
基于混合倒谱系数与CNN的OLTC动作声信号快速分辨方法
2022-11-21 03:38刘云鹏王博闻张兴辉
振动与冲击 2022年21期
刘云鹏, 王博闻, 韩 帅, 高 飞, 王 康, 张兴辉
(1. 华北电力大学(保定) 河北省输变电设备安全防御重点实验室, 河北 保定 071003;2. 中国电力科学研究院有限公司, 北京 100192;3. 国网福建省电力有限公司电力科学研究院, 福州 350007; 4. 国家电网公司, 北京 100031)
大型电力变压器中的有载分接开关(on-load tap changer,OLTC)具有调节电压的重要作用,其机械结构比较复杂因此极易发生机械类故障[1]。以某省110 kV及以上变压器统计为例,其中由OLTC引起的故障比重占18.13%,六成以上都是机械类故障。为了监测OLTC机械状态,及时发现OLTC的异常动作,目前已有许多研究将振动检测方法应用于OLTC机械状态监测方法[2-5]。近年来,声纹监测技术也应用于OLTC机械状态监测和诊断中[6-7]。振动与声纹为机械波在不同介质中的表现形式,因此二者特征机理类似声纹监测在成本低廉、布置方式简单且空间敏感度低等方面具有独特优势[6],然而在声信号监测过程中,判别系统易受到外界信号干扰发生误动或漏动,给后续诊断带来困扰。因此在边缘计算端需要一种能够快速区分OLTC动作信号与其他环境干扰信号的检测方法。目前的声信号检测方法一般设计用于故障状态识别,而没有考虑对外界干扰的筛选,无法直接应用于OLTC动作声信号的端点检测。
对此,本文通过一种混合倒谱计算方法与轻量级卷积神经网络结构对OLTC动作与干扰声信号进行快速区分。首先通过现场采集与人工混音的方式形成了声信号样本库,样本库包含1 320条OLTC动作声信号样本与600条变压器运行环境下外界干扰声信号样本;其次,根据OLTC声信号的频率分布特性,分别采用梅尔倒谱系数(Mel frequency cepstral coefficient, MFCC)、伽马通滤波倒谱系数(Gammatone filter cepstral coef-ficient, GFCC),幂律归一化倒谱系数(power-normalized cepstral coefficient, PNCC)对原始信号进行降维与初步特征提取;最后,引入类视觉几何组(visual geometry group,VGG)结构的卷积神经网络(convolutional neural networks, CNN)将MFCC,GFCC,PNCC三重特征进行混合,构成OLTC声信号与干扰信号二分类模型,并通过数据集验证模型的有效性。
1 OLTC声信号采集与样本库构建
