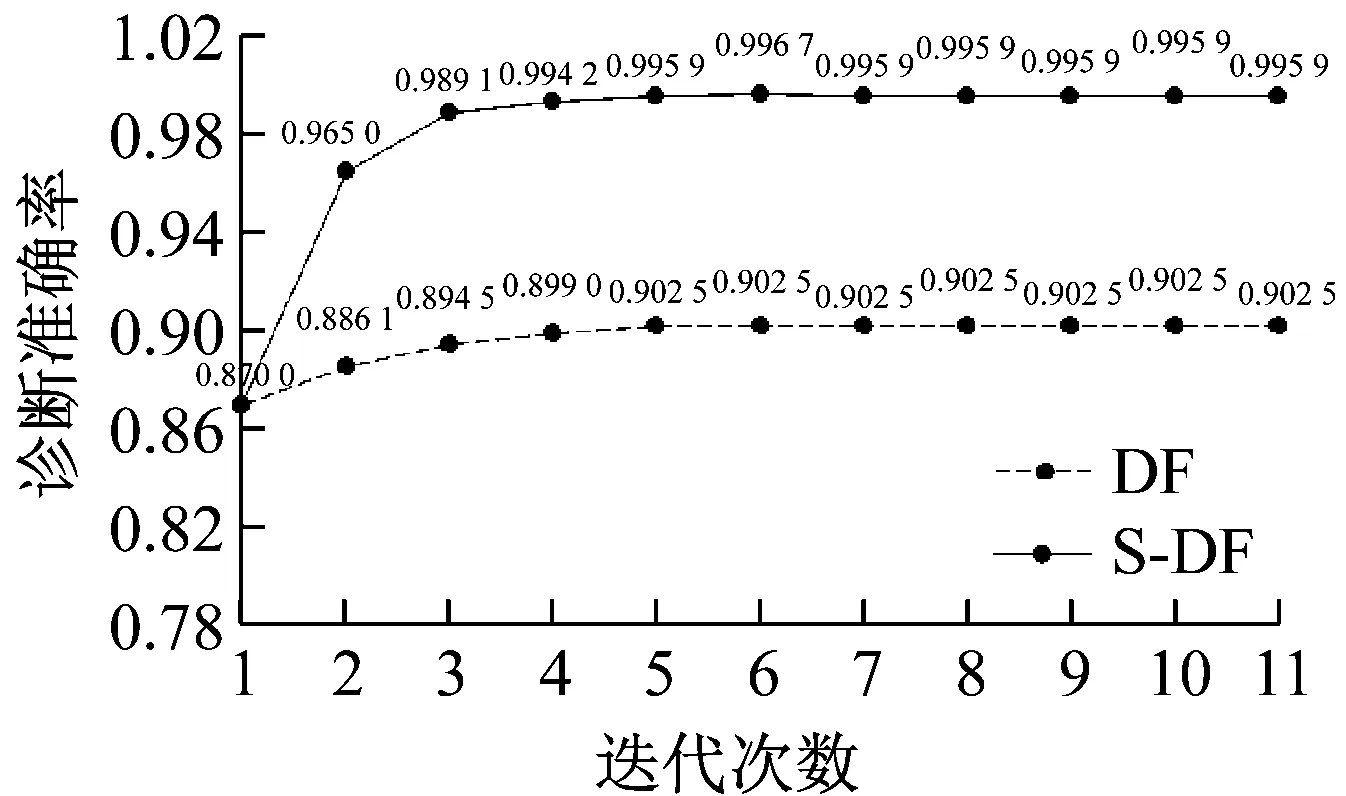
图9 凯斯西储大学轴承数据集下准确率随迭代次数变化Fig.9 The accuracy of Case Western Reserve University bearing data set changes with the number of iterations
4.2.6 抗噪试验
为了进一步验证本文所提方法的可行性,本文在原始数据集中加入-2 dB和-10 dB两种噪声信号,观察几种模型在这两个噪声数据集下的诊断准确率的变化,其中训练-总数据比例为0.8。
几种故障诊断模型在添加噪声信号后,诊断准确率大部分都有所降低,尤其在添加-10 dB噪声信号后下降的趋势更为明显,如表4所示。但本文所提方法在添加-2 dB和-10 dB噪声下仍然有99.33%和90.92%的诊断精度,远远高于其他模型,展现更优良的抗噪性能。并且在同一数据集下,本文所提方法的诊断精度更高,能更好的适用于一些对于诊断性能要求更高的工程项目。以上充分印证了本文所提方法的可行性与优越性。

表4 两个噪声数据集下不同诊断方法对比Tab.4 Comparison of different diagnostic methods under two noisy datasets
4. 3 齿轮箱数据集测试试验
4.3.1 试验条件