实现声纹辨识模型的训练,需要积累类型多样、数量可观的OLTC动作和外界干扰声信号数据。为此本文从现场和实验室两方面构建了OLTC动作声信号数据集、从现场和公开数据集两方面构建外界干扰声信号数据集。另外,为了还原变压器本体声纹的背景干扰,本文采集了1 800例变压器本体声纹数据,以提高声纹辨识模型的泛用性。
1.1 OLTC声信号的数据采集
OLTC声信号数据集主要由现场采集与实验室采集两部分组成。
1.1.1 现场采集
在±800 kV金华换流站进行了OLTC动作声信号现场采集。现场采集情况如图1所示。

图1 换流变压器中的OLTC动作声信号采集Fig.1 Acoustic signal acquisition of OLTC in converter transformer
现场采集于该站停电大修期间开展,档位升降为手动控制,对每台OLTC升档与降档分别采集15例,具体的数据样本分布,如表1所示。

表1 OLTC现场声数据样本分布Tab.1 Distribution of OLTC acoustic data samples in actual scene
采集设备选用具有指向型的枪式电容麦克风在OLTC控制箱附近进行采集,指向型麦克风能够减弱其他方向的噪音影响,提高样本质量。由于OLTC信号大量分布在可听声频段内,因此麦克风的频率响应范围为20 Hz~20 kHz,配合使用的录机信号采集频率设为48 kHz,后续采集声纹的设备与参数配置相同,不再赘述。
1.1.2 实验室采集
为了获得更为丰富的OLTC声信号样本,增强后续端点检测模型的泛用性,研究在数据样本中加入OLTC传动机构卡涩和内部组件松动两种典型OLTC故障的模拟声纹样本。
实验室声纹样本基于一套CM型110 kV分接开关模型,试验平台参数,如表2所示。
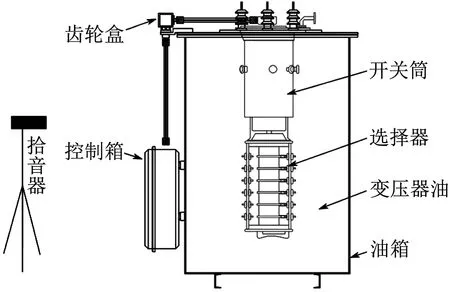
图2 实验室搭建的OLTC声信号采集平台Fig.2 OLTC acoustic signal acquisition platform built in laboratory

表2 OLTC试验平台参数Tab.2 OLTC experimental platform parameters
两种典型机械故障布置,如图3所示。试验平台分别使用在传动齿轮处加入木屑和拧松紧固螺栓的方式模拟传动机构卡涩和紧固件松动两种故障。完成故障布置后,将不同状态的OLTC进行换挡操作,并开展声信号采集。OLTC实验室声音数据样本分布,如表3所示。

(a) 传动机构卡涩

(b) 内部组件松动图3 OLTC试验平台故障布置Fig.3 Fault arrangement of OLTC experimental platform

表3 OLTC实验室声音数据样本分布Tab.3 Distribution of acoustic data samples from OLTC experimental platform
1.2 环境干扰信号的数据集
本文使用ESC-50[8]公开数据集与自采集的变压器处环境噪声作为环境声干扰数据集,数据集样本分布如表4所示。其中,ESC-50数据集包括50类各种常见的日常声音事件,声音样本与变压器所处环境噪声具有一定差异,因此研究额外采集并补充了10类变电站内的噪音数据集,包括刀闸开合、电晕放电、电钻等噪声用于提高后续检测模型在变压器场景下的适用性与泛化性。

表4 环境干扰声音数据样本分布Tab.4 Environmental interference acoustic data sample distribution
1.3 变压器背景噪声采集与叠加
由于现场状态下的OLTC动作声信号一般存在变压器本体声信号背景噪声,因此本文在河北省22个500 kV变电站进行了变压器本体声信号样本采集,并以OLTC时域信号峰值为基准,对背景噪声进行幅值调整后叠加于1.1节的OLTC动作声与1.2节的干扰声中,从而模拟现场声纹环境。在叠加过程中,将从1 800例变压器本体声音数据中随机抽取样本作为背景噪声,以增强与验证后续检测模型在现场应用的效果。变压器本体声音数据样本分布,如表5所示。
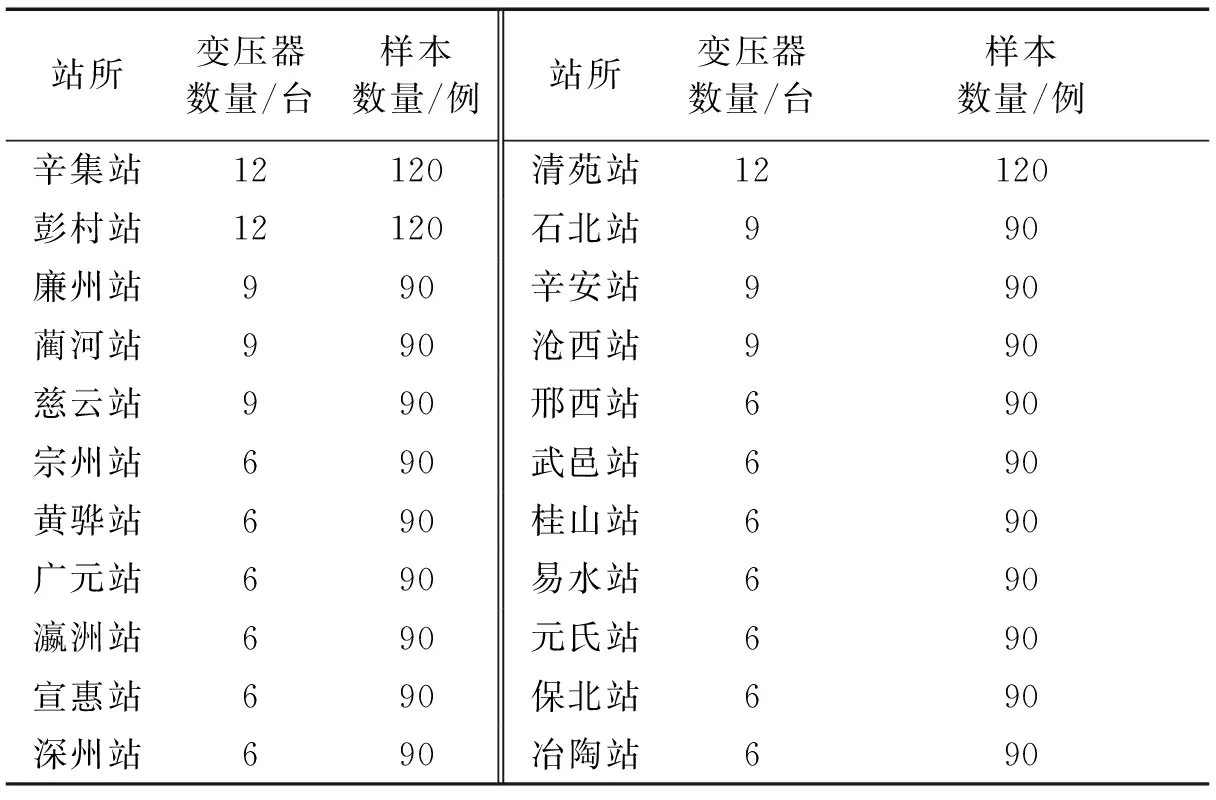
表5 变压器本体声音数据样本分布Tab.5 Sample distribution of transformer sound data
2 声信号预处理
声信号识别整体流程,如图4所示。流程主要包括声信号的预处理和模式识别两部分,其中信号预处理的主要作用是对变压器原始时域信号的特征提取和数据压缩,从而减少后续识别模型的运算量、提升识别效果。
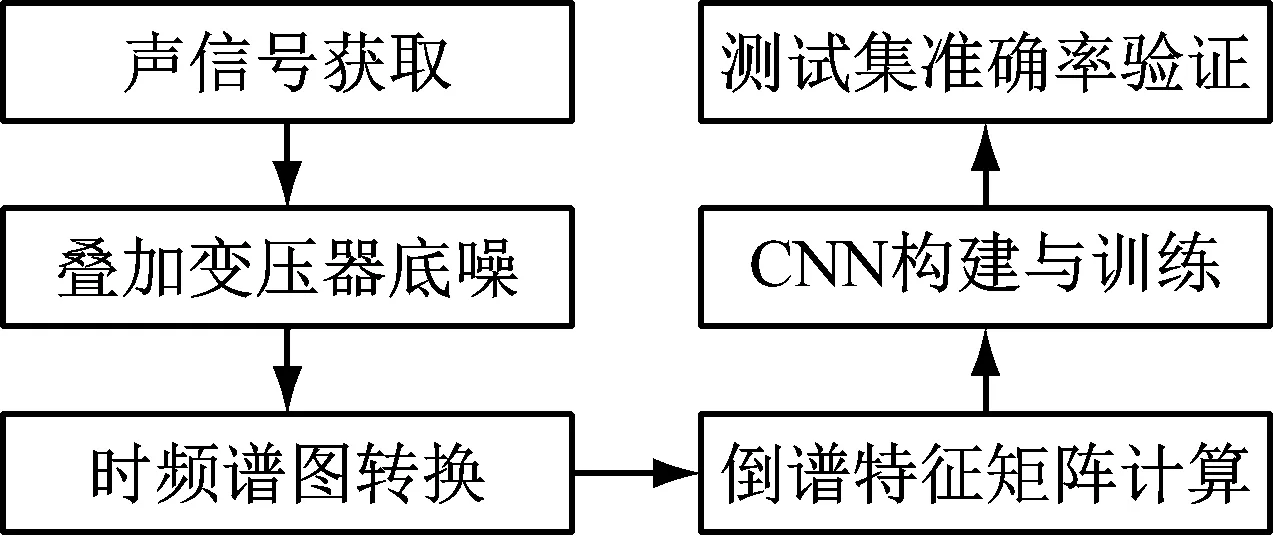
图4 声信号辨识流程Fig.4 Acoustic signal identification process
首先将叠加变压器本体运行噪声后的时域声信号转化为具有时域频域两个维度的时频谱图,然后通过计算MFCCs,GFCCs与PNCCs等3种倒谱对原始时频谱进行特征提取和降维,后续作为卷积神经网络的输入层。
2.1 时频谱图转换
由于原始的声信号的特征有限,因此一般需要通过将原始的时域声信号进行频谱分析,将不同时间内的频谱信息组合呈现为特征更为直观、信息更为丰富的时频谱图,用于后期机器学习等识别算法的训练。该过程主要包含了分帧、加窗以及离散傅里叶变换。
首先,对5 s的原始时域声信号进行交叠分段的分帧操作,考虑有载分接开关动作的暂态特性,本文选择帧长为0.1 s,帧移为0.05 s。