此工况下的数据来源于千鹏公司的齿轮箱数据集,试验台由变速驱动电机、轴承、齿轮箱、轴、偏重转盘等组成,如图10所示。通过调节配重、调节部分的安装位置以及组件的有机组合快速模拟各种故障。系统的机械部分还包括被测部件:有缺陷的轴承(外圈缺陷、内圈缺陷、滚珠缺陷);3只备件齿轮;旋转圆盘的配重块(在圆盘圆周边缘每隔10°开一螺孔,用于固定和调平衡用的配重块);加速度传感器;速度传感器。
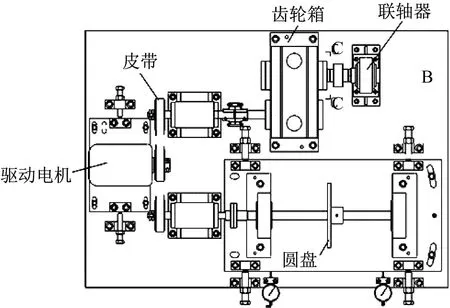
图10 千鹏公司试验台Fig.10 Qianpeng Company test bench
4.3.2 数据说明和模型参数选择
在本试验中,一共包含9个特征分别是:转速,输入轴X方向位移,输入轴Y方向位移,输出轴Y方向位移,输入轴电机侧轴承Y加速度,输出轴电机侧轴承Y加速度,输入轴负载侧轴承Y加速度,输出轴负载侧轴承Y加速度,输出轴负载侧轴承X加速度,输出轴负载侧轴承X磁电式速度。健康状态包括正常和5类故障状态,其中这5类故障状态包含大齿轮故障、小齿轮故障、以及二者的混合故障,具体情况如表5所示。

表5 数据集汇总Tab.5 Summary of datasets
本文将在输入轴电机侧轴承、输出轴电机侧轴承等处传感器测得的数据直接输入试验模型中进行训练。在千鹏公司齿轮箱数据集中,本文一共设置20 000组数据,6种健康状态即6种分类标签,每一个样本的特征长度为9,其中训练-总数据比例为0.8。
在千鹏公司齿轮箱数据集中多粒度扫描环节选取的滑动窗口长度为6,剩余模型参数选择与4.2.3节中保持一致。
4.3.3 与其他故障诊断模型对比