其次,为削弱傅里叶变换带来的频谱泄漏影响,还需要将每帧时域数据进行加窗处理。本文选取的是具有较好的时间和频率聚集特性的汉明窗(Hamming),即
w(n)=
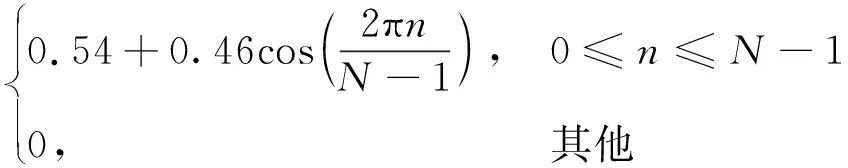
(1)
式中,N为汉明窗的长度,由帧长和采样率决定。
最后,对波形片段进行短时离散傅里叶变换,计算公式为式(2),即可得到能够同时描述时间与频率的时频谱。时频谱图中的横坐标为时间,纵坐标为频率,条纹状的图形的颜色代表当前频率在该时刻含量的大小,由功率谱密度(power spectral density,PSD)表示。

0≤n且k≤N-1
(2)
式中:k为频点序号;x(m,n),X(m,k)分别为第m帧原始离散时域信号和第m帧的频谱分布。由以上步骤可得到不同厂家的OLTC动作声信号时频谱图对比,如图5所示;外界干扰声信号时频谱图,如图6所示。由于数据库样本类型较多,限于篇幅此处仅展示部分时频谱图。

(a) 西电
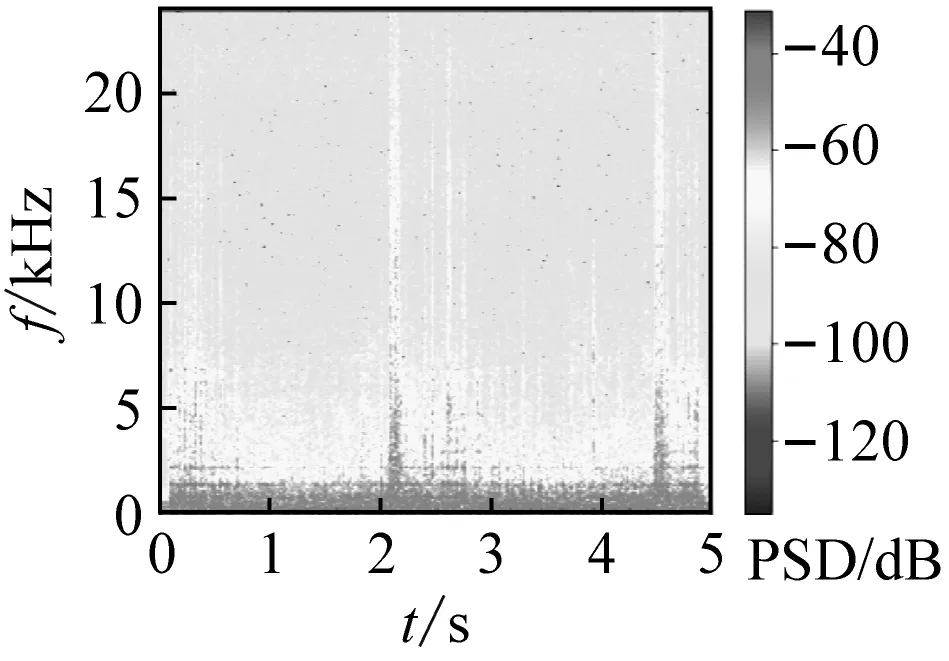
(b) 华明
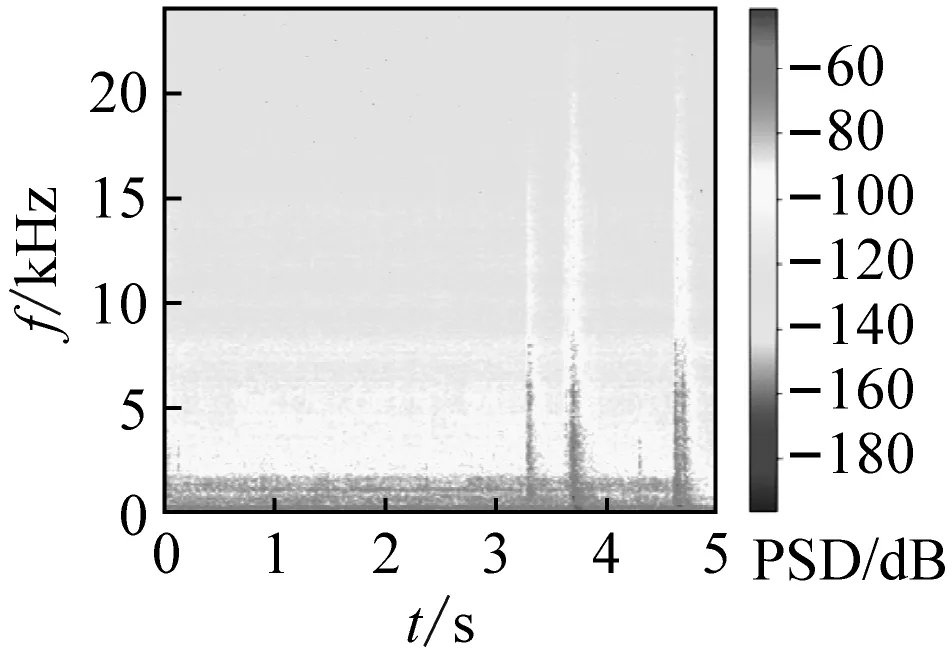
(c) MR
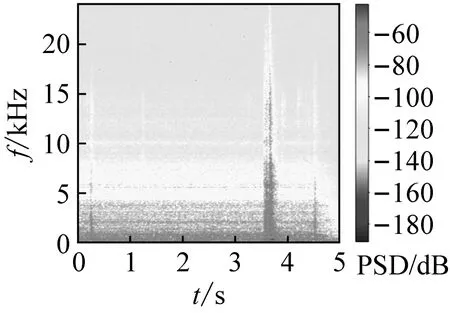
(d) 西门子图5 不同厂家OLTC声信号时频谱图对比Fig.5 Comparison of OLTC sound signal spectrum from different manufacturers
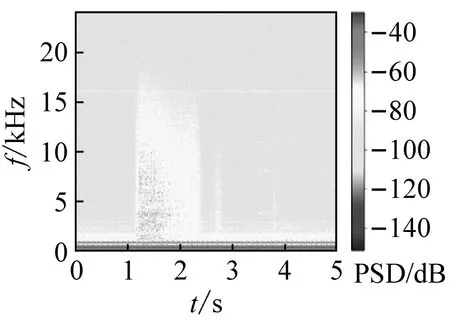
(a) 刀闸动作声

(b) 汽笛声

(c) 电锯声
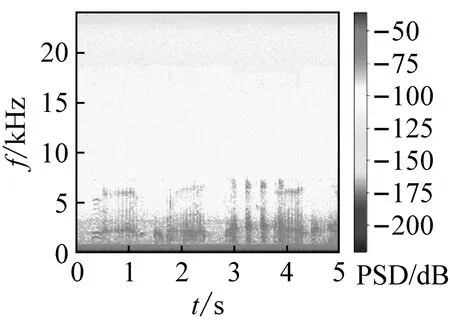
(d) 鸟鸣声图6 不同环境干扰声信号时频谱图对比Fig.6 Comparison of interference sound signal frequency spectrum in different environments
2.2 倒谱特征矩阵计算
OLTC多数故障发生在切换指令发出后30 s以内,因此相关声纹监测手段对实时性要求极高。本文中测得的OLTC动作声信号单样本的数据量可达近22万个数据,为了快速准确对声信号进行辨识,需在保留辨识特征的前提下对样本数据进行压缩处理。
各种倒谱系数都具备信号降维与特征提取功能,不同倒谱系数都具有各自优势和局限性,因此许多研究[9-10]将多种倒谱进行混合使用,以获得更好的特征提取效果。在各类倒谱系数中,MFCC的构建基础是听觉模型,GFCC的构建基础是耳膜模型,而PNCC在噪声背景下的声音特征更具有优势,以上倒谱在语音识别领域都已经得到了一定程度的应用[10-11],因此本研究选取MFCC,GFCC[12],PNCC[13]作为基础倒谱特征,构成倒谱特征矩阵,用于后续的特征融合和声信号识别,计算流程如图7所示。

图7 声信号倒谱特征矩阵计算流程图Fig.7 Calculation flow chart of acoustic signal cepstrum characteristic matrix
(1) MFCC计算
MFCC是基于人耳听觉感知特性的一种倒谱参数,在频域人耳听到的声音高低与频率不成线性关系,而在Mel域,人耳感知与Mel频率是成正比的。其关系可以用式(3)表达
Mel(f)=2 595lg(1+f/700)
(3)
梅尔频率倒谱系数的计算是以帧为单位进行的,以下为梅尔频率倒谱系数的具体计算步骤。
步骤1按式(1)计算得到每帧频谱X(m,k),对X(m,k)取模后平方得到功率谱。将功率谱通过频域为三角形的Mel尺度滤波器组得到新的参数R,滤波器组频率下限为fmin,上限为fmax,G为Mel滤波器数量。
步骤2将R(m,k)取自然对数
(4)
步骤3通过离散余弦变换得到G维MFCC
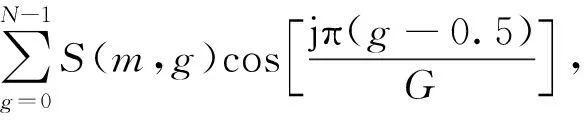
0 (5) 步骤4需要进行均值归一化。经上述步骤便可得到G维的MFCC。 (2) GFCC计算 GFCC的提取过程与MFCC提取过程几乎相同,两者区别在于功率谱通过的滤波器组是由G个不同尺度参数和形状参数的伽马滤波器组成的Gammatone滤波器组,而非Mel尺度滤波器,滤波器组频率下限为fmin,上限为fmax,后续步骤也相同。最终得到GFCC特征矩阵CGFCC(m,j)。 (3) PNCC计算 PNCC的提取过程的前两个步骤与GFCC相同,当功率谱通过Gammatone滤波器后得到Pg(m,g)。其中,Mw为平滑窗口的大小,一般将每一帧与前后两帧做平滑处理,此时Mw=1计算中时平均功率 (6) (7) g1=max(g-gw,1) (8) g2=min(g+gw,G) (9) 式中,gw设为4。 (10) 利用平均功率估计值μ[m]可对Tg[m,g]进行平均功率归一化 (11) (12) 式中,λμ为系数,可设置为任意常数。 为了更加接近人耳听觉神经的压缩感知特性,不同于MFCC所采用对数非线性,PNCC采用幂律非线性压缩 Vg[m,g]=Ug[m,g]1/15,0 (13) 最终进行离散余弦变换和均值归一化即可得到PNCC特征矩阵CPNCC(m,j)。 分别完成MFCC,GFCC,PNCC计算后,将三者合并为一个3维的倒谱特征矩阵。本文的声原始时频谱数据尺寸为498×24 000,经过信号降维与特征提取后的倒谱特征矩阵数据尺寸变为498×40×3,其中:498为时域分量;40为倒谱特征矩阵的频域分量;3为声信号的MFCC,GFCCs,PNCC 3层倒谱特征。