在千鹏公司数据中,由于数据集包含的特征数量较少,且齿轮箱故障具有多种类混合故障的特点同时本文将多个传感器采集到的数据直接输入到模型中训练,去除了特征提取环节,不可避免的给故障诊断带来了难度。因此,本文选择的对照故障诊断模型SVM、RF、AdaBoost、KNN、GaussianNB在此数据集下的故障诊断准确率只有89.7%,82.35%,79.42%,83.45%和90.05%。但在此工况下本文所提方法有98.05%的诊断准确率比传统的深度森林诊断模型97.80%的诊断准确率高出0.25%,且诊断性能要远远优于上述其他模型。
各个模型的诊断时间相对长短情况与凯斯西储大学轴承数据集相似。同时因为输入的特征数目和需要分类的健康状态较少,所有模型诊断时间都相对凯斯西储大学轴承数据集的诊断时间要少很多。千鹏公司数据下不同诊断方法对比,如表6所示。

表6 千鹏公司数据下不同诊断方法对比Tab.6 Comparison of different diagnostic methods under the data of Qianpeng Company
4.3.4 诊断结果分析
深度森林和改进深度森林在千鹏公司齿轮箱数据集的准确率情况,如图11所示。图11中:predict为模型预测的健康状态类别;而true则为实际数据的健康状态;“0~5”为6种不同的健康状态类别。
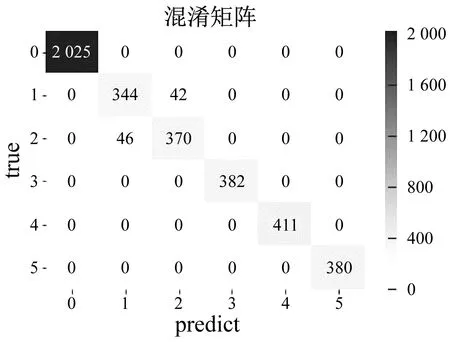
(a) 深度森林