倒谱特征矩阵的计算在保留声纹特征的基础上能够提升了后续深度学习的运算效率。 卷积神经网络(convolutional neural network,CNN)作为一种典型前馈型深度学习网络,在非线性映射和局部特征提取方面都具有显著优势[14]。在图像识别领域,CNN往往将彩色图像拆分为红绿蓝(RGB)3个颜色层作为网络的输入层,从而对不同色彩变化的特征进行学习感知。相似地,本研究将声信号的3种倒谱构成的倒谱特征矩阵作为输入层,构建混合倒谱-卷积神经网络(mixed cepstrum-convolutional neural network,MC-CNN)识别模型,从而进行声音分类识别。相较于人工设计的倒谱混合方法,通过深度神经网络的学习机制对3种倒谱进行融合能够使混合倒谱的融合方式具有自适应性。 为保证深度学习的有效性,在进行模型训练时需要对样本数据进行数据集划分:从1 320例OLTC动作案例中随机抽取480例作为训练集,120例作为测试集;外界干扰声音案例共600例,随机抽取480例作为训练集,120例作为测试集。最终形成数据集样本分布,如表6所示。所有数据首先按照1.3节方法随机叠加变压器背景噪声,然后按照第2章中的方法算得各自的倒谱特征矩阵,最终将所有带有标签的倒谱特征矩阵样本按随机顺序输入到CNN网络进行训练。 表6 声音数据库样本分布Tab.6 Sample distribution of acoustic database 经过结构参数优化后,本文研究构建了一个包含3层卷积-池化层的类VGG[15]小尺度CNN网络,详细结构如表7所示。在该网络中,Dropout概率设置为0.5;为了加快收敛速度并防止梯度消失现象,进行了批规范化操作[16]。 表7 用于OLTC声纹识别的CNN网络结构Tab.7 CNN structure for the OLTC voiceprint recognition 为了提高模型性能,研究对MC-CNN识别模型进行学习率(learning rate,LR)和批尺寸(batch size,BS)进行了优化。 3.3.1 学习率参数调节 MC-CNN识别模型的训练集损失率,如图8所示。过高的学习率会在迭代次数增加后降低学习效率,过低的学习率则会减慢训练速度。由测试结果可知,当学习率为0.000 1时,训练集损失率下降较为稳定且训练速度较快。 图8 不同学习率对MC-CNN模型的损失率影响Fig.8 Loss of MC-CNN model with different learning rate 3.3.2 批尺寸参数调节 批尺寸越小则误差越小。但批尺寸减小会导致训练时间延长,因此需要平衡准确率、误差和训练时间等指标最终确定训练参数。平均每次迭代的训练时间、最终准确率和到达最终准确率所需迭代次数,如表8所示。可见当批尺寸为32和40时准确率下降,当批尺寸为8,16,24时准确率都达到了100%,综合考虑迭代速度后,认为批尺寸为24时识别模型的性能最优。 表8 不同批尺寸训练时间对比Tab.8 Comparison of iteration time of different batch size 通过对学习率和批尺寸的优化,得到最终的MC-CNN识别模型。为更加直观地展示模型的识别效果,本文将深度学习模型进行了100次迭代,结果如图9所示。MC-CNN模型在迭代了80次之后,测试集识别准确率在99%~100%小幅波动,迭代100次时损失率为0.001左右。 图9 MC-CNN模型识别准确率与损失率Fig.9 Recognition accuracy rate and loss rate of MC-CNN model 为进一步验证本文提出方法的有效性,对MC-CNN,MFCC-CNN,GFCC-CNN,PNCC-CNN以及常规CNN模型的辨识成功率和运算时间进行了对比。在类VGG模型框架下,经过参数调优后,结果如表9所示。可见MC-CNN模型在识别成功率上表现最佳,样本运算时间相较于常规CNN方法具有明显提升,证明了本文所提出MC-CNN声识别模型的优越性。与使用单独某种倒谱系数预处理方法的方法相比,MC-CNN使用更多类型的倒谱特征能够适应种类繁杂的外界干扰声信号与信噪比不同背景噪声环境,牺牲了部分计算速度的但提高了准确率。 表9 OLTC与环境干扰声音辨识方法对比Tab.9 Comparison of OLTC sound and environmental noise identification methods 与直接使用时频谱图输入CNN网络进行训练和识别的方法相比,MC-CNN经过了混合倒谱计算的预处理后,数据量计算量大幅下降,样本的数据减少也意味着降低了深度神经网络的识别难度,因此能够提升识别率和降低识别时间。 3.3.3 外界干扰信号对识别效果的影响 由于现场运行环境复杂,有可能出现OLTC动作信号与外界干扰信号同时出现的情况,因此,需要对此类情况进行识别效果验证。 首先,从3.1节测试集中进行了随机抽取与排列组合,并进行混叠,形成了500例样本,如图10所示为两个样例的时频谱图。 (a) 西电+鸟鸣 (b) 西门子+连续汽笛图10 外界干扰信号与OLTC动作信号混合的时频谱图Fig.10 Spectrum diagram of mixing external interference signal and OLTC action signal 然后,利用已训练好的识别模型进行测试,用来检测在有外界干扰信号存在的情况下该模型对OLTC动作信号的识别能力。 