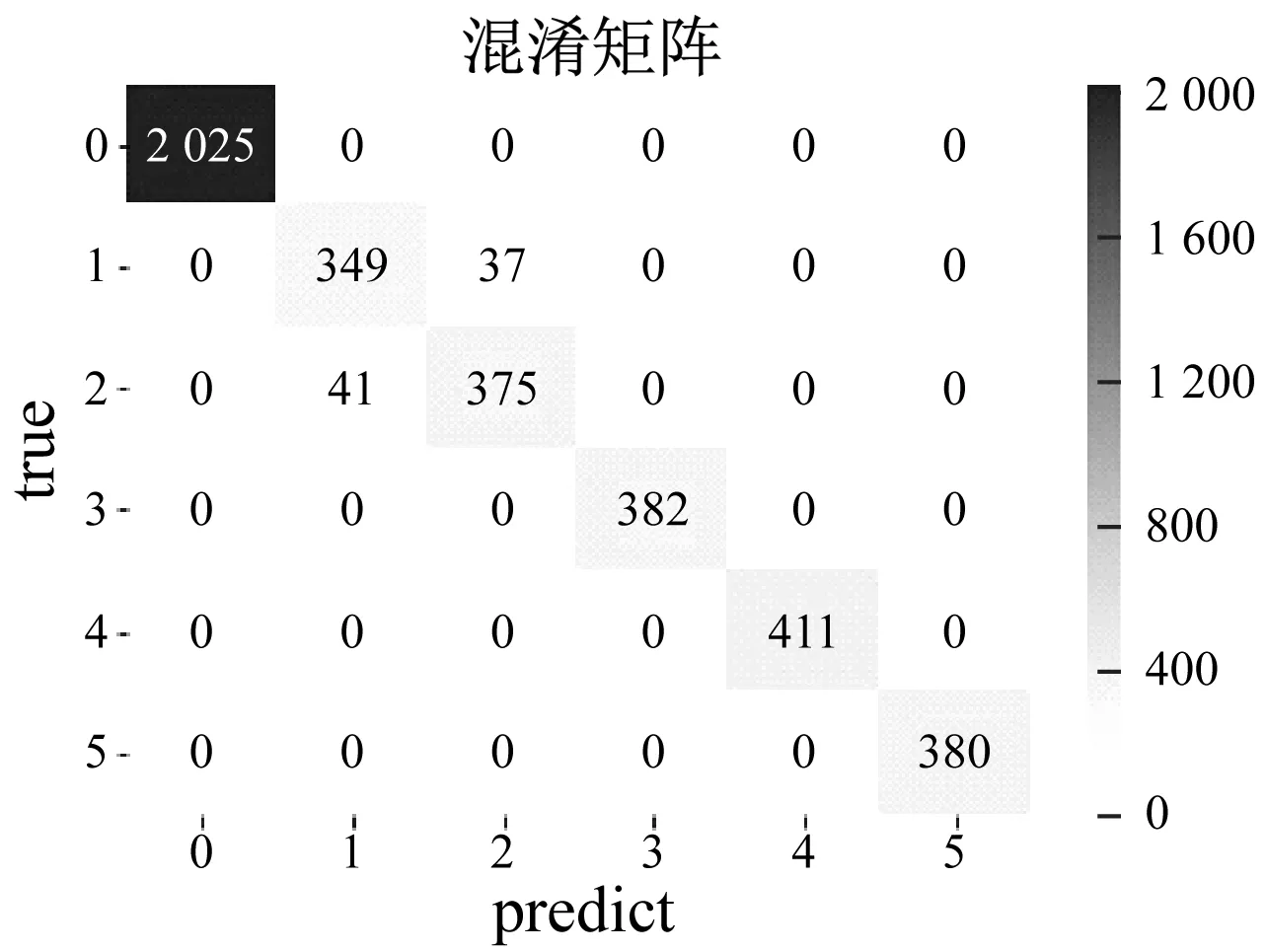
(b) 改进深度森林图11 千鹏公司齿轮箱数据集下准确率混淆矩阵Fig.11 Accuracy confusion matrix under the gearbox data set of Qianpeng Company
本文所提方法和传统的深度森林故障诊断模型在千鹏公司数据上的准确率混淆矩阵大致相同,但在第1类、第2类健康状态诊断中,两种模型却出现了误分类情况,具体分析如下:第一类健康状态是大齿轮点蚀;而第二类健康状态是大齿轮点蚀+小齿轮磨损的混合故障状态,这两种故障在一些特征的变化上面相似,在故障分类上造成干扰。
但本文所提方法在原有深度森林基础上添加了stacking层对数据进行处理,不仅保存了原有深度森林模型的优势,还结合stacking层多个初级学习器的优点,实现了在细微处更好的诊断效果,如图12所示。
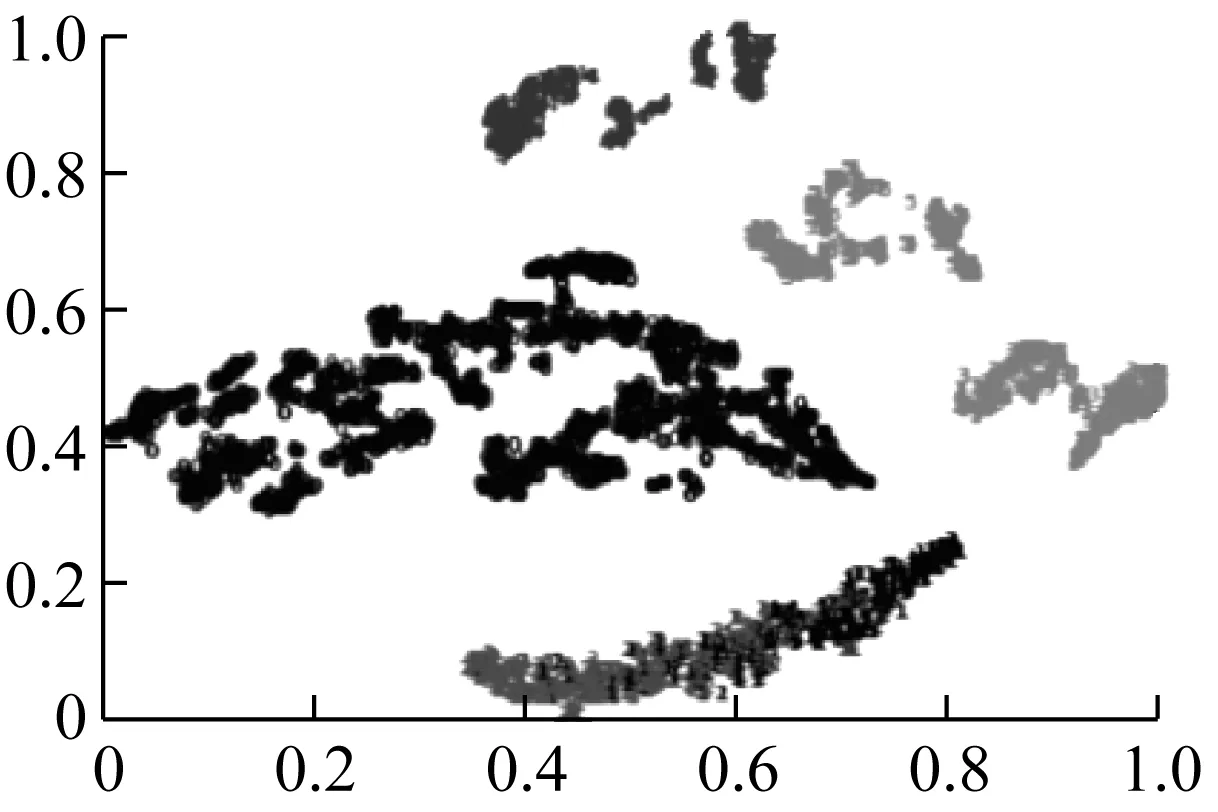
(a) 原始深度森林输出
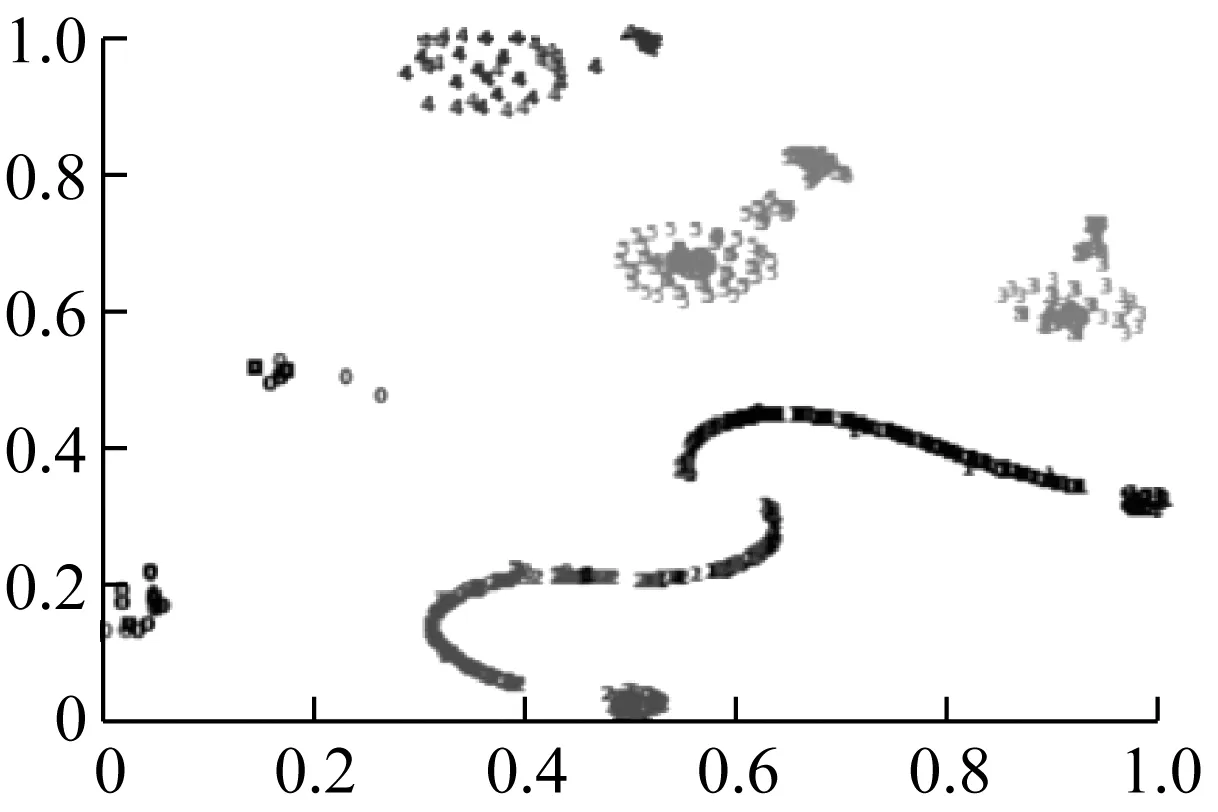
(b) 改进深度森林输出图12 可视化显示Fig.12 Visual display
本文所提方法在准确率上面有所提升,同时本文所提方法与原始深度森林收敛速度均较快在第4、第5次迭代循环中达到收敛,印证本文所提方法对原始深度森林诊断效率的提升,如图13所示。

图13 千鹏公司齿轮箱数据集下准确率随迭代次数变化Fig.13 The accuracy of the gearbox data set of Qianpeng Company varies with the number of iterations
在凯斯西储大学轴承数据集中,因为只存在单一振动点特征,直接输入模型进行训练得到的效果并不理想。为了缩小源域和目标域之间的分布差异,得到高维空间各单视角特征集,本文在凯斯西储大学轴承数据集中采用特征提取方法。而在千鹏公司齿轮箱数据集中,因为输入特征数目满足分类诊断任务,再进行特征提取工作会加大时间成本。尽管模型准确率会有所提升,但训练时间过长成本过高,故在千鹏公司齿轮箱数据集中不采用特征提取工作,如表7所示。
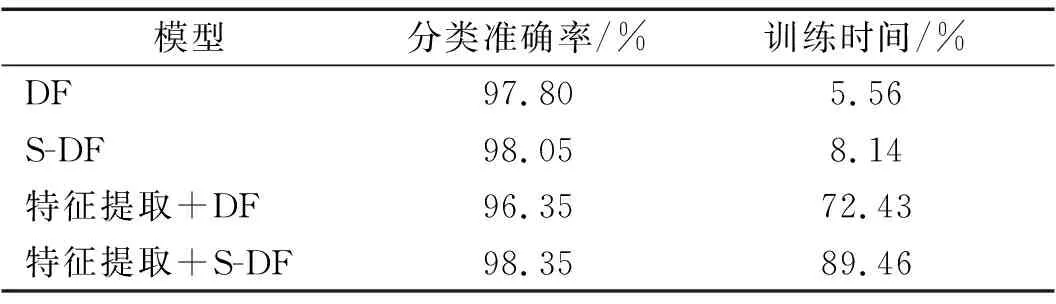
表7 千鹏公司数据下引入特征提取后模型性能对比Tab.7 The model performance comparison after feature extraction is introduced under Qianpeng Companydata
由于采用特征提取方法,得到的特征数目众多,其中的特征信息存在冗余现象。如果仅利用多粒度扫描对部分特征分析转化特征向量会造成误诊现象。而本文所提方法结合stacking算法,综合考虑所有特征避免信息冗余弊端,实现更好的诊断性能,从而使深度森林更适应特征数目过多的情况。因此,本文所提方法能在凯斯西储大学轴承数据集上诊断性能提升更为明显。
5 结 论