测试结果表明,本文中的MC-CNN能够对98.4%的样本识别为OLTC动作,而对1.6%的样本识别为环境干扰信号。其中,识别为环境干扰的样本典型案例如图10(b)所示,此类样本具有以下特点:① 环境干扰信号强度较大,导致OLTC信号信噪比过低;② 环境干扰信号为持续时间较长,导致样本的全部时段都被环境干扰信号覆盖。针对此类持续性强干扰下OLTC动作声信号的识别,目前有待后续研究,但在实际应用时,可通过将声信号传感器放置位置靠近OLTC本体的方式提高信噪比,从而改善识别准确率。 本文对OLTC声信号快速辨识方法进行了研究。通过采集现场及实验室的OLTC声信号和环境干扰信号,构建数据集,建立MC-CNN模型对信号进行识别,得到的主要结论如下: (1) 不同厂家生产的OLTC声音时频谱特征各异,同时外界干扰信号种类繁多,直接使用幅值、峰峰值等人工设计的特征值提取手段进行区分比较困难。 (2) 采用混合倒谱的降维处理方式,可将计算数据量压缩2 000倍,能够提取特征的同时有效降低原始数据的维度,提升了后续算法模型的识别速度和准确率。 (3) 混合时频谱图结合CNN能够对OLTC动作与外界干扰信号进行准确区分,在本文的数据样本测试集中,混合时频谱图的成功率高于单个时频谱预处理和无预处理的CNN模型,且有较快的识别速度,证明了本文所提出Mel-CNN声音识别模型的有效性。通过本文的方法与OLTC故障声纹诊断算法相结合,能够实现在无电气连接的情况下对OLTC进行机械状态监控,对工程应用有一定借鉴价值。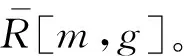
3 基于卷积神经网络的声信号辨识
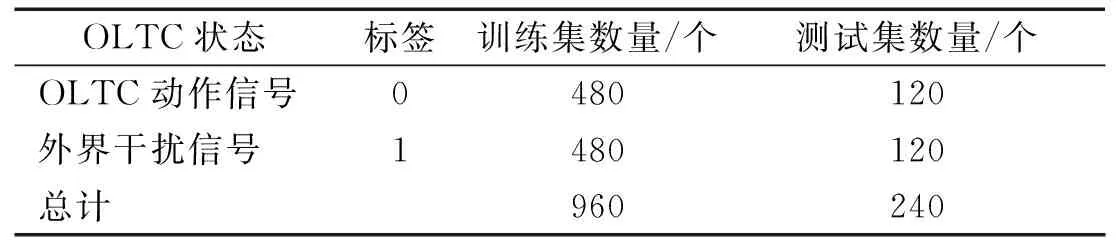
3.1 训练数据集与测试数据集
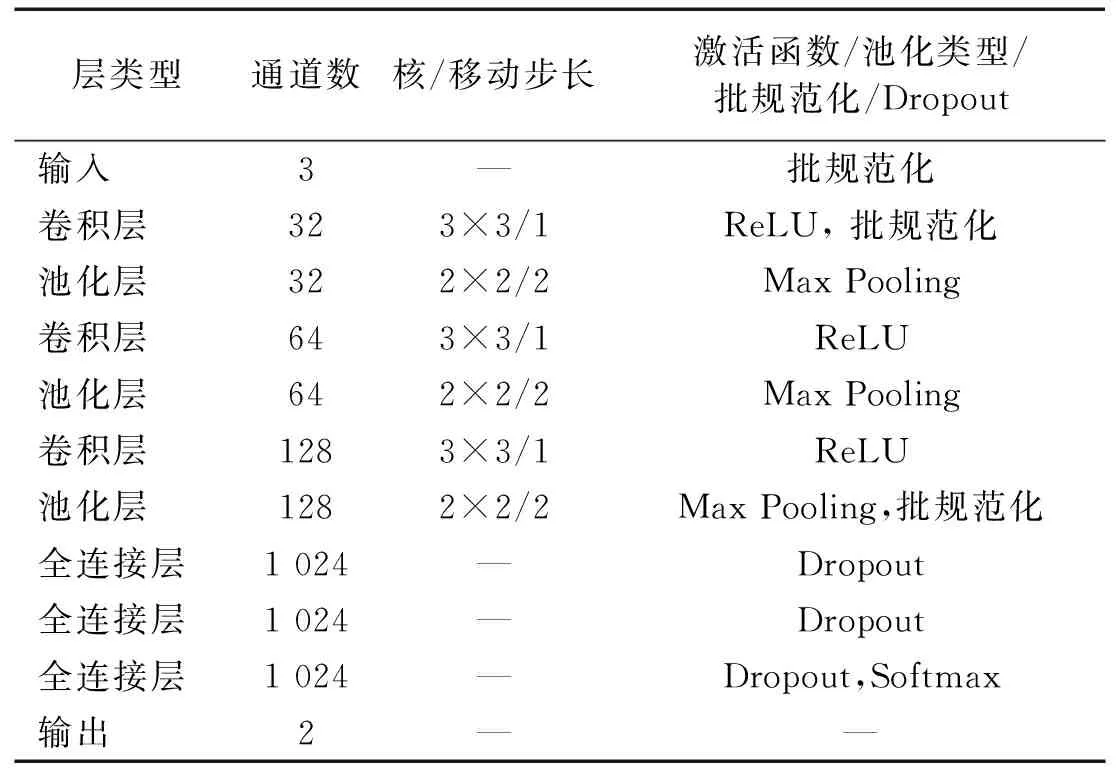
3.2 网络结构
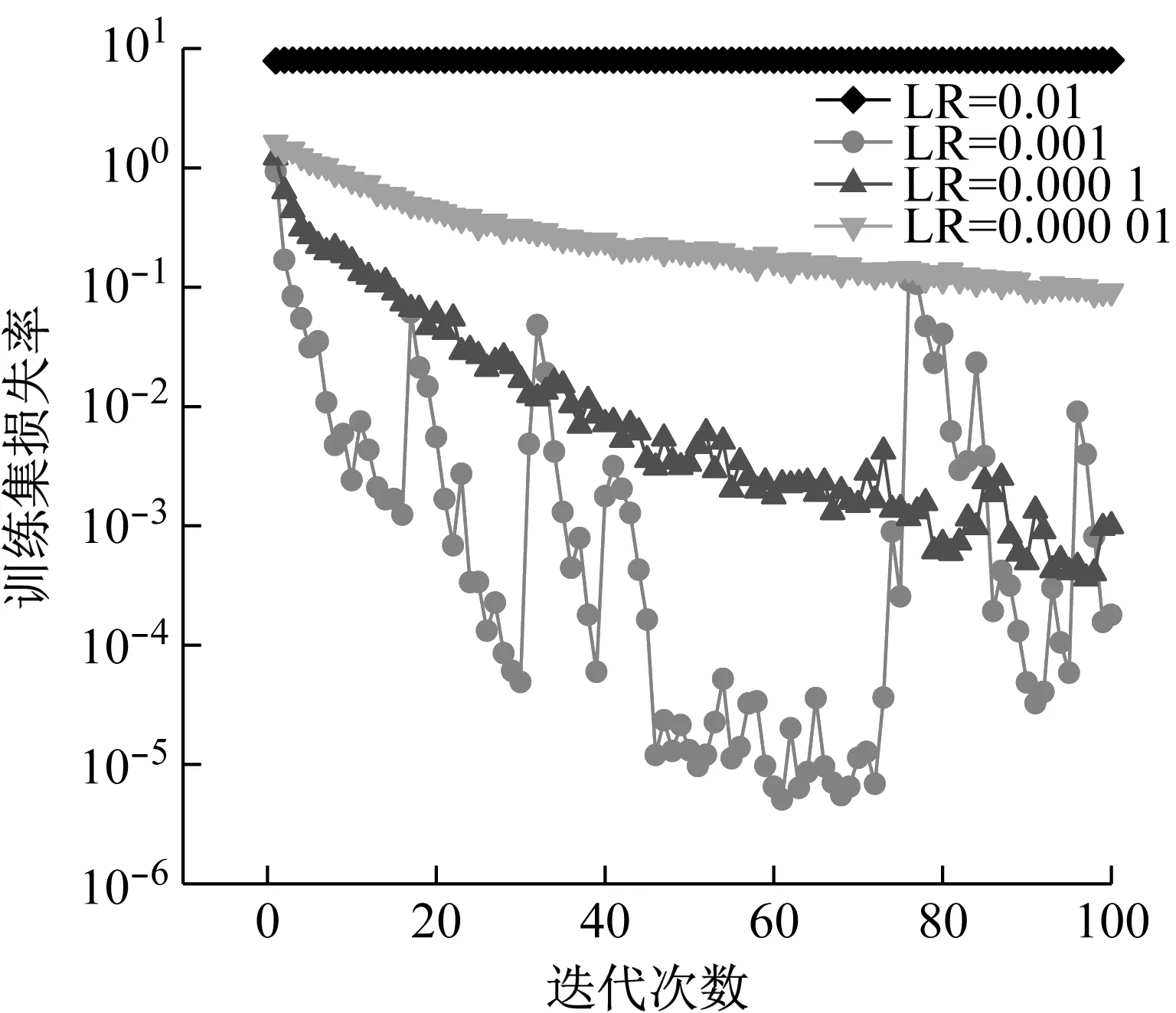
3.3 训练参数优化与识别模型结果

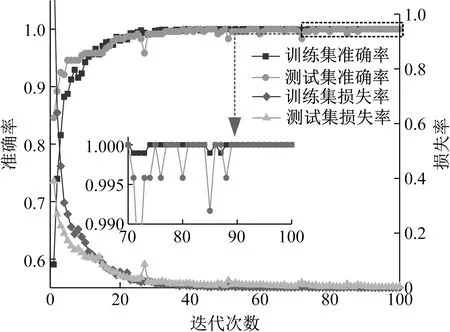



4 结 论
猜你喜欢
计算技术与自动化(2022年2期)2022-07-04海军航空大学学报(2021年1期)2021-09-01空间科学学报(2021年6期)2021-03-09通信电源技术(2020年22期)2020-03-27通信产业报(2018年32期)2018-11-24移动通信(2017年3期)2017-03-13空间控制技术与应用(2015年2期)2015-06-05浙江大学学报(工学版)(2015年1期)2015-03-01海军航空大学学报(2015年4期)2015-02-27现代电子技术(2009年13期)2009-08-31