针对原始深度森林模型在多粒度扫描环节中可能会忽视输入特征彼此之间的联系造成诊断准确率下降的问题,本文提出了一种将stacking集成学习方法与多粒度扫描结合的改进深度森林方法,并用于旋转机械故障诊断,通过传动系统故障数据集对该方法进行了验证。
(1) 通过采用凯斯西储大学轴承数据集故障诊断比较试验,本文所提方法有99.59%和98.05%的诊断精度,诊断性能明显优于AdaBoost、SVM、KNN、GaussianNB等常用模型,且大幅提高了深度森林模型的诊断性能,为基于数据驱动的旋转机械故障诊断方法提供了一条新的路径。
(2) 在处理通过多粒度扫描和stacking层得到的特征数据时,在级联森林中只应用了随机森林和完全随机森林,使用的模型过于单一,在某些情况下可能无法精准的对故障进行诊断,还须对级联森林的缺陷做进一步优化。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
核安全(2022年3期)2022-06-29
保定学院学报(2022年2期)2022-04-07
粉末冶金技术(2021年3期)2021-07-28
小型微型计算机系统(2020年10期)2020-10-21
数学大世界(2019年7期)2019-05-28
—— “T”级联
同位素(2019年1期)2019-03-14
数码设计(2017年1期)2017-10-13
中华建设(2017年1期)2017-06-07
电子制作(2016年19期)2016-08-24
